Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
研究室紹介用スライド: Unified Memoryを活⽤した効率的な計算⽅法を考えよう
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
SuperHotDog
January 09, 2025
120
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
研究室紹介用スライド: Unified Memoryを活⽤した効率的な計算⽅法を考えよう
SuperHotDog
January 09, 2025
More Decks by SuperHotDog
See All by SuperHotDog
LLM高速化勉強会資料
superhotdogcat
8
2.8k
Dockerの裏側を攻める
superhotdogcat
0
38
SigLIP
superhotdogcat
1
140
post-training
superhotdogcat
3
640
大規模モデル計算の裏に潜む 並列分散処理について
superhotdogcat
1
84
オンプレソロプレイ
superhotdogcat
0
100
CUDAを触ろう
superhotdogcat
0
140
GemmaでRAG を作ろう
superhotdogcat
1
720
Featured
See All Featured
Technical Leadership for Architectural Decision Making
baasie
3
450
Building Applications with DynamoDB
mza
96
7.1k
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
230
How to make the Groovebox
asonas
2
2.3k
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
350
Build The Right Thing And Hit Your Dates
maggiecrowley
39
3.4k
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
HDC tutorial
michielstock
2
760
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
240
Darren the Foodie - Storyboard
khoart
PRO
3
3.5k
Odyssey Design
rkendrick25
PRO
2
740
Making Projects Easy
brettharned
120
6.7k
Transcript
Unified Memoryを活⽤した効 率的な計算⽅法を考えよう SuperHotDogCat
宣伝: GB10 NVIDIA Project DIGITS(3000$)
親の顔より⾒たエラー
何故起きるのか ・GPUメモリが⾜り ない →複数枚積めばいい のか?
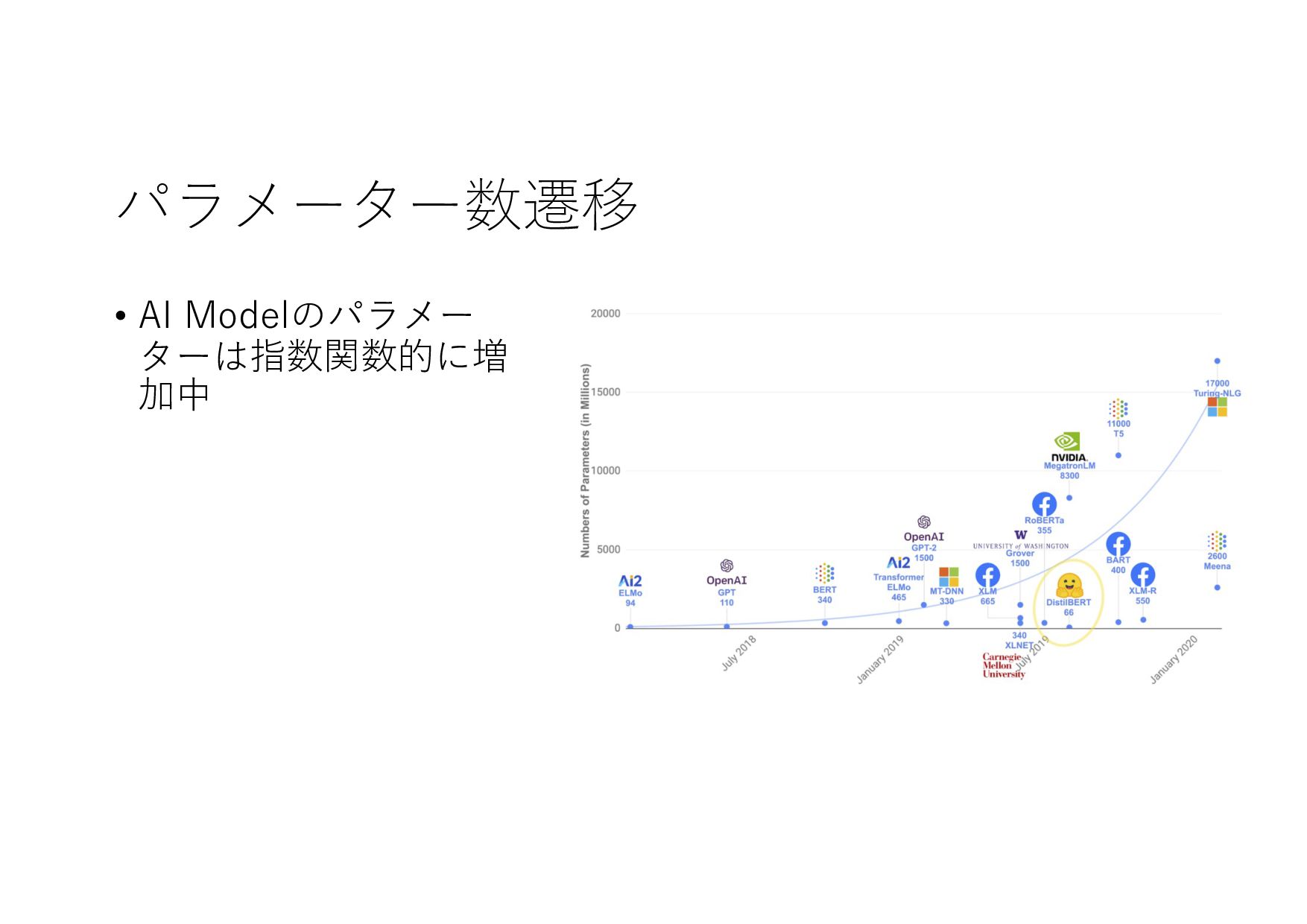
パラメーター数遷移 • AI Modelのパラメー ターは指数関数的に増 加中
VRAMは? ・V100 32GB(2017) ・A100 80GB(2020) ・H100 80GB(2022) ・H200 141GB(2024) ・B200
180GB/192GB(2024) ・1B Model → float32で4GB, fullでの訓練はAdam Optimizerで 16倍ぐらいになるので64GB必要 ・100B Modelで6.4TBのGPU必要 ・1T Modelだと640TB, 苦しい
省メモリへのアプローチ ・量⼦化(1/2~1/4倍削減), 枝刈り(1/2倍削減程度)←精度劣化が 避けられない, 枝刈りは推論のみでしか使えない(Edgeデバイス では依然として重要) ・アルゴリズム的な削減 ・再計算(Gradient Checkpointing) ・Flash
attention ↑厳密計算かつメモリ削減でGood ・複数台に分散 ・Megatron-LM, Deepspeedなどが開発ではよく使われる
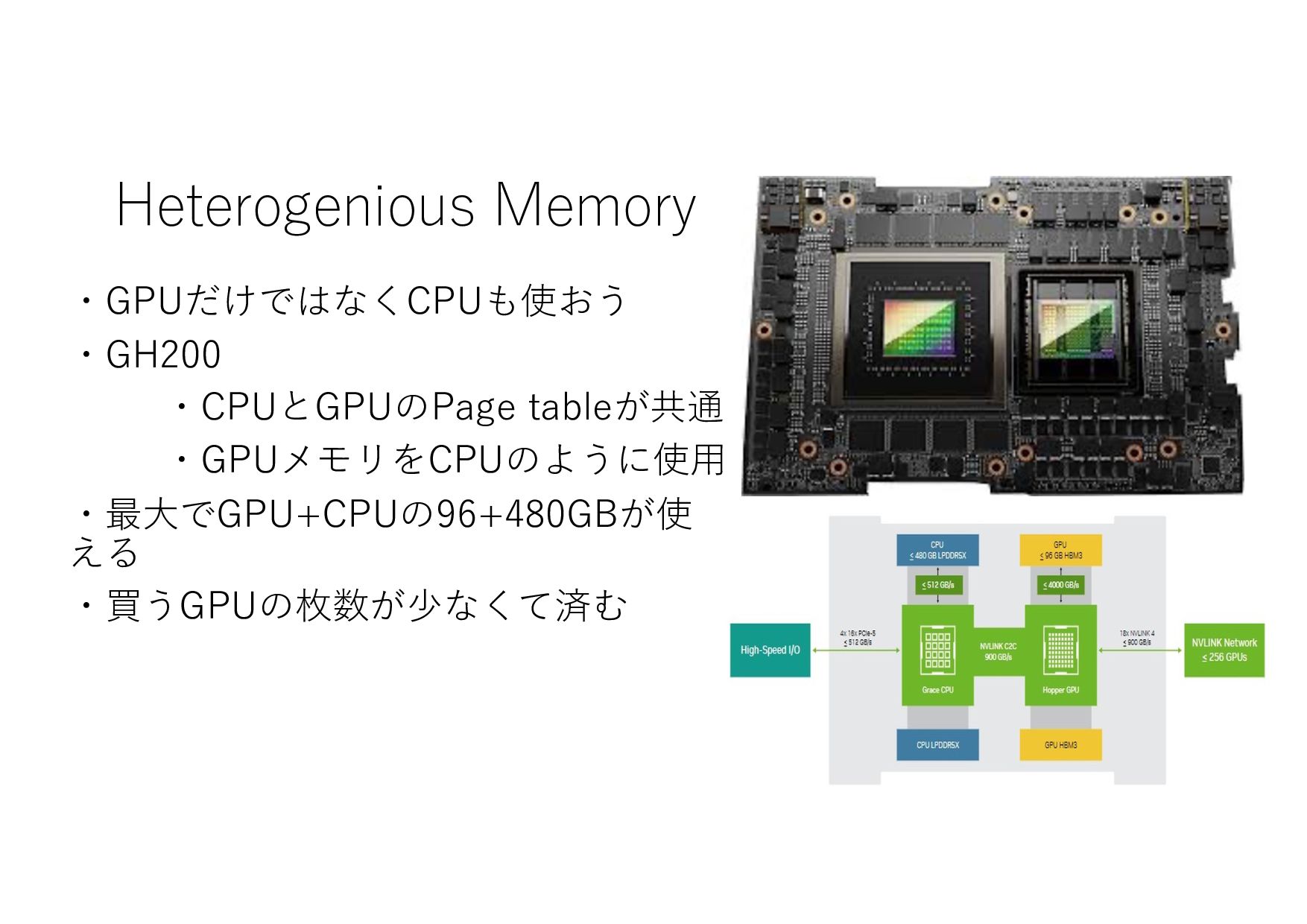
Heterogenious Memory ・GPUだけではなくCPUも使おう ・GH200 ・CPUとGPUのPage tableが共通 ・GPUメモリをCPUのように使⽤ ・最⼤でGPU+CPUの96+480GBが使 える ・買うGPUの枚数が少なくて済む
問題点 ・ソフトウェア上はGPUとCPUのメモリが同じように使える ・物理メモリ的にどこに割り当てられているかで速度低下などが 起きる←速度向上のためにGPUを使うのだから本末転倒 ・頑張って両⽴する
宣伝: GB10 NVIDIA Project DIGITS(3000$)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}