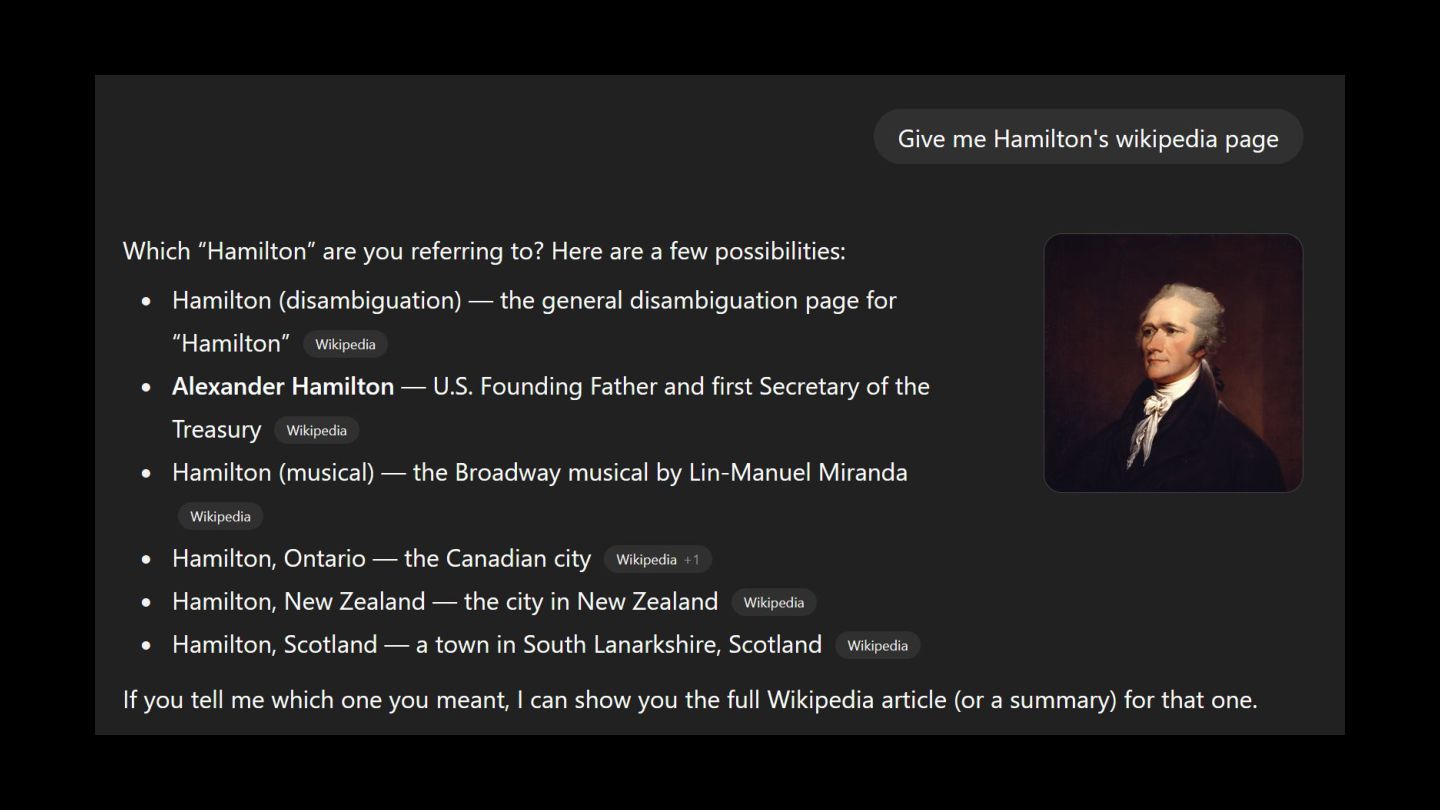
the 2025 F1 championship? As of the latest standings after the 2025 Singapore GP, Oscar Piastri is leading the Drivers’ Championship. Who won in Monaco? Lando Norris did.
