through Stochastic Differential Equations.”, ICLR2021 (原論文) • Jonathan Ho et al., “Denoising Diffusion Probabilistic Models.”, NeurIPS2020 (拡散モデルの定式化. DDPMの論文) • B. D. O. Anderson, “Reverse-Time Diffusion Equation Models.”, Stochastic Processes and their Applications, 1982 (Reverse SDEの導出) • Yang Song et al, “Generative Modeling by Estimating Gradients of the Data Distribution”, NeurIPS2019 (スコアベースモデル. SMLDの論文) • Tero Karras et al., “Elucidating the Design Space of Diffusion-Based Generative Models”, NeurIPS2022 (EDMの論文) • 参考書 • 岡之原大輔,”拡散モデル データ生成技術の数理”,岩波書店 (全般) • 動画 • nnabla ディープラーニングチャンネルの解説動画 • 【AI論文解説】拡散モデルによるデータ生成の高速化技術 -詳細編Part3- (拡散モデルの拡散過程からForward SDEの導出) • 【AI論文解説】拡散モデルによるデータ生成の高速化技術 -詳細編Part4- (データ生成の高速化) • Yang Songさん (原論文著者)の発表動画 • Score Based Generative Modeling through Stochastic Differential Equations Best Paper | ICLR 2021 (Forward SDEとReverse SDEについて) 参考文献 21
{kind=link}
