Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
GemmaでRAG を作ろう
Search
SuperHotDog
March 10, 2024
720
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
GemmaでRAG を作ろう
Codebase used in this handson ->
https://github.com/SuperHotDogCat/Gemma-RAG-Handson
SuperHotDog
March 10, 2024
More Decks by SuperHotDog
See All by SuperHotDog
LLM高速化勉強会資料
superhotdogcat
8
2.8k
Dockerの裏側を攻める
superhotdogcat
0
38
SigLIP
superhotdogcat
1
140
post-training
superhotdogcat
3
640
研究室紹介用スライド: Unified Memoryを活⽤した効率的な計算⽅法を考えよう
superhotdogcat
0
120
大規模モデル計算の裏に潜む 並列分散処理について
superhotdogcat
1
84
オンプレソロプレイ
superhotdogcat
0
100
CUDAを触ろう
superhotdogcat
0
140
Featured
See All Featured
Side Projects
sachag
455
43k
Ruling the World: When Life Gets Gamed
codingconduct
0
290
How to train your dragon (web standard)
notwaldorf
97
6.7k
The Psychology of Web Performance [Beyond Tellerrand 2023]
tammyeverts
49
3.5k
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
31
3.3k
Statistics for Hackers
jakevdp
799
230k
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.7k
Building Adaptive Systems
keathley
44
3.1k
Building Applications with DynamoDB
mza
96
7.1k
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.8k
Context Engineering - Making Every Token Count
addyosmani
9
1k
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.5k
Transcript
ろくがをわすれない GemmaでRAGをつくろう
