Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
(ICLR2023) Improving Deep Regression with Ordin...
Search
Shumpei Takezaki
April 23, 2025
52
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
(ICLR2023) Improving Deep Regression with Ordinal Entropy
Shumpei Takezaki
April 23, 2025
More Decks by Shumpei Takezaki
See All by Shumpei Takezaki
(IJCNN2026) Cell Instance Segmentation via Multi-Task Image-to-Image Schrödinger Bridge
shumpei777
0
16
(IJCNN2026) SCoRe: Clean Image Generation from Diffusion Models Trained on Noisy Images
shumpei777
0
22
(CVPR2026) Back to Basics: Let Denoising Generative Models Denoise
shumpei777
0
210
(Preprint) Diffusion Transformers with Representation Autoencoders
shumpei777
1
1.3k
(Blog post) Diffusion is spectral autoregression
shumpei777
3
1.3k
(Preprint) Diffusion Classifiers Understand Compositionality, but Conditions Apply
shumpei777
1
650
(ICLR2021) Score-Based Generative Modeling through Stochastic Differential Equations
shumpei777
1
690
(NeurIPS2024) Guiding a Diffusion Model with a Bad Version of Itself
shumpei777
0
45
(ICML2023) I2SB: Image-to-Image Schrödinger Bridge
shumpei777
0
66
Featured
See All Featured
Scaling GitHub
holman
464
140k
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
150
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
65
56k
The Cult of Friendly URLs
andyhume
79
6.9k
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