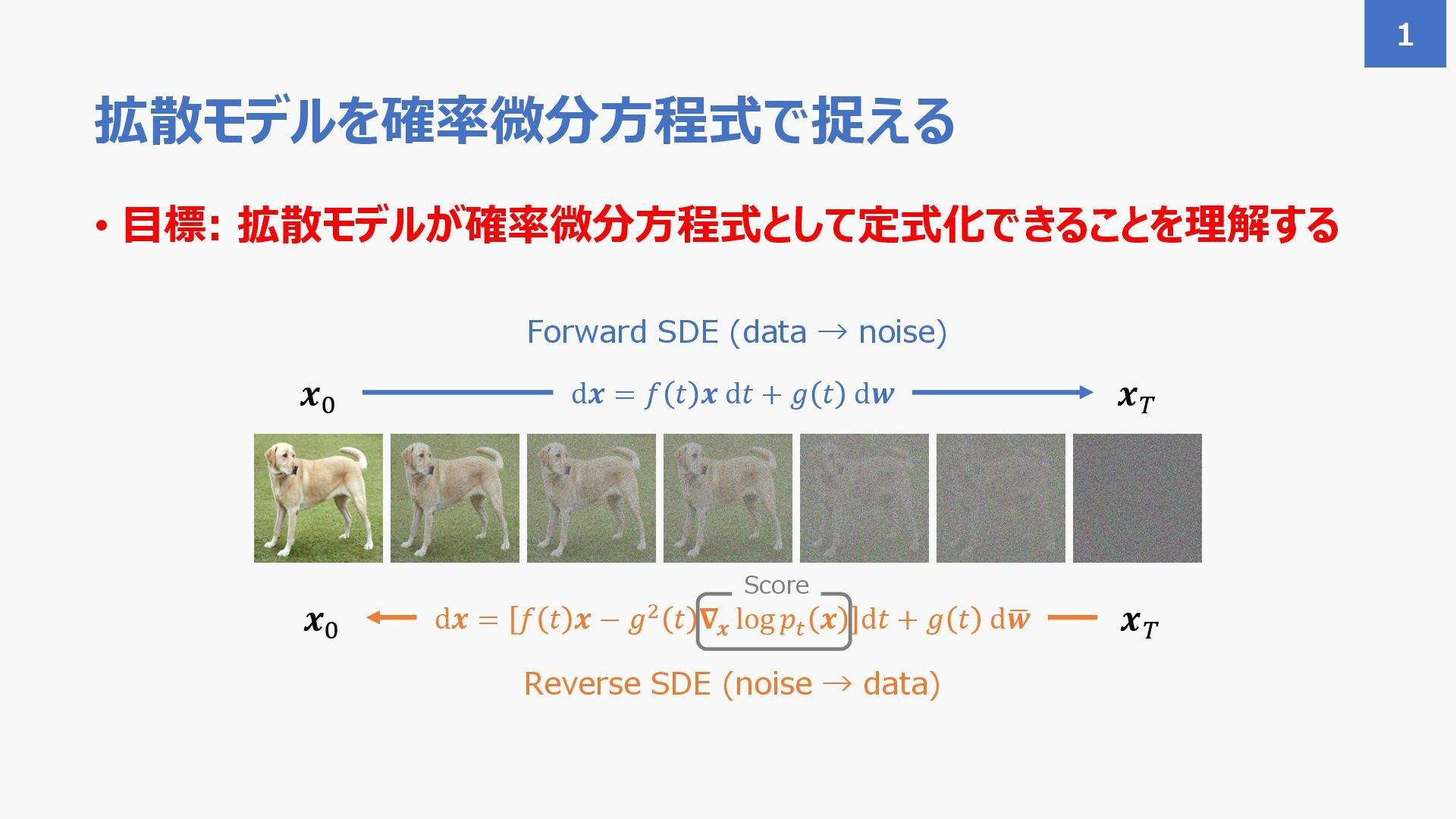{kind=link}
{kind=link}
{kind=link}
{kind=link}
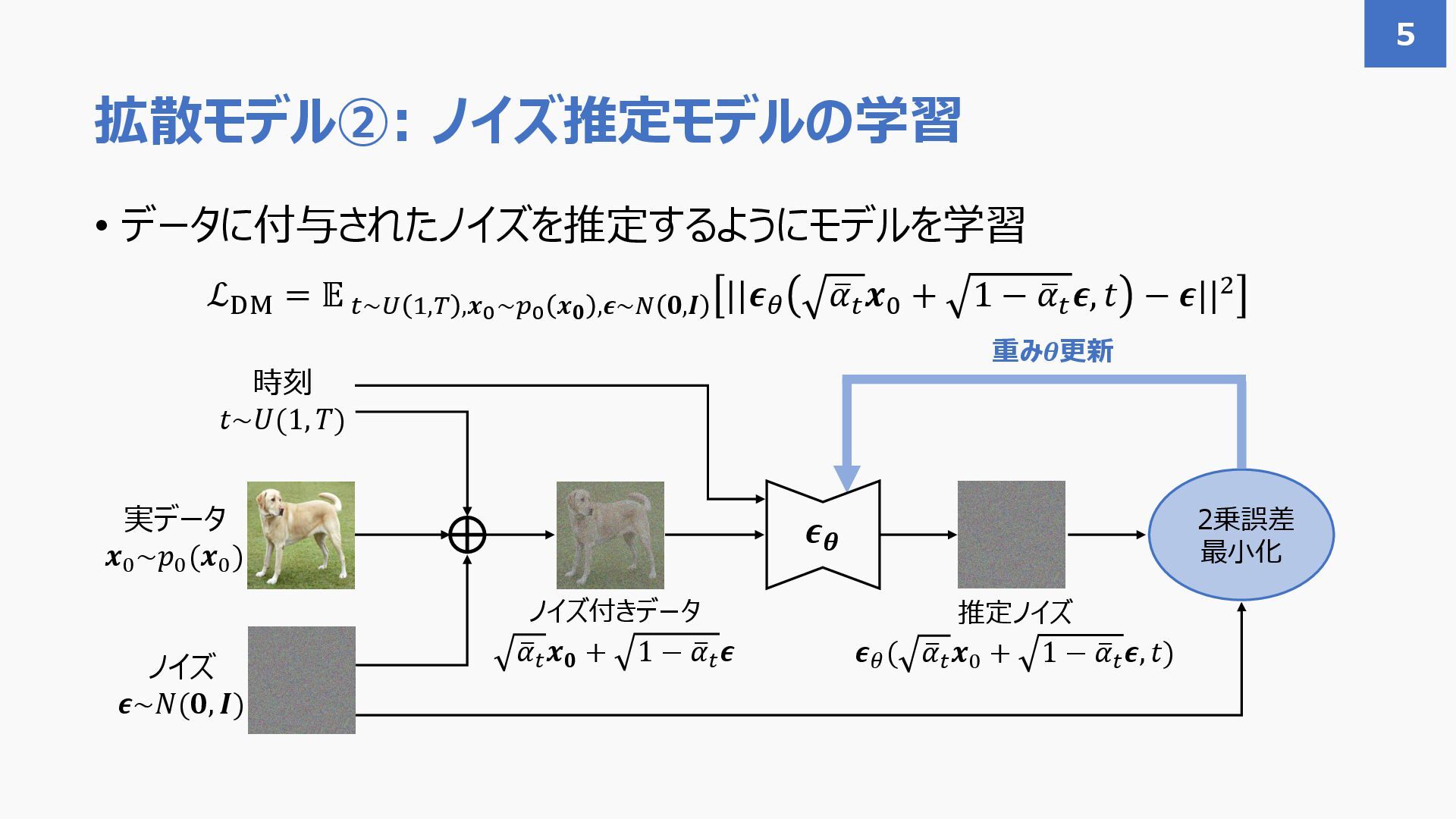{kind=link}
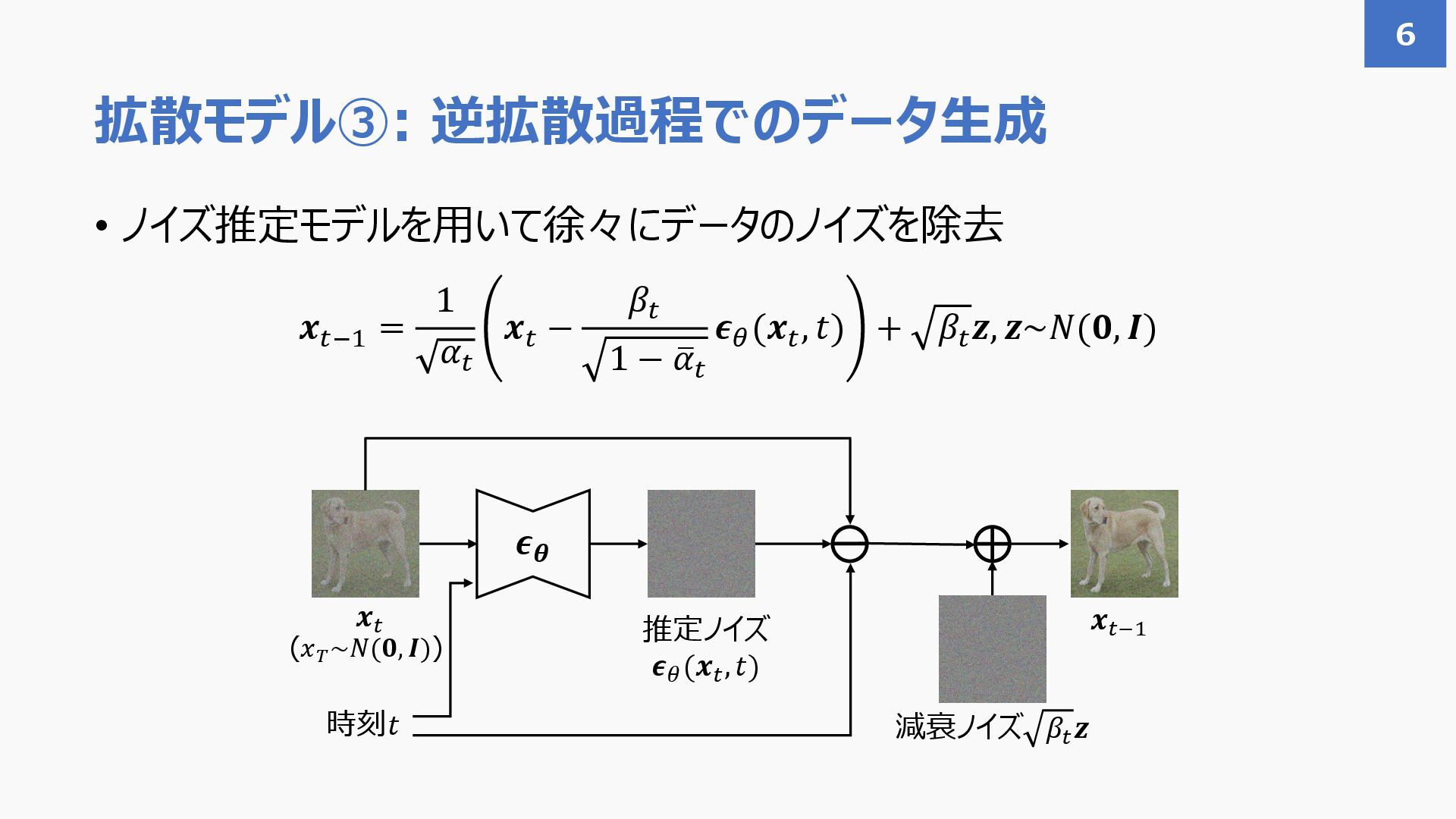{kind=link}