まずお前誰だよ ・Xアカウント名: 犬(SSR) @takanas0517 ・GitHub @SuperHotDogCat ・職業: 東大工学部電子情報工学科3年(次は4年生) ・好きなコンピューターサイエンスの分野 ・OS
・WebAssembly ・ML ・最近pythonのライブラリ作った ・研究者と開発者の中間みたいな人を目指している ・趣味: 論文実装
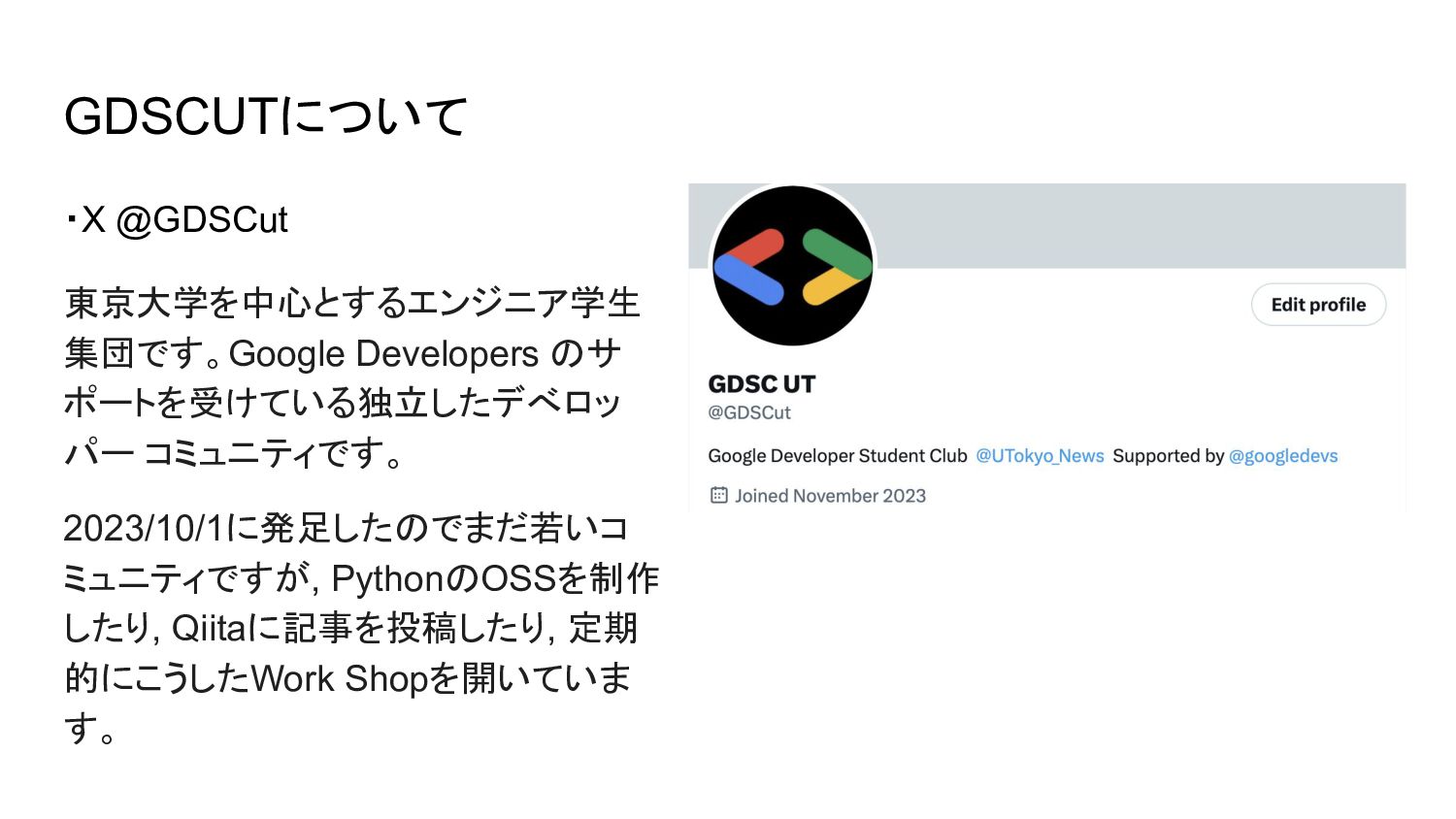
GDSCUTについて ・X @GDSCut 東京大学を中心とするエンジニア学生 集団です。Google Developers のサ ポートを受けている独立したデべロッ パー コミュニティです。
2023/10/1に発足したのでまだ若いコ ミュニティですが, PythonのOSSを制作 したり, Qiitaに記事を投稿したり, 定期 的にこうしたWork Shopを開いていま す。
発表の注意 発表者は大学三年生なのでミスや若気のいたりによる間違いなどがあるかもしれませ ん、その場合はご指摘ください。
目標 1. みんなに自然言語処理技術をなんとなくでも良いのでわかってもらう 2. RAGの組み方, 検索方法についてなんとなく理解してもらう 3. Lang ChainとHugging Faceを使ってOpen
LLMを使った開発に入門する
NLP技術について 今回のイベントは参加者に自然言語処理の知識を前提としていないので 少し解説をします。 まずNLP(Natural Language Processing)とは何かということについてです。 ざっくりいうと, 自然言語をパソコンが扱えるように処理をしようという研究分野です。 最近はNLP≒MLみたいになってますがNLPへのアプローチは必ずしもMLと は限りません。MLが採用されているのはMLが工学上有用だからです。
どうやるの? 独断と偏見で大雑把に分けて3ステップあります。 1. 自然言語の数値化 2. タスクに応じて数字を変換 3. 変換された数字を自然言語に復元 この3ステップをI love
applesという入力に対してMe tooという応答を返すシス テムを例に解説します。
1. 自然言語の数値化 パソコンが扱えるのは数字のみなので, 自然言語をまず数字に直す作業が必要です。 Pythonの型で表現するならString->List<Int>を行う作業です。 例: I love apples. ->[I,
love, apples, .]->[40, 1842, 22514, 13] この2つの変換の一つ目をtokenize, 二つ目をencodeと呼びます。上の例ではそれぞれ の単語に数字が割り当てられています。
2. タスクに応じて数字を変換 ML言語モデルはList<Int>の入力に対してList<Int>を返します。ここがGPTやGeminiの モデル本体がやっていることです。 ML言語モデル [40, 1842, 22514, 13]-> ->[5308,
1165, 13]
3. 変換された数字を自然言語に復元 1.で行ったTokenizeの逆の作業を行います。 例: [5308, 1165, 13]->Me too.
