Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
大規模モデル計算の裏に潜む 並列分散処理について
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
SuperHotDog
November 11, 2024
84
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
大規模モデル計算の裏に潜む 並列分散処理について
SuperHotDog
November 11, 2024
More Decks by SuperHotDog
See All by SuperHotDog
LLM高速化勉強会資料
superhotdogcat
8
2.8k
Dockerの裏側を攻める
superhotdogcat
0
38
SigLIP
superhotdogcat
1
140
post-training
superhotdogcat
3
640
研究室紹介用スライド: Unified Memoryを活⽤した効率的な計算⽅法を考えよう
superhotdogcat
0
120
オンプレソロプレイ
superhotdogcat
0
100
CUDAを触ろう
superhotdogcat
0
140
GemmaでRAG を作ろう
superhotdogcat
1
720
Featured
See All Featured
Designing Powerful Visuals for Engaging Learning
tmiket
1
470
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
750
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
310
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
The Art of Programming - Codeland 2020
erikaheidi
57
14k
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
580
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
240
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.5k
Accessibility Awareness
sabderemane
1
170
30 Presentation Tips
portentint
PRO
1
360
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.5k
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
620
Transcript
大規模モデル計算の裏に潜む 並列分散処理について [公開用]
$whoami 名前: 犬(SSR🐈) 東大工学部電子情報工学科四年 HPCの研究をしています X: @takanas0517
この登壇資料を制作しようと思ったモチベ ・OpenAIがGPUサーバーを3万台調達, GPUを50万枚調達などのニュースを見て ウオースゲーと驚くことは誰でもできる ・ただし実際のところその大多数のコン ピューターを協働させて動かすにはどういう 仕組みがあるのか, それを理解している学 生は少ないのではないか, そう思い少し作
