2026/02/25 STORES Data Lounge「AI時代のデータ基盤とデータ活用」
(https://hey.connpass.com/event/379343/)
発表時間:20分
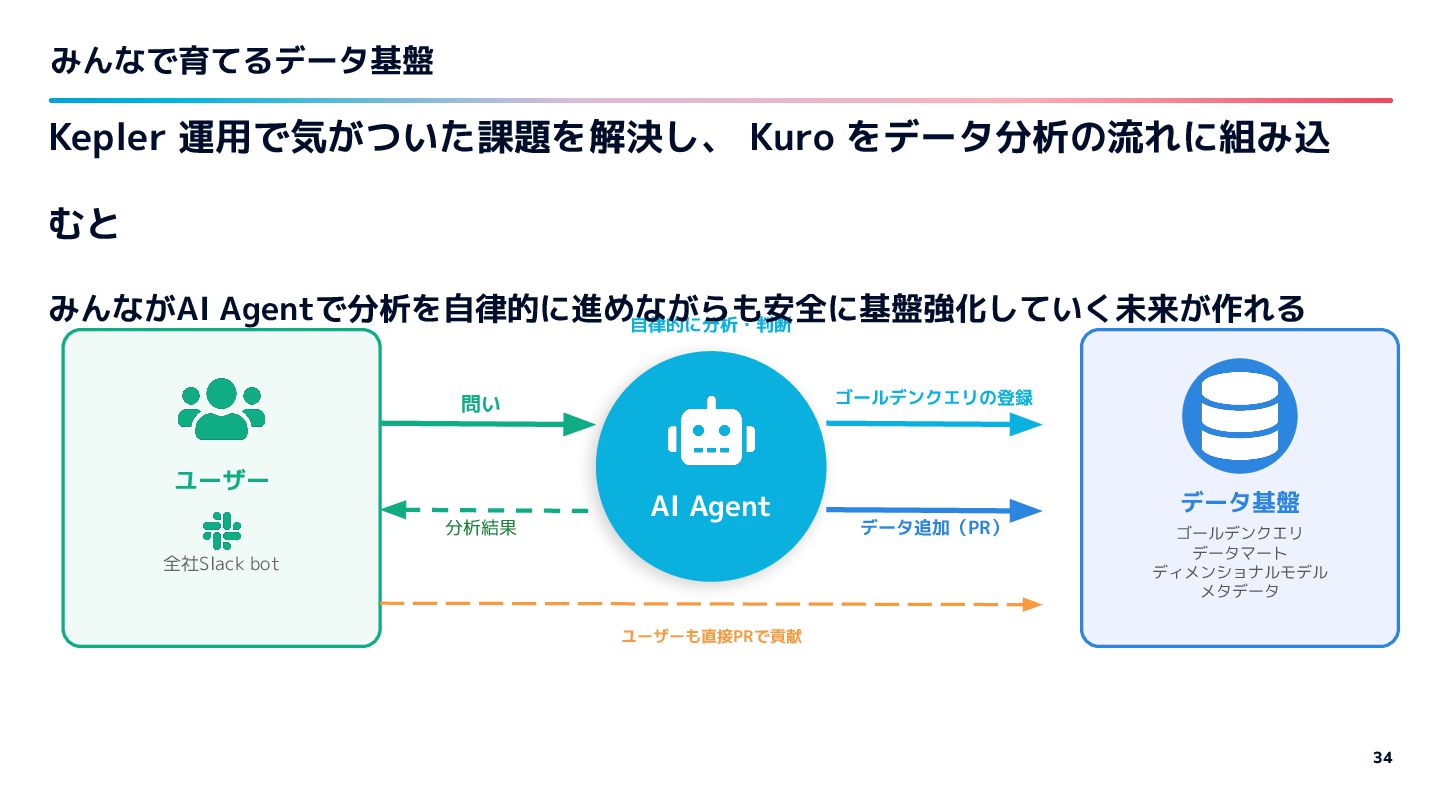
データ分析AI Agent「Kepler」を動かして気づいた課題とその対応についてまとめました。
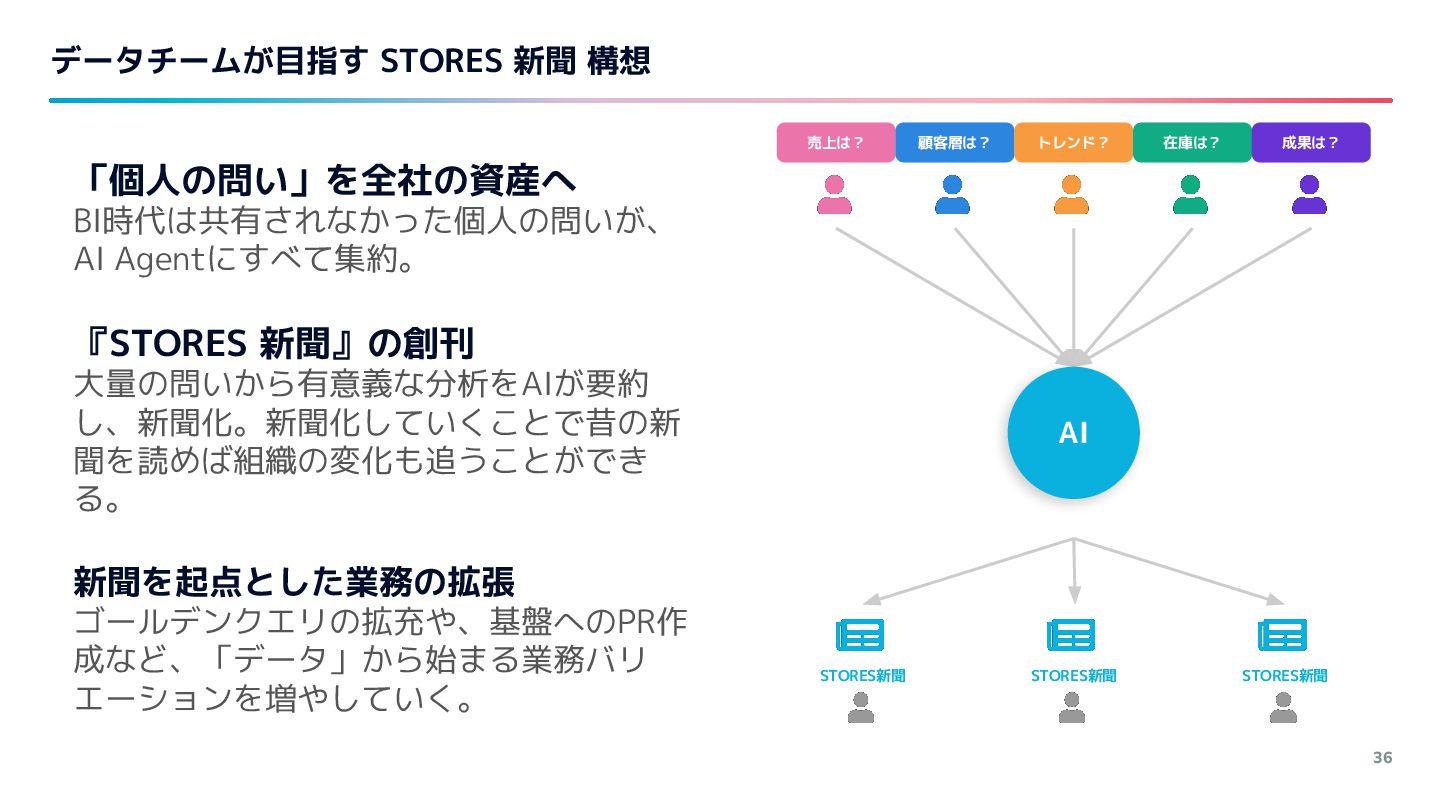