{kind=link}
{kind=link}
{kind=link}
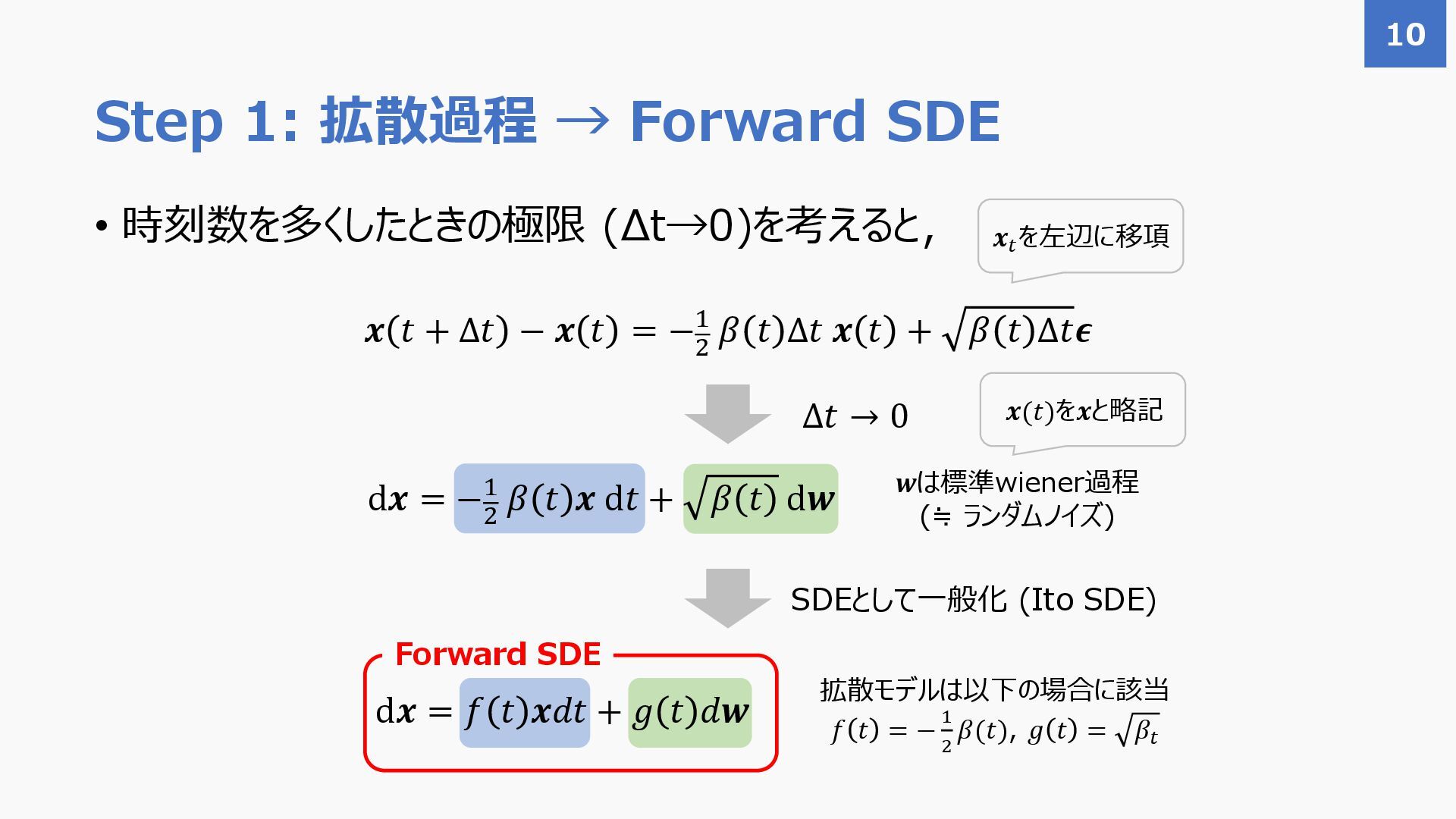{kind=link}
{kind=link}
{kind=link}
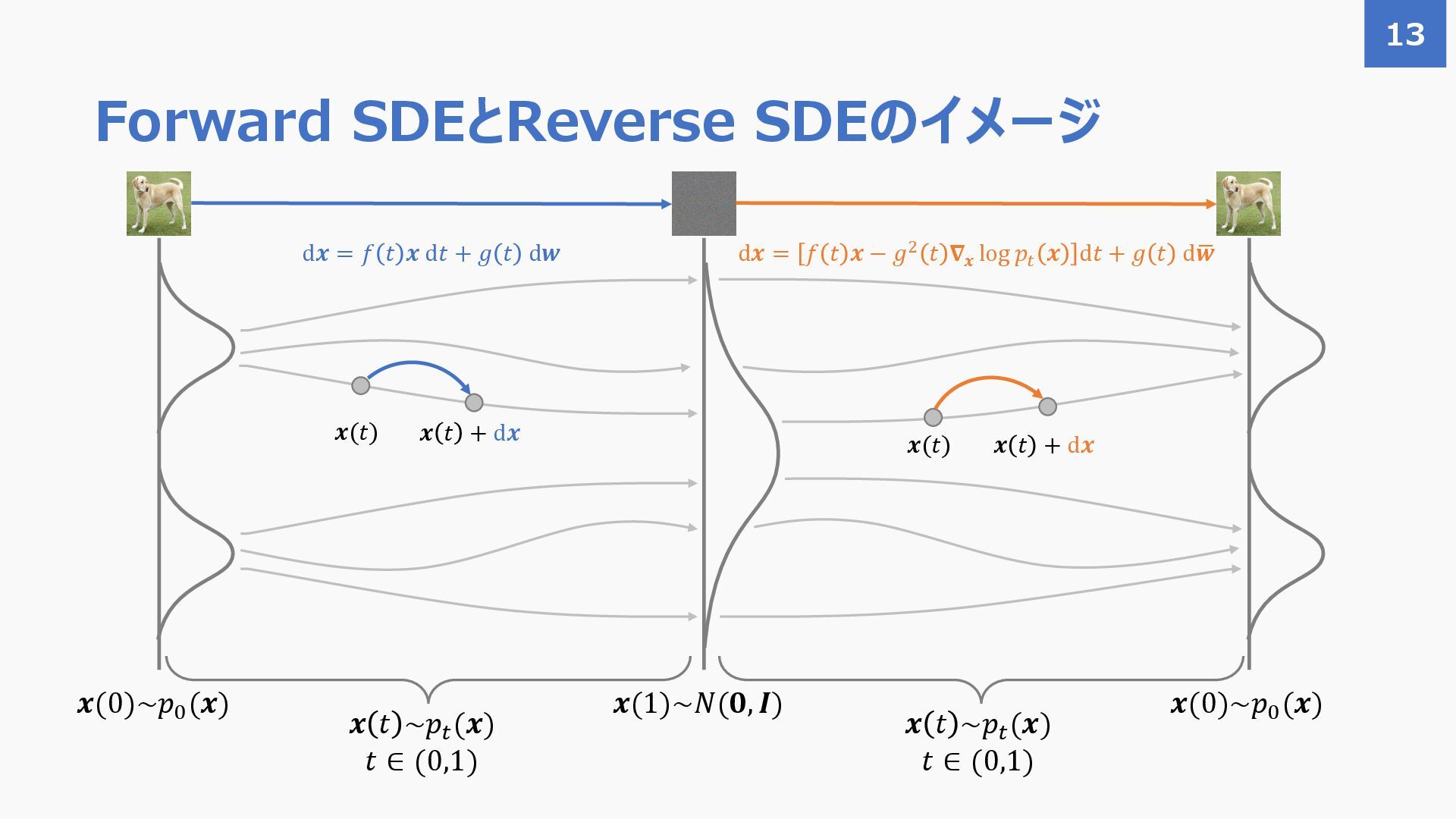{kind=link}
