classification and information extraction tasks on clinical notes (from EHR) 結論: ① プロンプトに対してロバストではない ② 医療特化モデルのパフォーマンスが概して Generalなモデルより悪かった ③ プロンプトの変更が出力の Fairnessに影響してし まう https://aclanthology.org/2024.bionlp-1.5/
Longitudinal Electronic Health Record Data https://arxiv.org/pdf/2402.01713 研究の問い • RQ1 (Data-Level) What constitutes an effective EHR data prompt for LLMs? • RQ2 (Task-Level) Are LLMs capable of diverse clinical prediction tasks with various time spans? • RQ3 (Model-Level) What are the zero-shot performance differences of various LLMs in handling EHR data, and can they outperform traditional machine learning models in few-shot settings?
y —--------------------------------------------------------------------→ θ と y の関係 F xは観測できないので yから推定したい {yi,θi}という学習データは入手できない 部分的に得た{yi,xi}からKを学習する方針
Another Leap Forward in Board Examination Performance - Comparative diagnostic accuracy of GPT-4o and LLaMA 3-70b: Proprietary vs. open-source large language models in radiology (Clinical Imaging) - Best Practices for Large Language Models in Radiology Vision(レントゲン画像)も - Tanno et al. (Nature Medicine, 2024) - Rad-Phi3 - BenchX (NeurIPS 2024) - provide 9 MedVLP baselines - VLScore (NeurIPS 2024) - 医療的な観点を加味した評価スコア . ただのテキスト類似性では不十分であることを指摘 . - Multi-modal large language models in radiology: principles, applications, and potential (Abdominial Radiology) - radiologistの業務の多くをサポートすることが可能 . 