from causallib.datasets import load_nhefs from causallib.estimation import IPW, PropensityMatching, StratifiedStandardization from causallib.evaluation import evaluate import matplotlib.pyplot as plt import numpy as np from sklearn.linear_model import LogisticRegression data = load_nhefs()
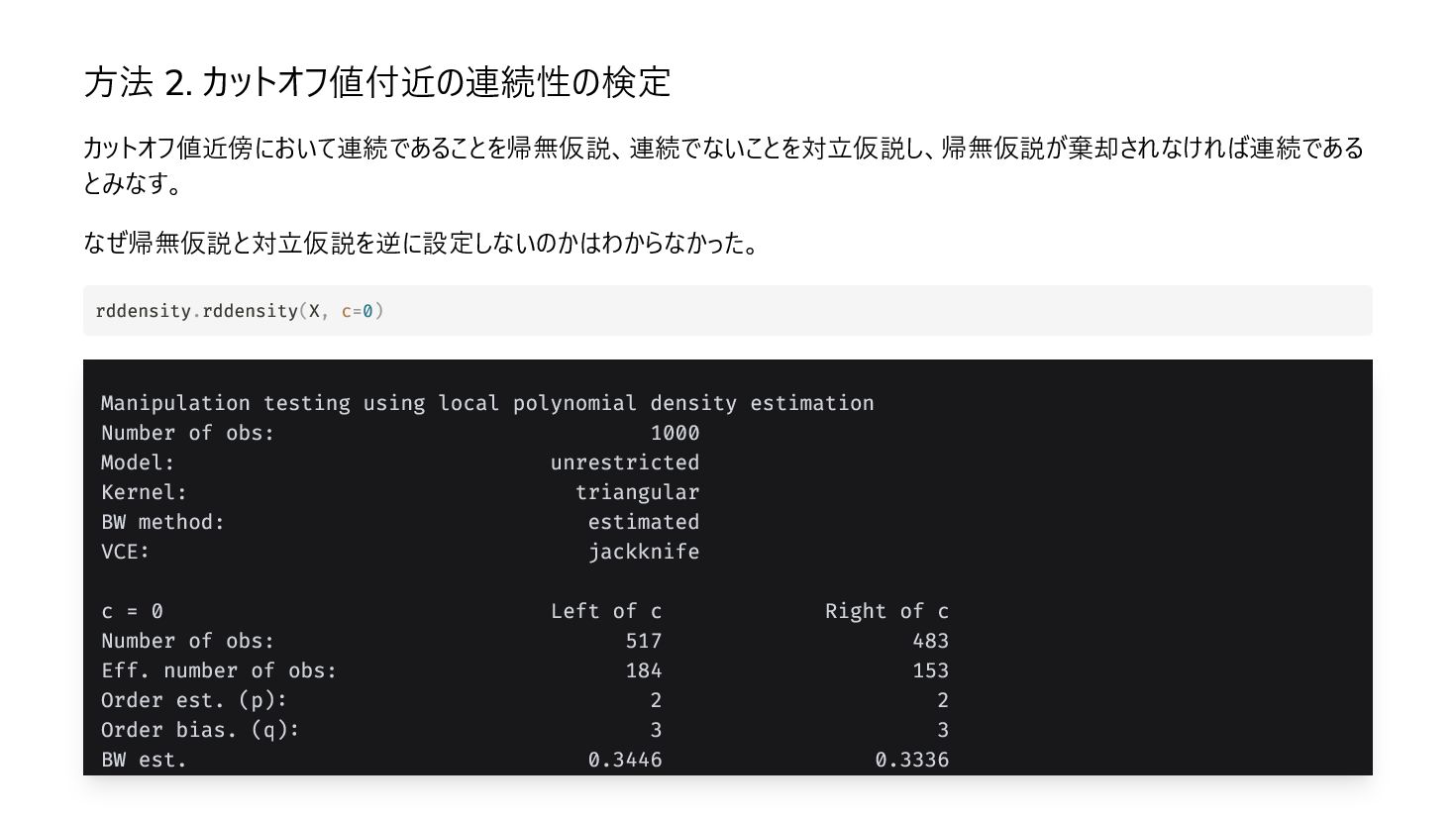
polynomial density estimation Number of obs: 1000 Model: unrestricted Kernel: triangular BW method: estimated VCE: jackknife c = 0 Left of c Right of c Number of obs: 517 483 Eff. number of obs: 184 153 Order est. (p): 2 2 Order bias. (q): 3 3 BW est. 0.3446 0.3336 rddensity.rddensity(X, c=0)