全体の概観 ML言語モデル ->[5308, 1165, 13]->Me too. I love apples. ->[40,
1842,22514, 13]->
余談
LLM という感じで, 先に話したNLPの図におけるML言語モデルの開発が長年行われてきま した。 RNN, LSTM, GRUなどを経て, Transformerという現在デファクトスタンダードになって いるモデルが生まれました。 初めはTransformerは機械翻訳のタスクで生まれました。
やがて任意の言語入力に対して汎用的に応答が生成できるような大規模なモデルが生 まれました。 それらの言語モデルを総称してLLM(Large Language Model)と呼んでいます。
LLM ・流石にこの時間内で全てを解説するのは厳しい。 ・何か実装系の本を1つ使ってひと通り実装してみるのが良いです。 ・知識だけが欲しい人は以下の検索ワードで調べてみましょう モデル関連 ・Word2Vec, RNN, LSTM, GRU, Attention,
Transformer, GPT その他 ・Encoder-Decoder, Embedding, RLHF, SFT
もっと学びたい人向け ・大学生なら毎学期東大松尾研究室で行われている深層学習基礎講座 , LLM講座がおすすめ 今日の内容はLLM講座より少し先に進んだ話をしています。 ・社会人の方なら->https://qiita.com/KNR109/items/2d95aa8862b14ff50378 のようにMixi, CA, AWSなどが公開している資料がいいのだろうか いずれにせよ,
Pytorch, JAX, Kerasで一度は組んでみたほうが良いかなと思います。
実装したい人向け ・Andrej Karpathy大先生がLLM from scratchのリポジトリを公開してくれています。是 非グラボを積んで遊びましょう。 minGPT nanoGPT これらをforkしたnanoChatGPTもあります。 nanoChatGPT
難しい話はさておき やはり, モデルをただ動かしたい人がモデルを制作する段階から始めるのは非常に難し い(GPUもないし) 最近はHugging FaceというOSSの機械学習モデルがまとめられたサイトがある。 そこ で制作されたHugging Faceモデルを使って動かすというパターンが多い。
難しい話はさておき
Hugging Faceのアカウントを作りましょう 今日使うGemmaはライセンスへの同意とHugging Face API Keyが必要なため、アカ ウントを作っておこう Hugging Face
Hallucinationに気をつけよう Hugging FaceやOpenAI, Geminiを使えば今なら誰でもLLMを使うことができる。 しかし, ここでHallucinationという問題がある。
None
