- 2015 SIDERARE SOFTWARE 4 4Vs en grande: • Volumen, Velocidad, Variedad y Variabilidad • Desde el punto de vista técnico, Big Data es un conjunto de técnicas para resolver los problemas de escalabilidad y complejidad de los sistemas de bases de datos y computación modernos, que tienden al manejo de una gran cantidad de datos más allá de la frontera de las bases de datos tradicionales (en la última década). Discusión abierta desde las ciencias del lenguaje: • Big Data es un término acuñado por la industria y no por la academia. • Como muchos otros términos de la industria, está más ligado a propósitos comerciales y tecnológicos que científicos. • Es un ejemplo interesante de cómo la tecnología impacta a la ciencia. • Actualmente representa una oportunidad para el creciente mercado (18k millones de USD) y la investigación…
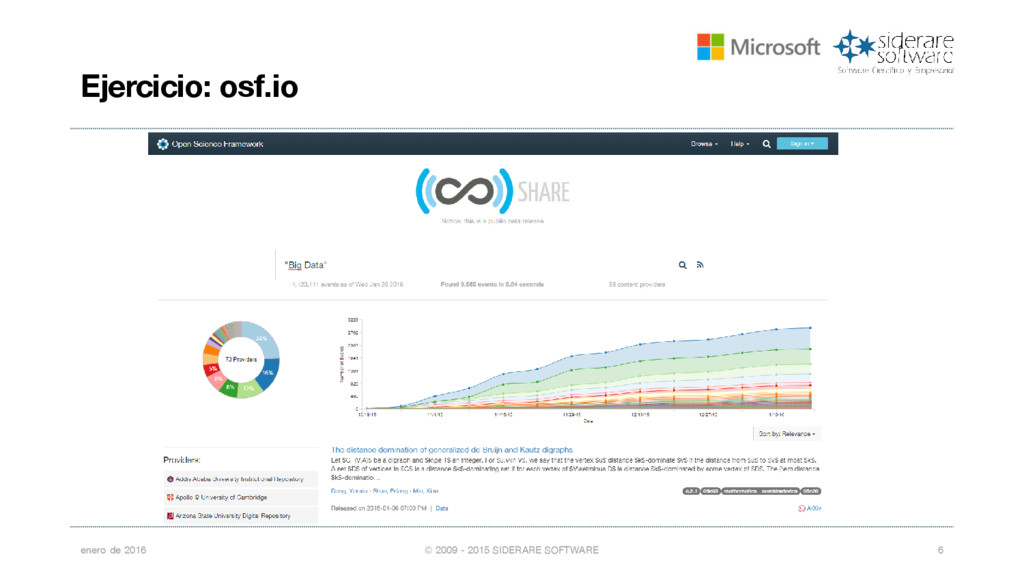
- 2015 SIDERARE SOFTWARE 5 The Open Science Framework • Más de 9000 resultados de investigaciones y artículos que incluyen el término “Big Data” en osf.io (share) Algunos campos de aplicación en las ciencias: • Bioinformática • Observaciones de la tierra • Ciencias de la Salud • Bibliotecología y ciencias del lenguaje • Ciencias Físicas y Ciencias de la Complejidad • Análisis del clima y el tiempo, etc.
