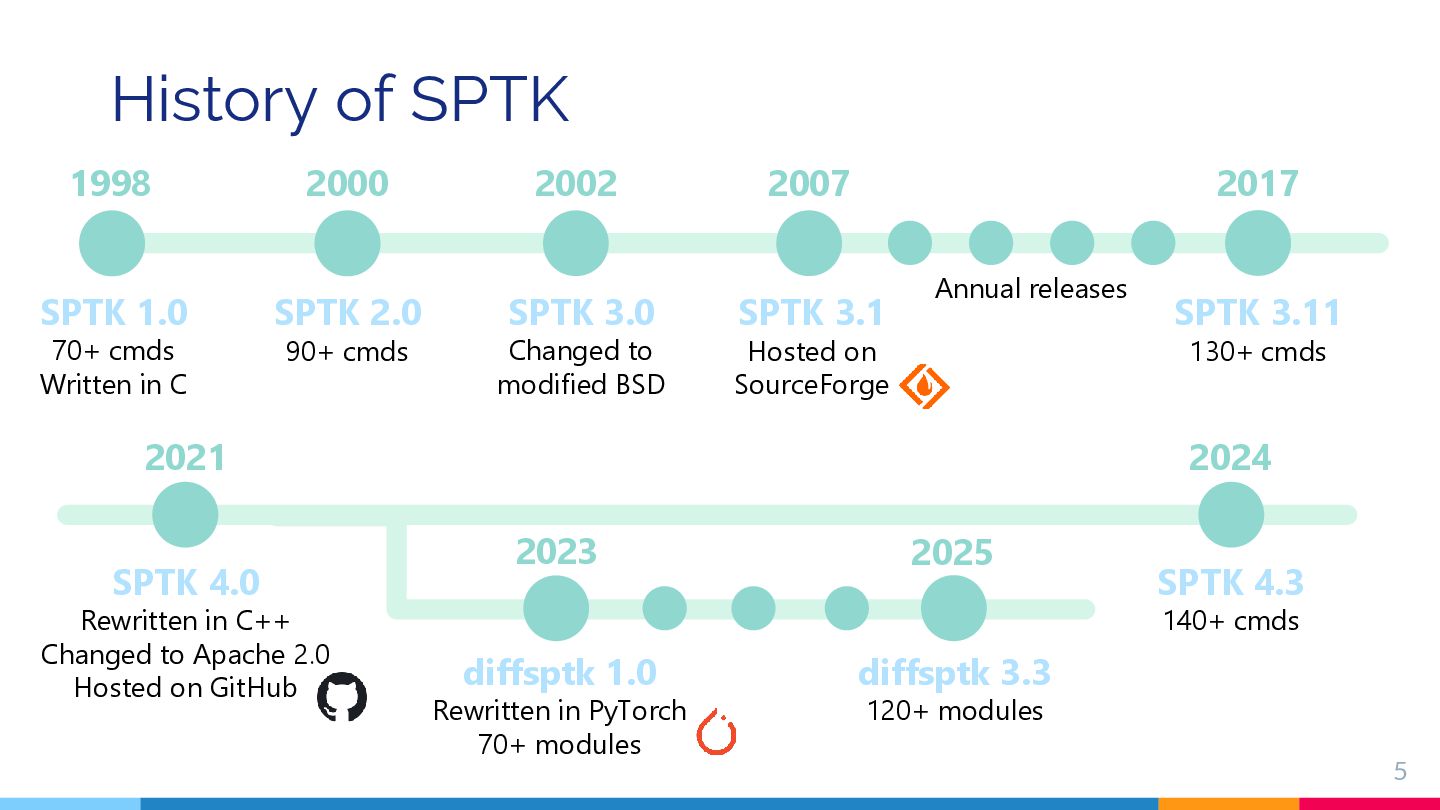
The Speech Signal Processing Toolkit (SPTK) is an open-source suite of tools for speech signal processing, including speech analysis and synthesis. It has been actively maintained