Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Paper Introduction] Robotic Manipulation by Im...
Search
T. Kuwada
July 16, 2025
0
42
[Paper Introduction] Robotic Manipulation by Imitating Generated Videos Without Physical Demonstrations
2025/07/16
Paper introduction@TanichuLab
https://sites.google.com/view/tanichu-lab-ku/
T. Kuwada
July 16, 2025
Tweet
Share
Featured
See All Featured
Large-scale JavaScript Application Architecture
addyosmani
515
110k
The agentic SEO stack - context over prompts
schlessera
0
650
Build The Right Thing And Hit Your Dates
maggiecrowley
39
3k
Bootstrapping a Software Product
garrettdimon
PRO
307
120k
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
Introduction to Domain-Driven Design and Collaborative software design
baasie
1
590
Product Roadmaps are Hard
iamctodd
PRO
55
12k
Speed Design
sergeychernyshev
33
1.5k
WCS-LA-2024
lcolladotor
0
450
Mozcon NYC 2025: Stop Losing SEO Traffic
samtorres
0
150
A Tale of Four Properties
chriscoyier
162
24k
Designing for Performance
lara
610
70k
Transcript
論文紹介: Robotic Manipulation by Imitating Generated Videos Without Physical Demonstrations
Symbol Emergence System Lab. Name: Taiki Kuwada 1
論文情報 • Title: Robotic Manipulation by Imitating Generated Videos Without
Physical Demonstrations • Author: Shivansh Patel et al. • Pub. date: 29 May 2025, FMEA @ CVPR 2025 Oral • Link: https://arxiv.org/abs/2507.00990 2
背景 • 問題提起 • マニュピレーションタスクにおけるロボットの実データを取集することは大 変。 • 特に、データ収集時に実験環境(ロボットの種類やカメラ位置など)を厳密に 揃えながら行う必要があることが大変。 •
