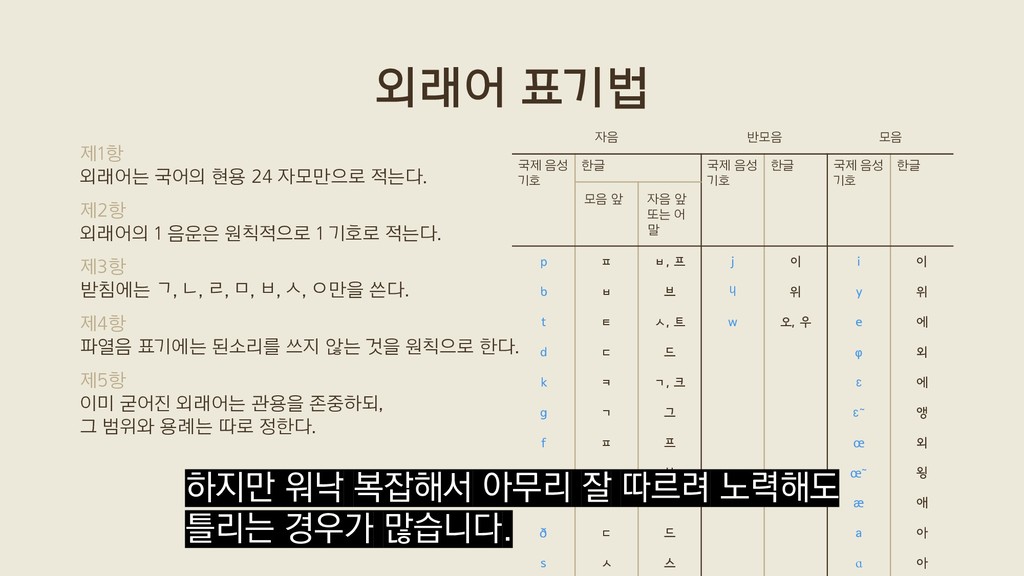
음운은 원칙적으로 1 기호로 적는다. 제3항 받침에는 ㄱ, ㄴ, ㄹ, ㅁ, ㅂ, ㅅ, ㅇ만을 쓴다. 제4항 파열음 표기에는 된소리를 쓰지 않는 것을 원칙으로 한다. 제5항 이미 굳어진 외래어는 관용을 존중하되, 그 범위와 용례는 따로 정한다. 외래어 표기법 자음 반모음 모음 국제 음성 기호 한글 국제 음성 기호 한글 국제 음성 기호 한글 모음 앞 자음 앞 또는 어 말 p ㅍ ㅂ, 프 j 이 i 이 b ㅂ 브 ɥ 위 y 위 t ㅌ ㅅ, 트 w 오, 우 e 에 d ㄷ 드 φ 외 k ㅋ ㄱ, 크 ɛ 에 g ㄱ 그 ɛ̃ 앵 f ㅍ 프 œ 외 v ㅂ 브 œ̃ 욍 θ ㅅ 스 æ 애 ð ㄷ 드 a 아 s ㅅ 스 ɑ 아
음운은 원칙적으로 1 기호로 적는다. 제3항 받침에는 ㄱ, ㄴ, ㄹ, ㅁ, ㅂ, ㅅ, ㅇ만을 쓴다. 제4항 파열음 표기에는 된소리를 쓰지 않는 것을 원칙으로 한다. 제5항 이미 굳어진 외래어는 관용을 존중하되, 그 범위와 용례는 따로 정한다. 외래어 표기법 자음 반모음 모음 국제 음성 기호 한글 국제 음성 기호 한글 국제 음성 기호 한글 모음 앞 자음 앞 또는 어 말 p ㅍ ㅂ, 프 j 이 i 이 b ㅂ 브 ɥ 위 y 위 t ㅌ ㅅ, 트 w 오, 우 e 에 d ㄷ 드 φ 외 k ㅋ ㄱ, 크 ɛ 에 g ㄱ 그 ɛ̃ 앵 f ㅍ 프 œ 외 v ㅂ 브 œ̃ 욍 θ ㅅ 스 æ 애 ð ㄷ 드 a 아 s ㅅ 스 ɑ 아 외래어 표기법은 이런 규칙집으로 이뤄져 있습니다.
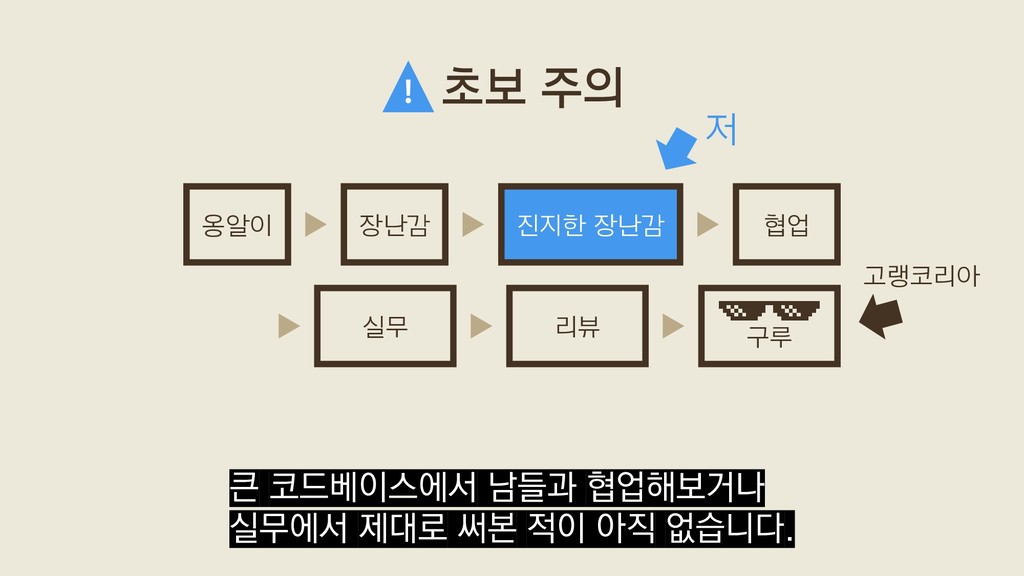
음운은 원칙적으로 1 기호로 적는다. 제3항 받침에는 ㄱ, ㄴ, ㄹ, ㅁ, ㅂ, ㅅ, ㅇ만을 쓴다. 제4항 파열음 표기에는 된소리를 쓰지 않는 것을 원칙으로 한다. 제5항 이미 굳어진 외래어는 관용을 존중하되, 그 범위와 용례는 따로 정한다. 외래어 표기법 자음 반모음 모음 국제 음성 기호 한글 국제 음성 기호 한글 국제 음성 기호 한글 모음 앞 자음 앞 또는 어 말 p ㅍ ㅂ, 프 j 이 i 이 b ㅂ 브 ɥ 위 y 위 t ㅌ ㅅ, 트 w 오, 우 e 에 d ㄷ 드 φ 외 k ㅋ ㄱ, 크 ɛ 에 g ㄱ 그 ɛ̃ 앵 f ㅍ 프 œ 외 v ㅂ 브 œ̃ 욍 θ ㅅ 스 æ 애 ð ㄷ 드 a 아 s ㅅ 스 ɑ 아 국립국어원 홈페이지에서 누구나 자유롭게 볼 수 있죠.
음운은 원칙적으로 1 기호로 적는다. 제3항 받침에는 ㄱ, ㄴ, ㄹ, ㅁ, ㅂ, ㅅ, ㅇ만을 쓴다. 제4항 파열음 표기에는 된소리를 쓰지 않는 것을 원칙으로 한다. 제5항 이미 굳어진 외래어는 관용을 존중하되, 그 범위와 용례는 따로 정한다. 외래어 표기법 자음 반모음 모음 국제 음성 기호 한글 국제 음성 기호 한글 국제 음성 기호 한글 모음 앞 자음 앞 또는 어 말 p ㅍ ㅂ, 프 j 이 i 이 b ㅂ 브 ɥ 위 y 위 t ㅌ ㅅ, 트 w 오, 우 e 에 d ㄷ 드 φ 외 k ㅋ ㄱ, 크 ɛ 에 g ㄱ 그 ɛ̃ 앵 f ㅍ 프 œ 외 v ㅂ 브 œ̃ 욍 θ ㅅ 스 æ 애 ð ㄷ 드 a 아 s ㅅ 스 ɑ 아 하지만 워낙 복잡해서 아무리 잘 따르려 노력해도 틀리는 경우가 많습니다.
아베라, 암살라 Amsale Aberra 1954(?1953)~ 에티오피아 여성 기업가·디자이너. 암살라(Amsale) 그룹 대표 겸 디자 인 총책임자. 유행을 좇지 않으면서 세련된 클래식 모던을 강조하는 디자인으로 유명함. • 아벨란제, 주앙 João Havelange 1916~ 국제축구연맹(FIFA) 회장(1974~1998). 브라질 인. • 그루벨, 루스 Ruth M. Grubel 1950~ 미국 교육가·선교사. 일본 간사이(關西)학원 원장(2007. 4.~ ).
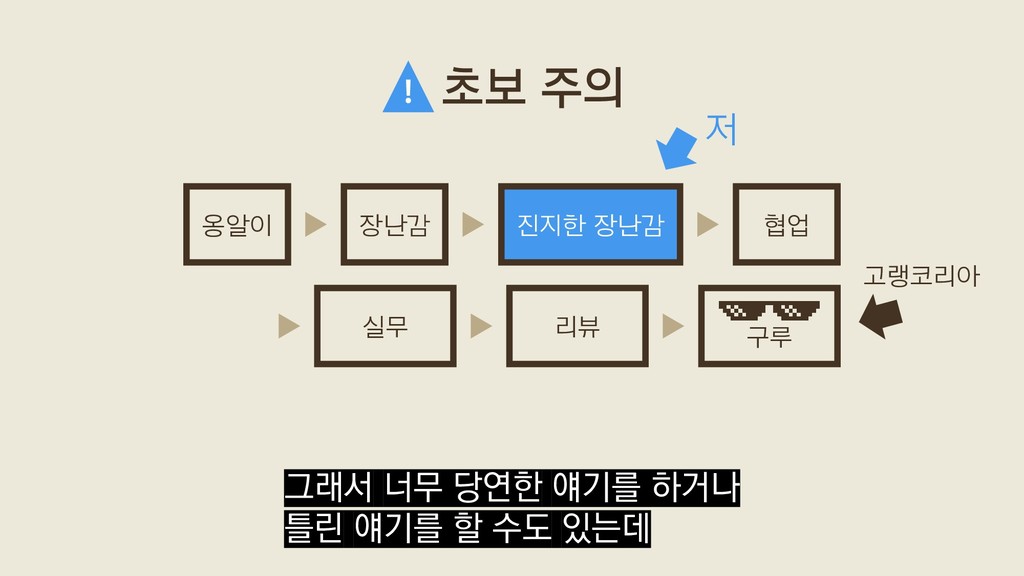
아베라, 암살라 Amsale Aberra 1954(?1953)~ 에티오피아 여성 기업가·디자이너. 암살라(Amsale) 그룹 대표 겸 디자 인 총책임자. 유행을 좇지 않으면서 세련된 클래식 모던을 강조하는 디자인으로 유명함. • 아벨란제, 주앙 João Havelange 1916~ 국제축구연맹(FIFA) 회장(1974~1998). 브라질 인. • 그루벨, 루스 Ruth M. Grubel 1950~ 미국 교육가·선교사. 일본 간사이(關西)학원 원장(2007. 4.~ ). 이건 외래어 심의위가 발표한 표기 심의 결정안 중 하나인데
아베라, 암살라 Amsale Aberra 1954(?1953)~ 에티오피아 여성 기업가·디자이너. 암살라(Amsale) 그룹 대표 겸 디자 인 총책임자. 유행을 좇지 않으면서 세련된 클래식 모던을 강조하는 디자인으로 유명함. • 아벨란제, 주앙 João Havelange 1916~ 국제축구연맹(FIFA) 회장(1974~1998). 브라질 인. • 그루벨, 루스 Ruth M. Grubel 1950~ 미국 교육가·선교사. 일본 간사이(關西)학원 원장(2007. 4.~ ). 아버라, 암살러 그루블 심의위에서도 드물게 틀리는 경우가 있습니다.
