Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
機械学習モデルの解釈手法-1-前提知識&基本手法-20250728
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
TomNJP
August 07, 2025
310
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
機械学習モデルの解釈手法-1-前提知識&基本手法-20250728
TomNJP
August 07, 2025
More Decks by TomNJP
See All by TomNJP
深層学習-1-誤差逆伝播法まで-20250616
tomnjp
0
100
因果推論-1-前提知識-20250616
tomnjp
0
130
因果推論-2-基本実装-20250630
tomnjp
0
160
Featured
See All Featured
The Cult of Friendly URLs
andyhume
79
6.9k
Visualization
eitanlees
152
17k
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
940
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
340
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.8k
The Mindset for Success: Future Career Progression
greggifford
PRO
0
360
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
160
Kristin Tynski - Automating Marketing Tasks With AI
techseoconnect
PRO
0
270
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
123
22k
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
210
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
Transcript
機械学習モデルの解釈手法-1-前 提知識&基本手法 ・ 学部2年 ・ 中島智哉
目的 実践的な機械学習モデルの解釈手法の知識を身につける。 実装スキルまでは目指さず、必要になったときに適切に利用できる知識を習得する。 今回は前提知識と基本的な手法、機械学習モデルの精度向上への応用例をまとめる。 .
参考書籍 機械学習を解釈する技術〜予測 力と説明力を両立する実践テクニッ ク 著者:森下 光之助 出版社:技術評論社
なぜ解釈性が必要か 説明責任を果たすため(求められる) トラブルを事前に回避したり、直面したときに対処しやすい モデルの精度向上にも寄与する
