es l ti n Image S nt esis wit Latent i si n els”, 2022 [2] la est Labs, L X, 2024, tt s://git b m/bla - est-labs/ l x [3] at i sse , et al , “S aling e ti ie l w ans me s ig - es l ti n Image S nt esis”, I L2024 [4] at il e a n, et al , “ me ging e ties in Sel -S e vise isi n ans me s,” I 2021 [5] axime Oq ab, et al , “ INOv2: Lea ning b st is al eat es wit t S e visi n,” L , 2024 [6] Kaiming e, et al , “ as e A t en e s A e S alable isi n Lea ne s,” 2022 [7] Ale a , et al , “Lea ning ans e able is al els m Nat al Lang age S e visi n,” I L2021 [8] Xia a Z ai, et al , “Sigm i L ss Lang age Image e- aining,” I 2023 [9] Jing eng Ya , et al , “ e nst ti n vs Gene ati n: aming O timizati n ilemma in Latent i si n els,” 2025 [10] e s K zelis, et al , “ sting Gene ative Image eling via J int Image- eat e S nt esis,” Ne I S2025 [11] Si n Y , et al , “ e esentati n Alignment Gene ati n: aining i si n ans me s Is asie an Y in ”, I L 2025 [12] Xingjian Leng, et al , “ A- : nl ing A n -t - n ning wit Latent i si n ans me s”, I 2025 [13] Ge W , et al , “ e esentati n ntanglement Gene ati n: aining i si n ans me s Is asie an Y in ,” a xiv e int, 2025 [14] S ai Wang et al , “ : e le i si n ans me ,” a xiv e int, 2025 [15] Nan e a, et al , “Si : x l ing l w an i si n-base Gene ative els wit S alable Inte lant ans me s,” 2024 [16] e Ka as, et al , “G i ing a i si n el wit a a e si n Itsel ,” Ne I S2024 [17] wei en, et al , “Aligning is al n ati n n e s t enize s i si n els,” a xiv e int, 2025 [18] ian i i, et al , “ isi n n ati n els an e G enize s Latent i si n els”, a xiv e int, 2025 [19] ing G i, et al , “A a ting Sel -S e vise e esentati ns as a Latent S a e i ient Gene ati n,” a xiv e int, 2025 [20] inglei S i, et al , “Latent i si n el wit t a iati nal A t en e ”, a xiv e int, 2025 参考文献 25
{kind=link}
{kind=link}
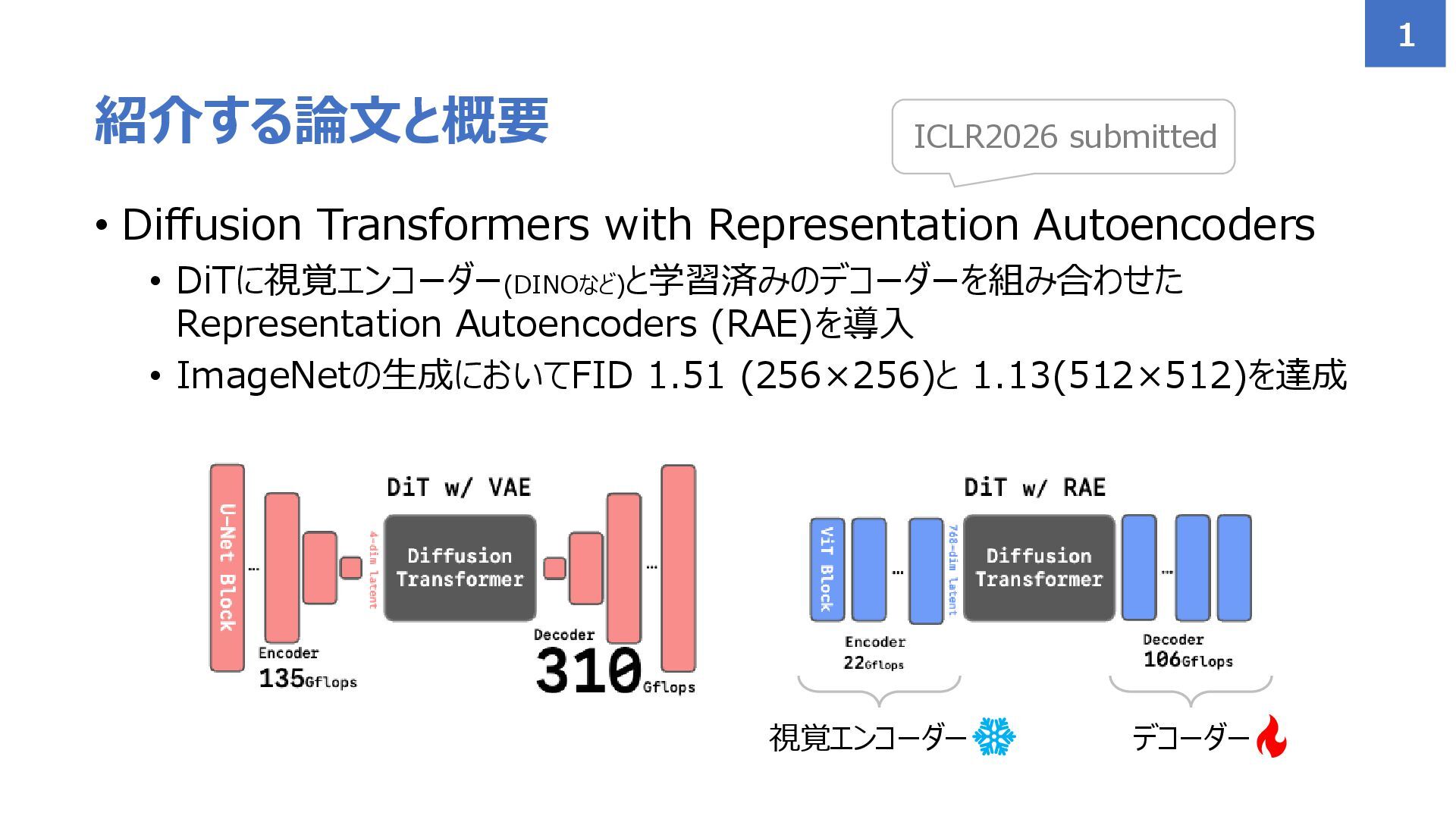
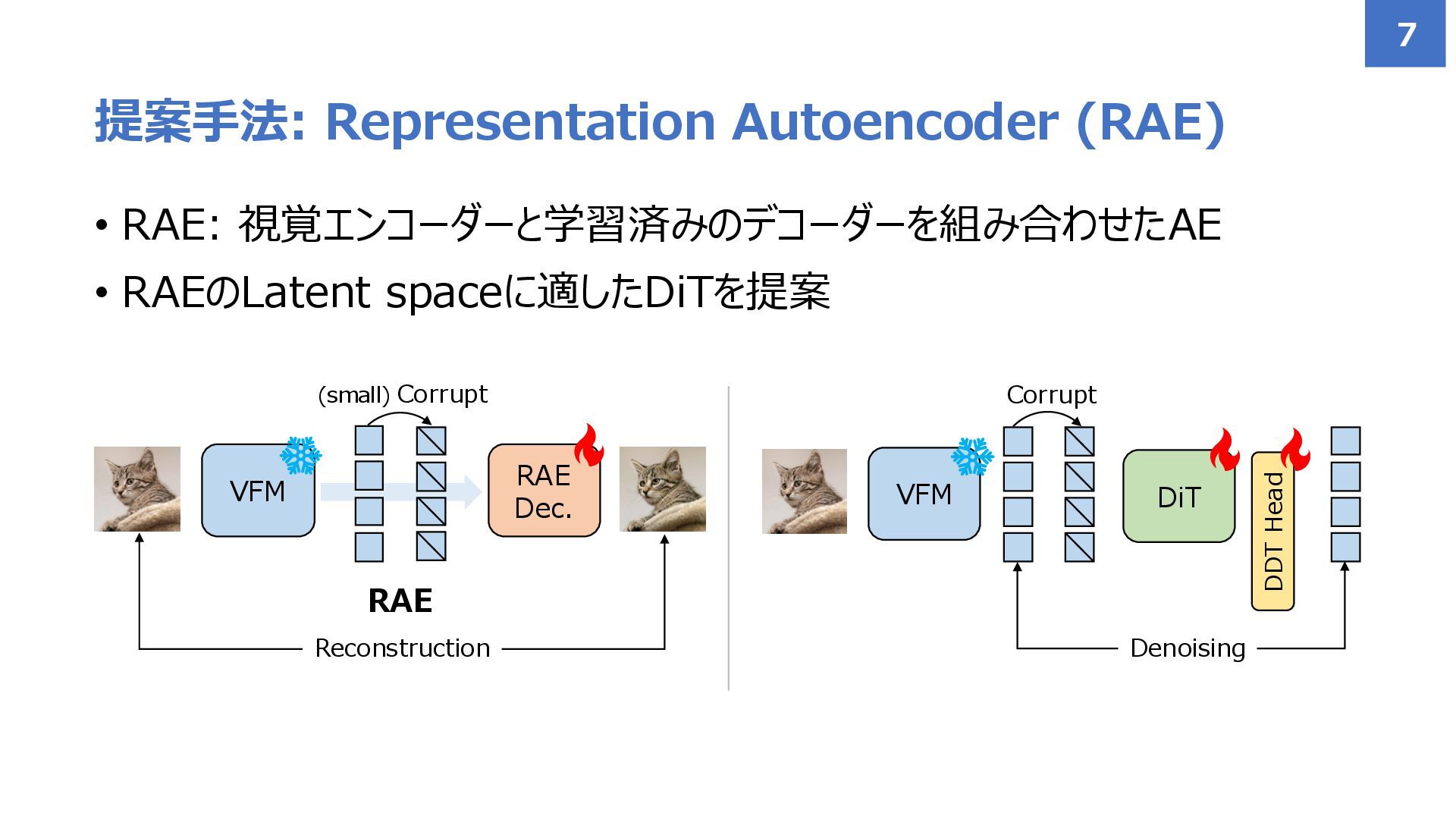
![• Latent Diffusion Models (LDM)やDiffusion Transformer (DiT) が高い生成精度と処理効率を実現 • ほとんどの大規模な拡散モデル[1,2,3]はLatent](https://files.speakerdeck.com/presentations/28100fa84ab043cf95c9a15569af6480/slide_2.jpg){kind=link}
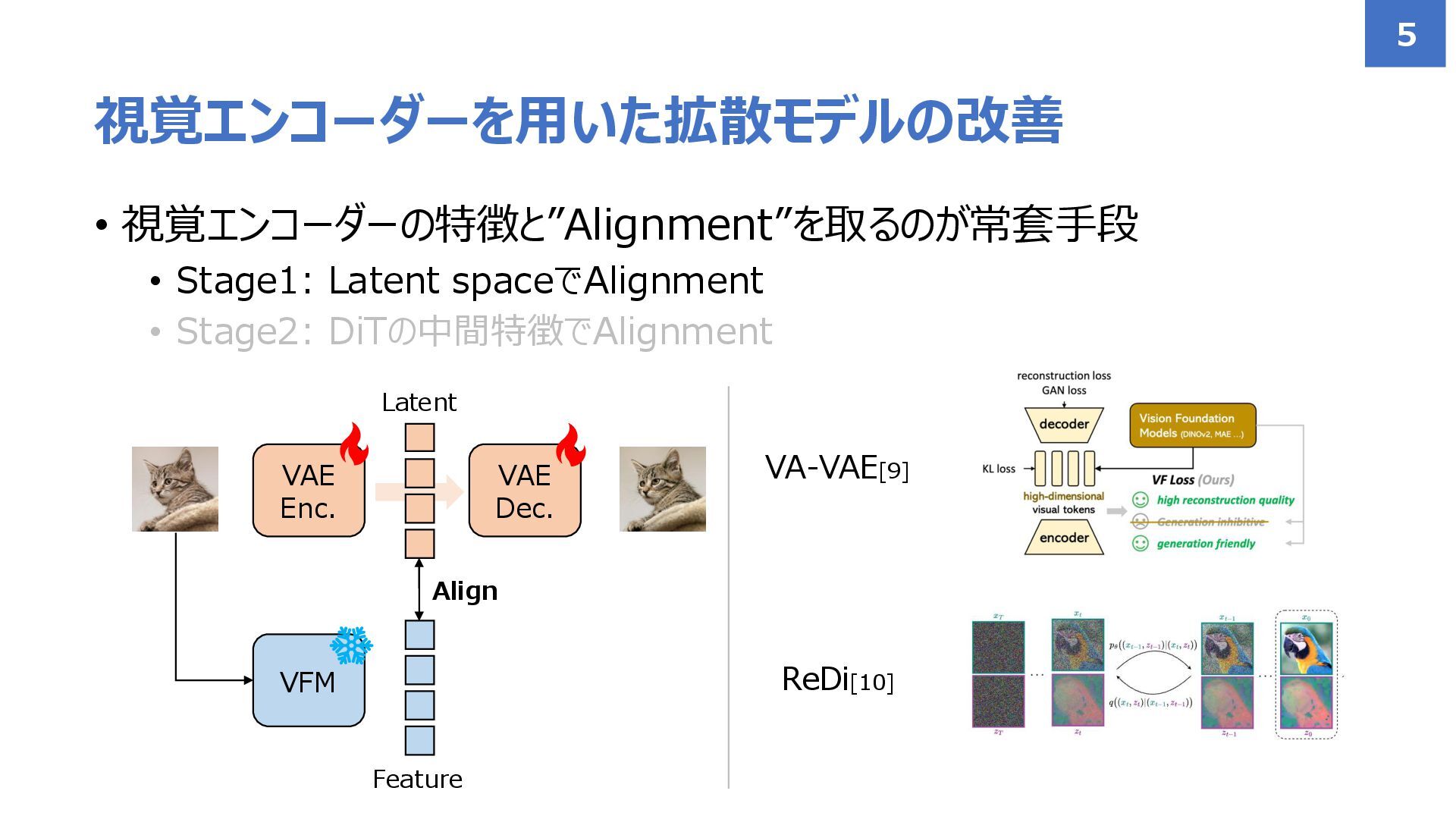
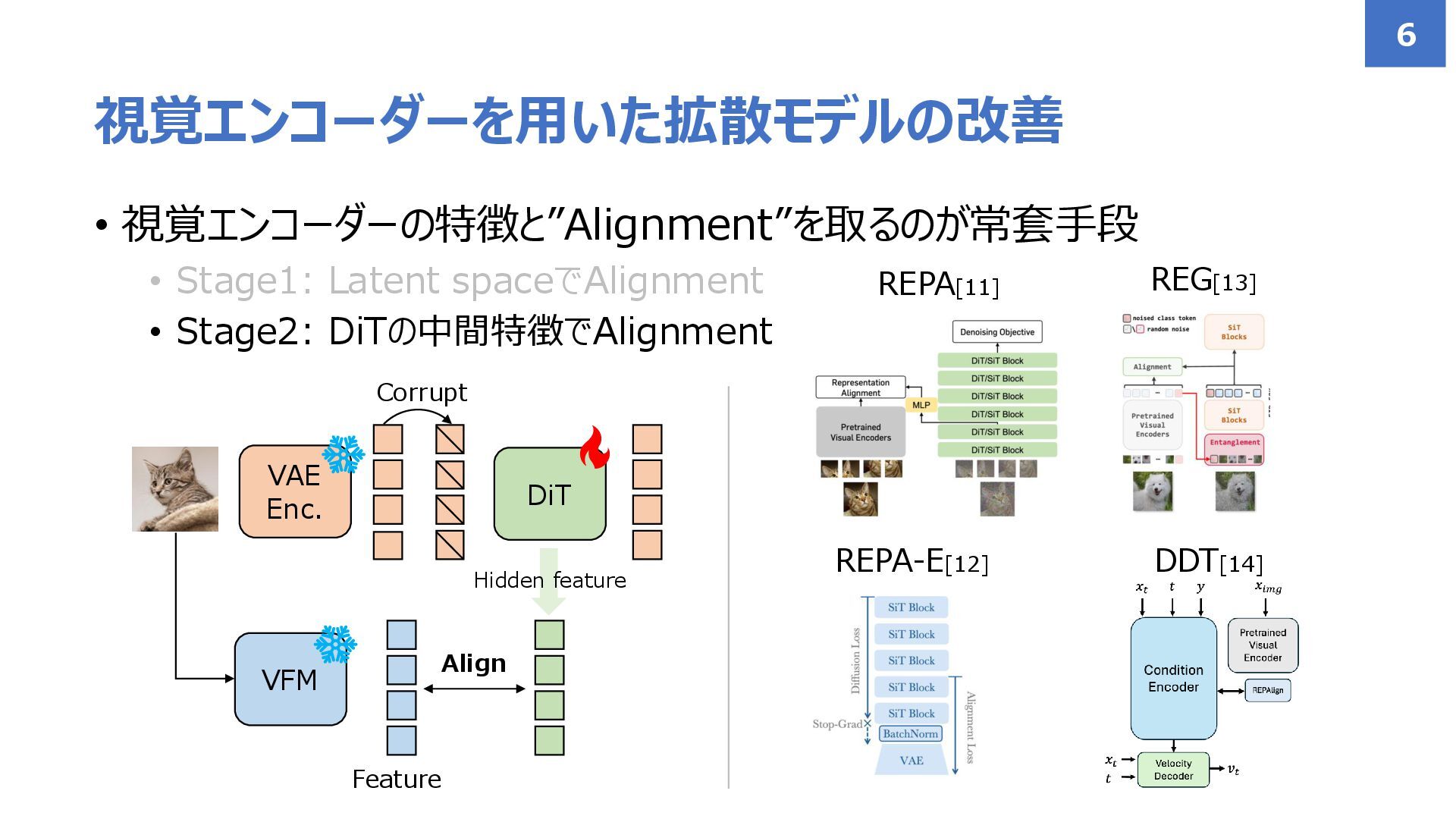
