with different spells l Negatively impact NLP tasks[1] l Examples: l Abbreviation(NLP, natural language processing) l Slang(bucks, dollar) l Okurigana(moving: 引っ越し, 引越し, 引越) l Foreign word(user: ユーザー, ユーザ) l Character types(apple: りんご, リンゴ, 林檎, ringo) Introduction(1/2) 2 [1] K. Yamamoto, “Nihongo no hyokiyure mondai ni kansuru kosatsu to taisho” [On Orthographical Variants Problem and Our Solution], Japio year book, pp. 202–205, 2015 (in Japanese).
Frequently caused in Japanese l (1)Hiragana, (2)Katakana, (3)Kanji and (4)Roman alphabet are used together in the same context. l e.g. 「コーヒー を 飲 む 。 (I drink coffee.)」 l Often represent difference word meanings l An in-depth semantic analysis has not been conducted yet l Some previous studies focus on Japanese character types, but they are based only on surface aspects of a text. 3 (1) (1) (2) (3)
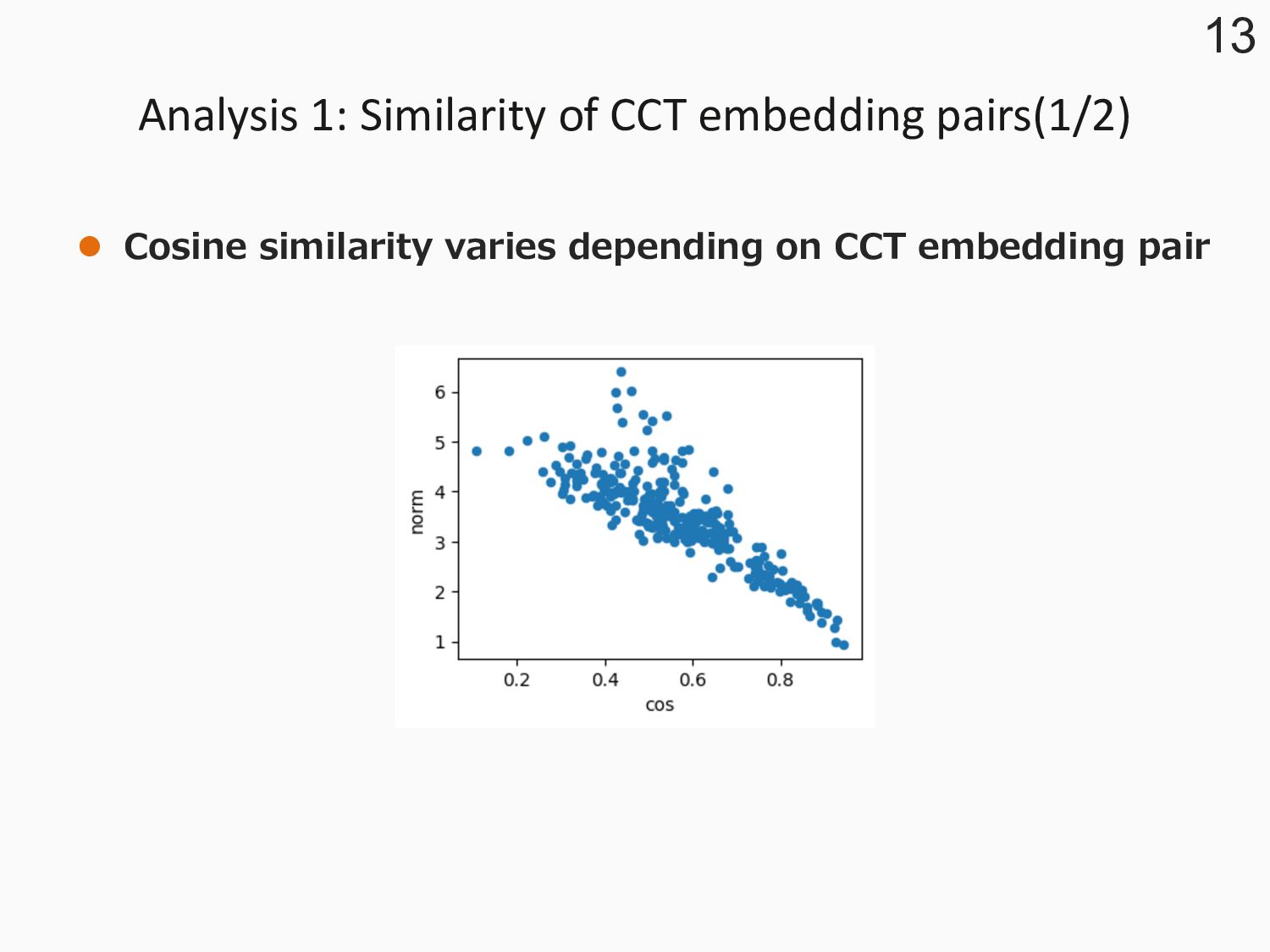
of CCT words l For the convenience of investigation, we focused on two Japanese character types: Hiragana and Kanji. (おいしい) (美味しい) l To realize semantic-level analyses, we tried using word embedding. 4
