for building personalized recommendation system Reflects changes in the user's geographical location Reveal users' preferences, social relationships and behavior patterns The disadvantages of the traditional method High reliance on sparse check-in data Weak cross-user and regional generalization capabilities 3
behavioral modeling ➢ The large language model is a deep learning model trained with large amounts of text data that enables the model to generate natural language text or understand the meaning of language text LLM is widely used in recommendation systems 4 Understanding complex user behavior Strong generalization ability for sparse data Reduce reliance on manual feature engineering.
and recent stays to reflect long- and short-term preferences ◆ Adding target time (e.g., “tomorrow morning”) into the prompt for time-aware prediction ◆ Using a fixed prompt template to encode user behavior as natural language ◆ Generating next POI along with natural language explanations for interpretability u LLMMob only uses the target user's own trajectory and does not leverage similar trajectories from other users. Lack of research Reference:Wang X, Fang M, Zeng Z, et al. Where would i go next? large language models as human mobility predictors[J]. arXiv preprint arXiv:2308.15197, 2023.
to capture user preferences ◆ Constructing candidate POIs sorted by geographic distance ◆ Modeling typical sequential patterns between POI categories ◆ Using a fixed prompt to frame the task as zero-shot POI ranking ◆ Achieving state-of-the-art prompt performance for POI recommendation ◆ LLMMove still relies on manually designed prompts, limiting adaptability across users and tasks. Lack of research Reference:Feng S, Lyu H, Li F, et al. Where to move next: Zero-shot generalization of llms for next poi recommendation[C]//2024 IEEE Conference on Artificial Intelligence (CAI). IEEE, 2024: 1530-1535. The workflow of the designed LLMmove framework and the corresponding prompts.
