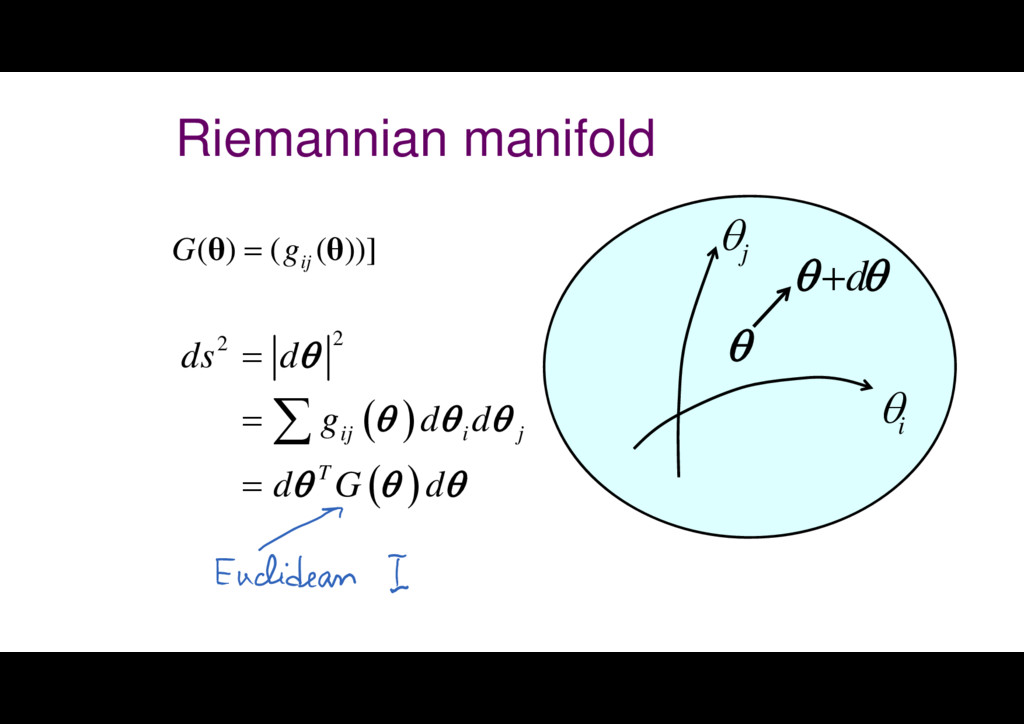
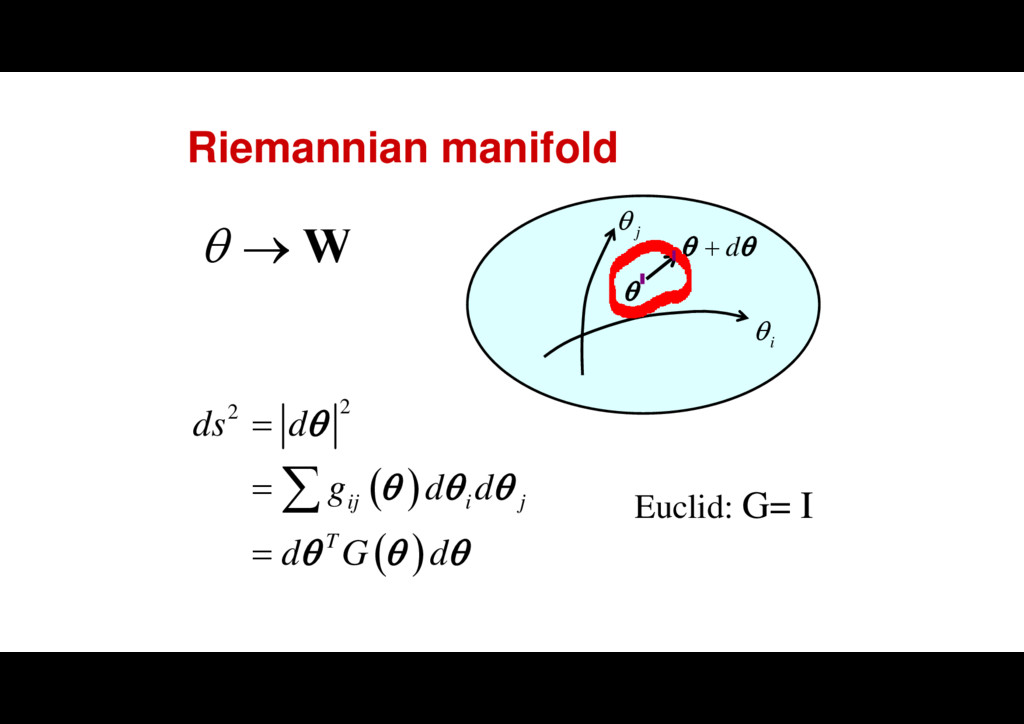
1 1 2 , , = n i j ij l l l l G l d d Gd G d d d ( ) l ( , ; ) t t t t t l x y