一方で3D medical imagingにはまだ課題. - MAIRA-Seg - LLM-RG4 - Radiology Report Generation via Multi-objective Preference Optimization 総説・警鐘 Radiologyが熱い オープンソースのデータが豊富なためか?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
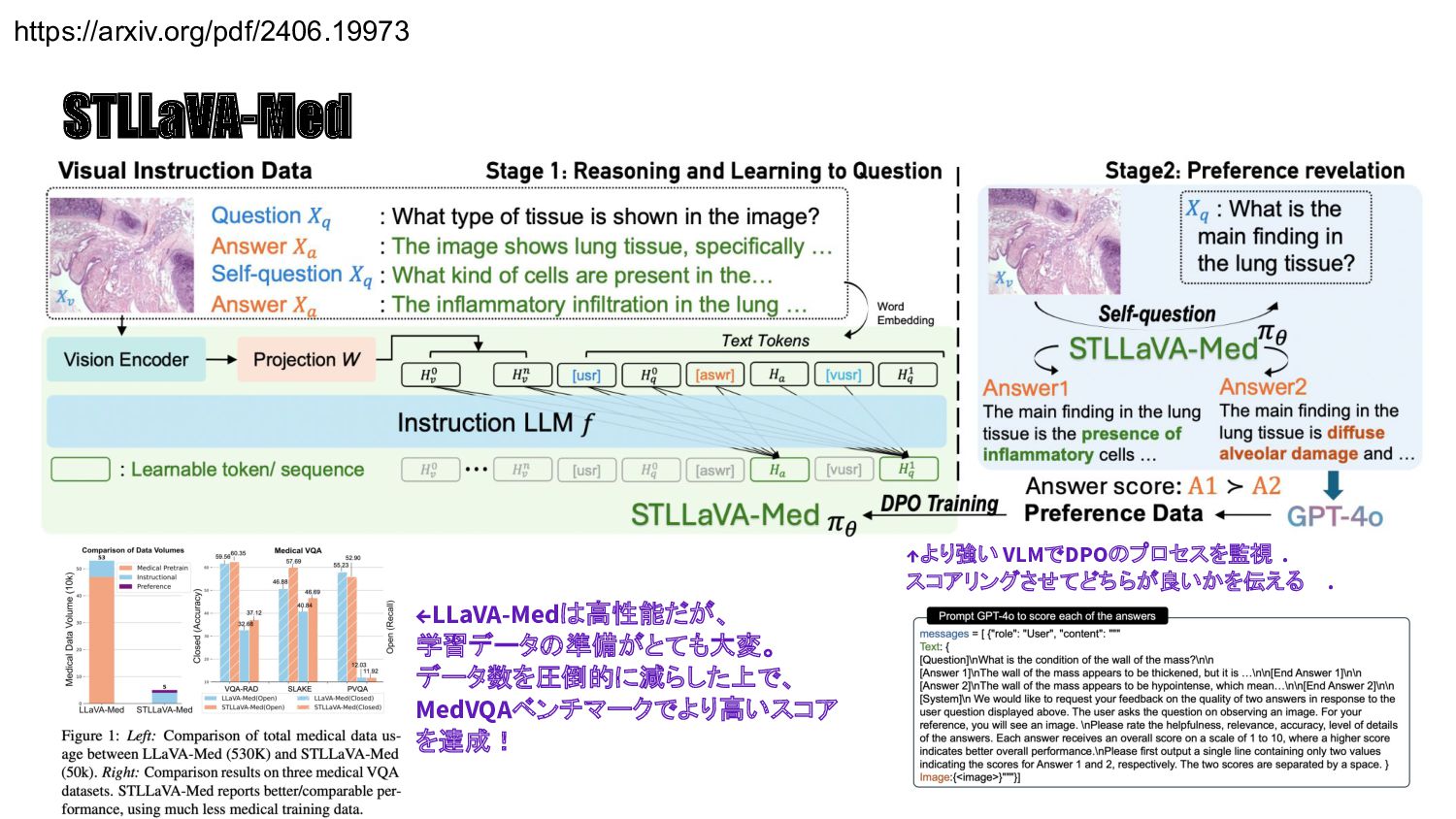{kind=link}
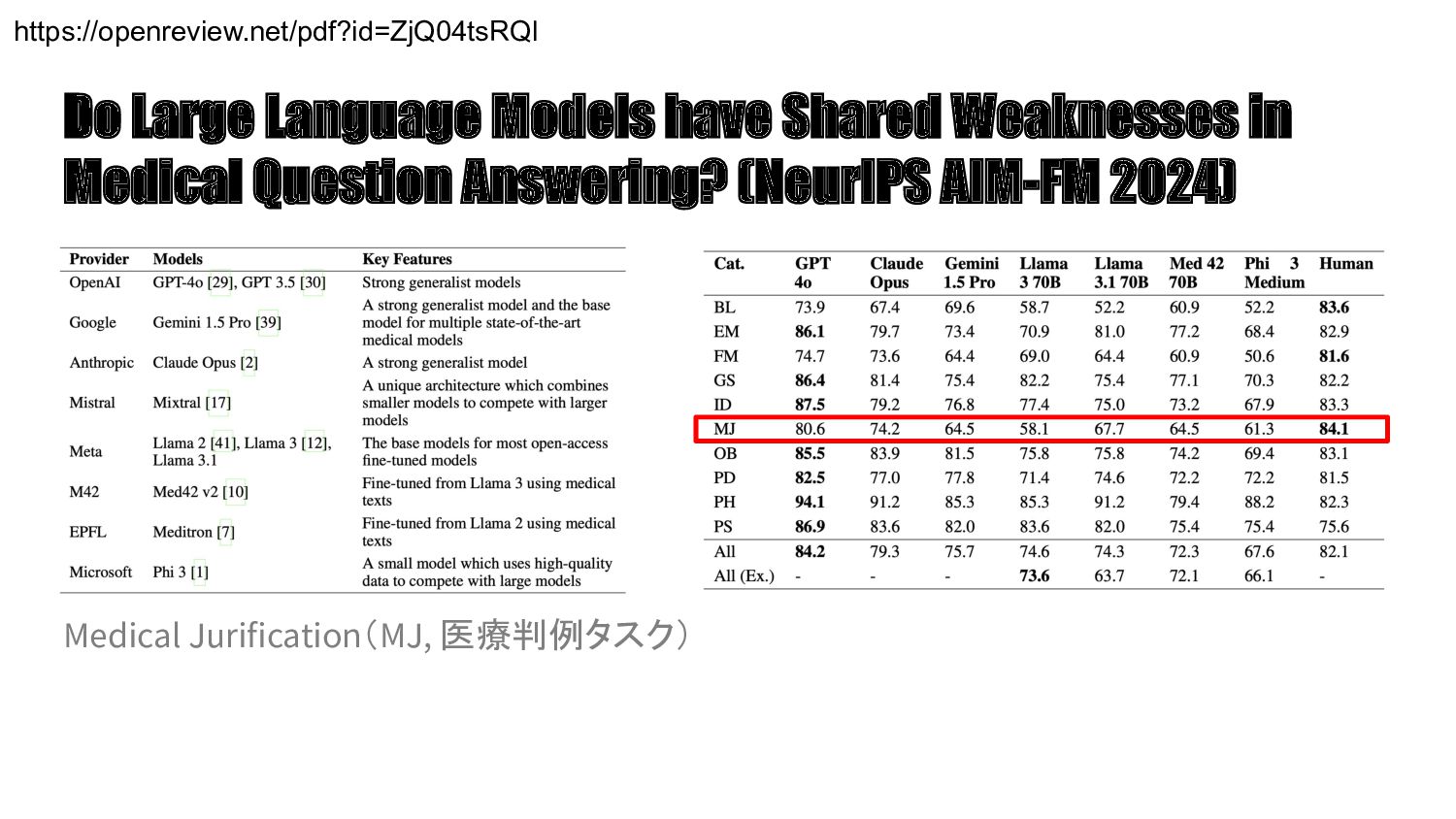{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
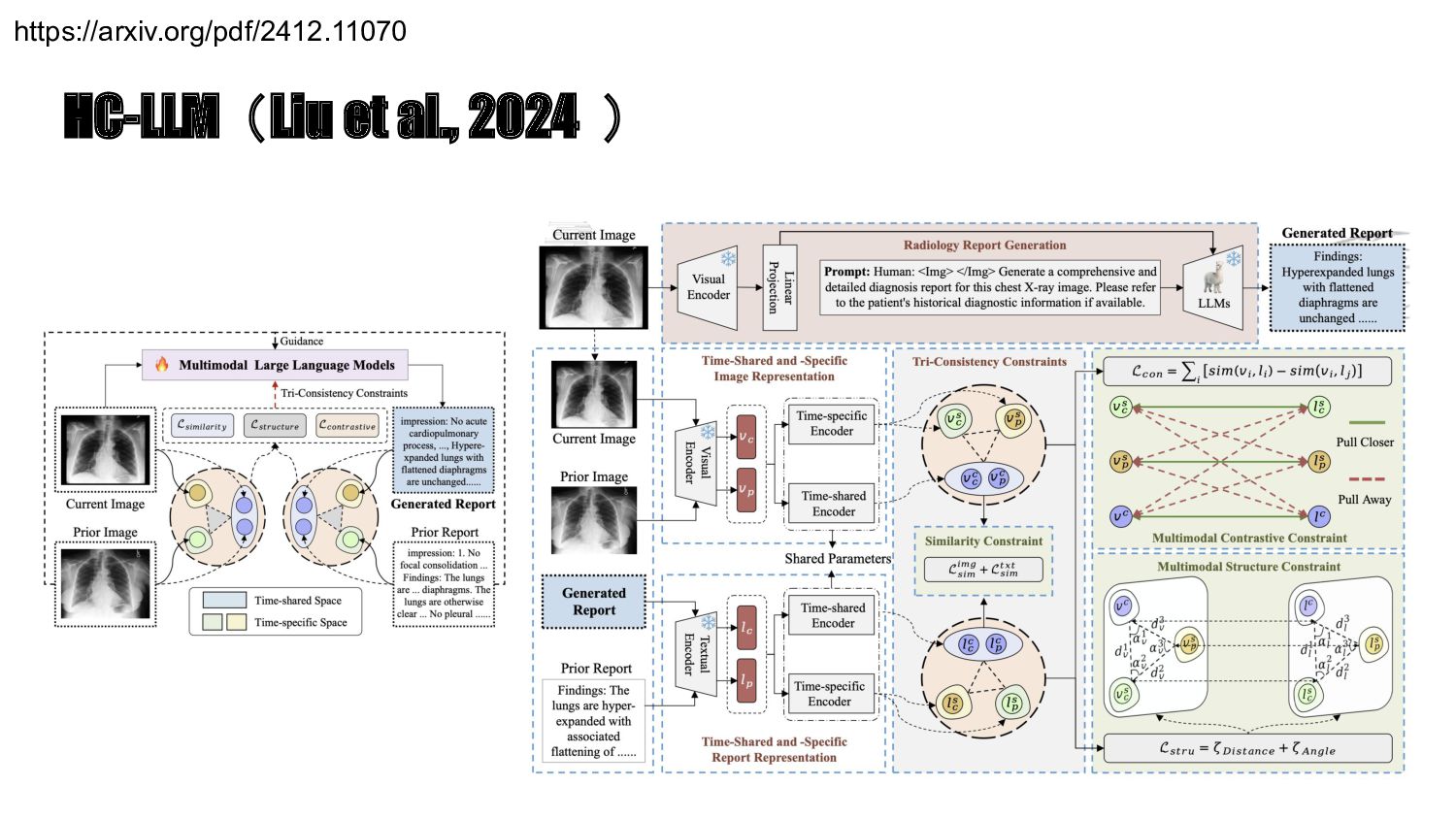{kind=link}
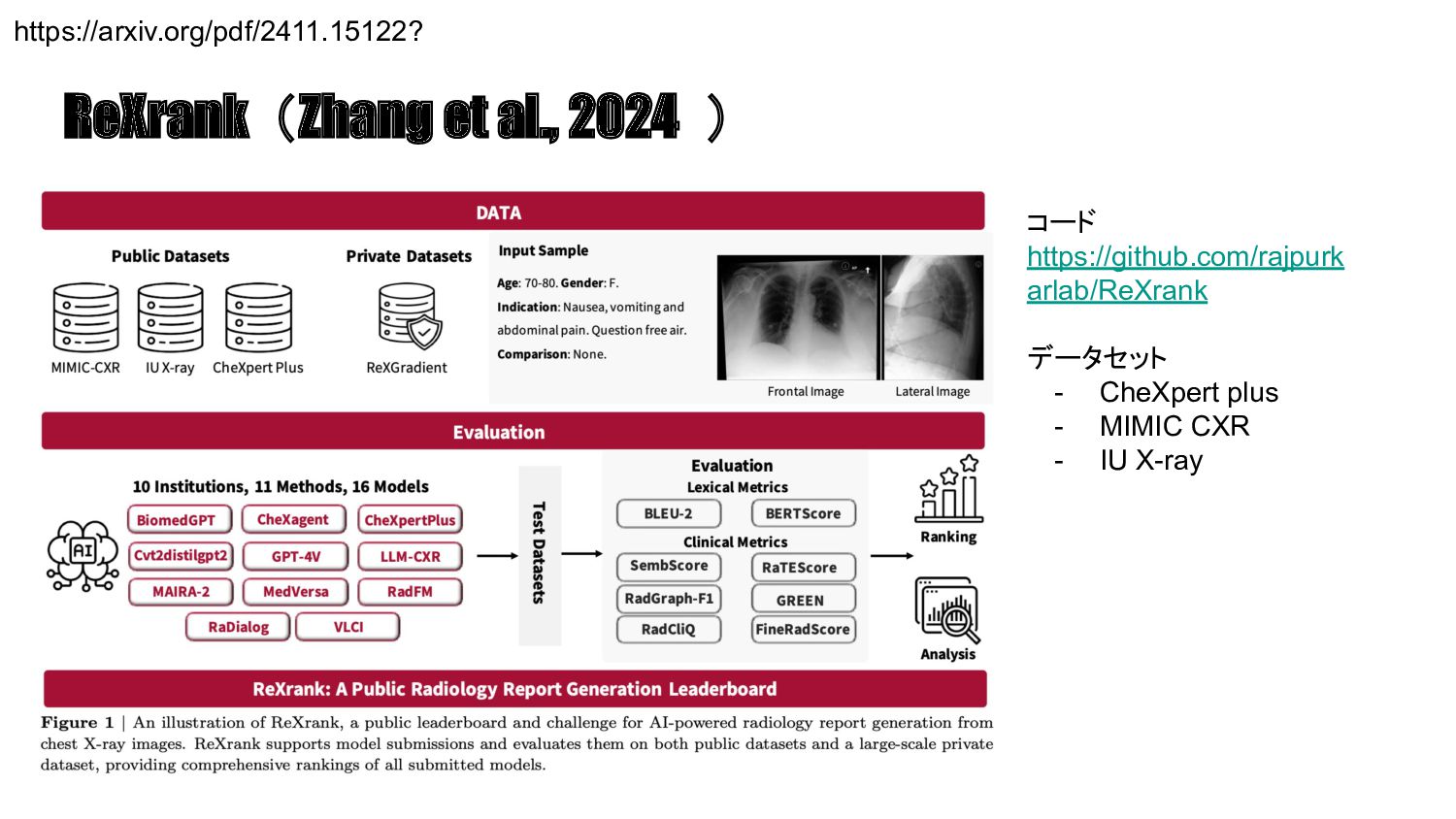{kind=link}
{kind=link}
{kind=link}