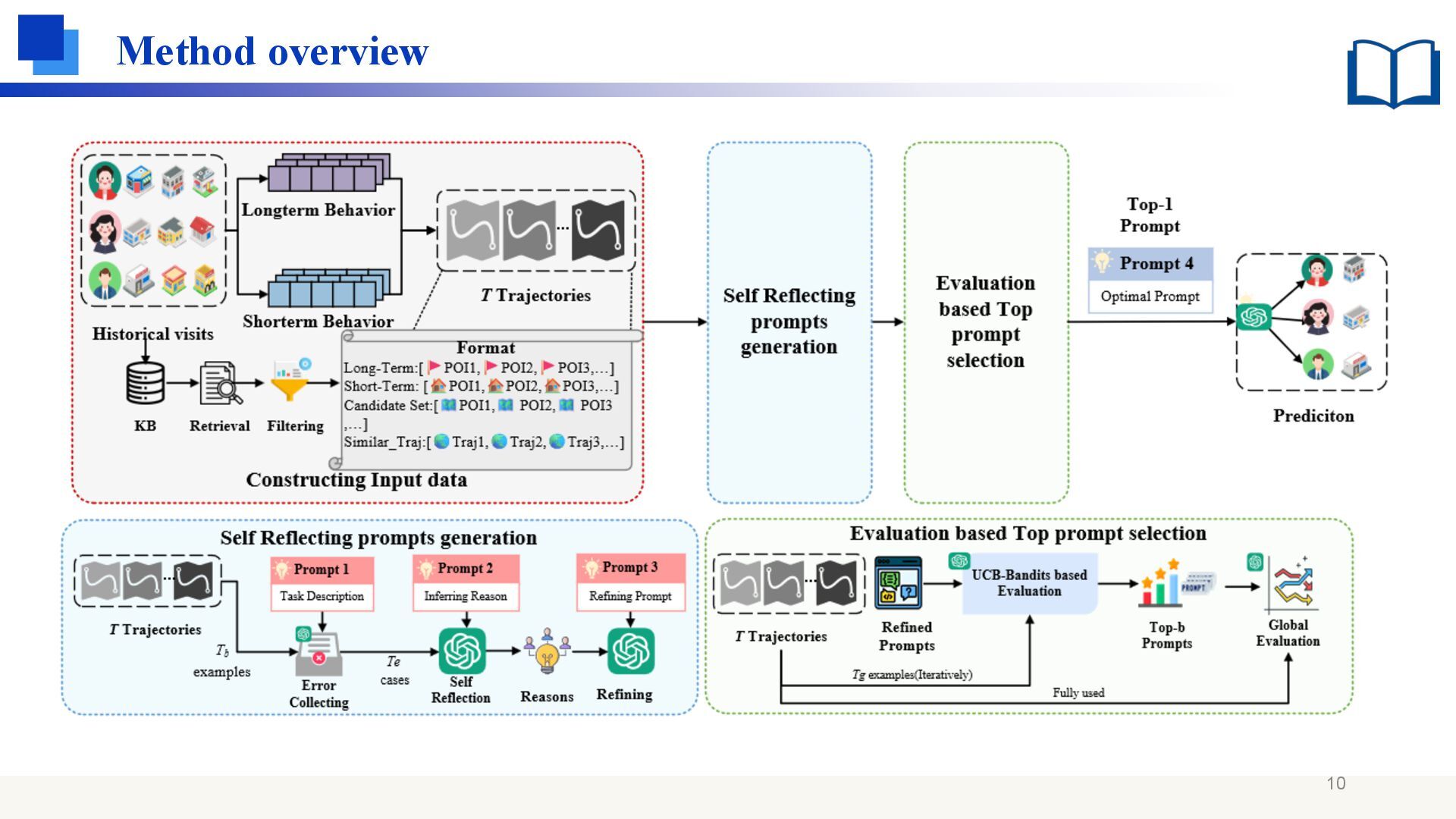
which combines retrieval enhanced method with prompt optimization: Retrieve semantically similar user trajectories from a large scale behavior database Use short-and long-term behavior to infer intent categories and optimize prompts Main contributions ⚫ This represents the first attempt to integrate semantically similar trajectories into the POI recommendation prompt design. ⚫ Use the self-reflection ability of language model to optimize the effectiveness of hints. 7
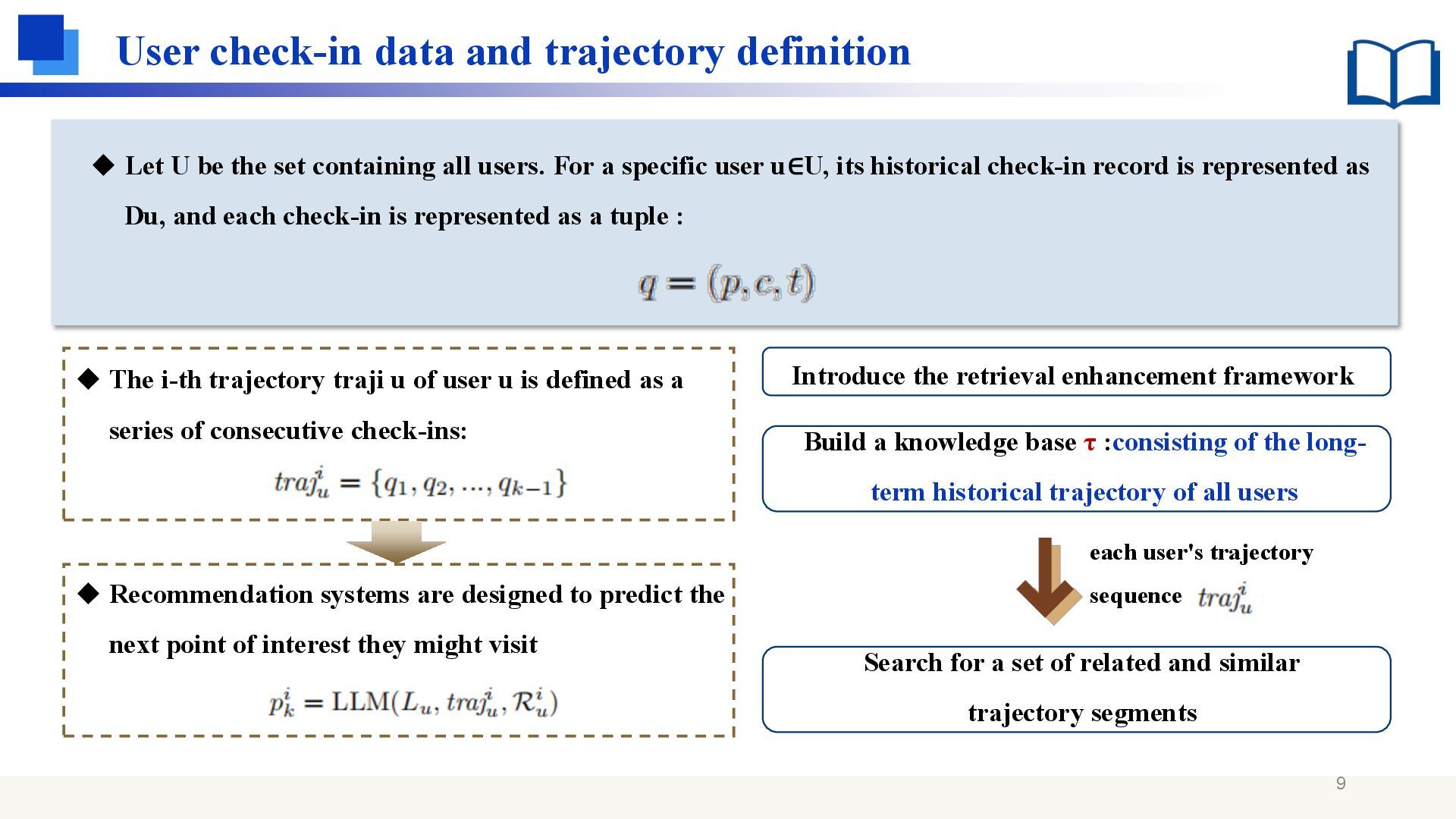
the set containing all users. For a specific user u∈U, its historical check-in record is represented as Du, and each check-in is represented as a tuple : ◆ The i-th trajectory traji u of user u is defined as a series of consecutive check-ins: ◆ Recommendation systems are designed to predict the next point of interest they might visit Introduce the retrieval enhancement framework Build a knowledge base τ :consisting of the long- term historical trajectory of all users each user's trajectory sequence Search for a set of related and similar trajectory segments 9
data and predict the next point of interest: Define the time threshold Tsplit ➢ Any check-in records that occur before or at the same time as Tsplit are used to capture the user's long-term preferences. Extract the most recent l check-ins Sort them by timestamp. Build a candidate set of POI predictions for the next POI Select POI based on geographical proximity and historical visits Consider that users tend to visit places close to their current location or places they have visited in the past. ➢ to represent user’s recent and immediate intent.
