Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
OpenShift_BootCamp_3章システム運用
Search
taketomsho
March 07, 2022
Technology
61
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
OpenShift_BootCamp_3章システム運用
taketomsho
March 07, 2022
More Decks by taketomsho
See All by taketomsho
いまからでも遅くない!Git超入門(ハンズオン編)
taketomsho
0
150
いまからでも遅くない!Git超入門 ハンズオン編 rerun
taketomsho
0
520
OpenShift_BootCamp_1章_概要
taketomsho
0
54
OpenShift_BootCamp_2章デプロイ
taketomsho
0
130
Other Decks in Technology
See All in Technology
Claude Code の Sandbox 機能を Anthropic Sandbox Runtime(srt) で試そう!/lets-play-anthropic-sandbox-runtime
tomoki10
1
320
タクシーアプリ『GO』の実践的データ活用
mot_techtalk
3
180
チームで実践する AI-DLC 思考の軌跡を残すチェックポイント設計
belongadmin
0
3.1k
もりもり新機能を一挙紹介! AgentCoreに入門して、AWS上にAIエージェントを構築しよう
minorun365
PRO
6
870
小さくはじめるSLI/SLO ~育てながら組織に定着させる実践知~ / Starting Small with SLI/SLOs: Building Adoption Through Continuous Growth
nari_ex
0
250
LLMと共に進化するプロセスを目指して
ymatsuwitter
12
3.7k
非エンジニアがClaudeと挑んだ「1ヶ月間プロダクト30本ノック」
askokc
0
150
[モダンアプリ勉強会]今更聞けないGit/GitHub入門
tsukuboshi
0
310
個人最適 から 全体最適 へ AI情報共有会・AIギルド・AI-DLC で進める カンリーの組織展開
rfdnxbro
0
2k
「コーディング」しない人のための Claude Code 入門 ChatGPT の次の一歩 — 業務に組み込む 育成・共有・自動化
rfdnxbro
2
1.3k
AI駆動開発が変える、大規模開発の前提 ーHuman in the Loop から Human on the Loop へ / AIE2026
visional_engineering_and_design
30
22k
Socrates × Looker 〜セマンティックレイヤーで進化するデータ分析エージェント〜
hanon52_
3
1.6k
Featured
See All Featured
How to Ace a Technical Interview
jacobian
281
24k
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
How STYLIGHT went responsive
nonsquared
100
6.2k
Statistics for Hackers
jakevdp
799
230k
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
570
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
31
3.2k
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
140
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8.2k