l Japanese-origin words: Hiragana l Chinese-origin words: Kanji l Loan words: Katakana and Roman alphabet l Cases where the notation changes: l Simple Japanese: character type conversion from Kanji to Hiragana is actively performed for vocabulary simplification[2] 5 [2] Agency for Cultural Affairs, “Zairyushien no tame no yasashii nihongogaidorain” [Simple Japanese Guidelines for Residential Support], 2020(in Japanese)
usage l Conducted a character type frequency survey using the “Balanced Corpus of Contemporary Written Japanese” to investigate the use of character types for each corpus genre[3] 6 [3] W. Kashino and M.Okumura, “Wago ya kango no katakana hyoki :‘Gendai nihongo kakikotoba kinko kopasu’ no shoseki ni okeru shiyojittai” [Analysis of Katakana Representation for Japanese Native Wordsand the Words Imported from Classical Chinese : Using BCCWJJapanese Corpus], Mathematical linguistics, Vol. 28, No. 4, pp. 153–161, 2012.
meaning of a single word with a low-dimensional real-valued vector l Static word embeddings (e.g. word2vec[4]) l Dynamic word embeddings (e.g. BERT[5]) l Word2vec l Be based on the assumption that words used in the same context have similar meanings l Can perform addition and subtraction l Can calculate similarity l Remove the effects of dynamic contexts 7 [4] T. Mikolov, K. Chen, G. S. Corrado, and J. Dean, “Efficient Estimationof Word Representations in Vector Space,” In Proceedings of Workshopat ICLR, 2013. [5] J. Devlin, M. Chang, K. Lee, and K. Toutanova, “Bert: Pre-trainingof Deep Bidirectional Transformers for Language Understanding”, InProceedings of the 2019 Conference of the North American Chapter ofthe Association for Computational Linguistics, Minneapolis, MN, USA,pp. 4171–4186, 2019.
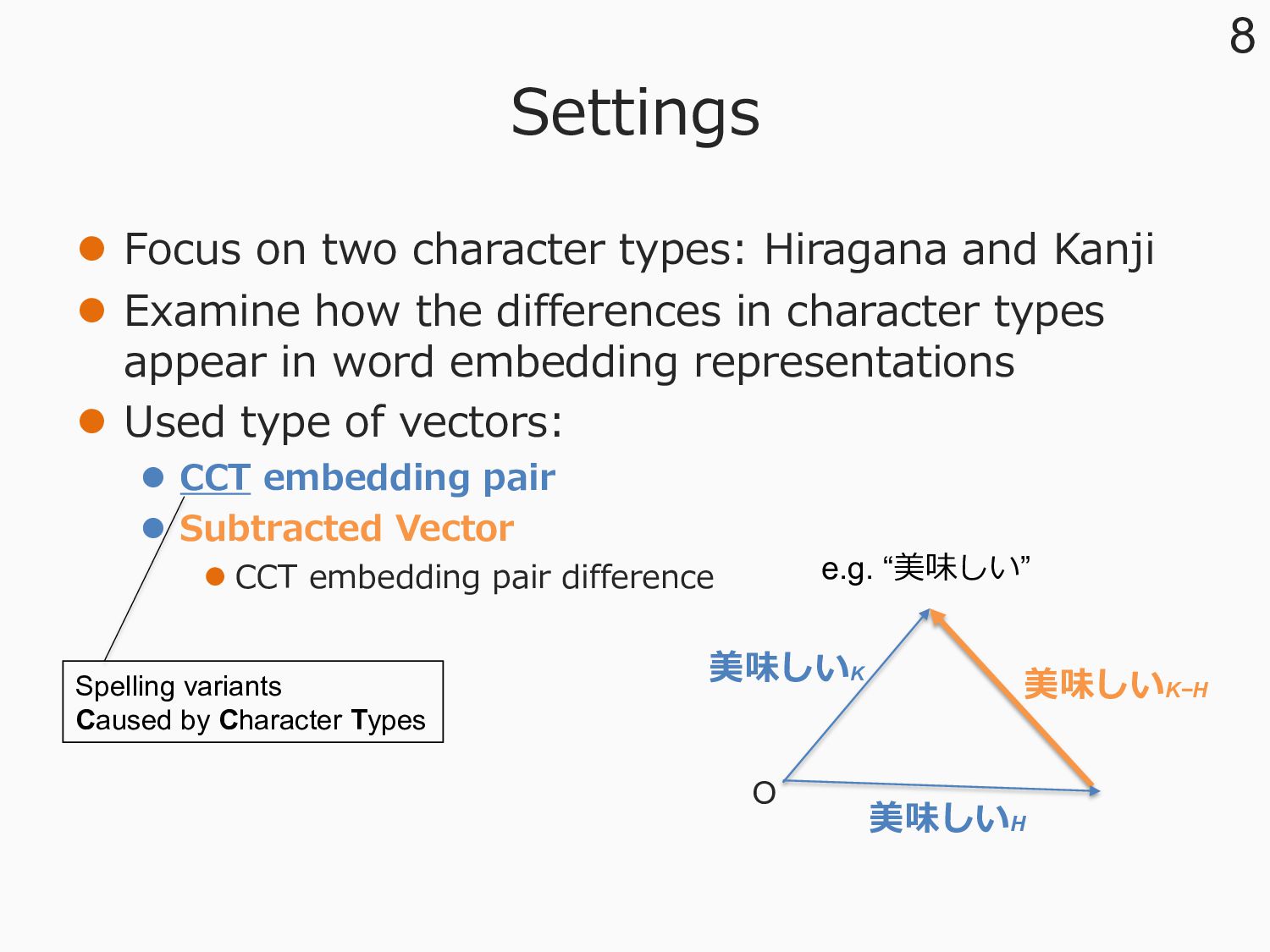
l Examine how the differences in character types appear in word embedding representations l Used type of vectors: l CCT embedding pair l Subtracted Vector l CCT embedding pair difference 8 美味しいH 美味しいK 美味しいK−H O e.g. “美味しい” Spelling variants Caused by Character Types