아베라, 암살라 Amsale Aberra 1954(?1953)~ 에티오피아 여성 기업가·디자이너. 암살라(Amsale) 그룹 대표 겸 디자 인 총책임자. 유행을 좇지 않으면서 세련된 클래식 모던을 강조하는 디자인으로 유명함. • 아벨란제, 주앙 João Havelange 1916~ 국제축구연맹(FIFA) 회장(1974~1998). 브라질 인. • 그루벨, 루스 Ruth M. Grubel 1950~ 미국 교육가·선교사. 일본 간사이(關西)학원 원장(2007. 4.~ ). 아버라, 암살러 그루블 원 단어의 발음을 잘못 유추하는 바람에 표기를 잘못 정하는 경우가 종종 있다고 해요.
에스토니아어 핀란드어 고대 그리스어 세르보크로아트어 헝가리어 아이슬란드어 이탈리아어 일본어 일본어최영애-김용옥 조지아어제1안 조지아어제2안 라틴어 라트비아어 리투아니아어 마케도니아어 네덜란드어 폴란드어 포르투갈어 브라질 포르투갈어 루마니아어 러시아어 슬로바키아어 슬로베니아어 스페인어 알바니아어 스웨덴어 터키어 우크라이나어 베트남어 웨일스어중세 한글라이즈엔 현재 일본어, 헝가리어 등 총 40개의 전사 규칙이 들어있어요.
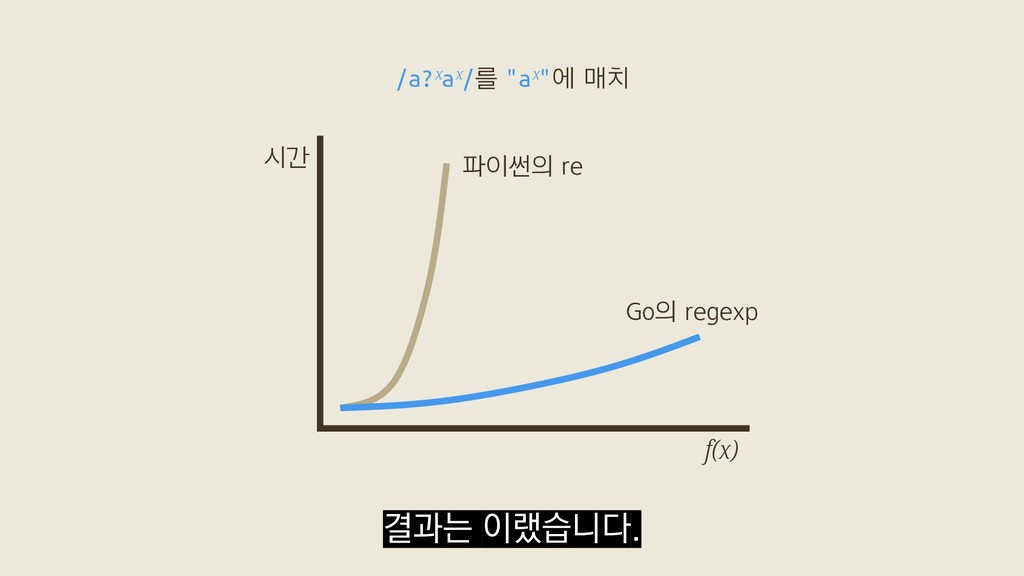
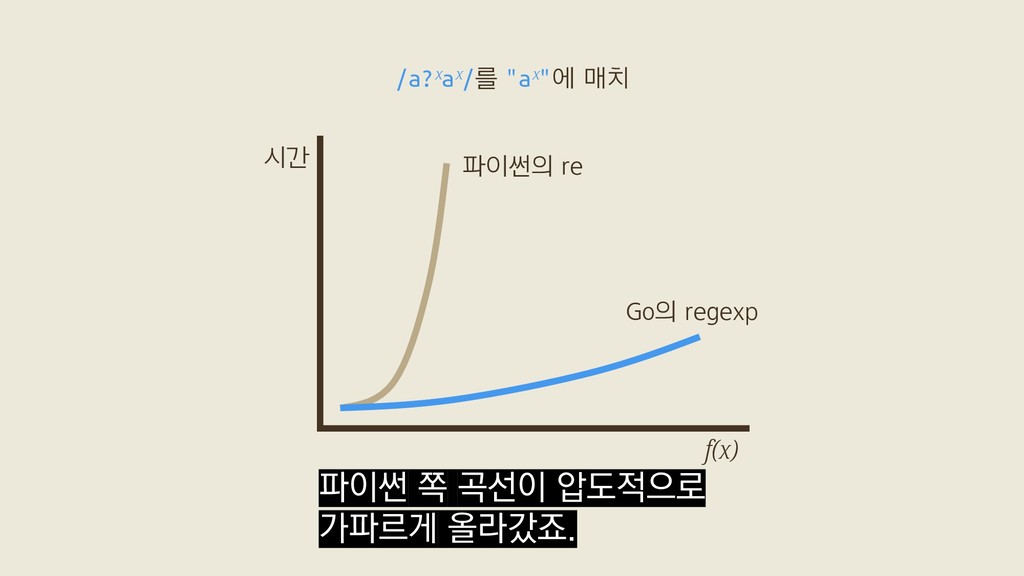
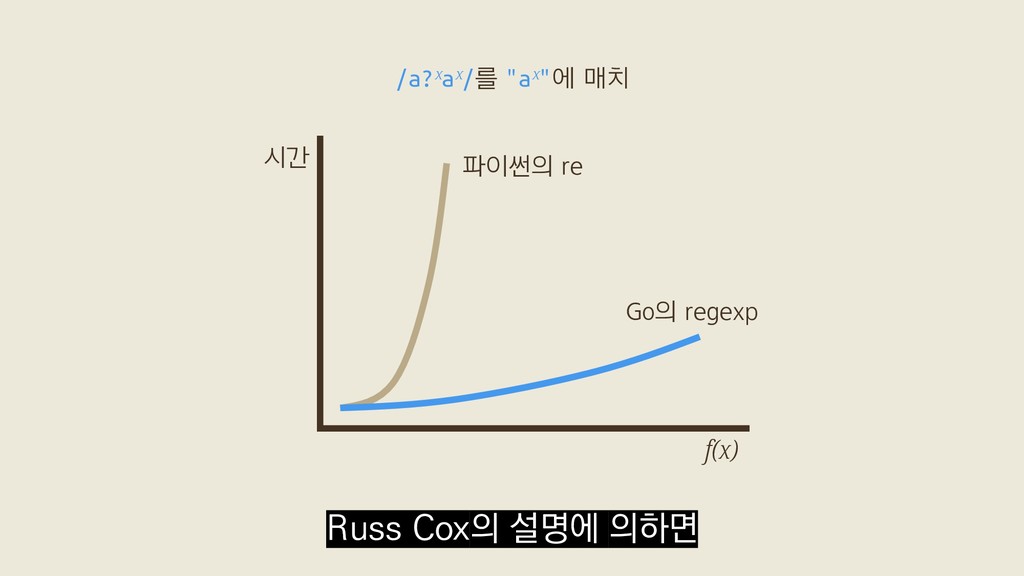
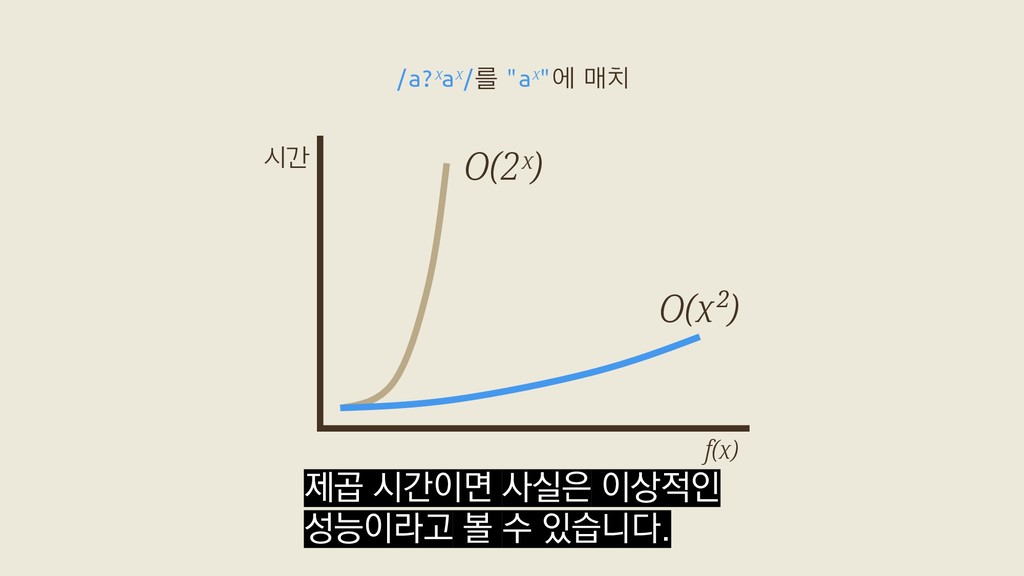
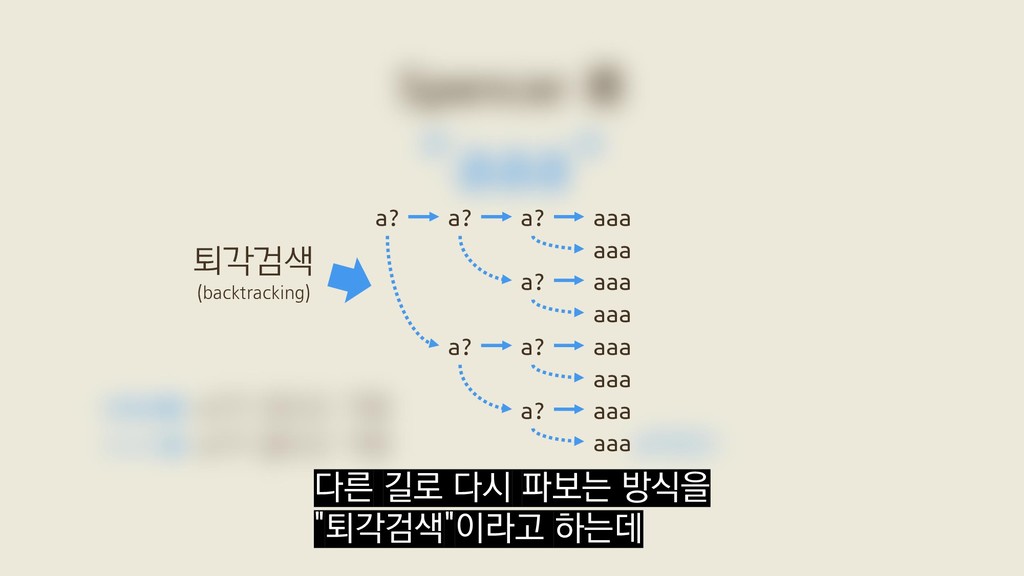
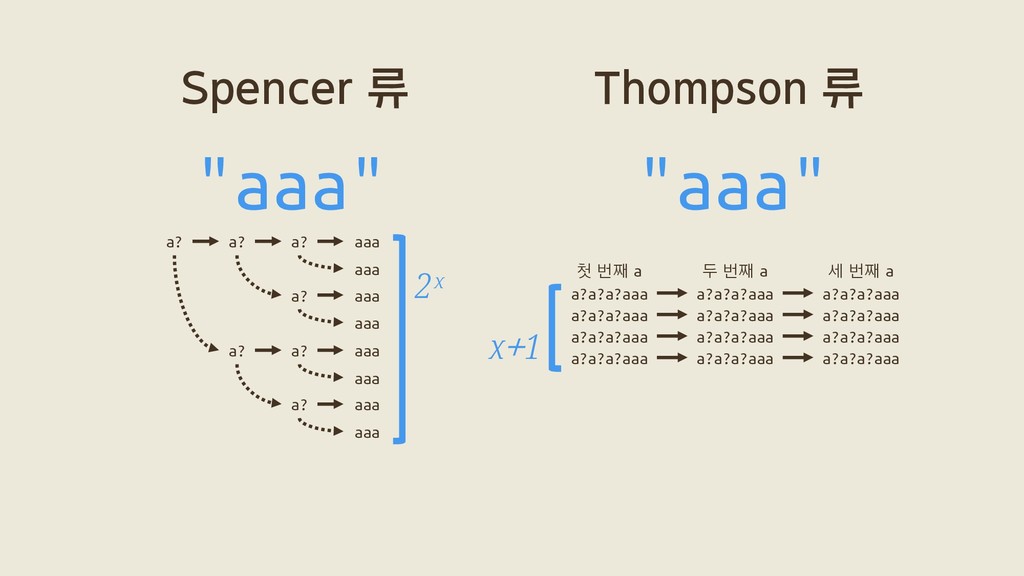
f(5) = /a?a?a?a?a?aaaaa/를 "aaaaa"에 매치 f(x) = /a?ˣaˣ/를 "aˣ"에 매치 벤치마크 Russ Cox, 〈Regular Expression Matching Can Be Simple And Fast〉(2007) x개의 "a"로 이뤄진 대상 문자열을 가지고
f(5) = /a?a?a?a?a?aaaaa/를 "aaaaa"에 매치 f(x) = /a?ˣaˣ/를 "aˣ"에 매치 벤치마크 Russ Cox, 〈Regular Expression Matching Can Be Simple And Fast〉(2007) Go의 정규식 표준 라이브러리 "regexp" 두 가지로 직접 돌려봤어요.