成した ・一応登壇者は576ノードのMPI並列化なら したことはある xAIにDGXを運ぶNVIDIA CEO OpenAIにDGXを運ぶNVIDIA CEO
今日のおしながき ・並列分散処理が何故必要なのか ・並列分散処理プログラムの内部 ・並列分散処理プログラムを書くための武器 ・並列分散処理民主化のための個人的な取り組み
並列分散処理が何故必要なのか 大きなメリットとしては ・速度 →沢山のCPUを動かせた方が早い‼ ・メモリ消費削減 →沢山のCPUに分散させて配置させたら 1CPUあたりのメモリ消費量は減る‼
並列分散処理が何故必要なのか: 速度編 ・スパコンで実際に計算を扱うCPUコア数は増 え続けている ・Auroraは9,264,128コア →神奈川県の人口程度 ・Fugakuで7,630,848コア →埼玉県の人口程度 関東近郊の県民全員が一斉に計算を始める top500.org
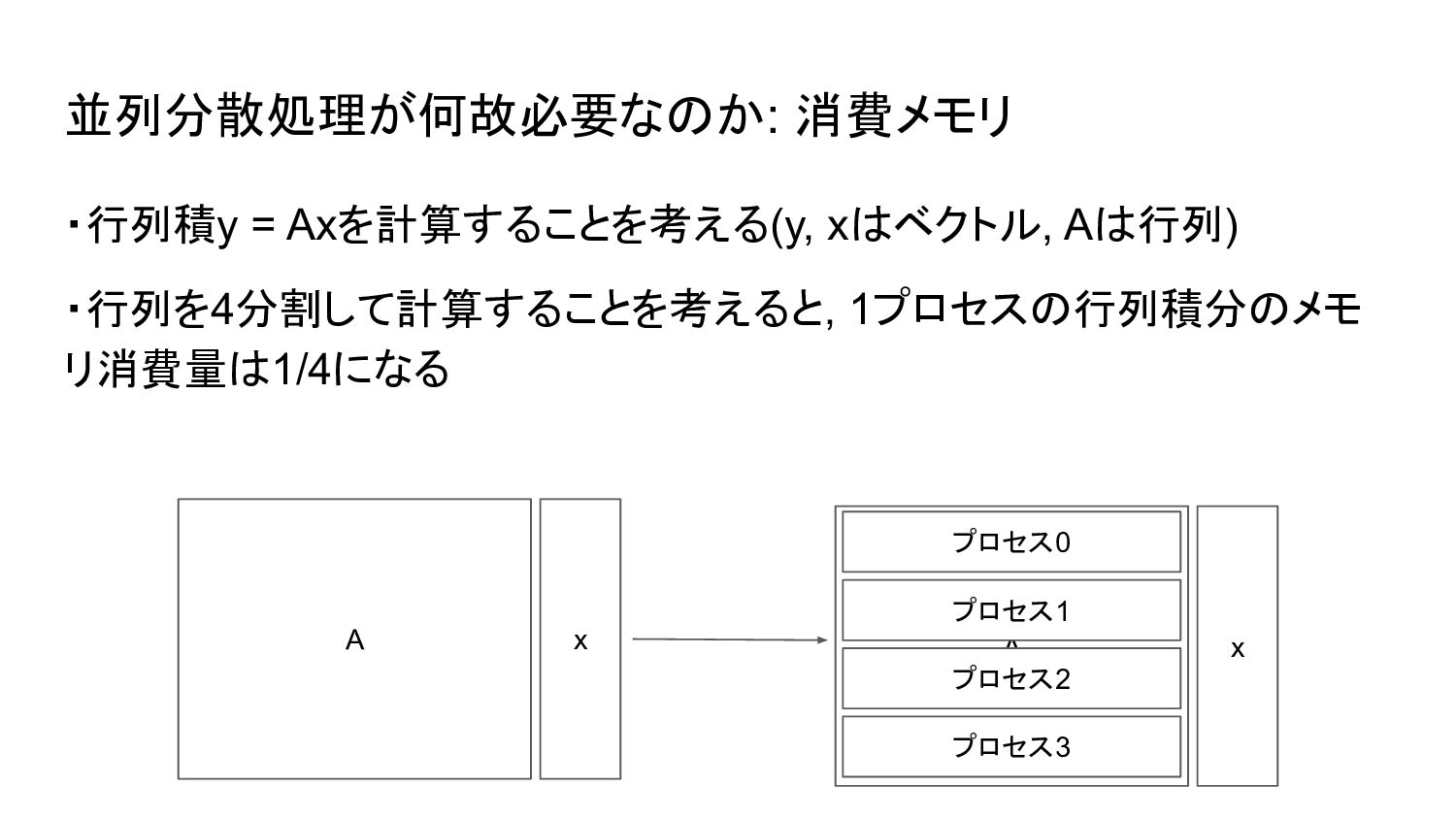
並列分散処理が何故必要なのか: 消費メモリ ・行列積y = Axを計算することを考える(y, xはベクトル, Aは行列) ・行列を4分割して計算することを考えると, 1プロセスの行列積分のメモ リ消費量は1/4になる
A x A x プロセス0 プロセス1 プロセス2 プロセス3
並列分散処理が何故必要なのか: 消費メモリ ・大規模モデルの文脈の話をすると, 最近では10B, 100B, 1Tパラメータークラスのモ デルが出てきている ・それぞれfloat32のパラメーターだとすると40GB, 400GB, 4TBのGPUメモリが必要に