240
Raft: Consensus for Rubyists
vanstee
141
7.6k
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
Measuring & Analyzing Core Web Vitals
bluesmoon
9
880
Game over? The fight for quality and originality in the time of robots
wayneb77
1
220
Building an army of robots
kneath
306
46k
Joys of Absence: A Defence of Solitary Play
codingconduct
1
410
Transcript
回帰タスクにおける損失関数比較してみた 2024/11/20@論文読み会 Shumpei Takezaki (D1, Uchida Lab.)
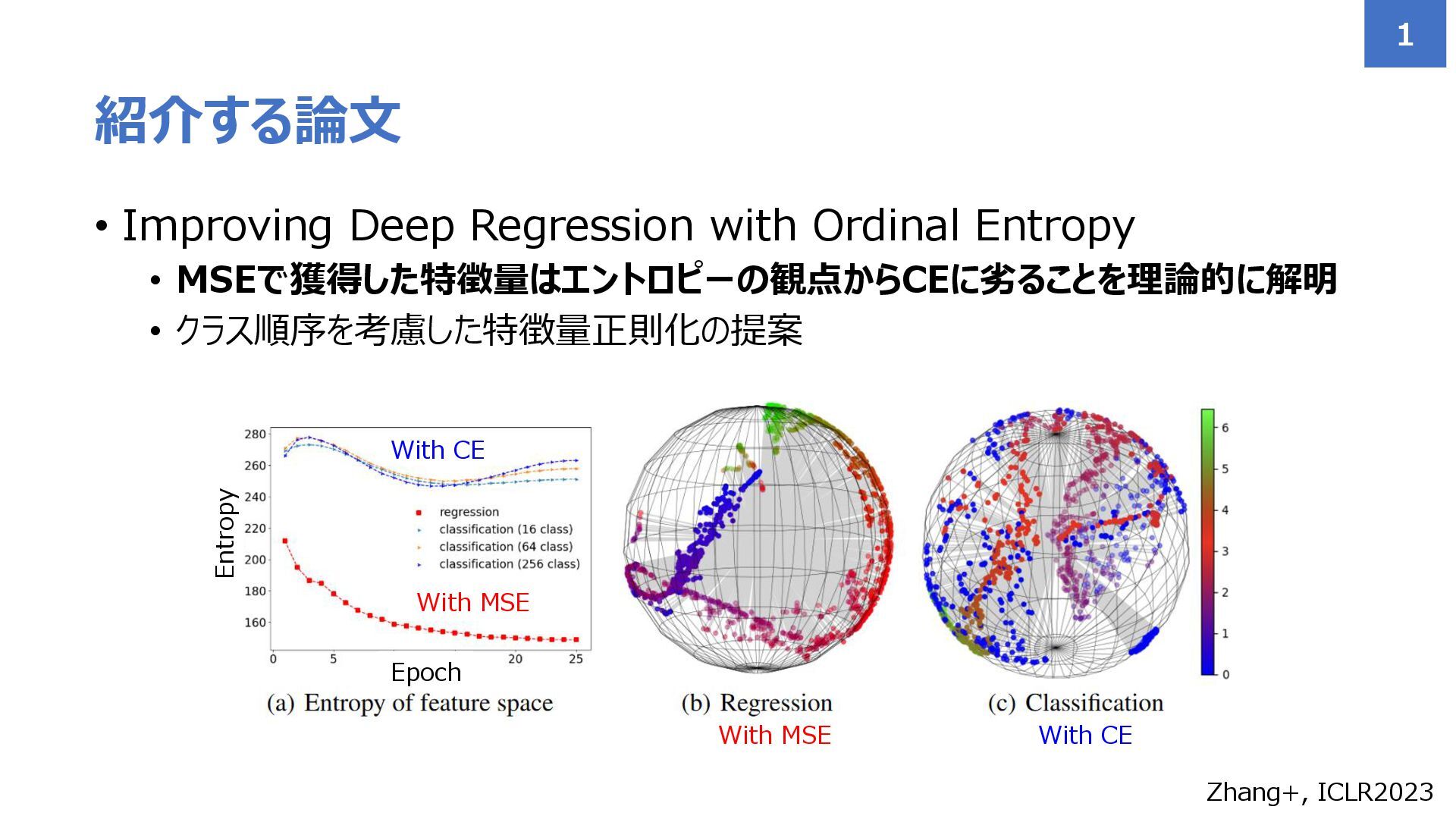
• Improving Deep Regression with Ordinal Entropy • MSEで獲得した特徴量はエントロピーの観点からCEに劣ることを理論的に解明 •
クラス順序を考慮した特徴量正則化の提案 紹介する論文 1 Zhang+, ICLR2023 With MSE With CE Entropy Epoch With MSE With CE
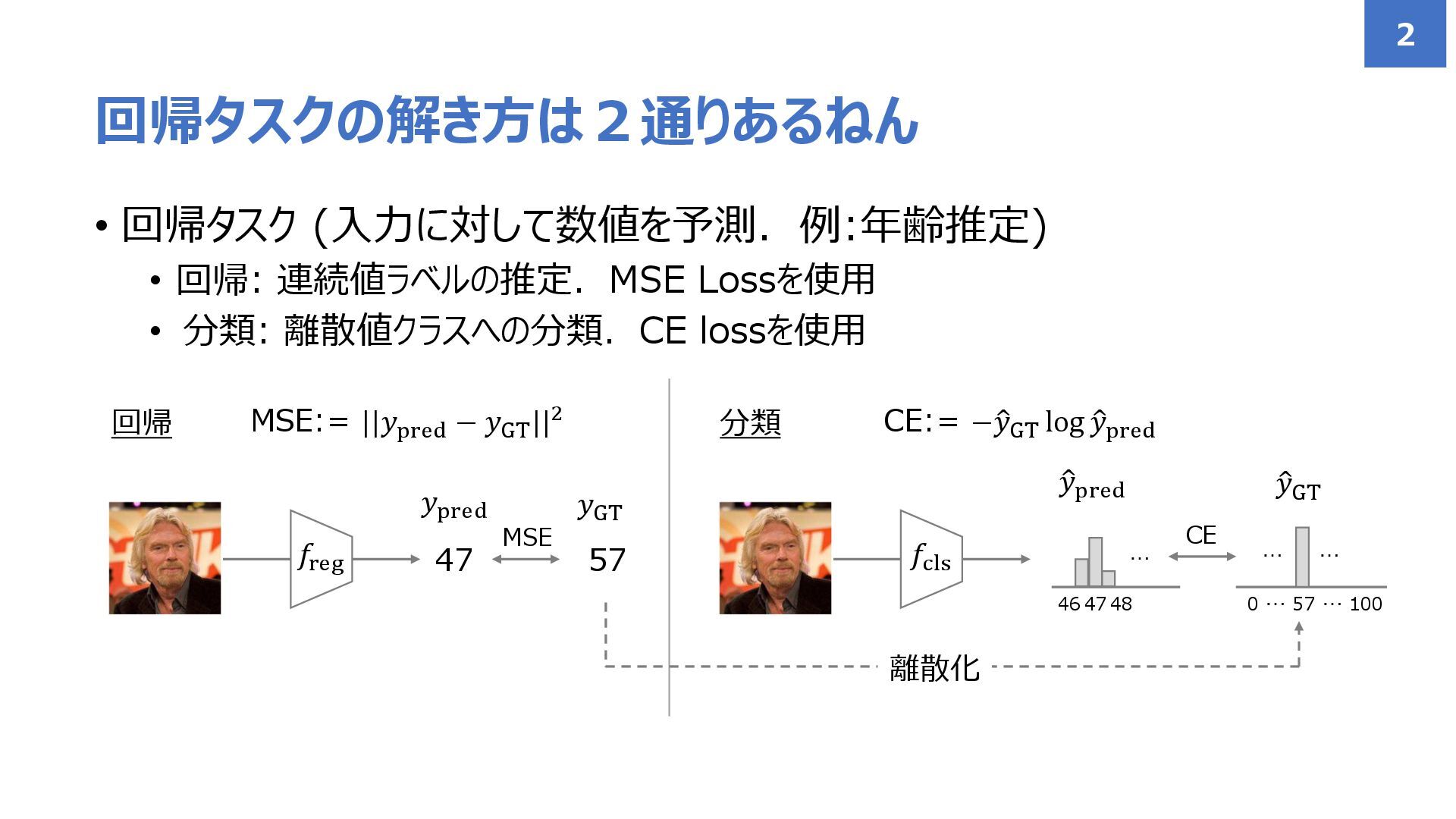
• 回帰タスク (入力に対して数値を予測.例:年齢推定) • 回帰: 連続値ラベルの推定.MSE Lossを使用 • 分類: 離散値クラスへの分類.CE
lossを使用 回帰タスクの解き方は2通りあるねん 2 𝑓reg 47 57 𝑦pred 𝑦GT MSE:= ||𝑦pred − 𝑦GT ||2 𝑓cls ො 𝑦pred ො 𝑦GT 回帰 分類 CE:= −ො 𝑦GT log ො 𝑦pred MSE … 57 0 … 100 … … 47 CE 46 48 … 離散化
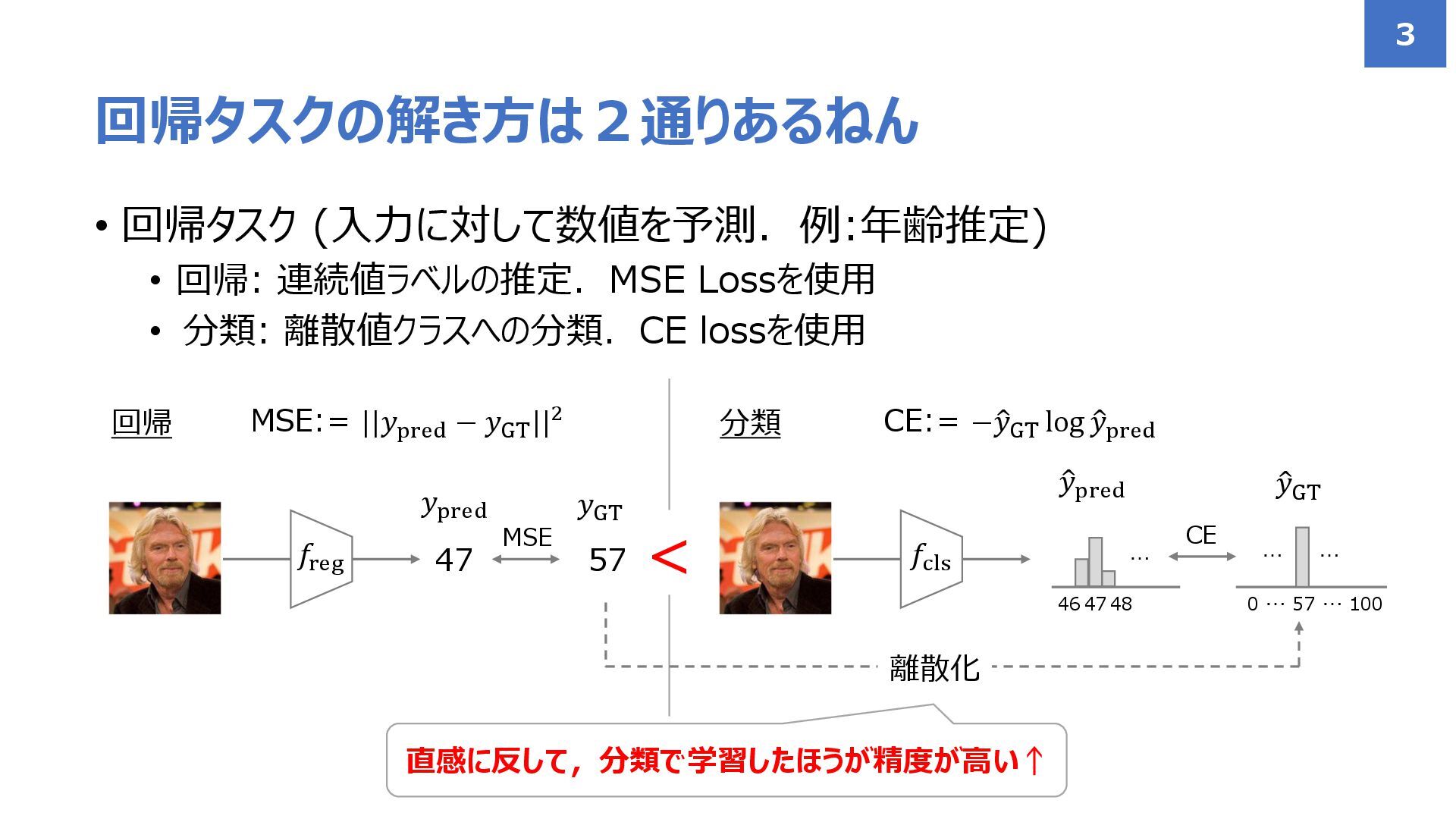
• 回帰タスク (入力に対して数値を予測.例:年齢推定) • 回帰: 連続値ラベルの推定.MSE Lossを使用 • 分類: 離散値クラスへの分類.CE
lossを使用 回帰タスクの解き方は2通りあるねん 3 𝑓reg 47 57 𝑦pred 𝑦GT MSE:= ||𝑦pred − 𝑦GT ||2 𝑓cls ො 𝑦pred ො 𝑦GT 回帰 分類 CE:= −ො 𝑦GT log ො 𝑦pred MSE … 57 0 … 100 … … 47 CE 46 48 … 離散化 直感に反して,分類で学習したほうが精度が高い↑ <
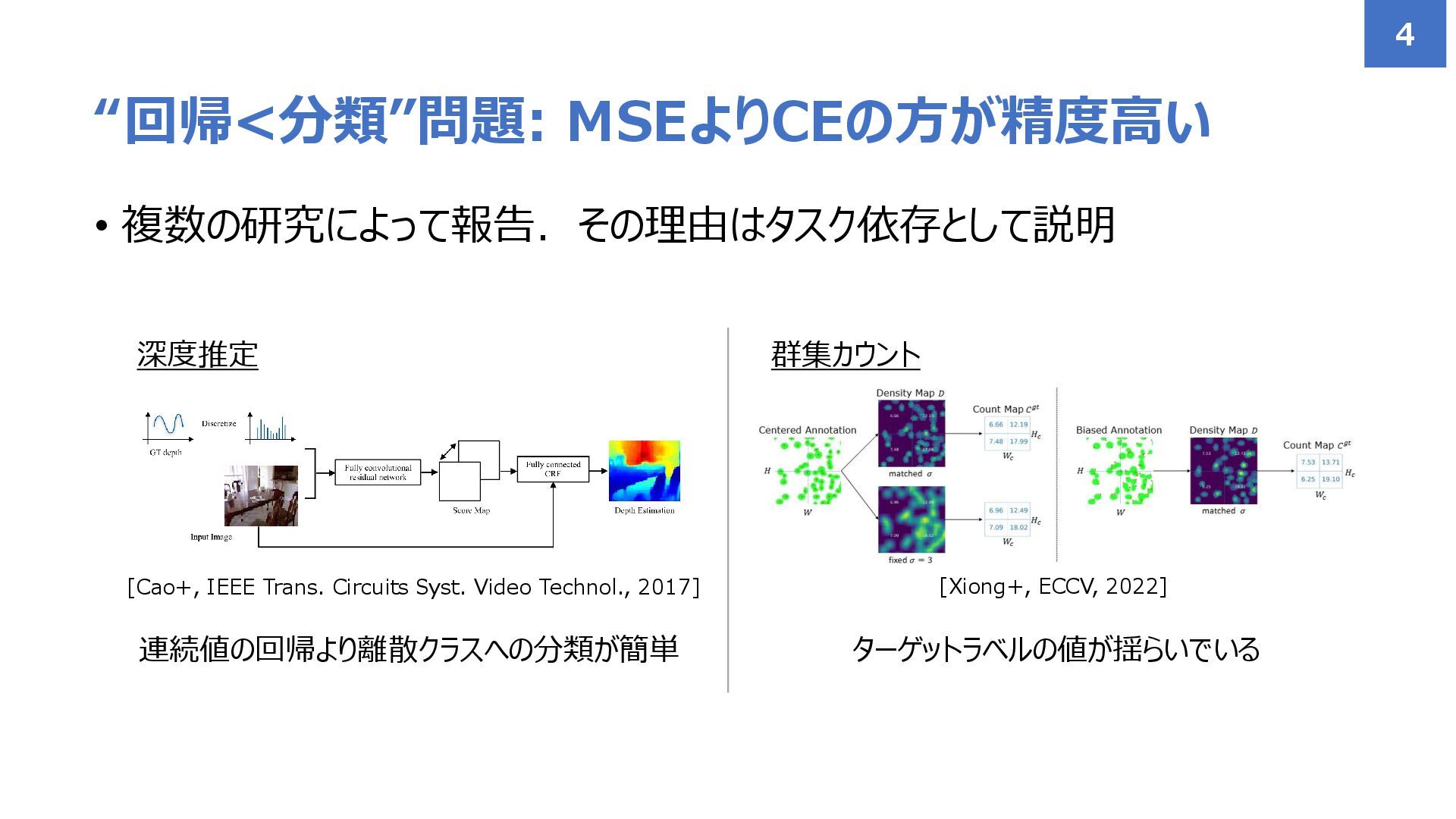
• 複数の研究によって報告.その理由はタスク依存として説明 “回帰<分類”問題: MSEよりCEの方が精度高い 4 [Cao+, IEEE Trans. Circuits Syst.