また、開発サポートAIの登場によって全社的にAI化が進む中でのデータ基盤開発の民主化や、AI時代にデータチームがどういう基盤(「STORES新聞」構想など)を目指していきたいかについてお話ししています。
STORES 株式会社
データ本部 データ基盤グループ
小野 嵩征(ono.takayuki)/ アナリティクスエンジニア
{kind=link}
{kind=link}
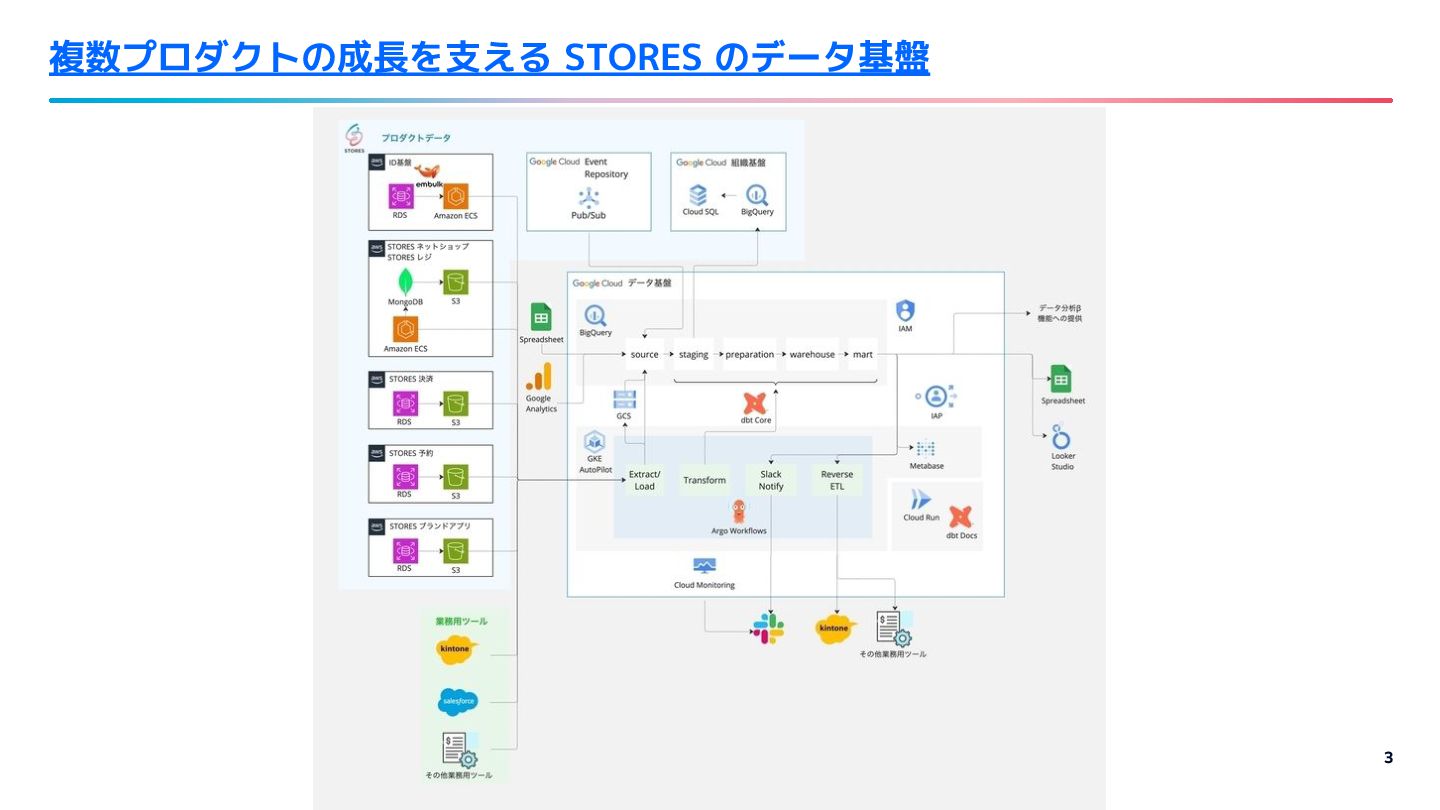{kind=link}