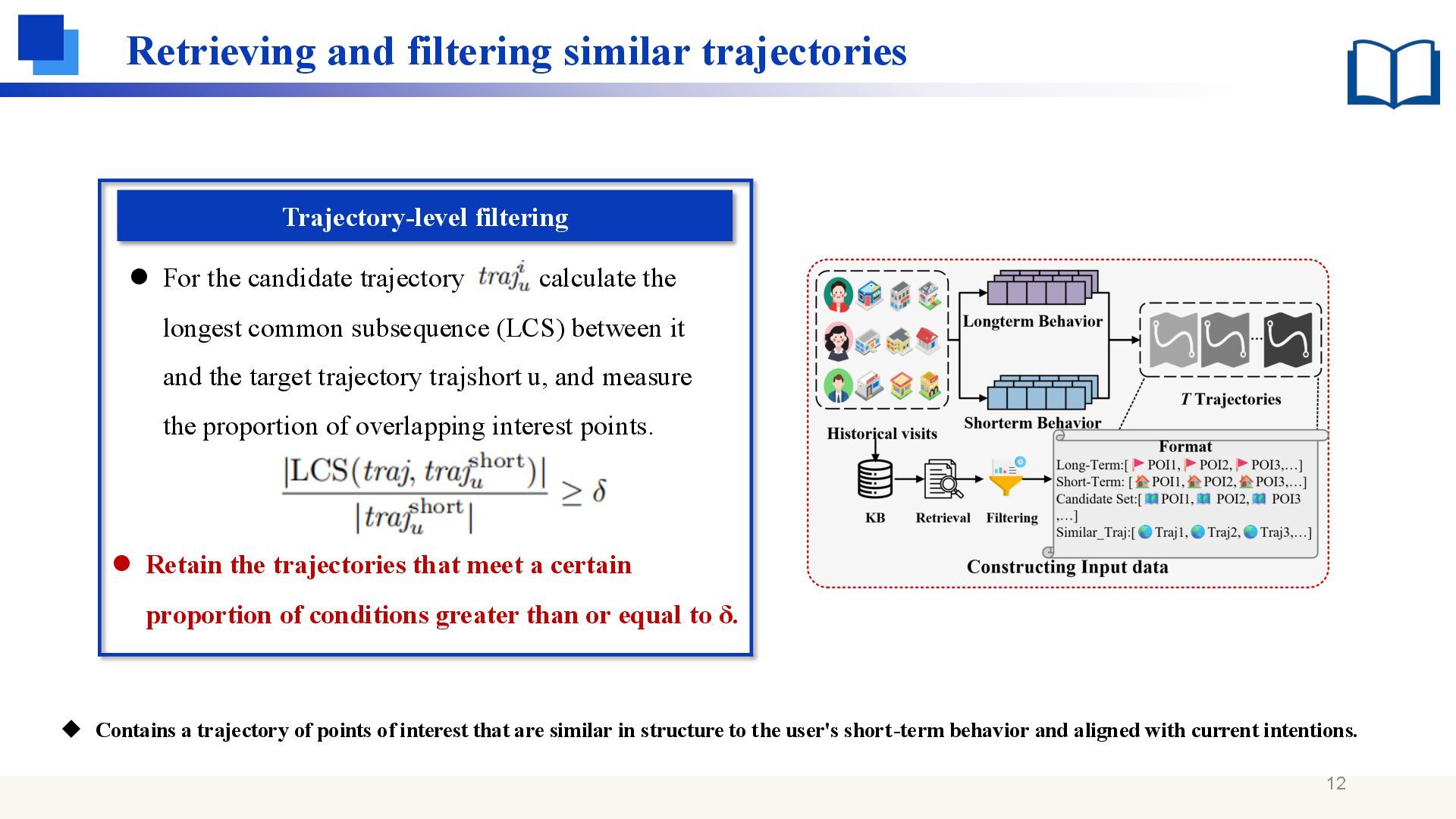
the trajectories that meet a certain proportion of conditions greater than or equal to δ. ⚫ For the candidate trajectory calculate the longest common subsequence (LCS) between it and the target trajectory trajshort u, and measure the proportion of overlapping interest points. ◆ Contains a trajectory of points of interest that are similar in structure to the user's short-term behavior and aligned with current intentions.
the correlation score sc of each interest point category c: :the frequency of category c in long-term behavior, :the frequency of short-term behavior. ⚫ Select the top 10 categories with the highest scores as Ctop, and exclude the interest points in the trajectories that do not belong to these categories. ◆ Contains a trajectory of points of interest that are similar in structure to the user's short-term behavior and aligned with current intentions.