Ethics towards AI in product and experience design
skipperchong
2
300
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
160
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
Transcript
OpenShift Boot Camp OpenShift入門コース 3章 システム運用 Tech Dojo
目次 © 2021 IBM Corporation 2 3-1. スケーリング 3-2. モニタリング
オプションの演習(演習時間に余裕のある方は実施してください) オプション演習1. ヘルスチェックの設定 オプション演習2. HPAによるPodの自動スケーリング ・OpenShiftのアップデート ・ログ管理 ・構成変更管理 ・バックアップ ・災害対策 *この研修では詳細を扱わないシステム運用
OpenShiftでも可用性向上機能 © 2021 IBM Corporation 3 ◼ ヘルスチェック • Readiness
Probe:Podがリクエストを受付可能なこと • Liveness Probe :Podが正常稼働していること ◼ セルフヒーリング – K8sと同じ機能:Podの再起動と再配置を実施 ◼ サービス・ディスカバリーと負荷分散 – クライアント、エンドユーザーにアプリケーションアクセスのエンドポイントを提供 – 複数Podにスケールしたサービスへの負荷分散を実施 – ヘルスチェックの結果を受けてPodへのアクセスを制御 ◼ オートスケール – CPU負荷に基づいてPod数の増減を実施 (Horizontal Pod Autoscaler) – クラスターのリソースに基づいてWorkerNodeの増減を実施 (Machine Autoscaler) Kubernetes主要機能の組み合わせにより、サービスの高い可用性を実現 : この章で扱う項目
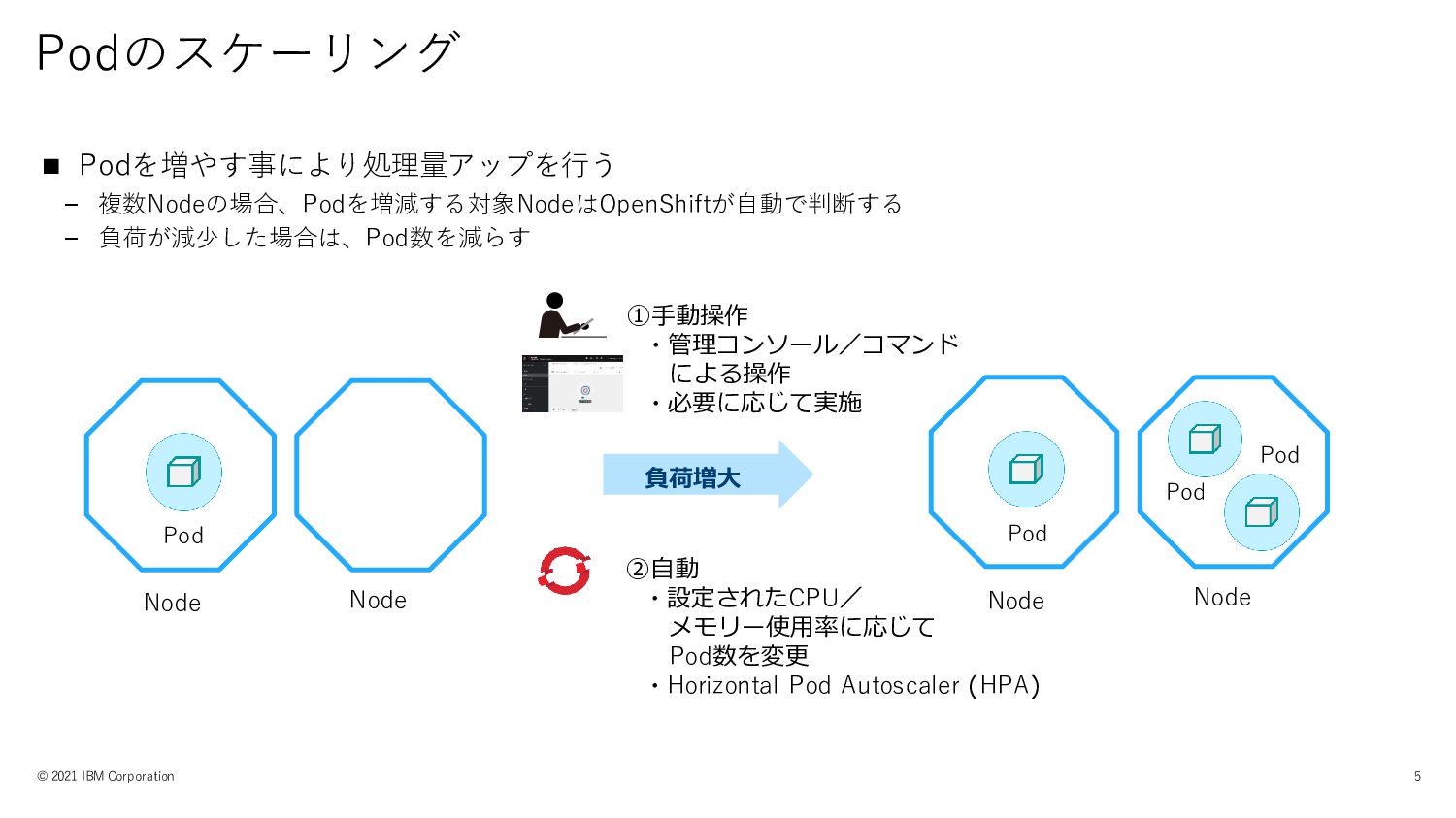
3-1. スケーリング © 2021 IBM Corporation 4
②自動 ・設定されたCPU/ メモリー使用率に応じて Pod数を変更 ・Horizontal Pod Autoscaler (HPA) Podのスケーリング ©
2021 IBM Corporation 5 ◼ Podを増やす事により処理量アップを行う – 複数Nodeの場合、Podを増減する対象NodeはOpenShiftが自動で判断する – 負荷が減少した場合は、Pod数を減らす Node Pod 負荷増大 ①手動操作 ・管理コンソール/コマンド による操作 ・必要に応じて実施 Node Node Pod Node Pod Pod
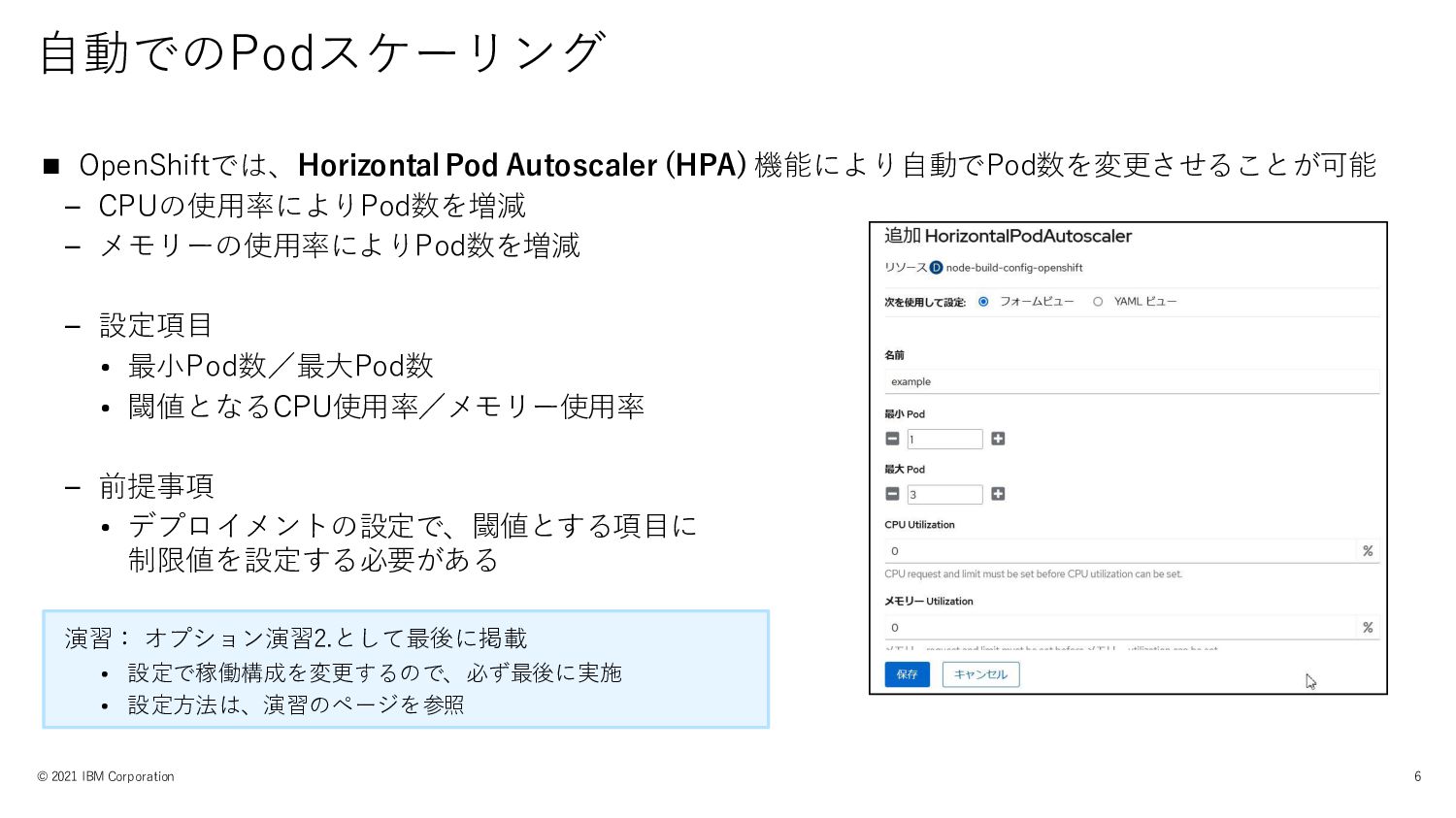
自動でのPodスケーリング © 2021 IBM Corporation 6 ◼ OpenShiftでは、Horizontal Pod Autoscaler
(HPA) 機能により自動でPod数を変更させることが可能 – CPUの使用率によりPod数を増減 – メモリーの使用率によりPod数を増減 – 設定項目 • 最小Pod数/最大Pod数 • 閾値となるCPU使用率/メモリー使用率 – 前提事項 • デプロイメントの設定で、閾値とする項目に 制限値を設定する必要がある 演習: オプション演習2.として最後に掲載 • 設定で稼働構成を変更するので、必ず最後に実施 • 設定方法は、演習のページを参照
Worker Nodeのスケーリング © 2021 IBM Corporation 7 ◼ Worker Nodeのスケーリング
– Worker Nodeのリソース(CPU, メモリー等)に余裕がなくなった場合は、WorkerNodeを増やす ことにより処理性能を向上させる – Worker Nodeを増やす場合は、インフラにWorkerNodeを増やせるように用意しておく必要がある ◼ 手動によるWorkerNodeの増減 – MachineとMachineSetの構成を変更する事によりWorker Nodeを変更 ◼ 自動WorkerNode増減 – ClusterAutoscalerとMachineAutoscalerを設定する事により可能 • ClusterAutoscaler :ノード数の上限やスケールダウンの可否などを設定 • MachineAutoscaler : MachineSet内のMachine数を自動的に調整するためのリソース Node 説明のみで演習無し CPU メモリー Node Node