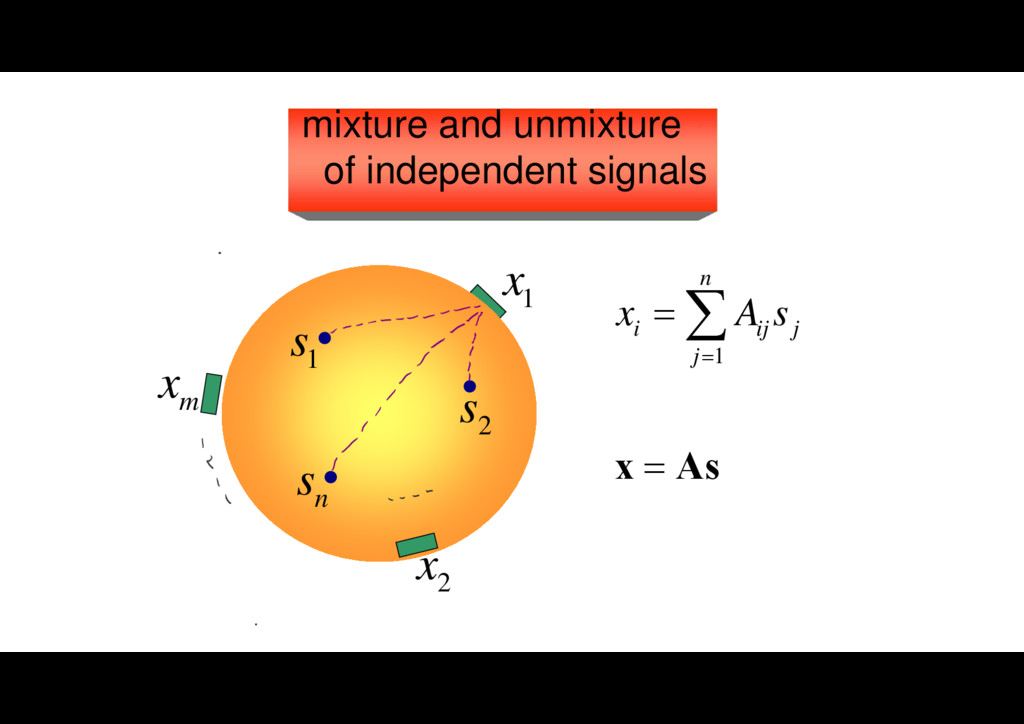
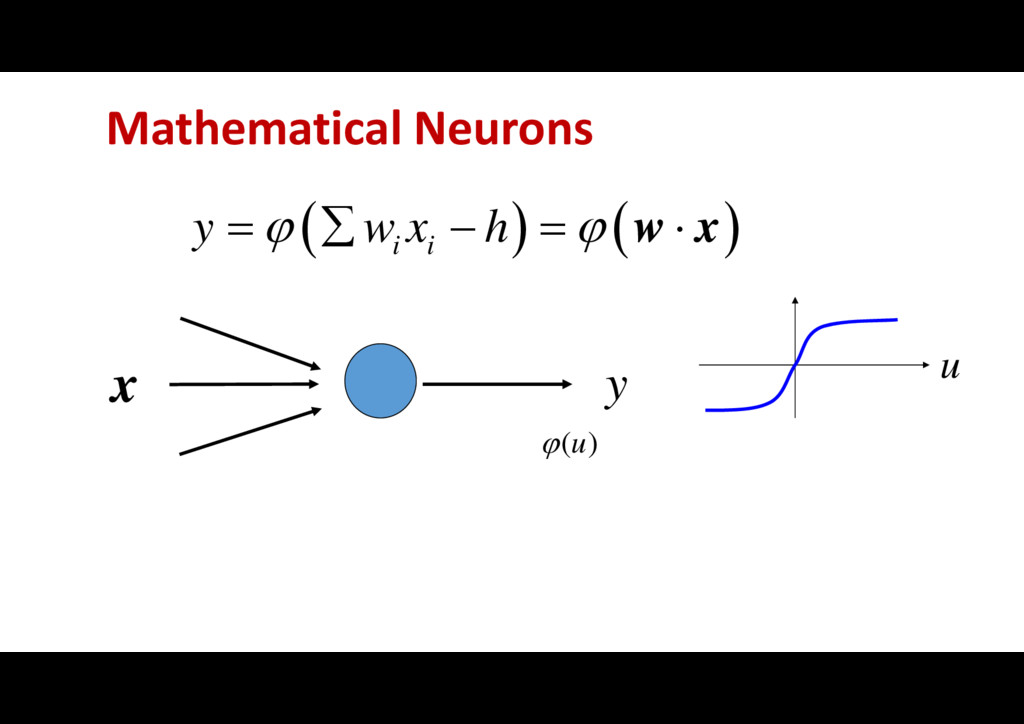
unknown (s): unknown observations: x(1), x(2), …, x(t) 1 1 2 2 independ ( ) ( ent distributi ) ( )... ( ) on [ ] 0 