なる ・最先端のH200でカタログスペックだと141GB程度のVRAMしかない ・実際にはモデルパラメーターだけではなく, 訓練途中の誤差逆伝播法アルゴリズムな どによりモデルパラメーターの定数倍分だけ使用メモリは増える →並列分散は必須 数字が大きすぎて定数倍の増加でも致命的なほどVRAMを使用する
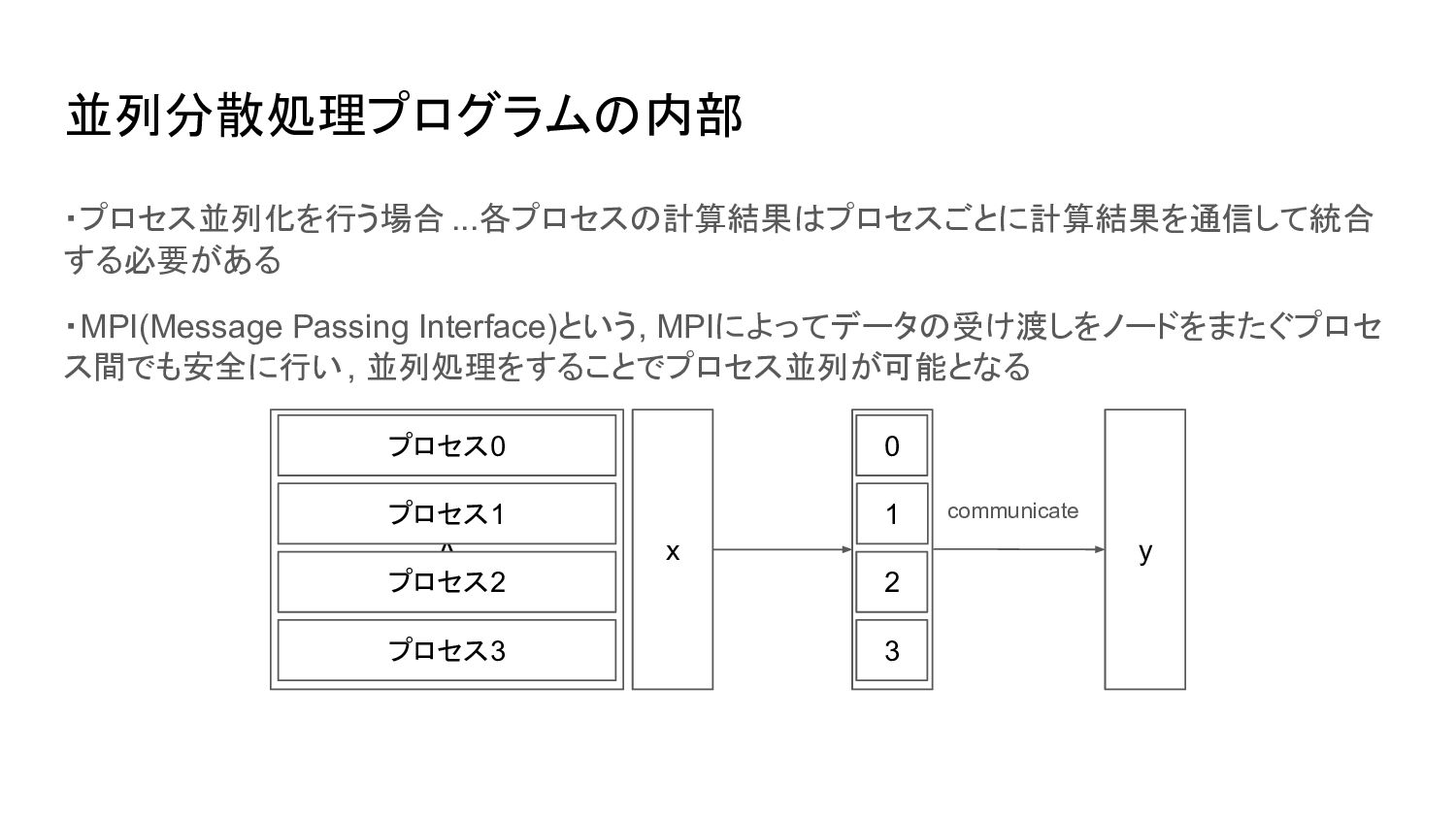
並列分散処理プログラムの内部 ・プロセス並列化を行う場合 ...各プロセスの計算結果はプロセスごとに計算結果を通信して統合 する必要がある ・MPI(Message Passing Interface)という, MPIによってデータの受け渡しをノードをまたぐプロセ ス間でも安全に行い, 並列処理をすることでプロセス並列が可能となる
A x プロセス0 プロセス1 プロセス2 プロセス3 0 1 2 3 y communicate
並列分散処理プログラムの内部 ・さらに, プロセス内でもスレッド並列化が可能で ある ・OpenMPやGPUで高速処理を実現している ・特に, AIの計算処理はGPUの得意とする演算と 相性が良い →NVIDIAのGPUは特にハードウェアの効率化も すごい
e.g. メモリ通信帯域, GPUコアの利用効率向上 最適化, Tensor core A6000
None
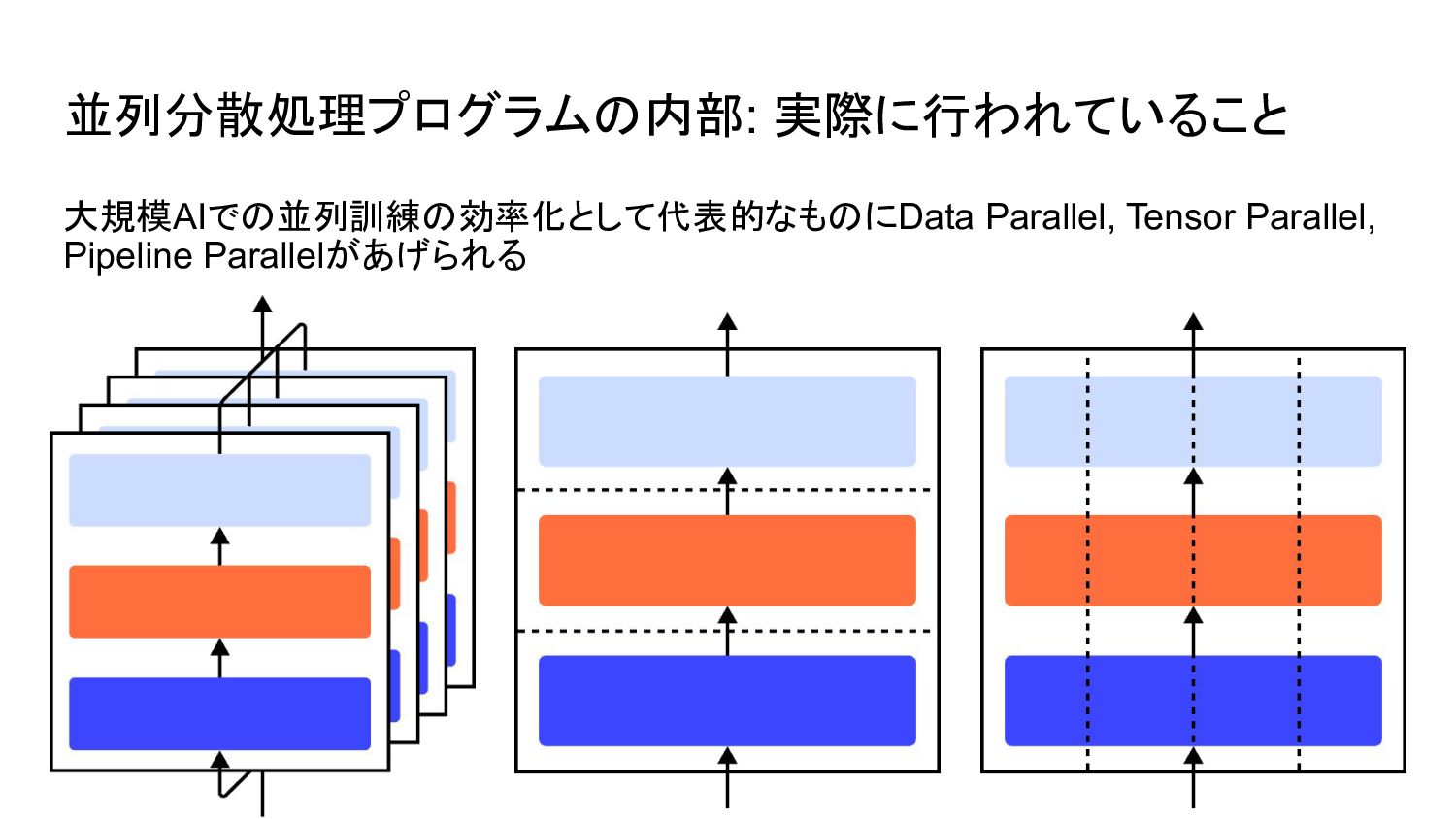
並列分散処理プログラムの内部: 実際に行われていること 大規模AIでの並列訓練の効率化として代表的なものにData Parallel, Tensor Parallel, Pipeline Parallelがあげられる