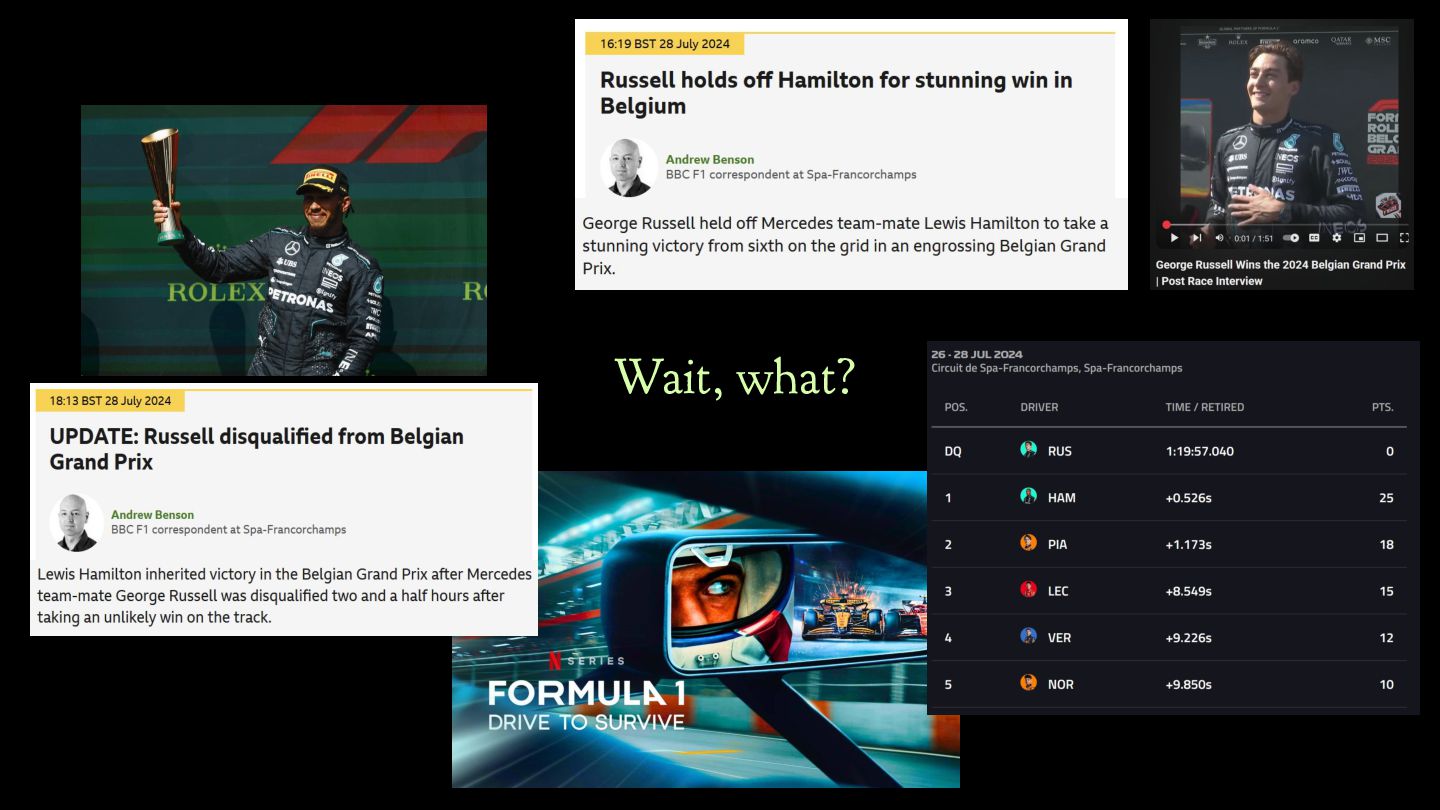
crossed the finish line first, securing victory for Mercedes. So Russel won the Spa GP in 2024? No, Hamilton did. Russel his car was disqualified after the race due to being 1.5kg underweight.