PO4ISR[Sun et.al.,2023] , a self-reflection prompt generation mechanism is adopted to improve the understanding of user behavior patterns of large language models (LLM), so as to more accurately recommend the next point of interest. It mainly includes the following steps: Initial prediction and interpretation ⚫ Using the initial prompt, ask the LLM to predict the user's top 10 possible POIs and provide an explanation for each prediction. Error collection LLM Self Reflection ⚫ The LLM analyzes and automatically generates r causes that may lead to the failure of the prediction, and integrates these cause sets R into the optimization process. Error-based prompt refinement. ⚫ Based on the above reasons and real interest point Promptr,(i) LLM re-adjusts the initial prompt: 1 2 3 4
Evaluation ⚫ The top-b prompts obtained from the UCB-based selection process are further evaluated on the entire training dataset T: ⚫ Balance the eval uation of each prompt’s perform- ance and compu tational resource consumption: ◆ Optimal hints are those that most effectively enhance the ability of a language model to capture and model patterns of user behavior in order to predict the next point of interest. Each candidate prompt is dynamically evaluated using Tg and NDCG in each iteration Select the top tips based on the final score The highest average score in the entire data set is a hint for the best final deployment Robustness of the prompt &Best overall performance
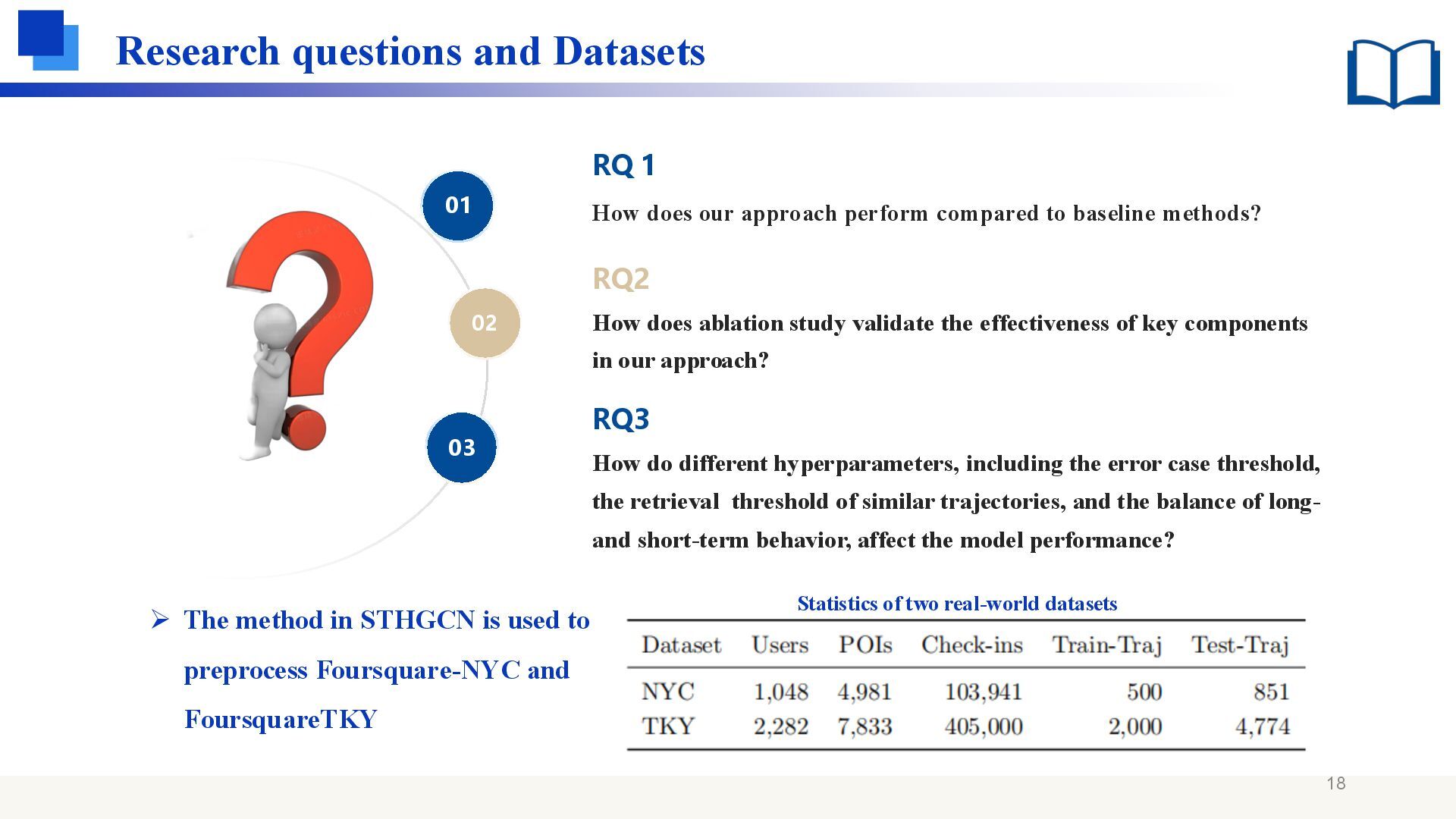
error case threshold, the retrieval threshold of similar trajectories, and the balance of long- and short-term behavior, affect the model performance? RQ3 How does our approach perform compared to baseline methods? RQ 1 How does ablation study validate the effectiveness of key components in our approach? RQ2 02 01 03 Statistics of two real-world datasets ➢ The method in STHGCN is used to preprocess Foursquare-NYC and FoursquareTKY 18
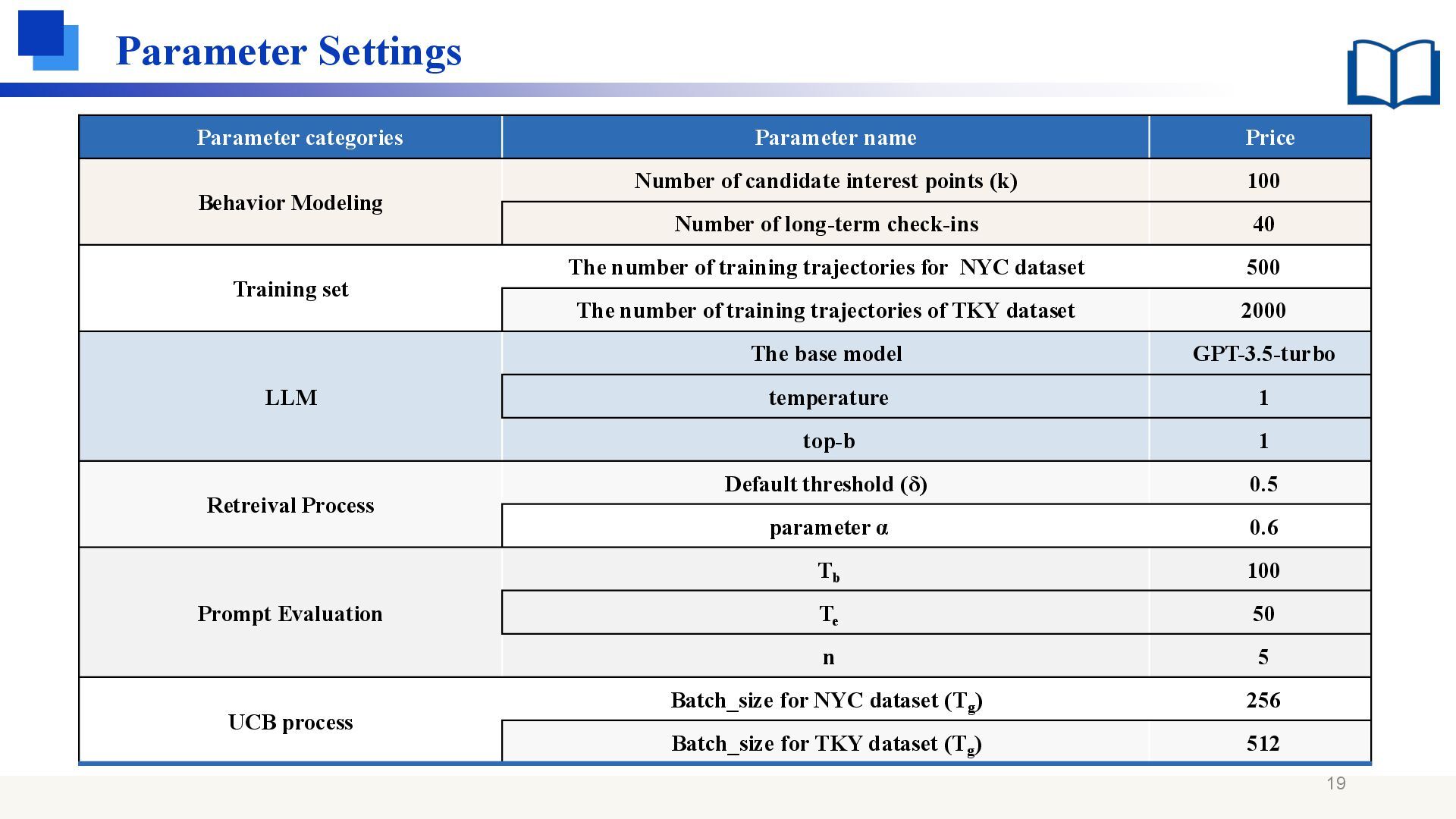
of candidate interest points (k) 100 Number of long-term check-ins 40 Training set The number of training trajectories for NYC dataset 500 The number of training trajectories of TKY dataset 2000 LLM The base model GPT-3.5-turbo temperature 1 top-b 1 Retreival Process Default threshold (δ) 0.5 parameter α 0.6 Prompt Evaluation Tb 100 Te 50 n 5 UCB process Batch_size for NYC dataset (Tg ) 256 Batch_size for TKY dataset (Tg ) 512 19
among the first K recommendations. ◆ MRR@10: The ranking position of the first correct recommendation is evaluated to reflect the early ability of the model to retrieve relevant POIs. Evaluation Metrics ➢ In line with previous studies on POI recommendation, this study adopts the following main performance indicators: ⚫ m: Total number of test instances ⚫ ranki : The position of the first correct prediction in the recommendation list of the i-th instance. ✓ A high MRR value indicates that the model has a stronger retrieval ability at higher ranking positions. 20
