code. 2. You should have assembled a team to build your software. 3. If you choose the right license, more people will use and build on your software. 4. Making software free for commercial use shows you are not against companies. 5. You should maintain your software indefinitely. 6. Your “stable URL” can exist forever. 7. You should make your software “idiot proof.” 8. You used the right programming language for the task. Lior Pachter https://liorpachter.wordpress.com/2015/07/10/the-myths-of-bioinformatics-software/
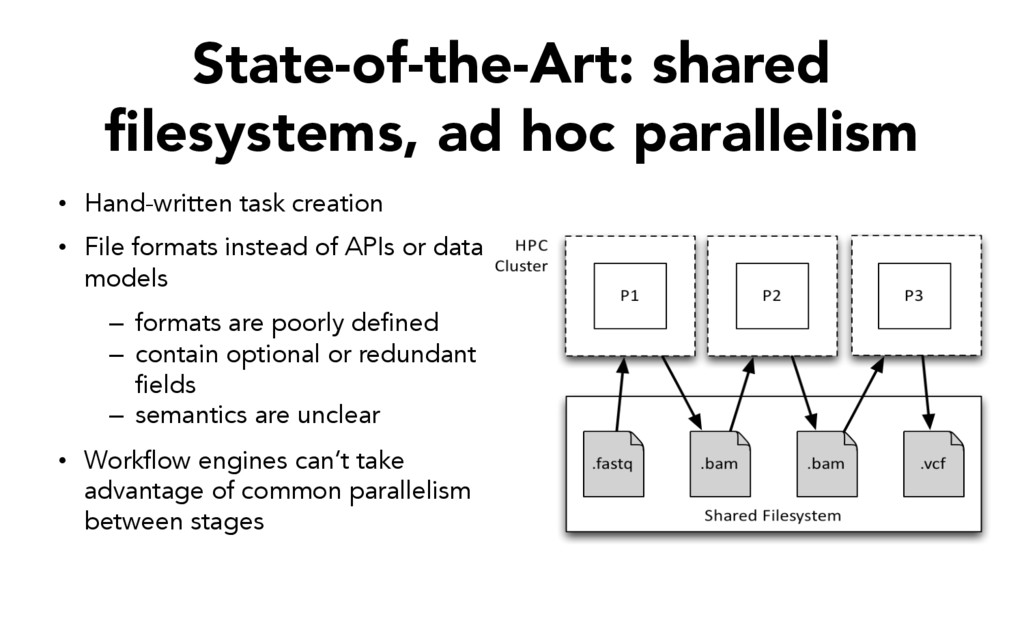
• File formats instead of APIs or data models – formats are poorly defined – contain optional or redundant fields – semantics are unclear • Workflow engines can’t take advantage of common parallelism between stages
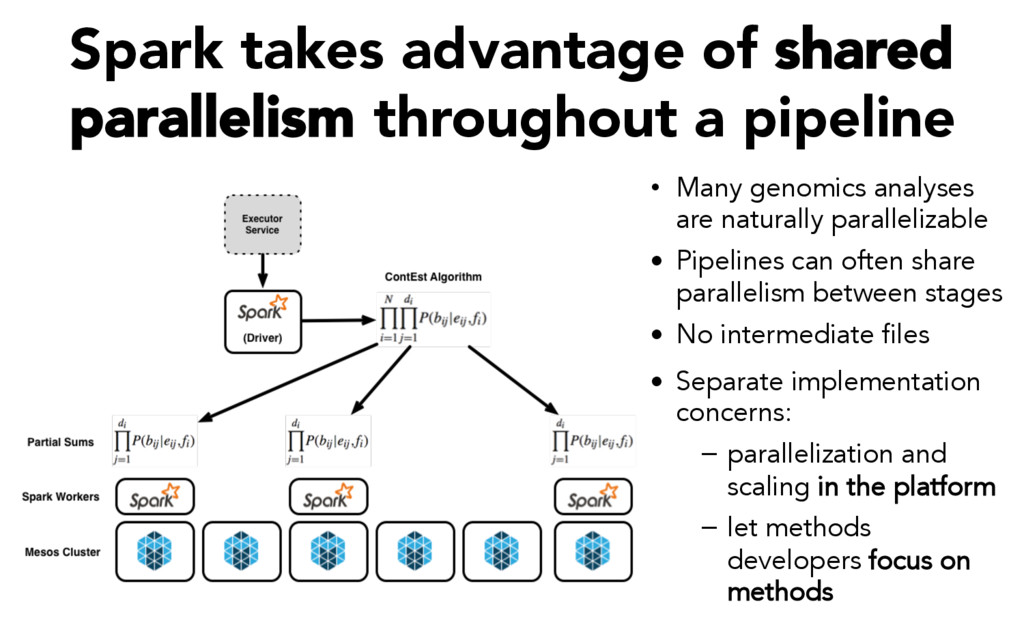
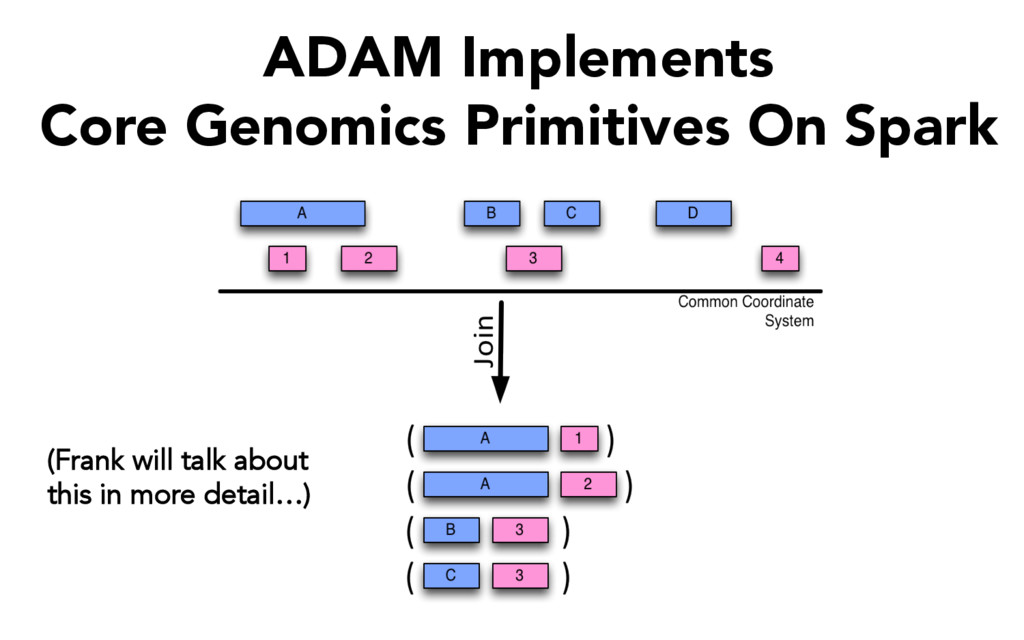
Many genomics analyses are naturally parallelizable • Pipelines can often share parallelism between stages • No intermediate files • Separate implementation concerns: – parallelization and scaling in the platform – let methods developers focus on methods
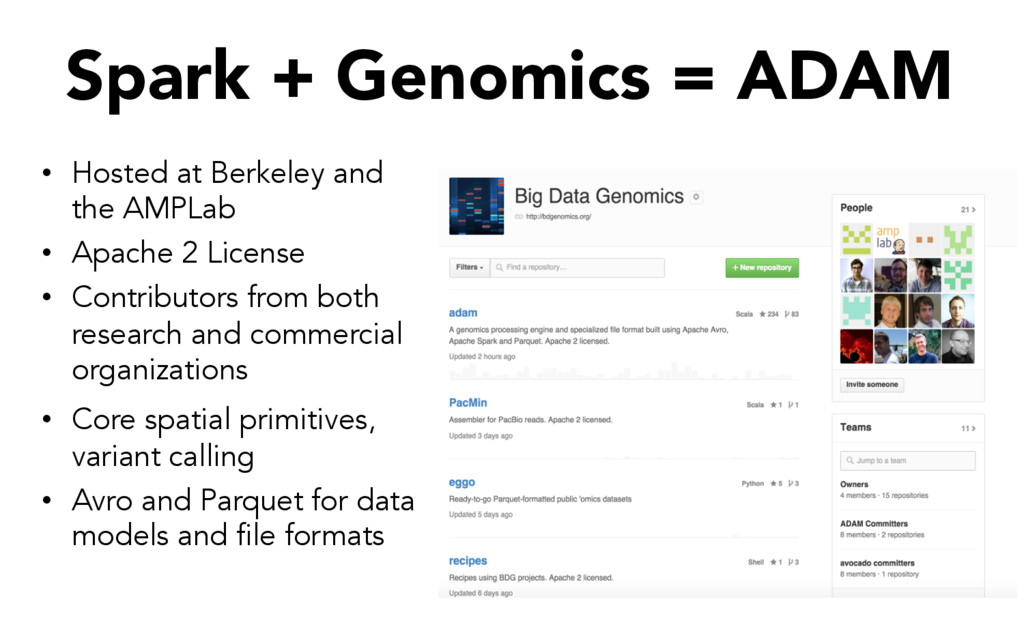
