Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
SSII2026 [OS1-1] 機械学習のための計算基盤の開発
Search
画像センシングシンポジウム
PRO
June 09, 2026
380
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
SSII2026 [OS1-1] 機械学習のための計算基盤の開発
画像センシングシンポジウム
PRO
June 09, 2026
More Decks by 画像センシングシンポジウム
See All by 画像センシングシンポジウム
SSII2026 [SS1] 作業動画理解 〜基盤モデル時代の応用と課題〜
ssii
PRO
0
690
SSII2026 [SS2] CADにおけるAI分野の動向と製造業 への実適⽤
ssii
PRO
1
1.3k
SSII2026 [TS2] 日本古典文化とAI ~ データセットからアプリケーションまで~
ssii
PRO
0
490
SSII2026 [PT1] アクセラレーテッド・コンピューティングが切り拓く知能の最前線 ~生成AIからエージェンティックAI、そしてフィジカルAIへの進化~
ssii
PRO
0
630
SSII2026 [PT2] 記号創発ロボティクスとフィジカルAIの展開 〜集合的予測符号化が繋ぐ言語と身体の時空間階層性〜
ssii
PRO
0
660
SSII2026 [OS1] 計算機インフラどうしてる?
ssii
PRO
0
380
SSII2026 [OS1-2] 学術クラウド基盤mdx IIの 設計と運用
ssii
PRO
0
400
SSII2026 [OS1-3] 実験室自動化を目指した 計算機との試行錯誤
ssii
PRO
0
350
SSII2026 [OS2] 産業界における生成AIの利活用
ssii
PRO
0
650
Featured
See All Featured
Navigating Weather and Climate Data
rabernat
0
360
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
800
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
Heart Work Chapter 1 - Part 1
lfama
PRO
8
36k
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
590