精度と解釈可能性のトレードオフ 予測精度と解釈性はトレードオフ 現在はまず高い精度を追求し、後から解釈可能性を確保するアプローチが主流
大枠としては線形回帰モデルと同等の解釈性を目指せば良い 特徴量の重要度 特徴量と予測値の平均的な関係 特徴量と予測値のインスタンスごとの関係 インスタンスごとの予測の理由 f(X , X
) = 1 2 X (β + 1 1 β X ) 2 2
それぞれの解釈性に対応する手法 今回はどんな機械学習モデルに対しても適用できる基本的な手法をまとめる。 PFI:特徴量の重要度 PD:特徴量と予測値の平均的な関係 ICE:特徴量と予測値のインスタンスごとの関係 SHAP:インスタンスごとの予測の理由 .
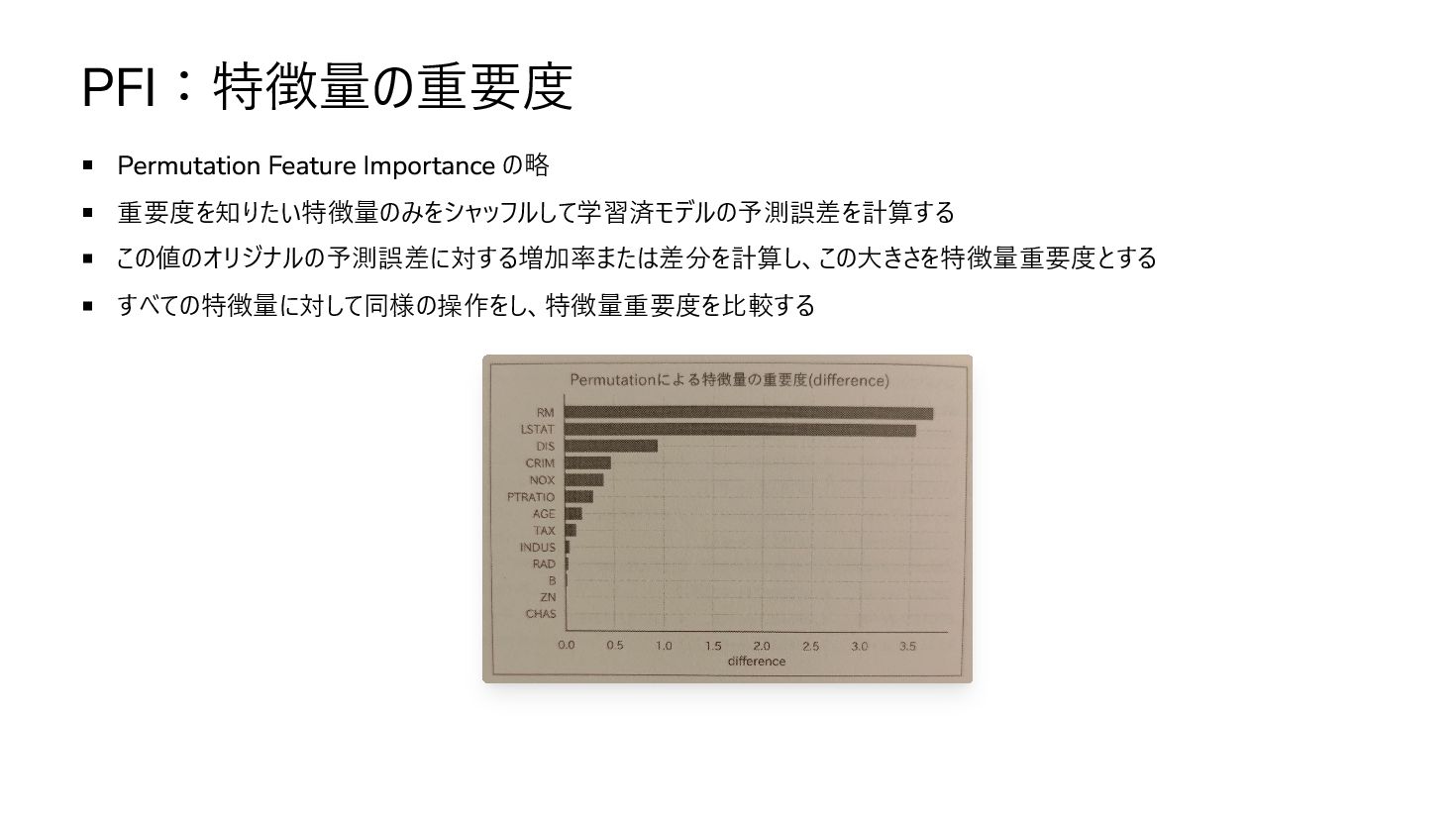
PFI:特徴量の重要度 Permutation Feature Importance の略 重要度を知りたい特徴量のみをシャッフルして学習済モデルの予測誤差を計算する この値のオリジナルの予測誤差に対する増加率または差分を計算し、この大きさを特徴量重要度とする すべての特徴量に対して同様の操作をし、特徴量重要度を比較する
GPFI(Grouped PFI) 特定の特徴量群を一纏めにして 1 つの特徴量とみなしてから PFI を適用する。 . 多重共線性を持つ場合 多重共線性を持つ特徴量それぞれに特徴量重要度が分散してしまい、実際より重要ではないという解釈をしてしまう