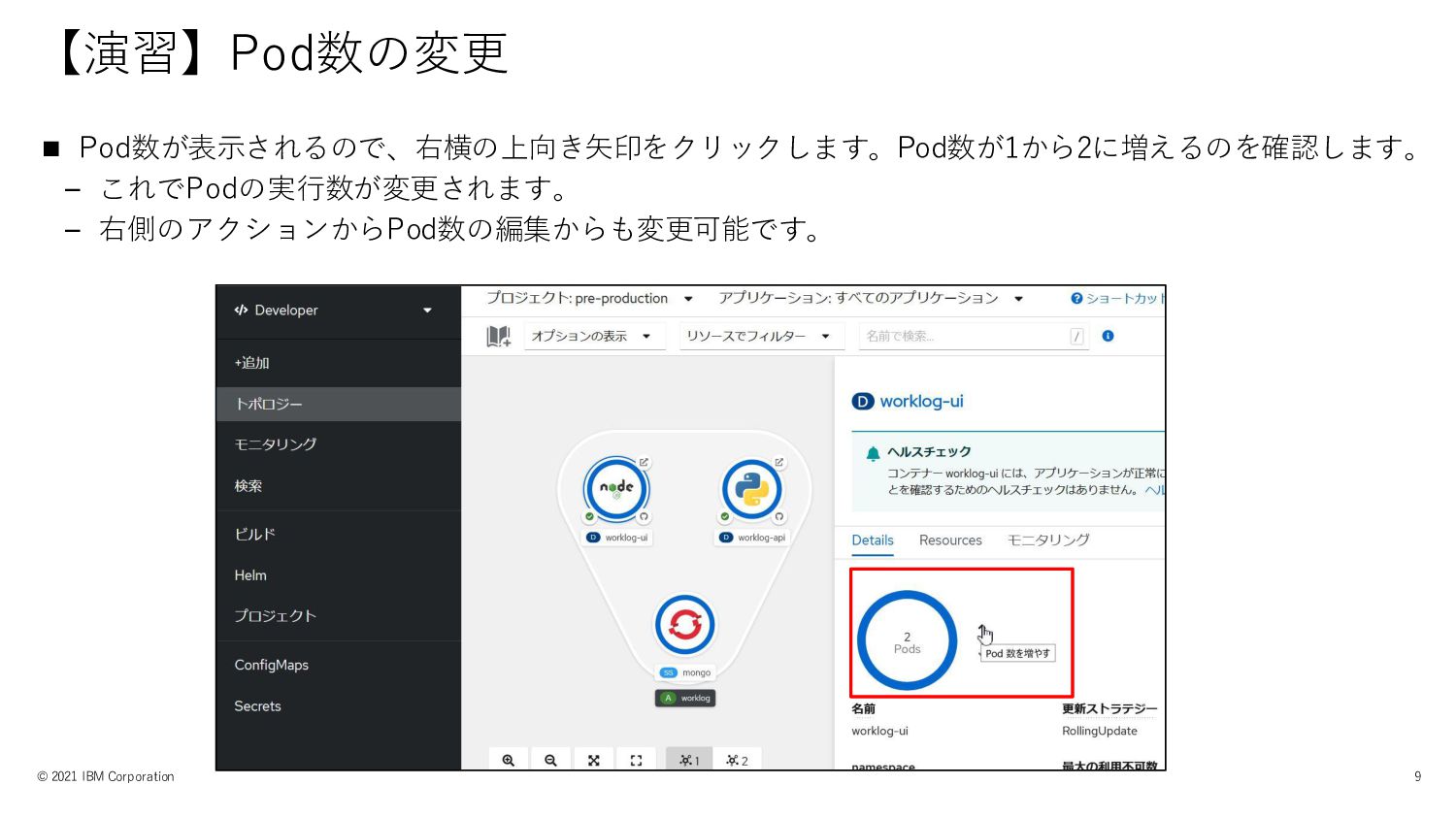
【演習】Pod数の変更 © 2021 IBM Corporation 8 ◼ Developerパースペクティブでトポロジーを表示し、自分のプロジェクトを設定します。 ◼ Pod数を変更するDeployment(ここでは[worklog-ui])を選択して、詳細画面で[Details]を選択します。
【演習】Pod数の変更 © 2021 IBM Corporation 9 ◼ Pod数が表示されるので、右横の上向き矢印をクリックします。Pod数が1から2に増えるのを確認します。 – これでPodの実行数が変更されます。
– 右側のアクションからPod数の編集からも変更可能です。
【演習】Pod数の変更 © 2021 IBM Corporation 10 ◼ 画面右側の[worklog-ui]をクリックして、デプロイメント画面を表示します。 ◼ [YAML]を選択して、「replicas」の設定が2になっていることを確認します。
– デプロイメントの設定上も変更されています。
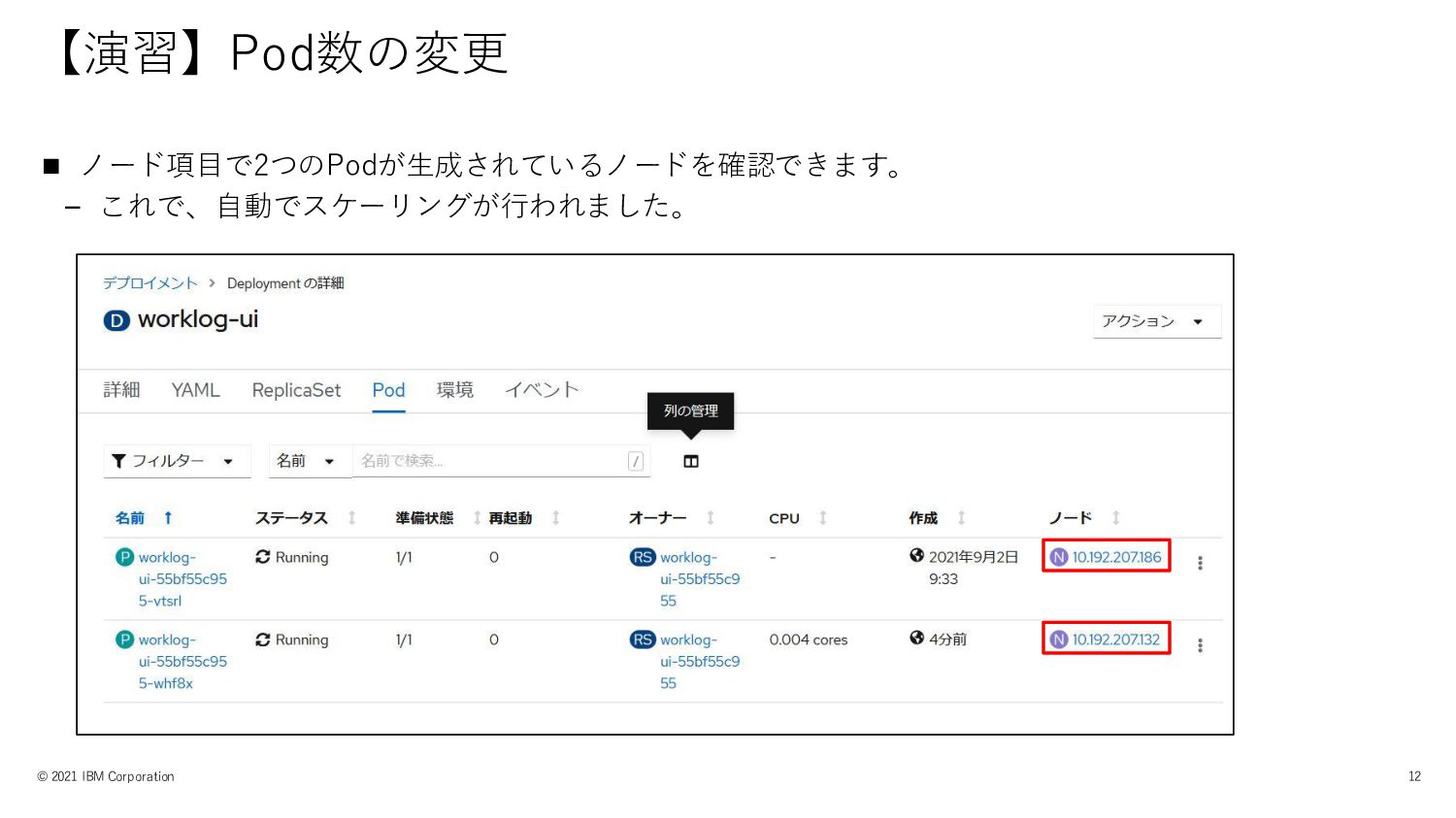
【演習】Pod数の変更 © 2021 IBM Corporation 11 ◼ Podを選択し[列の管理]アイコンを選択します。 ◼ 「列の管理」で、どれでも良いので左側の1つのチェックを外します。(画面はメモリー)
右側のノードを選択して保存します。
【演習】Pod数の変更 © 2021 IBM Corporation 12 ◼ ノード項目で2つのPodが生成されているノードを確認できます。 – これで、自動でスケーリングが行われました。
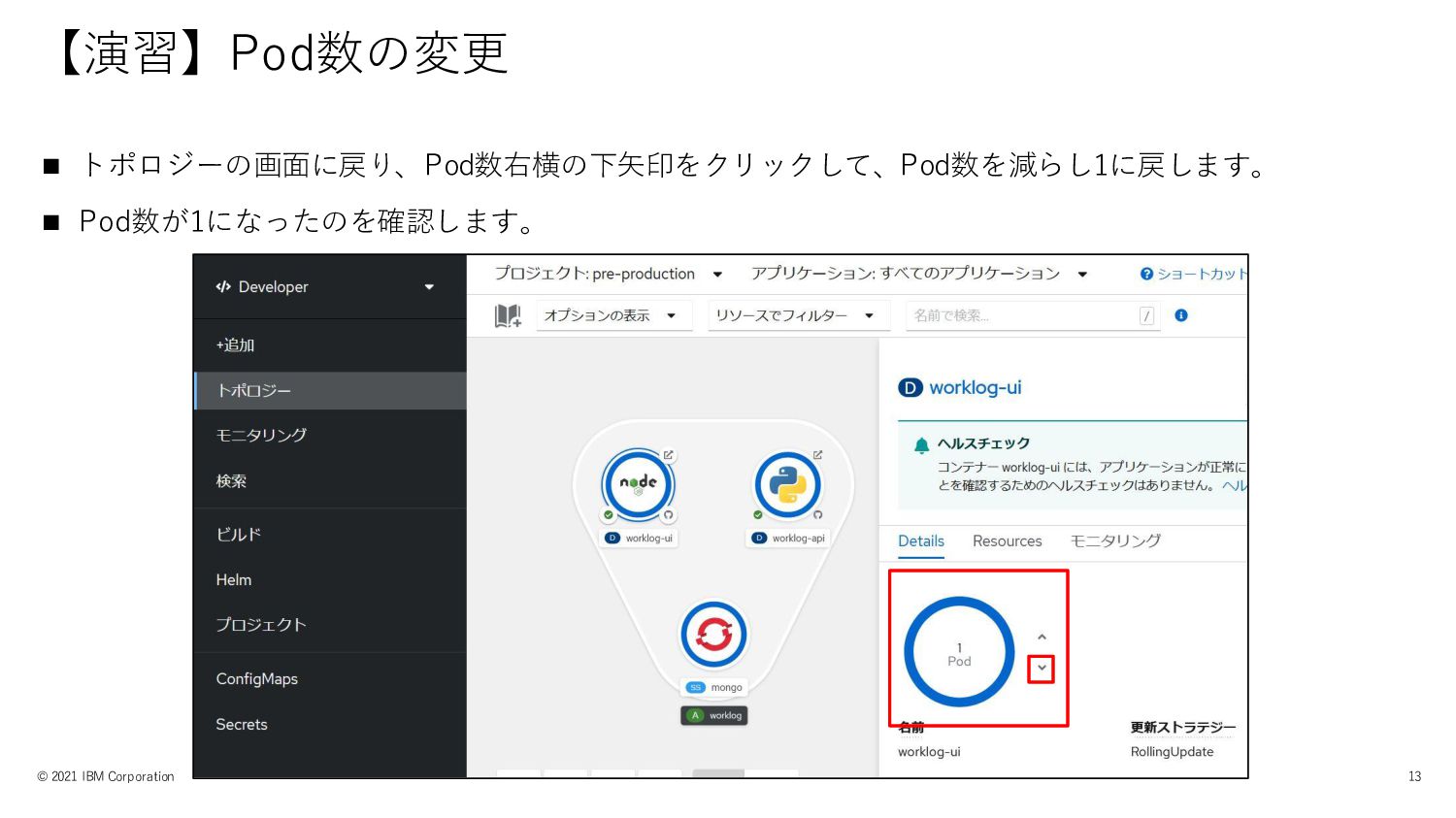
【演習】Pod数の変更 © 2021 IBM Corporation 13 ◼ トポロジーの画面に戻り、Pod数右横の下矢印をクリックして、Pod数を減らし1に戻します。 ◼ Pod数が1になったのを確認します。
【演習】障害の自動復旧(セルフヒーリング) © 2021 IBM Corporation 14 ◼ 演習の説明 – アプリケーションで起動するPod数が、DeploymentのYAMLファイルに定義されています。
– 今回は障害を発生させる代わりに実際にPodを1つ手動停止させます。 その後、 DeploymentのYAMLファイルに定義された数の通り、新しくPodが作成され起動されることを 確認します。
障害の自動復旧(セルフヒーリング) © 2021 IBM Corporation 15 ◼ 管理者パースペクティブで、[ワークロード]の[Pod]を選択します。プロジェクトは[pre-production]を 指定します。 ◼
[名前]に[worklog-ui-]を指定してworklog-uiのPodを探します。見つかったら[Podの削除]を選択します。
障害の自動復旧(セルフヒーリング) © 2021 IBM Corporation 16 ◼ 「Podを削除しますか?」と言う確認ダイアログがでるので、[削除]を選択します。 – この操作によりPodを強制的に停止させ、設定されている以下のPod数(この場合は0)にします。
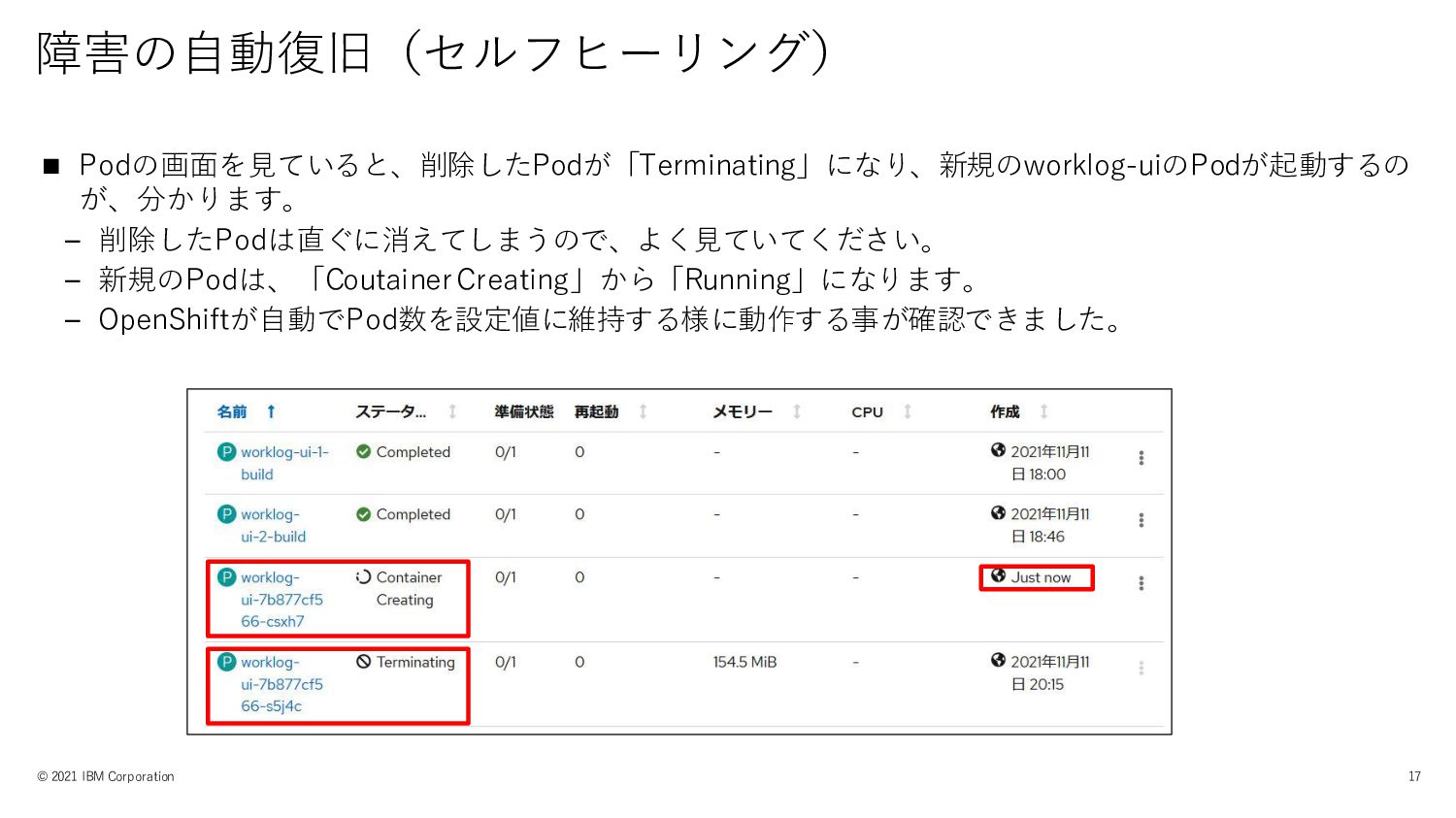
障害の自動復旧(セルフヒーリング) © 2021 IBM Corporation 17 ◼ Podの画面を見ていると、削除したPodが「Terminating」になり、新規のworklog-uiのPodが起動するの が、分かります。 –
