Evaluation of IMAX4 Prototype for Server Environment Takuto Ando, Yu Eto, Yasuhiko Nakashima Nara Institute of Science and Technology (NAIST) The 26th Workshop on Synthesis And System Integration of Mixed Information technologies (SASIMI) October 9-10, 2025 R1-2 VPK180 VPK180 VPK180 VPK180 VPK180 VPK180 VPK180 VPK120 IMAX4 (Host: Intel Xeon) VS IMAX3 (Host: ARM on board)
on a 2D array Challenge: Complex routing algorithms lead to very long compilation times Conventional CGRA (Coarse-Grained Reconfigurable Array) IMAX Architecture (CGLA: Coarse-Grained Linear Array) Upgraded the host from a 2-core ARM to a 16-core Xeon with PCIe Gen5 From IMAX3's Challenge to IMAX4's Evolution Concept: PEs are arranged in a linear structure for simple, fast compilation Design: Interleaves 64 PEs with 512KB of local cache memory to minimize slow main memory access Memory ring PE ring
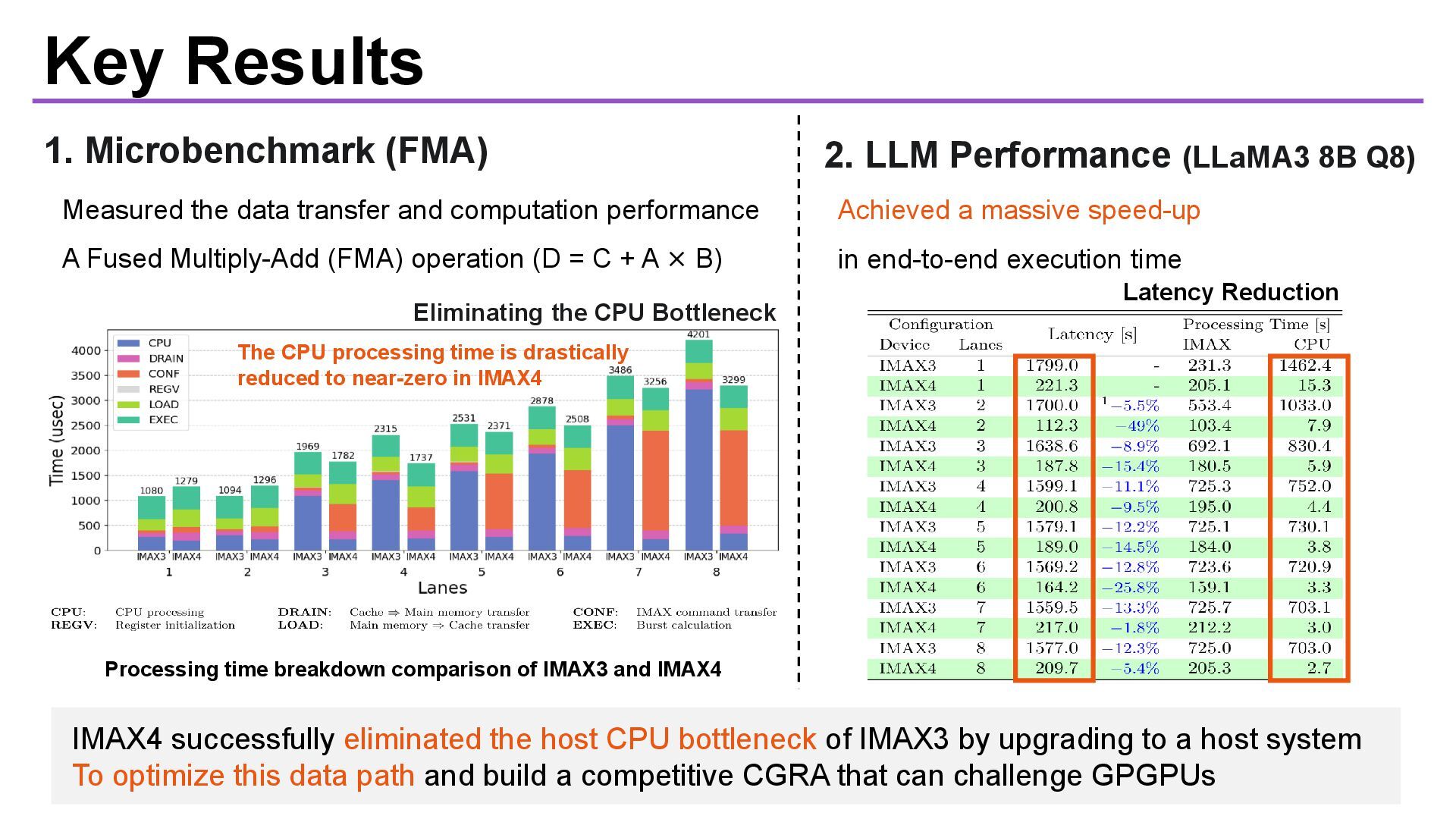
Q8) The CPU processing time is drastically reduced to near-zero in IMAX4 IMAX4 successfully eliminated the host CPU bottleneck of IMAX3 by upgrading to a host system To optimize this data path and build a competitive CGRA that can challenge GPGPUs Measured the data transfer and computation performance A Fused Multiply-Add (FMA) operation (D = C + A × B) Achieved a massive speed-up in end-to-end execution time Processing time breakdown comparison of IMAX3 and IMAX4 Eliminating the CPU Bottleneck Latency Reduction
{kind=link}
{kind=link}
{kind=link}