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
Between Models and Reality
mayunak
4
370
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
Being A Developer After 40
akosma
91
590k
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.7k
Transcript
SSII 2026 オーガナイズドセッション1 計算機インフラどうしてる? 機械学習のための計算基盤の開発 2026.6.10 上野 裕一郎 (株式会社 Preferred
Networks)
2 • むかし: 東工大 横田理央研究室 修士課程 ◦ 「多数のGPUで深層学習を効率的にやる」 ◦ 集団通信アルゴリズムの開発・評価とか
◦ グランドチャレンジ(2048GPUs学習)とか • 2021/04~: Preferred Networks に新卒入社 ◦ Kubernetes クラスタの開発 & 運用 ◦ GPU, MN-Core, NIC 周りなどに興味 ◦ 分散キャッシュシステムの開発 自己紹介: 上野 裕一郎 (Yuichiro Ueno / @y1r)
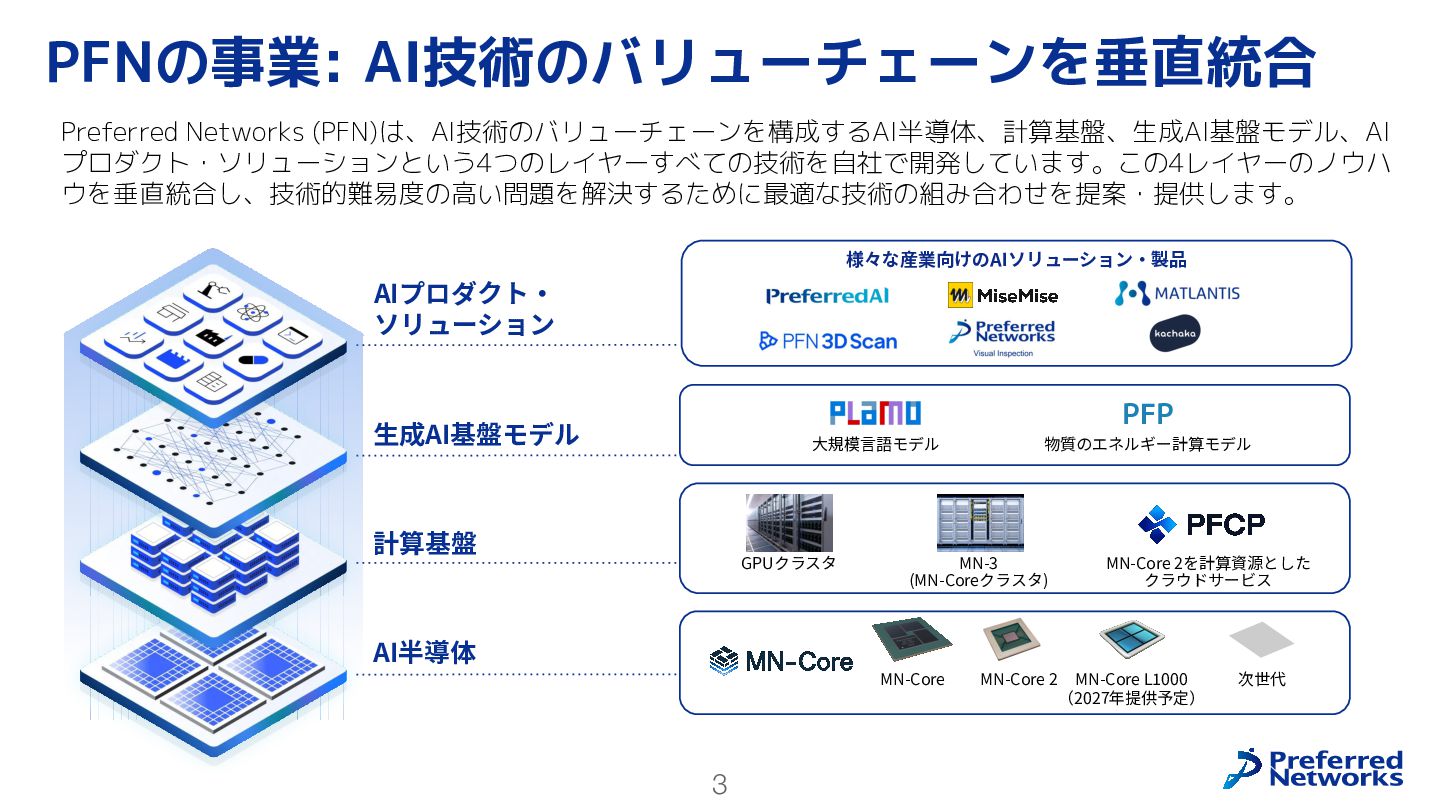
3 PFNの事業: AI技術のバリューチェーンを垂直統合 AIプロダクト‧ ソリューション 計算基盤 AI半導体 ⽣成AI基盤モデル MN-Core MN-Core
2 GPUクラスタ MN-3 (MN-Coreクラスタ) ⼤規模⾔語モデル 次世代 MN-Core 2を計算資源とした クラウドサービス 物質のエネルギー計算モデル PFP MN-Core L1000 (2027年提供予定) Preferred Networks (PFN)は、AI技術のバリューチェーンを構成するAI半導体、計算基盤、生成AI基盤モデル、AI プロダクト・ソリューションという4つのレイヤーすべての技術を自社で開発しています。この4レイヤーのノウハ ウを垂直統合し、技術的難易度の高い問題を解決するために最適な技術の組み合わせを提案・提供します。 様々な産業向けのAIソリューション‧製品
4 • 計算機が1台、利用者が1人であれば、なにも考えることはない ◦ 複数の計算機を使いたい、複数の利用者で使いたい = 「計算基盤」 • 「計算基盤」には何が必要か? ◦