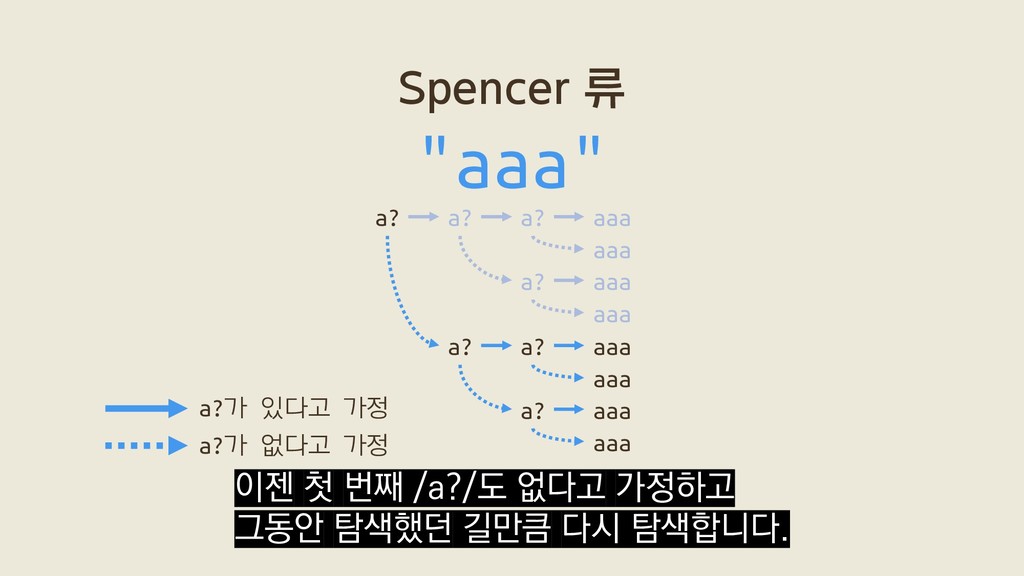
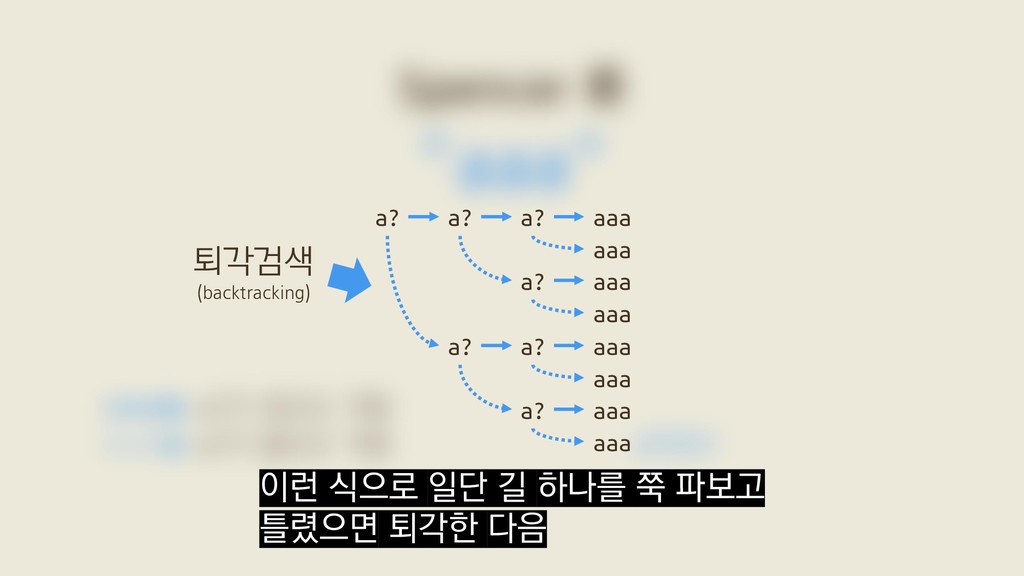
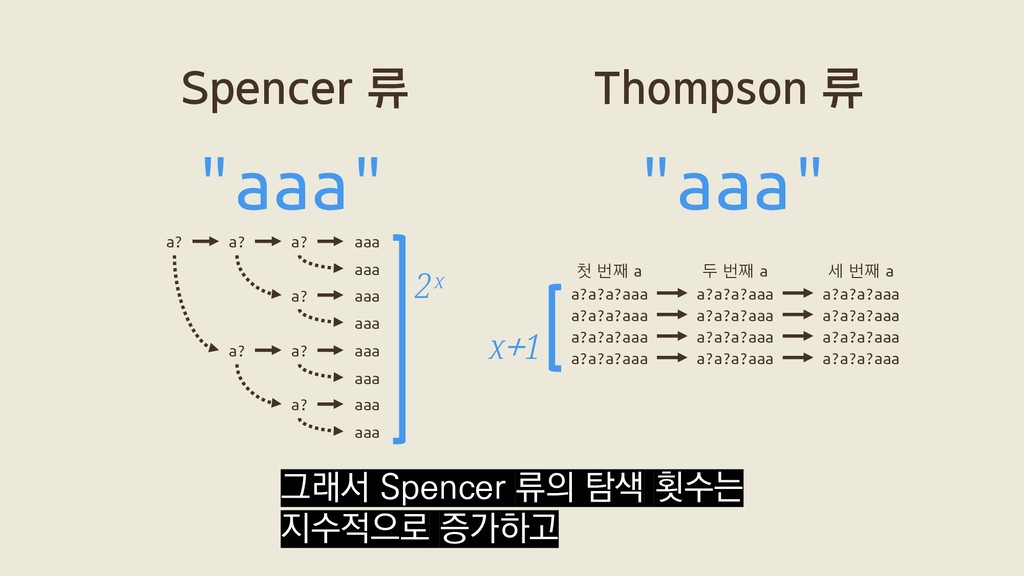
a? a? aaa a? aaa a? aaa aaa aaa aaa aaa 2ˣ a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa 첫 번째 a 두 번째 a 세 번째 a x+1
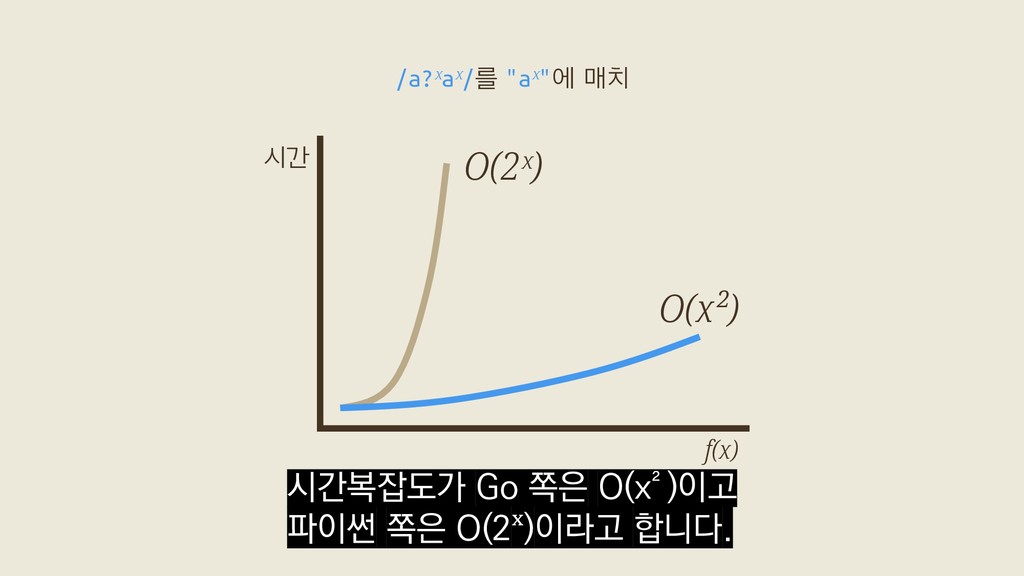
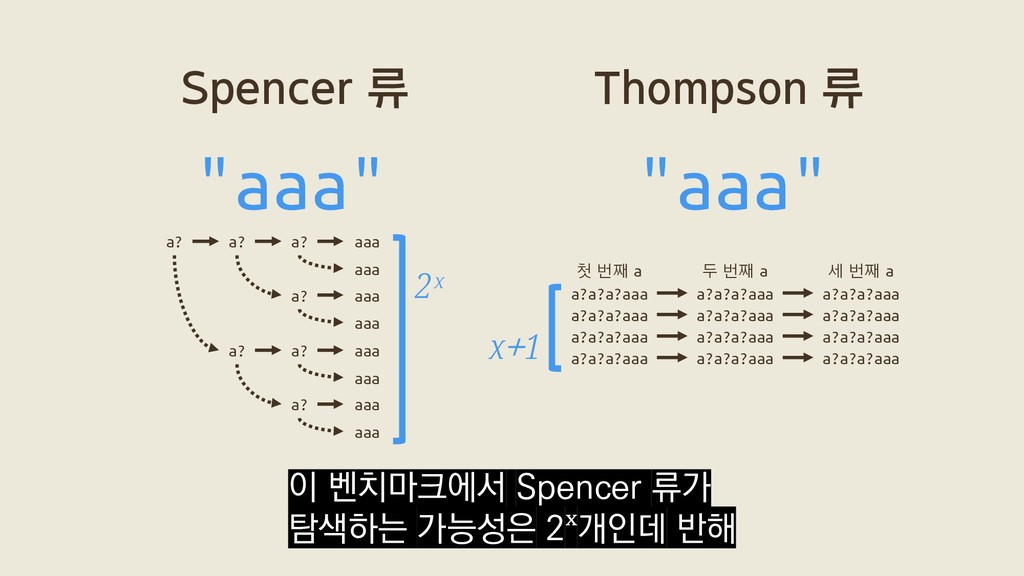
a? a? aaa a? aaa a? aaa aaa aaa aaa aaa 2ˣ a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa 첫 번째 a 두 번째 a 세 번째 a x+1 이 벤치마크에서 Spencer 류가 탐색하는 가능성은 2ˣ개인데 반해
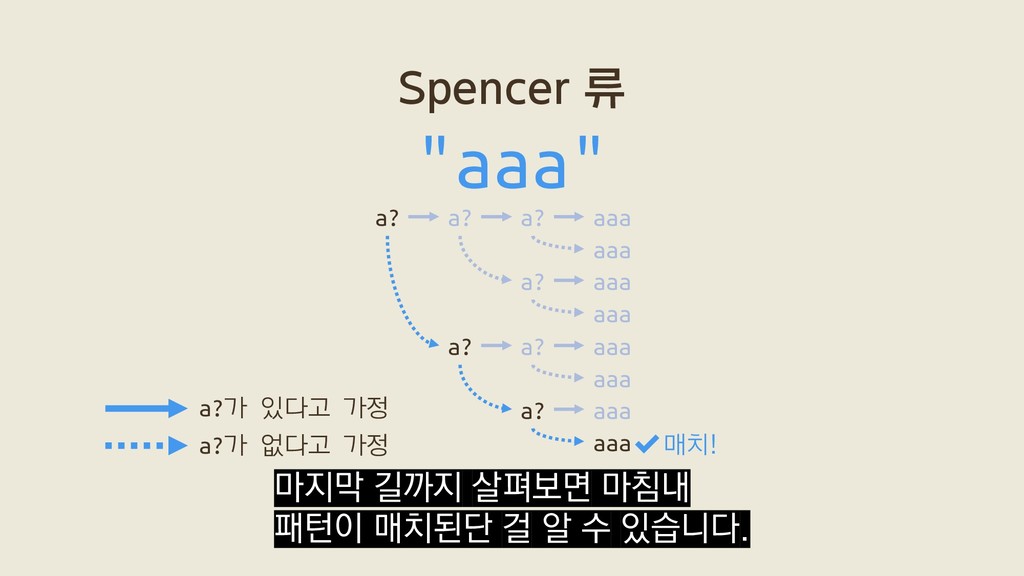
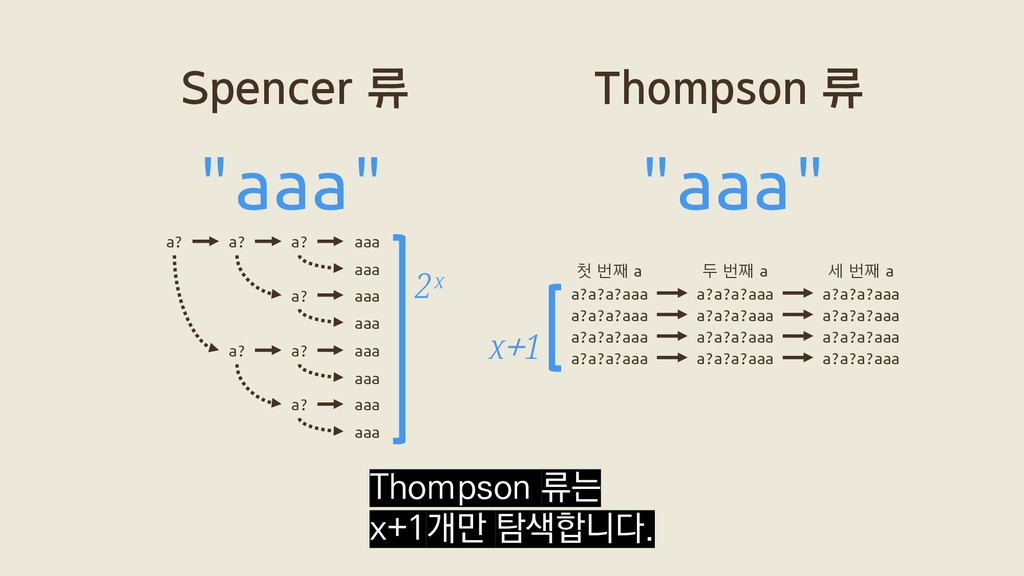
a? a? aaa a? aaa a? aaa aaa aaa aaa aaa 2ˣ a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa 첫 번째 a 두 번째 a 세 번째 a x+1 Thompson 류는 x+1개만 탐색합니다.
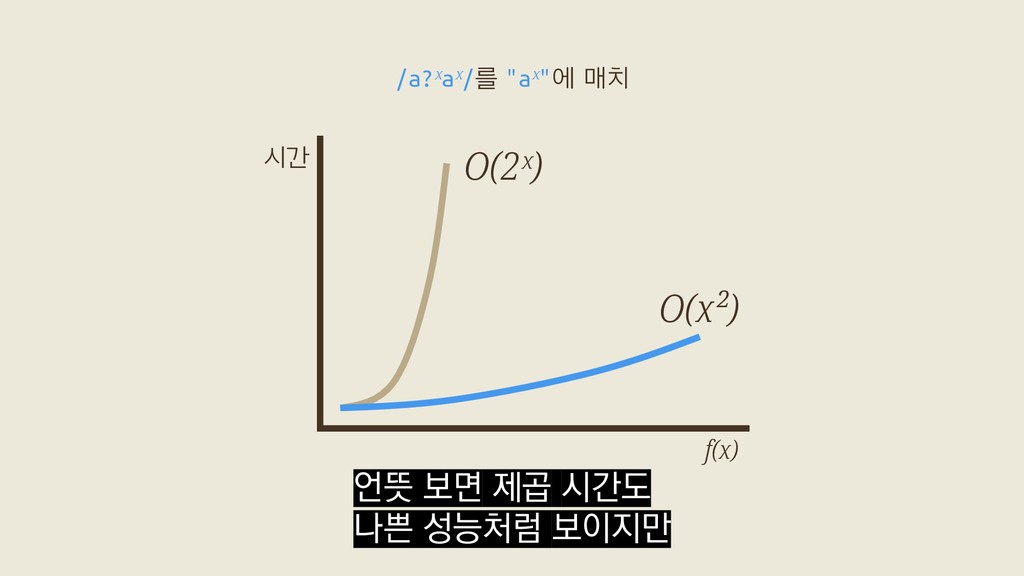