the AMPLab • Apache 2 License • Contributors from both research and commercial organizations • Core spatial primitives, variant calling • Avro and Parquet for data models and file formats
Instead of defining custom file formats for each data type and access pattern… • Parquet creates a compressed format for each Avro-defined data model. • Improvement over existing formats1 • 20-22% for BAM • ~95% for VCF 1compression % quoted from 1K Genomes samples
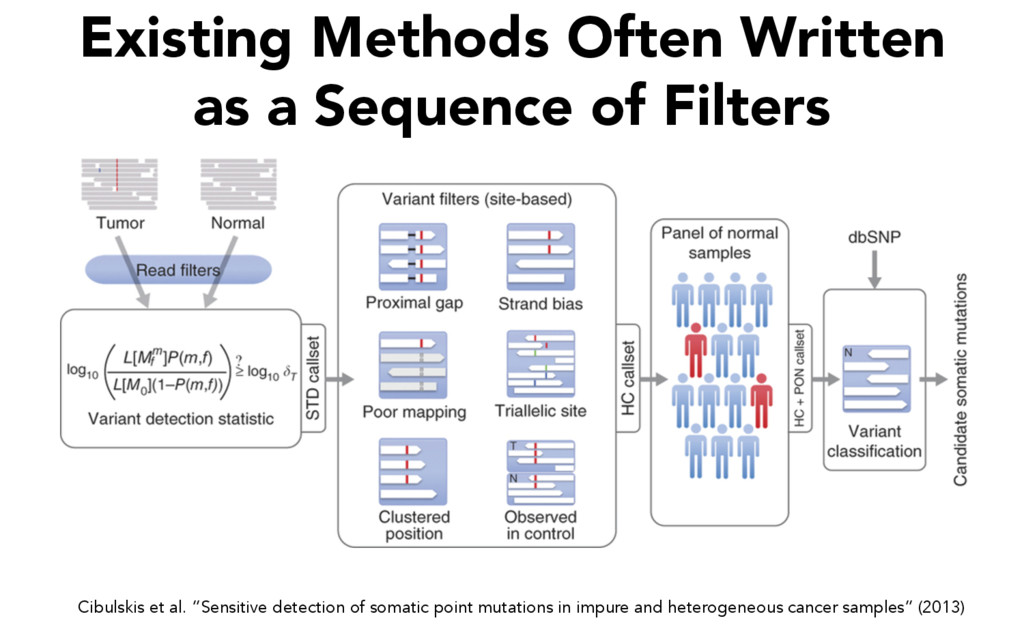
single piece of a single filtering stage for a somatic variant caller • Can you spot the embedded file- format assumption? Cibulskis et al. Nature Biotechnology 31, 213–219 (2013)
single piece of a single filtering stage for a somatic variant caller • “11-base-pair window centered on a candidate mutation” actually turns out to be optimized for a particular file format and sort order Cibulskis et al. Nature Biotechnology 31, 213–219 (2013)
a few already, it will require rewriting all our software, we should focus on methods instead. • Yes: we need to move to commodity computing, start planning for a day when sharing is not copying, write methods that scale with more resources Most importantly: separate “developing a method” from “building a platform,” and allow different developers to work separately on both
code. 2. You should have assembled a team to build your software. 3. If you choose the right license, more people will use and build on your software. 4. Making software free for commercial use shows you are not against companies. 5. You should maintain your software indefinitely. 6. Your “stable URL” can exist forever. 7. You should make your software “idiot proof.” 8. You used the right programming language for the task. Lior Pachter https://liorpachter.wordpress.com/2015/07/10/the-myths-of-bioinformatics-software/
have assembled a team to build your software. 3. If you choose the right license, more people will use and build on your software. 4. Making software free for commercial use shows you are not against companies. 5. You should maintain your software indefinitely. 6. Your “stable URL” can exist forever. 7. You should make your software “idiot proof.” 8. You used the right programming language for the task. Lior Pachter https://liorpachter.wordpress.com/2015/07/10/the-myths-of-bioinformatics-software/ “Myths of Bioinformatics Software”
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}