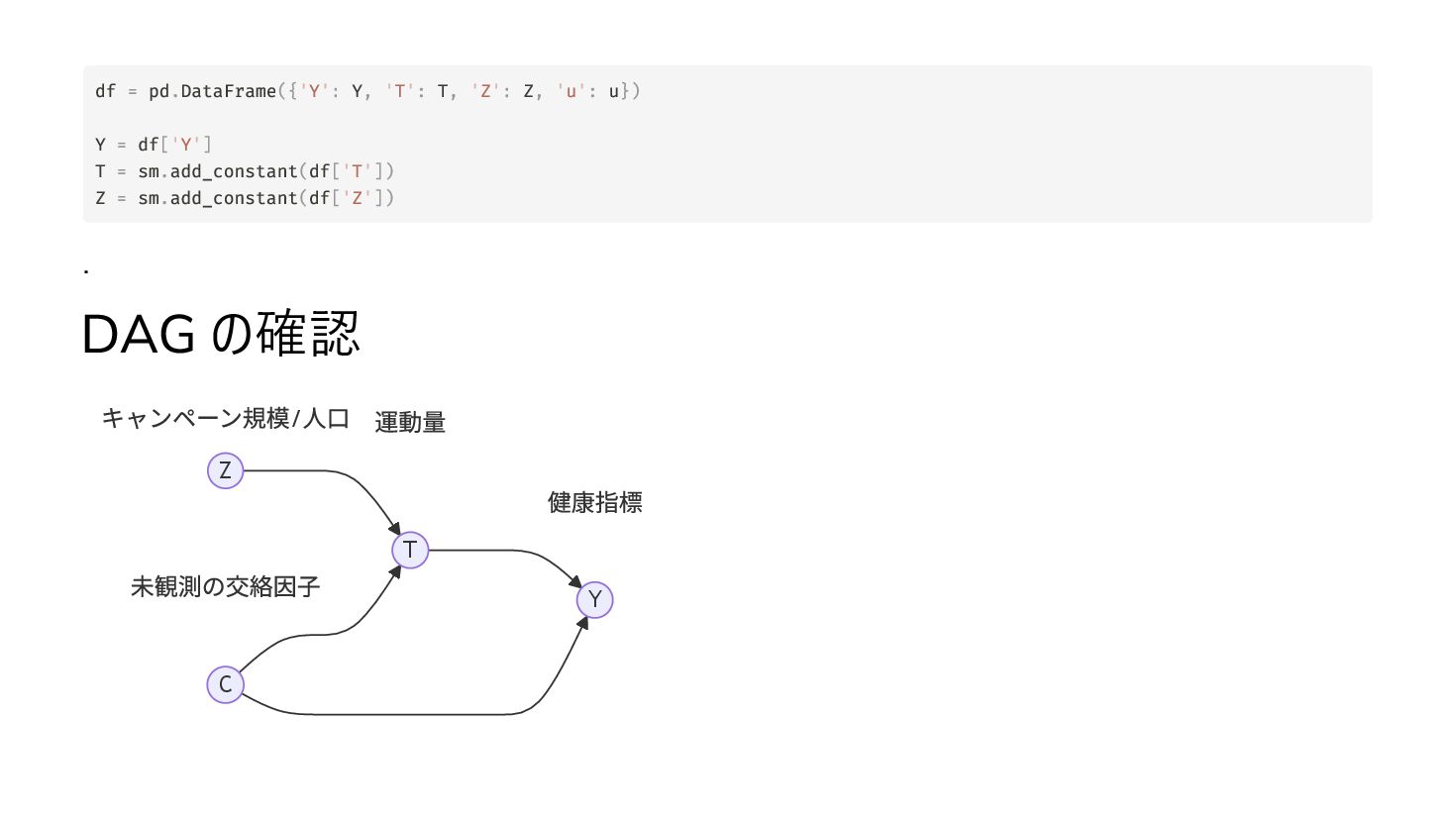
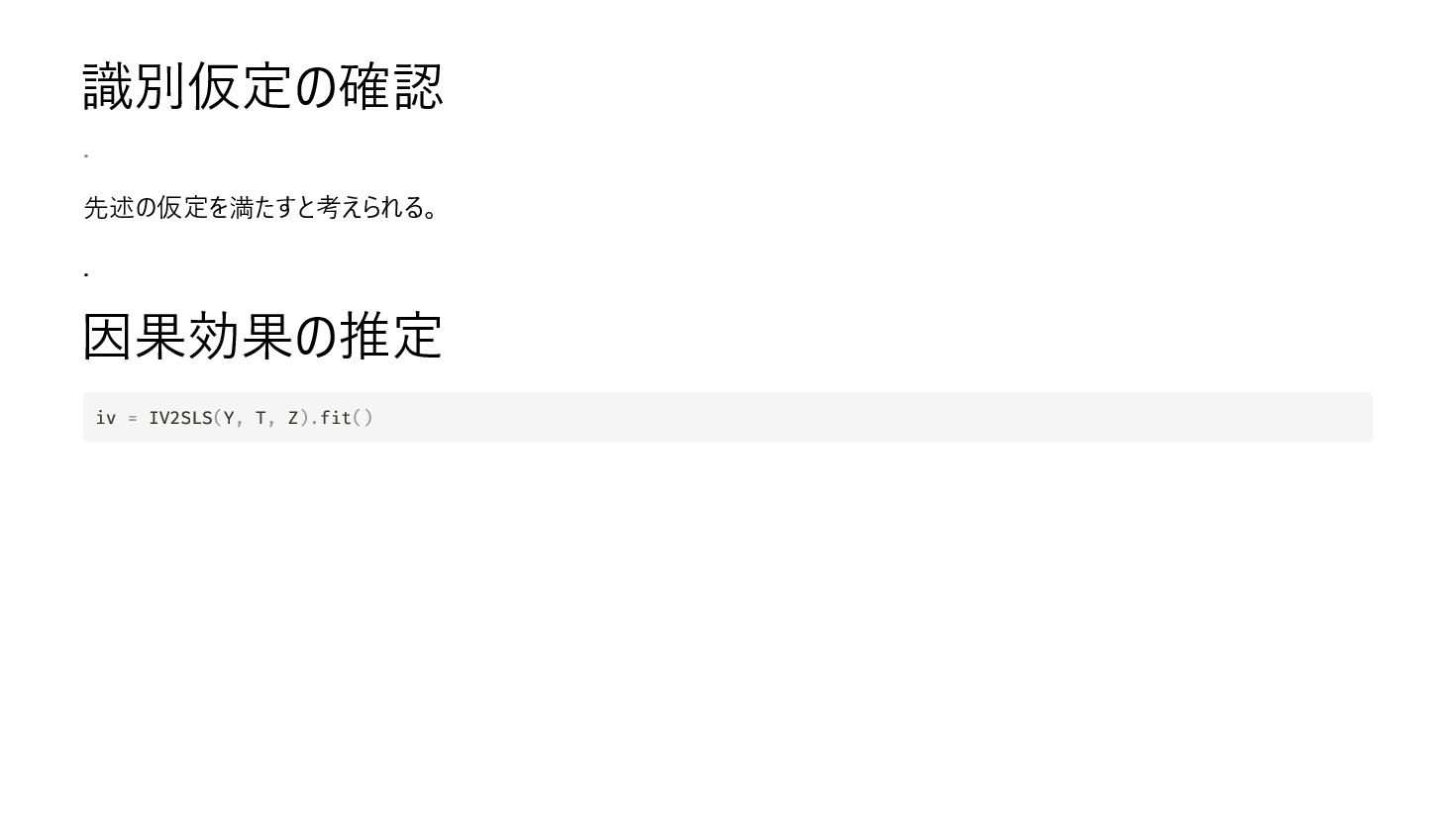
が を通して以外に に影響を与えない (除外制約) と は共通の原因 を持たない 最初の条件については、実際には関連するだけではなく、 と強い相関を持つ を用意する必要がある。 評価の方法としては、 と の回帰において が無関係であるという帰無仮説のもとで F 検定統計量が 10 以上であれば良い とされている。 . T Y Z Z T Cov(Z, T) = 0 Z T Y Z Y T Z Z T Z