削除したPodは直ぐに消えてしまうので、よく見ていてください。 – 新規のPodは、「CoutainerCreating」から「Running」になります。 – OpenShiftが自動でPod数を設定値に維持する様に動作する事が確認できました。
3-2.モニタリング IBM Garage / © 2021 IBM Corporation 18
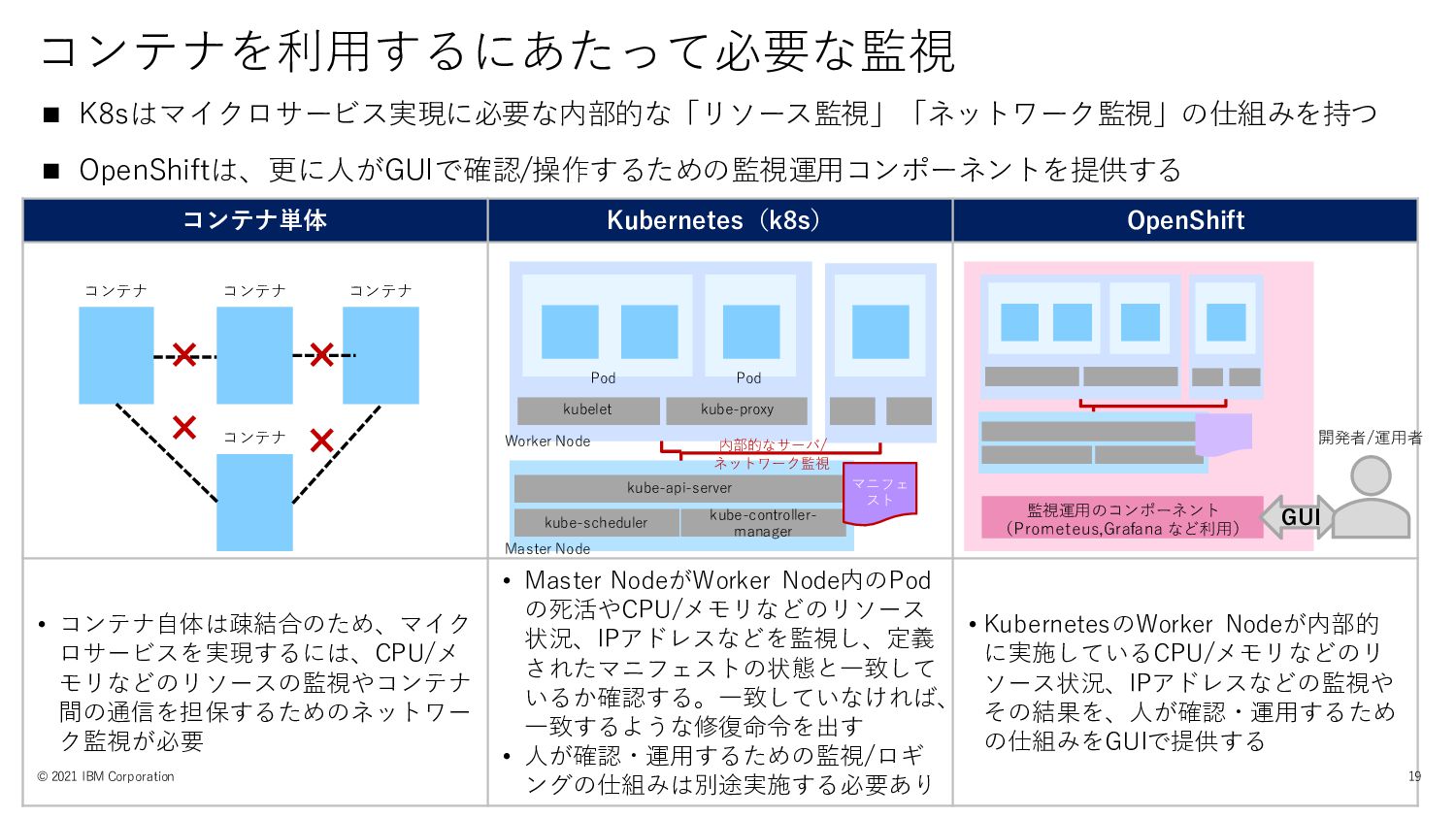
コンテナ単体 Kubernetes(k8s) OpenShift • コンテナ自体は疎結合のため、マイク ロサービスを実現するには、CPU/メ モリなどのリソースの監視やコンテナ 間の通信を担保するためのネットワー ク監視が必要 •
Master NodeがWorker Node内のPod の死活やCPU/メモリなどのリソース 状況、IPアドレスなどを監視し、定義 されたマニフェストの状態と一致して いるか確認する。一致していなければ、 一致するような修復命令を出す • 人が確認・運用するための監視/ロギ ングの仕組みは別途実施する必要あり • KubernetesのWorker Nodeが内部的 に実施しているCPU/メモリなどのリ ソース状況、IPアドレスなどの監視や その結果を、人が確認・運用するため の仕組みをGUIで提供する コンテナを利用するにあたって必要な監視 ◼ K8sはマイクロサービス実現に必要な内部的な「リソース監視」「ネットワーク監視」の仕組みを持つ ◼ OpenShiftは、更に人がGUIで確認/操作するための監視運用コンポーネントを提供する コンテナ コンテナ コンテナ コンテナ 監視運用のコンポーネント (Prometeus,Grafana など利用) GUI © 2021 IBM Corporation 19 Pod Worker Node kubelet kube-proxy Master Node kube-api-server kube-scheduler kube-controller- manager マニフェ スト 内部的なサーバ/ ネットワーク監視 Pod 開発者/運用者
代表的なOpenShiftの監視コンポーネント ◼ OpenShiftはk8sと親和性の高いOSSを活用して次のような監視コンポーネントを提供 機能 主な利用OSS 説明 Dashboards Grafana • ClusterやPodのCPU使用率、メモリ使用率、帯域幅、受信パケットなどデ
フォルトのメトリクスをグラフで確認 Metrics Prometheus • 任意のメトリクスをクエリを作成・実行することで結果を取得・表示 Alerting Alertmanager • アラートの管理(登録、検索 など) • サイレンスの管理(メンテナンス期間中にアラートをオフにする設定) © 2021 IBM Corporation 20
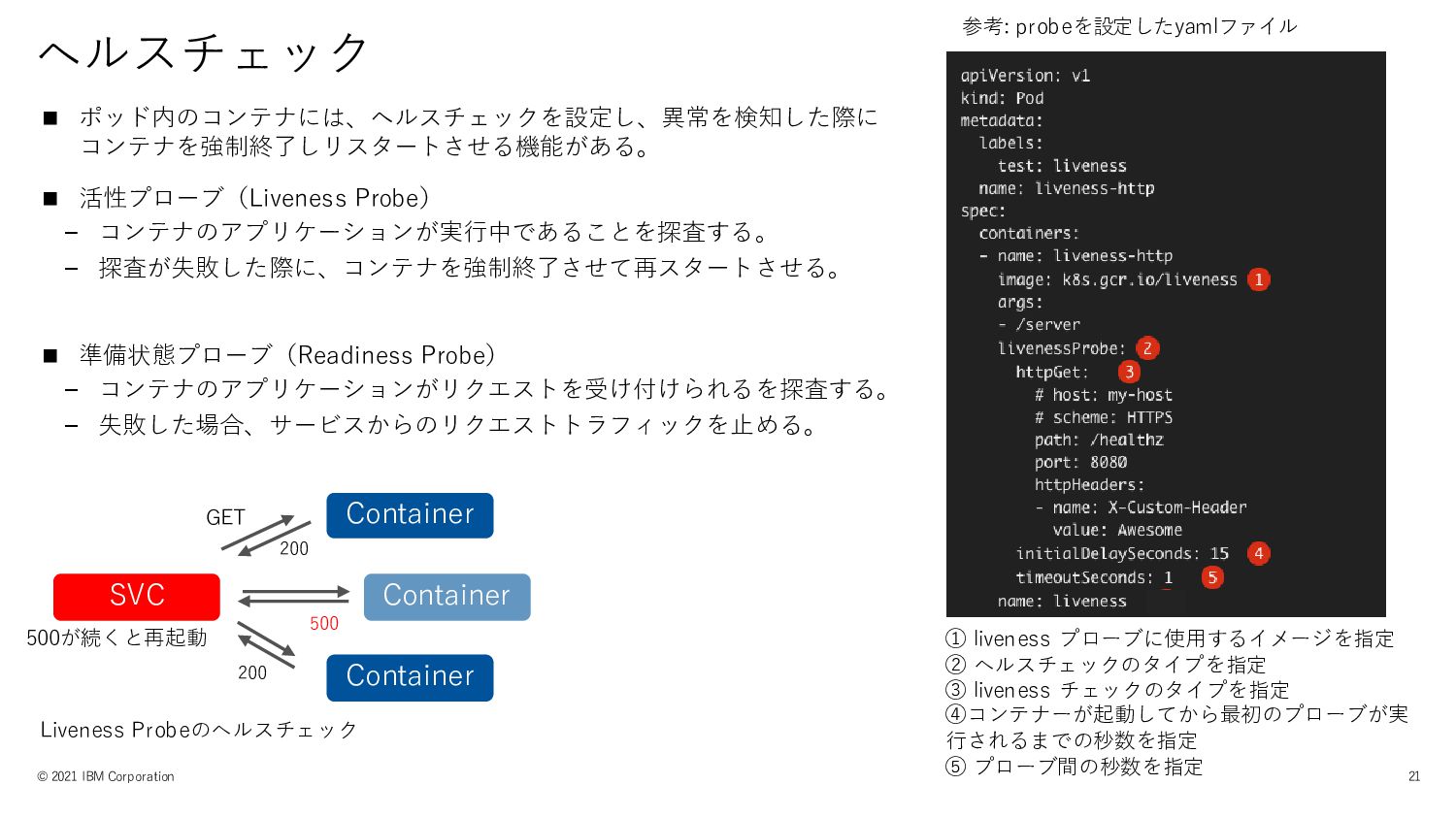
ヘルスチェック © 2021 IBM Corporation 21 ◼ ポッド内のコンテナには、ヘルスチェックを設定し、異常を検知した際に コンテナを強制終了しリスタートさせる機能がある。 ◼
活性プローブ(Liveness Probe) – コンテナのアプリケーションが実行中であることを探査する。 – 探査が失敗した際に、コンテナを強制終了させて再スタートさせる。 ◼ 準備状態プローブ(Readiness Probe) – コンテナのアプリケーションがリクエストを受け付けられるを探査する。 – 失敗した場合、サービスからのリクエストトラフィックを止める。 SVC Liveness Probeのヘルスチェック Container Container Container GET 200 500 200 500が続くと再起動 参考: probeを設定したyamlファイル ① liveness プローブに使用するイメージを指定 ② ヘルスチェックのタイプを指定 ③ liveness チェックのタイプを指定 ④コンテナーが起動してから最初のプローブが実 行されるまでの秒数を指定 ⑤ プローブ間の秒数を指定
【演習】Podのログの確認 © 2021 IBM Corporation 22 ◼ トポロジー画面からworklog-apiの[View logs]をクリックします。 –