![• 視覚エンコーダー (DINO[4,5], MAE[6], CLIP[7]/SigLIP[8]など)を使って 拡散モデルを改善するような手法が提案 • 意味構造を持つ特徴空間を拡散モデルの学習に活用! 視覚エンコーダーを用いた拡散モデルの改善 3](https://files.speakerdeck.com/presentations/28100fa84ab043cf95c9a15569af6480/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
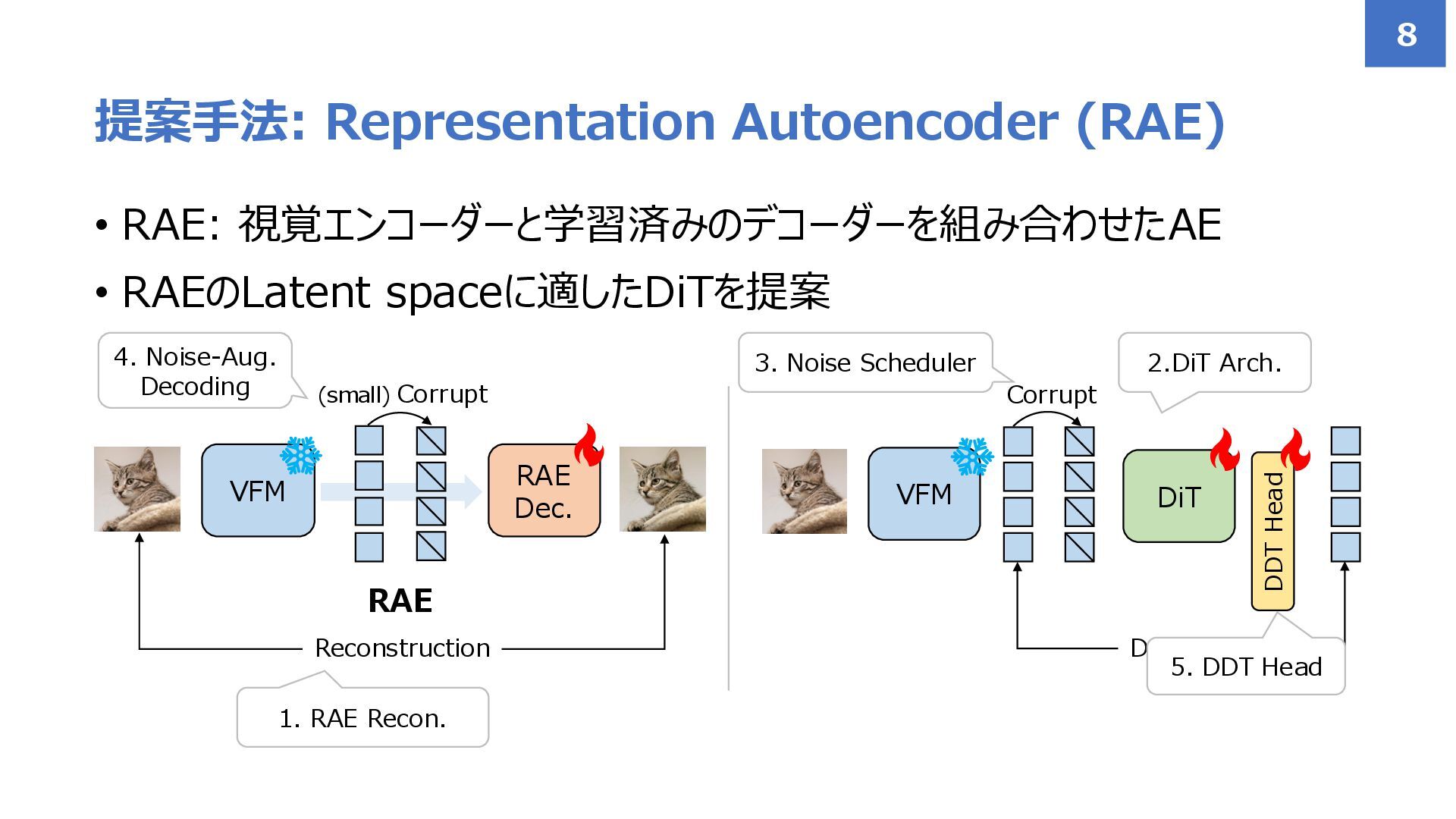{kind=link}
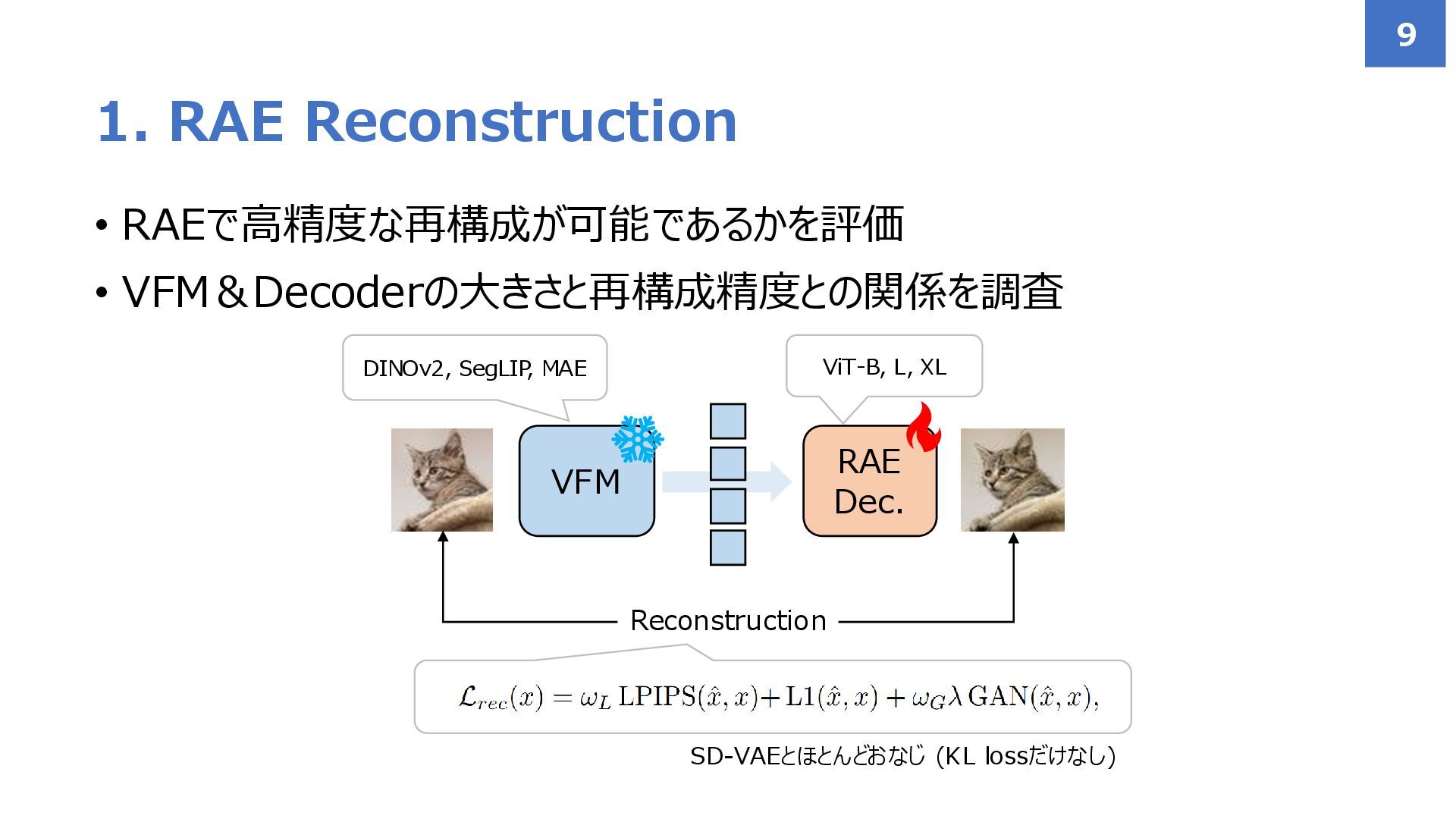{kind=link}
{kind=link}
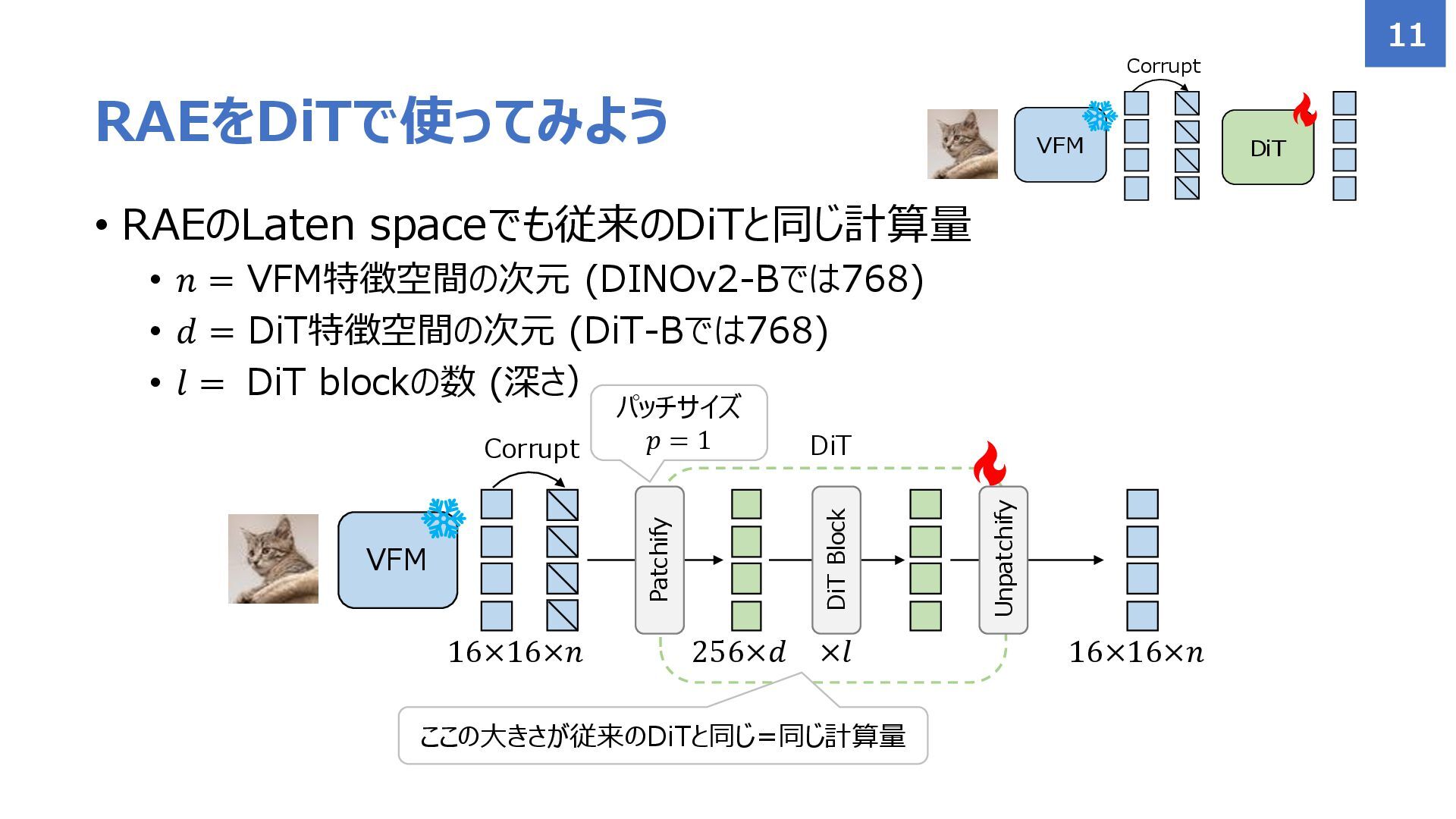{kind=link}
{kind=link}