Video Technol., 2017] 深度推定 連続値の回帰より離散クラスへの分類が簡単 ターゲットラベルの値が揺らいでいる [Xiong+, ECCV, 2022] 群集カウント
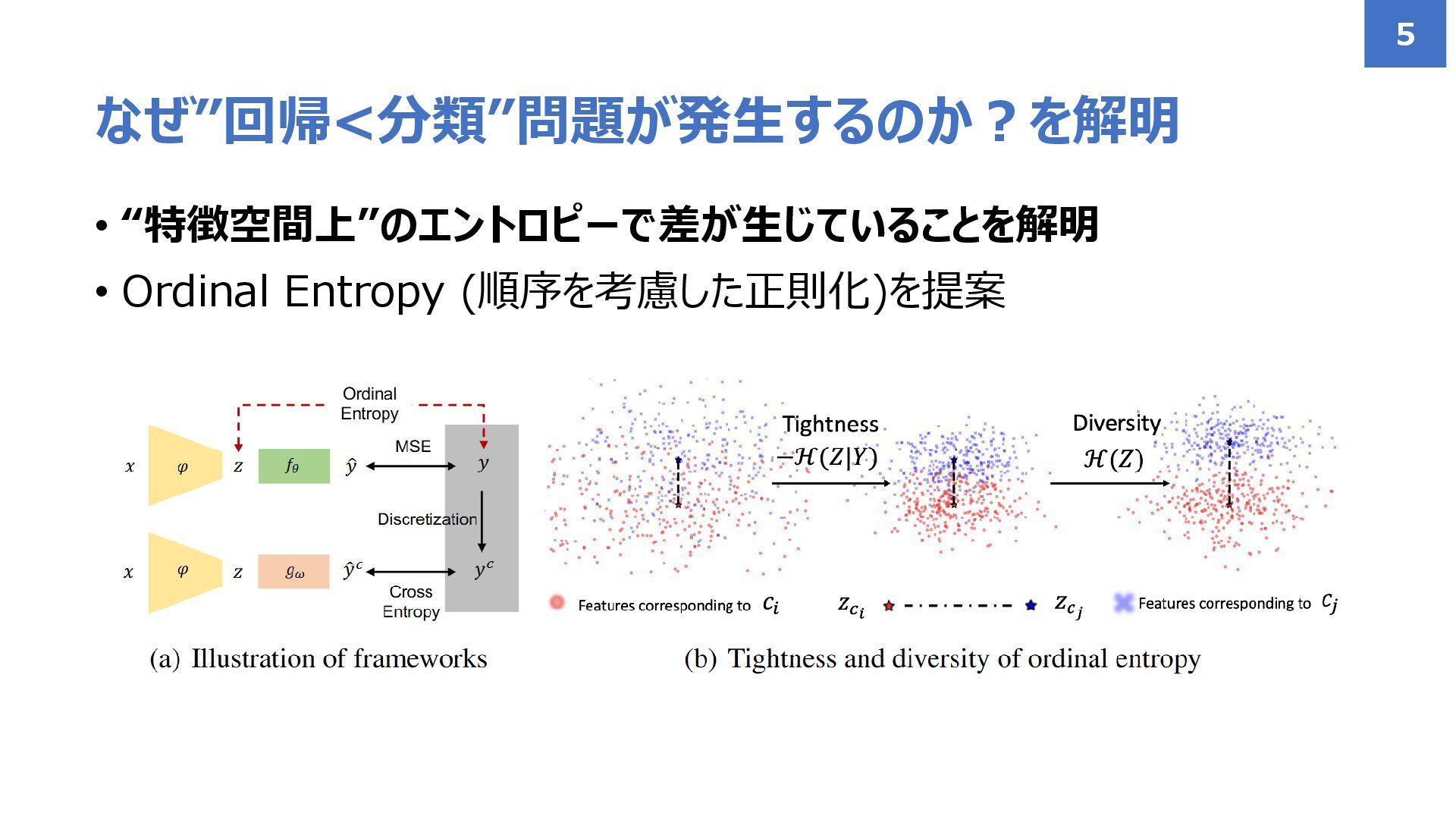
• “特徴空間上”のエントロピーで差が生じていることを解明 • Ordinal Entropy (順序を考慮した正則化)を提案 なぜ”回帰<分類”問題が発生するのか?を解明 5
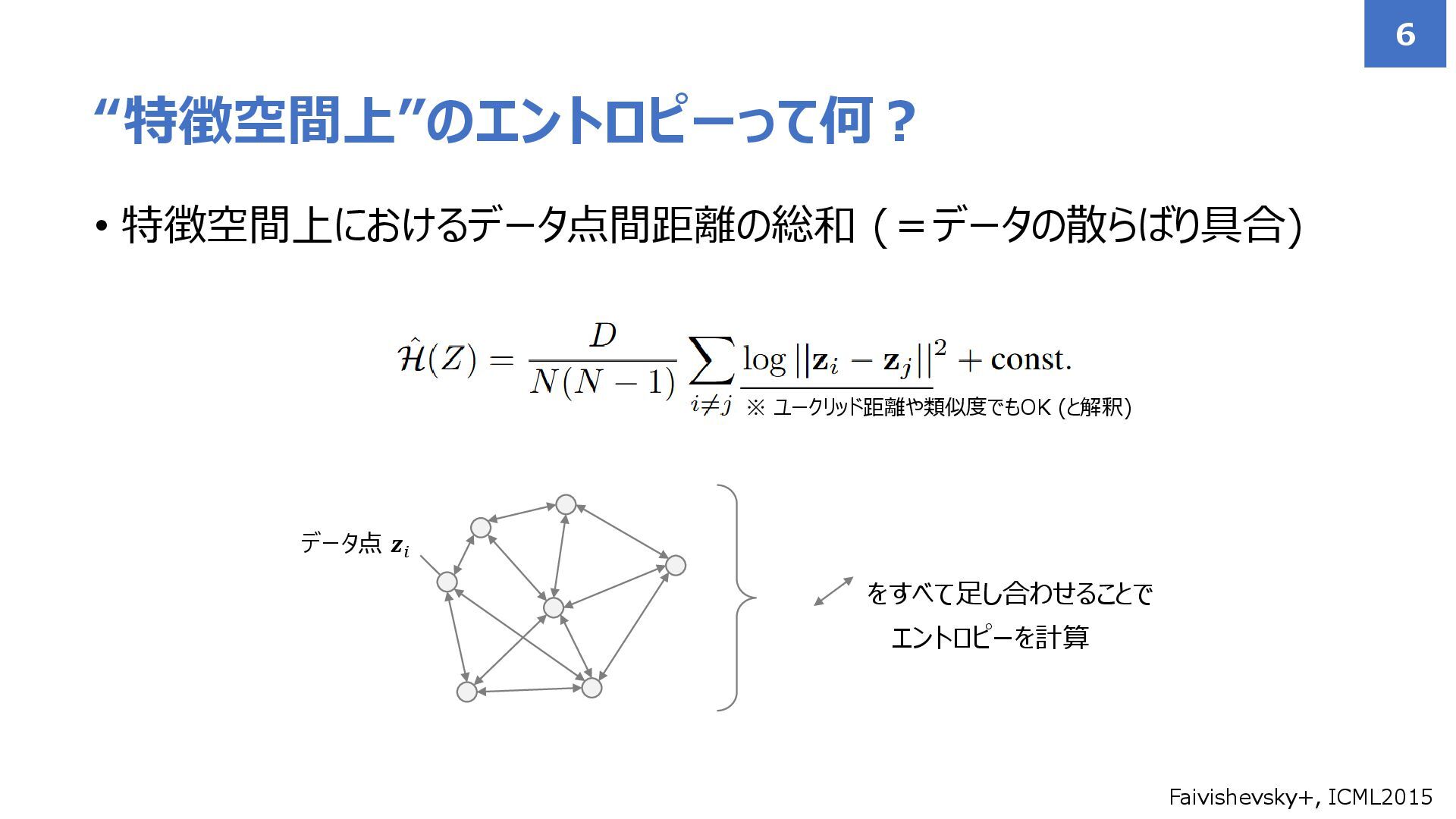
• 特徴空間上におけるデータ点間距離の総和 (=データの散らばり具合) “特徴空間上”のエントロピーって何? 6 ※ ユークリッド距離や類似度でもOK (と解釈) データ点 𝒛𝑖