tips for different recommendation scenarios ◆ This study uses zero sample sequential recommendation tips as the baseline. LLMRank[Hou et.al.,2024] ◆ The recommendation is transformed into a sorting task to guide the LLM to sort the candidate items according to the historical interaction; ◆ Especially using the prompt of the most recent login information. ListRank[Dai et.al.,2023] ◆ The performance of the model is improved by integrating ranking strategies; ◆ The list ranking method is used as the baseline evaluation. LLMMob[Wang et.al.,2024] ◆ Combine long-term and short-term behaviors and time factors to predict mobility; ◆ Compare the removal of time factors and add the same geographical influence as the study (fair comparison). LLMmove[Feng et.al, 2024] ◆ Extract user preferences and geographic influences as cues; ◆ Compare this approach to evaluate its effectiveness. 21 ➢Compare our approach with the following methods:
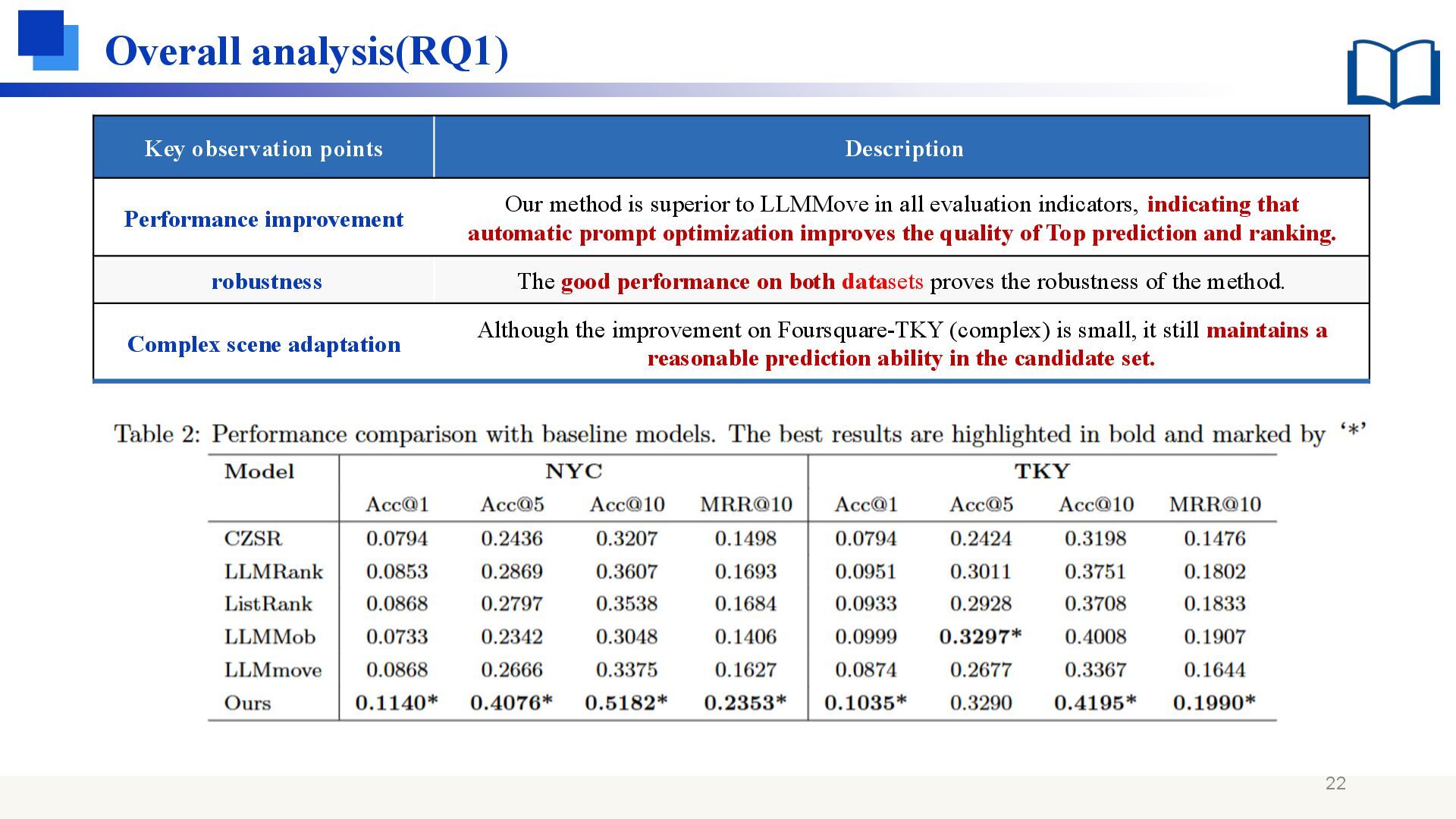
method is superior to LLMMove in all evaluation indicators, indicating that automatic prompt optimization improves the quality of Top prediction and ranking. robustness The good performance on both datasets proves the robustness of the method. Complex scene adaptation Although the improvement on Foursquare-TKY (complex) is small, it still maintains a reasonable prediction ability in the candidate set.