{kind=link}
{kind=link}
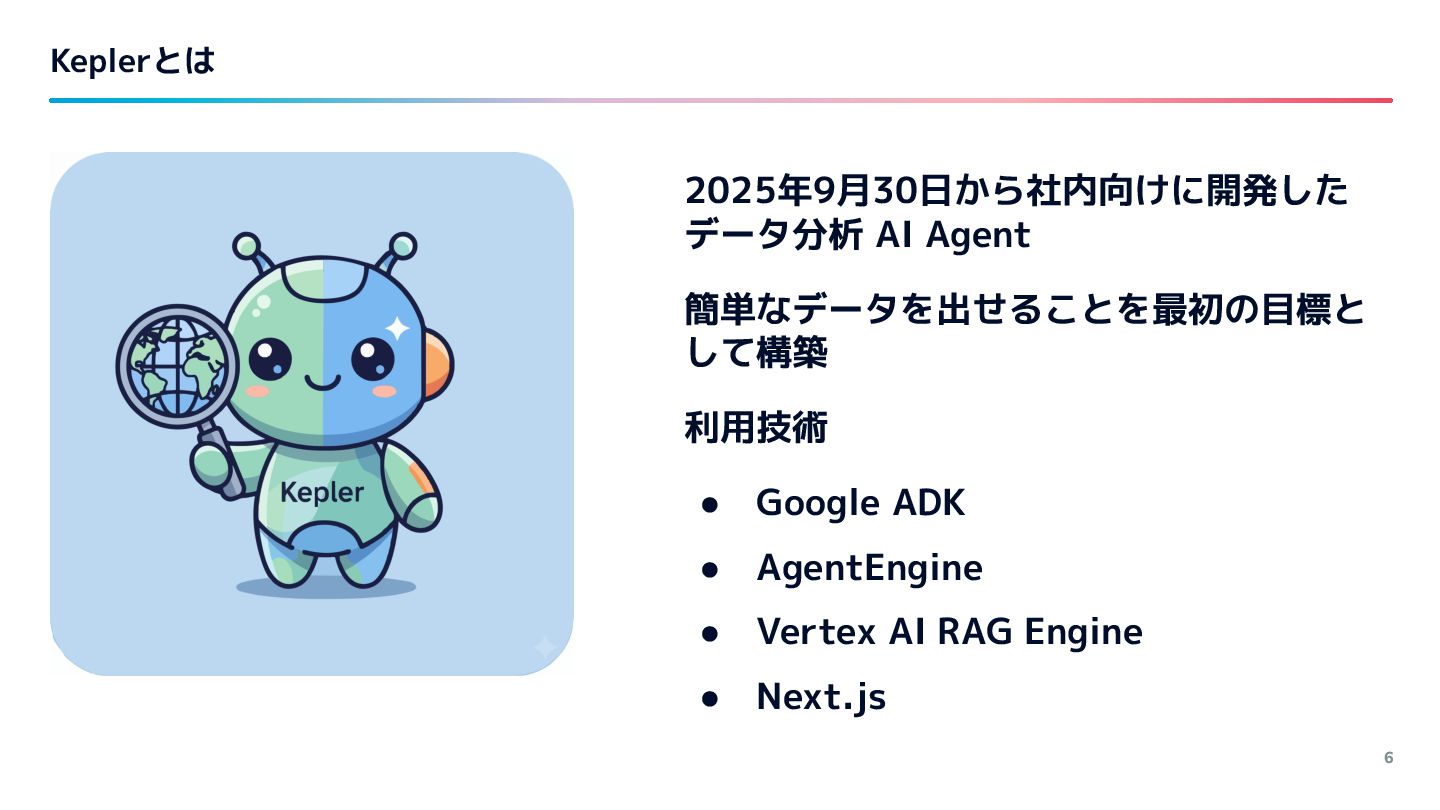{kind=link}
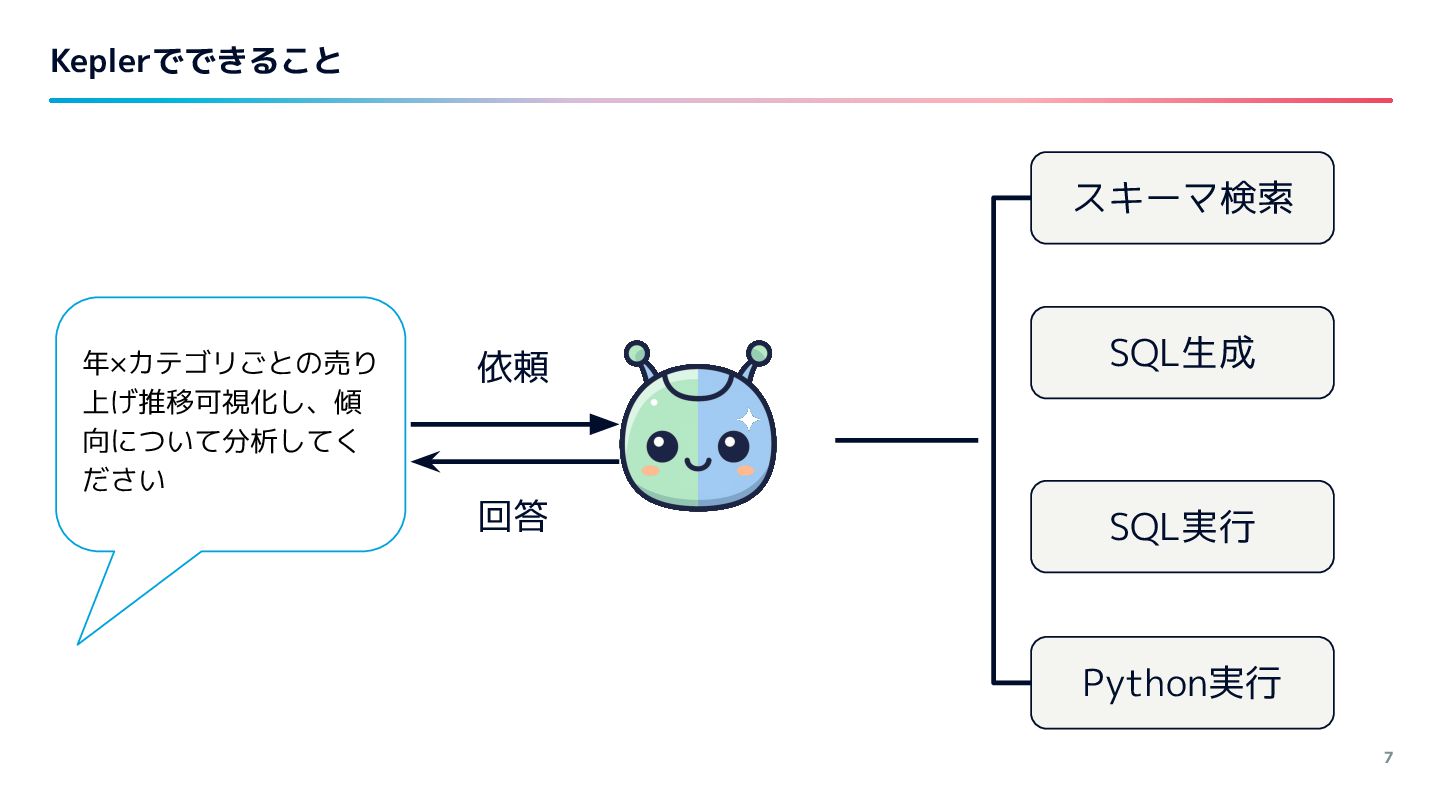