SOFTWARE 7 ¿Qué es convergencia tecnológica? • La convergencia tecnológica es la tendencia de diferentes sistemas tecnológicos en la evolución hacia la realización de tareas similares. Convergencia en Big Data • La convergencia tecnológica en Big Data se propicia cuando los sistemas de tratamiento de datos y las herramientas están al tanto de su naturaleza distribuida. • A partir de esta naturaleza se forma un ecosistema de herramientas cambiante y adaptativo. • Las herramientas de Big Data se intersectan con el mundo emergente de la Ciencia de Datos.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
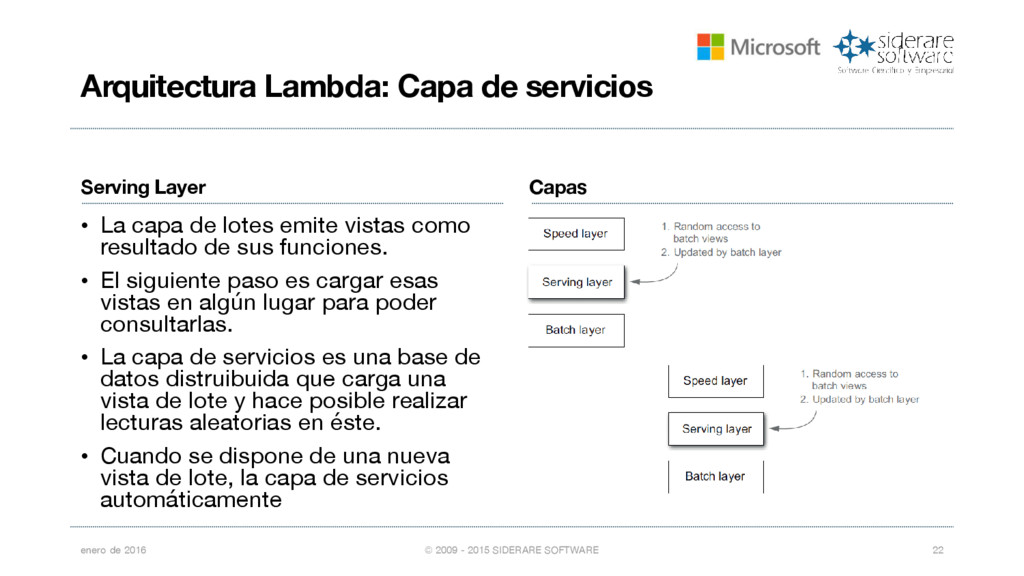{kind=link}
{kind=link}
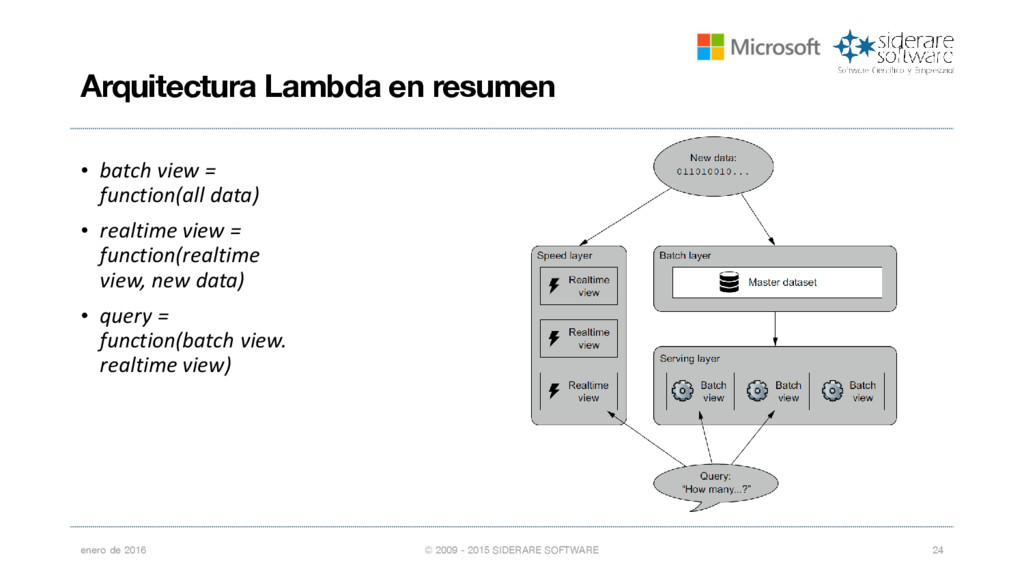{kind=link}