背景 • 最新の動画生成モデルであるSORAやKlingを使うことで、言語と画像を入力 として現実と遜色ない動画を生成できる。 • しかし、生成された動画は一見よく見えても実行不可能な動画も多く、先行 研究では実データと組み合わせるなどの工夫がなされている。 3
研究目標 • 研究目標 • この論文では、タスクに特化しているような実データを使わずに、生 成された動画だけを使ってマニュピレーションタスクを可能にするこ とを目標としている。 • 貢献 •
生成した動画だけで実世界でのタスクを可能にするモデルの提案 • 生成した動画が実際の動画と同等の性能を発揮することの検証 • 6Dの物体軌跡を利用して動作を決定することの優位性を検証 4
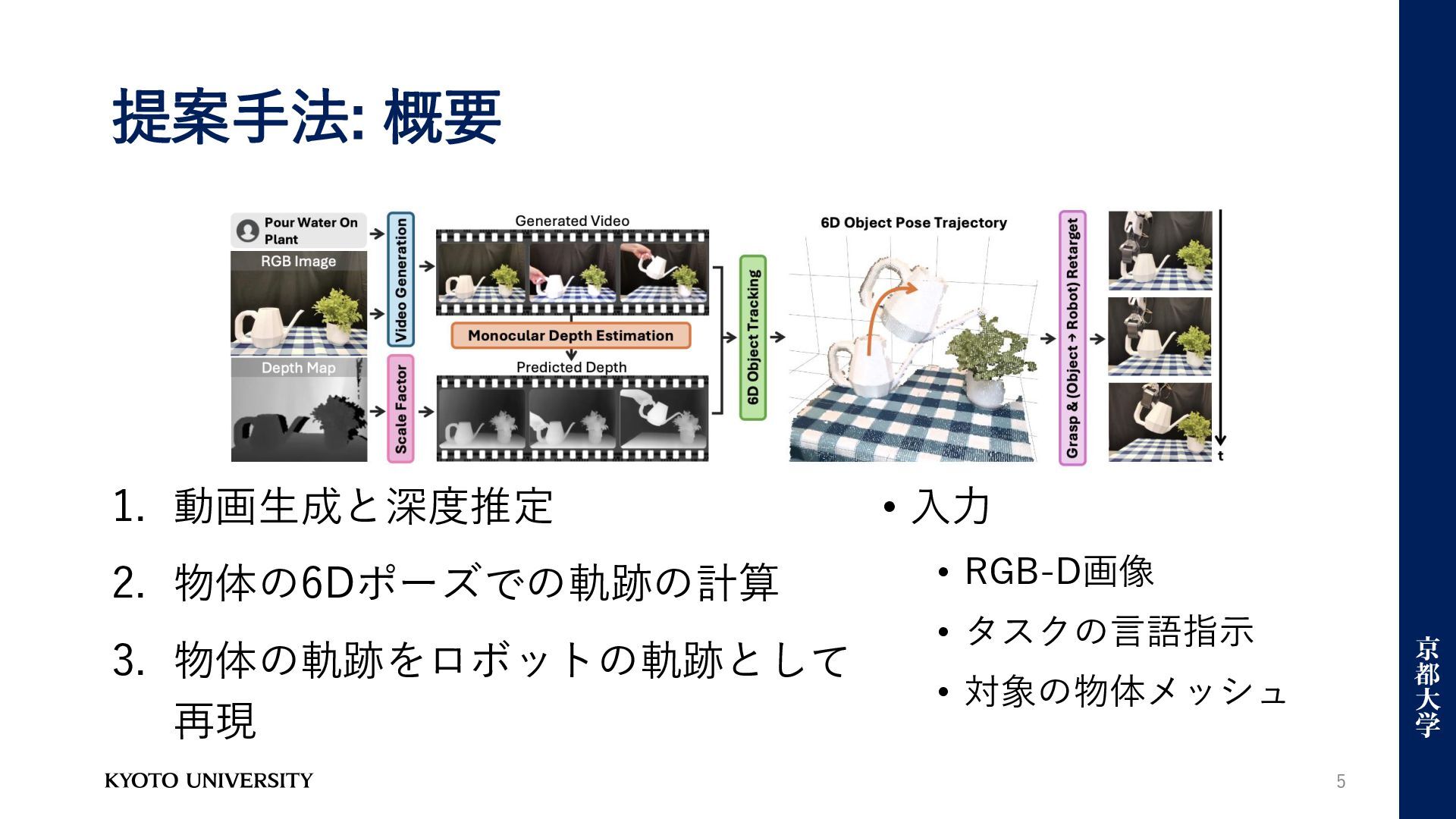
提案手法: 概要 1. 動画生成と深度推定 2. 物体の6Dポーズでの軌跡の計算 3. 物体の軌跡をロボットの軌跡として 再現 5