Hallucinationが起こる理由 ・適当に存在しない物を認識したり, それっぽいものをでっちあげたりする ・文脈にそぐわないフレーズを発言してしまうこと ・学習時点でのデータにデータが含まれていなのでそもそもLLMが知らないため, 不完 全な情報しか提供できない など, Halluciationを調査したpaperもあります->https://arxiv.org/pdf/2202.03629.pdf
RAG RAGはこのうち不完全な情報に対するHallucinationに対抗するための技術です。 つまり、 ・学習時点でのデータにデータが含まれていなのでそもそもLLMが知らないため, 不完 全な情報しか提供できない というHallucinationに対抗するための手法です。
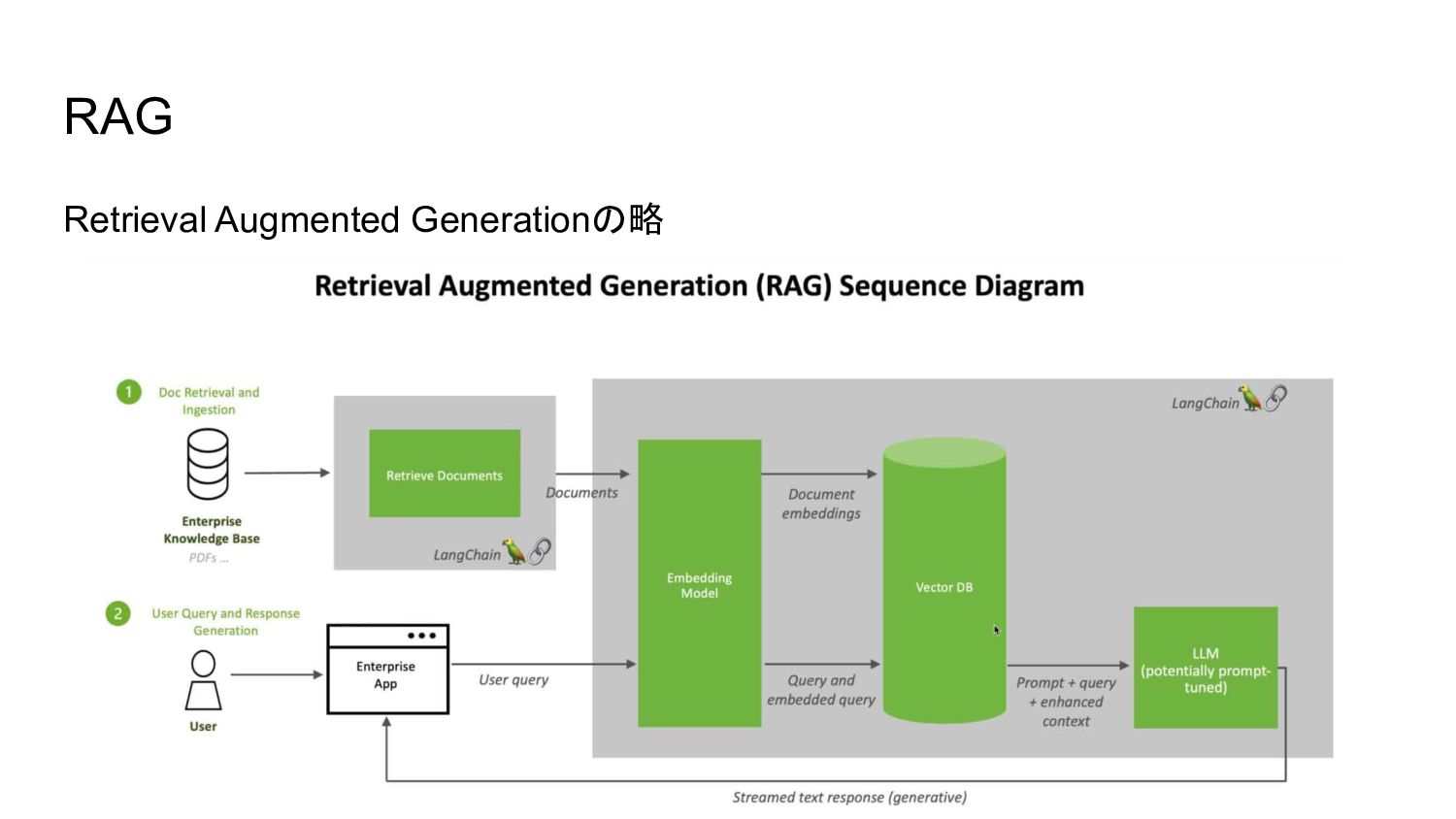
RAG Retrieval Augmented Generationの略
RAG RAGの性能は該当文章を検索するRetrieval部分で決まる。 Retrieval, つまり文書検索を上手く実装できるかが鍵 まずは基本的な技術であるベクトル検索を解説します。
ML NLP復習 ML言語モデル ->[5308, 1165, 13]->Me too. I love an
apple ->[40, 1842,22514, 13]->
ML NLP復習 ML言語モデル ->[5308, 1165, 13]->Me too. I love an
apple ->[40, 1842,22514, 13]-> ↑学習の方法にもよるが、 大抵はML言語モデルによる数値変換を経て、 似たような意味を持つ文が同じような数値表現にな る(証明, 数式的な感覚は略)
文の分散表現 ML言語モデル ->[5308, 1165, 13]->Me too. I love an apple
->[40, 1842,22514, 13]-> [0.4, -0.6, 0.8, ] ↑途中で取り出して得られた数字 を分散表現ないしはEmbedding と呼びます。
ベクトル検索 1. 同じような意味は似たような表現になる 2. 数字表現してn次元のベクトルとして捉えると同じ向きを向く 3. ちょっと難しい数式の話になるけど, n次元の内積を取って, n次元のベクトルが成す角の cosθを考えると1に近づく(cos類似度と呼びます)
4. 近い意味の単語の分散表現を取り出してきて cos類似度を文章が似ていることの指標とする。 回転焼き 大判焼き ラーメン
ベクトル検索 あるn次元の分散表現ベクトルに対してRAGの参考にしたい文章データがd個あると, 全 データとのcos類似度の計算にはO(nd)かかる ->ビックデータではdが1000万以上とかになるかも, 非常に遅い ->近似アルゴリズム&GPUで解く FAISSが有名 日本語の資料も東大の松井先生という方が公開済み->近似最近傍探索とVector DBの
理論的背景 余談: 授業でいい評価もらえたから好き
