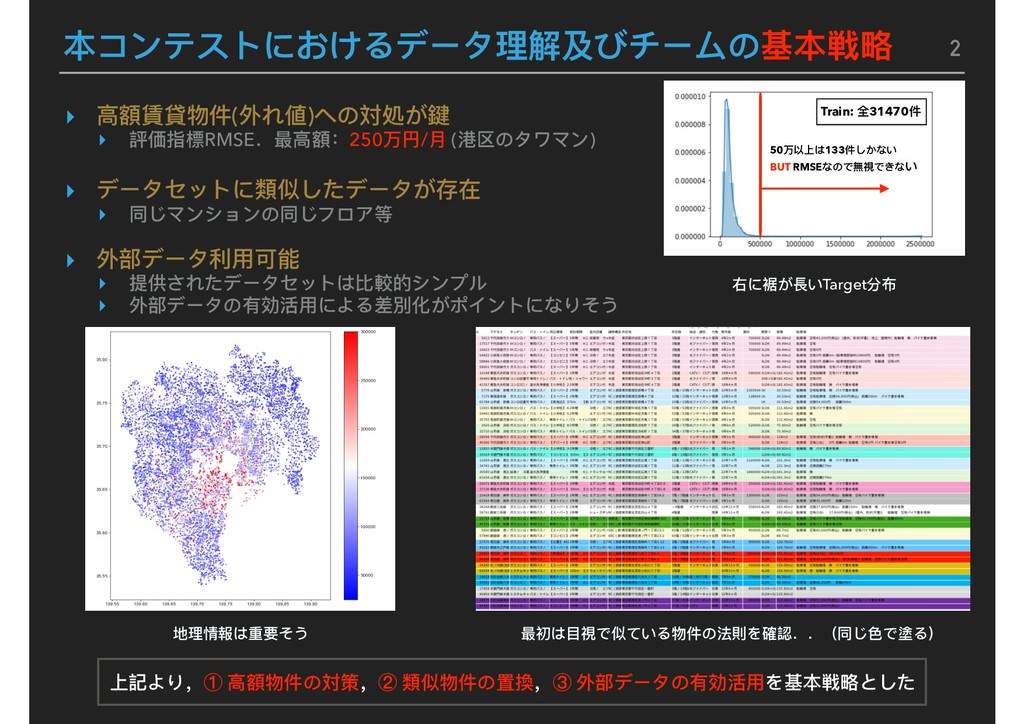
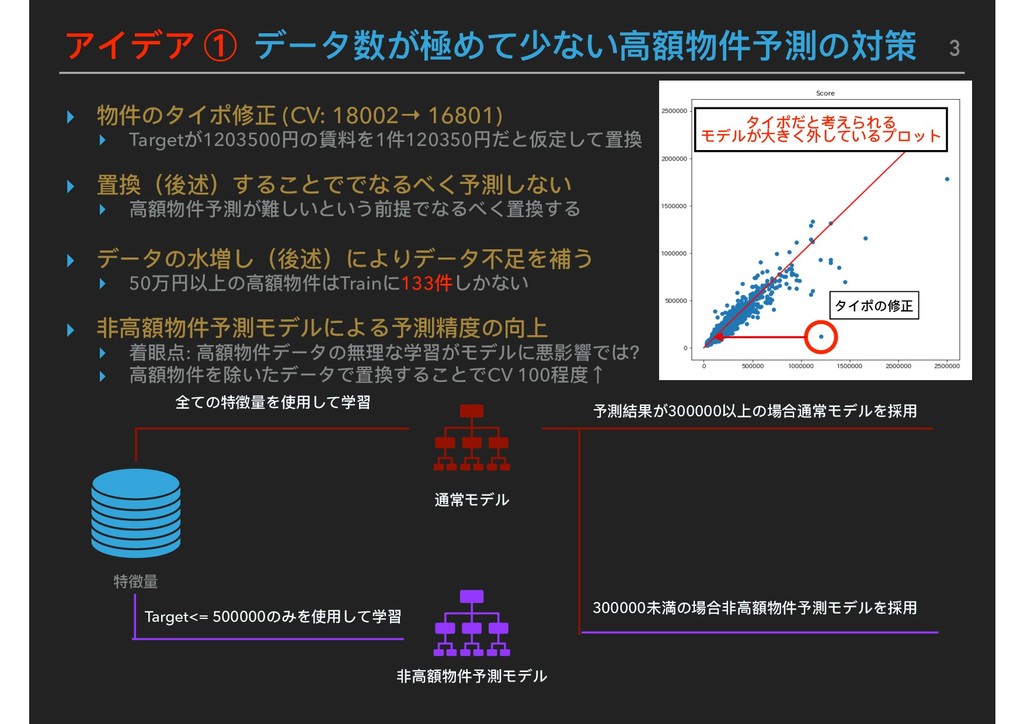
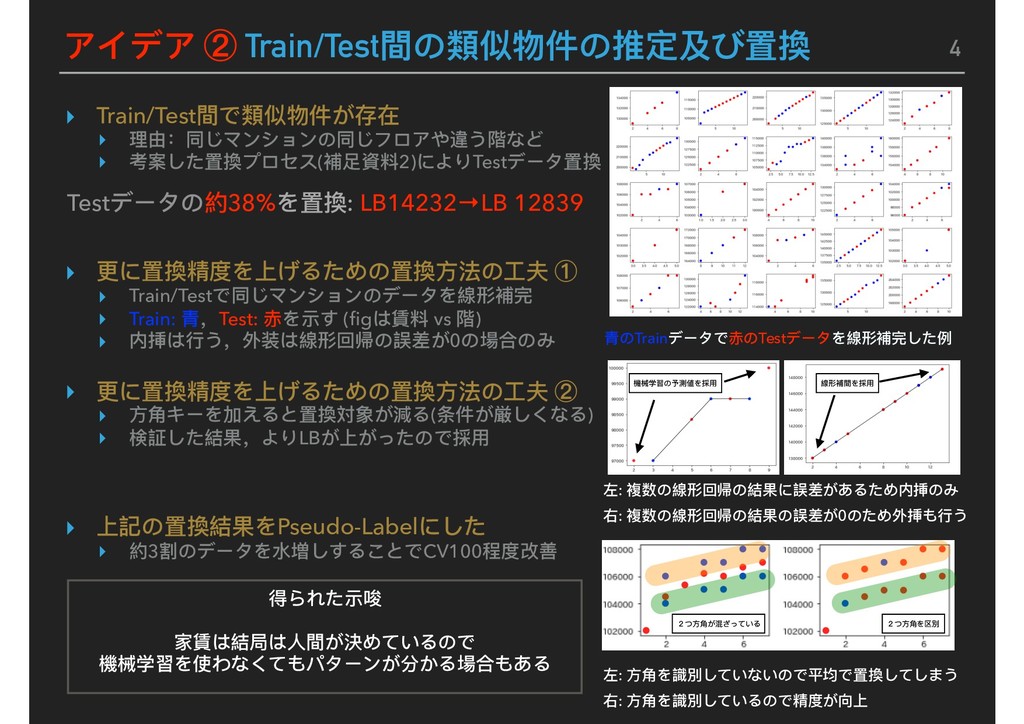
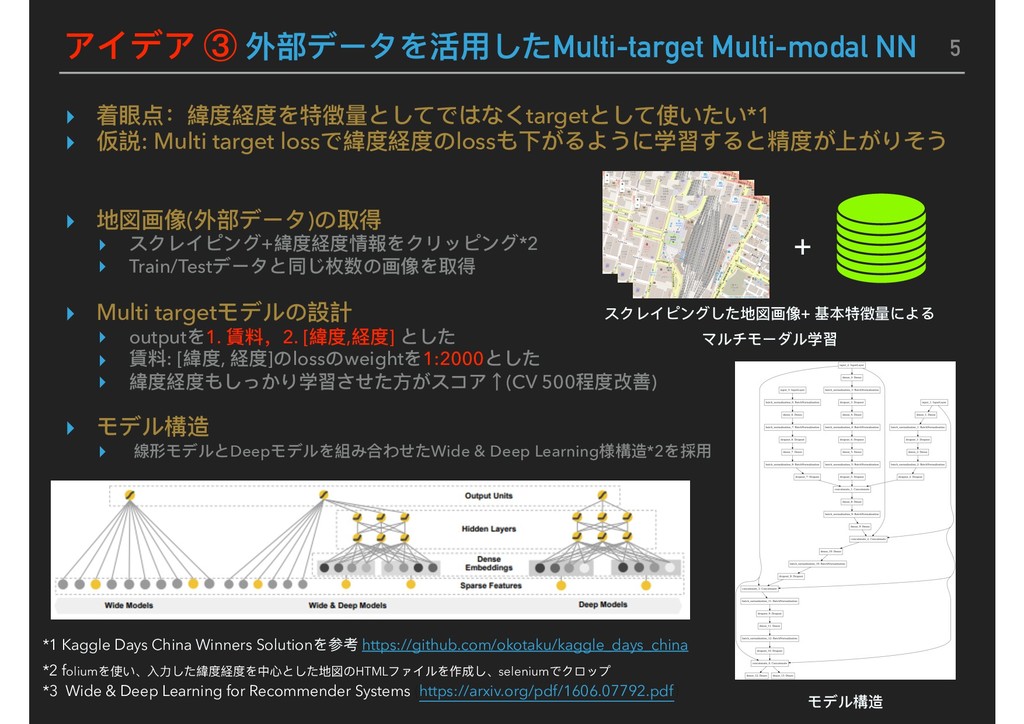
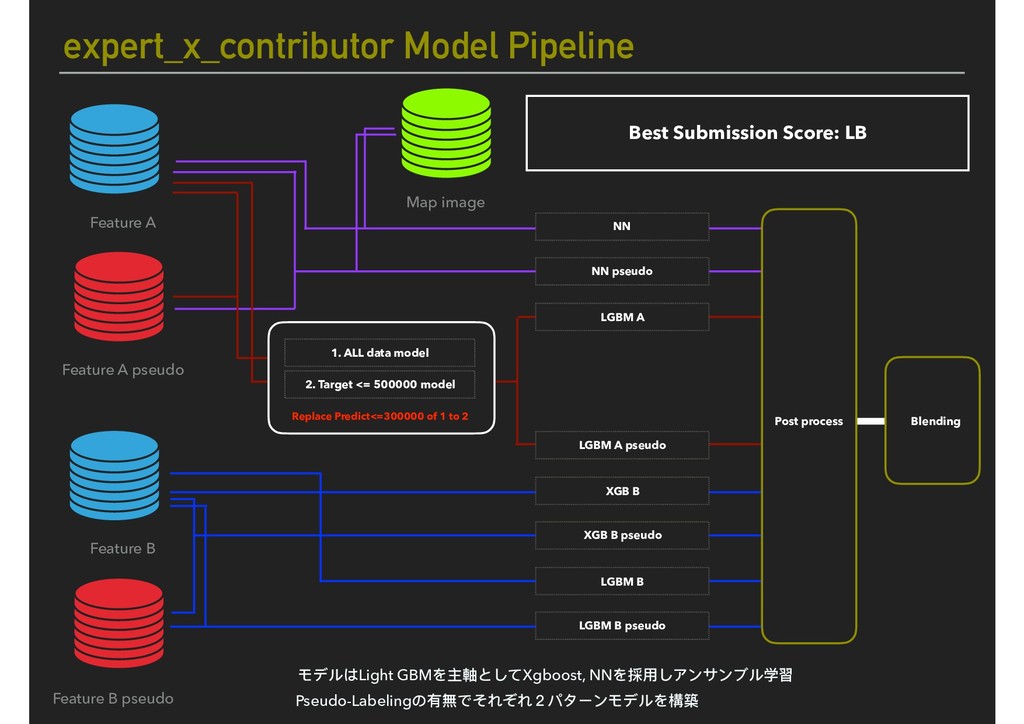
Map image NN NN pseudo LGBM A LGBM A pseudo XGB B XGB B pseudo LGBM B LGBM B pseudo 1. ALL data model 2. Target <= 500000 model Replace Predict<=300000 of 1 to 2 Feature B pseudo Post process Blending Best Submission Score: LB モデルはLight GBMを主軸としてXgboost, NNを採⽤用しアンサンブル学習 Pseudo-Labelingの有無でそれぞれ2パターンモデルを構築
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![補⾜足資料料4 上⼿手く⾏行行かなかったアイデア 11 ▸ モデリング ▸ Targetを[0, 1]の範囲で正規化 → Xntropy](https://files.speakerdeck.com/presentations/ca99613e063b456e9edf1ef2f0727395/slide_10.jpg){kind=link}