ちょっと機械学習の用語整理(詳しい算数の話は抜き) ・forward ・データを流して計算を行う作業 ・gradient ・AIのパラメーターを正しい方向に移動させるための情報, forwardで得た結果から 計算される ・backward ・gradientを使って実際にパラメーターを更新する作業
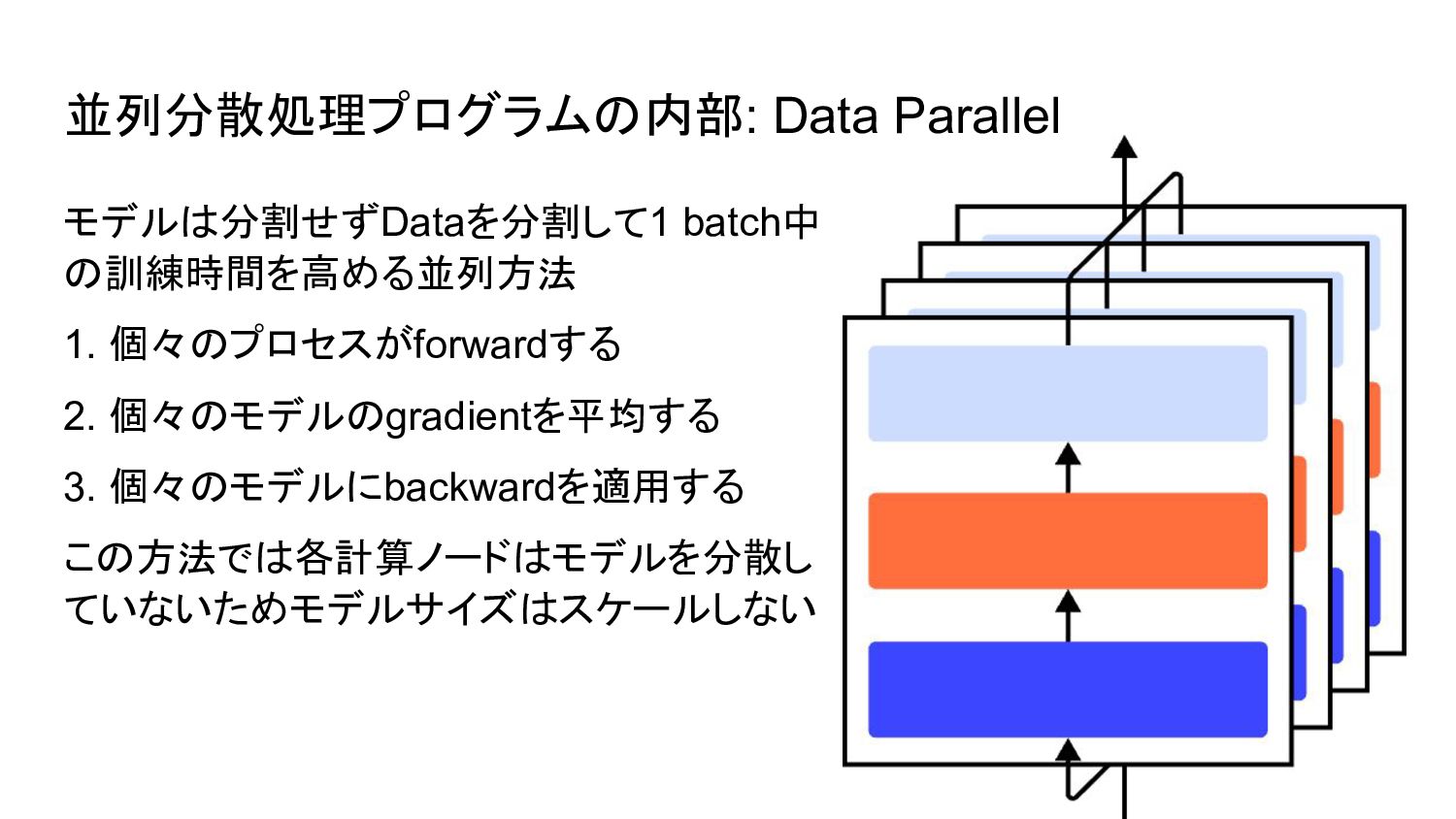
並列分散処理プログラムの内部: Data Parallel モデルは分割せずDataを分割して1 batch中 の訓練時間を高める並列方法 1. 個々のプロセスがforwardする 2. 個々のモデルのgradientを平均する
3. 個々のモデルにbackwardを適用する この方法では各計算ノードはモデルを分散し ていないためモデルサイズはスケールしない
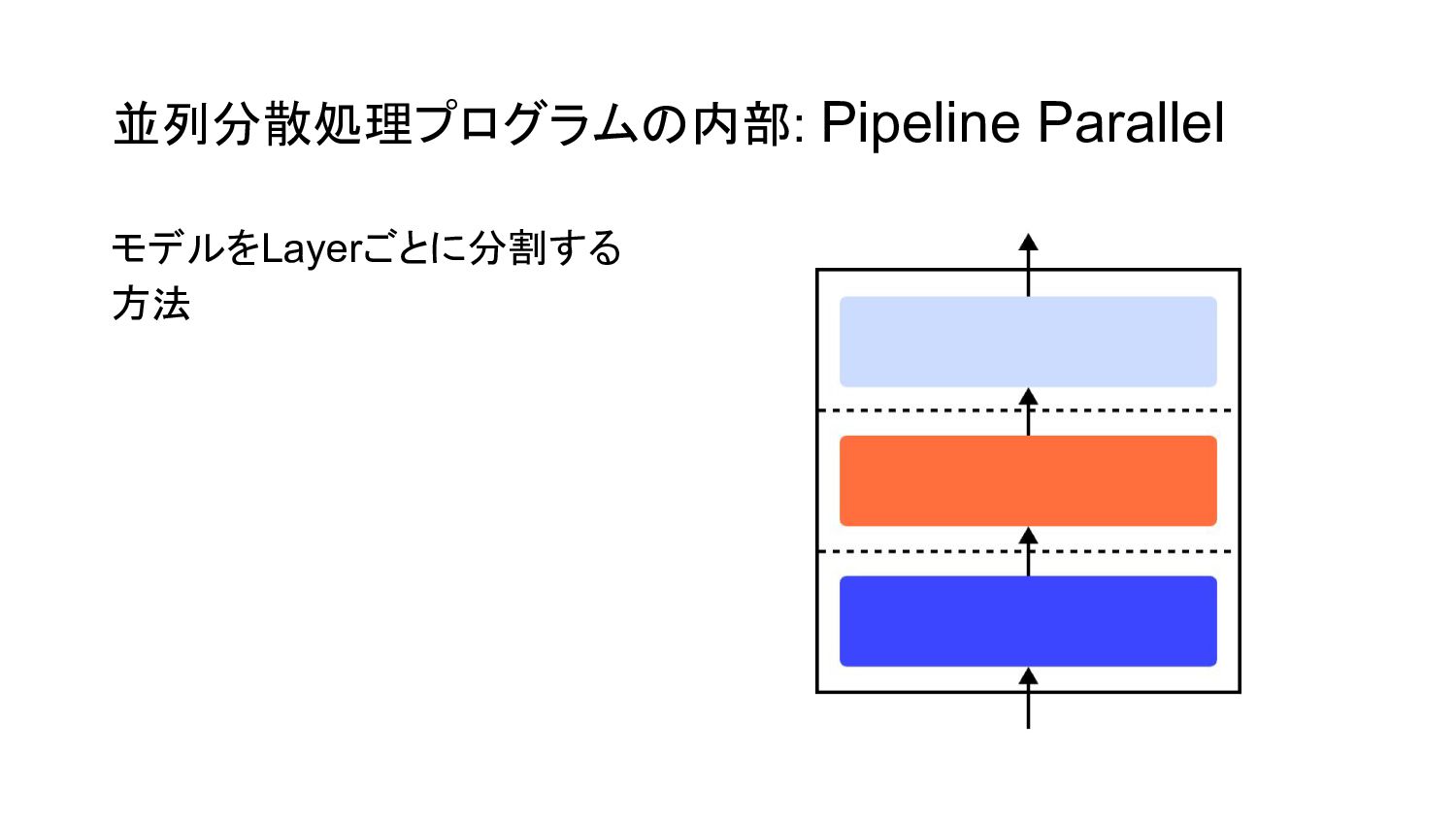
並列分散処理プログラムの内部: Pipeline Parallel モデルをLayerごとに分割する 方法
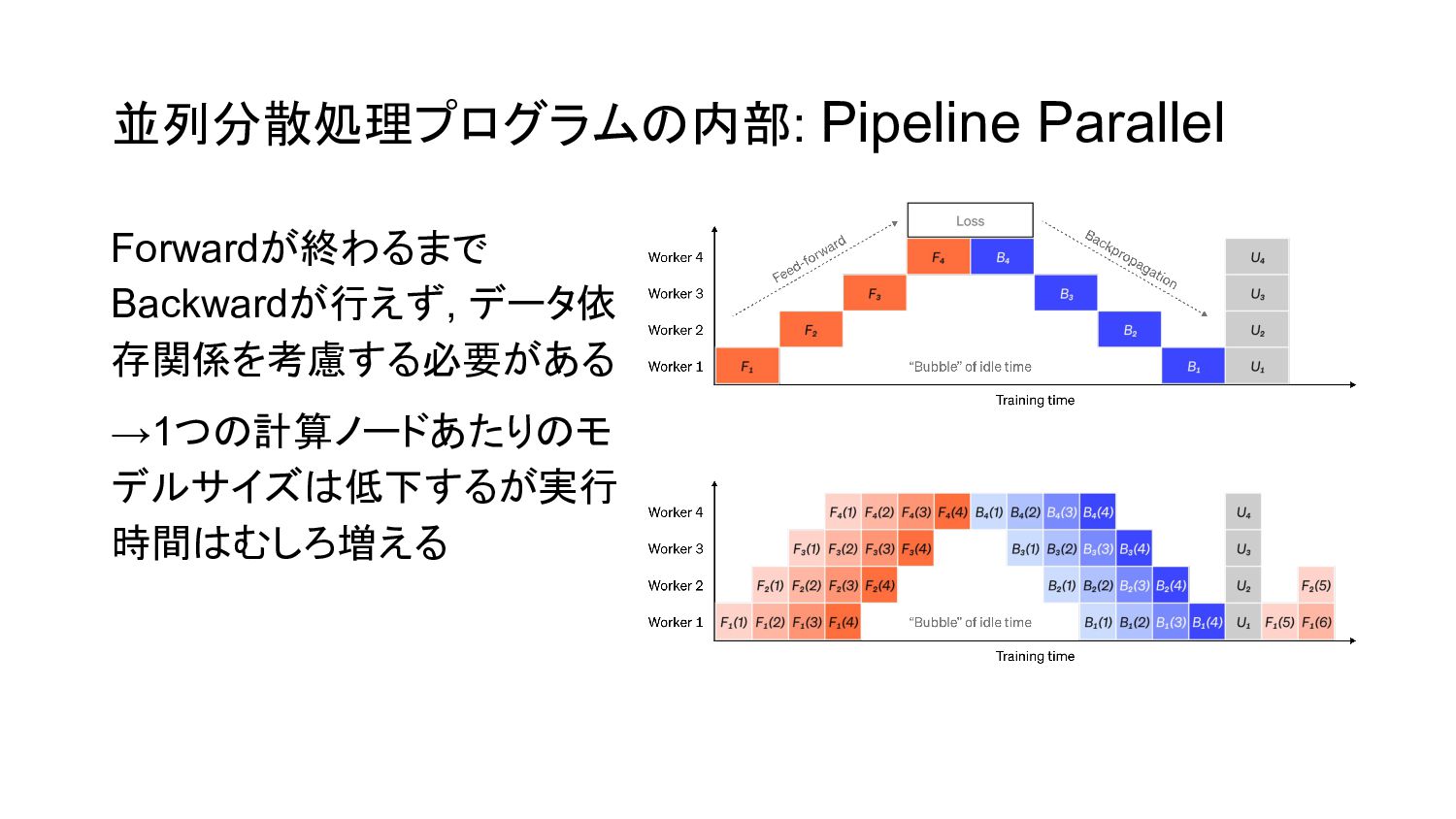
並列分散処理プログラムの内部: Pipeline Parallel Forwardが終わるまで Backwardが行えず, データ依 存関係を考慮する必要がある →1つの計算ノードあたりのモ デルサイズは低下するが実行 時間はむしろ増える
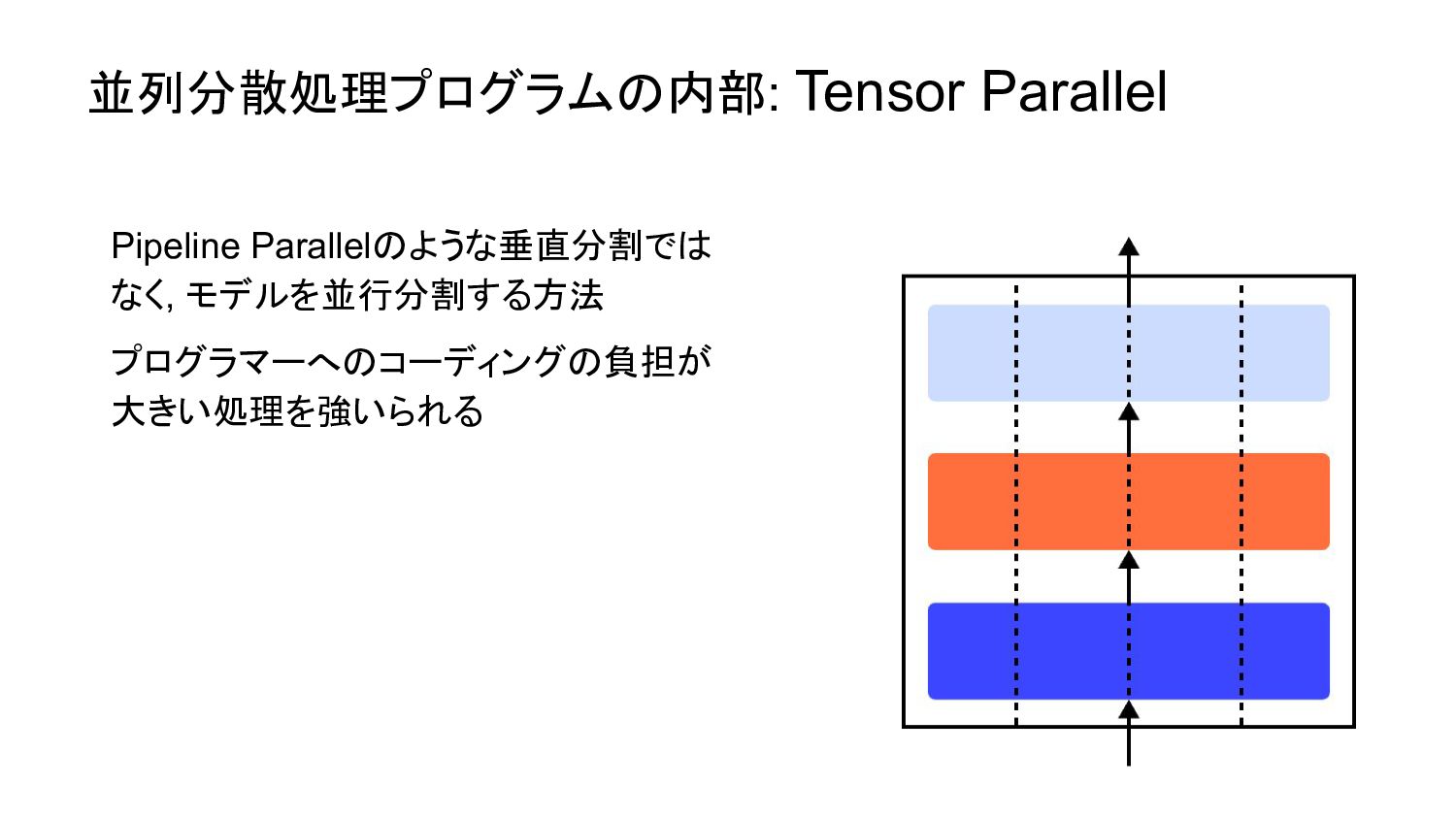
並列分散処理プログラムの内部: Tensor Parallel Pipeline Parallelのような垂直分割では なく, モデルを並行分割する方法 プログラマーへのコーディングの負担が 大きい処理を強いられる
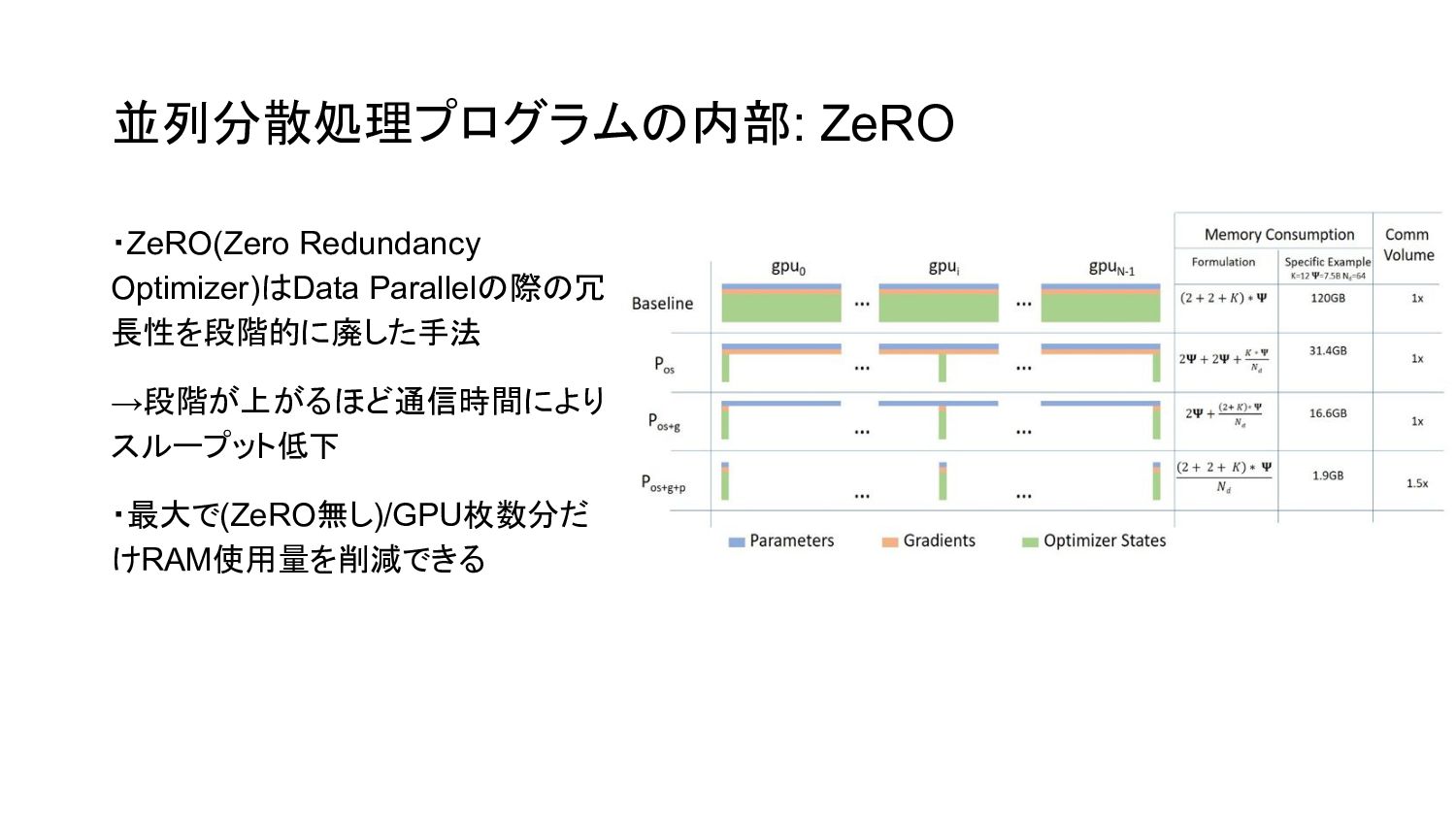