• 入力 • RGB-D画像 • タスクの言語指示 • 対象の物体メッシュ
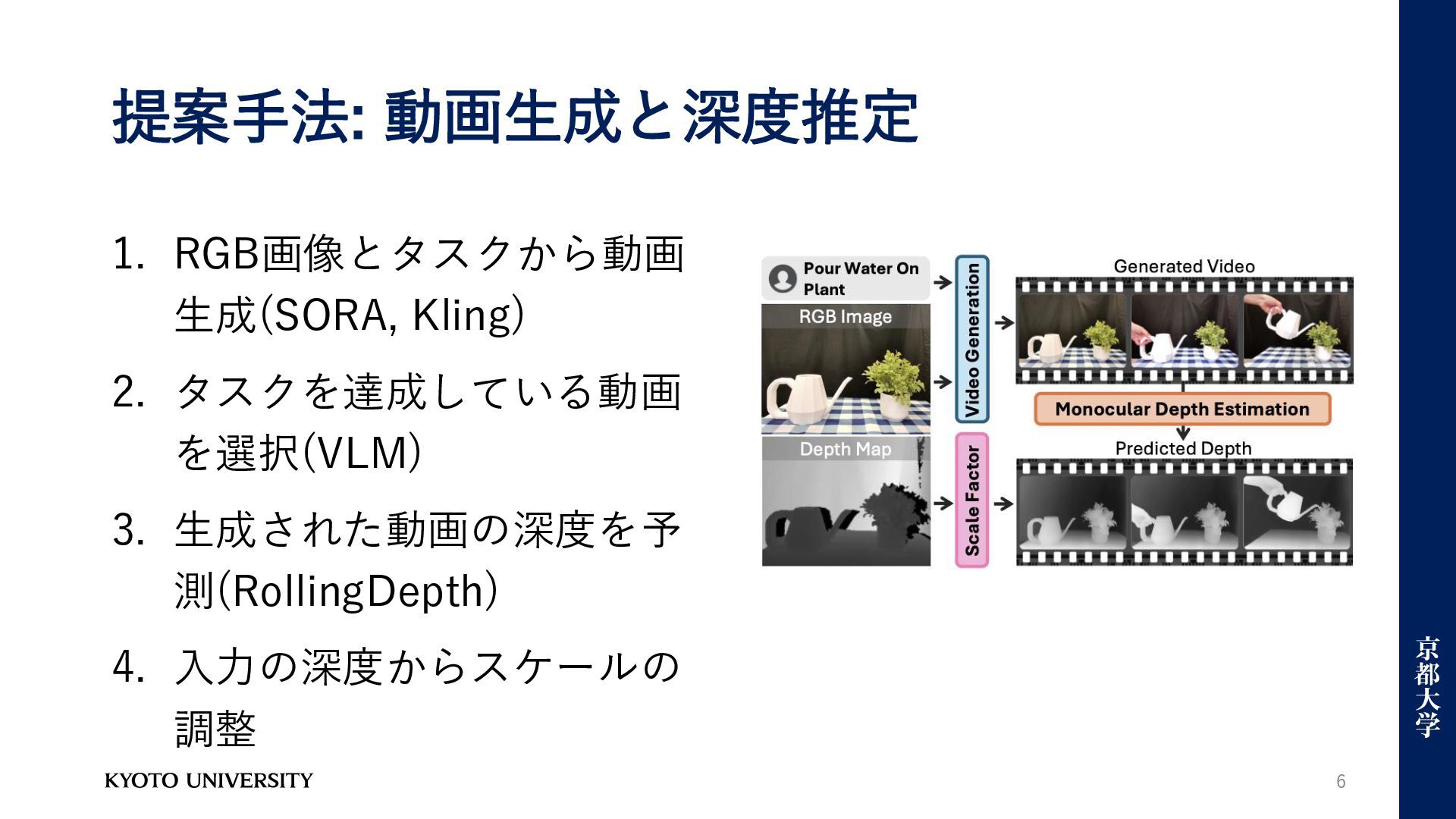
提案手法: 動画生成と深度推定 6 1. RGB画像とタスクから動画 生成(SORA, Kling) 2. タスクを達成している動画 を選択(VLM)
3. 生成された動画の深度を予 測(RollingDepth) 4. 入力の深度からスケールの 調整
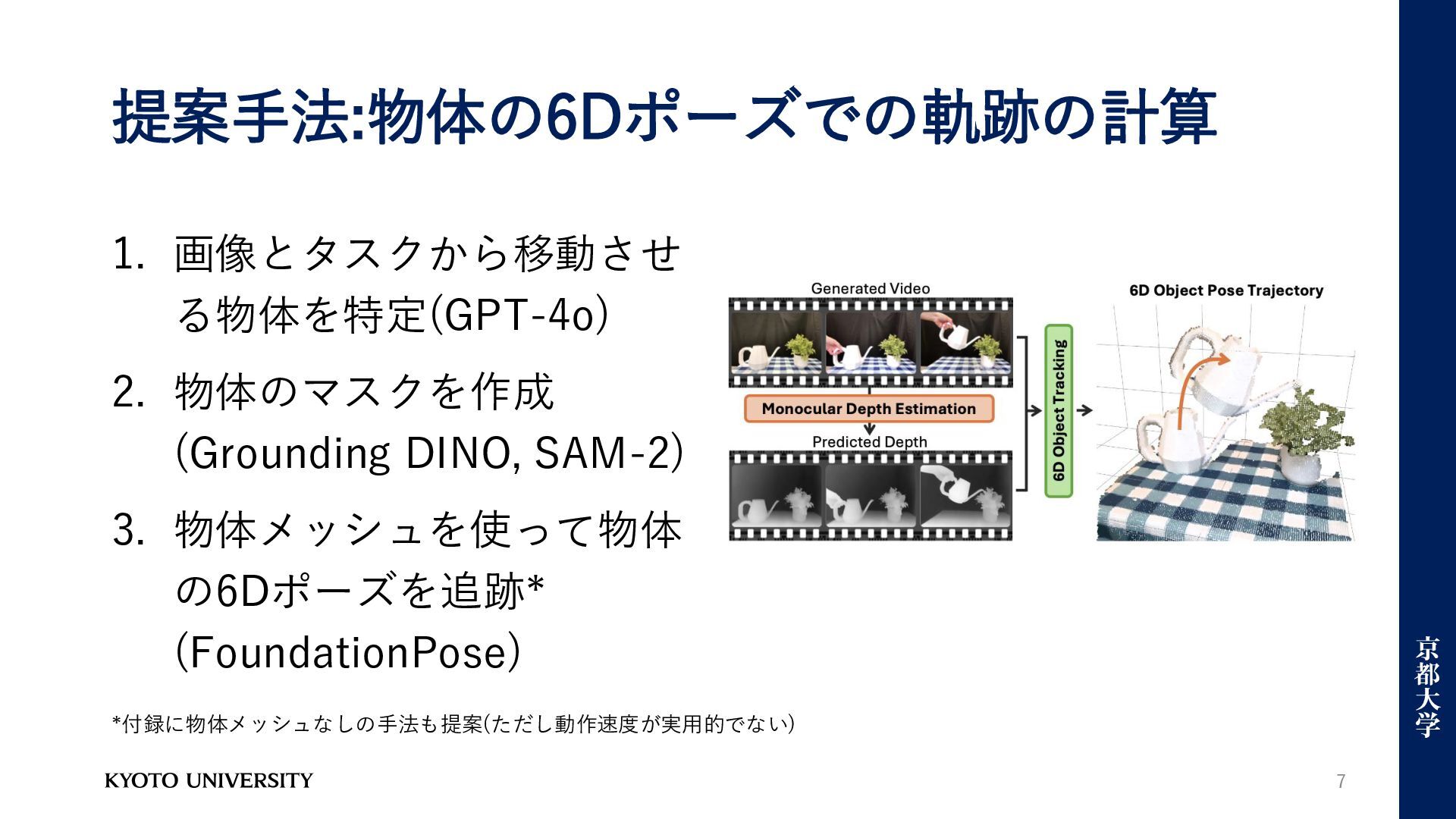
提案手法:物体の6Dポーズでの軌跡の計算 7 1. 画像とタスクから移動させ る物体を特定(GPT-4o) 2. 物体のマスクを作成 (Grounding DINO, SAM-2)
3. 物体メッシュを使って物体 の6Dポーズを追跡* (FoundationPose) *付録に物体メッシュなしの手法も提案(ただし動作速度が実用的でない)
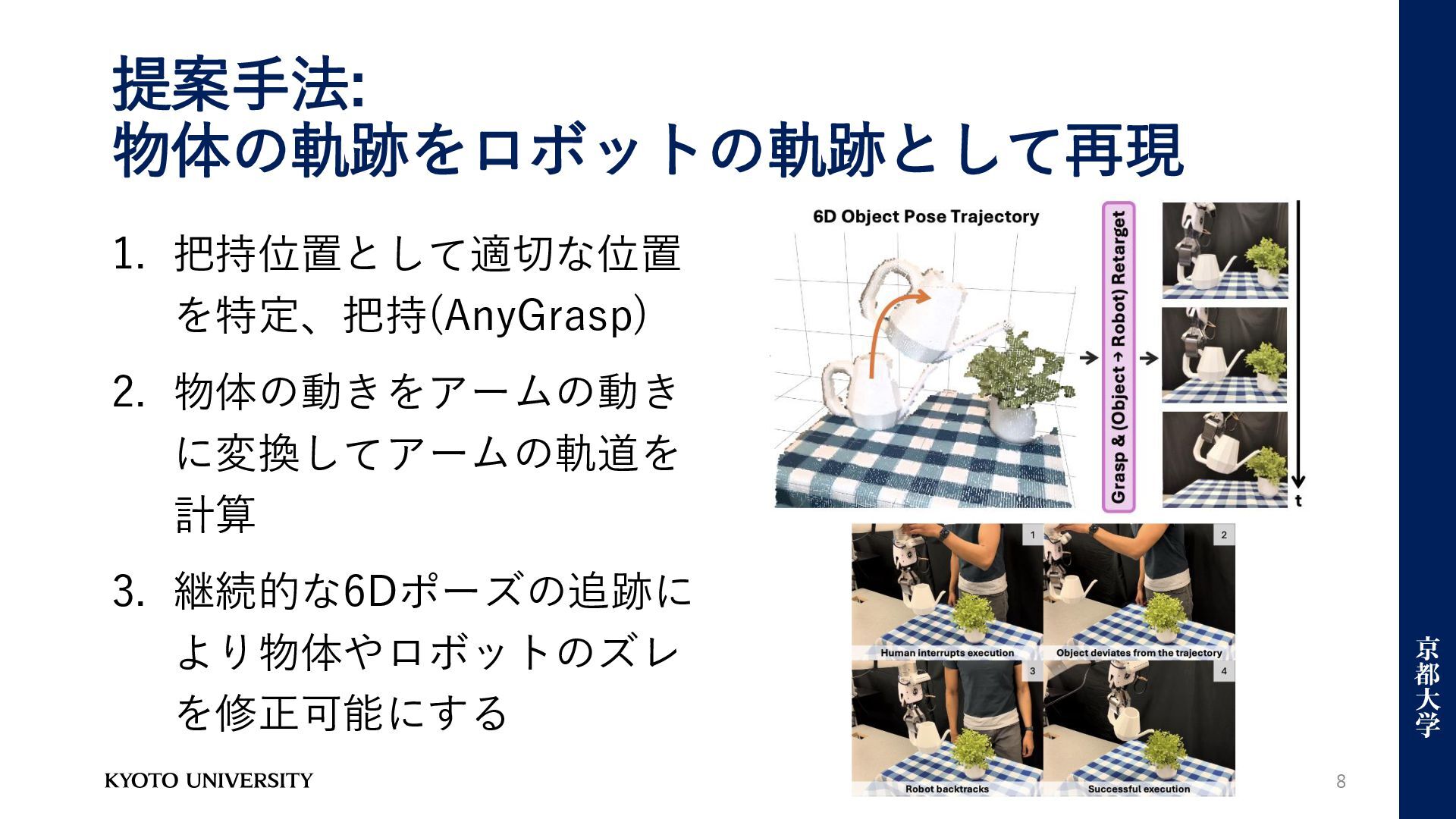
