This details why Cassandra is a great fit for storing performance metrics. It briefly describes a suggested schema and gives advice on aggregating metrics.
This talk was presented for the Big Data Benchmarking Community (BDBC) on November 29th, 2012: http://clds.ucsd.edu/bdbc/community
![©2012 DataStax 1 Metrics and Cassandra Tyler Hobbs [email protected]](https://files.speakerdeck.com/presentations/0bad0b401cb501309fe31231380e9c7e/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
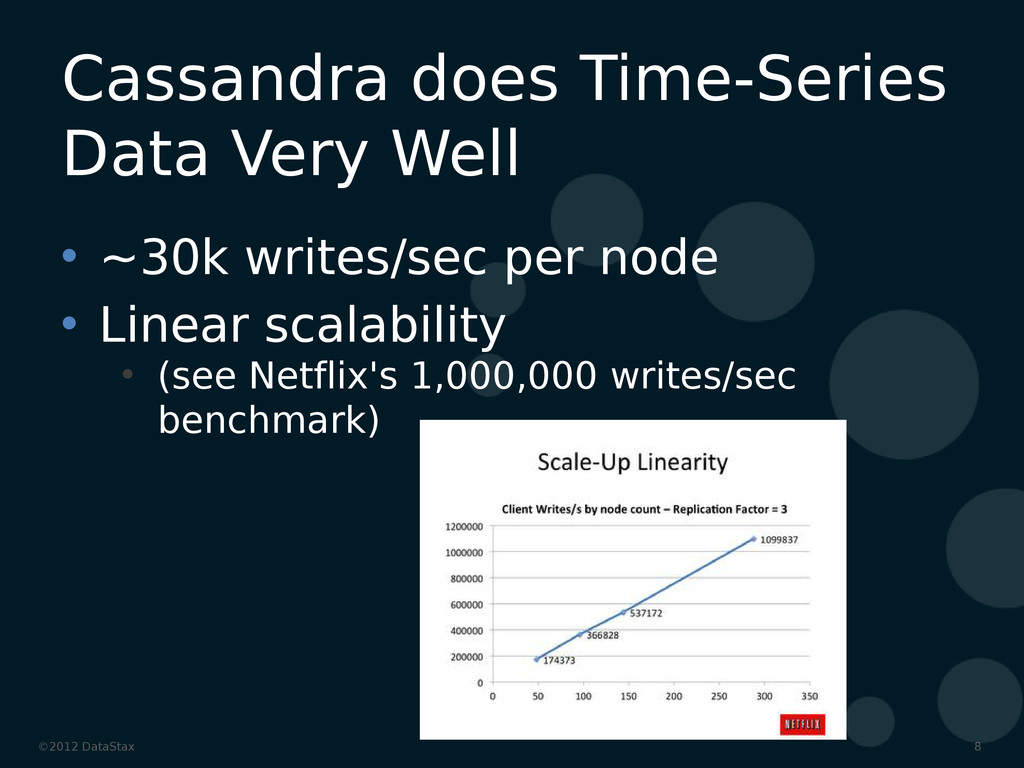{kind=link}
{kind=link}
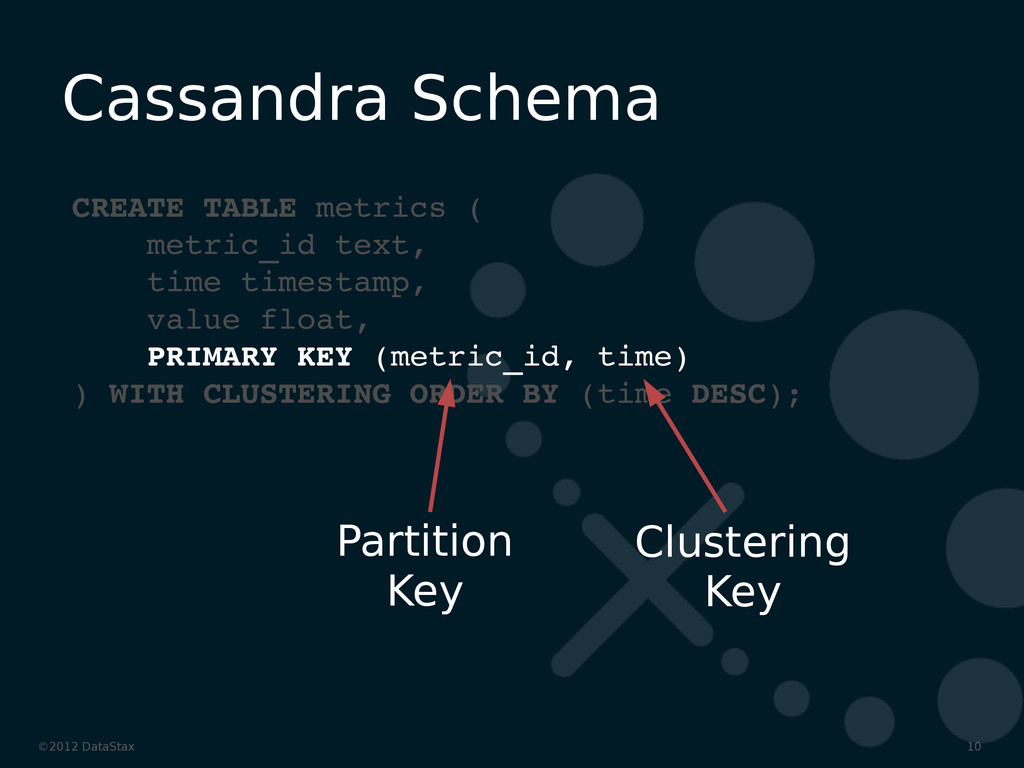{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![©2012 DataStax 19 Questions? Tyler Hobbs [email protected]](https://files.speakerdeck.com/presentations/0bad0b401cb501309fe31231380e9c7e/slide_18.jpg){kind=link}