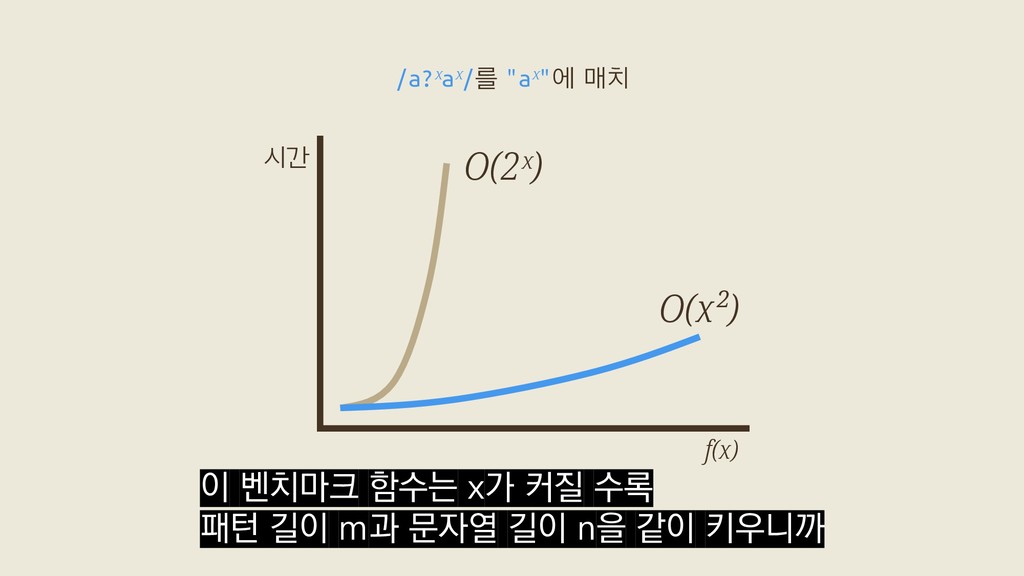
a? a? aaa a? aaa a? aaa aaa aaa aaa aaa 2ˣ a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa 첫 번째 a 두 번째 a 세 번째 a x+1 그래서 Spencer 류의 탐색 횟수는 지수적으로 증가하고
a? a? aaa a? aaa a? aaa aaa aaa aaa aaa 2ˣ a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa 첫 번째 a 두 번째 a 세 번째 a x+1 Thompson 류의 탐색 횟수는 선형적으로 증가하죠.
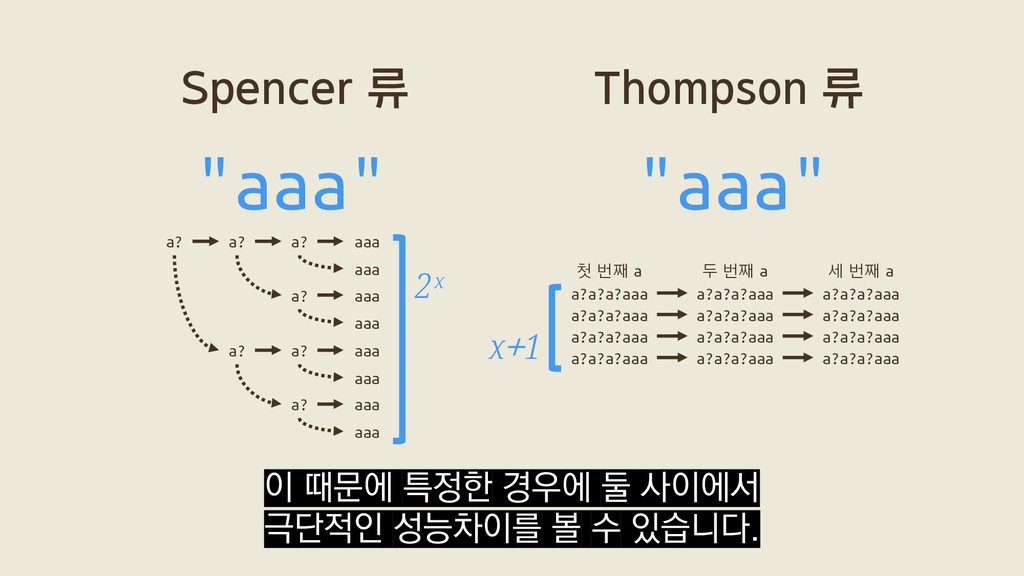
a? a? aaa a? aaa a? aaa aaa aaa aaa aaa 2ˣ a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa a?a?a?aaa 첫 번째 a 두 번째 a 세 번째 a x+1 이 때문에 특정한 경우에 둘 사이에서 극단적인 성능차이를 볼 수 있습니다.
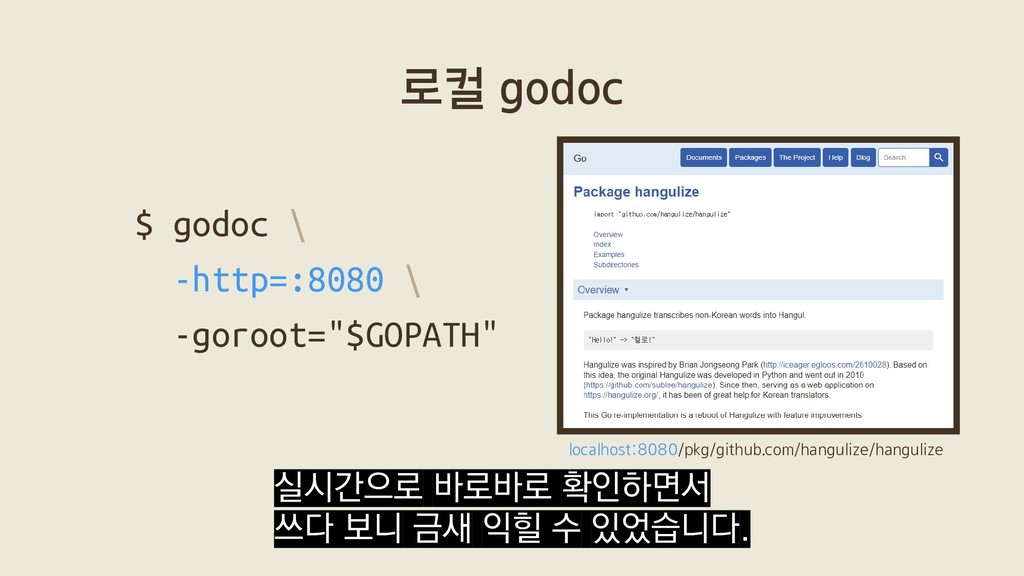
크다. (800KB) import "github.com/mozillazg/go-pinyin" args := pinyin.NewArgs() pinyin.SinglePinyin('青', args) == "Qīng" "go-pinyin"이라는 라이브러리를 쓰면 손쉽게 병음을 구할 수 있습니다.