計算機やその内部のリソースを一時的に借りる ▪ スケジューリング や アイソレーション が必要 ◦ どの計算機でも同じように仕事ができる ▪ データをどうやり取りするか ▪ 計算機をどう抽象化するか、どう「個性なく」設定するか ◦ 複数計算機をうまく組み合わせて仕事をしたい ▪ ネットワーク・インターコネクトも考慮が必要 計算基盤・計算機インフラに必要なこと
5 • 機械学習のための計算基盤の開発 に取り組んできました! ◦ 小規模なケース ▪ 大学研究室のインフラ開発 ▪ 🖥:
スパコン的な考え方 • Slurm, 共有ファイルシステム, … ◦ 大規模なケース ▪ PFN 社内向け計算基盤の開発 ▪ Preferred Computing Platform (PFCP) の開発 ▪ ☁: クラウド・Webサービス的な考え方 • Kubernetes, コンテナイメージ, … 計算機インフラどうしてる? これらを比較しながら「計算機インフラをどうしてきたか」を紹介します
6 🖥 小規模なケース 🖥 「スパコン的な考え方」のインフラ
7 東工大 横田理央研究室 の ひなどりクラスタ • 目的 ◦ スーパーコンピュータなどでは取り入れられていない最新の環境を いち早く導入して研究を行う
• 要件 ◦ 管理に時間をかけない(本業の研究が優先) ◦ スパコンとひなどりクラスタで同じコード・実験が動く 1Uサーバ (2 GPUs 搭載) 4Uサーバ (8 GPUs 搭載) Grafana / Prometheus による監視基盤
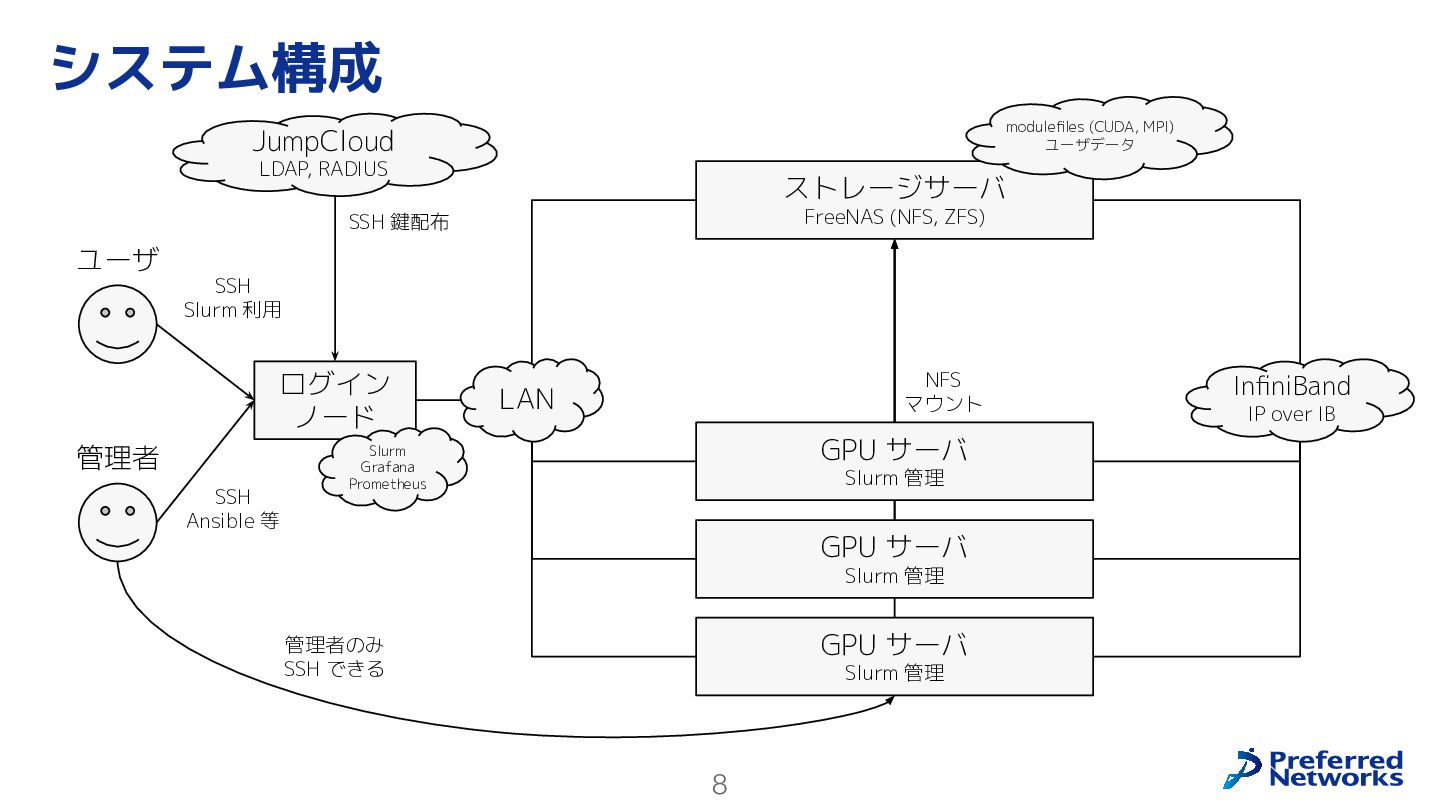
8 システム構成 ユーザ 管理者 ログイン ノード LAN ストレージサーバ FreeNAS (NFS,
ZFS) JumpCloud LDAP, RADIUS SSH 鍵配布 SSH Slurm 利用 SSH Ansible 等 InfiniBand IP over IB modulefiles (CUDA, MPI) ユーザデータ Slurm Grafana Prometheus 管理者のみ SSH できる NFS マウント GPU サーバ Slurm 管理 GPU サーバ Slurm 管理 GPU サーバ Slurm 管理
9 ☁ 大規模なケース ☁ 「クラウド・Webサービス的な考え方」のインフラ
10 • PFN が構築、運用する AI・ML ワークロード向けのクラウドサービス ◦ https://pfcomputing.com/ ◦ ユーザガイド:
https://docs.pfcomputing.com/ • PFN のエンジニア・リサーチャが使用する環境と同じものを提供 ◦ これまで社内向けに計算基盤を開発運用してきた経験を元に開発 • 強力な計算ボードと高速なネットワーク ◦ 独自開発したアクセラレータ MN-Core™ シリーズを提供 ◦ 深層学習に最適化された高速なネットワークで相互に接続 誰もが MN-Core™ シリーズを利用できる AI クラウドサービス Preferred Computing Platform (PFCP)
11 • 実験も学習も推論も ◦ 実験環境としてマネージドな JupyterLab を提供 ◦ 学習だけでなく、推論サーバの運用まで幅広いワークロードをサポート •
オープンソースを採用 ◦ コンテナ実行環境にKubernetes を採用 (Linux Foundation / CNCF) ◦ AI・ML ワークロード向けに独自に拡張 • リソース使用状況の可視化 ◦ ワークロード状態を観測するためのモニタリングサービスも付随 誰もが MN-Core™ シリーズを利用できる AI クラウドサービス Preferred Computing Platform (PFCP) 管理コンソール ワークロード・計算資源監視 対話型実験環境 分散学習・LLM 推論
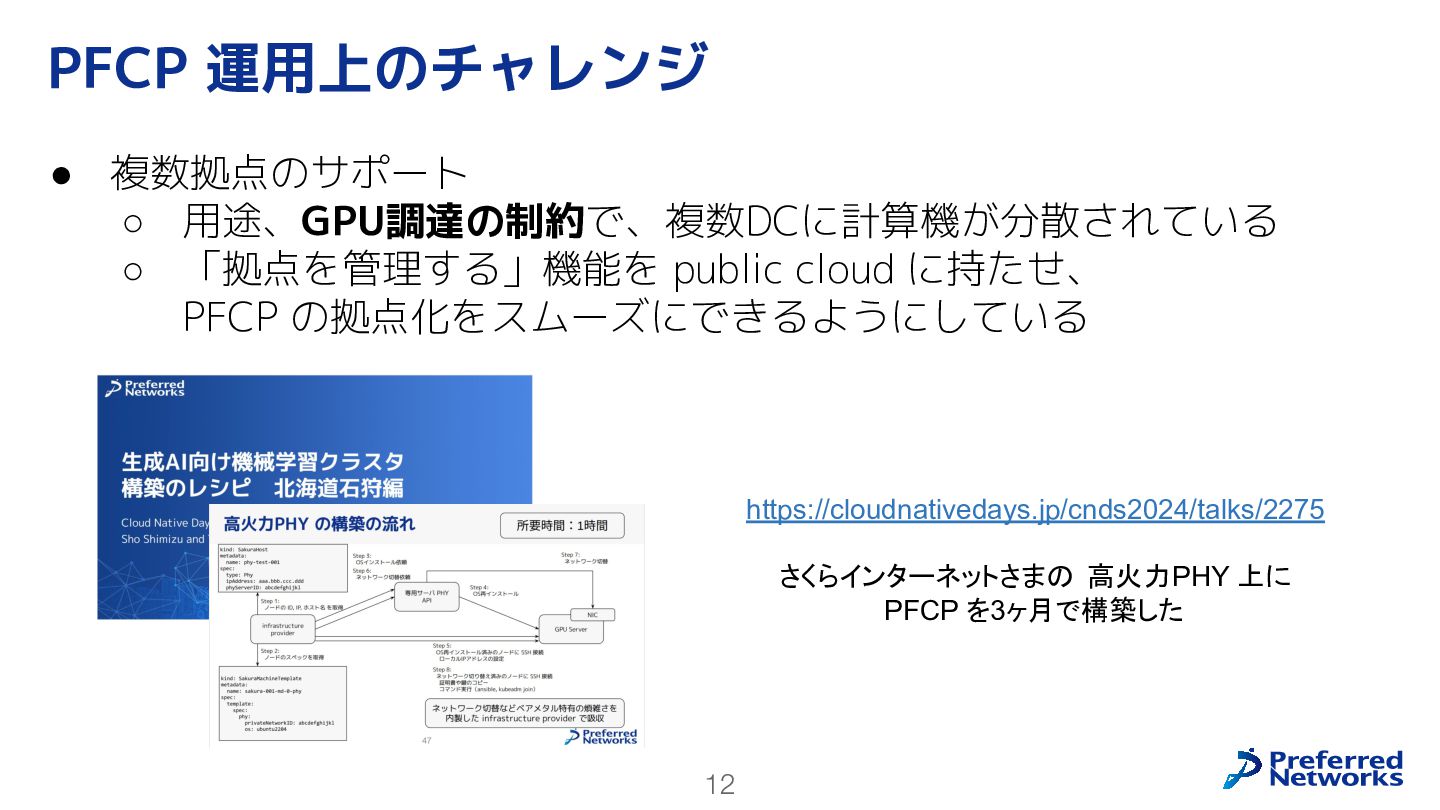
12 • 複数拠点のサポート ◦ 用途、GPU調達の制約で、複数DCに計算機が分散されている ◦ 「拠点を管理する」機能を public cloud に持たせ、
PFCP の拠点化をスムーズにできるようにしている PFCP 運用上のチャレンジ https://cloudnativedays.jp/cnds2024/talks/2275 さくらインターネットさまの 高火力PHY 上に PFCP を3ヶ月で構築した
13 • マルチテナントのサポート ◦ 貴重な計算リソースを無駄なく・効率よく利用するためには 同一の計算クラスタで複数テナントをサポートすることが重要 ▪ どう Kubernetes の中でアイソレーションをするかが難しい
PFCP 運用上のチャレンジ https://speakerdeck.com/pfn/20251014-multi-te nant-kubernetes-container-platform どのようにしてマルチテナントを Kubernetes 上で実現したか
14 比較: 🖥 と ☁ の違い
15 🖥小規模ケース と ☁大規模ケース の比較 • ユーザの利用形態 ◦ どうやってジョブを投入するのか?どう記述するのか? ◦
共有ファイルシステムあったほうがいい? • ジョブスケジューラ ◦ Slurm と Kubernetes はどっちが便利? ◦ Kubernetes だとさらに何ができる?