and widely used in the speech processing community since its initial release in 1998. This lecture introduces the core concepts of SPTK, along with a brief overview of the fundamentals of speech signal processing. In addition, a differentiable extension of SPTK, called diffsptk, is also introduced. Designed for integration with deep learning workflows, diffsptk helps bridge the gap between classical signal processing and modern neural network architectures.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
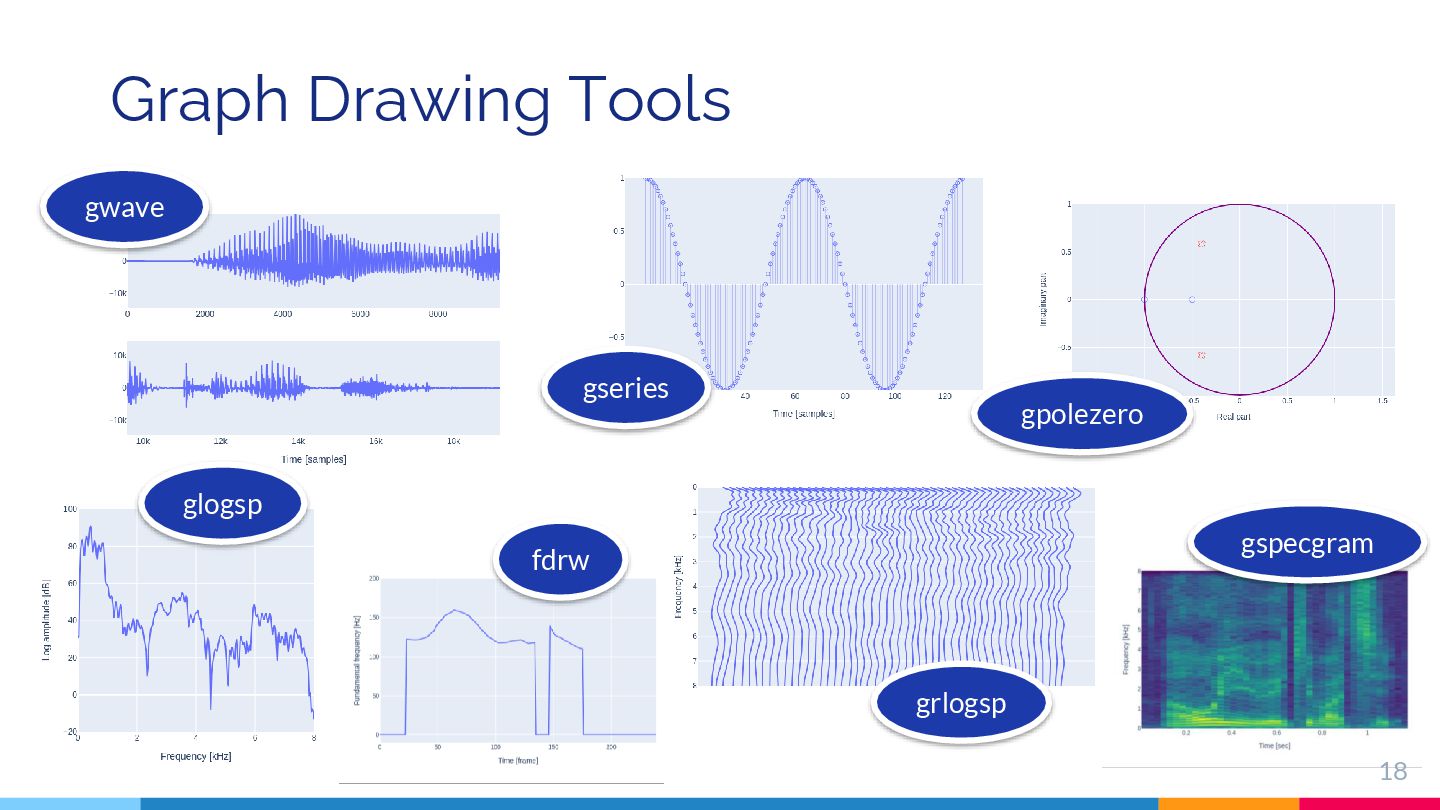{kind=link}
{kind=link}
{kind=link}
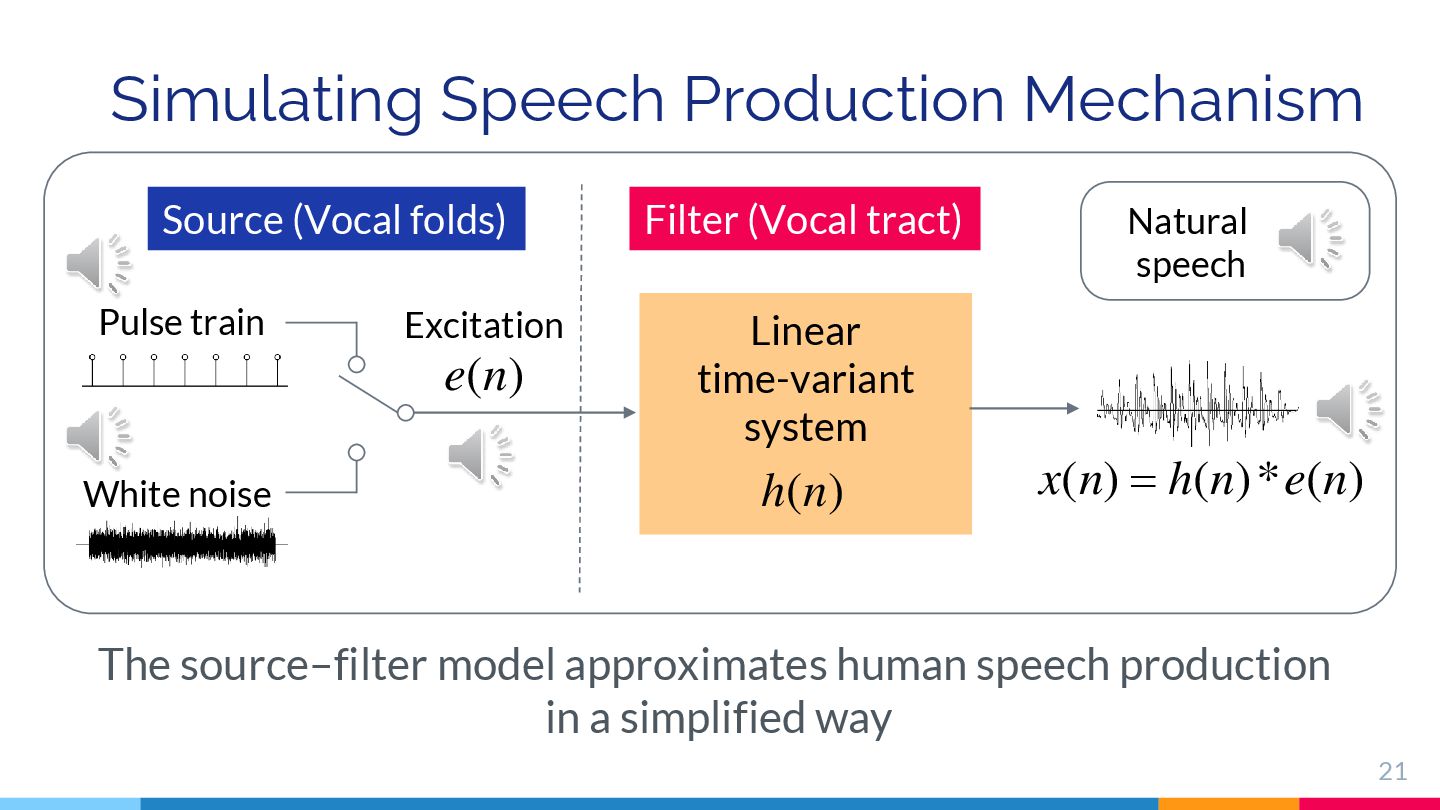{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