それらの特徴量を 1 つのグループにまとめてからその重要度を計算する . One Hot Encording を利用している場合 もともと 1 つだった特徴量を複数カラムで表しているので、まとめてから処理をしなければ適切ではない 同様に 1 つのグループにまとめてからその重要度を計算する .
注意点 多重共線性を持つ特徴量に対しては適切に GPFI を適用する必要がある 特徴量重要度は因果関係として解釈できるとは限らない
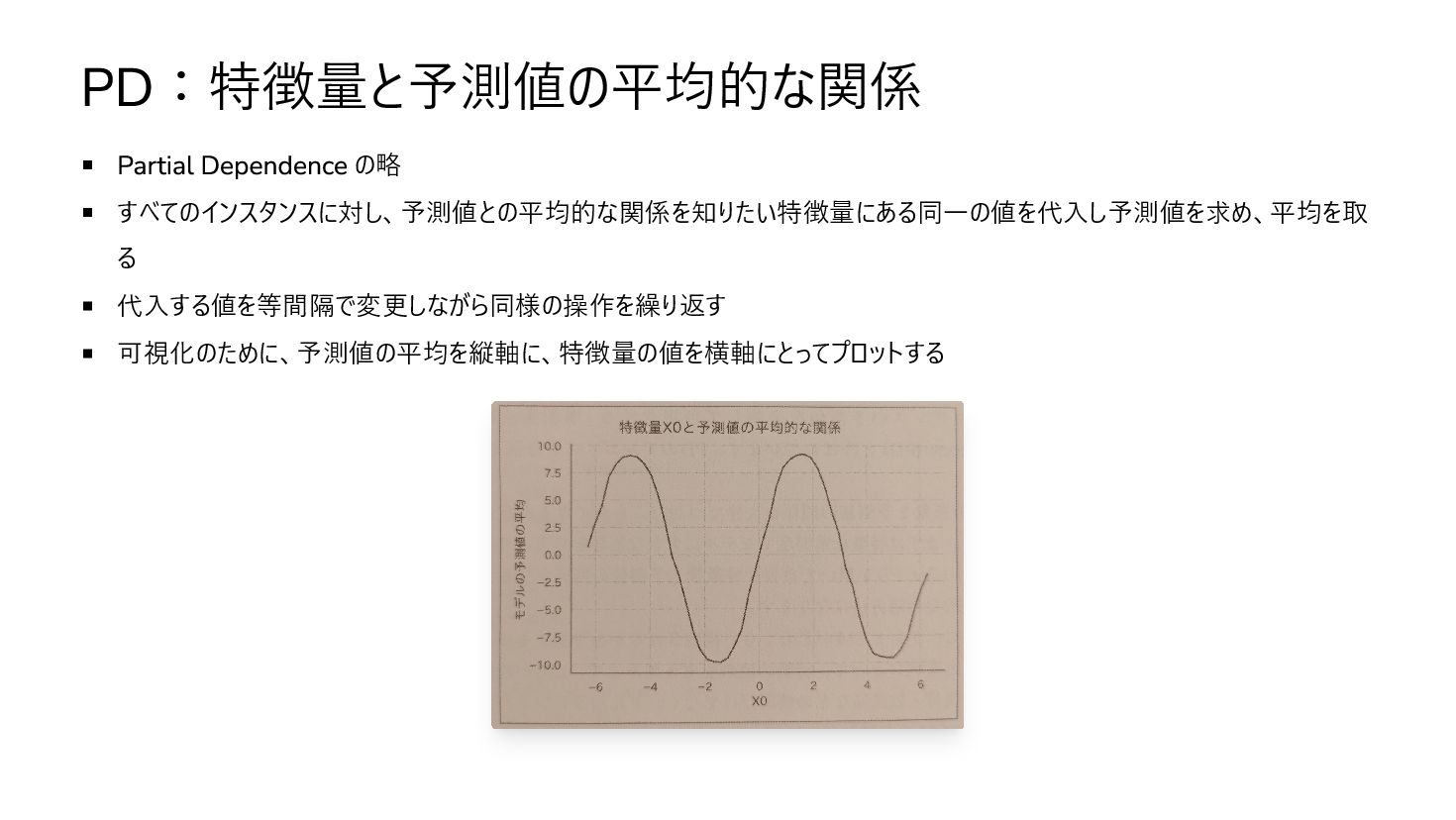
PD:特徴量と予測値の平均的な関係 Partial Dependence の略 すべてのインスタンスに対し、予測値との平均的な関係を知りたい特徴量にある同一の値を代入し予測値を求め、平均を取 る 代入する値を等間隔で変更しながら同様の操作を繰り返す 可視化のために、予測値の平均を縦軸に、特徴量の値を横軸にとってプロットする
注意点 未知の交絡因子が存在したり疑似相関している場合、またモデルがうまく学習できていない場合は因果関係を表さない あくまでも平均的な関係を表しているにすぎず、インスタンスごとで見ると振る舞いが異なる可能性がある
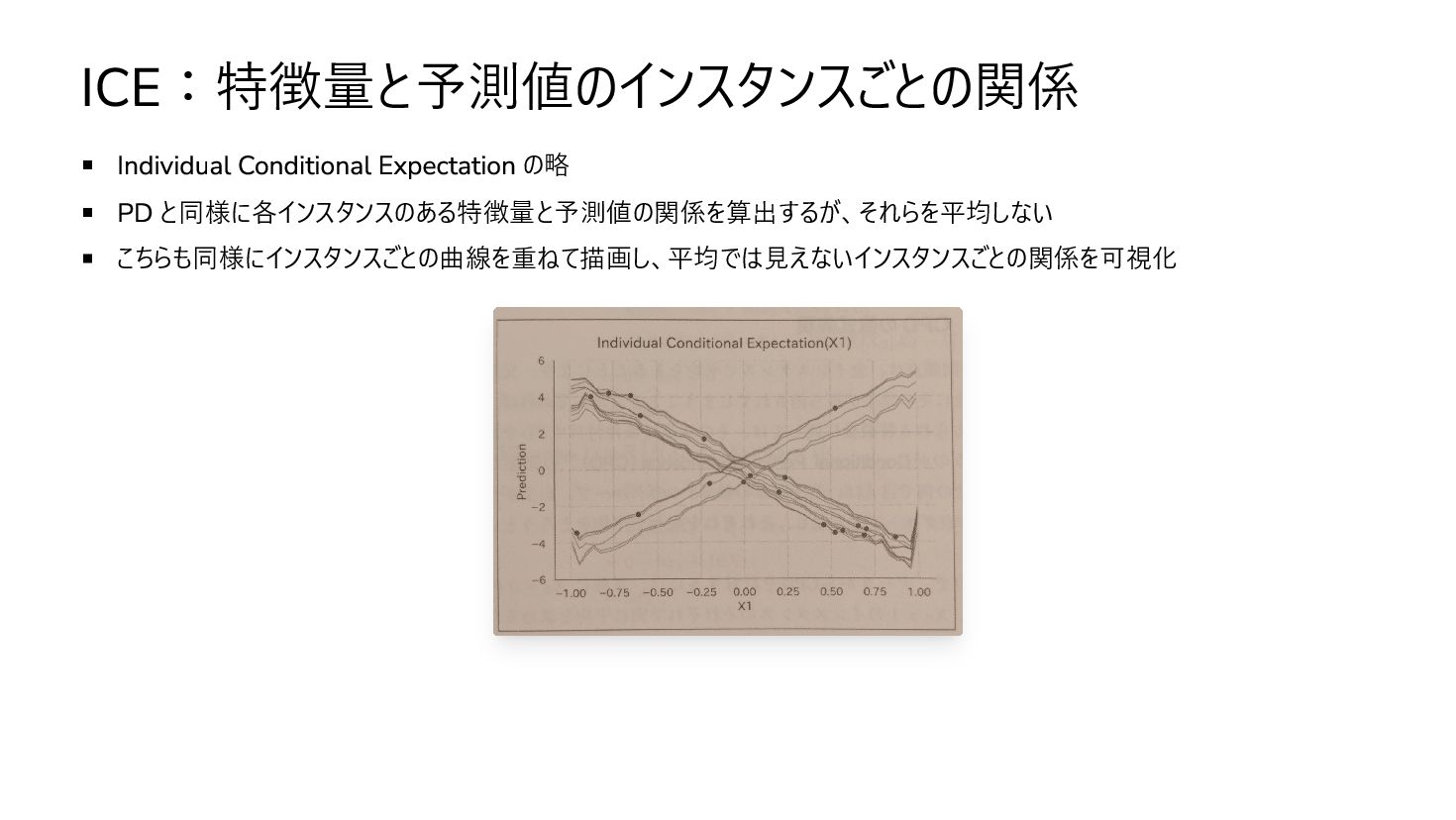
ICE:特徴量と予測値のインスタンスごとの関係 Individual Conditional Expectation の略 PD と同様に各インスタンスのある特徴量と予測値の関係を算出するが、それらを平均しない こちらも同様にインスタンスごとの曲線を重ねて描画し、平均では見えないインスタンスごとの関係を可視化
