few-shot learners. Advances in neural information processing systems, 33, 1877-1901. • Carlini, N., et al.. (2021). Extracting training data from large language models. In 30th USENIX Security Symposium (USENIX Security 21), 2633-2650. • Carlini, N., et al.. (2023). Quantifying Memorization Across Neural Language Models. In The Eleventh International Conference on Learning Representations. • D'ignazio, C., & Klein, L. F. (2020). Data feminism. MIT press. • Feng, S., et al.. (2023). From Pretraining Data to Language Models to Downstream Tasks: Tracking the Trails of Political Biases Leading to Unfair NLP Models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 11737–11762. • Gao, L., et al.. (2020). The pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027. • Hagendorff, T., et al.. (2023). Speciesist bias in AI: how AI applications perpetuate discrimination and unfair outcomes against animals. AI and Ethics, 3(3), 717-734. • Hoffmann, J., et al.. (2022). Training compute-optimal large language models. arXiv preprint arXiv:2203.15556. • Lewis, M., et al.. (2020). BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 7871-7880. • OpenAI. (2023). GPT-4 Technical Report. arXiv preprint arXiv:2303.08774. • Ouyang, L., et al.. (2022). Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35, 27730-27744. • Santurkar, S., et al.. (2023). Whose Opinions Do Language Models Reflect?. The Fortieth International Conference on Machine Learning. • Schaeffer, R., et al.. (2023). Are Emergent Abilities of Large Language Models a Mirage?. ICML 2023 Workshop DeployableGenerativeAI. • Touvron, H., et al.. (2023a). Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971. • Touvron, H., et al.. (2023b). Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288. • Wang, B., et al.. (2023). DecodingTrust: A Comprehensive Assessment of Trustworthiness in GPT Models. arXiv preprint arXiv:2306.11698. • Wei, J., et al.. (2022). Emergent Abilities of Large Language Models. Transactions on Machine Learning Research. 27
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
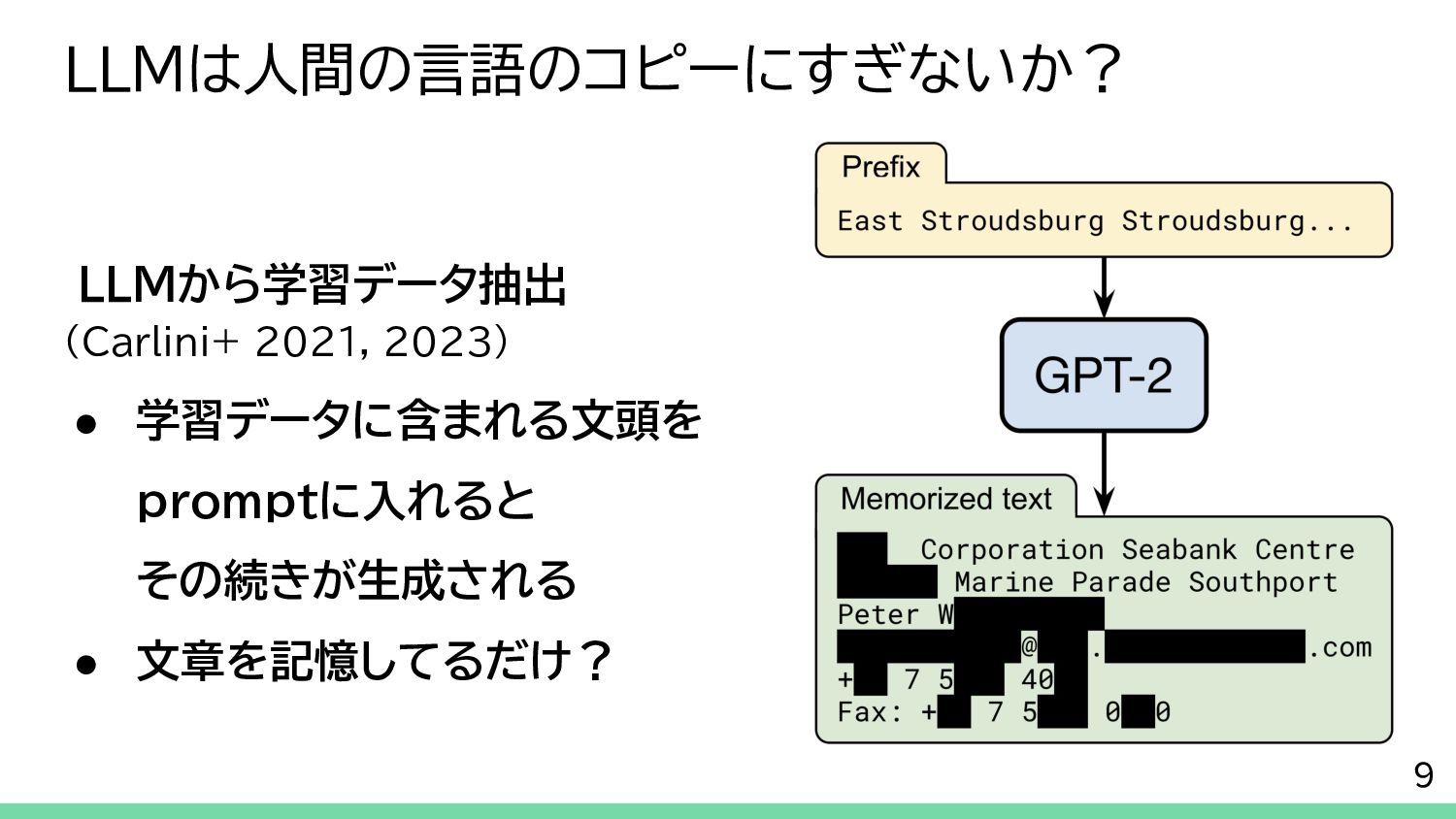{kind=link}
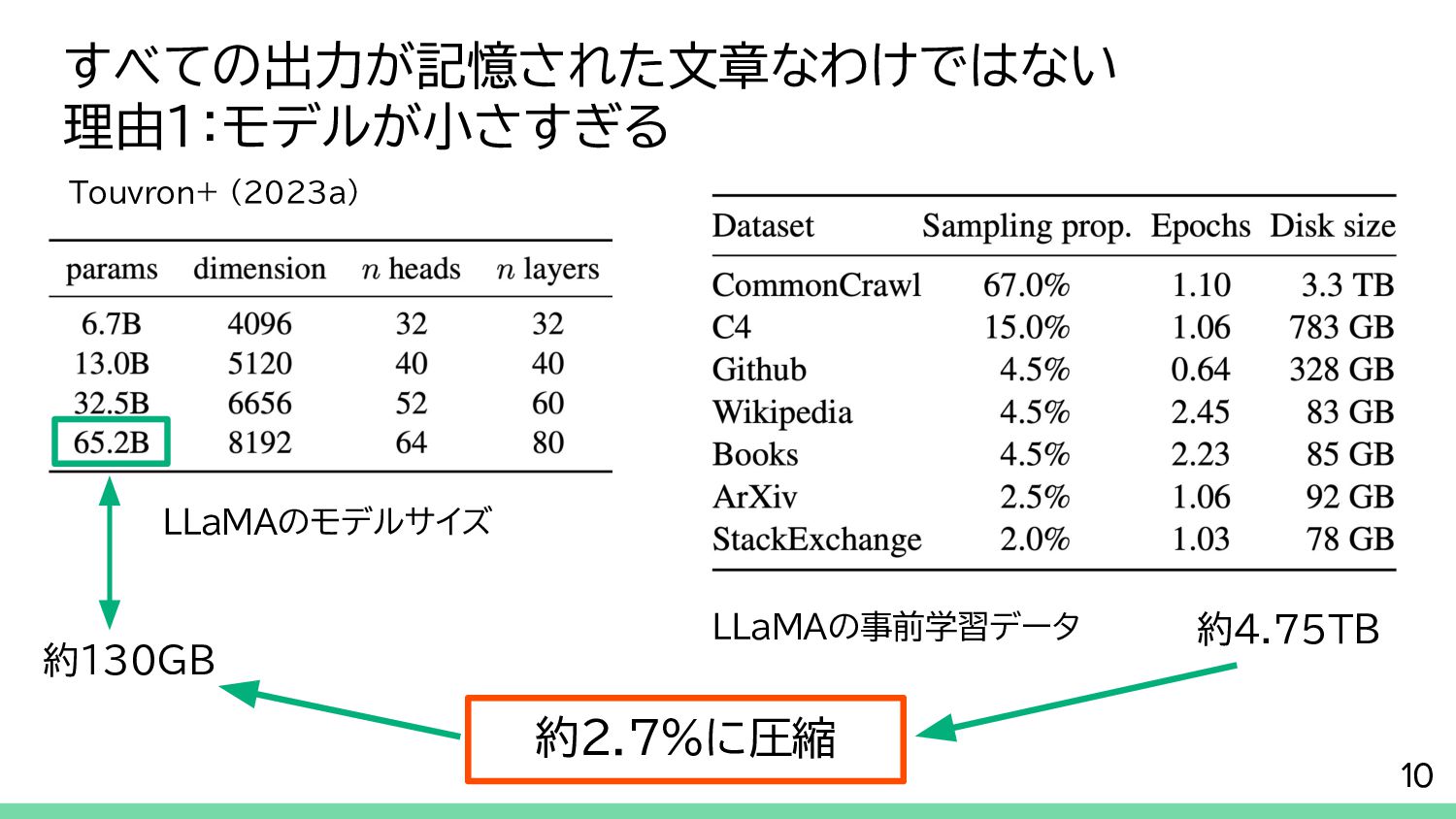{kind=link}
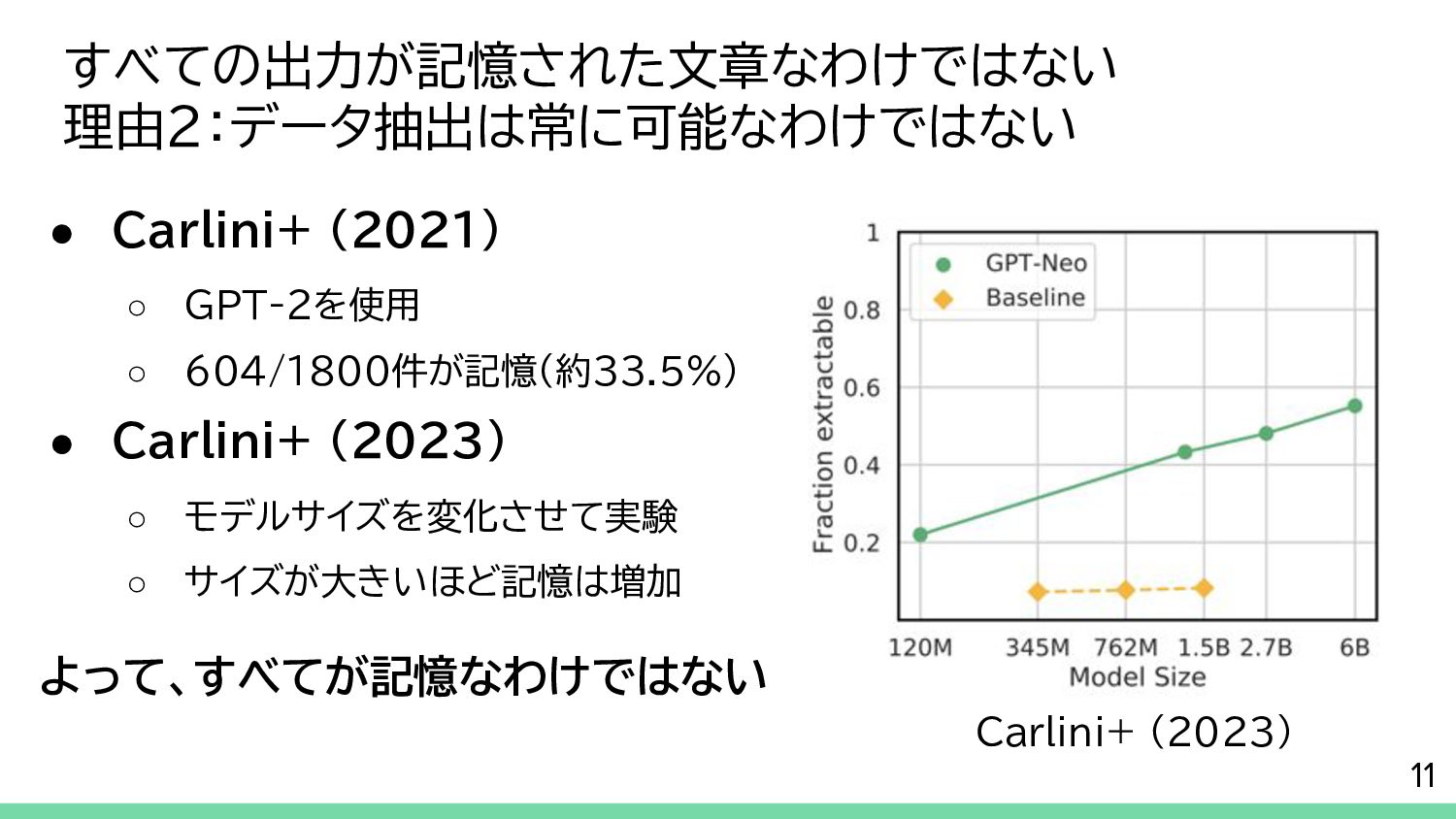{kind=link}
{kind=link}
{kind=link}
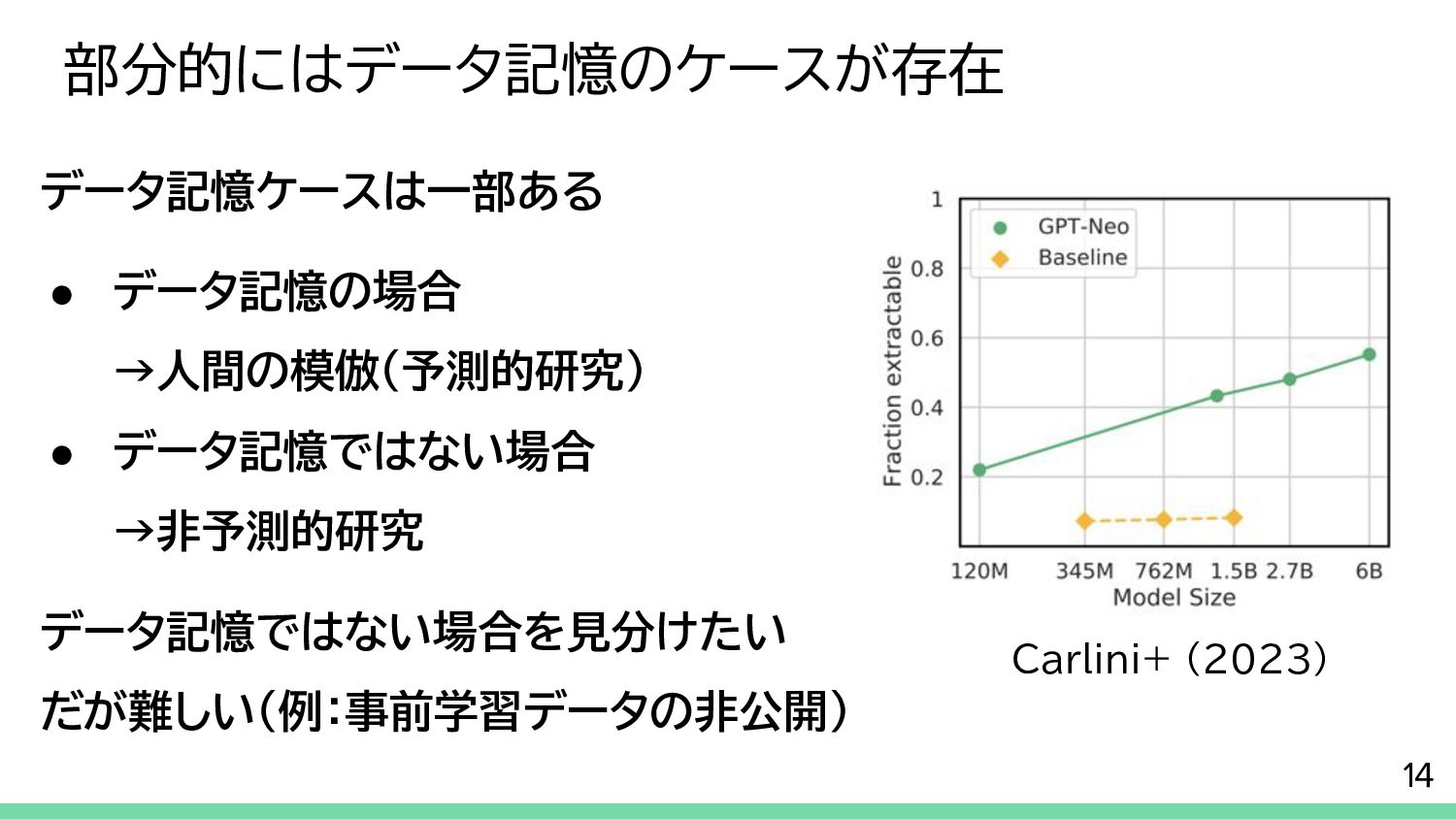{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}