worklog-uiはログが多いのでworklog apiを使用します。 ◼ Podのログが表されるので、 内容を確認してください。
◼ コンソールを表示し、管理者画面で左部メニューから[モニタリング]を展開し [ダッシュボード]をクリックします。 【演習】検証環境のリソースを確認しよう © 2021 IBM Corporation 23
◼ Namespace毎のPodのリソース使用状況を確認していきます。 ◼ [ダッシュボード]プルダウンメニューを展開し、 [Kubernetes / Compute Resources / Namespace
(Pods)]を選択します。 – 選択した内容によって、表示内容を絞り込むためのプルダウンメニュー(例: Namespace , Instance, Type)が変動します。 ◼ [Namespace]プルダウンメニューを展開し、[pre-production]を選択します。 【演習】検証環境のリソースを確認しよう 24 © 2021 IBM Corporation
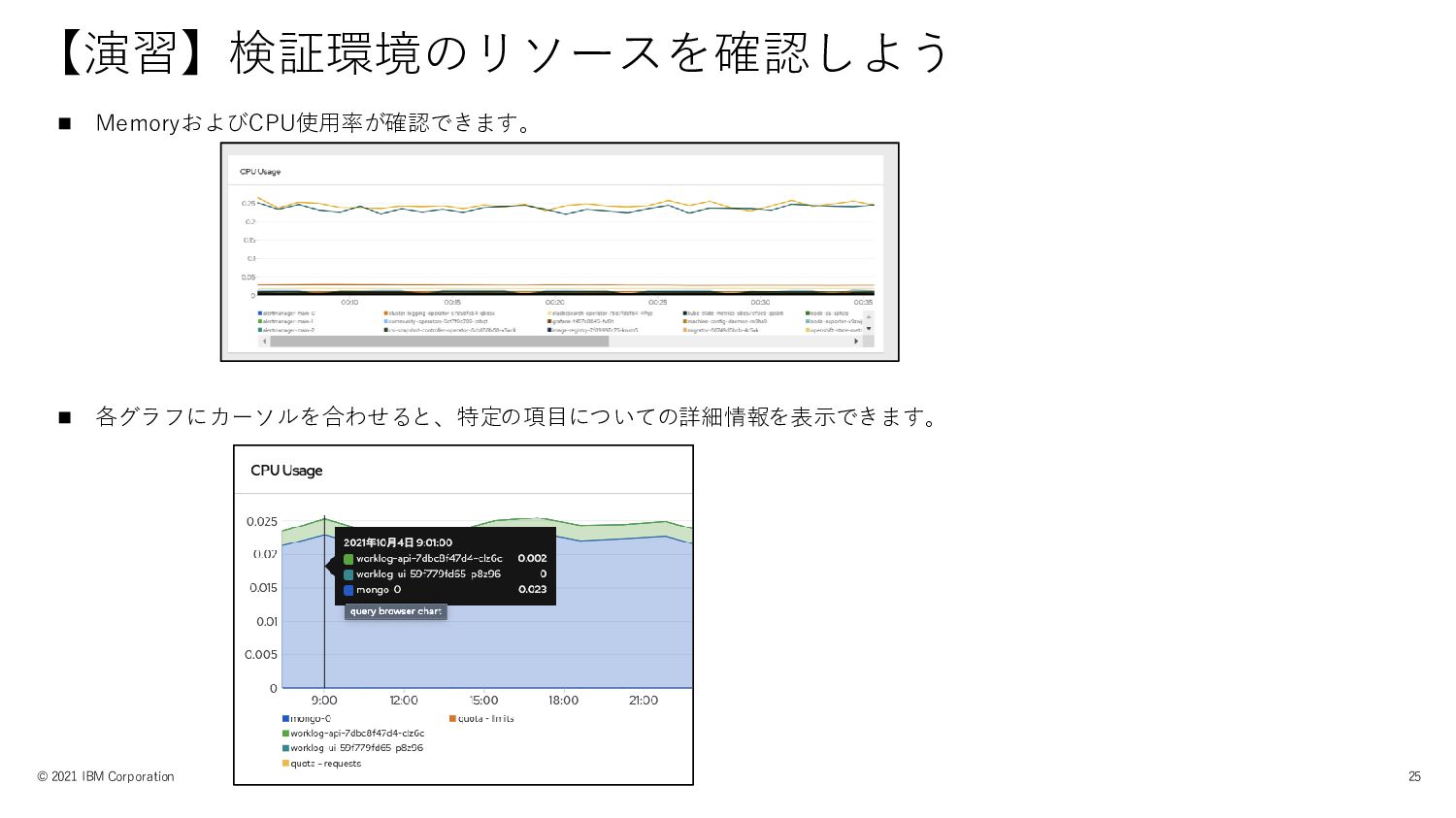
【演習】検証環境のリソースを確認しよう © 2021 IBM Corporation 25 ◼ MemoryおよびCPU使用率が確認できます。 ◼ 各グラフにカーソルを合わせると、特定の項目についての詳細情報を表示できます。
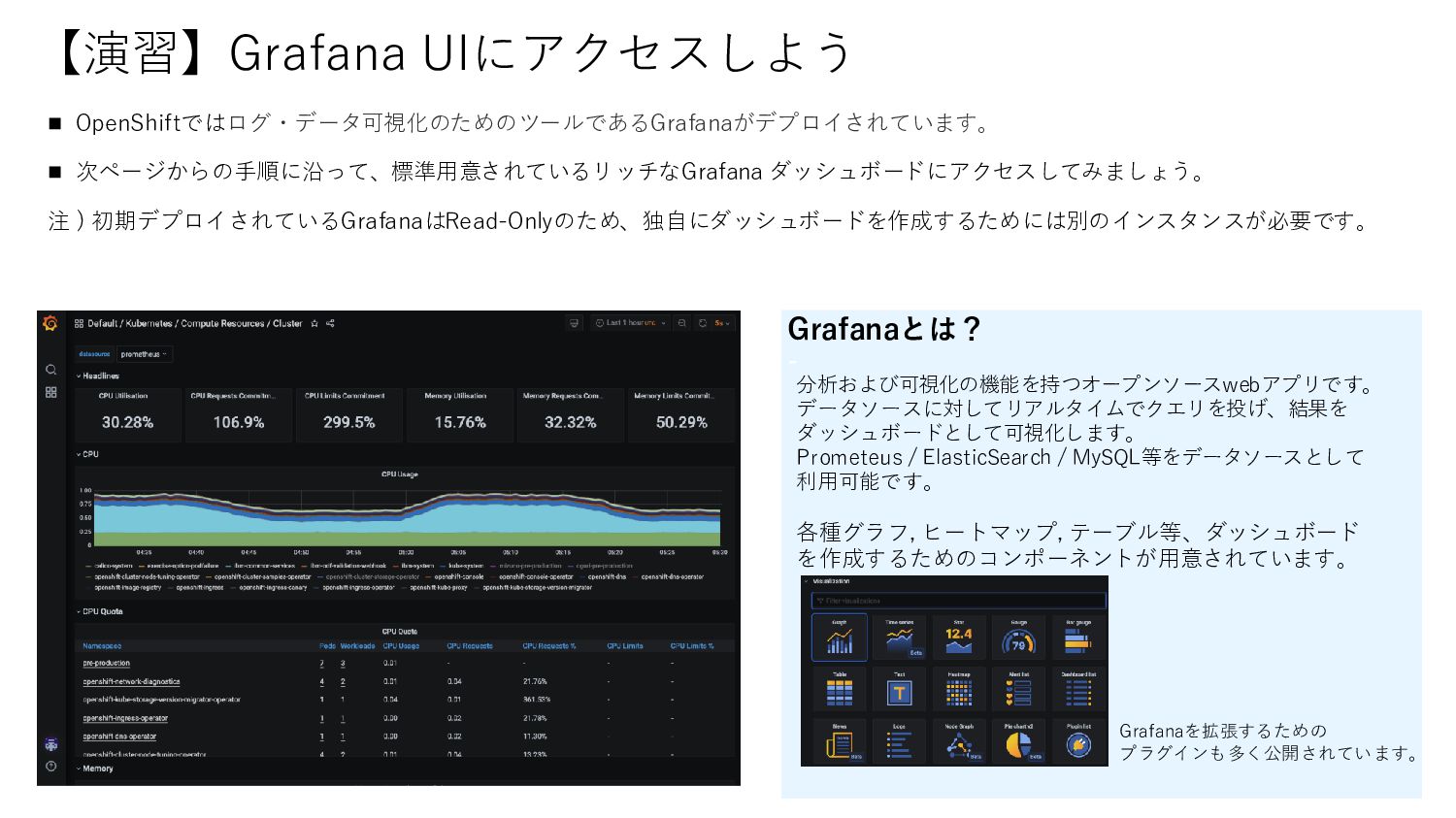
【演習】Grafana UIにアクセスしよう © 2021 IBM Corporation 26 ◼ OpenShiftではログ・データ可視化のためのツールであるGrafanaがデプロイされています。 ◼
次ページからの手順に沿って、標準用意されているリッチなGrafana ダッシュボードにアクセスしてみましょう。 注 ) 初期デプロイされているGrafanaはRead-Onlyのため、独自にダッシュボードを作成するためには別のインスタンスが必要です。 Grafanaとは? - 分析および可視化の機能を持つオープンソースwebアプリです。 データソースに対してリアルタイムでクエリを投げ、結果を ダッシュボードとして可視化します。 Prometeus / ElasticSearch / MySQL等をデータソースとして 利用可能です。 各種グラフ, ヒートマップ, テーブル等、ダッシュボード を作成するためのコンポーネントが用意されています。 Grafanaを拡張するための プラグインも多く公開されています。
◼ コンソールを表示し、管理者画面で左部メニューから[ネットワーク]を展開し [ルート]をクリックします。 ◼ 検索ボックスにgrafanaと入力すると、grafanaという名前のルートがヒットするので、場所列のURLをクリックします。 ◼ [Log in with OpenShift]をクリックします。
◼ Authorize Accessという画面で、[Allow selected permissions]をクリックします。 【演習】Grafana UIにアクセスしよう © 2021 IBM Corporation 27
【演習】Grafana UIにアクセスしよう © 2021 IBM Corporation 28 ◼ コンソールを表示し、管理者画面で左部メニューから[モニタリング]を展開し [ダッシュボード]をクリックします。
◼ ダッシュボードというタイトルの右横にある、[Grafana UI]をクリックします。 ◼ 遷移した画面で、[Log in with OpenShift]をクリックします。
【演習】Grafana UIにアクセスしよう 29 ◼ ログイン後に遷移するGrafanaのHome画面で、画面左のメニューバーにある[虫眼鏡アイコン]をクリックします。 注 ) Read-Onlyモードのため、メニューバーには一部のアイコンしか表示されていません。 直近のダッシュボード履歴 直近のGrafana公式ブログ記事
© 2021 IBM Corporation
◼ テキストボックスに[Cluster]と入力し、Kubernetes / Compute Resources / Clusterをクリックします。 ◼ OpenShiftモニタリング用に作成されている全てのダッシュボードは[Default]フォルダ内にあります。 【演習】Grafana