크다. (800KB) import "github.com/mozillazg/go-pinyin" args := pinyin.NewArgs() pinyin.SinglePinyin('青', args) == "Qīng" 의외로 데이터도 별로 크지 않아서 800KB 밖에 되지 않습니다.
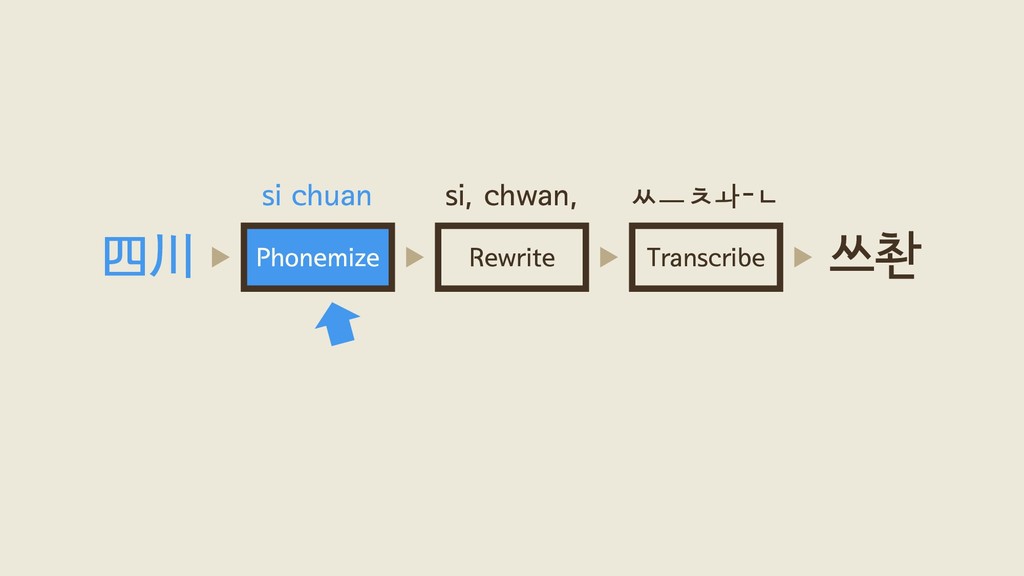
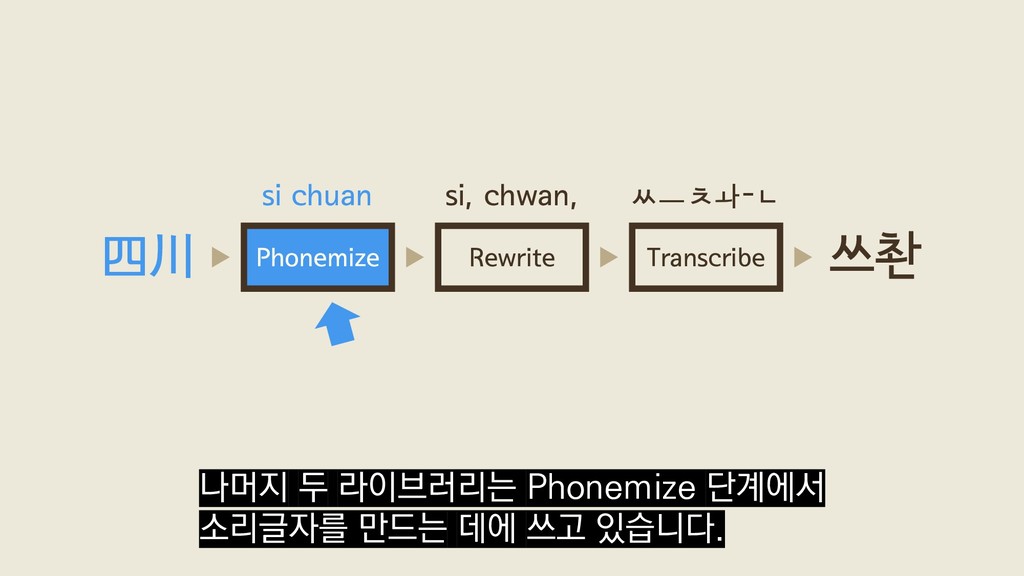
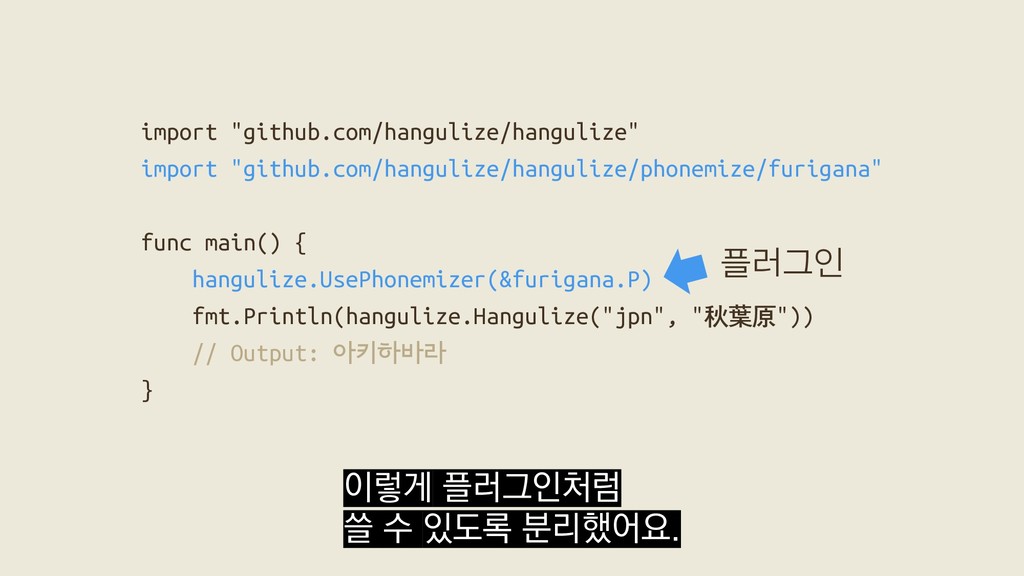
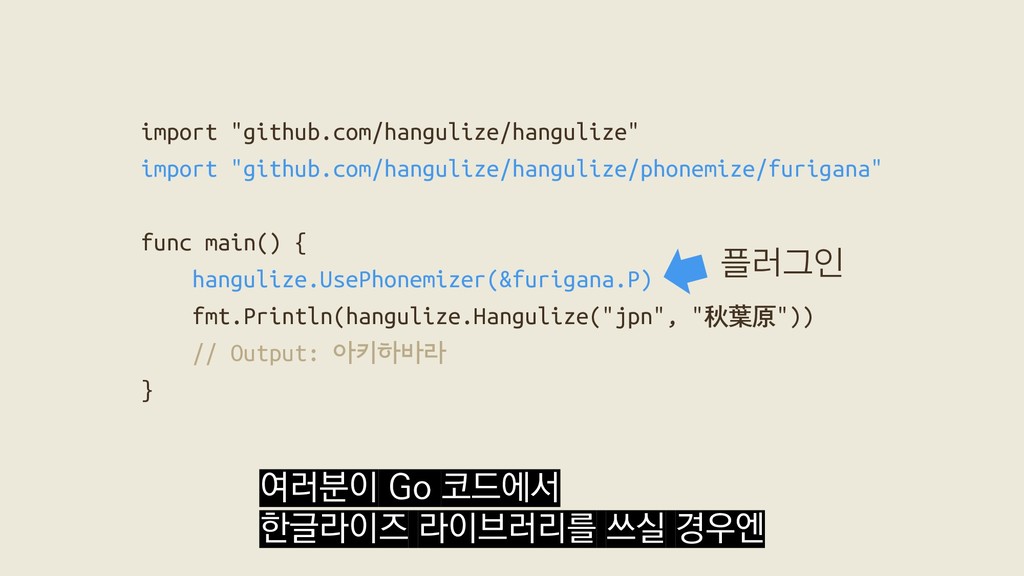
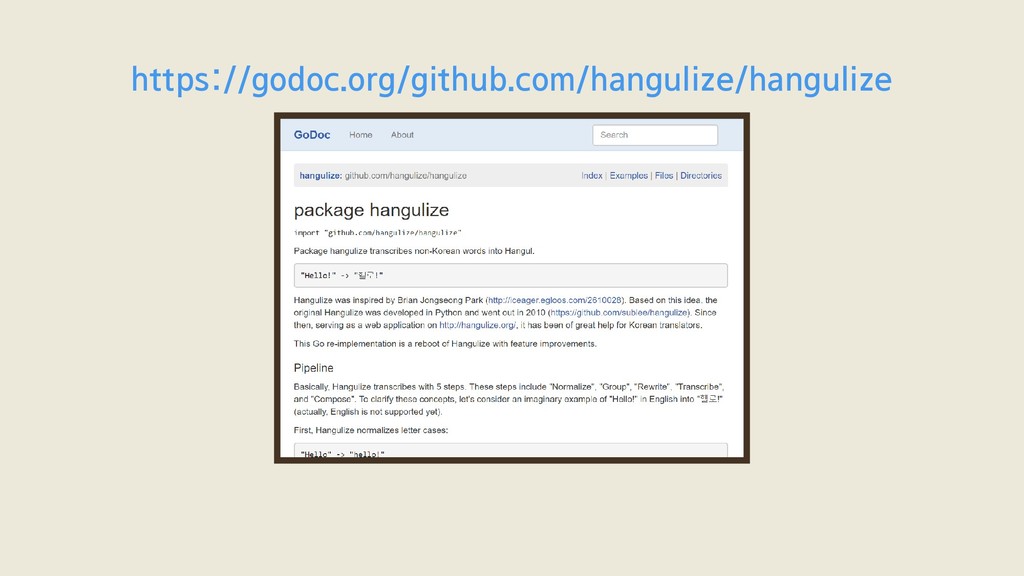
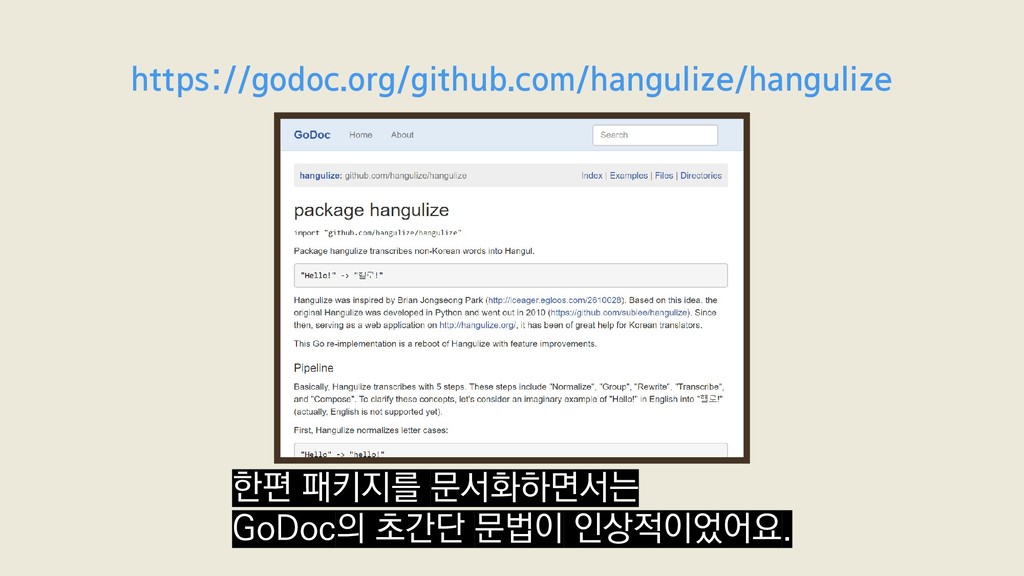
Package hangulize transcribes non-Korean words into Hangul. "Hello!" -> "헬로!" Hangulize was inspired by Brian Jongseong Park (http://iceager.egloos.com/2610028). Based on this idea, the original 커맨드라인 문법이 이렇게 단순한 건 GoDoc이 웹 사이트 뿐만 아니라
Package hangulize transcribes non-Korean words into Hangul. "Hello!" -> "헬로!" Hangulize was inspired by Brian Jongseong Park (http://iceager.egloos.com/2610028). Based on this idea, the original 커맨드라인 커맨드라인 출력도 중요하게 다루기 때문이라고 합니다.