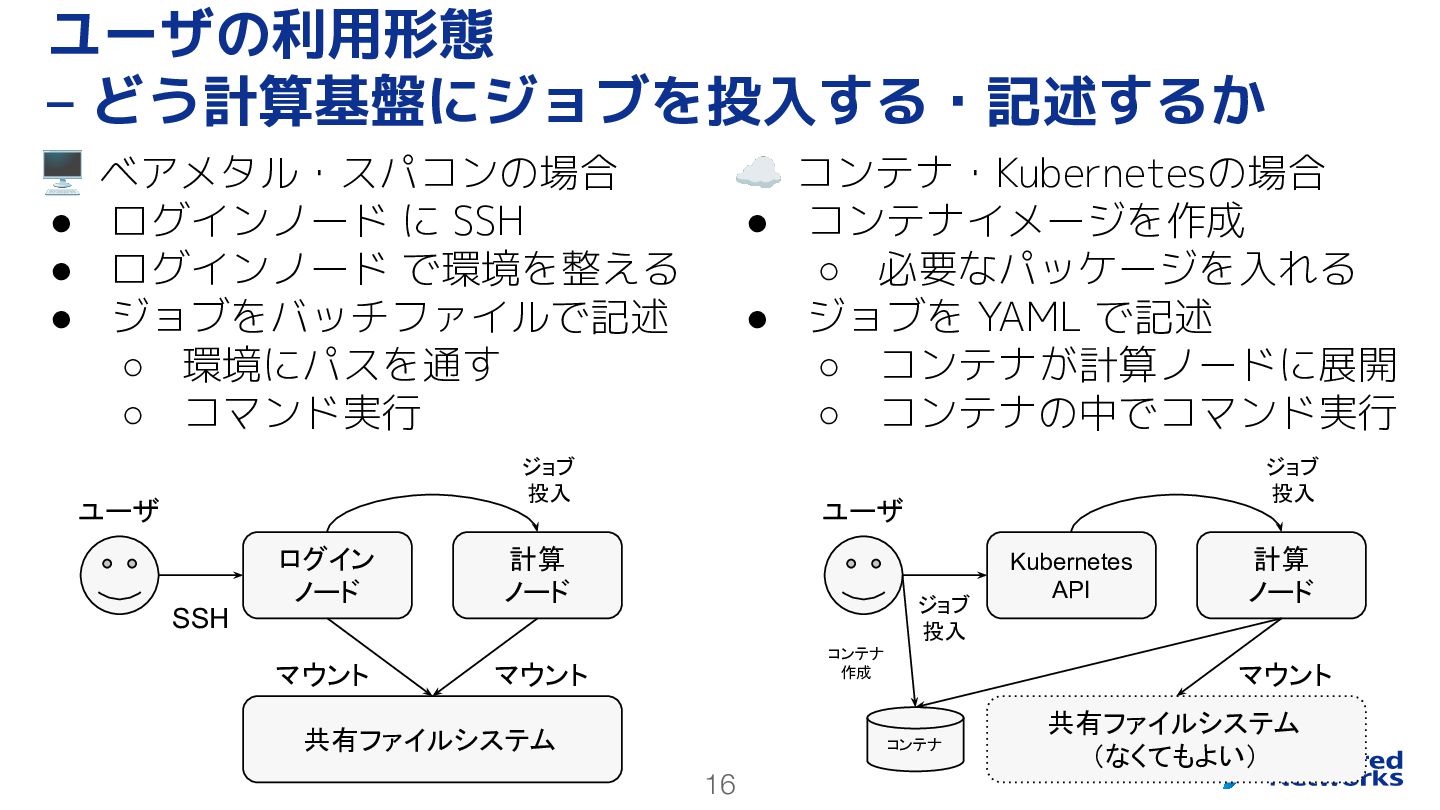
16 🖥 ベアメタル・スパコンの場合 • ログインノード に SSH • ログインノード で環境を整える
• ジョブをバッチファイルで記述 ◦ 環境にパスを通す ◦ コマンド実行 ユーザの利用形態 – どう計算基盤にジョブを投入する・記述するか ☁ コンテナ・Kubernetesの場合 • コンテナイメージを作成 ◦ 必要なパッケージを入れる • ジョブを YAML で記述 ◦ コンテナが計算ノードに展開 ◦ コンテナの中でコマンド実行 共有ファイルシステム ログイン ノード 計算 ノード SSH ジョブ 投入 マウント マウント 共有ファイルシステム (なくてもよい) Kubernetes API 計算 ノード ジョブ 投入 ジョブ 投入 マウント コンテナ コンテナ 作成 ユーザ ユーザ
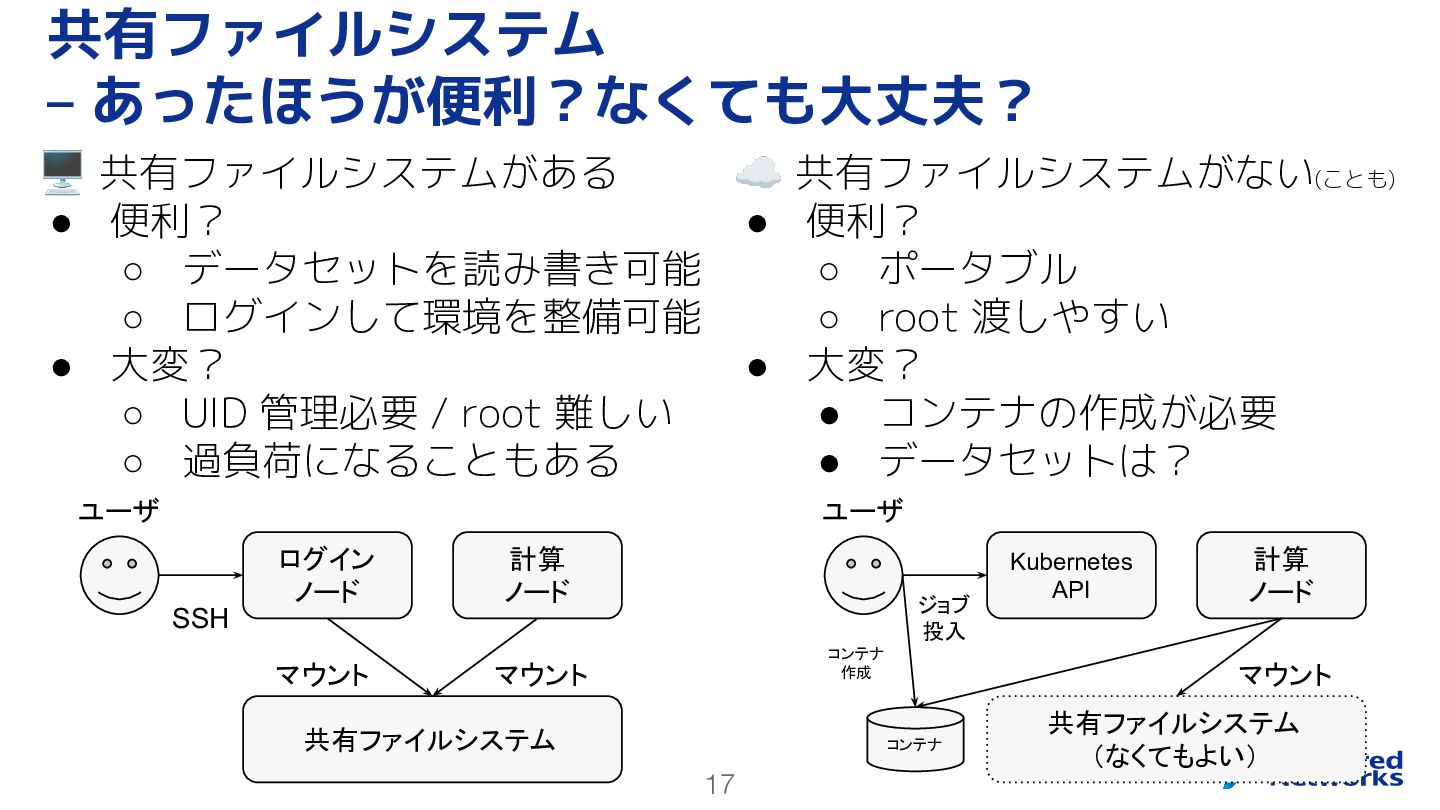
17 🖥 共有ファイルシステムがある • 便利? ◦ データセットを読み書き可能 ◦ ログインして環境を整備可能 •
大変? ◦ UID 管理必要 / root 難しい ◦ 過負荷になることもある 共有ファイルシステム – あったほうが便利?なくても大丈夫? ☁ 共有ファイルシステムがない(ことも) • 便利? ◦ ポータブル ◦ root 渡しやすい • 大変? • コンテナの作成が必要 • データセットは? 