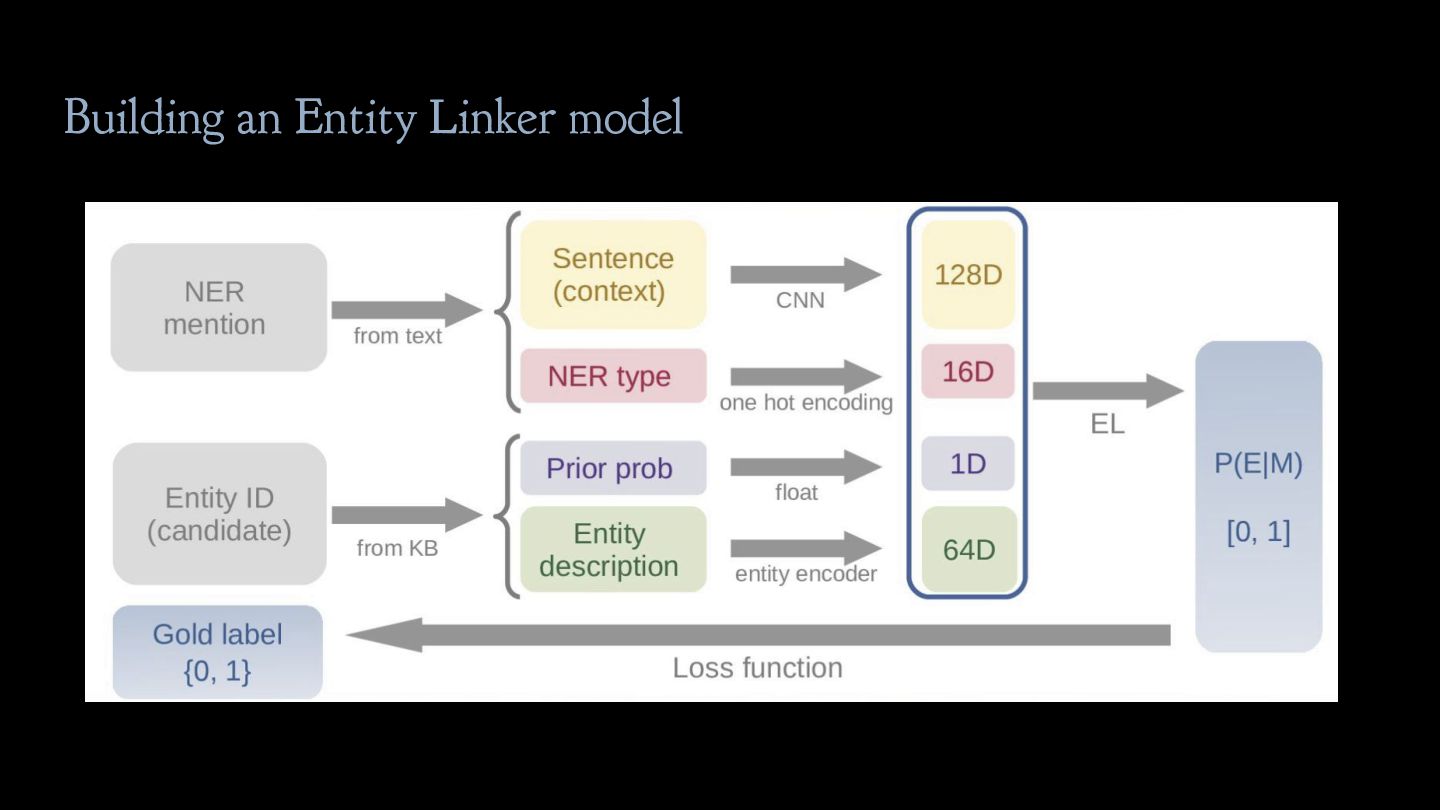
is linked to a certain concept Textual mention F1 race driver Founding father Musical "Hamilton" 35% 55% 10% "Lewis Hamilton" 99% 0% 0% "Alexander Hamilton" 0% 82% 15%