{kind=link}
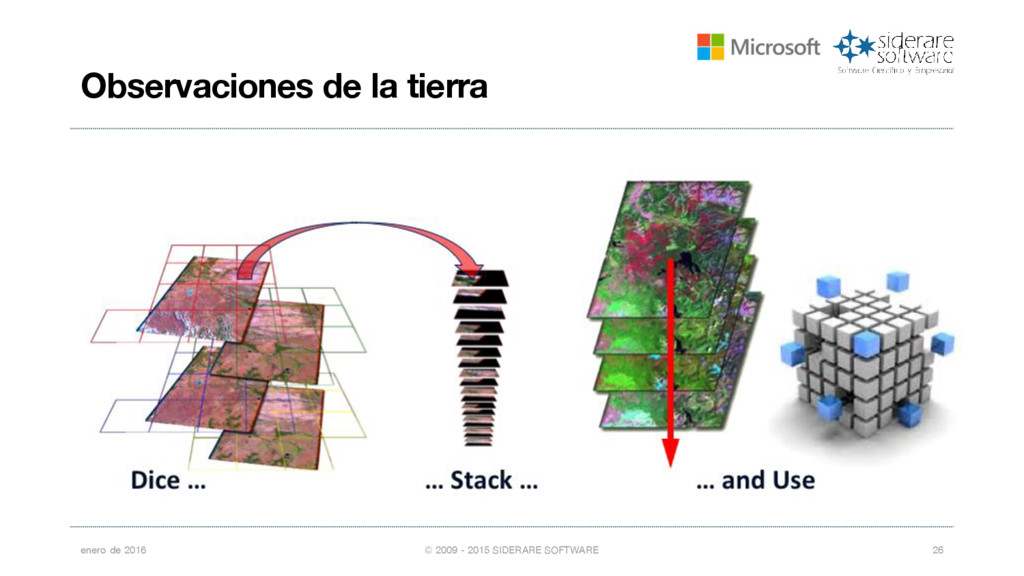{kind=link}
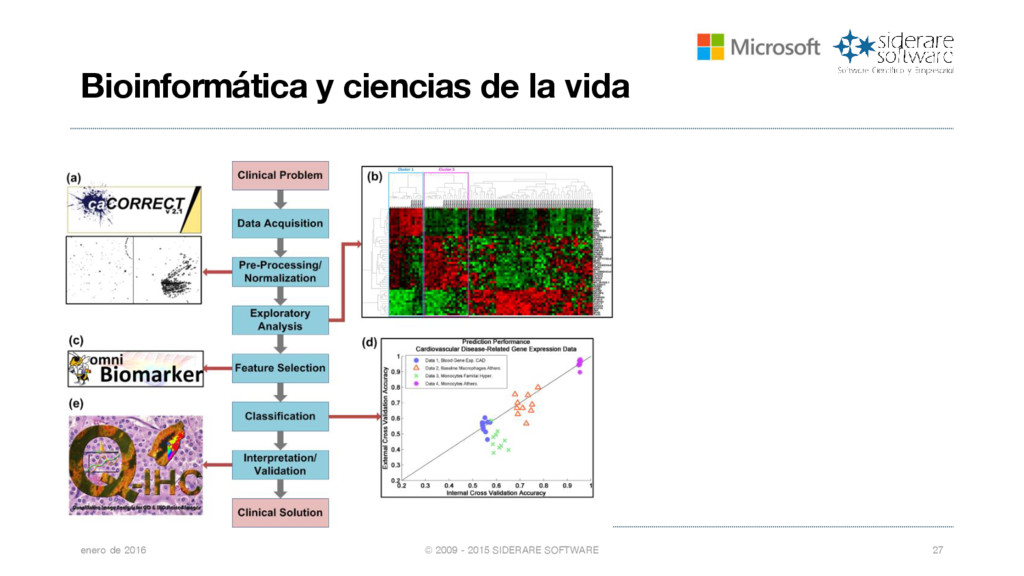{kind=link}
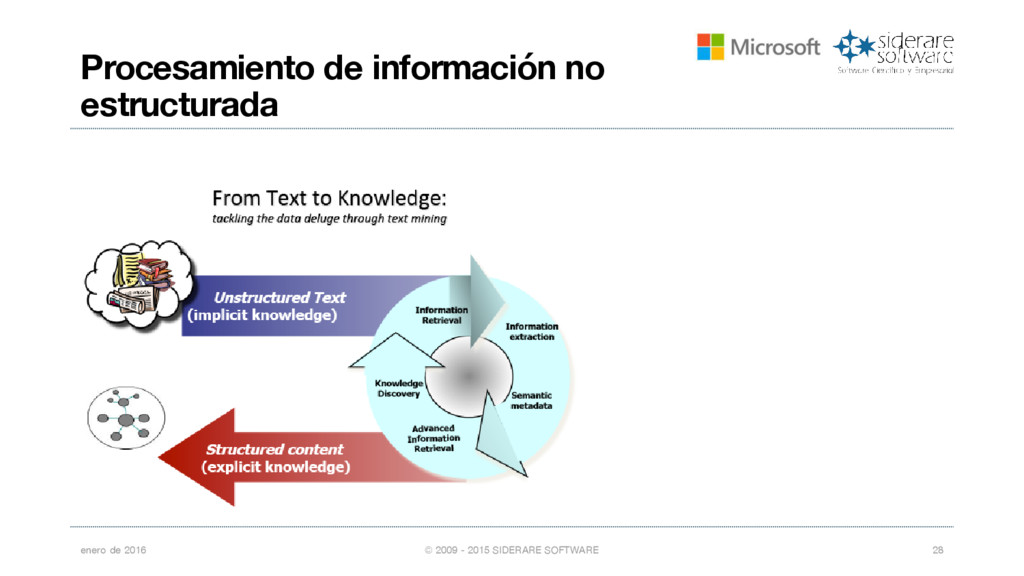{kind=link}
{kind=link}
{kind=link}
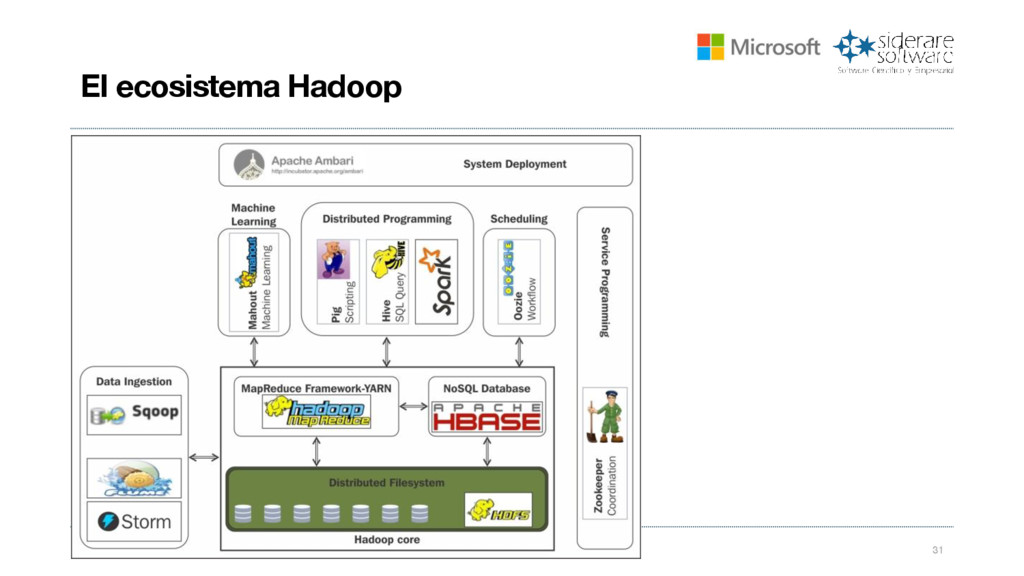{kind=link}
{kind=link}
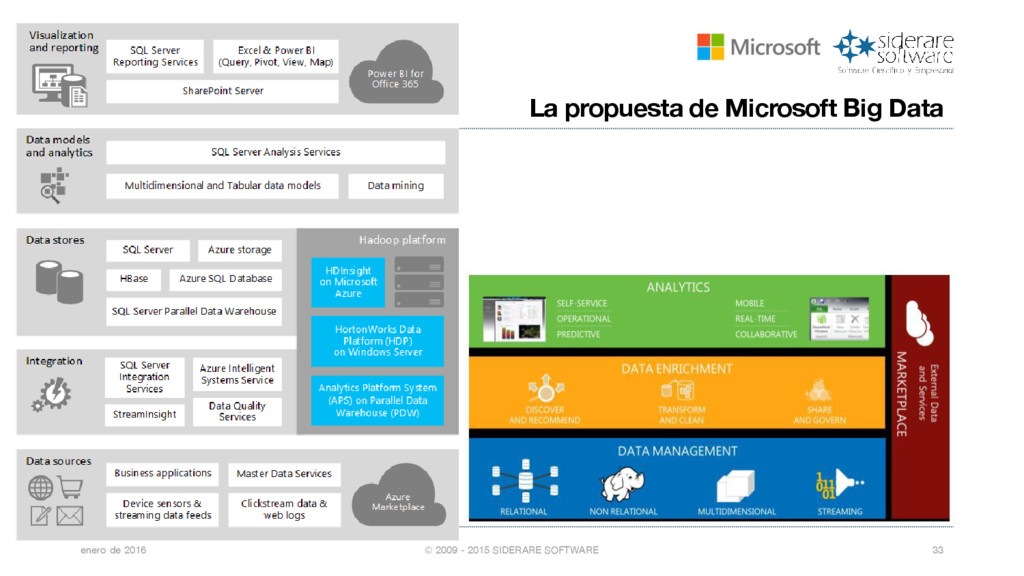{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}