共有ファイルシステム ログイン ノード 計算 ノード SSH マウント マウント 共有ファイルシステム (なくてもよい) Kubernetes API 計算 ノード ジョブ 投入 マウント コンテナ コンテナ 作成 ユーザ ユーザ
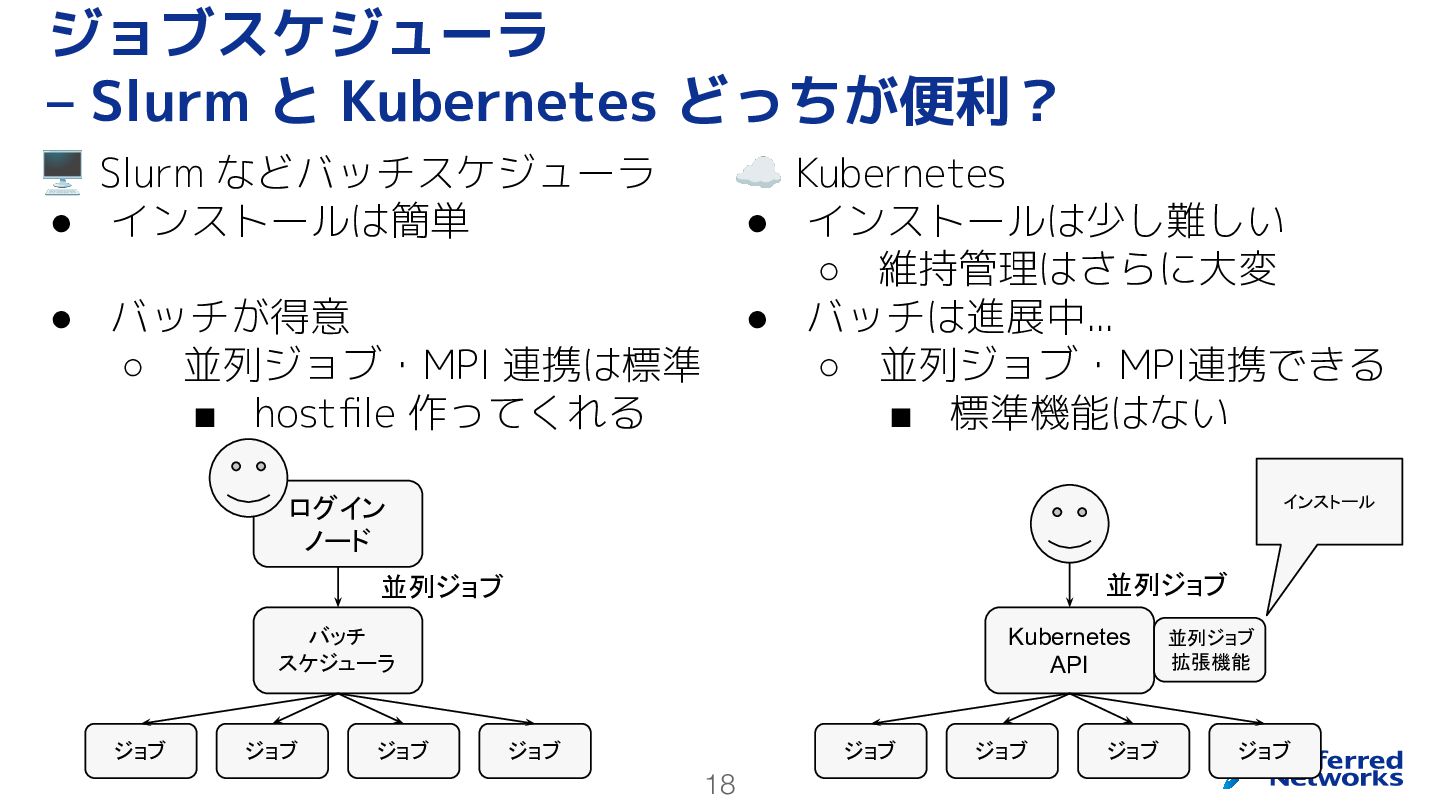
18 🖥 Slurm などバッチスケジューラ • インストールは簡単 • バッチが得意 ◦ 並列ジョブ・MPI
連携は標準 ▪ hostfile 作ってくれる ジョブスケジューラ – Slurm と Kubernetes どっちが便利? ☁ Kubernetes • インストールは少し難しい ◦ 維持管理はさらに大変 • バッチは進展中... ◦ 並列ジョブ・MPI連携できる ▪ 標準機能はない ログイン ノード バッチ スケジューラ 並列ジョブ ジョブ ジョブ ジョブ ジョブ Kubernetes API ジョブ ジョブ ジョブ ジョブ 並列ジョブ 並列ジョブ 拡張機能 インストール
19 • Custom Resource と Operator パターン ◦ CR: Kubernetes