並列分散処理プログラムの内部: ZeRO ・ZeRO(Zero Redundancy Optimizer)はData Parallelの際の冗 長性を段階的に廃した手法 →段階が上がるほど通信時間により スループット低下 ・最大で(ZeRO無し)/GPU枚数分だ
けRAM使用量を削減できる
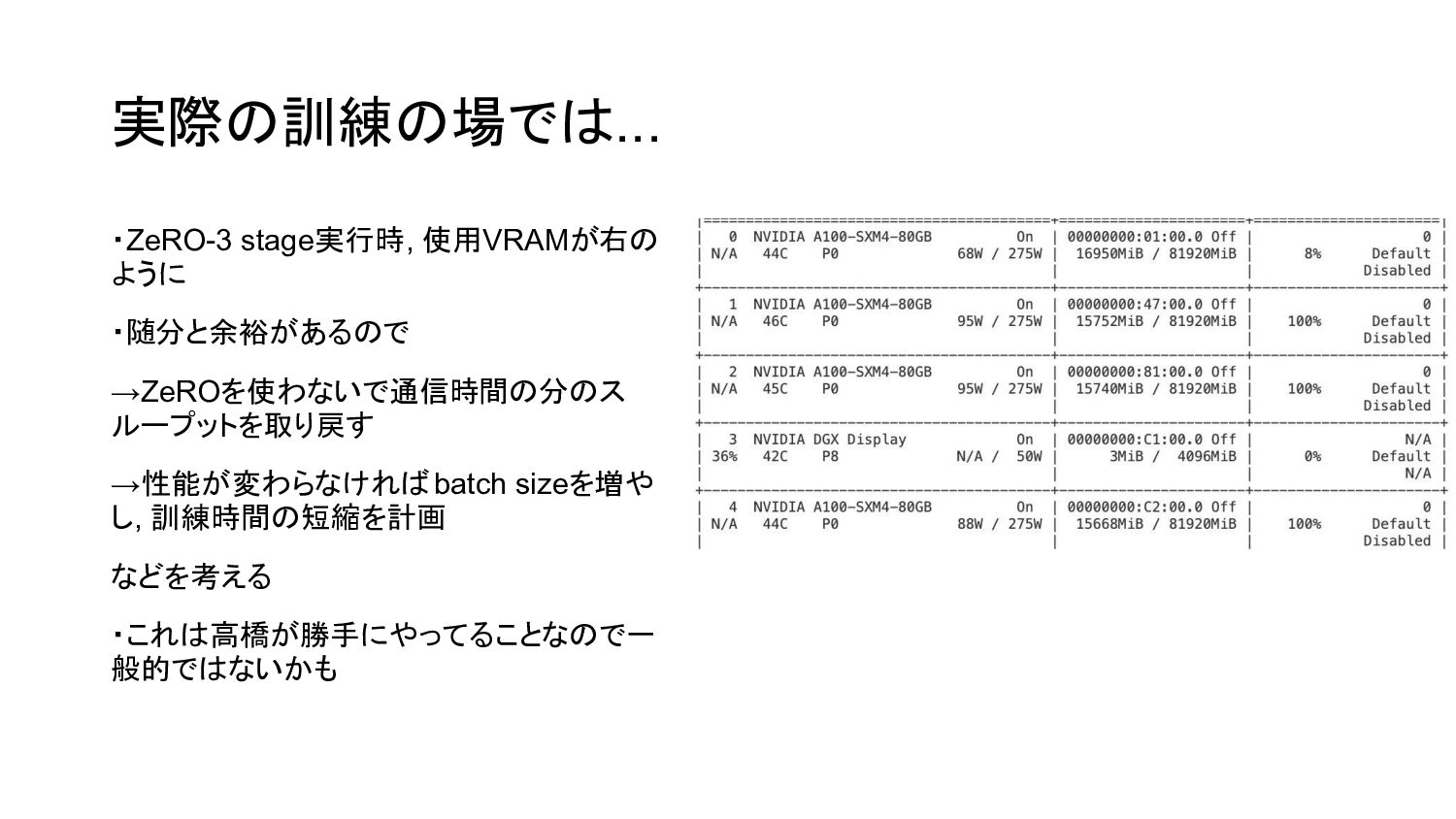
実際の訓練の場では... ・ZeRO-3 stage実行時, 使用VRAMが右の ように ・随分と余裕があるので →ZeROを使わないで通信時間の分のス ループットを取り戻す →性能が変わらなければbatch sizeを増や
し, 訓練時間の短縮を計画 などを考える ・これは高橋が勝手にやってることなので一 般的ではないかも
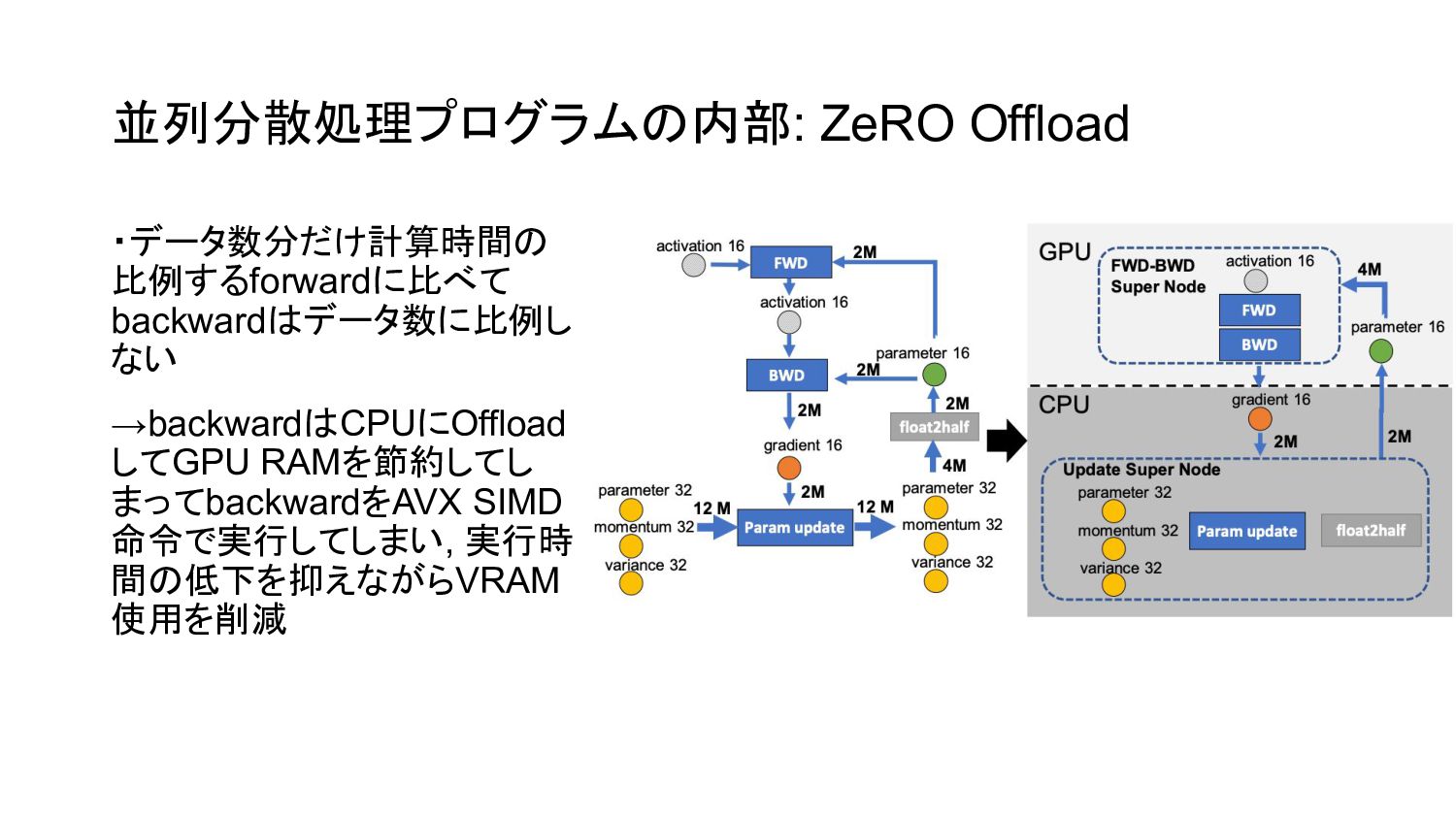
並列分散処理プログラムの内部: ZeRO Offload ・データ数分だけ計算時間の 比例するforwardに比べて backwardはデータ数に比例し ない →backwardはCPUにOffload してGPU RAMを節約してし
まってbackwardをAVX SIMD 命令で実行してしまい, 実行時 間の低下を抑えながらVRAM 使用を削減
並列分散処理プログラムを書くための武器 ・ハードウェアの用意 NVIDIAの商売根性は逞しく, GPU, OS setup, 環境構築が済み, しかも GPU間通信も高速なNVLinkで接続 されており,
通信帯域の最適化も済ん でいるDGXを買うのが一番早い カスタマイズしたい人はパーツごとに 買おう(できるのかな)