RAGの個人的な感想 ・また, 分散表現はMLモデルの訓練で決まるので, 訓練時にコーパスにない単語の分散表現は上手くいかないこともある。 ->対処法は分散表現を獲得するモデルはLLMのような大きいモデルではなくBERTなど のモデルを用いて, 対照学習(Contrast Learning)などでFine tuningなどを行う。 ->それでも欲しい情報の文章コーパスなんてないだろうから,
鶏が先か卵が先かという 疑問が残る
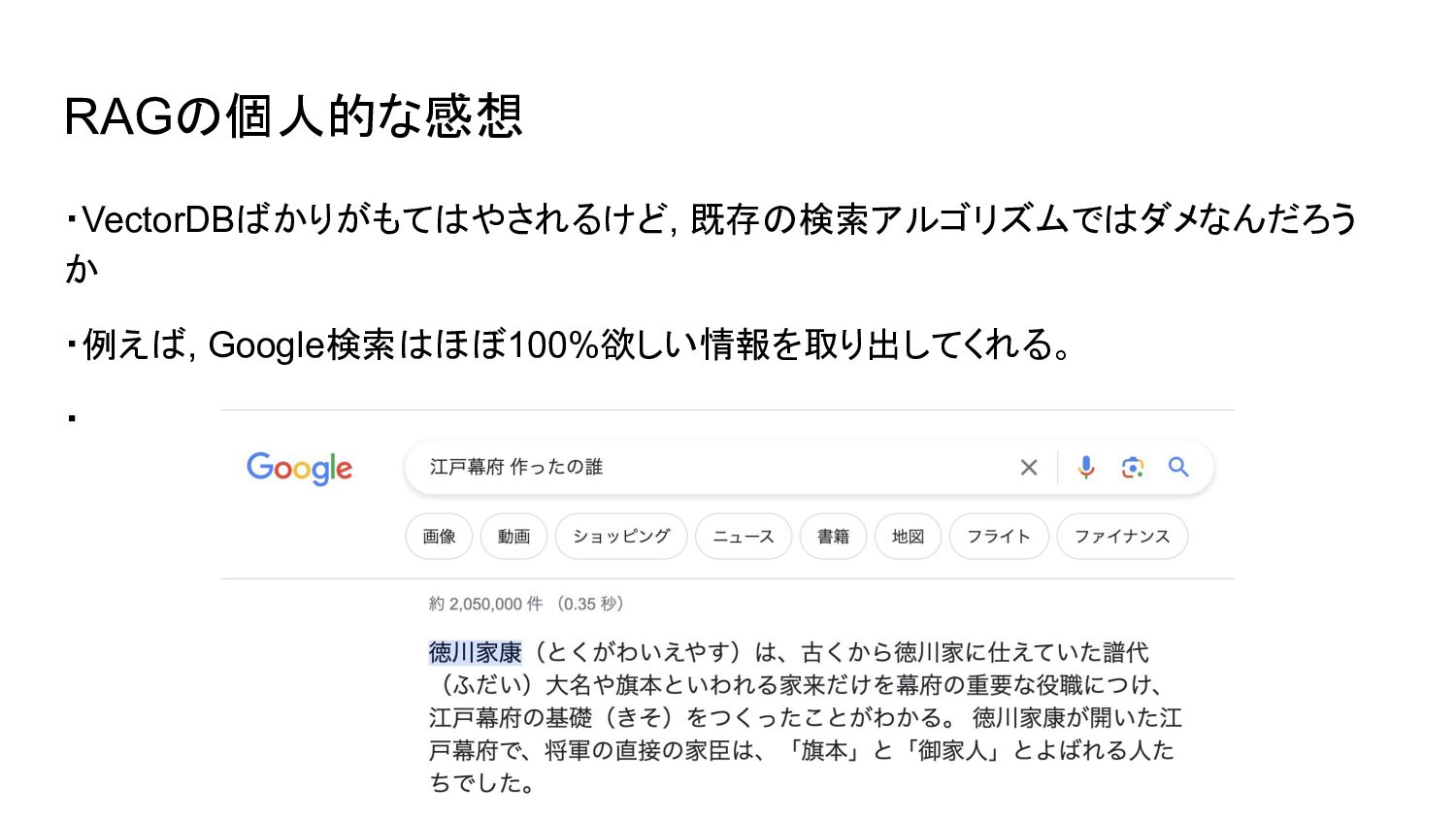
RAGの個人的な感想 ・VectorDBばかりがもてはやされるけど, 既存の検索アルゴリズムではダメなんだろう か ・例えば, Google検索はほぼ100%欲しい情報を取り出してくれる。 ・
RAGの個人的な感想 固有単語の検索ではBM25のような古典的自然言語アルゴリズムの方が強い時もある ->NNだけでなく, NLP全体を俯瞰して学んでいきましょう。 2024年3月11日(月)-3月15日(金)が言語処理学会です。是非読んでみましょう。
余談 AWS, Azure, GCPでもRAGの開発サポートをしている。ベクトル表現を貯めておくデー タベースはもちろん GCPではVertex AI Search, AzureではAzure AI
Search のように, 各社共に文書検索をラップして売り出している印象がある。 今日のハンズオンではlocalでの文書検索を主に話していきますが, 検索が上手くいくと いい性能が出ることを実感してもらえばと思います。
長々と話してきましたが... 今からコードを書いていきます。
10分休憩 14:00に再開します。 質問がある方はzoomもしくはslido でおねがいします。
Plus Ultra Weight and Biases 機械学習モデル開発者向け プラットフォーム • モデルの学習記録 •
モデル・データセットのバージョン管理 • モデルの性能評価 • 可視化 を行ってくれるサイトです。Pythonコードで 呼び出して使います。
Plus Ultra DeepSpeed 機械学習モデル開発者向け OSS, Megatron-LMと合わせて かなりデファクトスタンダードなOSS ・深層学習前半の訓練と推論の高速化ライブラリ ・省メモリ, MultiGPU,
データ通信をサポート 僕の家には8GB GPUしかないのですが, これを使うことでGPUメモリをあんま使わなく て良くなり, Transformerモデルの訓練が楽に行えるようになりました。
Plus Ultra RAGの問題点 LLMはロングコンテキストの入力になると性能が劣化する。 LangChainでの内部プロンプト実装では、、、
Plus Ultra RAGの問題点 長いコンテクスト, 回答に大量の情報を必要とするようなタスクには弱い。 こんな時は素直にLoRA, SFT, RLHFなどでFine Tuningする方が性能が出る しかしFine