の中で定義するリソースの型を追加する ◦ Operator: リソースをどう処理するかを定義する Kubernetes のいいところ(1) – 機能拡張しやすい 並列ジョブの Custom Resource • 普通のジョブ型の内容 ◦ イメージ名, コマンド, ... • 並列数 ◦ = 何ジョブ作るか? • 1ジョブあたりの並列数 ◦ = hostfile の slot数 ? 並列ジョブの Operator • 並列ジョブ型を見つけたら: ◦ 並列数だけ複製してジョブ作成 ◦ hostfile を生成してマウント • 並列ジョブ型が削除されたら ◦ 子のジョブを削除する 例:並列ジョブ拡張機能
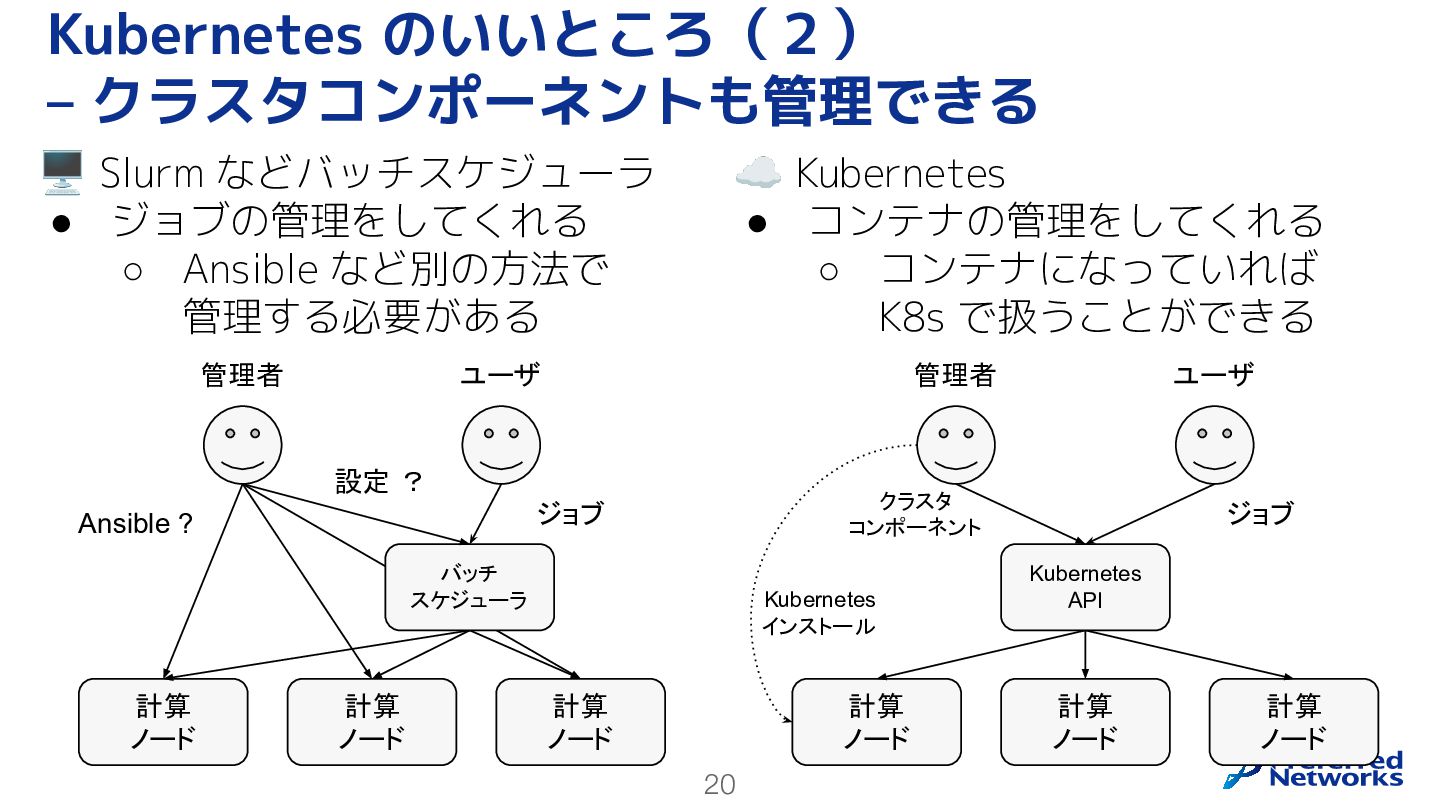
20 Kubernetes のいいところ(2) – クラスタコンポーネントも管理できる 🖥 Slurm などバッチスケジューラ • ジョブの管理をしてくれる
◦ Ansible など別の方法で 管理する必要がある ☁ Kubernetes • コンテナの管理をしてくれる ◦ コンテナになっていれば K8s で扱うことができる Ansible ? 管理者 ユーザ ジョブ 計算 ノード 計算 ノード 計算 ノード バッチ スケジューラ 設定 ? 管理者 ユーザ ジョブ 計算 ノード 計算 ノード 計算 ノード Kubernetes API クラスタ コンポーネント Kubernetes インストール