をすべて足し合わせることで エントロピーを計算 Faivishevsky+, ICML2015
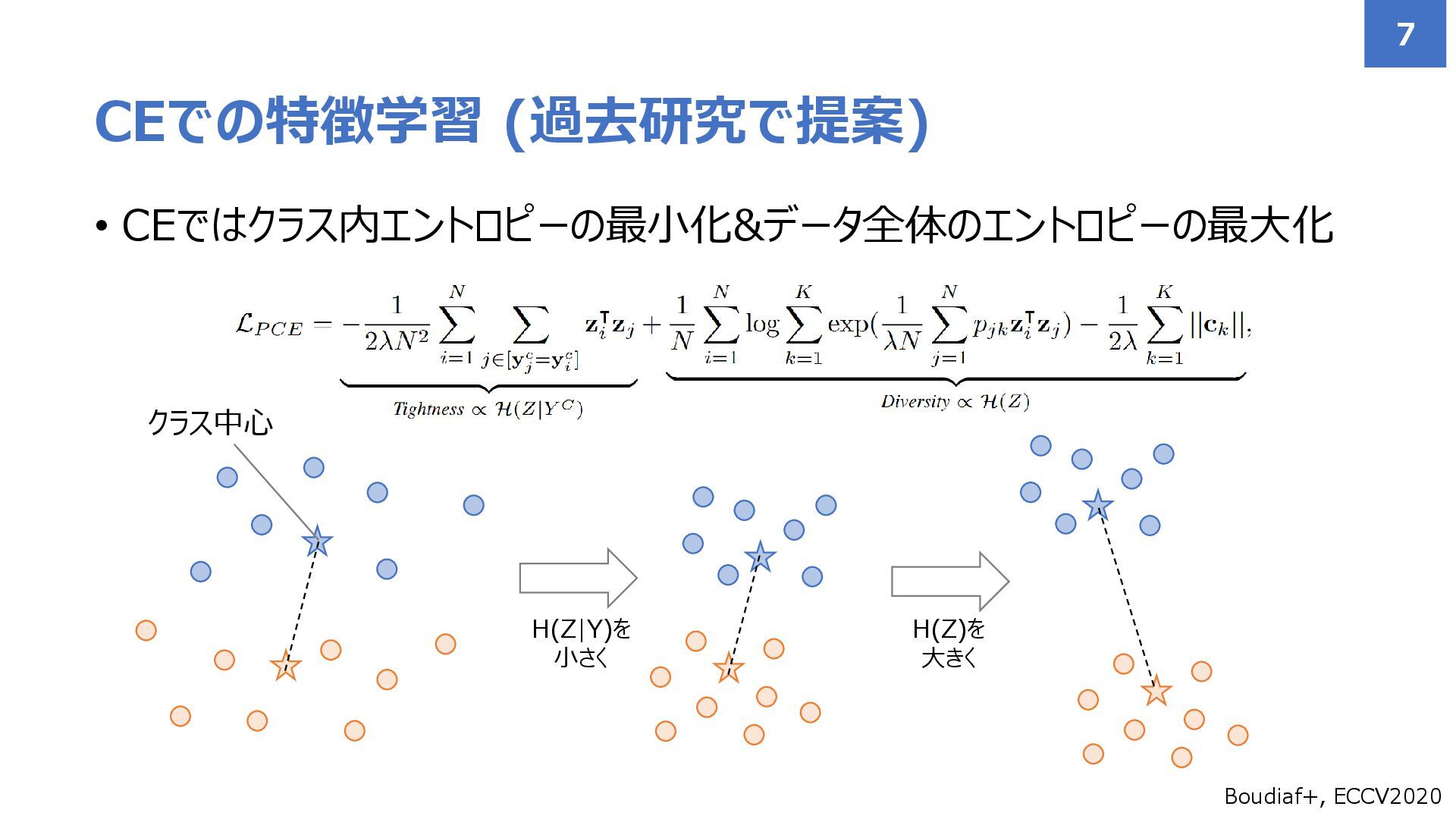
• CEではクラス内エントロピーの最小化&データ全体のエントロピーの最大化 CEでの特徴学習 (過去研究で提案) 7 Boudiaf+, ECCV2020 H(Z|Y)を 小さく H(Z)を
大きく クラス中心
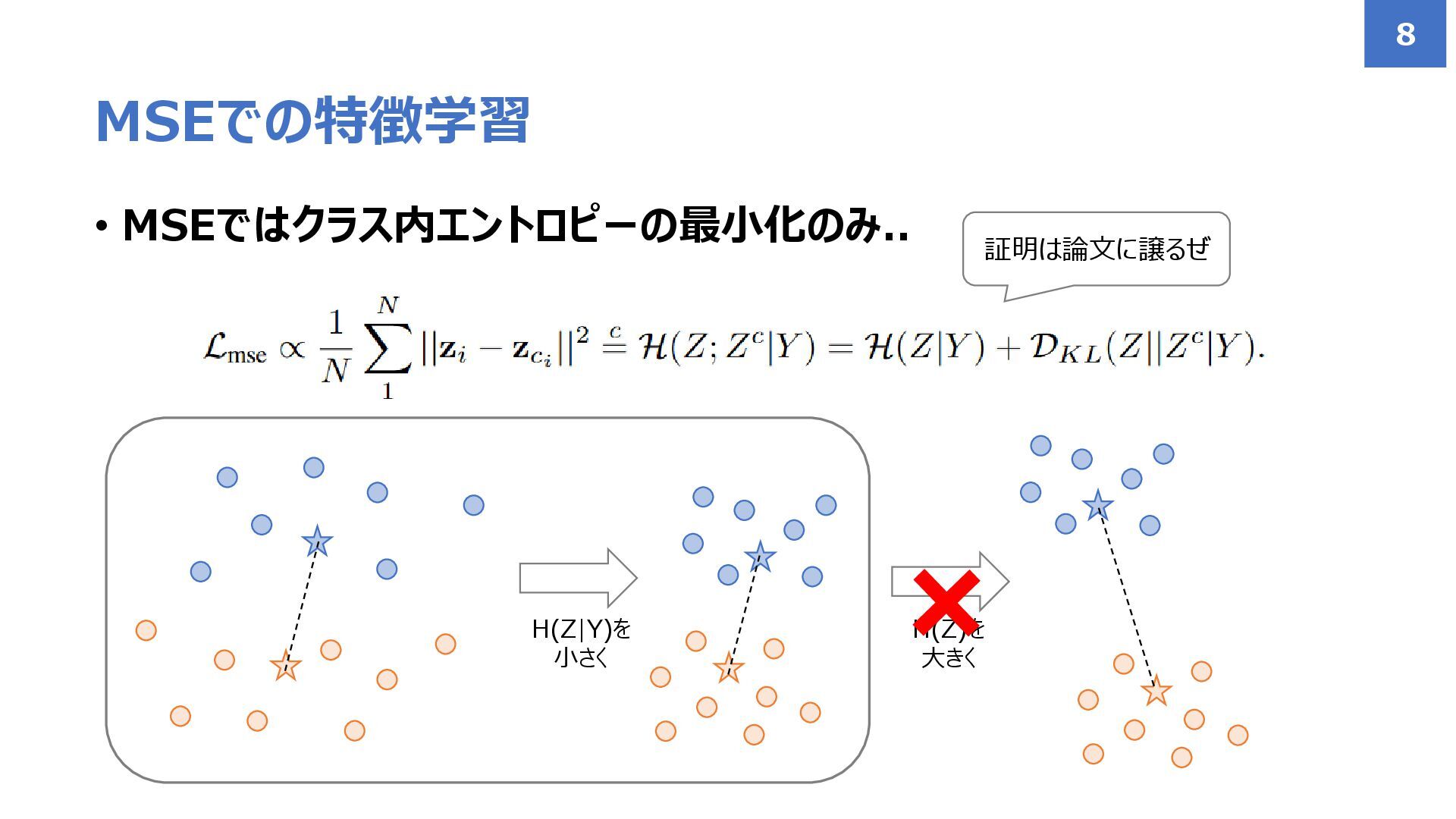
• MSEではクラス内エントロピーの最小化のみ.. MSEでの特徴学習 8 証明は論文に譲るぜ H(Z|Y)を 小さく H(Z)を 大きく