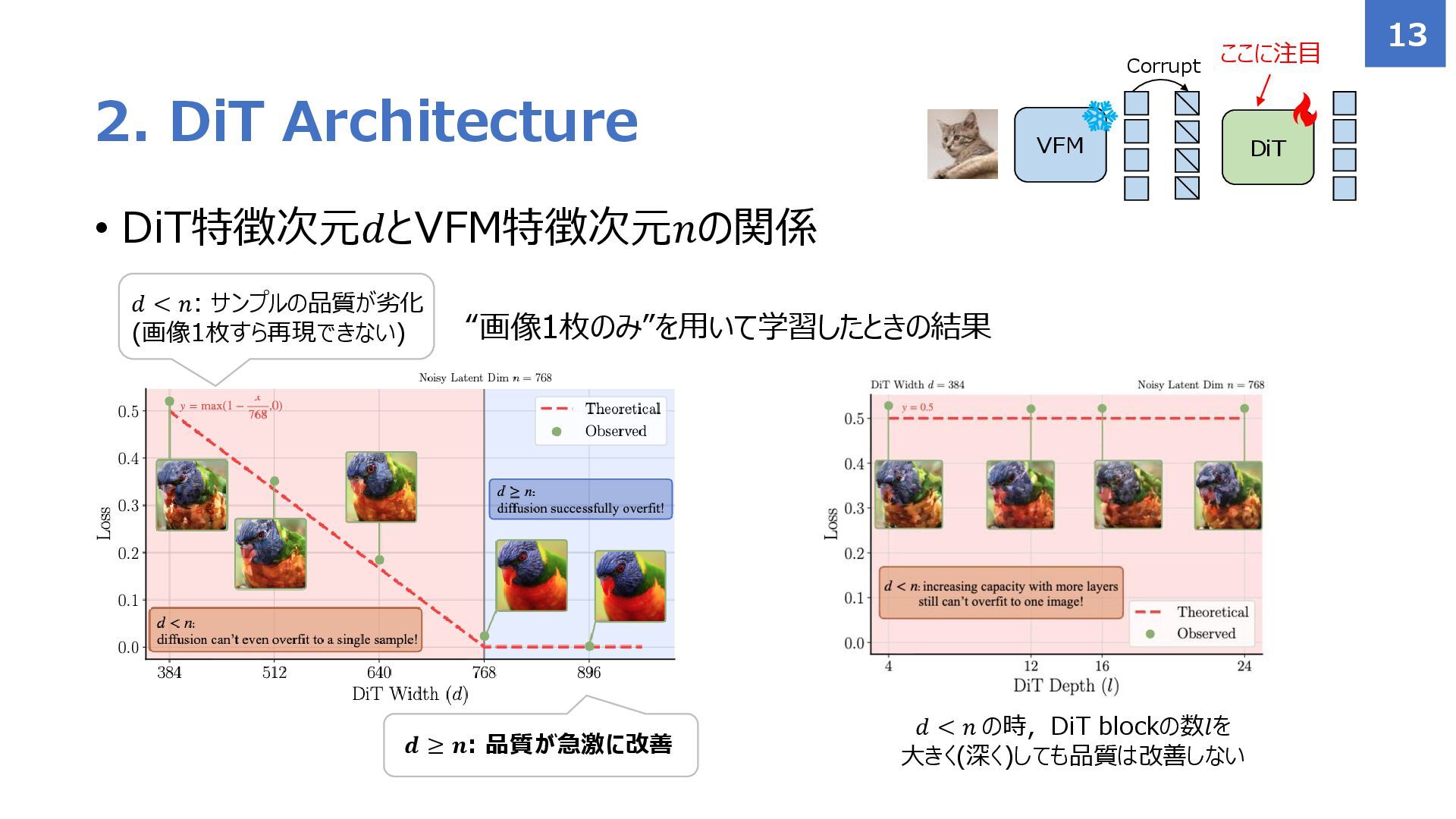{kind=link}
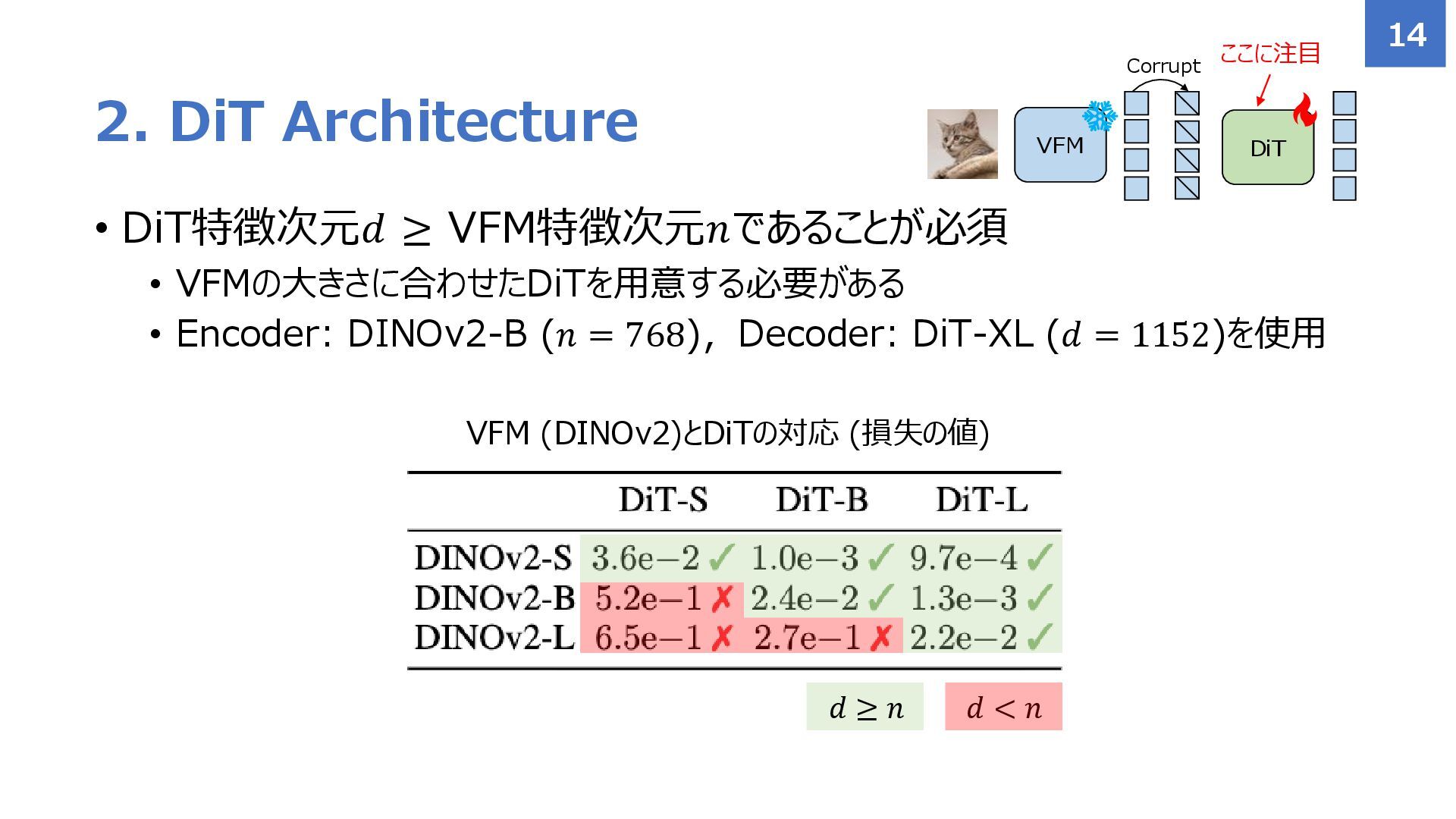{kind=link}
{kind=link}
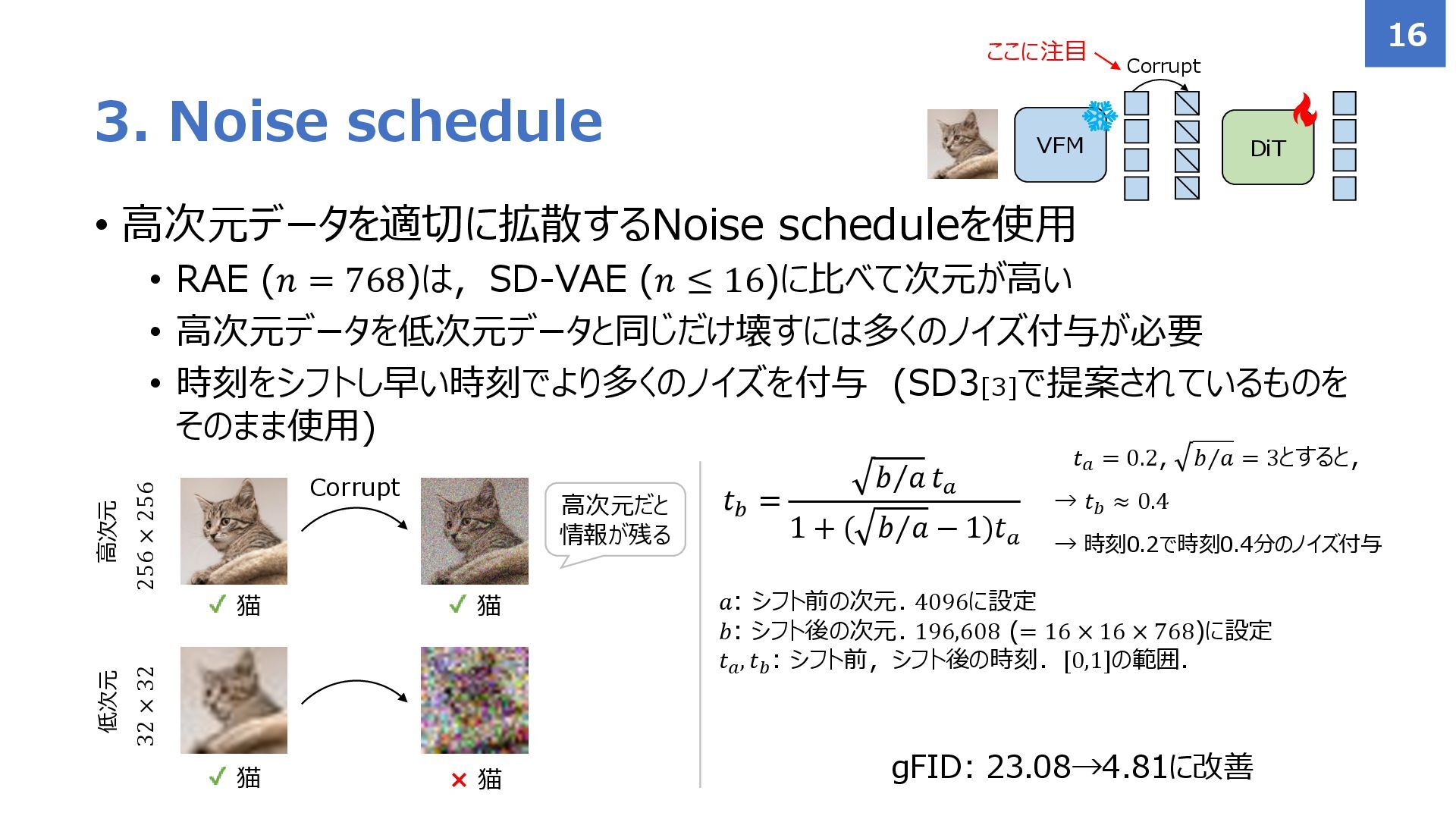{kind=link}
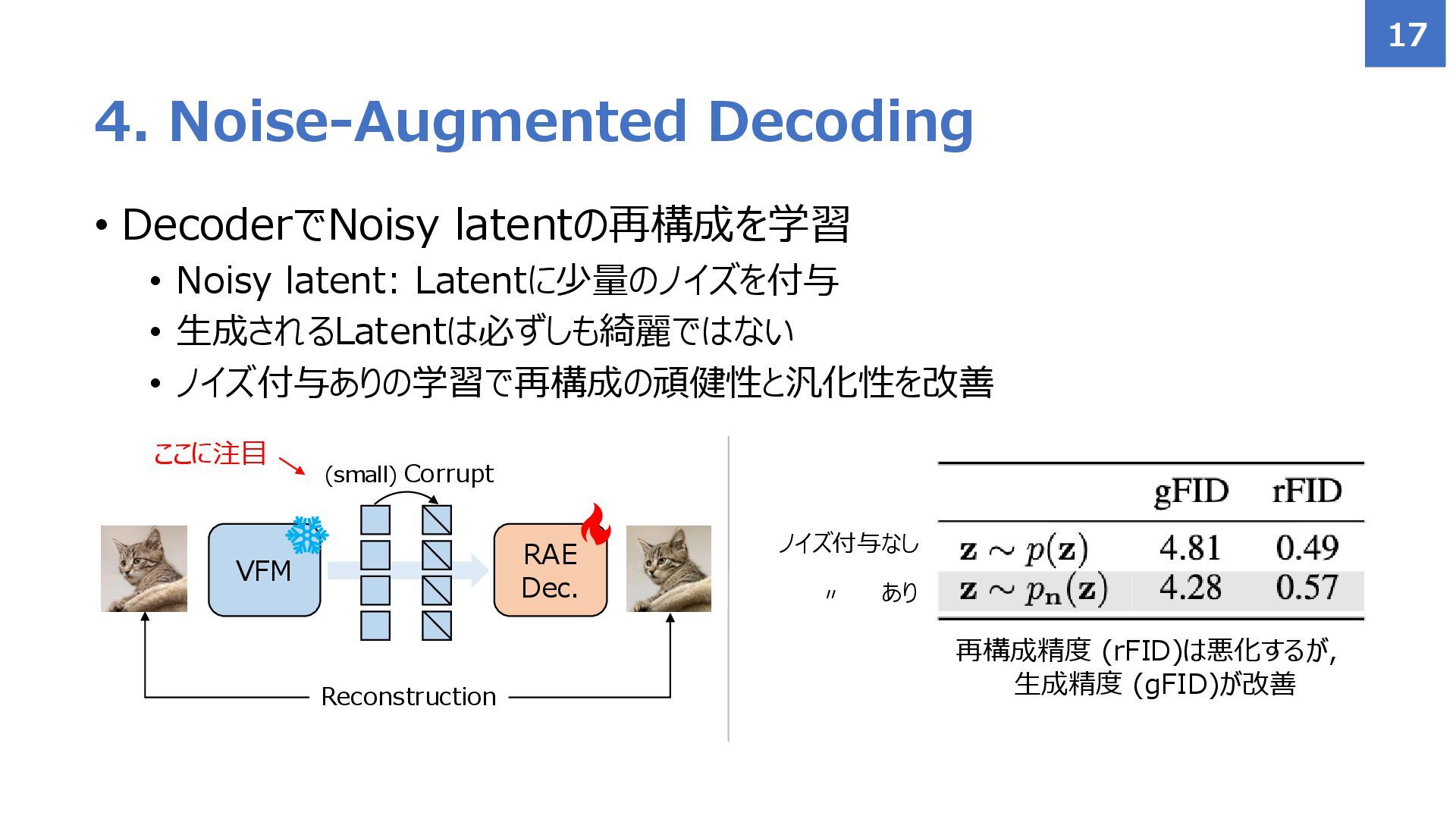{kind=link}
![• 1.~4.を組み合わせてモデルで従来手法 (SiT[15], REPA[11])と比較 改善点を組み込んだDiT with RAEを評価 18 g I](https://files.speakerdeck.com/presentations/28100fa84ab043cf95c9a15569af6480/slide_18.jpg){kind=link}
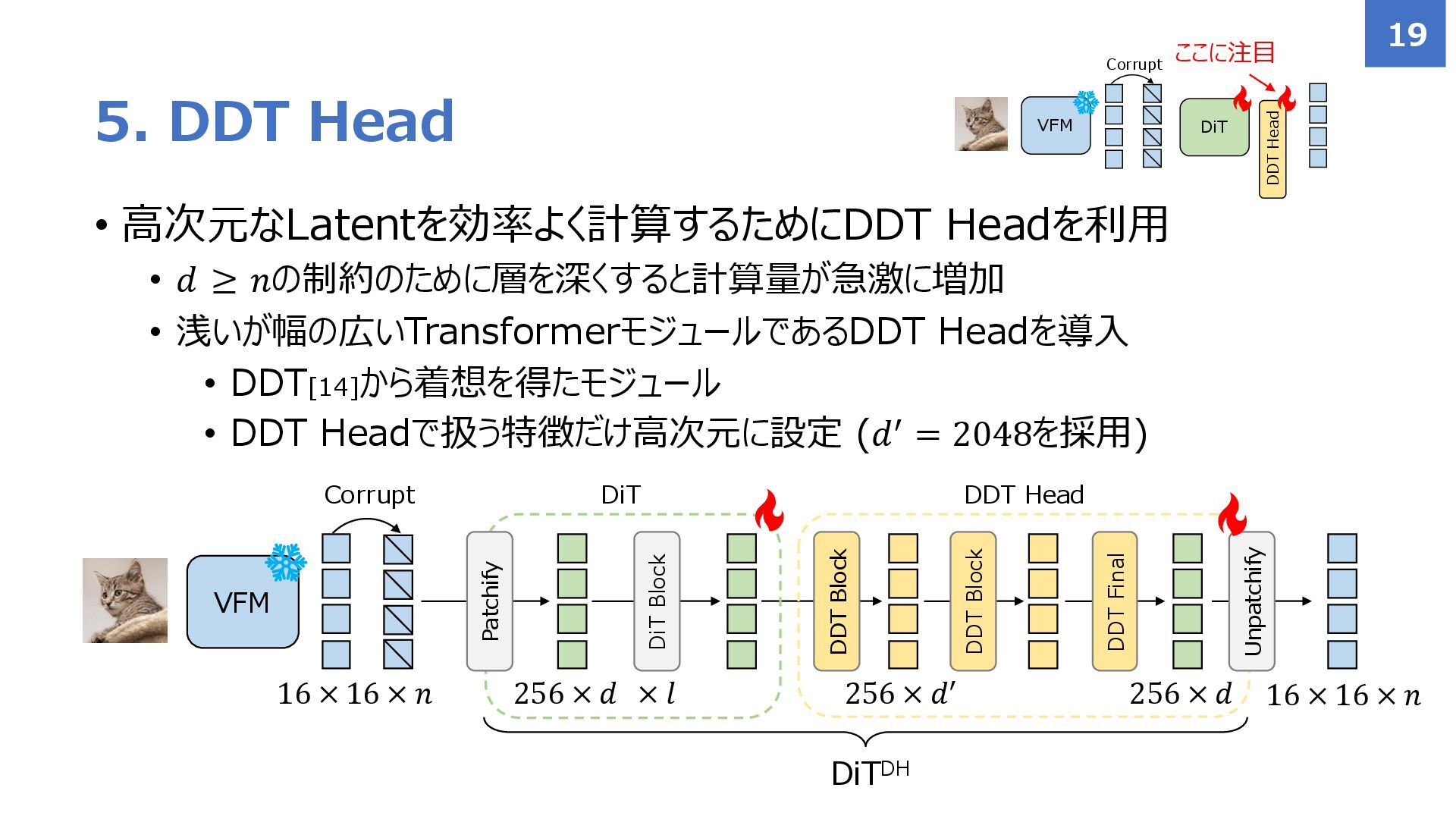{kind=link}