提案手法: 物体の軌跡をロボットの軌跡として再現 8 1. 把持位置として適切な位置 を特定、把持(AnyGrasp) 2. 物体の動きをアームの動き に変換してアームの軌道を 計算
3. 継続的な6Dポーズの追跡に より物体やロボットのズレ を修正可能にする
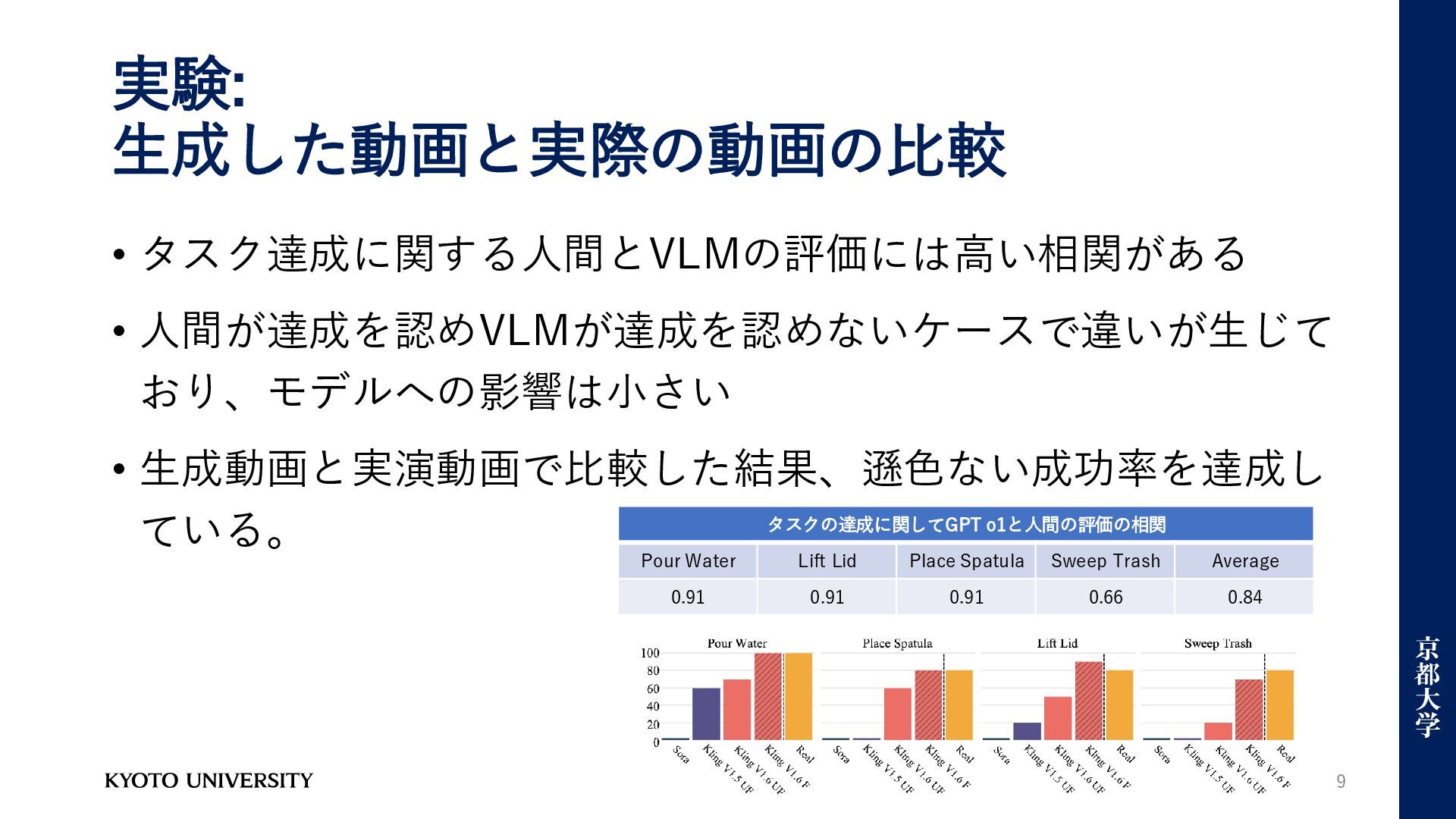
実験: 生成した動画と実際の動画の比較 タスクの達成に関してGPT o1と人間の評価の相関 Pour Water Lift Lid Place Spatula
Sweep Trash Average 0.91 0.91 0.91 0.66 0.84 9 • タスク達成に関する人間とVLMの評価には高い相関がある • 人間が達成を認めVLMが達成を認めないケースで違いが生じて おり、モデルへの影響は小さい • 生成動画と実演動画で比較した結果、遜色ない成功率を達成し ている。
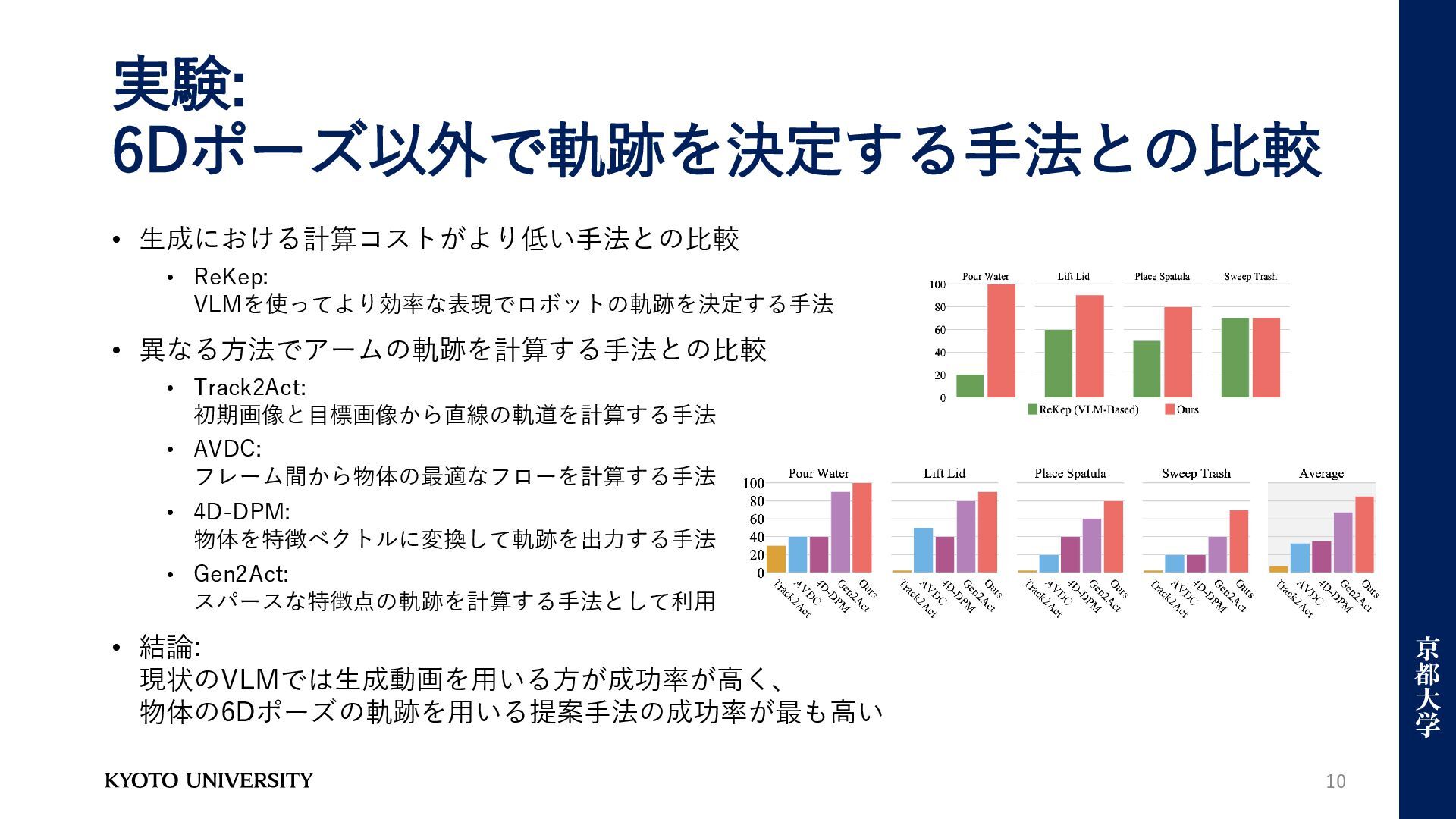
実験: 6Dポーズ以外で軌跡を決定する手法との比較 • 生成における計算コストがより低い手法との比較 • ReKep: VLMを使ってより効率な表現でロボットの軌跡を決定する手法 • 異なる方法でアームの軌跡を計算する手法との比較 •
Track2Act: 初期画像と目標画像から直線の軌道を計算する手法 • AVDC: フレーム間から物体の最適なフローを計算する手法 • 4D-DPM: 物体を特徴ベクトルに変換して軌跡を出力する手法 • Gen2Act: スパースな特徴点の軌跡を計算する手法として利用 • 結論: 現状のVLMでは生成動画を用いる方が成功率が高く、 物体の6Dポーズの軌跡を用いる提案手法の成功率が最も高い 10
結論と貢献 • 貢献 • 生成した動画だけで実世界でのタスクを可能にするモデルの提案 • 生成した動画が実際の動画と同等の性能を発揮することの検証 • 6Dの物体軌跡を利用して動作を決定することの優位性を検証 •
結論 • デモンストレーションを必要としない新しいモデルを提案し、生成ビ デオの密な視覚的・時間的手がかりが信頼性の高い性能をもたらすこ とを確認した。 11
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}