n n r r s r s r s E s s , l y W W W cost function: degree of non-independence r
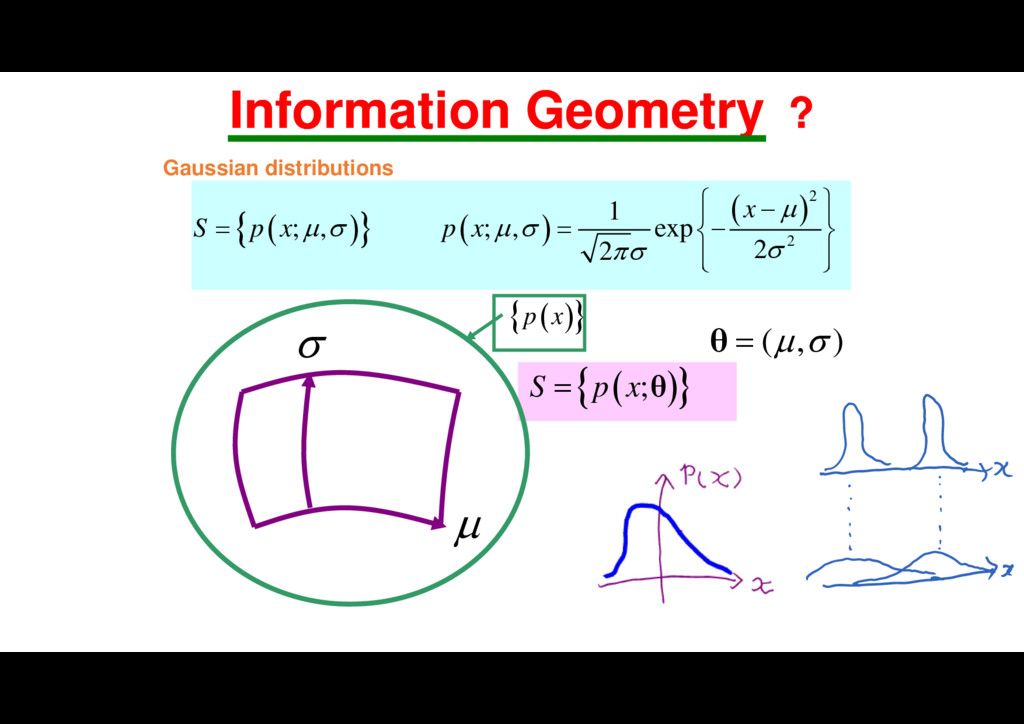
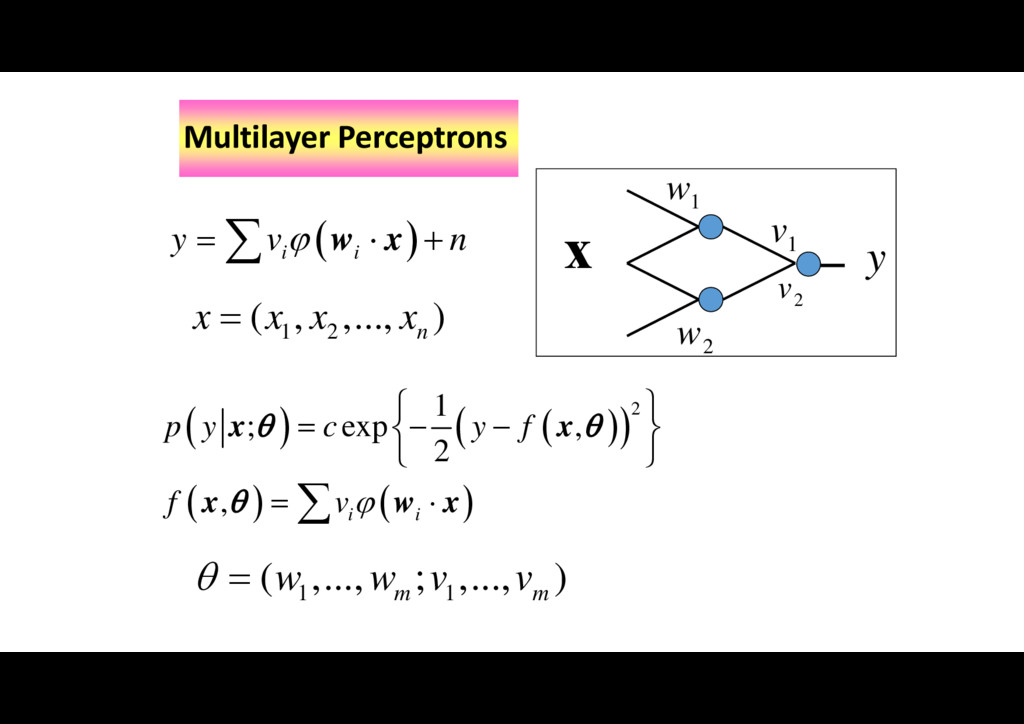