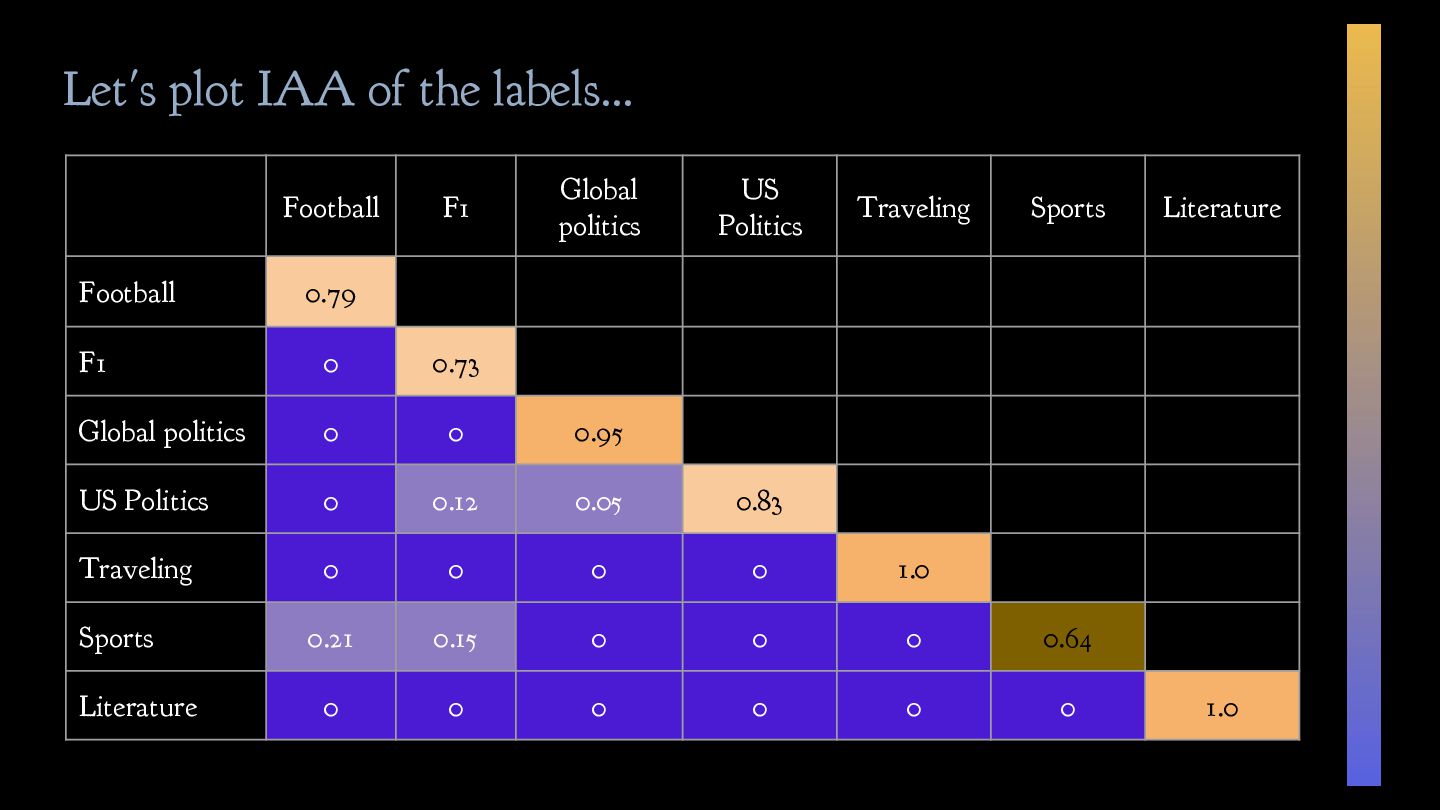
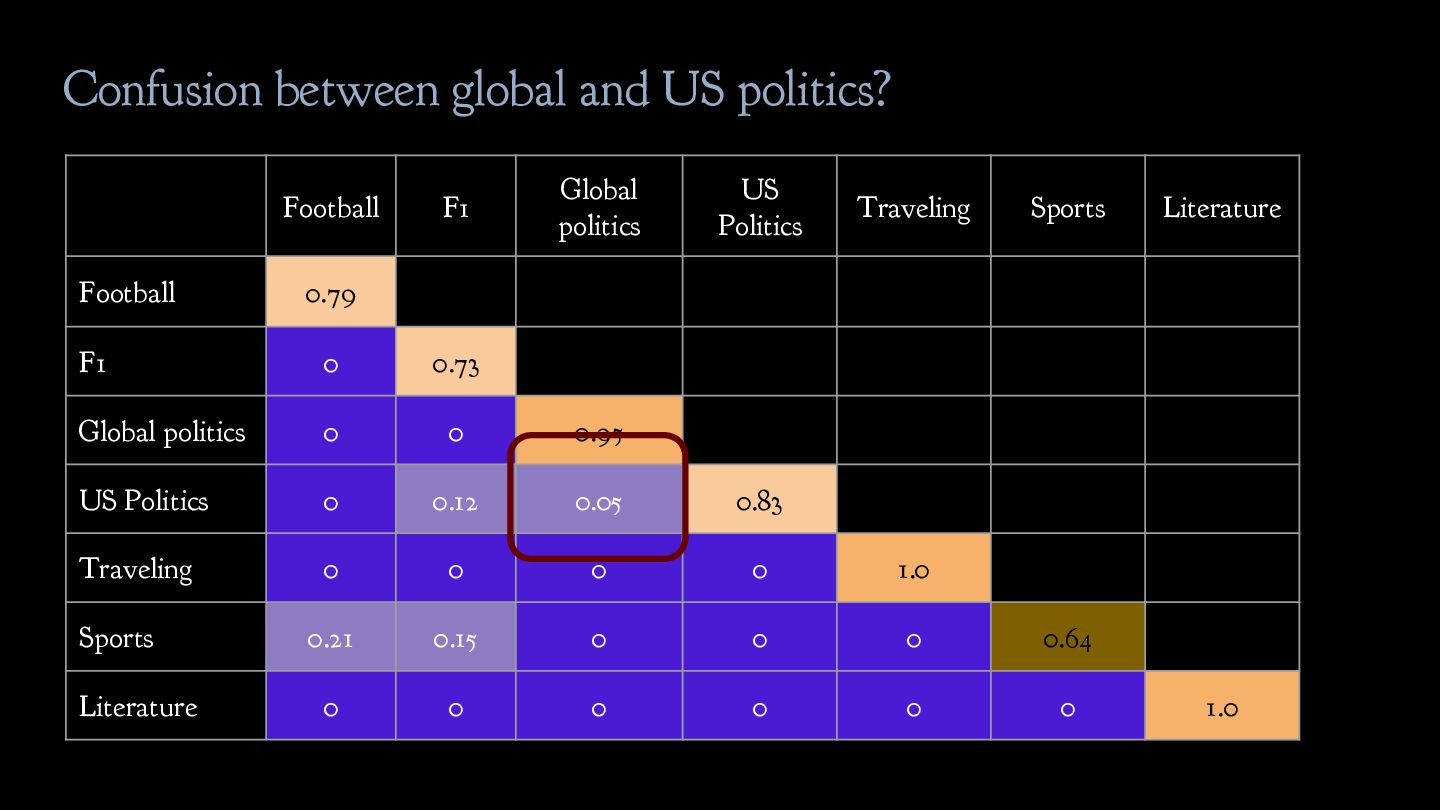
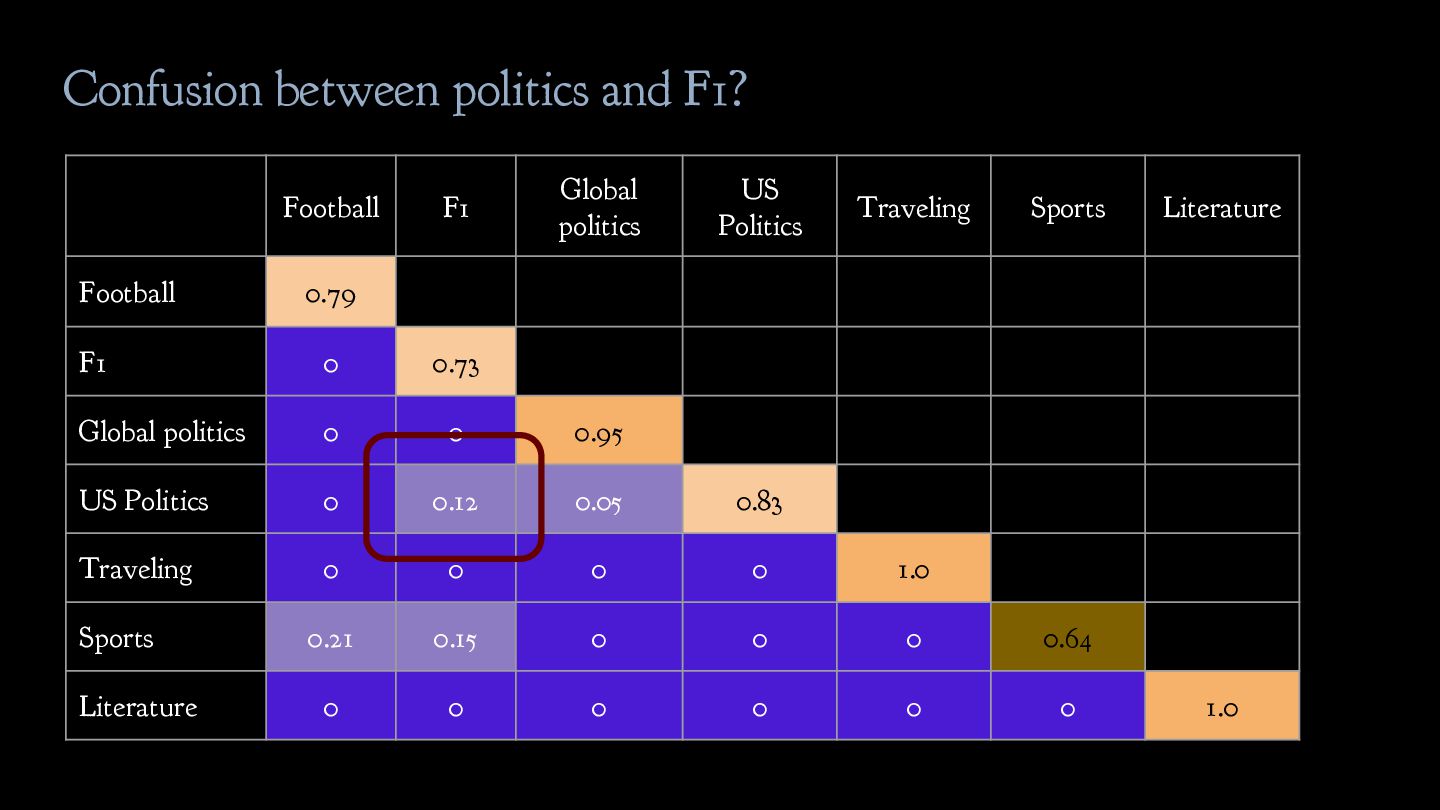
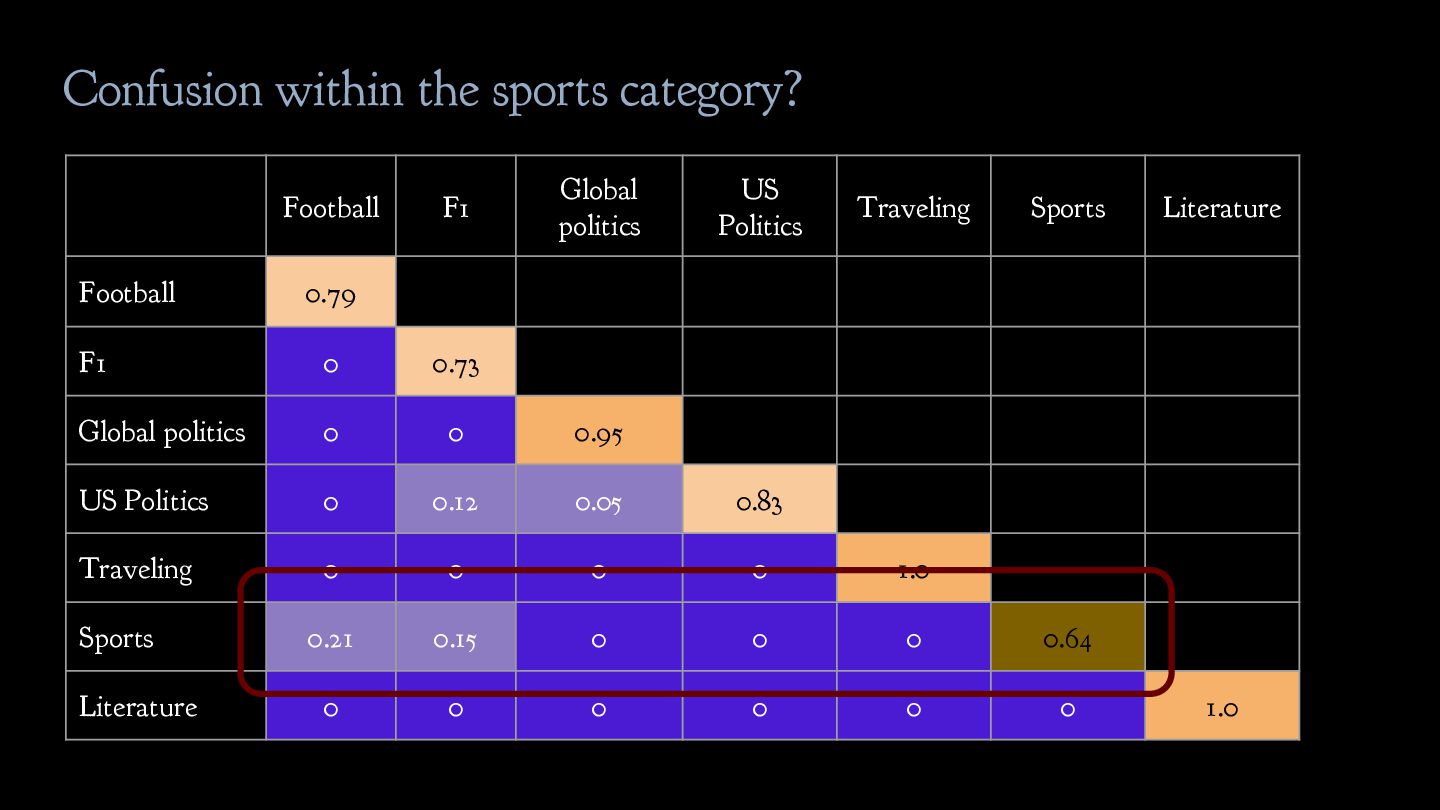
politics b. US politics 3. Leisure a. Traveling b. Sports c. Literature Solution: critically revise the label scheme given to you! Inherent ambiguity in the label scheme needs to be addressed
entity annotation: ❌ Gasly laments ‘quite sad’ [Monaco] GP crash ✅ Gasly laments ‘quite sad’ [Monaco GP] crash Write up annotation guidelines to help with consistency of annotations
consistent and unambiguous ✓ Draft clear annotation guidelines to ensure data consistency ✓ Measure inter-annotator agreement (IAA) ✓ Consider reframing your task/guidelines if the IAA is low ✓ Model uncertainty in your annotation workflow 📝 1/3
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}