この条件を設定することで、推定する処置効果は群全体で考える ATE ではなく、② 遵守者への ATE を算出することになる。こ のときの遵守者への ATE を CACE もしくは LATE と言う。 i T i D i T i D i D (T = i i 1) ≥ D (T = i i 0)
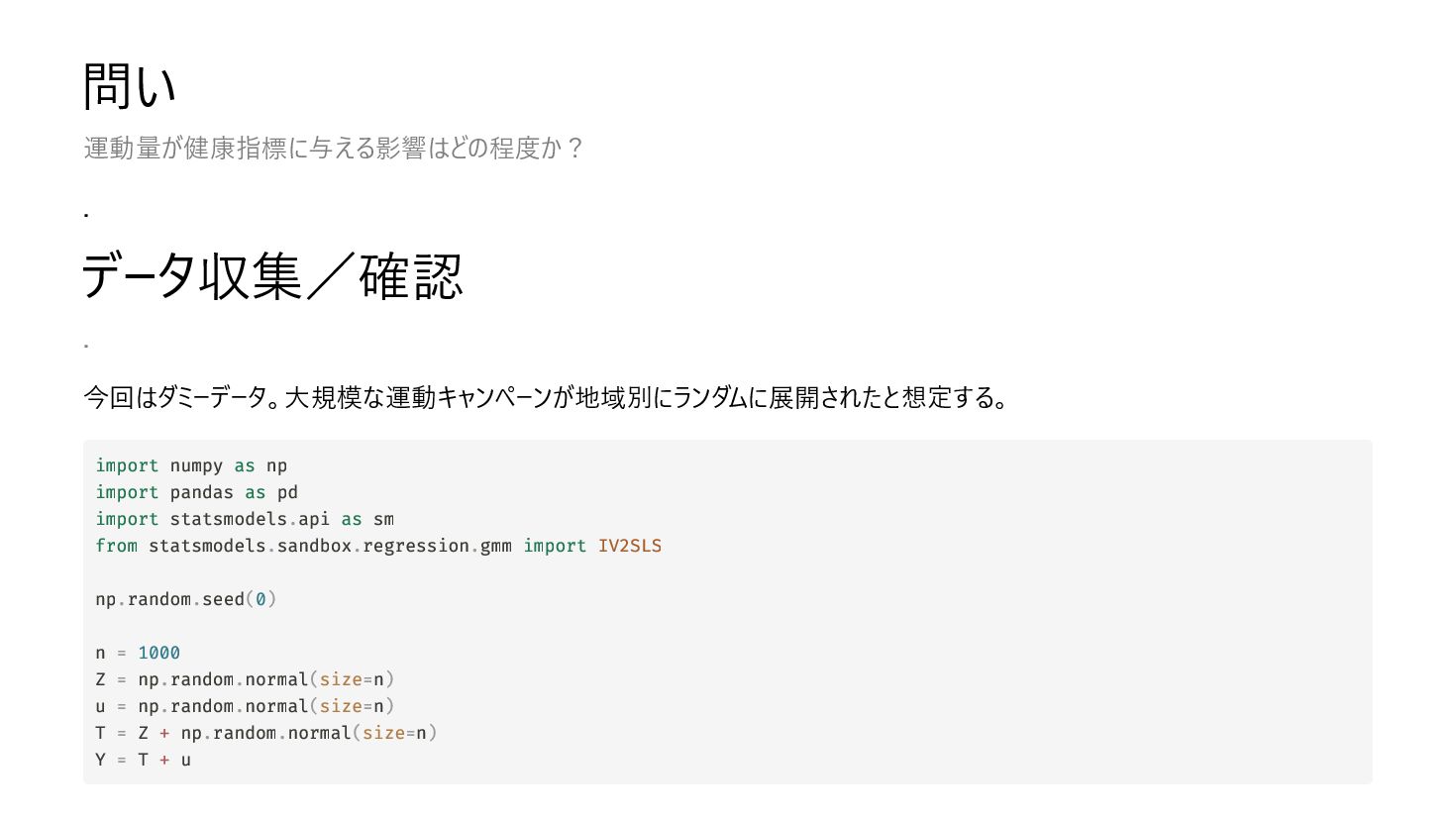
import pandas as pd import statsmodels.api as sm from statsmodels.sandbox.regression.gmm import IV2SLS np.random.seed(0) n = 1000 Z = np.random.normal(size=n) u = np.random.normal(size=n) T = Z + np.random.normal(size=n) Y = T + u
0.65 result = cp.SyntheticControl( df, treatment_time, formula="f ~ 0 + actual + a + b + c + d + e + g", model=cp.skl_models.WeightedProportion(), ) fig, ax = result.plot(plot_predictors=True)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
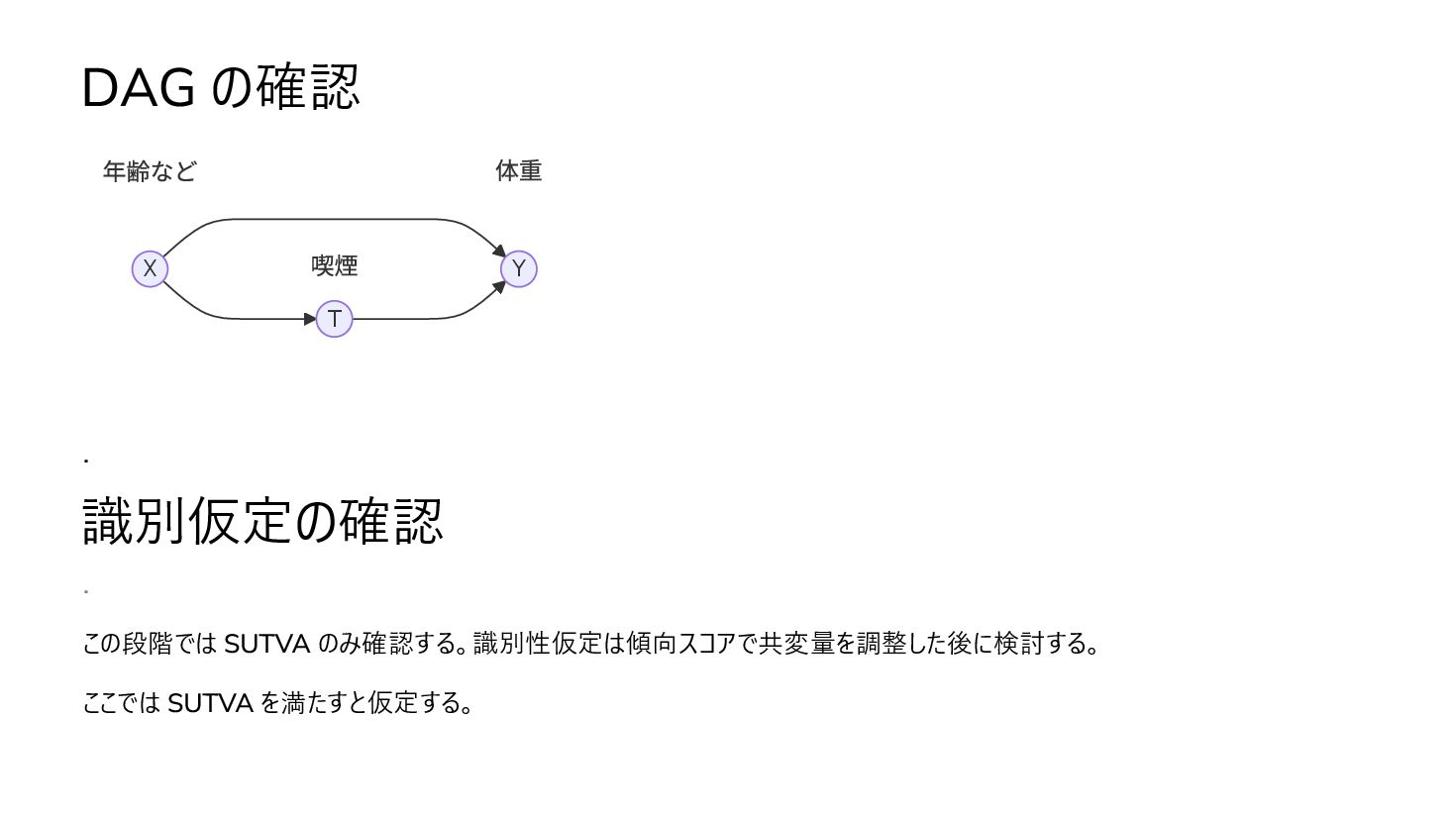{kind=link}
{kind=link}
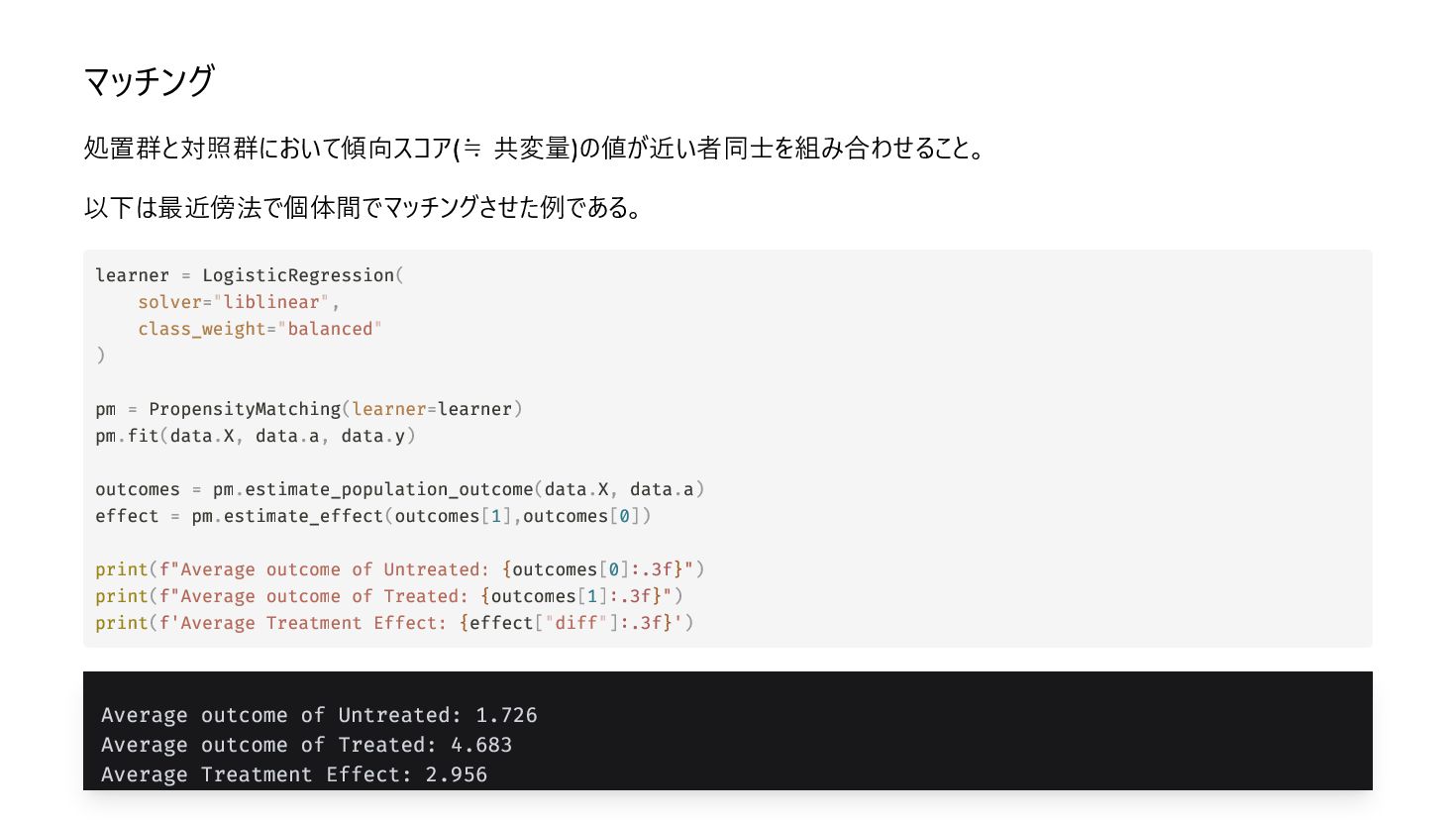{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
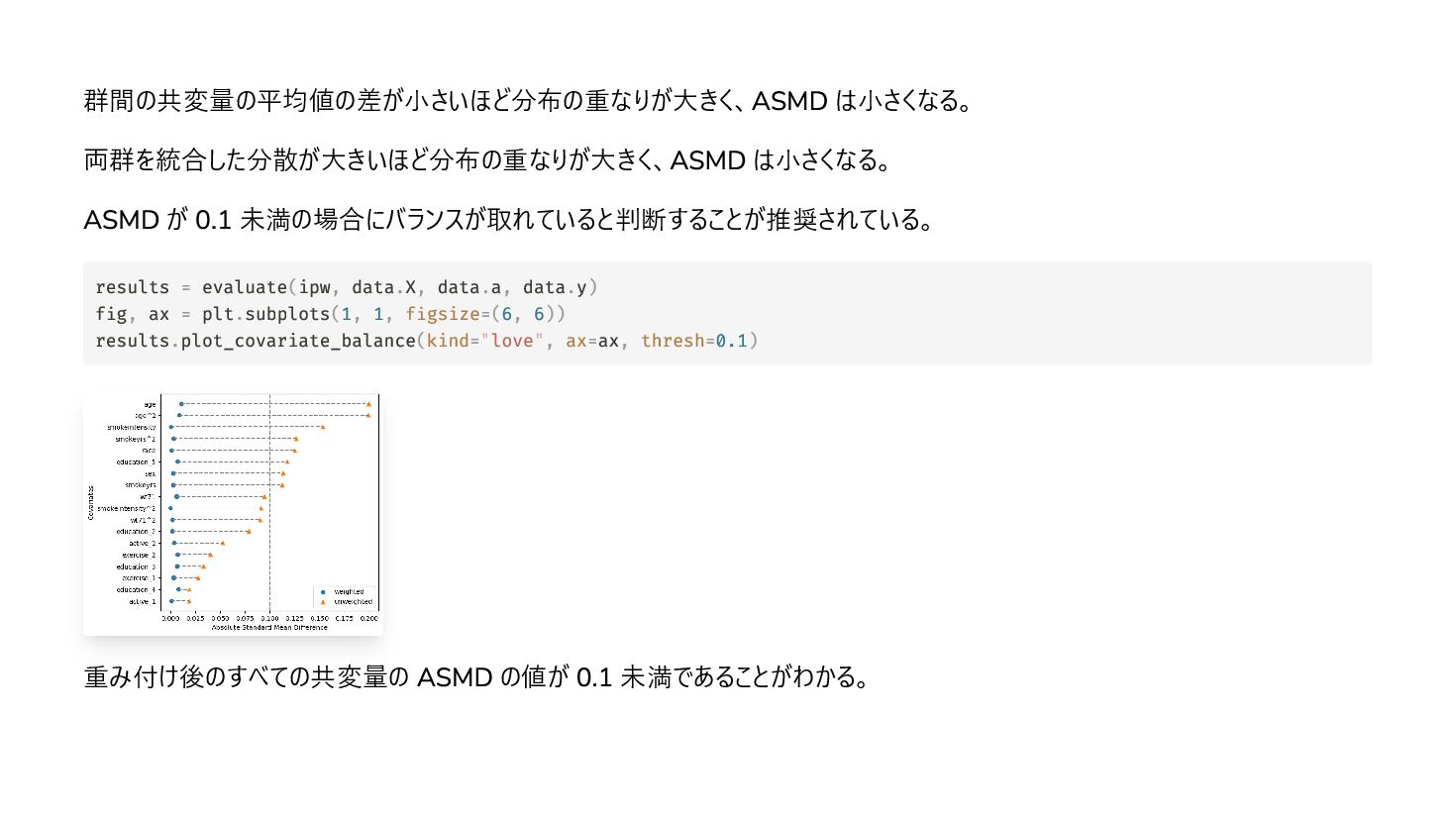{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