표기법에 따라 한글로 옮겨 적어주는 도구입니다. "Espresso"를 "에스프레소"로, "東京 "을 "도쿄"로 변환할 수 있죠. 본래 Python으로 구현했던 한글라 이즈를 Go로 재구현하면서 겪은 경험과 느낀점을 공유합니다. Go에 근자감 어떻게 보면 근자감일 수도 있는데 결국 이 발표까지 하게 됐습니다.
표기법에 따라 한글로 옮겨 적어주는 도구입니다. "Espresso"를 "에스프레소"로, "東京 "을 "도쿄"로 변환할 수 있죠. 본래 Python으로 구현했던 한글라 이즈를 Go로 재구현하면서 겪은 경험과 느낀점을 공유합니다. Go에 근자감 명확하게 정리하지 않고 넘어갔던 부분도 명확하게 이해할 수 있었고
표기법에 따라 한글로 옮겨 적어주는 도구입니다. "Espresso"를 "에스프레소"로, "東京 "을 "도쿄"로 변환할 수 있죠. 본래 Python으로 구현했던 한글라 이즈를 Go로 재구현하면서 겪은 경험과 느낀점을 공유합니다. Go에 근자감 한글라이즈를 더 많이 발전시킬 수 있는 기회가 되기도 했습니다.
표기법에 따라 한글로 옮겨 적어주는 도구입니다. "Espresso"를 "에스프레소"로, "東京 "을 "도쿄"로 변환할 수 있죠. 본래 Python으로 구현했던 한글라 이즈를 Go로 재구현하면서 겪은 경험과 느낀점을 공유합니다. Go에 근자감 발표 준비하는 동안 한글라이즈 코딩도 평소보다 더 많이 했던 것 같아요.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
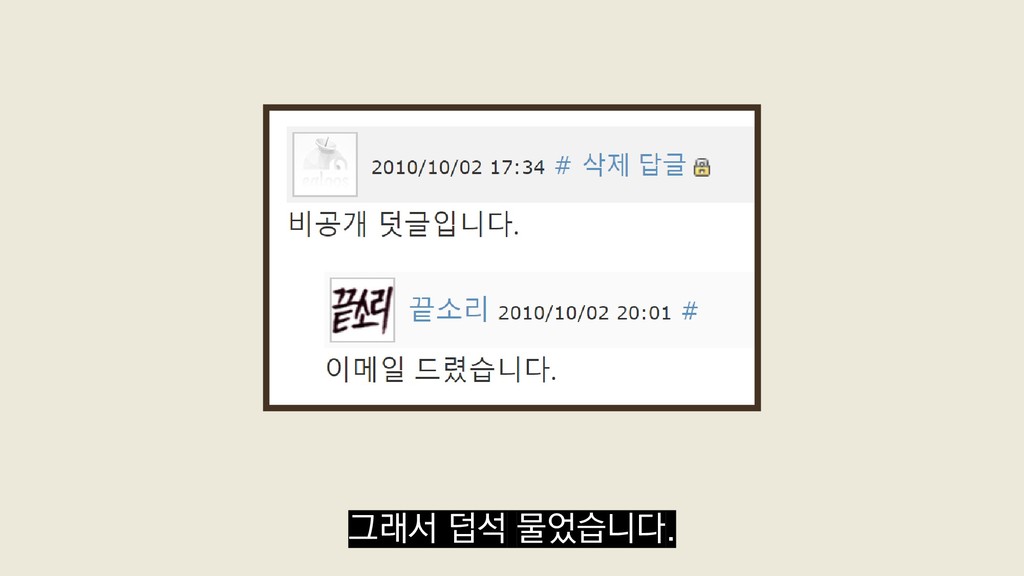{kind=link}
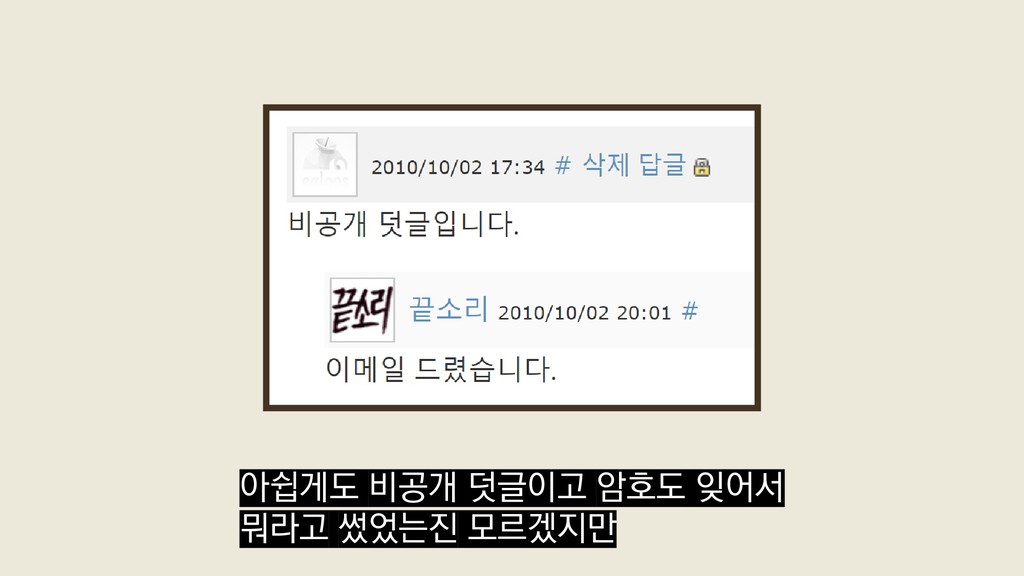{kind=link}
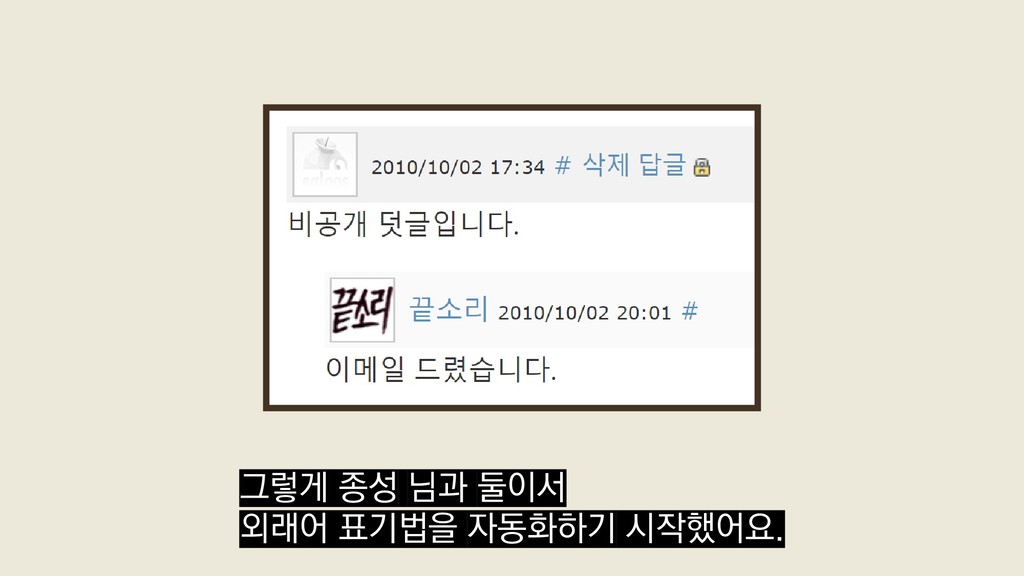{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
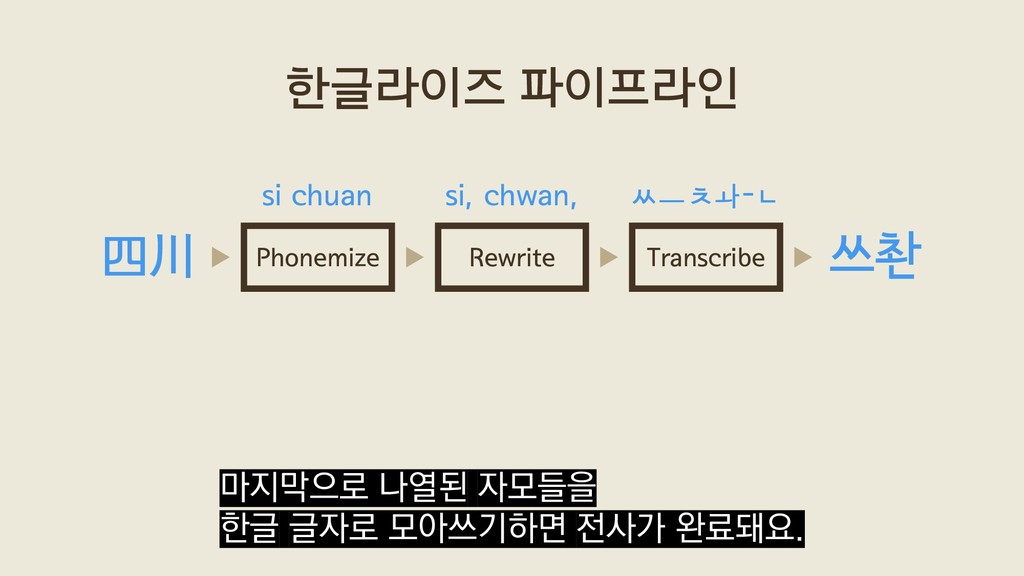{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
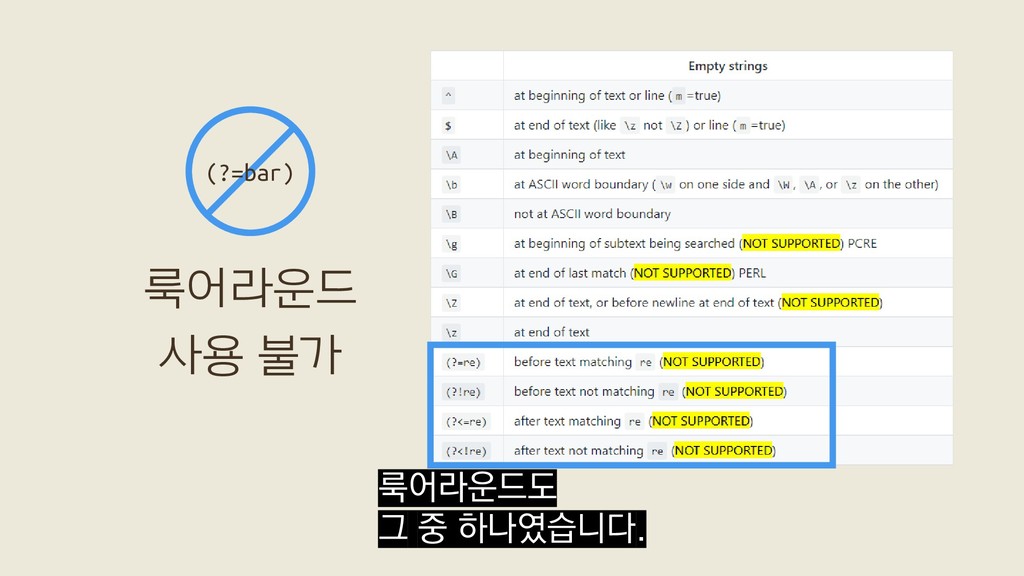
![/(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~- ]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d- \x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9- ]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:25[0- 5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0- 9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e- \x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])/ 이메일 정규표현식 http://emailregex.com/](https://files.speakerdeck.com/presentations/bad39d67493f42b09f2461fd217acd87/slide_211.jpg){kind=link}