並列分散処理プログラムを書くための武器 ・ソフトウェア面 実際は下記のフレームワークの使用で事足りることは多い ・Deepspeed(by Microsoft) ・MegatronLM(by NVIDIA) ・Accelerate(by Hugging Face)
ただし内部で何が行われているかを理解することは, 速度, RAM使用量, AIだと意 図している学習になっているか は非常に重要, AI時代でもボトルネックを改善して いくことと自分がどういう作業をしているのかを根本で理解していく能力は重要だと 思う
並列分散処理民主化のための個人的な取り組み 別にAIに限ったことではないんですが, 学生が自由に使えるコンパクトな複数 サーバー環境が必要かなとか考えていたりします これがあると, AIに限らず ・Kubernetesクラスタ制作 ・Load balancer制作 ・Ansibleで遊んでみる
など, 実世界の大規模システムをスモールスケールではあるけども体験すること ができます
並列分散処理民主化のための個人的な取り組み: マイコンサーバー ・東大ではエンジニアがマイコンサーバーを制作し て複数台のコンピューターを協働する処理ができな いかという活動をしています ・今までは3層アーキテクチャの作成, Kubernetes クラスタの作成などを行いました ・いずれGPU付きのJetsonマイコンを買い, GPUを
使った並列分散処理の民主化もできないものかと 考えています
その他 その他の高速技術に関する技術とフレームワークとして.... ・KV cache ・vllm ・TensorRT-LLM ・llama.cpp などがあるが, 割愛
その他: 並列分散処理を深く学びたい人向けの資料 ・MPI「超」入門 ・東大情報基盤センターの資料 ・Parallel and Distributed Programming ・うちのボスの講義 ,
コードはこちら<-なんでうちのボスは C++/CUDAでDNNを実装できるんだ .... ・並列プログラミング入門: サンプルプログラムで学ぶOpenMPとOpenACC ・スパコンプログラミング入門: 並列処理とMPIの学習 ・どっちも本です ・CUDA C++ Programming Guide ・CUDAを書くなら公式ドキュメントは必見 ・NVIDIA社員ブログ と Anthropicのブログ ・プロの並列分散処理と naiveな並列分散処理では 100倍も速度が違う, どうすれば効果的なコードがかけるのかを解説している
Reference 1. Microsoft: ZeRO: Memory Optimizations Toward Training Trillion Parameter
Models 2. Microsoft: ZeRO-Offload: Democratizing Billion-Scale Model Training 3. NVIDIA: NVIDIA H200 Tensor core GPU 4. 東京大学情報基盤センター: 30分でだいたいわかる並列プログラミング 5. TOP500 List - June 2024 6. OpenAI: Techniques for training large neural networks
![大規模モデル計算の裏に潜む 並列分散処理について [公開用]](https://files.speakerdeck.com/presentations/5e3f3c3c6aae4446881d1e1157e168b8/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}