the Japanese version of Wikipedia articles with the word2vec algorithm l Contains 751,361 word vectors with a 200-dimensional space 9 [6] M. Suzuki, K. Matsuda, S. Sekine, N. Okazaki, and K. Inui, “AJoint Neural Model for Fine-Grained Named Entity Classification ofWikipedia Articles,” IEICE Transactions on Information and Systems,Special Section on Semantic Web and Linked Data, Vol. E101-D, No.1,pp. 73–81, 2018 美味しいH 美味しいK O e.g. “美味しい”
pairs in 3 steps Step 1: Collect pairs from Japanese textbooks l Basic words in both Kanji and Hiragana notations. l Transform verb and adjective words into their standard form Step 2: Exclude pairs not included in Wikipedia Entity Vectors Step 3: Exclude pairs with ambiguity caused primarily by the character types l Occasionally, two words that have different meanings each other share the same Hiragana notation in Japanese l obtain 293 CCT embedding pairs 11
l len_H: the number of characters of 𝑤! l len_K: the number of characters of 𝑤" l level_K: values defined based on standard learning year of 𝑤! l 1-6: taught in 𝑛th grade of elementary school l 7: taught after elementary school l 8: non-common use Kanji characters 15
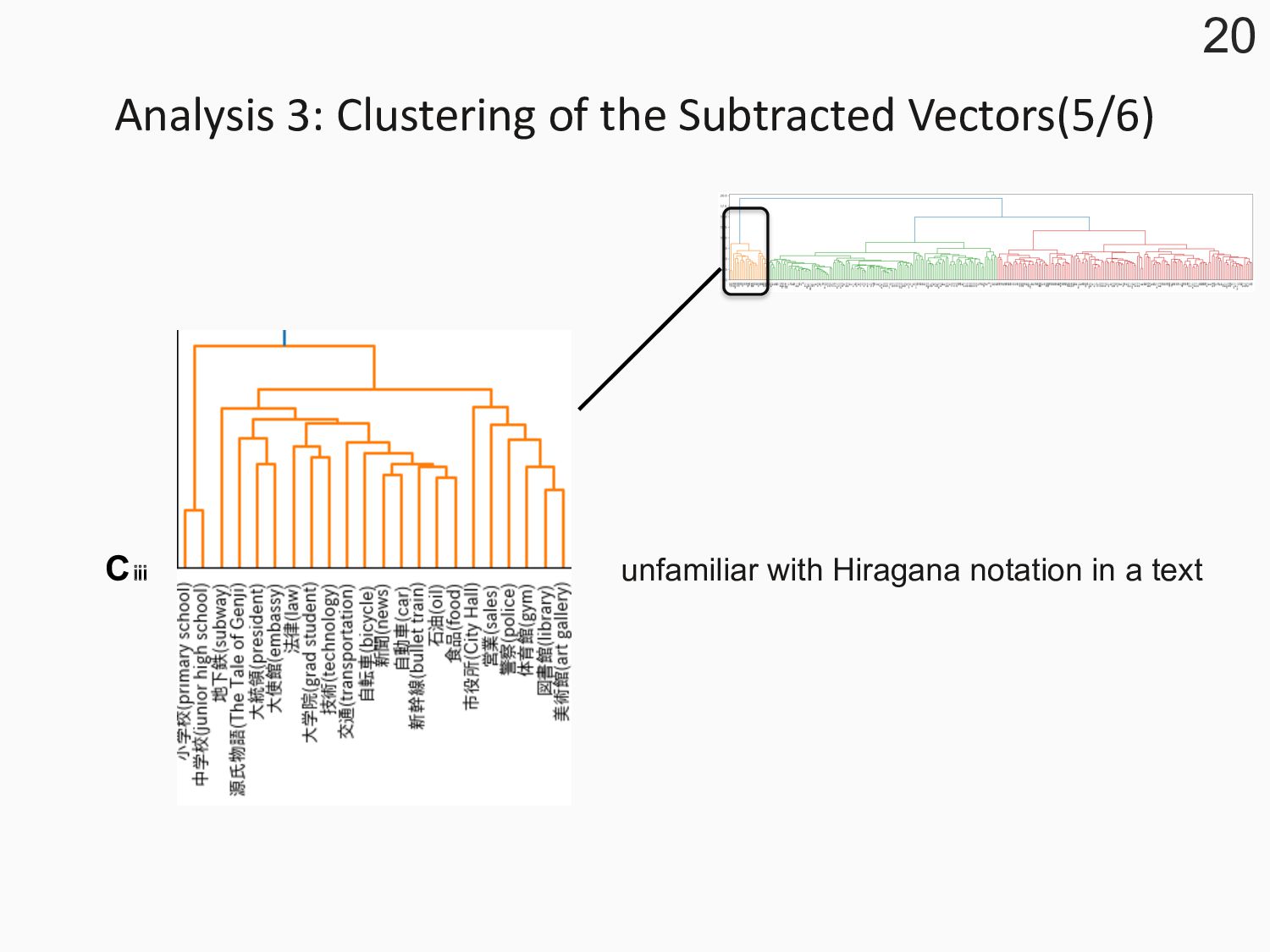
a hierarchical clustering l To explore words with comparable differences in word meanings in the CCT variants l It can be assumed that words with similar subtracted vectors are similarly used in different character types, so it is possible to classify the influence of character types. l WARD algorithm 16
two subtracted vectors with some semantic relations tend initially to be merged. l It suggests that words with some semantic relations have a similar usage of CCT variants in a text. l Synonym l 速い(fast) and 早い(quick) l 曲がる(bend) and 折れる(break) l Words with causal or order relationships l 合格(pass) and 卒業(graduation) l 危ない(dangerous) and 壊れる(broken) l Antonym l ⼤きな(large) and ⼩さな(small) l 登る(climb) and 降りる(climb down) 17
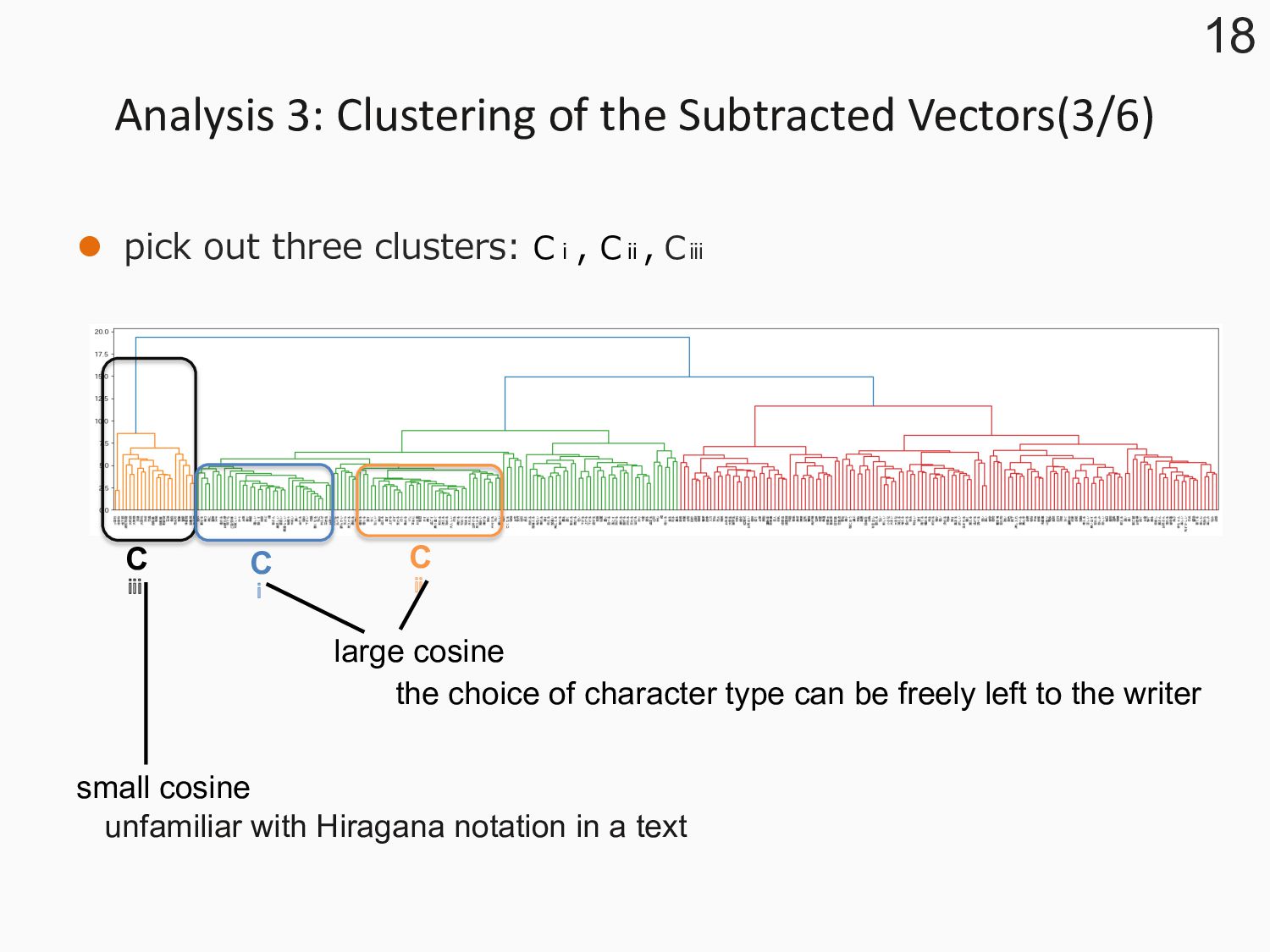
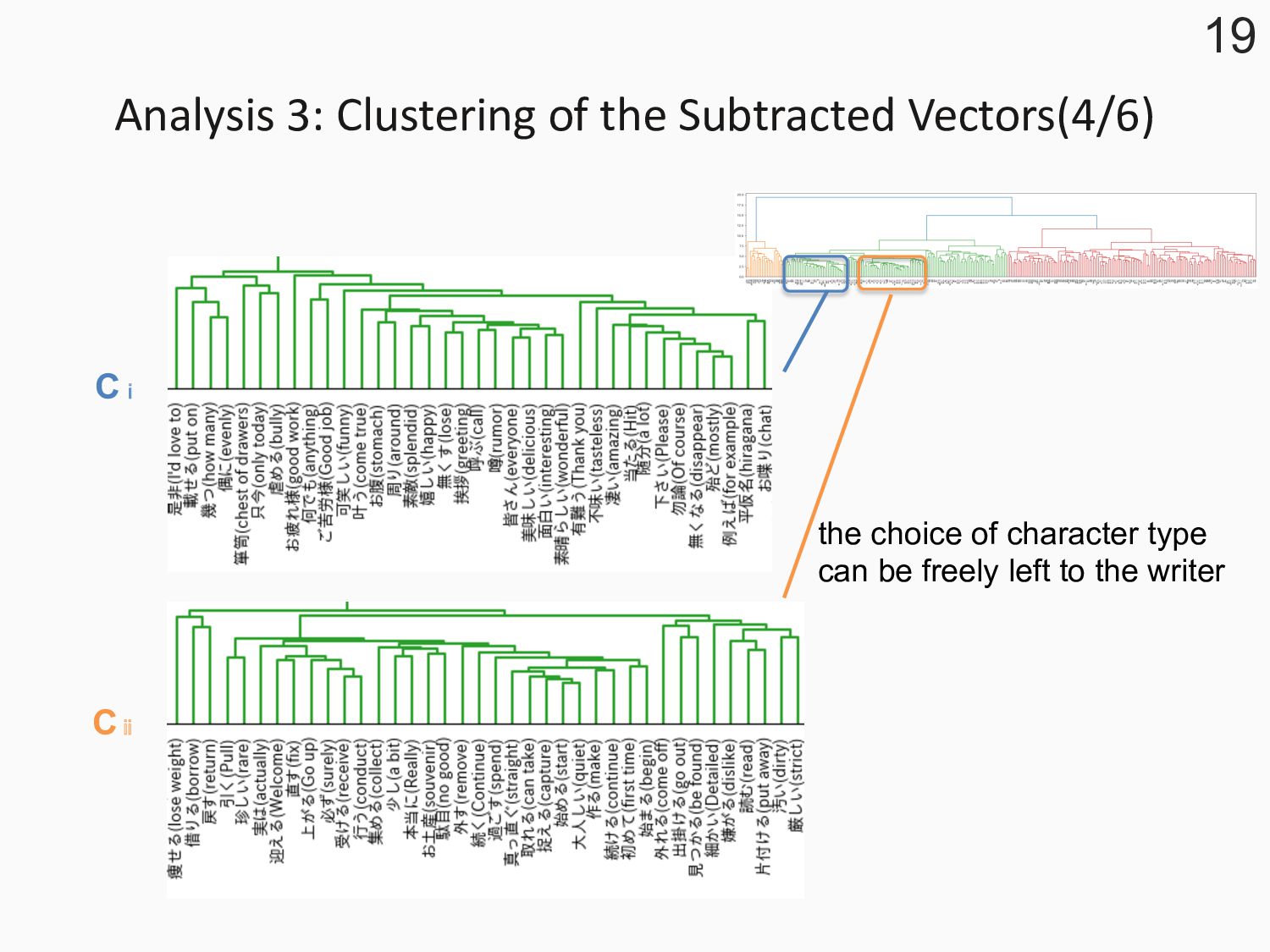
three clusters: Cⅰ, Cⅱ, Cⅲ 18 C ⅰ C ⅱ C ⅲ small cosine large cosine the choice of character type can be freely left to the writer unfamiliar with Hiragana notation in a text
types and attempted to utilize word embeddings to analyze the differences in word meanings. l We analyzed 293 words and found that CCT words can have different meanings, especially CCT nouns, which tend to have low cosine similarity values that suggest holding different meanings. l Through the clustering of subtracted vectors, CCT word pairs consisting of two semantically-related words tend to construct clusters. l We are currently analyzing to find out more details. 22
character types (e.g. Katakana) l other target words (e.g. onomatopoeia) l other vocabulary-based indices (e.g. word familiarity) l dynamic word embeddings (e.g. BERT) 23
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Word Embeddings Used l Wikipedia Entity Vectors[6] l Trained from](https://files.speakerdeck.com/presentations/259a5804a8fe46a099b1fe9cccac34a6/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Analysis 3: Clustering of the Subtracted Vectors(2/6) l [n=2 cluster]](https://files.speakerdeck.com/presentations/259a5804a8fe46a099b1fe9cccac34a6/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}