![/(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~- ]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d- \x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9- ]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:25[0- 5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0- 9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e- \x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])/ 이메일 정규표현식 http://emailregex.com/](https://files.speakerdeck.com/presentations/bad39d67493f42b09f2461fd217acd87/slide_212.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![/(a+)+/ /([a-zA-Z]+)*/ /(a|aa)+/ /(a|a?)+/ ReDoS 공격 하지만 Spencer 류 정규식](https://files.speakerdeck.com/presentations/bad39d67493f42b09f2461fd217acd87/slide_293.jpg){kind=link}
![/(a+)+/ /([a-zA-Z]+)*/ /(a|aa)+/ /(a|a?)+/ ReDoS 공격 만약 사용자 입력으로 정규식](https://files.speakerdeck.com/presentations/bad39d67493f42b09f2461fd217acd87/slide_294.jpg){kind=link}
![/(a+)+/ /([a-zA-Z]+)*/ /(a|aa)+/ /(a|a?)+/ ReDoS 공격 공격자가 정규식 엔진에서 최악의](https://files.speakerdeck.com/presentations/bad39d67493f42b09f2461fd217acd87/slide_295.jpg){kind=link}
![/(a+)+/ /([a-zA-Z]+)*/ /(a|aa)+/ /(a|a?)+/ ReDoS 공격 악의적인 정규식 패턴으로 ReDoS](https://files.speakerdeck.com/presentations/bad39d67493f42b09f2461fd217acd87/slide_296.jpg){kind=link}
![/(a+)+/ /([a-zA-Z]+)*/ /(a|aa)+/ /(a|a?)+/ ReDoS 공격 구글에서도 ReDoS 공격에 대한](https://files.speakerdeck.com/presentations/bad39d67493f42b09f2461fd217acd87/slide_297.jpg){kind=link}
![/(a+)+/ /([a-zA-Z]+)*/ /(a|aa)+/ /(a|a?)+/ ReDoS 공격 Thompson의 정규식 알고리즘을 기반으로](https://files.speakerdeck.com/presentations/bad39d67493f42b09f2461fd217acd87/slide_298.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
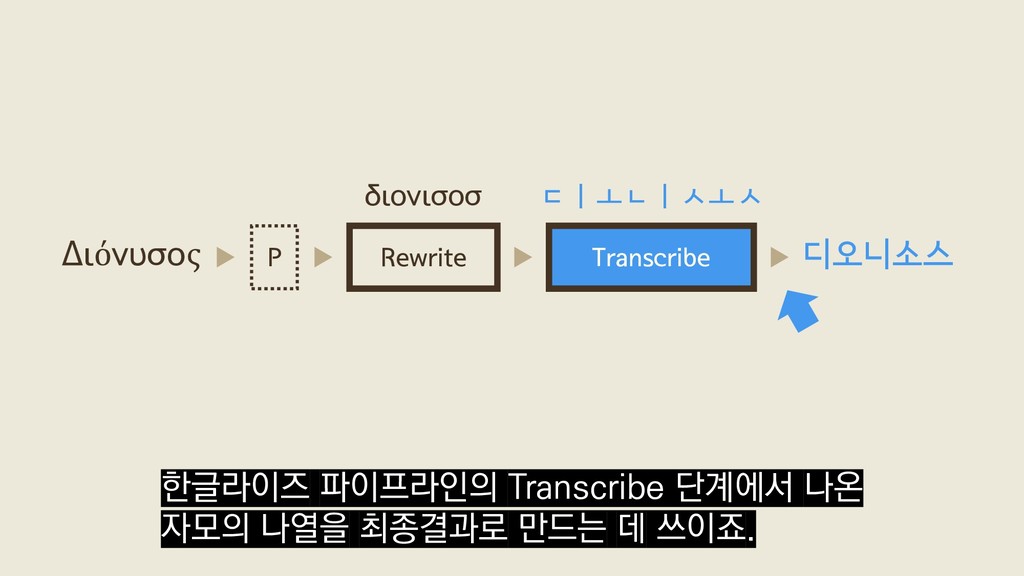{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