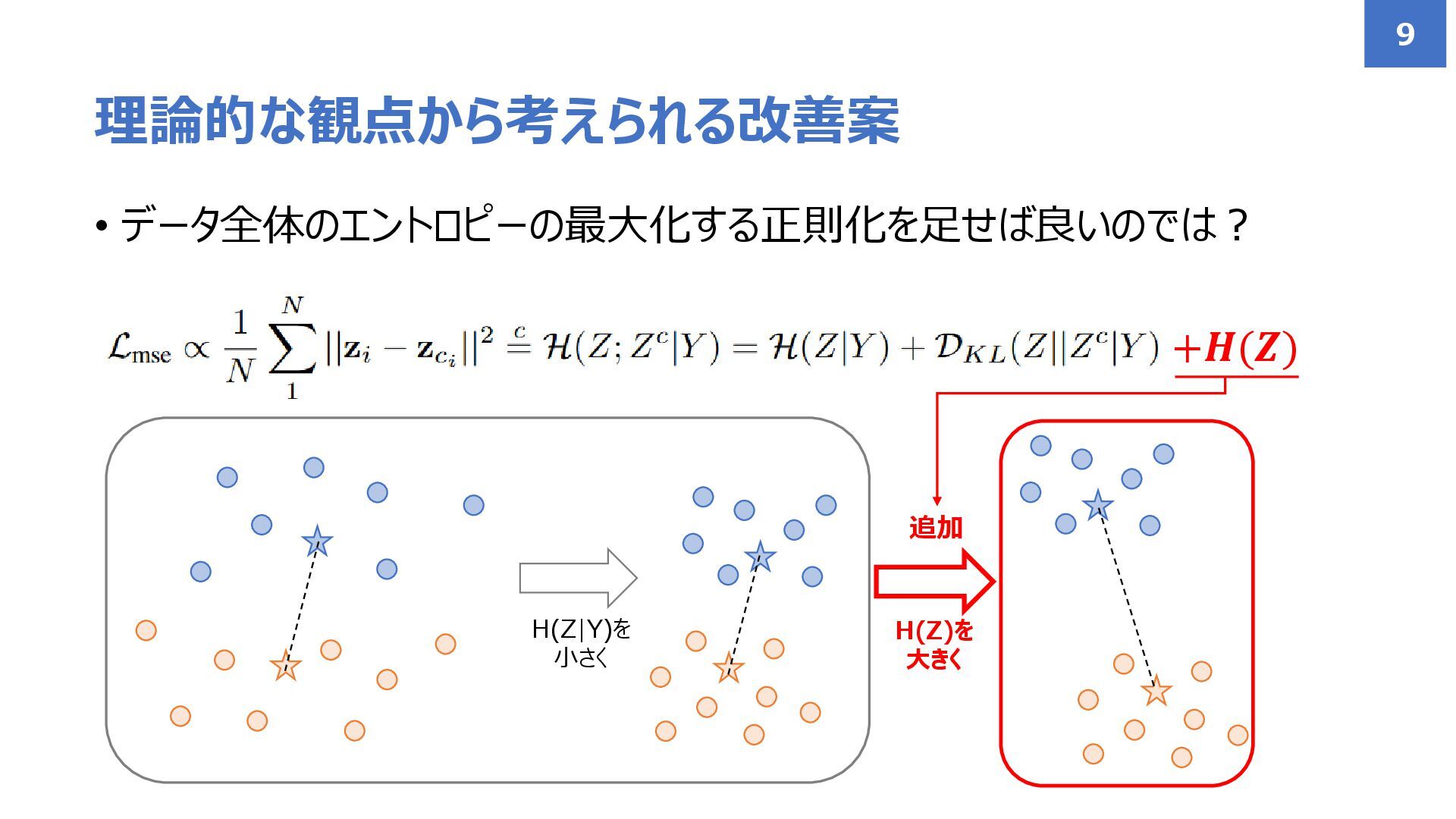
• データ全体のエントロピーの最大化する正則化を足せば良いのでは? 理論的な観点から考えられる改善案 9 H(Z|Y)を 小さく H(Z)を 大きく +𝑯(𝒁) 追加
• データ全体のエントロピーの最大化のために順序を考慮した正則化を提案 • データ間距離をクラスの距離で重み付け • (追加で) クラス内エントロピーの最小化するような正則化 提案手法: Ordinal Entropy
(特徴空間の正則化) 10
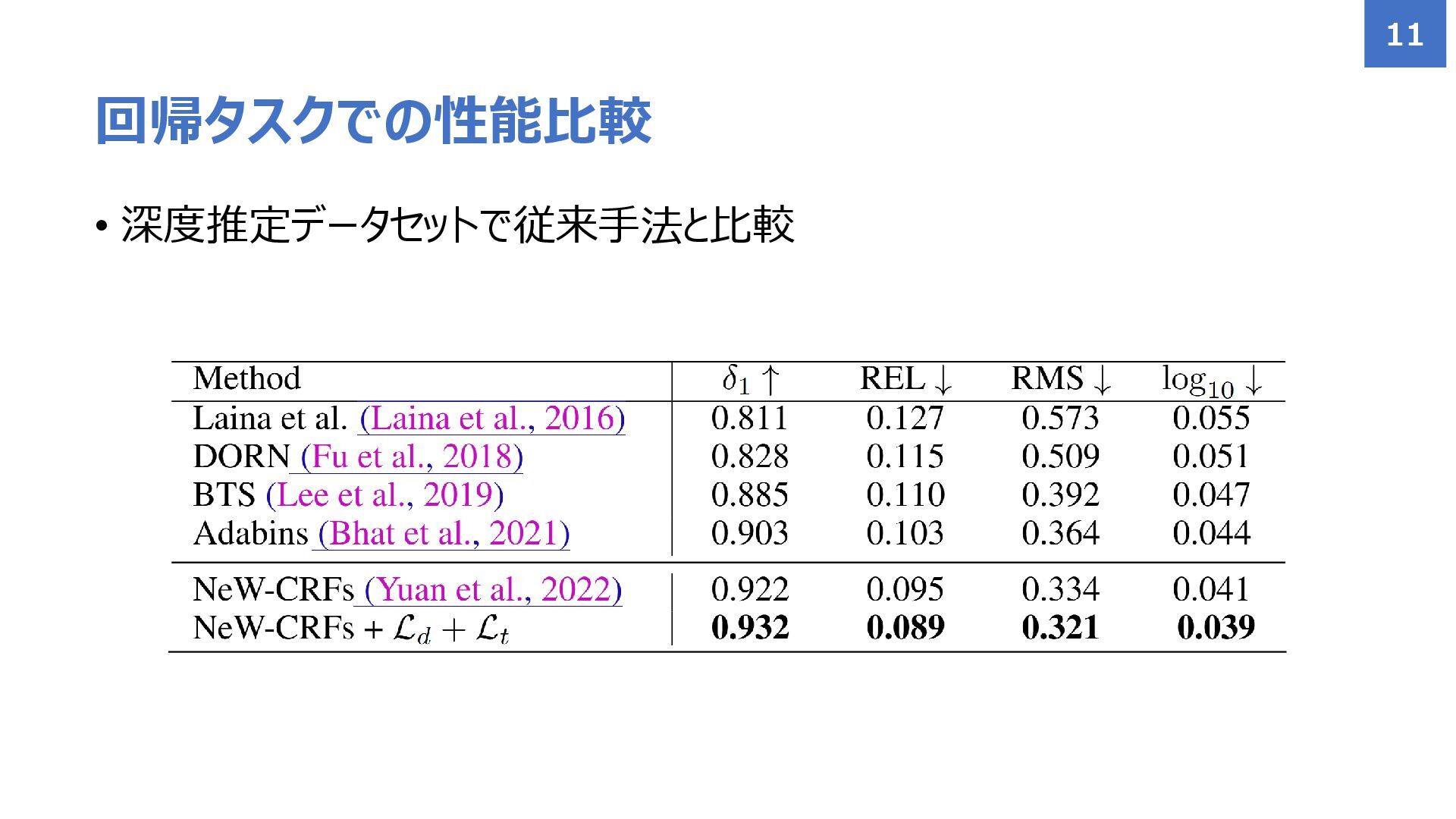
• 深度推定データセットで従来手法と比較 回帰タスクでの性能比較 11
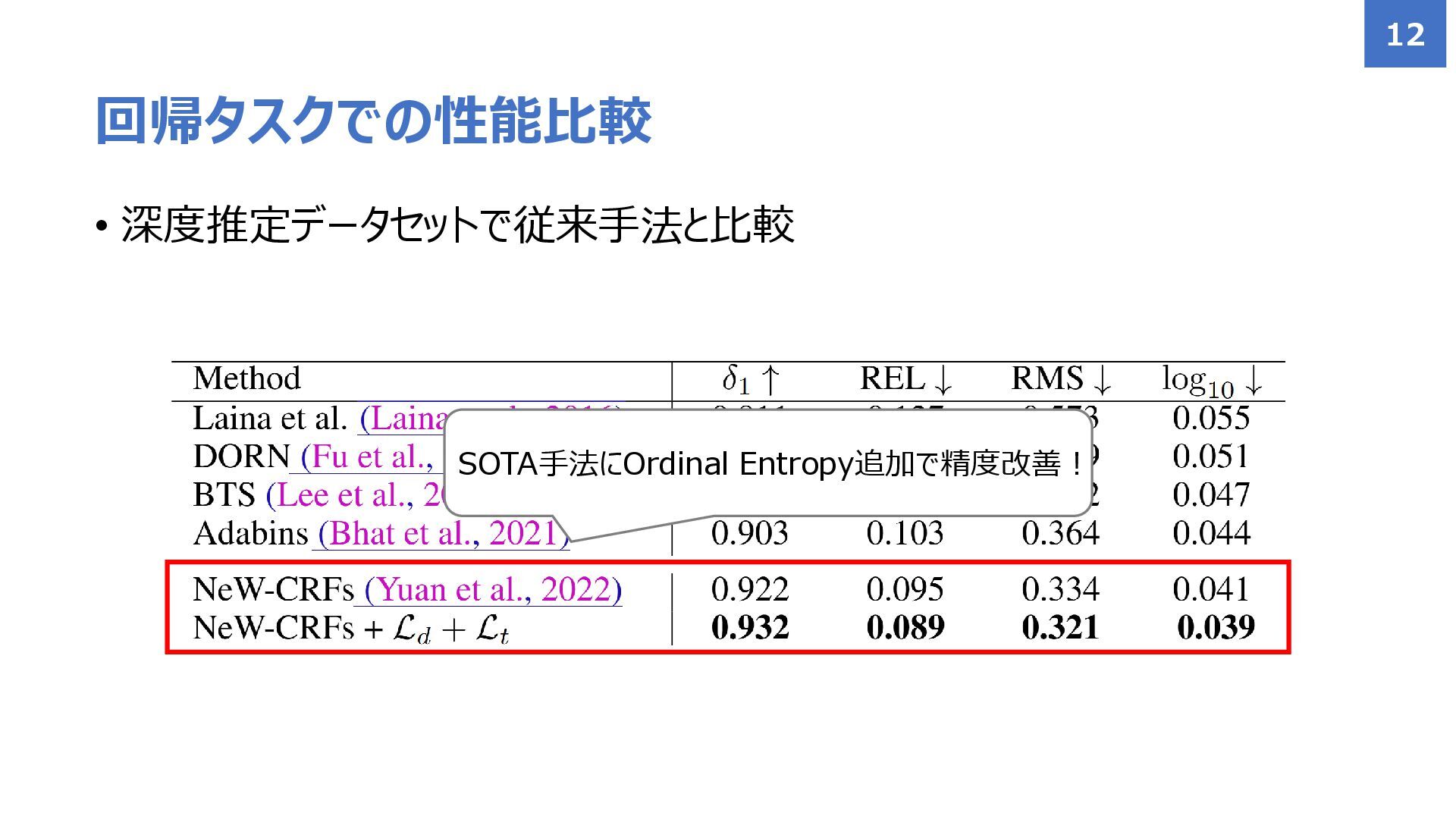