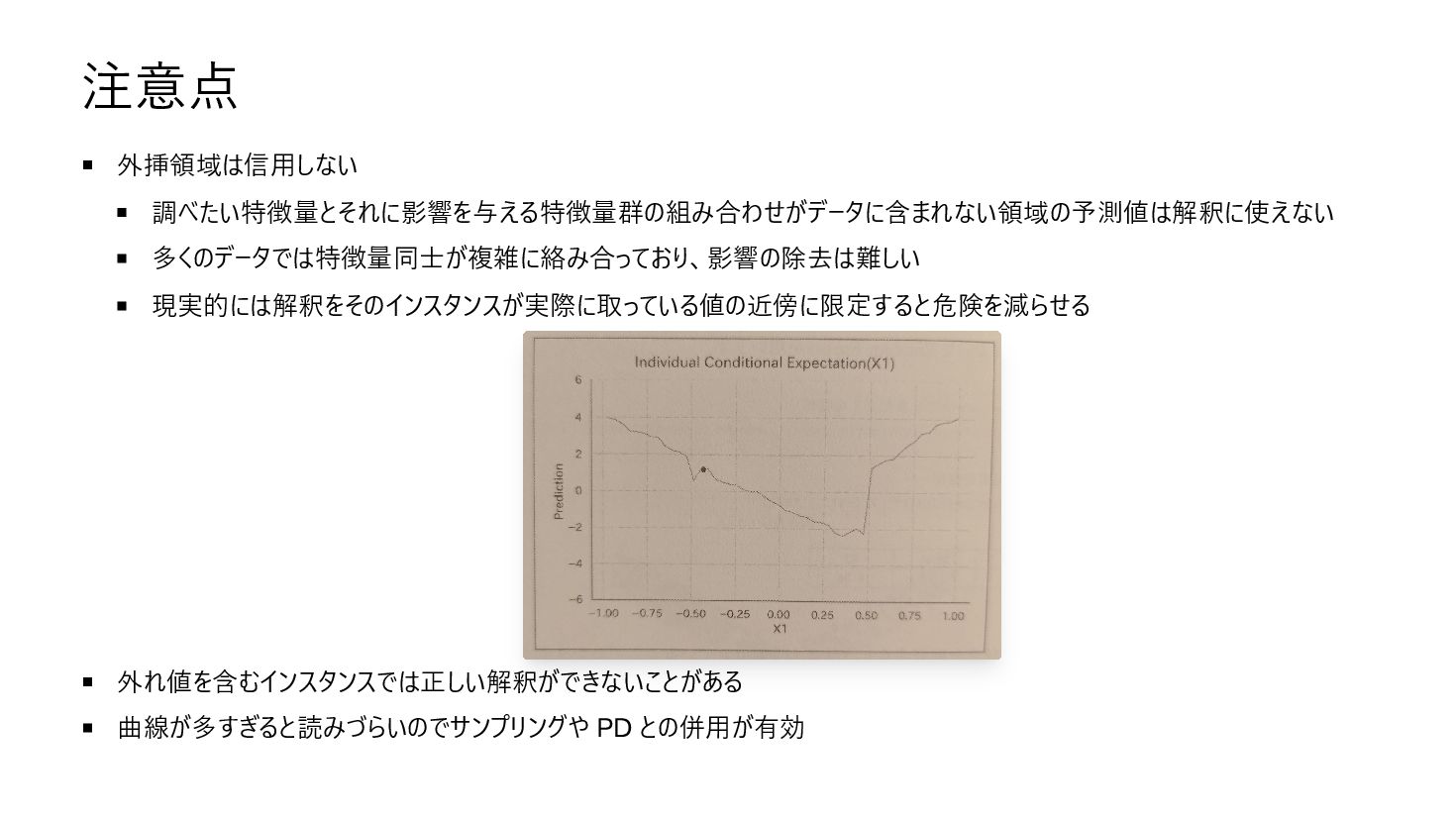
注意点 外挿領域は信用しない 調べたい特徴量とそれに影響を与える特徴量群の組み合わせがデータに含まれない領域の予測値は解釈に使えない 多くのデータでは特徴量同士が複雑に絡み合っており、影響の除去は難しい 現実的には解釈をそのインスタンスが実際に取っている値の近傍に限定すると危険を減らせる 外れ値を含むインスタンスでは正しい解釈ができないことがある 曲線が多すぎると読みづらいのでサンプリングや PD との併用が有効
SHAP:インスタンスごとの予測の理由 SHapley Additive exPlanations の略 ゲーム理論の Shapley 値を予測寄与に転用 各特徴量が「どれだけ予測を押し上げ/押し下げたか」を定量化 局所説明と大域的集約を共通ロジックで扱えるのが強み
SHAP のアルゴリズム 1. あるインスタンスに対する、すべての特徴量が利用できない場合の予測値をベースラインとする 2. ある特徴量を予測に使える特徴量として追加した際の予測値の増分を算出 3. すべての特徴量を利用するようになるまで、未利用の特徴量を対象に 2 を繰り返す
4. すべての追加順で 2~3 を繰り返す 5. それぞれの追加順における各特徴量を追加した際の予測値の増分を平均する 6. 5 の結果をプロットする なお、特定の特徴量群が使えない状況は周辺化を用いて作る