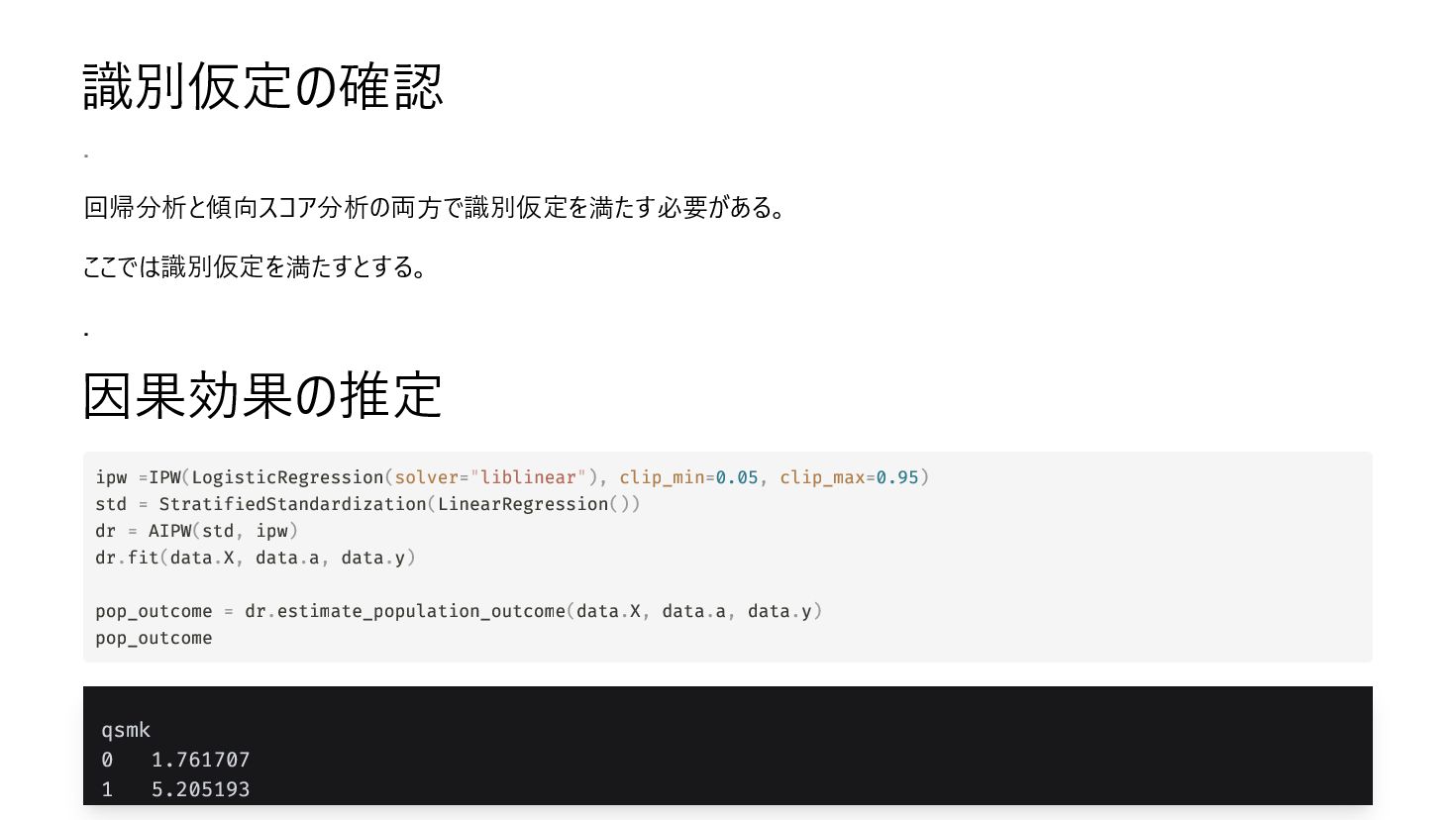{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![方法 1. カットオフ値付近の個体の分布の確認 横軸にカットオフの基準に使う変数をとって個体数をプロットする。 plt.hist(df[df['X'] < threshold]['X'], bins=10, alpha=0.5, label='BelowThreshold')](https://files.speakerdeck.com/presentations/466c062dc29c4735b747f54f0209a7e2/slide_38.