w x 2 1 ; exp , 2 , i i p y c y f f v x x x w x 1 2 ( , ,..., ) n x x x x 1 1 ( ,..., ; ,..., ) m m w w v v 1 w 2 w 1 v 2 v y x
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
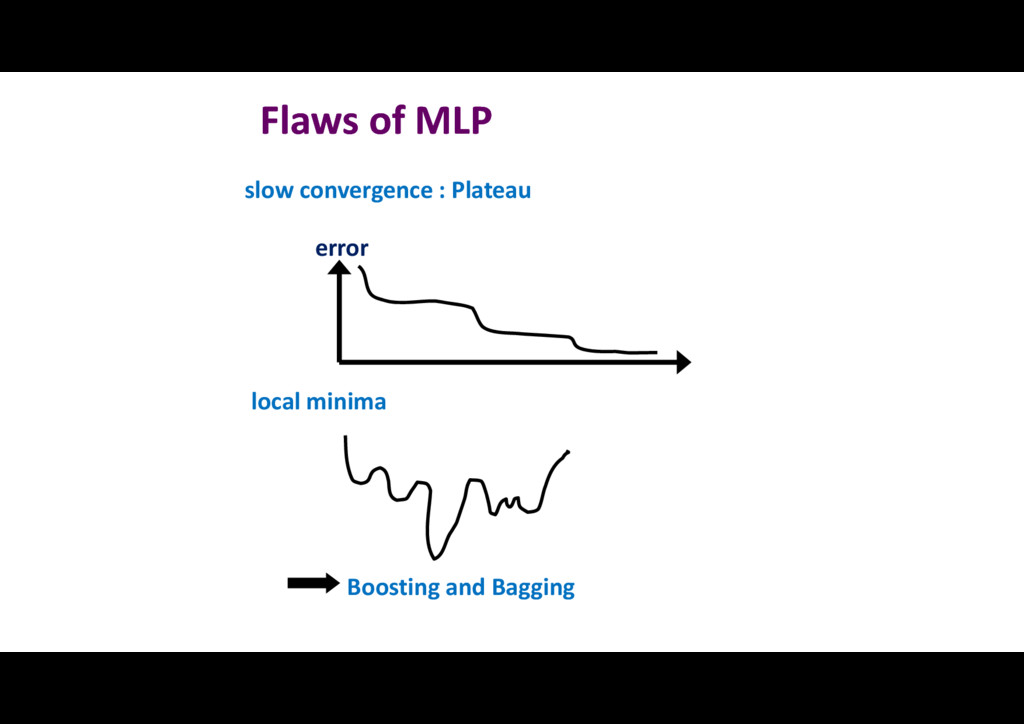{kind=link}
{kind=link}
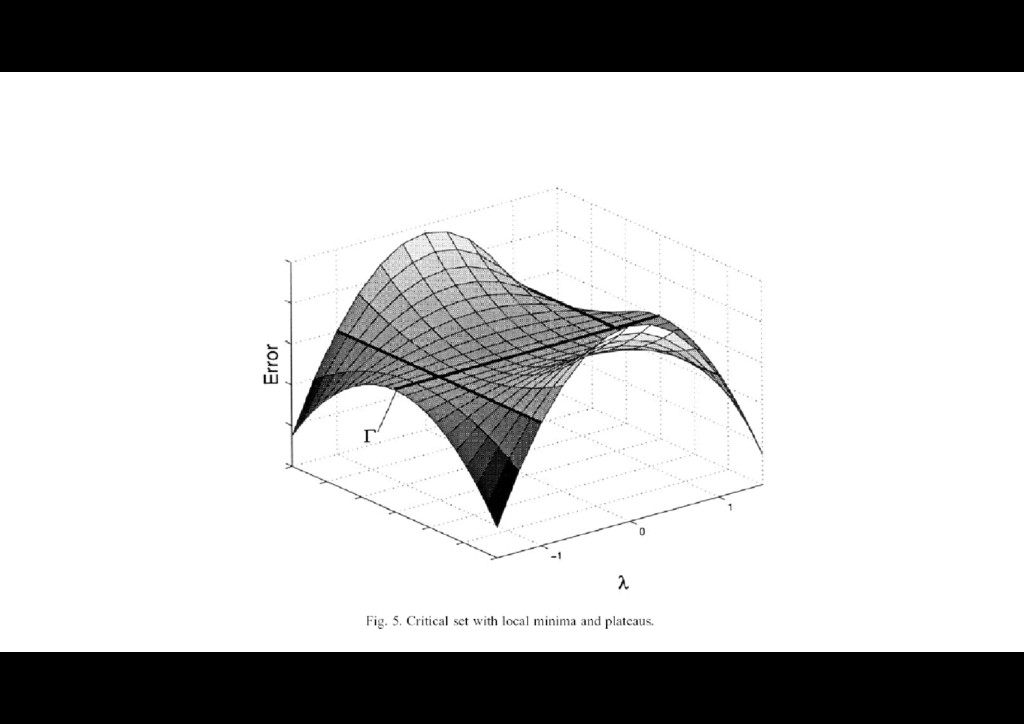{kind=link}
{kind=link}
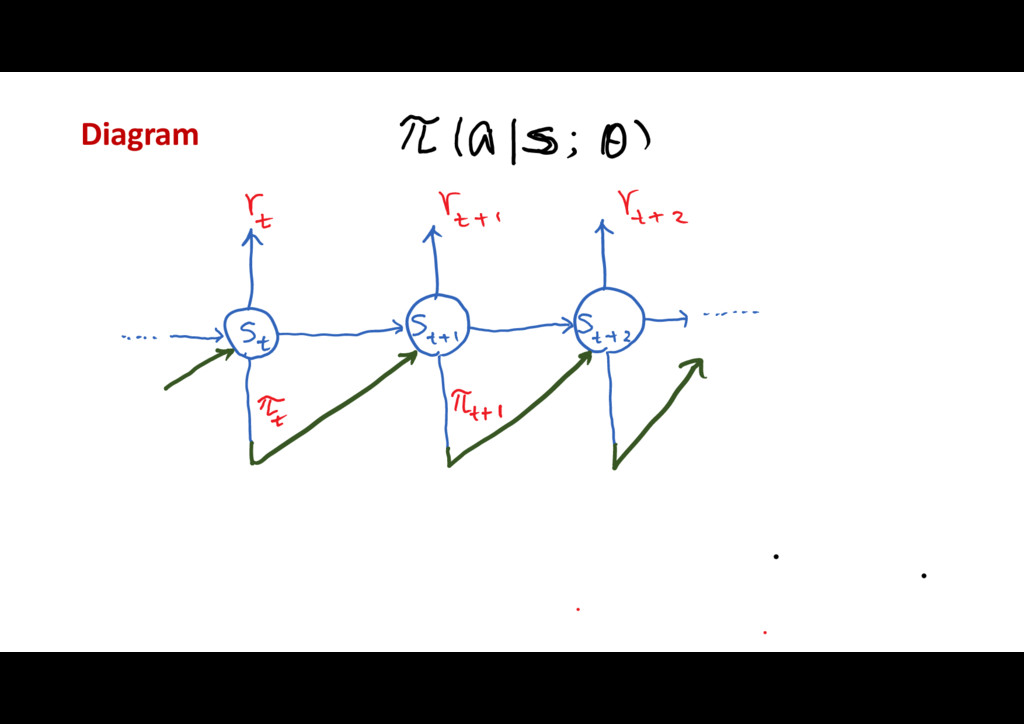{kind=link}
{kind=link}