• 深度推定データセットで従来手法と比較 回帰タスクでの性能比較 12 SOTA手法にOrdinal Entropy追加で精度改善!
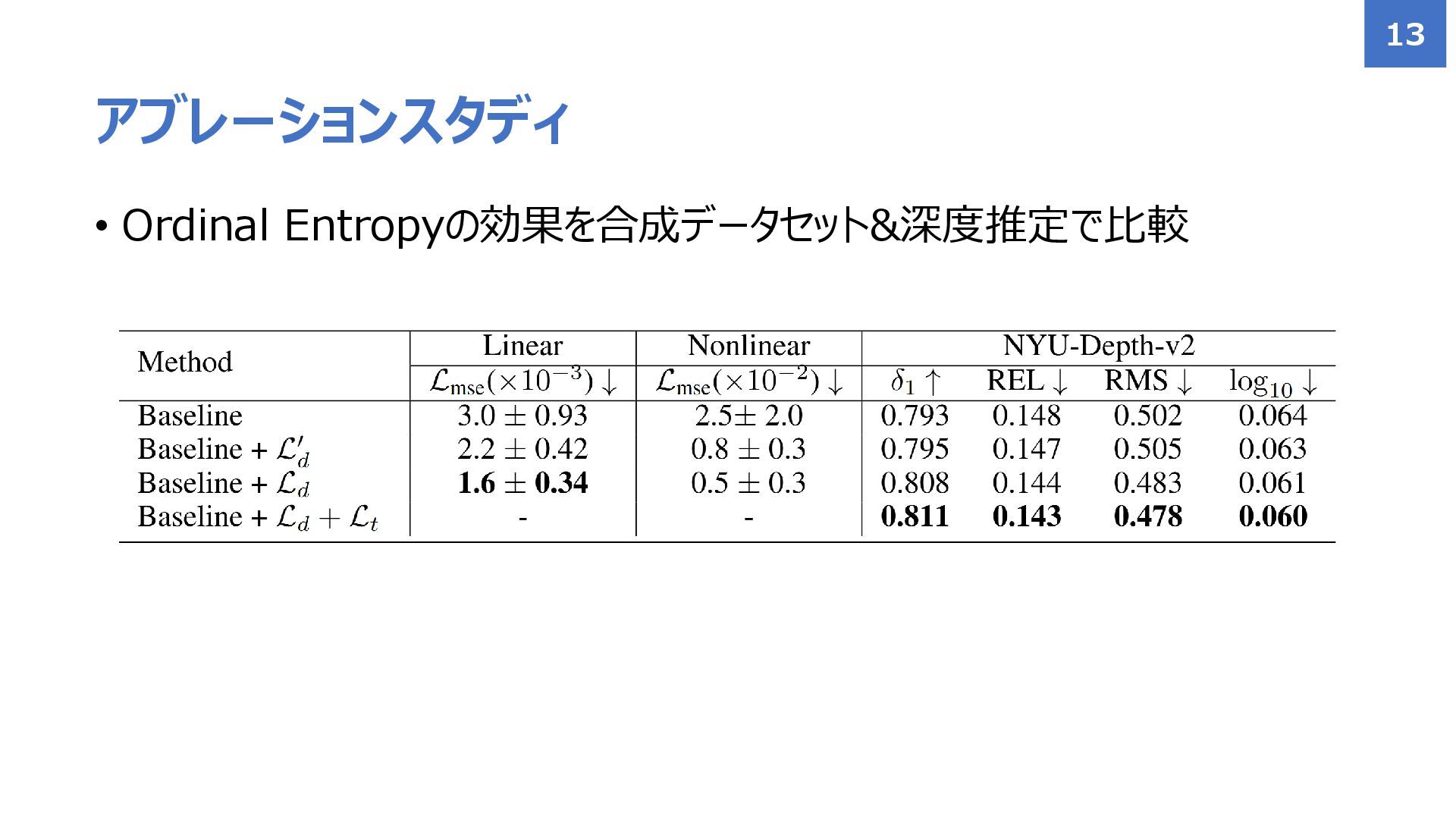
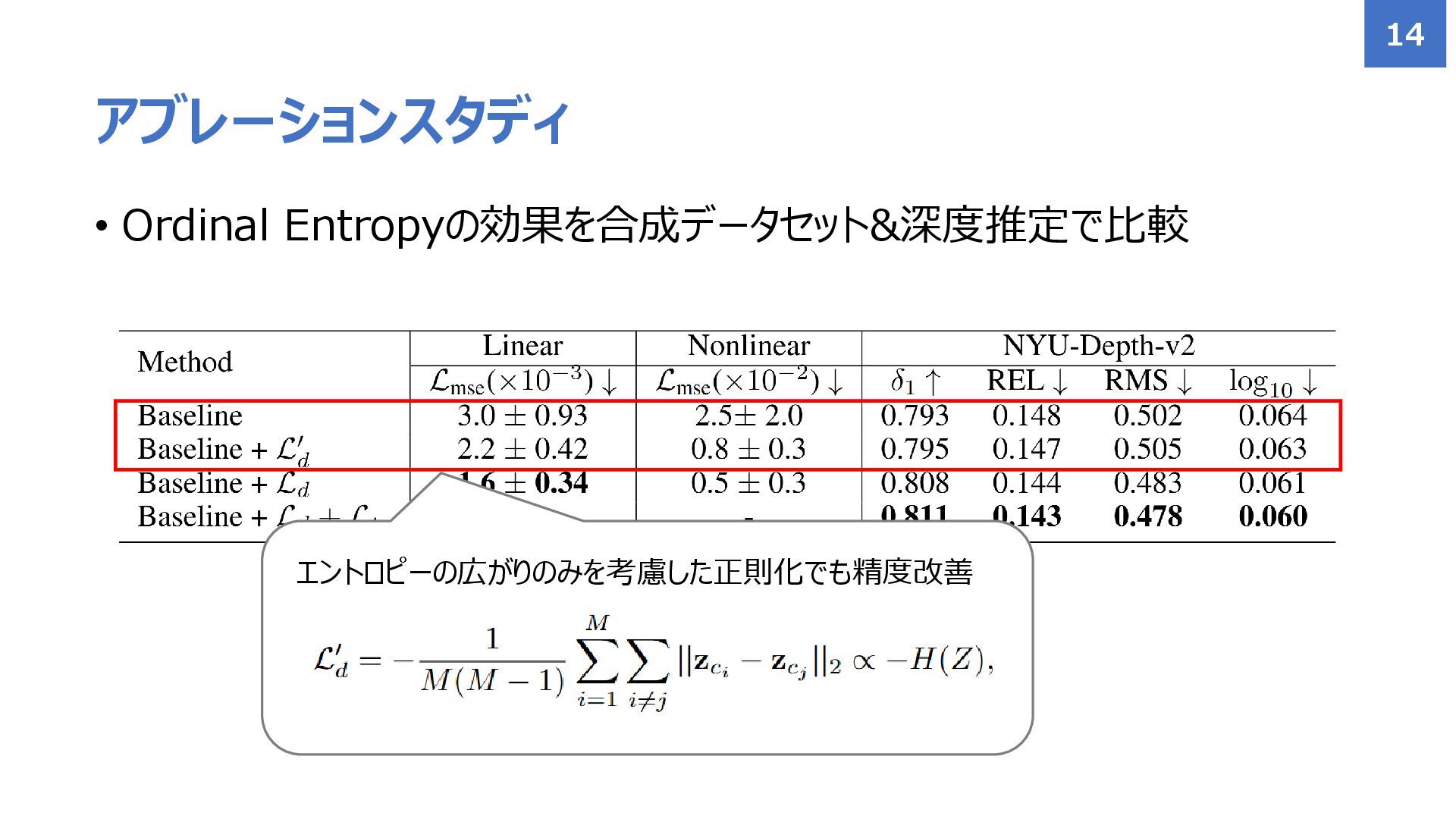
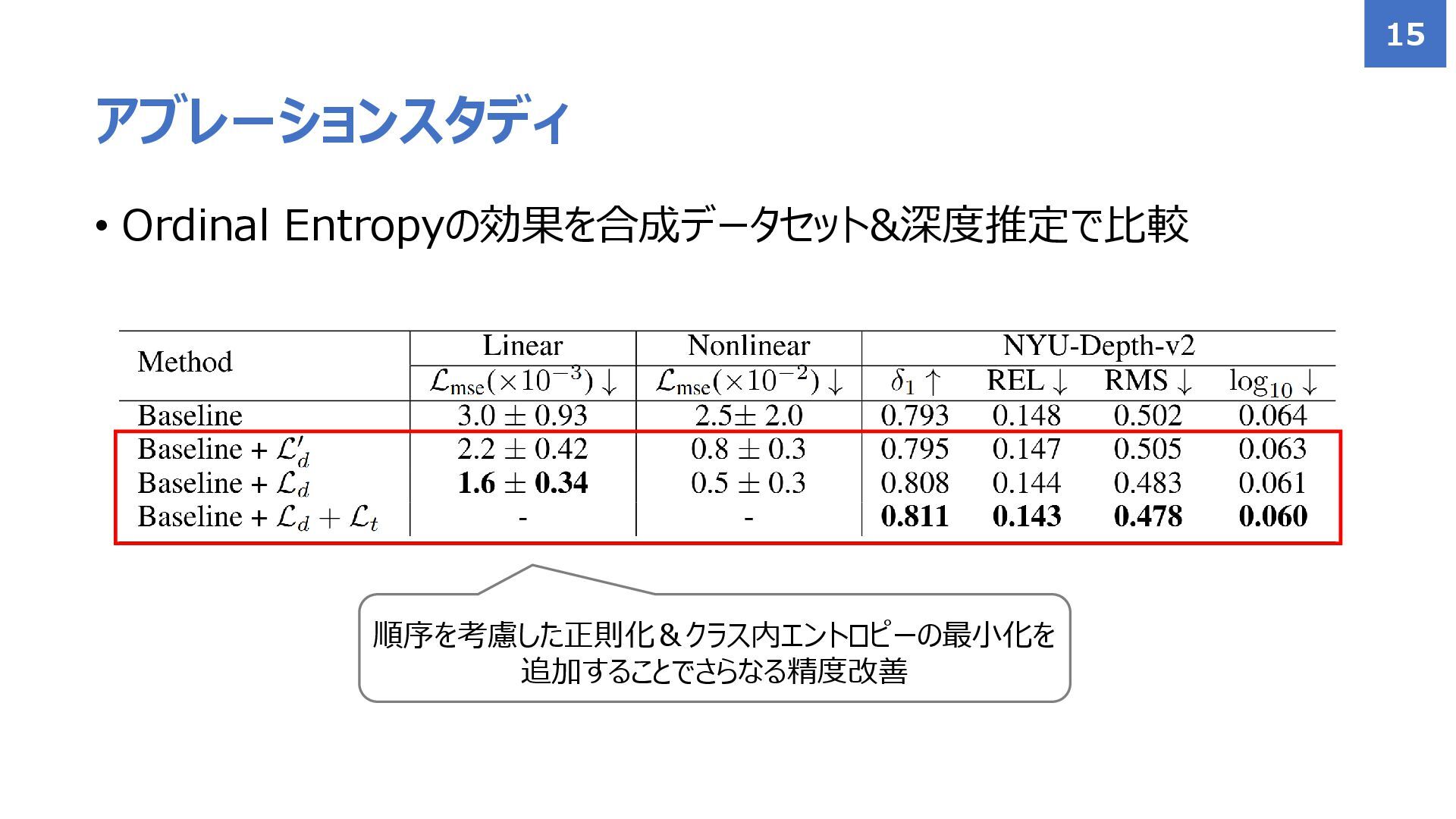
• Ordinal Entropyの効果を合成データセット&深度推定で比較 アブレーションスタディ 13
• Ordinal Entropyの効果を合成データセット&深度推定で比較 アブレーションスタディ 14 エントロピーの広がりのみを考慮した正則化でも精度改善