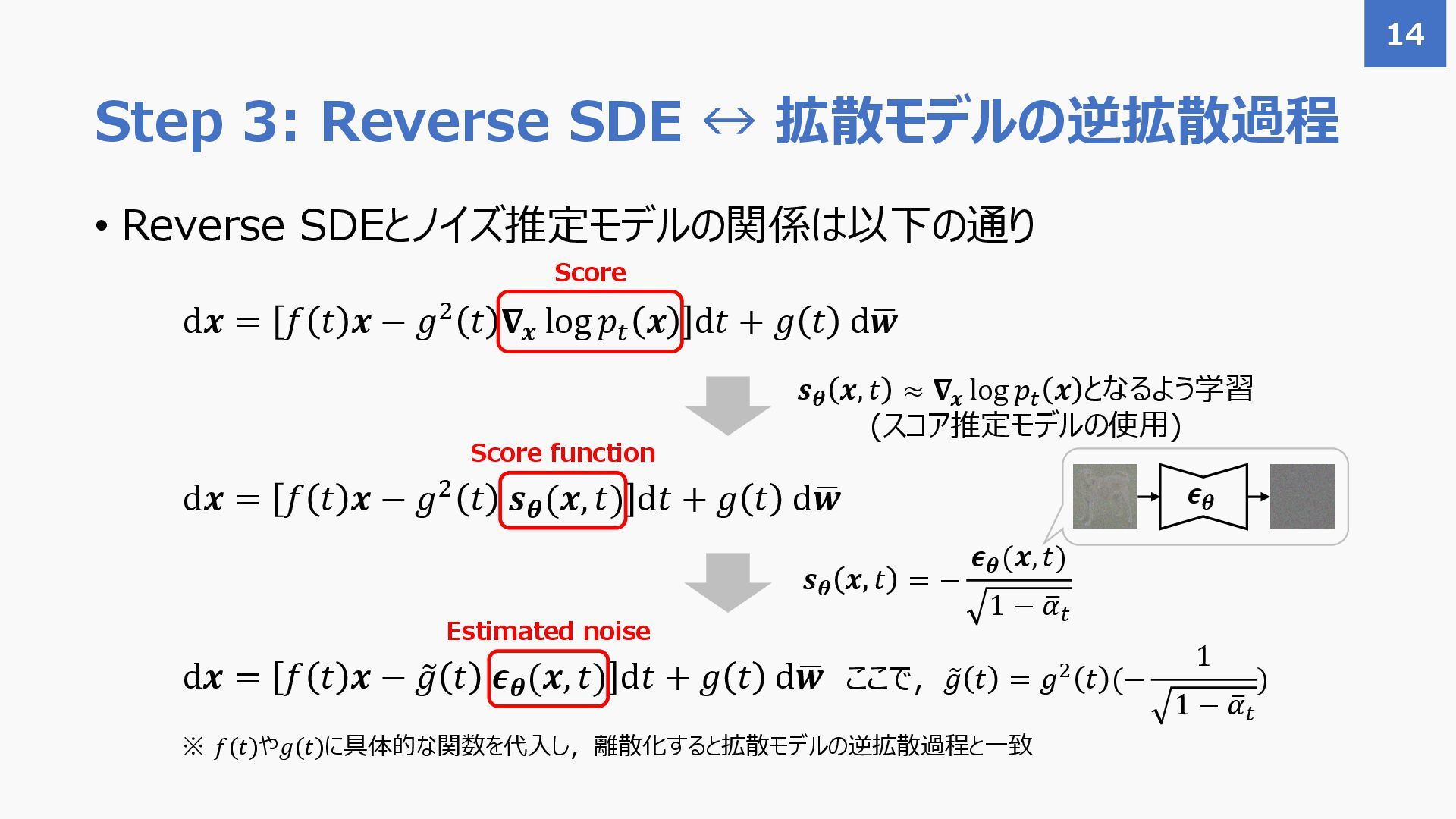{kind=link}
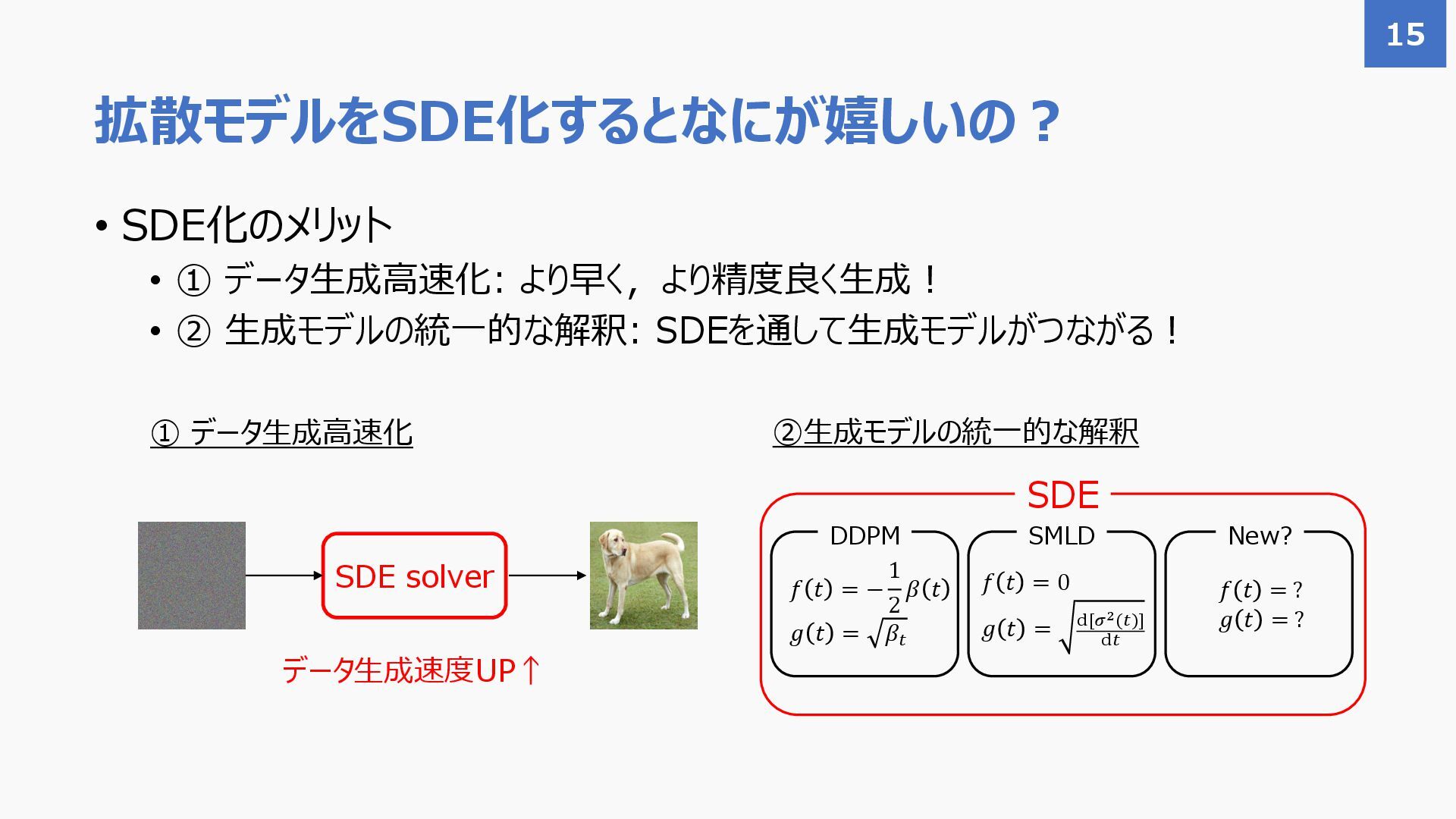{kind=link}
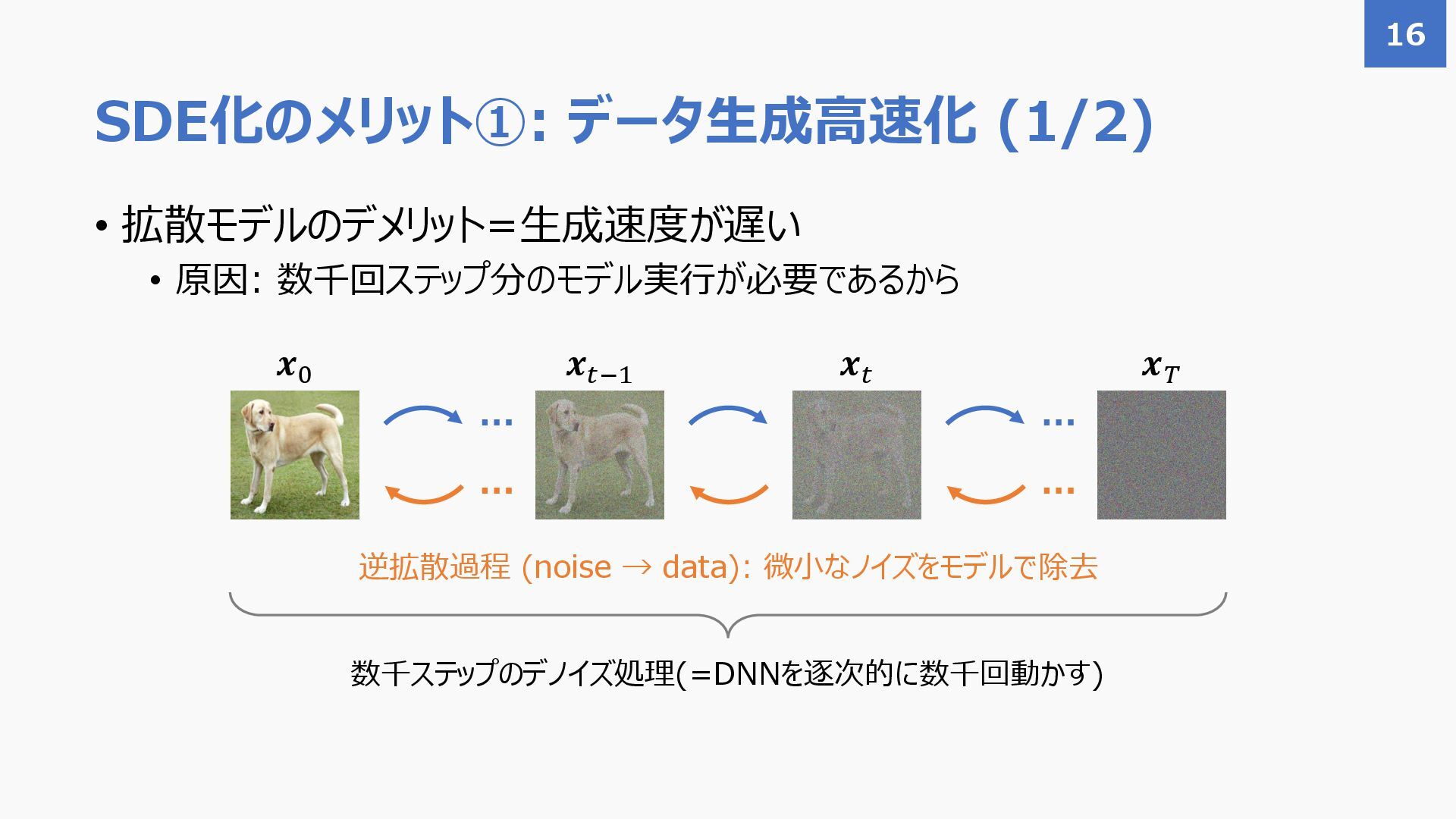{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}