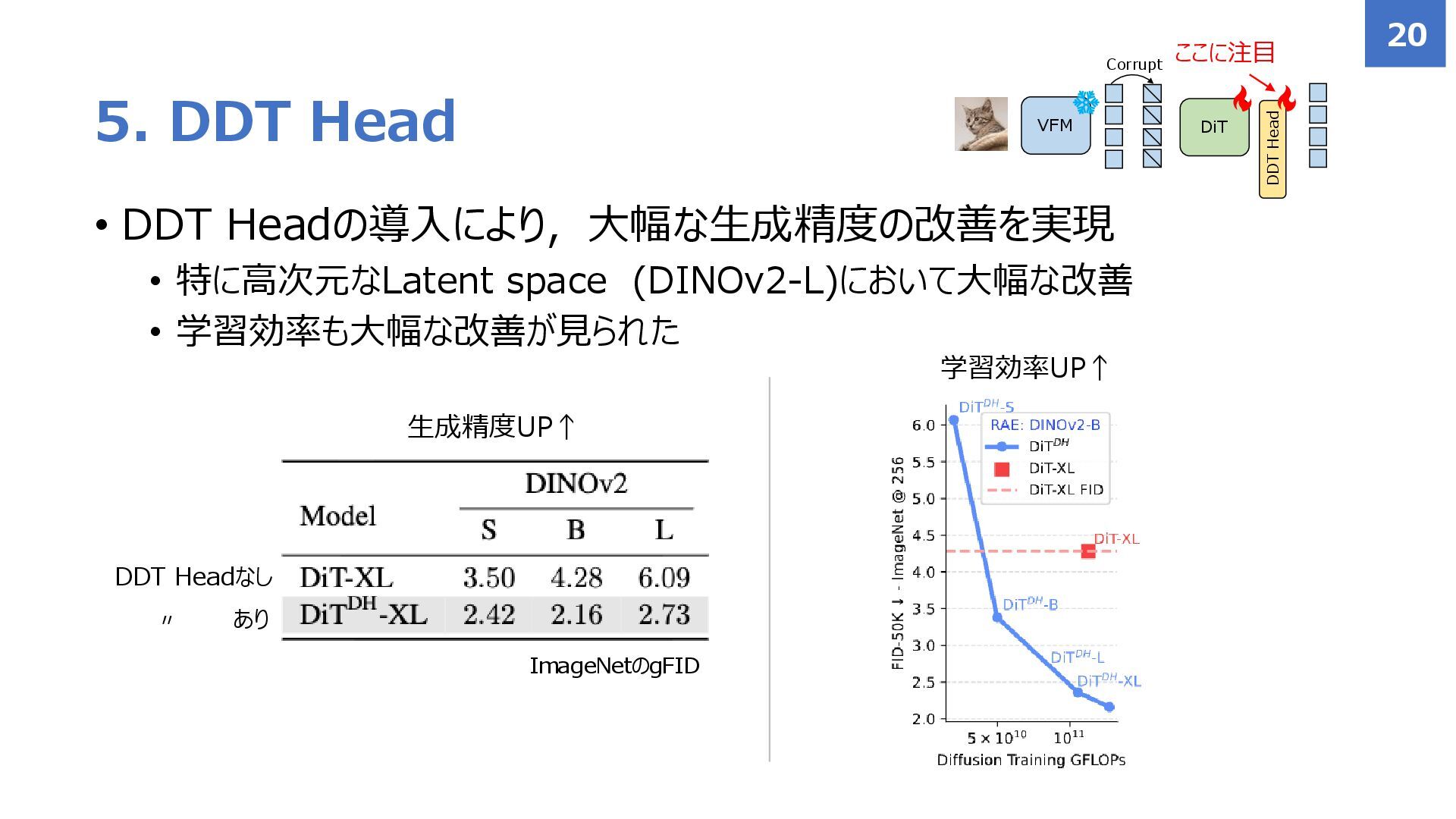{kind=link}
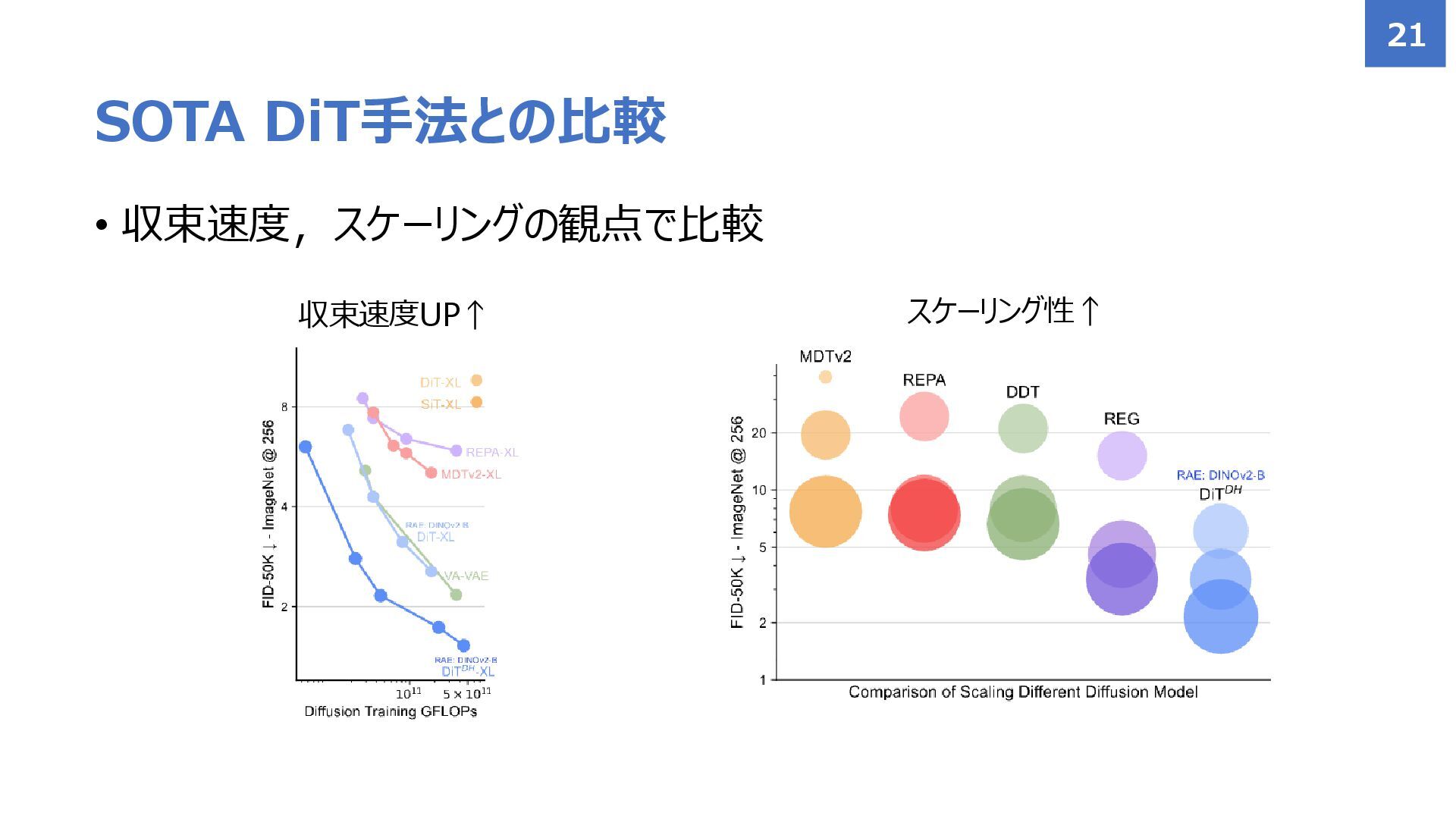{kind=link}
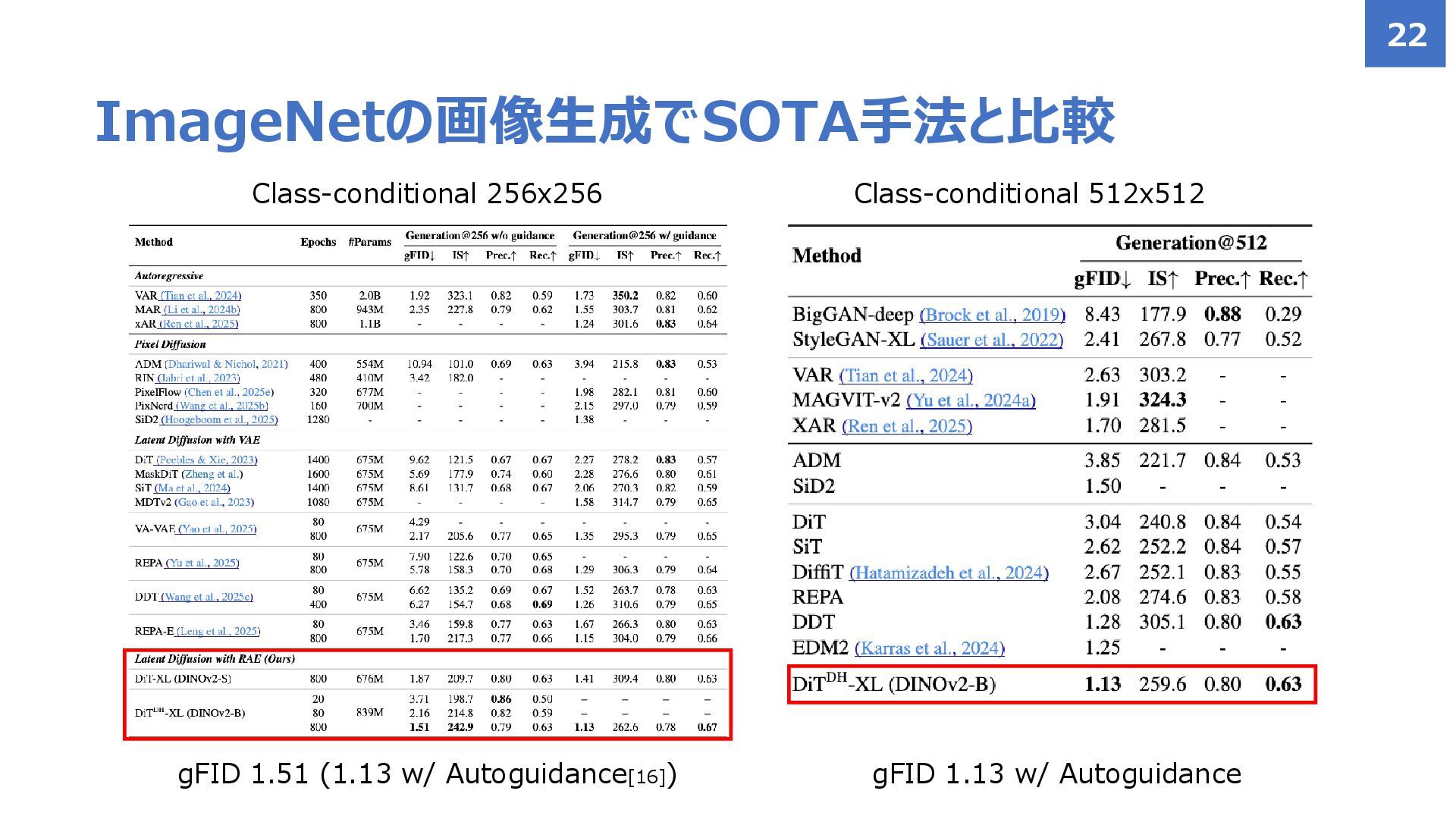{kind=link}
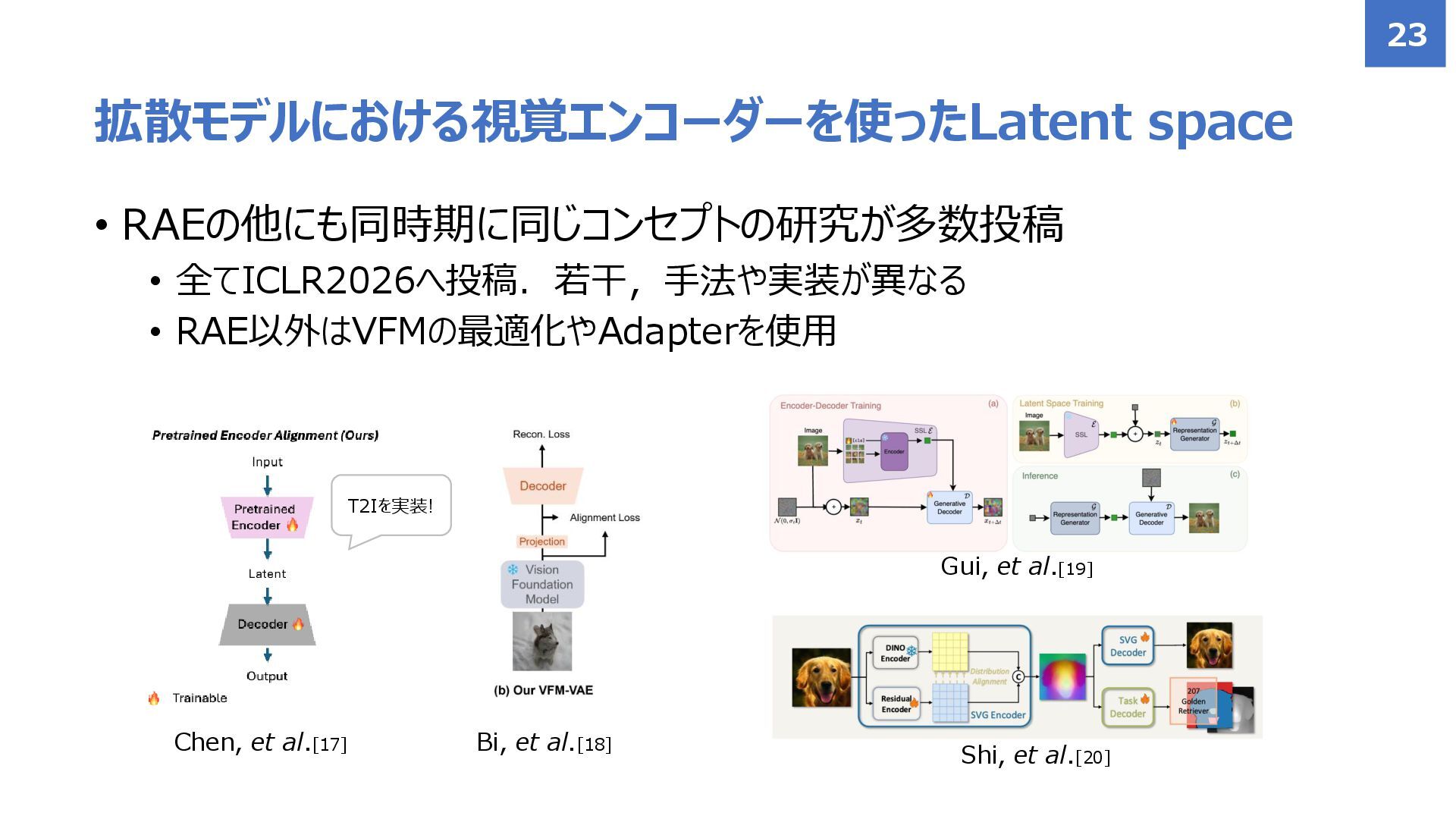{kind=link}
{kind=link}
![[1] bin mba , et al , “ ig -](https://files.speakerdeck.com/presentations/28100fa84ab043cf95c9a15569af6480/slide_25.jpg){kind=link}
{kind=link}
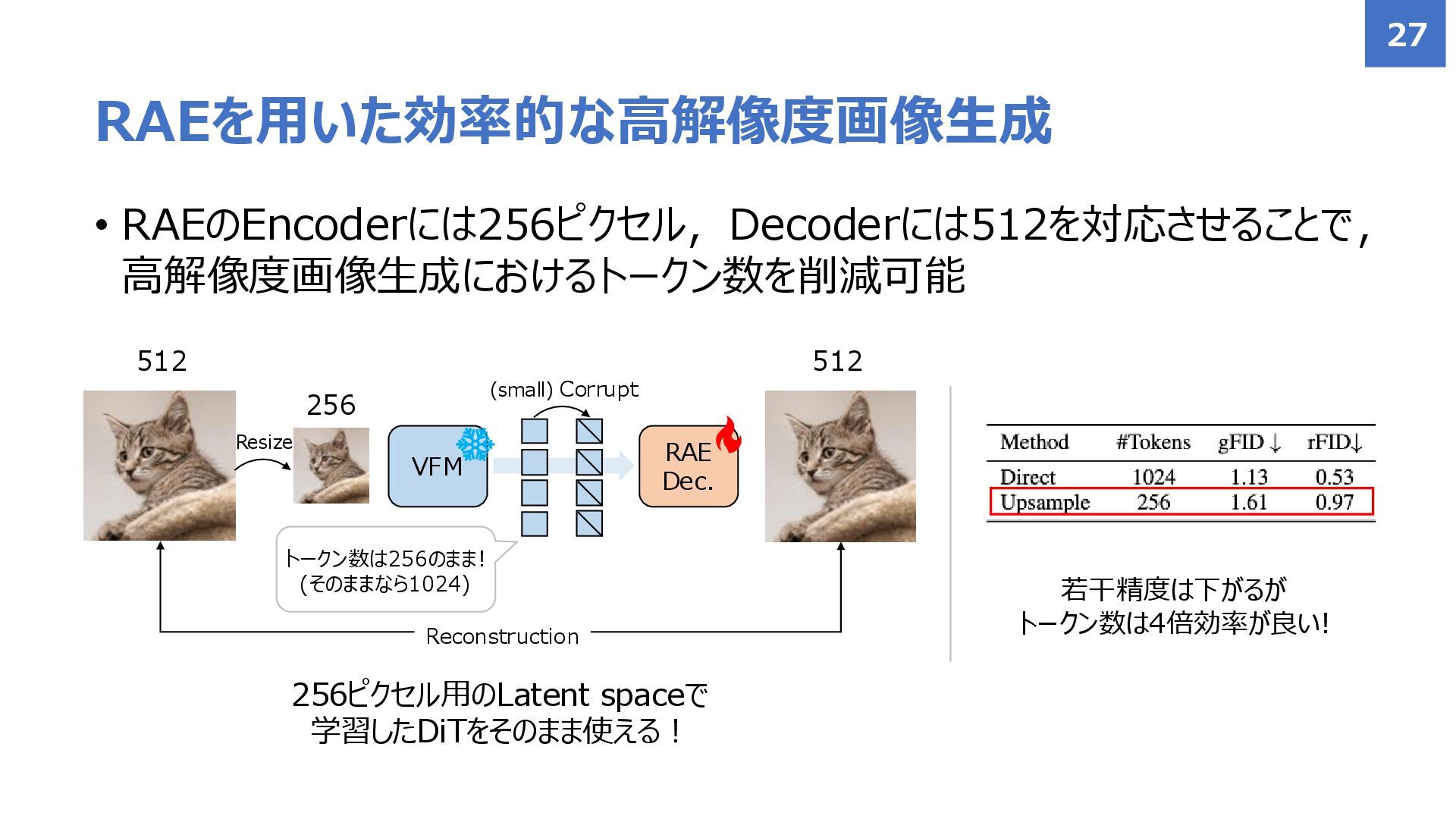{kind=link}
{kind=link}
{kind=link}