{kind=link}
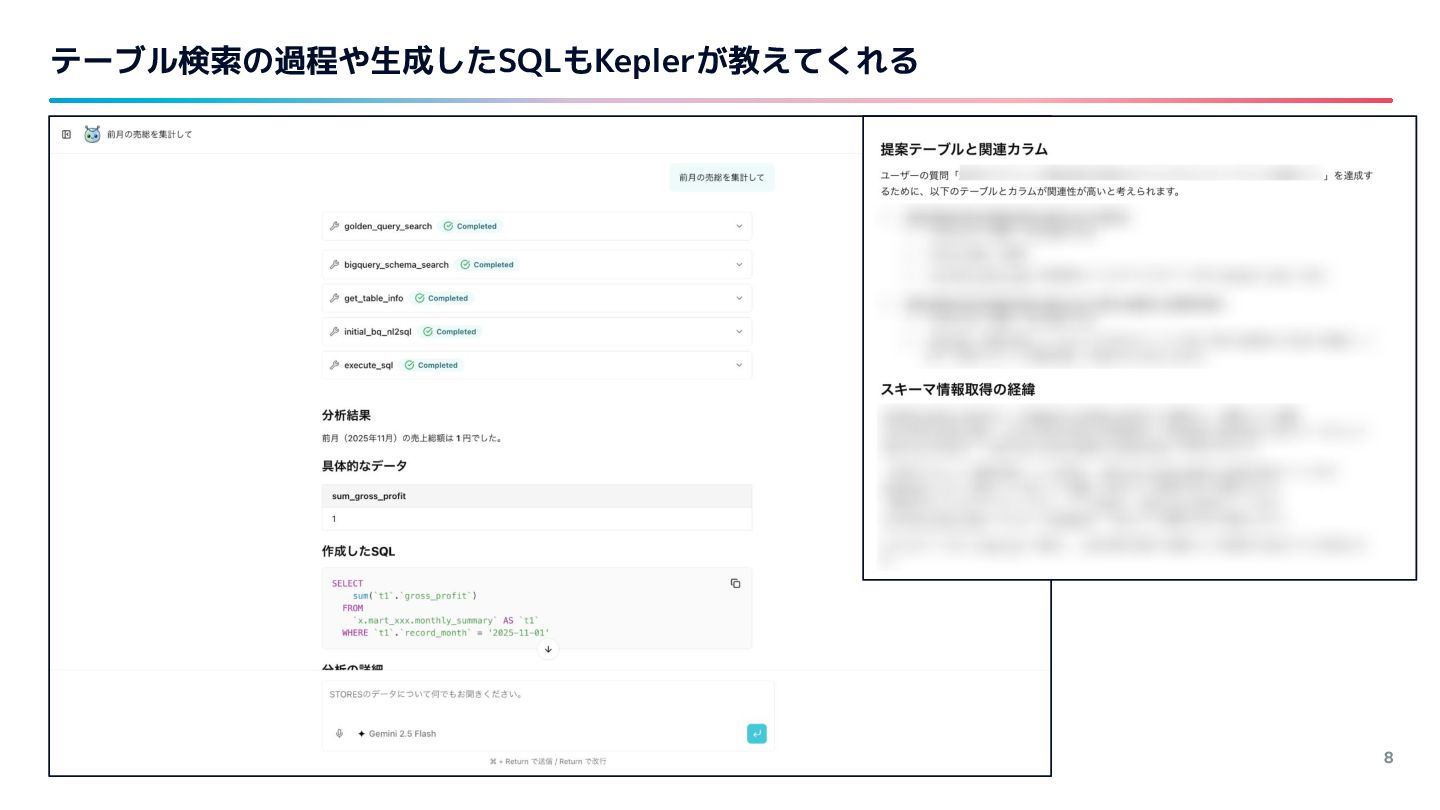{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}