• Ordinal Entropyの効果を合成データセット&深度推定で比較 アブレーションスタディ 15 順序を考慮した正則化&クラス内エントロピーの最小化を 追加することでさらなる精度改善
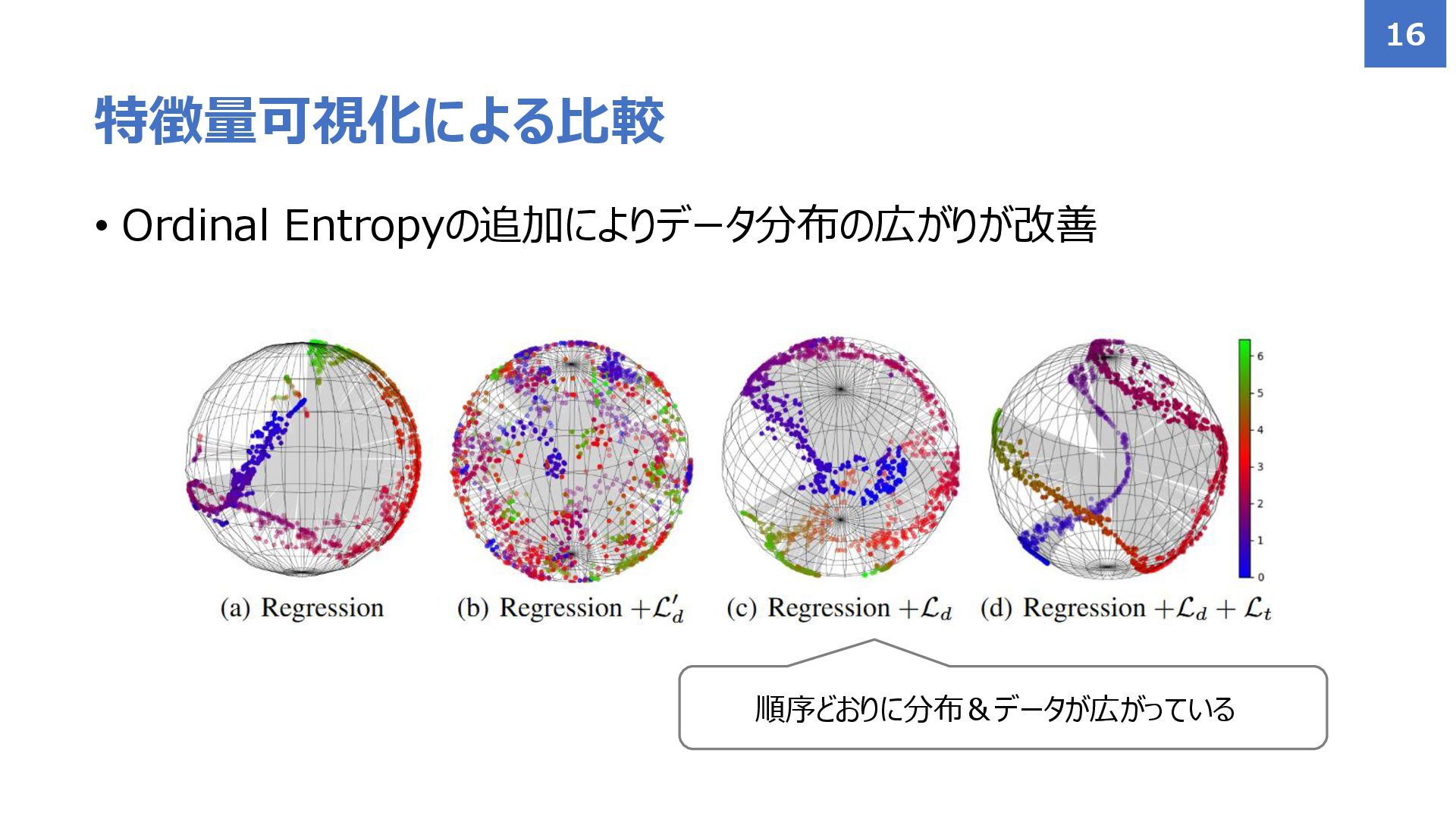
• Ordinal Entropyの追加によりデータ分布の広がりが改善 特徴量可視化による比較 16 順序どおりに分布&データが広がっている
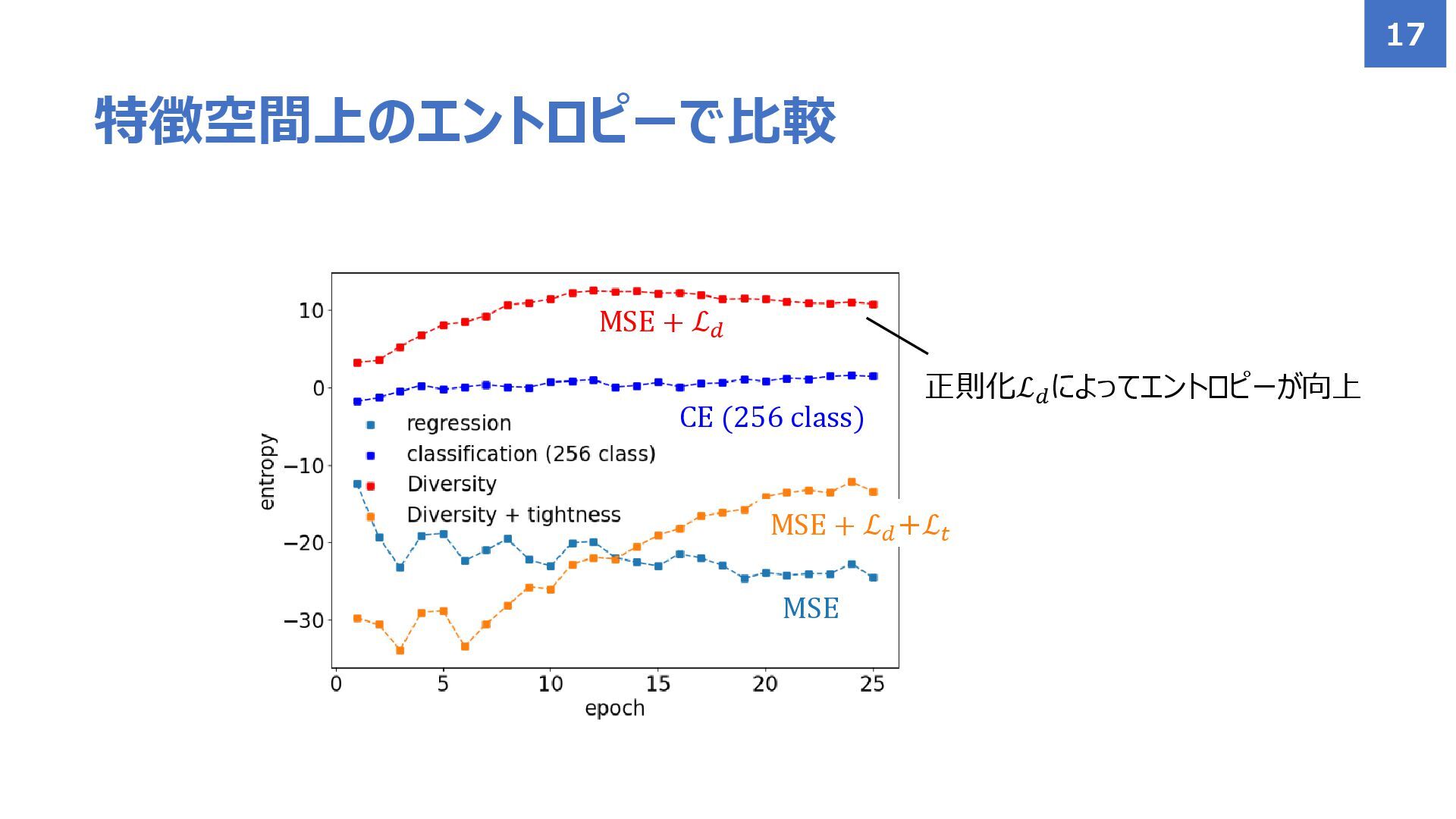
特徴空間上のエントロピーで比較 17 MSE + ℒ𝑑 CE (256 class) MSE +
ℒ𝑑 +ℒ𝑡 MSE 正則化ℒ𝑑 によってエントロピーが向上
• 目的: なぜ”回帰<分類”問題が発生するのか?を解明 • 理論的な結論: 特徴空間上のエントロピーに違いを発見 • 手法: Ordinal Entropy
(順序を考慮した正則化)を提案 • 結果: 回帰モデルへの導入で精度改善を実現 • 感想: • 損失関数の差を特徴学習の差として捉えるという方法が新鮮 • 複数の解き方があるOrdinal classification (Soft label, K-rankなど)を統一的な視点から 比較できるかも? • (完全に理解できていないが) 理論パートは仮定が多い印象 • 分類モデルとの比較がないので,結局はCEでの学習が優位?? まとめ 18
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}