UIにアクセスしよう 30 © 2021 IBM Corporation
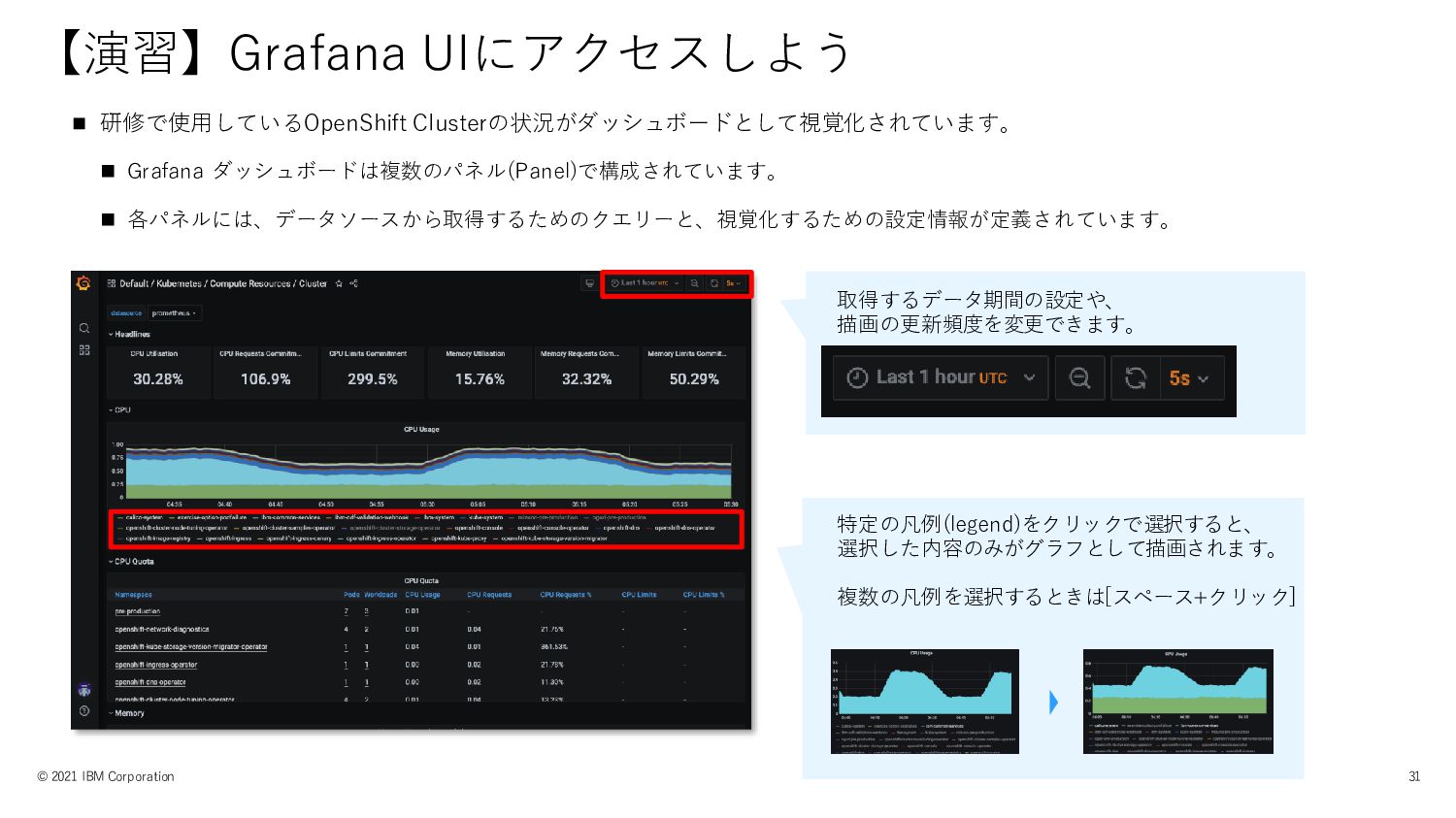
◼ 研修で使用しているOpenShift Clusterの状況がダッシュボードとして視覚化されています。 ◼ Grafana ダッシュボードは複数のパネル(Panel)で構成されています。 ◼ 各パネルには、データソースから取得するためのクエリーと、視覚化するための設定情報が定義されています。 【演習】Grafana UIにアクセスしよう
© 2021 IBM Corporation 31 取得するデータ期間の設定や、 描画の更新頻度を変更できます。 特定の凡例(legend)をクリックで選択すると、 選択した内容のみがグラフとして描画されます。 複数の凡例を選択するときは[スペース+クリック]
◼ Openshift上で現在発生しているアラートの有無を確認します。 ◼ コンソールを表示し、管理者画面で左部メニューから[モニタリング]を展開し [アラート]をクリックします。 ◼ タブメニューから[アラート]をクリックします。アラートが存在する場合は、アラート名称をクリックして詳細情報を確認できます。 1. アラートルールをクリックし、定義されている内容を確認します 【演習】アラートの確認
32 1. アラート : Openshift内で発生しているアラート 状況を確認できます。 2. サイレンス : ミュートになっているアラートの確認、 変更ができます。 3. アラートルール : 定義されているアラートの条件を確認できます。 アラート画面のタブメニュー3種 アラートが存在する場合は、名称をクリックして詳細を確認 © 2021 IBM Corporation
◼ 定義されているアラートルールの内容を確認します(重要なアラートは最初からルールが定義されています)。 ◼ アラート画面内のタブメニューから[アラートルール]をクリックします。 ◼ 名前 検索ボックスに「notready」と入力し、NodeやPodの起動状況に関するアラート一覧を確認します。 【演習】アラートのルール確認 33 多くのアラートルールが最初から定義されています。
詳細情報ではアラートの発火条件、アラートの内容、名称、 重要度といった情報が確認できます。 定義されているアラートルールの詳細 例) KubeNodeNotReady - Nodeが15分以上Ready状態にないときに実行 される © 2021 IBM Corporation
◼ メトリクス画面では、Prometheus のクエリー言語(PromQL) クエリーを実行し、メトリクスを可視化して検査できます。 ◼ コンソールを表示し、管理者画面で左部メニューから[モニタリング]を展開し [メトリクス]をクリックします。 【演習】メトリクスの確認 34 ①
② ③ ① カーソルでメトリクスを挿入する: - 利用可能なメトリクスの一覧 ②クエリーの追加 - クエリー入力ボックスを追加 - promQLは複数実行可能 ③ クエリーの実行 - 入力されているクエリーを実行 © 2021 IBM Corporation
【演習】メトリクスの確認 © 2021 IBM Corporation 35 ◼ [サンプルクエリーの挿入]をクリックします。 ◼ サンプルクエリーが挿入され、メトリクスグラフが描画されます。
sort_desc(sum(sum_over_time(ALERTS{alertstate =“firing”}[24h]))by(alertname)) サンプルクエリーの内容 24時間以内に“発火した“アラートの発生時間累計を アラート別に降順で表示
オプション演習 1. ヘルスチェックの設定 © 2021 IBM Corporation 36
【オプション演習】ヘルスチェックの設定 © 2021 IBM Corporation 37 ◼ 演習の説明 – デプロイメントに対してヘルスチェックの設定を追加する操作の演習です。