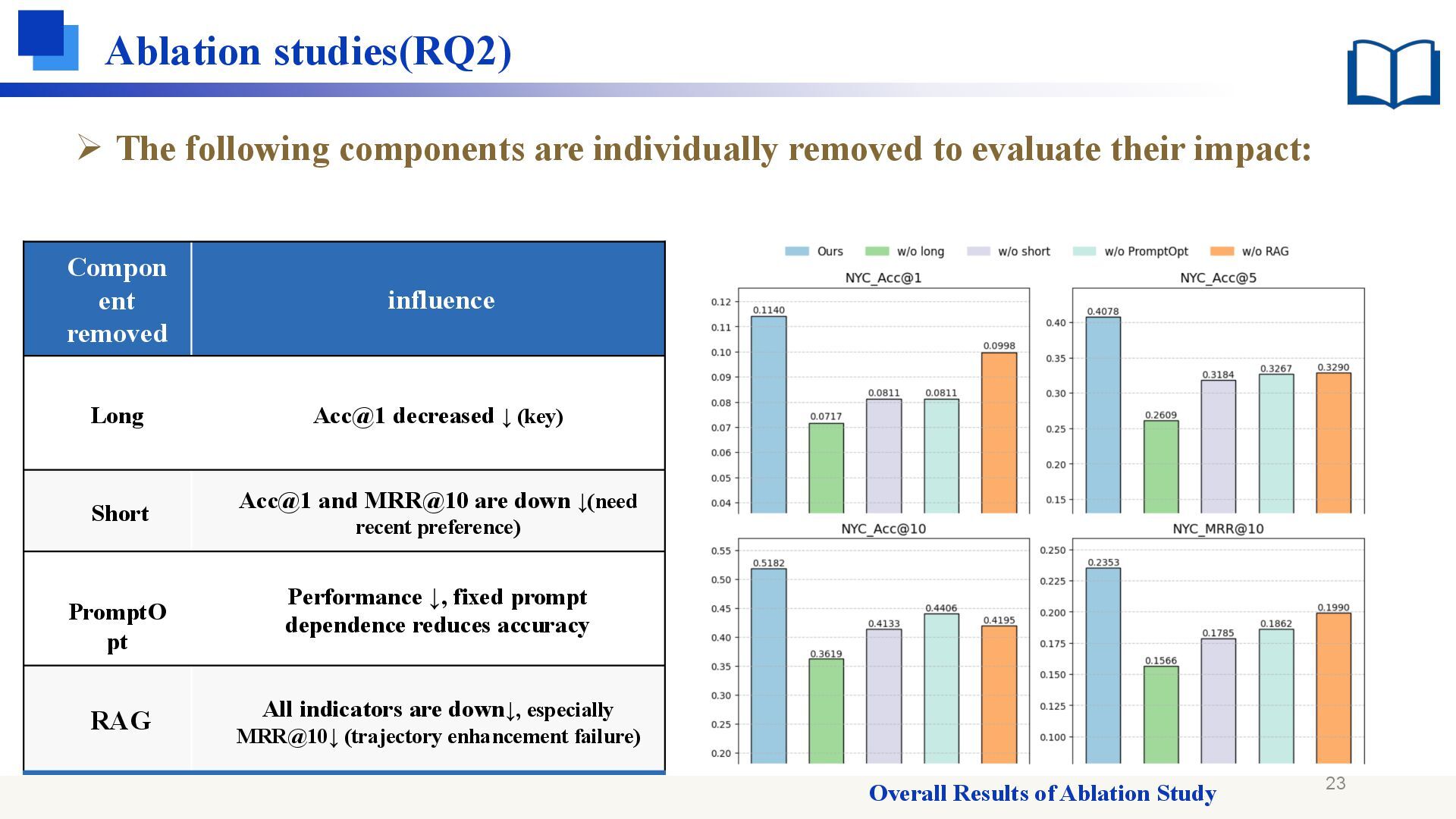
to evaluate their impact: Compon ent removed influence Long Acc@1 decreased ↓ (key) Short Acc@1 and MRR@10 are down ↓(need recent preference) PromptO pt Performance ↓, fixed prompt dependence reduces accuracy RAG All indicators are down↓, especially MRR@10↓ (trajectory enhancement failure) Overall Results of Ablation Study
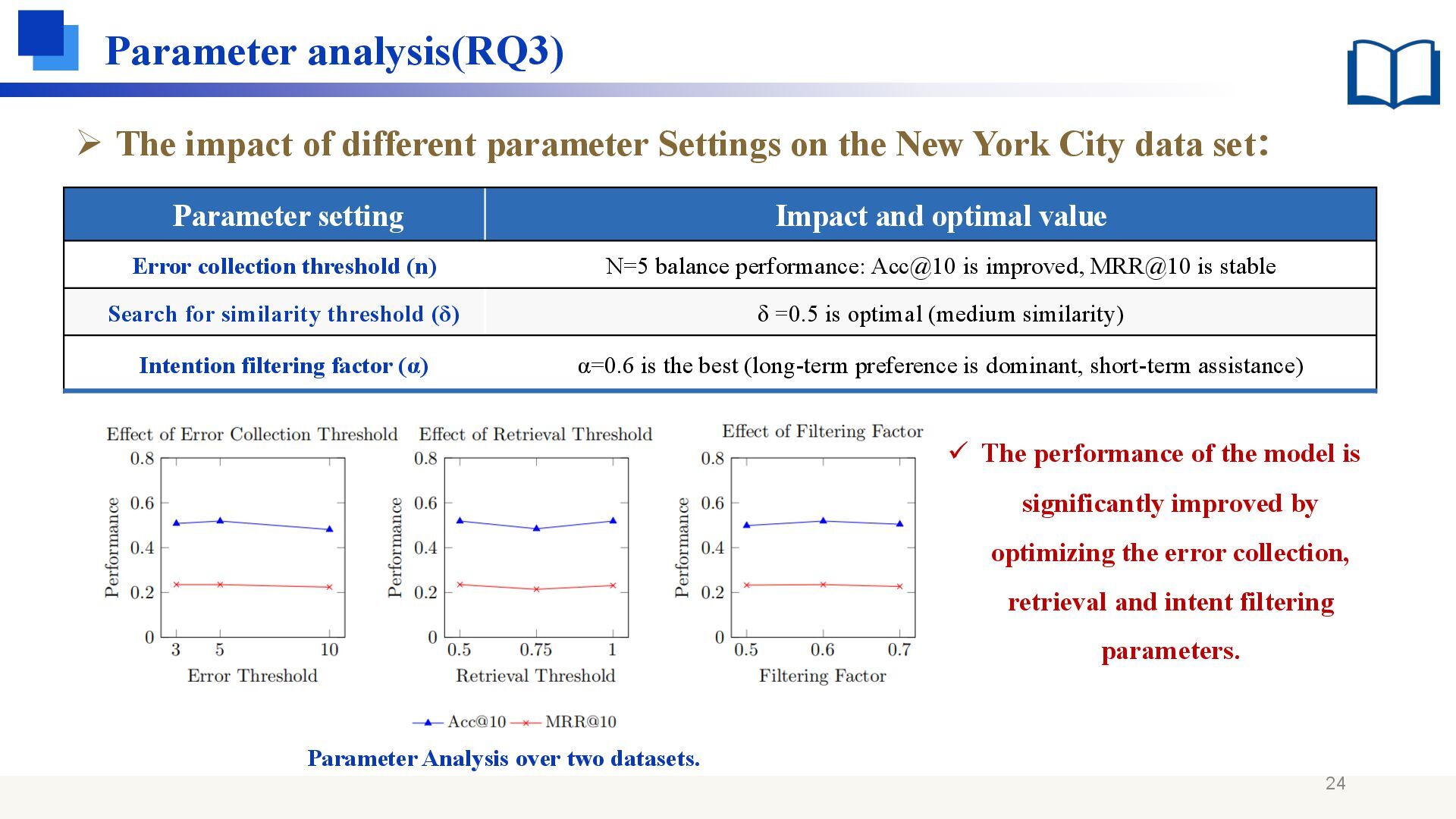
Impact and optimal value Error collection threshold (n) N=5 balance performance: Acc@10 is improved, MRR@10 is stable Search for similarity threshold (δ) δ =0.5 is optimal (medium similarity) Intention filtering factor (α) α=0.6 is the best (long-term preference is dominant, short-term assistance) ➢ The impact of different parameter Settings on the New York City data set: ✓ The performance of the model is significantly improved by optimizing the error collection, retrieval and intent filtering parameters.
combines retrieval-enhanced self-reflection mechanism and space-time modeling, significantly improves the recommendation accuracy. Method of dynamic generation and optimization of hints (RASR) Make large language models more effective at capturing changes in user interest. Experimental result ✓ In the real data set test, the accuracy and robustness of RASR are better than existing advanced methods.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Self-Reflective prompts generation 14 ◆ Inspired by Re2LLM[Wang et.al.,2024] and](https://files.speakerdeck.com/presentations/c3017ea0c9dd407da0a2048ec654fd0b/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Overall analysis(RQ1) Method Describe the changes CZSR[Wang et.al.,2023] ◆ Design](https://files.speakerdeck.com/presentations/c3017ea0c9dd407da0a2048ec654fd0b/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}