21 • バッチスケジューラは、バッチ処理のために開発された ◦ 並列バッチ、多数のバッチなどが得意 ▪ FIFO、バックフィルスケジューリングなどの強み • Kubernetes は、アプリケーションをデプロイするために開発された
◦ 長時間走る推論ワークロード ▪ 終了時間を決めない、走り続けるワークロードのサポート ◦ クラスタ外へのサービス公開・ロードバランシング ▪ ビルトインでサポート ◦ サービスディスカバリ ▪ DNS で、別のコンテナ(Pod)の IP を発見 Kubernetes のいいところ(3) – 推論ワークロード・サービス公開もサポート
22 まとめ
23 まとめ: 機械学習に向いた計算基盤 とは? • どのような計算基盤が良いかは目的にもよるが: ◦ 🖥: 小規模に始めてみたい ▪
Slurm + NFS サーバだけでも始められる ◦ ☁: サービスや色々なユースケースをサポートしたい ▪ Kubernetes コミュニティのバッチサポートは手厚くなってきた ▪ 推論などアプリケーションのデプロイにはやっぱり強い • やっぱり安定した基盤でなんでもやりたい・お手軽にやりたい ◦ PFCP や大手クラウドなど、色々支援するサービスはあるので うまく活用してください! // お問い合わせください!
Making the real world computable
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}