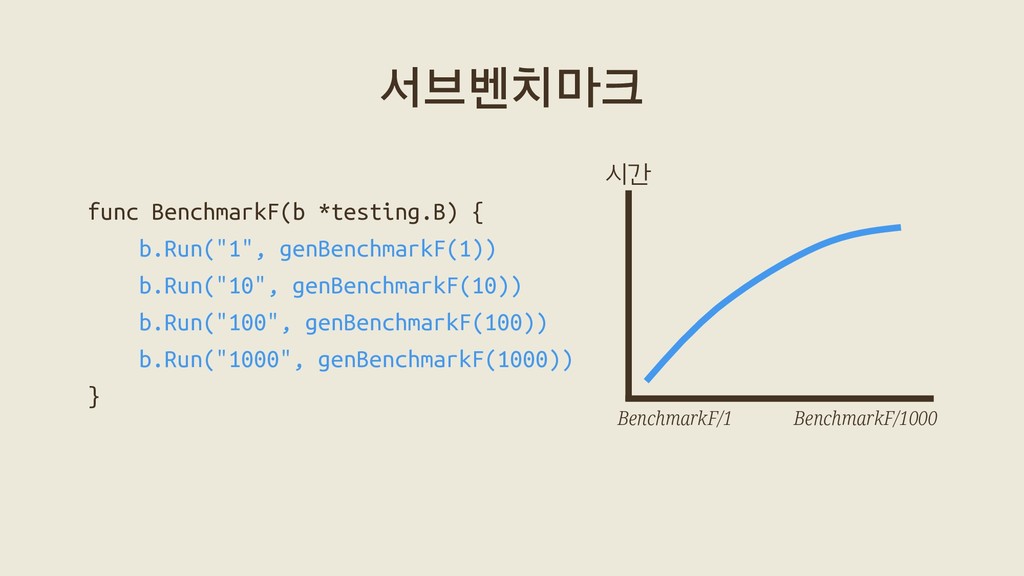{kind=link}
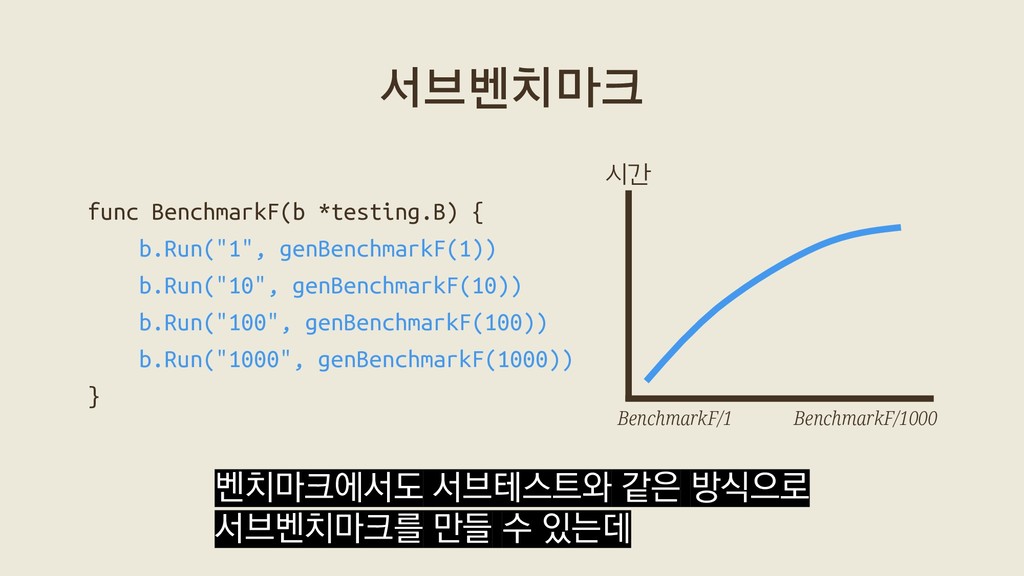{kind=link}
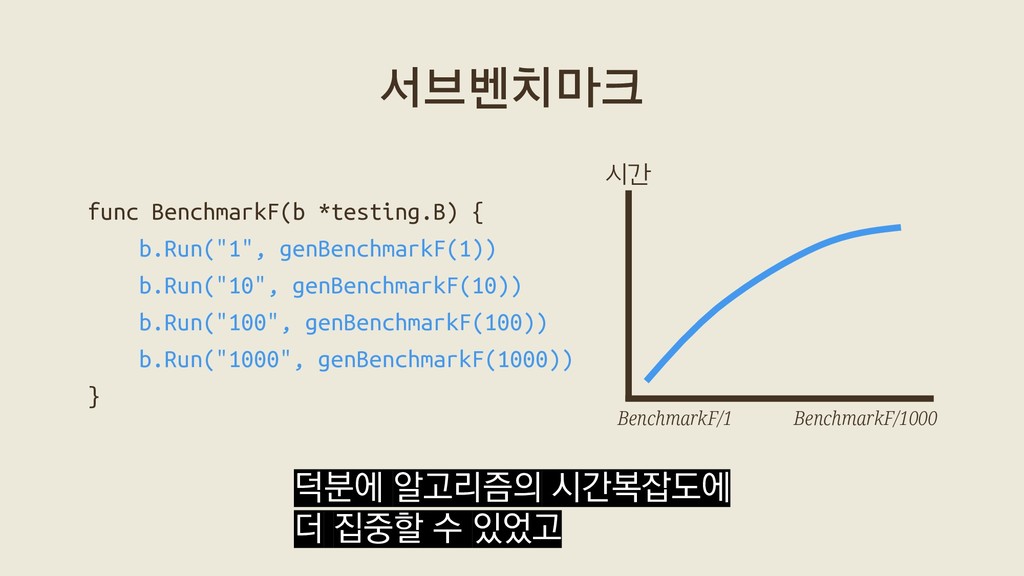{kind=link}
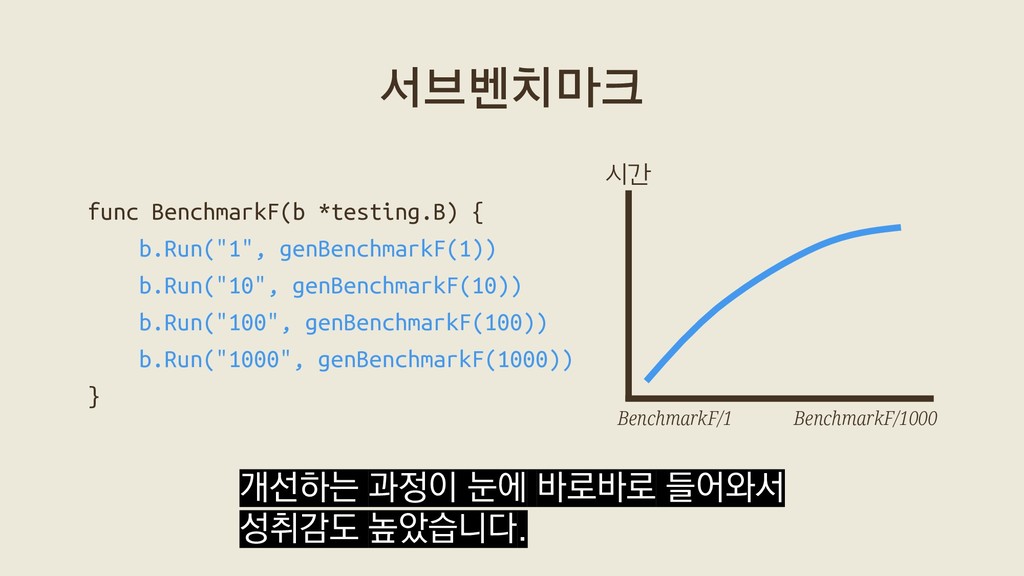{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
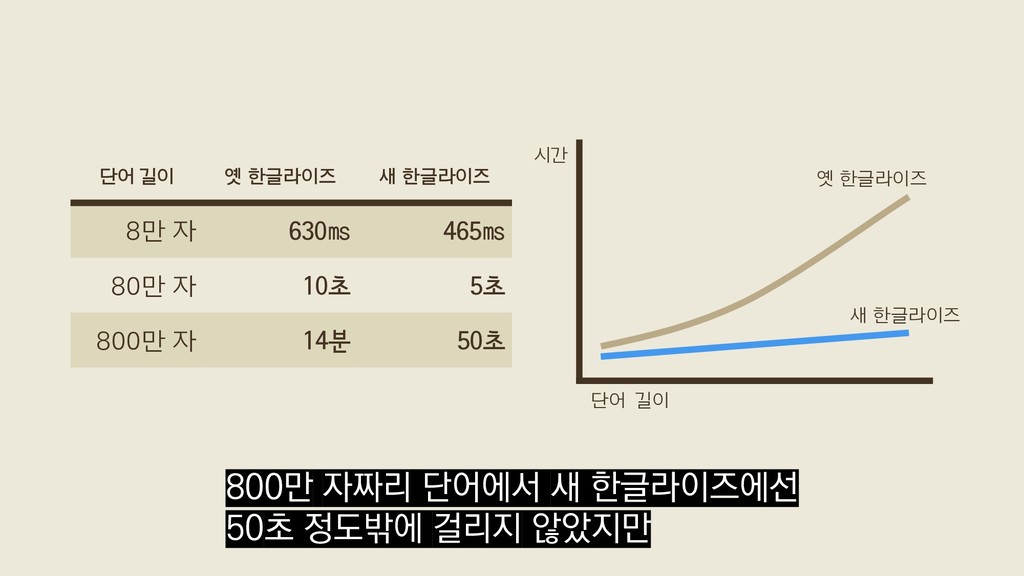{kind=link}
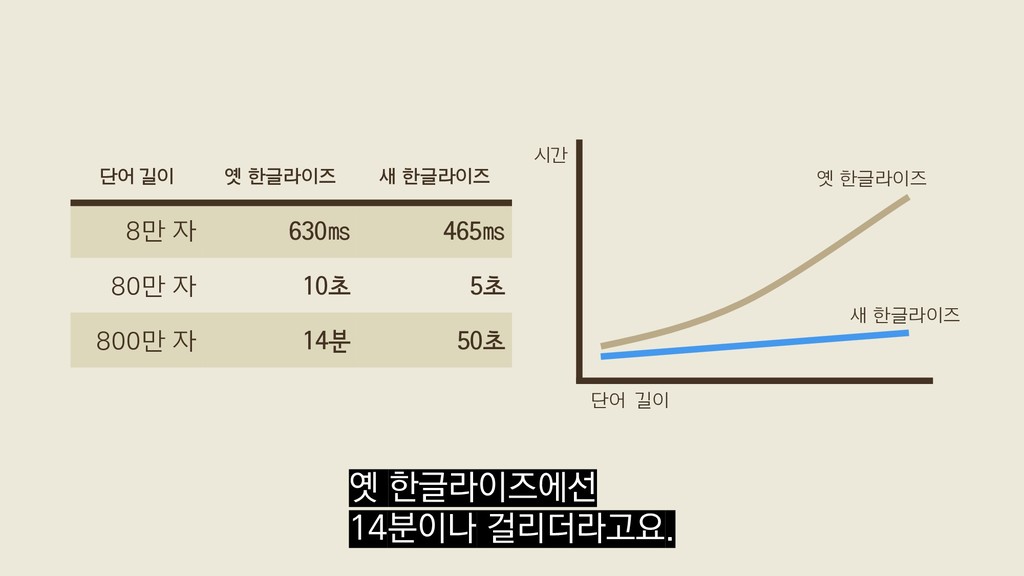{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
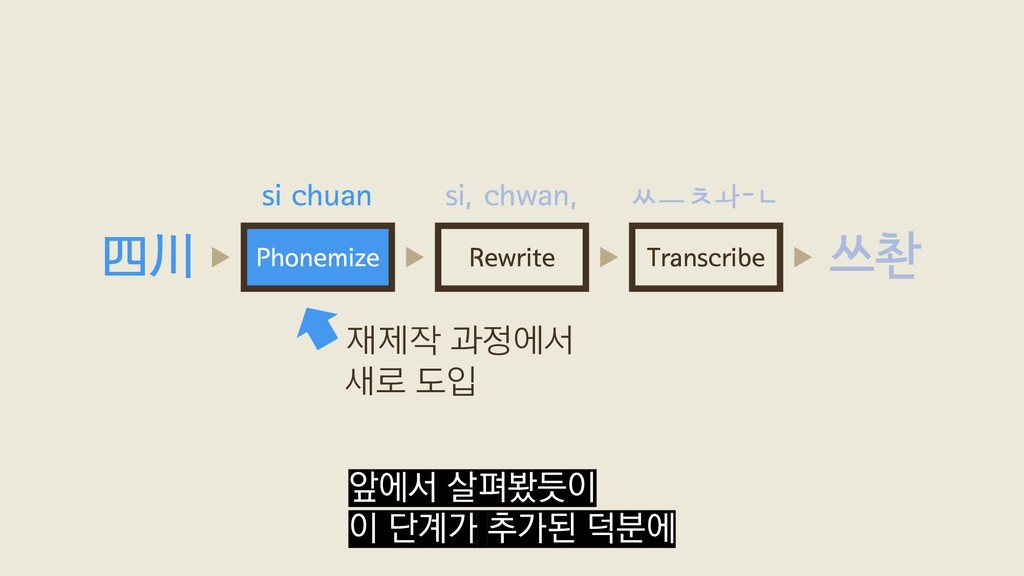{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
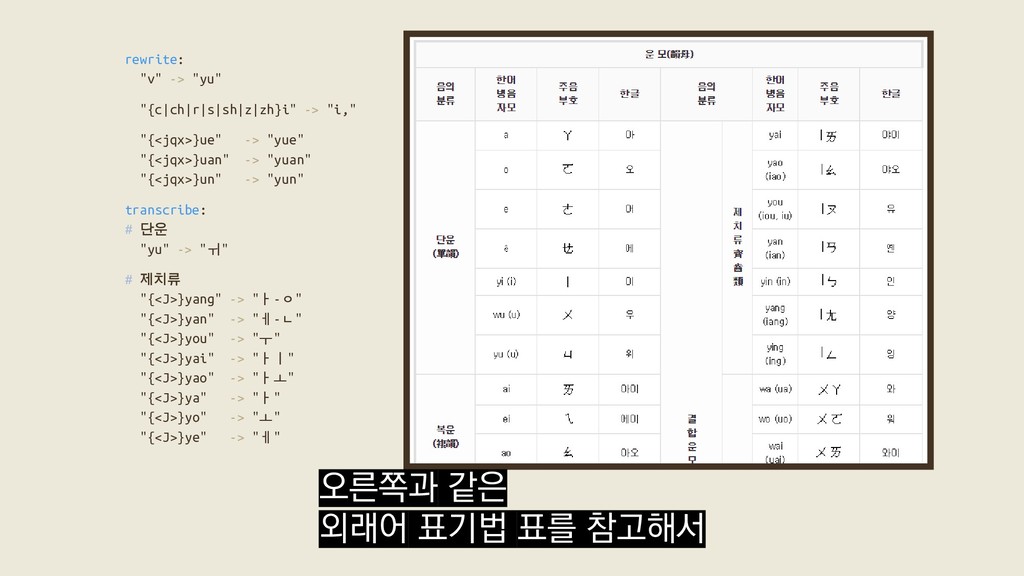{kind=link}
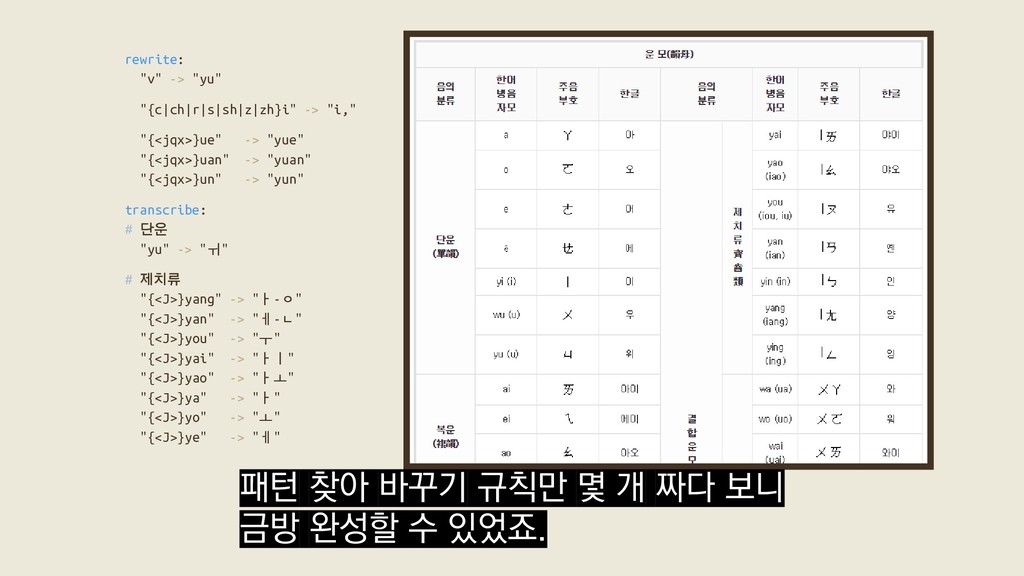{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![- [한글라이즈 재제작기] 이흥섭(넥슨 왓 스튜디오) 〈한글라이즈〉는 외국어 단어를 외래어](https://files.speakerdeck.com/presentations/bad39d67493f42b09f2461fd217acd87/slide_543.jpg){kind=link}
![- [한글라이즈 재제작기] 이흥섭(넥슨 왓 스튜디오) 〈한글라이즈〉는 외국어 단어를 외래어](https://files.speakerdeck.com/presentations/bad39d67493f42b09f2461fd217acd87/slide_544.jpg){kind=link}
![- [한글라이즈 재제작기] 이흥섭(넥슨 왓 스튜디오) 〈한글라이즈〉는 외국어 단어를 외래어](https://files.speakerdeck.com/presentations/bad39d67493f42b09f2461fd217acd87/slide_545.jpg){kind=link}
![- [한글라이즈 재제작기] 이흥섭(넥슨 왓 스튜디오) 〈한글라이즈〉는 외국어 단어를 외래어](https://files.speakerdeck.com/presentations/bad39d67493f42b09f2461fd217acd87/slide_546.jpg){kind=link}
![- [한글라이즈 재제작기] 이흥섭(넥슨 왓 스튜디오) 〈한글라이즈〉는 외국어 단어를 외래어](https://files.speakerdeck.com/presentations/bad39d67493f42b09f2461fd217acd87/slide_547.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![I GO 좀 더 이야기 나누고 싶은 분은 [email protected]로 이메일](https://files.speakerdeck.com/presentations/bad39d67493f42b09f2461fd217acd87/slide_552.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}