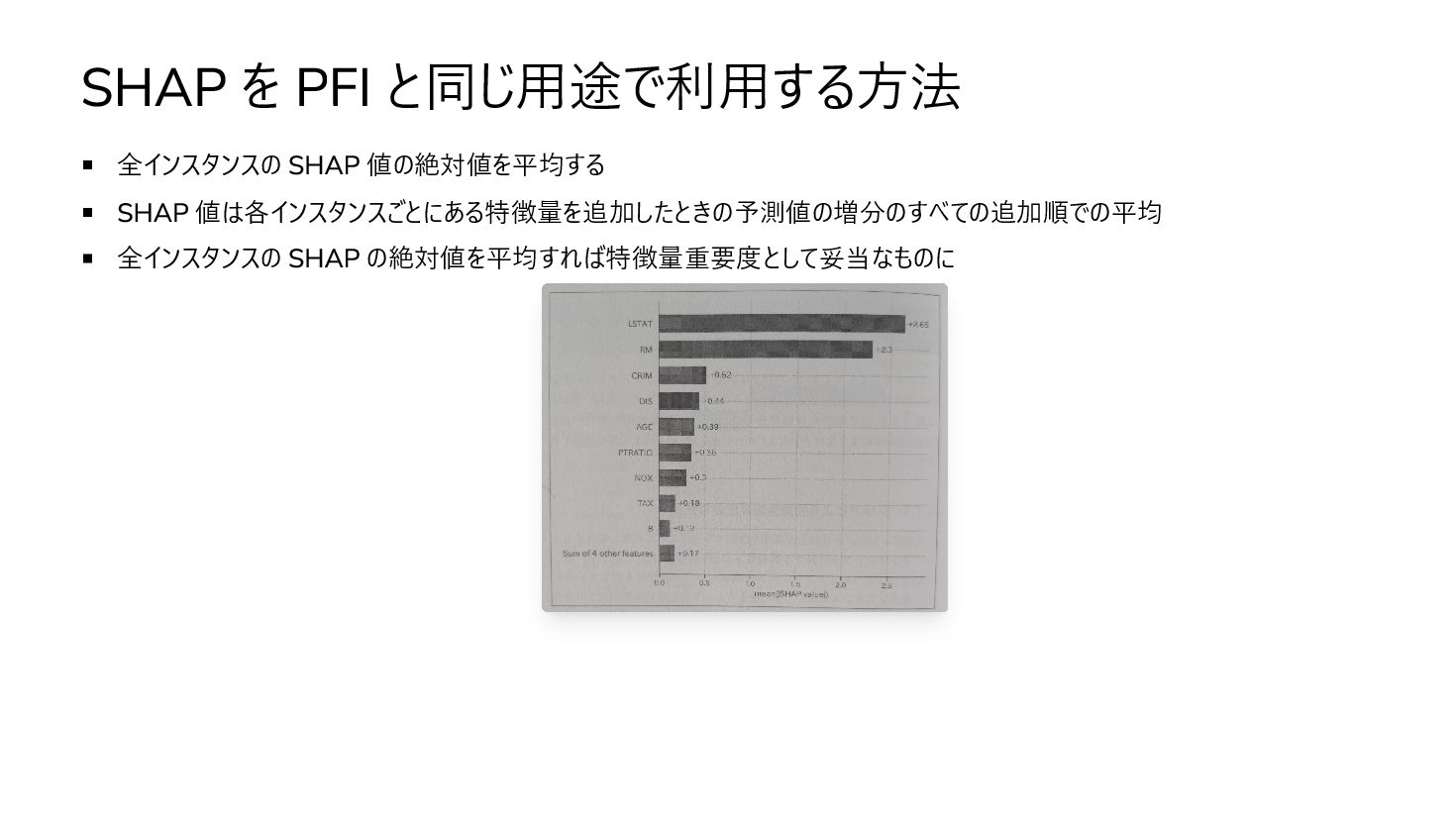
SHAP を PFI と同じ用途で利用する方法 全インスタンスの SHAP 値の絶対値を平均する SHAP 値は各インスタンスごとにある特徴量を追加したときの予測値の増分のすべての追加順での平均 全インスタンスの
SHAP の絶対値を平均すれば特徴量重要度として妥当なものに
PFI との違い インスタンスごとの擬似的な特徴量重要度を、その特徴量の大小との関係とともに可視化できる PFI では寄与度が両方の符号をとる特徴量の重要度が SHAP を用いた場合より低く見積もられる
SHAP を PD と同じ用途で利用する方法 縦軸に SHAP 値、横軸に特徴量値をとってプロット 最も強い交互作用項を色で表すようにすれば、その項が予測値に及ぼす影響も可視化できる
SHAP の注意点 計算コストが高いため、サンプリングが必要になる場面もある 理論が相対的に難しく、非専門家への説明に苦労する場合がある . 個人的に考えたこと 周辺化では暗黙的に特徴量の独立性を仮定しているように見えるが、実際に独立なデータはほぼ無さそう
解釈手法のモデルの精度向上への応用例 誤分類インスタンスへの対応:観察や理由の考察を通して対応策を考える 特異なインスタンスを発見:考察を深める 特徴量選択:寄与の小さい特徴量を削除 アンサンブルの設計:異なるモデルの寄与パターンを比較し補完的な組み合わせを構築
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}