TuningをするためにはGPUを自社で保有するか, GPUインスタンスを購入 するかといった問題が発生する。それに比べるとRAGは安価 ・知識ベースの回答かつ, 2, 3の情報で完全に答えられるような問題にはRAG ・大量の情報を統合し, 答えるようなタスクには自社データでFine Tuningをする方が良 い
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![2. タスクに応じて数字を変換 ML言語モデルはList<Int>の入力に対してList<Int>を返します。ここがGPTやGeminiの モデル本体がやっていることです。 ML言語モデル [40, 1842, 22514, 13]-> ->[5308,](https://files.speakerdeck.com/presentations/325b8751e40d42d5a899c8a992f4bbb2/slide_8.jpg){kind=link}
![3. 変換された数字を自然言語に復元 1.で行ったTokenizeの逆の作業を行います。 例: [5308, 1165, 13]->Me too.](https://files.speakerdeck.com/presentations/325b8751e40d42d5a899c8a992f4bbb2/slide_9.jpg){kind=link}
![全体の概観 ML言語モデル ->[5308, 1165, 13]->Me too. I love apples. ->[40,](https://files.speakerdeck.com/presentations/325b8751e40d42d5a899c8a992f4bbb2/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ML NLP復習 ML言語モデル ->[5308, 1165, 13]->Me too. I love an](https://files.speakerdeck.com/presentations/325b8751e40d42d5a899c8a992f4bbb2/slide_25.jpg){kind=link}
![ML NLP復習 ML言語モデル ->[5308, 1165, 13]->Me too. I love an](https://files.speakerdeck.com/presentations/325b8751e40d42d5a899c8a992f4bbb2/slide_26.jpg){kind=link}
![文の分散表現 ML言語モデル ->[5308, 1165, 13]->Me too. I love an apple](https://files.speakerdeck.com/presentations/325b8751e40d42d5a899c8a992f4bbb2/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}