– 今回の環境では障害を起こせませんので、設定後の動作を検証する事はできません。 単純に設定を追加する操作を体験してもらいます。 – 演習の最後で、必ず設定したヘルスチェックを削除する様にしてください。
ヘルスチェックの設定 © 2021 IBM Corporation 38 ◼ 管理画面の[トポロジー]を選択して、自分のプロジェクトを表示します。 ◼ [worklog-ui]を選択して、右側の[アクション]から[ヘルスチェックの追加]を選択します。
ヘルスチェックの設定 © 2021 IBM Corporation 39 ◼ 「ヘルスチェックの追加」画面から [Liveness プローブの追加]をクリックします。
◼ ヘルスチェックの設定値が出ますがデフォルト のまま、タイムアウトの下の[✓]をクリックし ます。 – これは、worklog-uiに対してトップページ(/)にアクセス して正常応答かチェックしています。 – 本来はアプリ内にチェックできる機能を設けて、そのパス を設定します。
ヘルスチェックの設定 © 2021 IBM Corporation 40 ◼ 「Leviness プローブの追加」が緑色になっているを確認して、[追加]ボタンを押します。 ◼
これでヘルスチェックが設定され、実行されます。
ヘルスチェックの削除 © 2021 IBM Corporation 41 ◼ トポロジーから[worklog-ui]を選択し、[アクション]から[ヘルスチェックの編集]を選択します。 ◼ 「Livenessプローブの追加」の右側の[-](削除)をクリックします。
◼ 「Livenessプローブの追加」が青字になったのを確認して[保存]ボタンを押します。 最後に必ず削除を 実施してください!
オプション演習 2. HPAによるPodの自動スケーリング IBM Garage / © 2021 IBM Corporation
42 注意事項: この演習は構成に変更を加えるので、 必ず最後に実施してください。 HPAの説明は、3-1. スケーリングを 参照してください。
HPAによるPodの自動スケーリング © 2021 IBM Corporation 43 ◼ [Developer]パースペクティブでトポロジーを選択。[worklog-ui]のクリックしてデプロイメントを 表示します。
HPAによるPodの自動スケーリング © 2021 IBM Corporation 44 ◼ [YAML]を選択します。 – 注:画面例の様に文字が色分けされるまで
編集できません。少し時間がかかります。 ◼ 「spec:」の下の「resources:」を見つけて、 下記の様に編集します。 ◼ 保存を実行後、リロードを要求される ので、リロードを行います。 resources: {} resources: limits: cpu: 30m memory: 100Mi requests: cpu: 3m memory: 40Mi *YAMLコード内で、Ctrl+Fを押すと検索入力がでるので、そこから 検索すると見つけやすいです。 注: ‘f:resources’: {} の項目 では無いので注意
HPAによるPodの自動スケーリング © 2021 IBM Corporation 45 ◼ トポロジー画面に戻り、worklog-uiのアクションから[HorizontalPodAutoscalerの追加]を選択します。
HPAによるPodの自動スケーリング © 2021 IBM Corporation 46 ◼ HPAの設定画面から「CPU Utilization」に 3
を指定します。 ◼ 保存を押します。
HPAによるPodの自動スケーリング © 2021 IBM Corporation 47 ◼ トポロジー画面に戻りworklog-uiのPod数表示を確認します。 – 自動スケーリングと表示されHPAが有効な事が分かります。
◼ アプリを実行して、自動スケーリングが変化する事を確認します。 – マシンの使用状況によっては変化しない場合もあります。 ◼ HPAを削除します。 – アクションから [HorizontalPodAutoscalerの削除]を選択 – 削除確認画面が出るので、[削除]を選択 – Pod数表示から自動スケーリングが 消えるのを確認 最後に必ずHPA の削除を実施し てください!