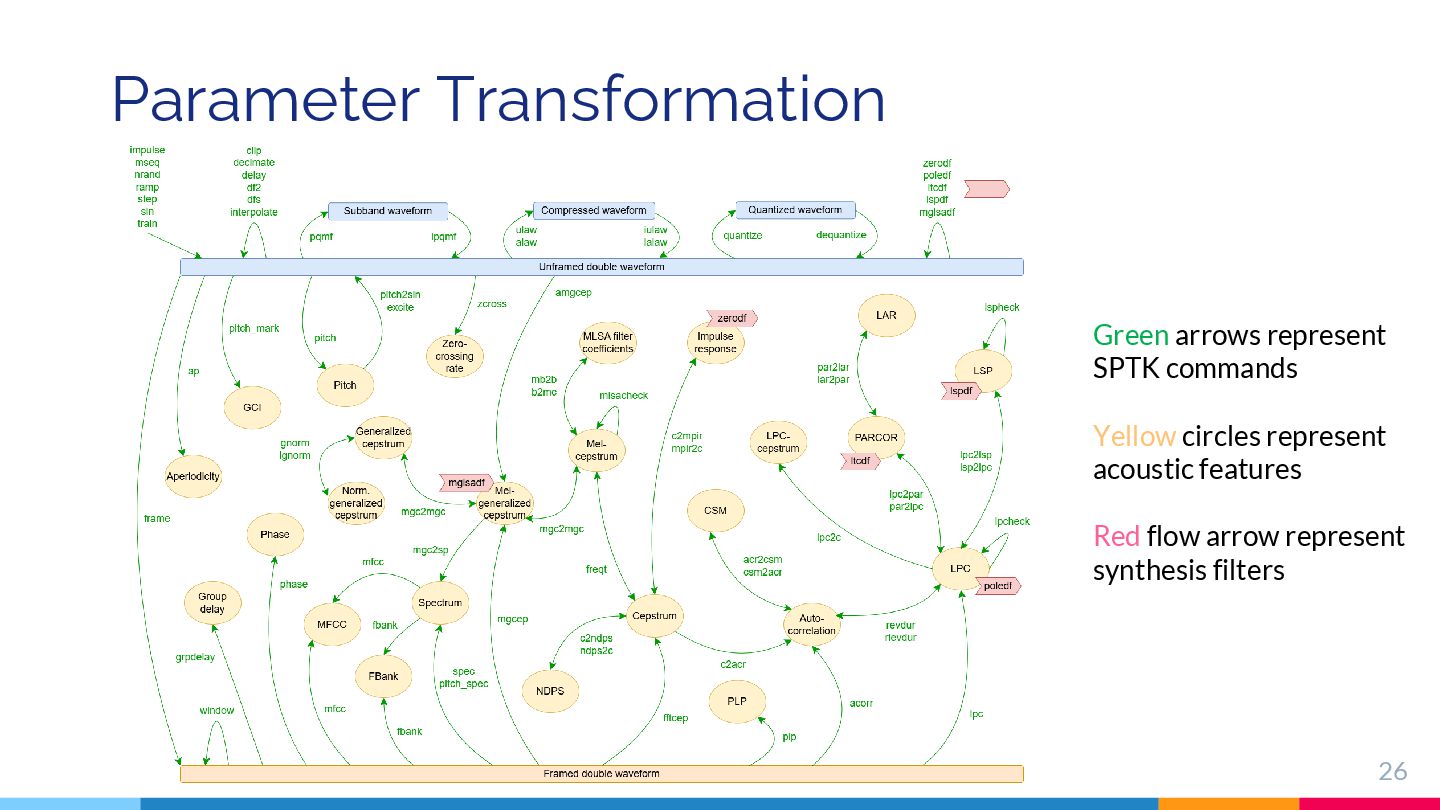{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
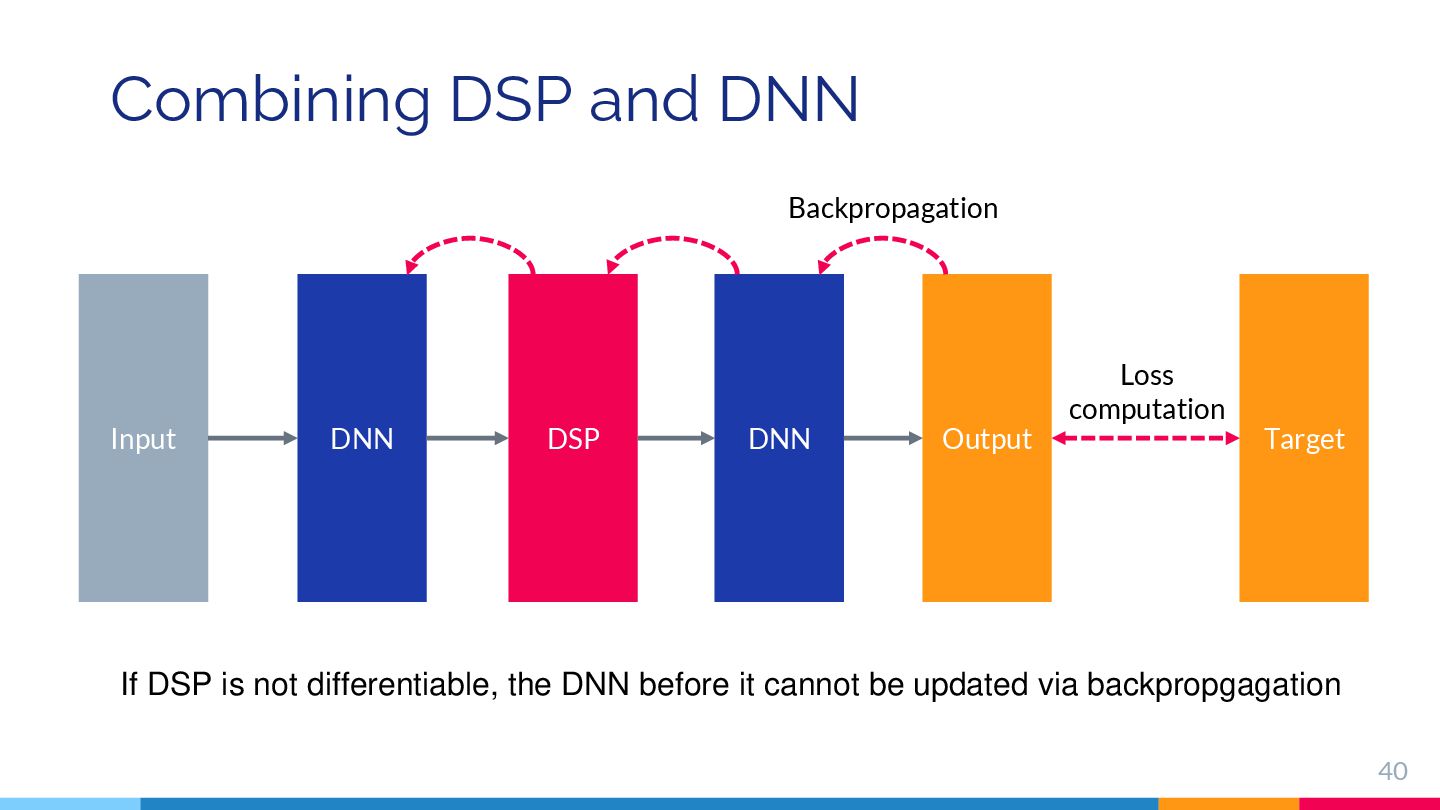{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}