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![【演習】Pod数の変更 © 2021 IBM Corporation 8 ◼ Developerパースペクティブでトポロジーを表示し、自分のプロジェクトを設定します。 ◼ Pod数を変更するDeployment(ここでは[worklog-ui])を選択して、詳細画面で[Details]を選択します。](https://files.speakerdeck.com/presentations/bc7cdf4aa91d4552a8f62fc62f49f1e9/slide_7.jpg){kind=link}
{kind=link}
![【演習】Pod数の変更 © 2021 IBM Corporation 10 ◼ 画面右側の[worklog-ui]をクリックして、デプロイメント画面を表示します。 ◼ [YAML]を選択して、「replicas」の設定が2になっていることを確認します。](https://files.speakerdeck.com/presentations/bc7cdf4aa91d4552a8f62fc62f49f1e9/slide_9.jpg){kind=link}
![【演習】Pod数の変更 © 2021 IBM Corporation 11 ◼ Podを選択し[列の管理]アイコンを選択します。 ◼ 「列の管理」で、どれでも良いので左側の1つのチェックを外します。(画面はメモリー)](https://files.speakerdeck.com/presentations/bc7cdf4aa91d4552a8f62fc62f49f1e9/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![障害の自動復旧(セルフヒーリング) © 2021 IBM Corporation 15 ◼ 管理者パースペクティブで、[ワークロード]の[Pod]を選択します。プロジェクトは[pre-production]を 指定します。 ◼](https://files.speakerdeck.com/presentations/bc7cdf4aa91d4552a8f62fc62f49f1e9/slide_14.jpg){kind=link}
![障害の自動復旧(セルフヒーリング) © 2021 IBM Corporation 16 ◼ 「Podを削除しますか?」と言う確認ダイアログがでるので、[削除]を選択します。 – この操作によりPodを強制的に停止させ、設定されている以下のPod数(この場合は0)にします。](https://files.speakerdeck.com/presentations/bc7cdf4aa91d4552a8f62fc62f49f1e9/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![【演習】Podのログの確認 © 2021 IBM Corporation 22 ◼ トポロジー画面からworklog-apiの[View logs]をクリックします。 –](https://files.speakerdeck.com/presentations/bc7cdf4aa91d4552a8f62fc62f49f1e9/slide_21.jpg){kind=link}
![◼ コンソールを表示し、管理者画面で左部メニューから[モニタリング]を展開し [ダッシュボード]をクリックします。 【演習】検証環境のリソースを確認しよう © 2021 IBM Corporation 23](https://files.speakerdeck.com/presentations/bc7cdf4aa91d4552a8f62fc62f49f1e9/slide_22.jpg){kind=link}
![◼ Namespace毎のPodのリソース使用状況を確認していきます。 ◼ [ダッシュボード]プルダウンメニューを展開し、 [Kubernetes / Compute Resources / Namespace](https://files.speakerdeck.com/presentations/bc7cdf4aa91d4552a8f62fc62f49f1e9/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
![◼ コンソールを表示し、管理者画面で左部メニューから[ネットワーク]を展開し [ルート]をクリックします。 ◼ 検索ボックスにgrafanaと入力すると、grafanaという名前のルートがヒットするので、場所列のURLをクリックします。 ◼ [Log in with OpenShift]をクリックします。](https://files.speakerdeck.com/presentations/bc7cdf4aa91d4552a8f62fc62f49f1e9/slide_26.jpg){kind=link}
![【演習】Grafana UIにアクセスしよう © 2021 IBM Corporation 28 ◼ コンソールを表示し、管理者画面で左部メニューから[モニタリング]を展開し [ダッシュボード]をクリックします。](https://files.speakerdeck.com/presentations/bc7cdf4aa91d4552a8f62fc62f49f1e9/slide_27.jpg){kind=link}
![【演習】Grafana UIにアクセスしよう 29 ◼ ログイン後に遷移するGrafanaのHome画面で、画面左のメニューバーにある[虫眼鏡アイコン]をクリックします。 注 ) Read-Onlyモードのため、メニューバーには一部のアイコンしか表示されていません。 直近のダッシュボード履歴 直近のGrafana公式ブログ記事](https://files.speakerdeck.com/presentations/bc7cdf4aa91d4552a8f62fc62f49f1e9/slide_28.jpg){kind=link}
![◼ テキストボックスに[Cluster]と入力し、Kubernetes / Compute Resources / Clusterをクリックします。 ◼ OpenShiftモニタリング用に作成されている全てのダッシュボードは[Default]フォルダ内にあります。 【演習】Grafana](https://files.speakerdeck.com/presentations/bc7cdf4aa91d4552a8f62fc62f49f1e9/slide_29.jpg){kind=link}
{kind=link}
![◼ Openshift上で現在発生しているアラートの有無を確認します。 ◼ コンソールを表示し、管理者画面で左部メニューから[モニタリング]を展開し [アラート]をクリックします。 ◼ タブメニューから[アラート]をクリックします。アラートが存在する場合は、アラート名称をクリックして詳細情報を確認できます。 1. アラートルールをクリックし、定義されている内容を確認します 【演習】アラートの確認](https://files.speakerdeck.com/presentations/bc7cdf4aa91d4552a8f62fc62f49f1e9/slide_31.jpg){kind=link}
![◼ 定義されているアラートルールの内容を確認します(重要なアラートは最初からルールが定義されています)。 ◼ アラート画面内のタブメニューから[アラートルール]をクリックします。 ◼ 名前 検索ボックスに「notready」と入力し、NodeやPodの起動状況に関するアラート一覧を確認します。 【演習】アラートのルール確認 33 多くのアラートルールが最初から定義されています。](https://files.speakerdeck.com/presentations/bc7cdf4aa91d4552a8f62fc62f49f1e9/slide_32.jpg){kind=link}
![◼ メトリクス画面では、Prometheus のクエリー言語(PromQL) クエリーを実行し、メトリクスを可視化して検査できます。 ◼ コンソールを表示し、管理者画面で左部メニューから[モニタリング]を展開し [メトリクス]をクリックします。 【演習】メトリクスの確認 34 ①](https://files.speakerdeck.com/presentations/bc7cdf4aa91d4552a8f62fc62f49f1e9/slide_33.jpg){kind=link}
![【演習】メトリクスの確認 © 2021 IBM Corporation 35 ◼ [サンプルクエリーの挿入]をクリックします。 ◼ サンプルクエリーが挿入され、メトリクスグラフが描画されます。](https://files.speakerdeck.com/presentations/bc7cdf4aa91d4552a8f62fc62f49f1e9/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
![ヘルスチェックの設定 © 2021 IBM Corporation 38 ◼ 管理画面の[トポロジー]を選択して、自分のプロジェクトを表示します。 ◼ [worklog-ui]を選択して、右側の[アクション]から[ヘルスチェックの追加]を選択します。](https://files.speakerdeck.com/presentations/bc7cdf4aa91d4552a8f62fc62f49f1e9/slide_37.jpg){kind=link}
![ヘルスチェックの設定 © 2021 IBM Corporation 39 ◼ 「ヘルスチェックの追加」画面から [Liveness プローブの追加]をクリックします。](https://files.speakerdeck.com/presentations/bc7cdf4aa91d4552a8f62fc62f49f1e9/slide_38.jpg){kind=link}
![ヘルスチェックの設定 © 2021 IBM Corporation 40 ◼ 「Leviness プローブの追加」が緑色になっているを確認して、[追加]ボタンを押します。 ◼](https://files.speakerdeck.com/presentations/bc7cdf4aa91d4552a8f62fc62f49f1e9/slide_39.jpg){kind=link}
![ヘルスチェックの削除 © 2021 IBM Corporation 41 ◼ トポロジーから[worklog-ui]を選択し、[アクション]から[ヘルスチェックの編集]を選択します。 ◼ 「Livenessプローブの追加」の右側の[-](削除)をクリックします。](https://files.speakerdeck.com/presentations/bc7cdf4aa91d4552a8f62fc62f49f1e9/slide_40.jpg){kind=link}
{kind=link}
![HPAによるPodの自動スケーリング © 2021 IBM Corporation 43 ◼ [Developer]パースペクティブでトポロジーを選択。[worklog-ui]のクリックしてデプロイメントを 表示します。](https://files.speakerdeck.com/presentations/bc7cdf4aa91d4552a8f62fc62f49f1e9/slide_42.jpg){kind=link}
![HPAによるPodの自動スケーリング © 2021 IBM Corporation 44 ◼ [YAML]を選択します。 – 注:画面例の様に文字が色分けされるまで](https://files.speakerdeck.com/presentations/bc7cdf4aa91d4552a8f62fc62f49f1e9/slide_43.jpg){kind=link}
![HPAによるPodの自動スケーリング © 2021 IBM Corporation 45 ◼ トポロジー画面に戻り、worklog-uiのアクションから[HorizontalPodAutoscalerの追加]を選択します。](https://files.speakerdeck.com/presentations/bc7cdf4aa91d4552a8f62fc62f49f1e9/slide_44.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}