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
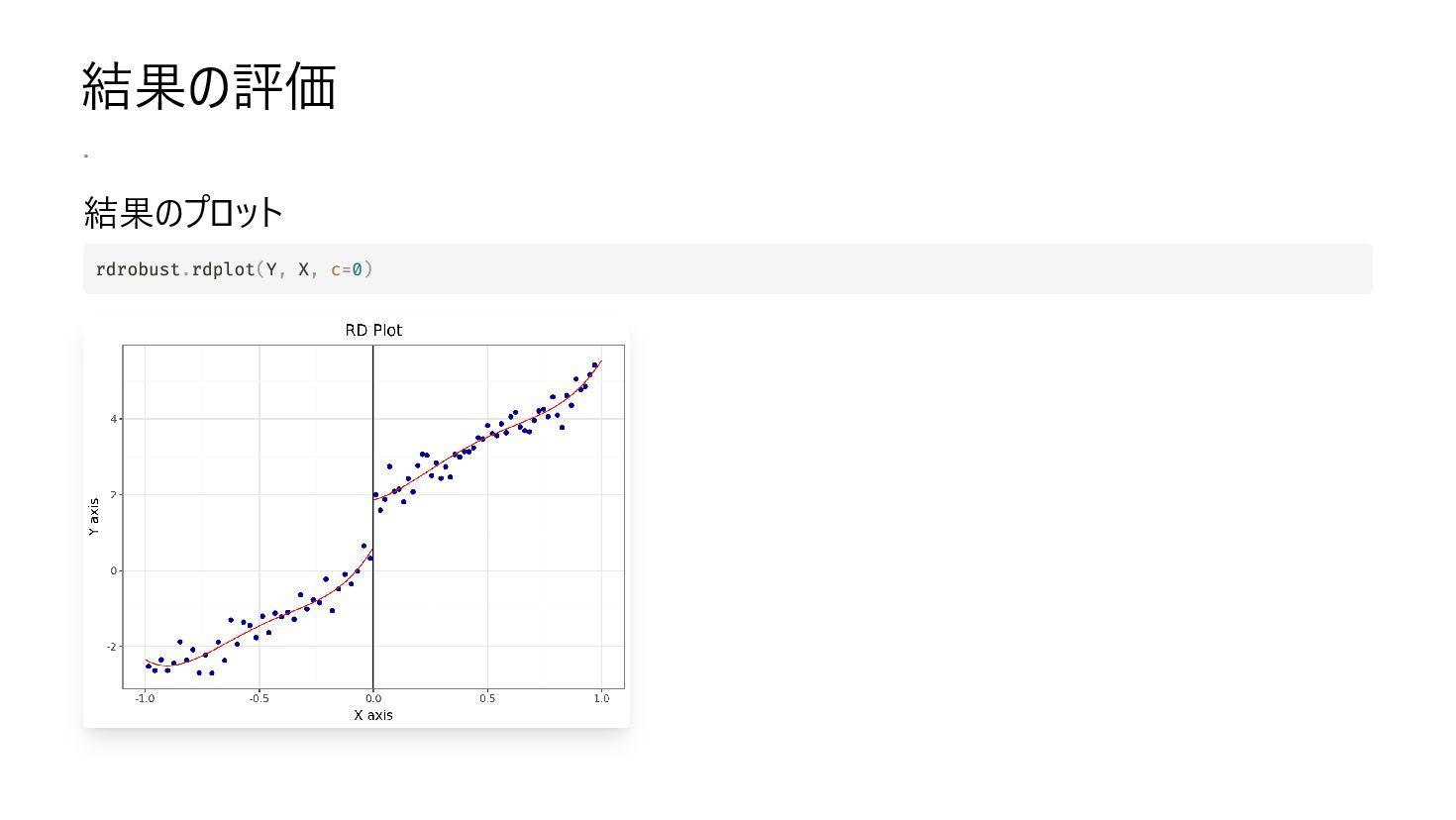{kind=link}
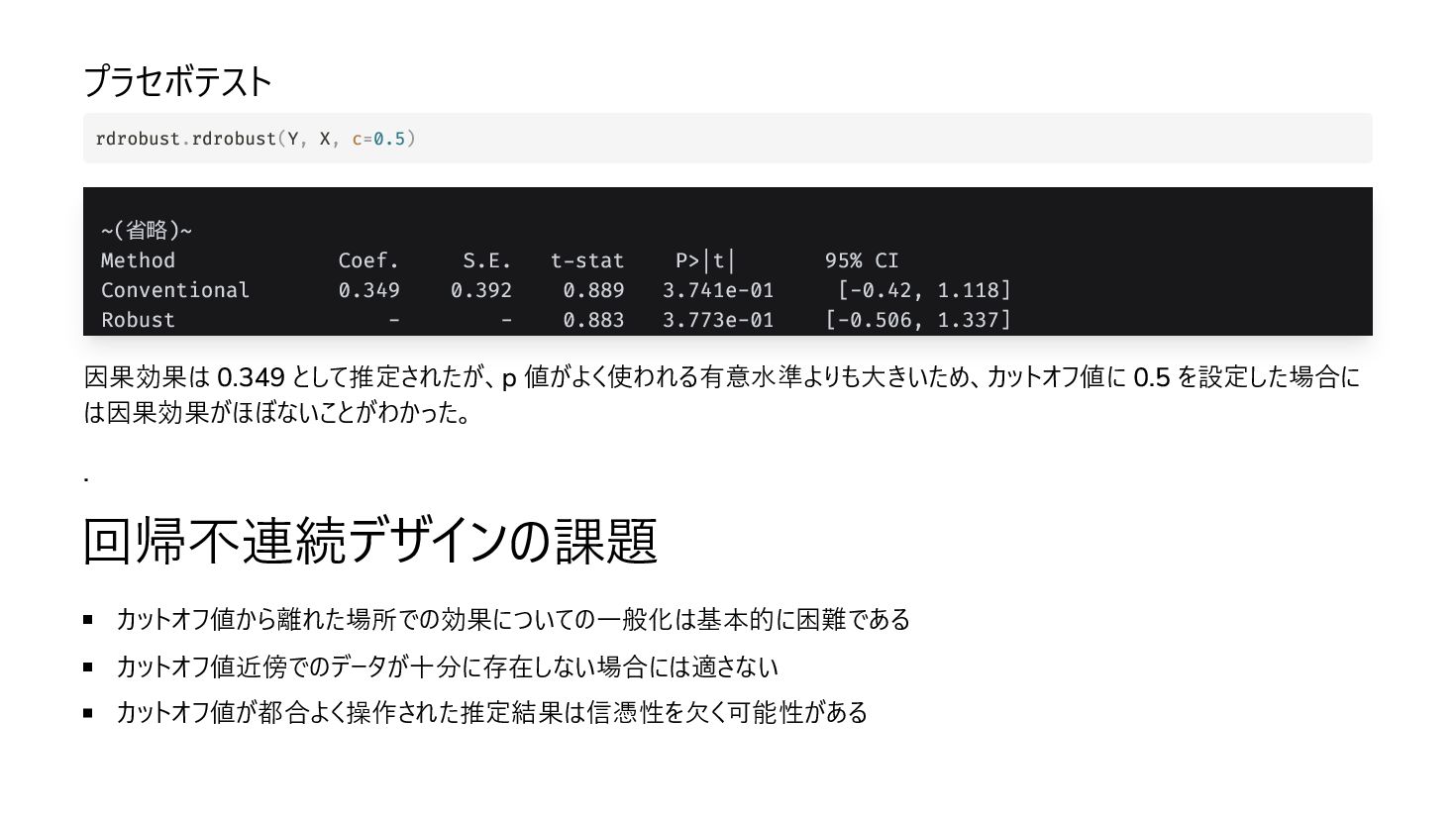{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
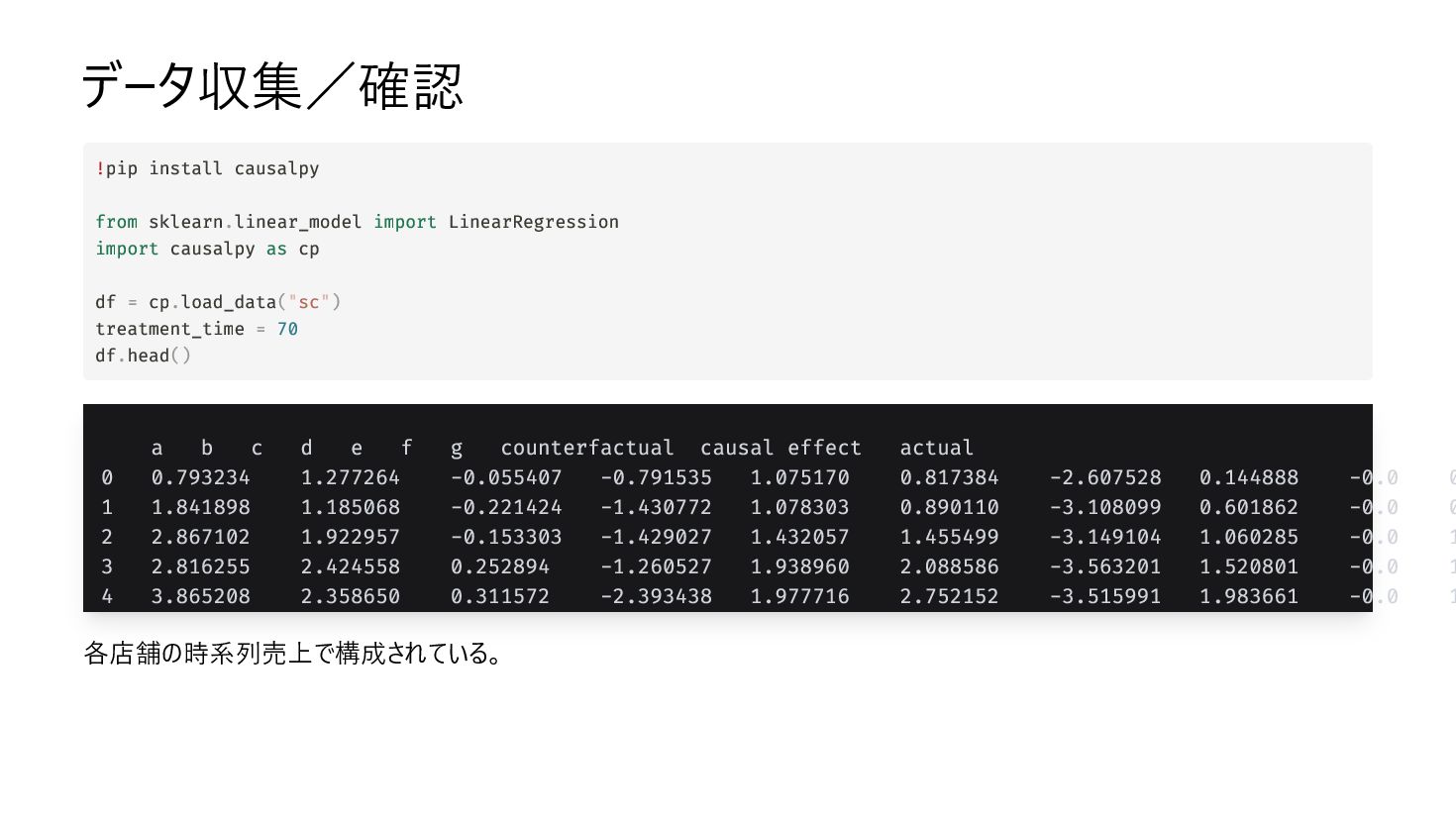{kind=link}
{kind=link}
{kind=link}
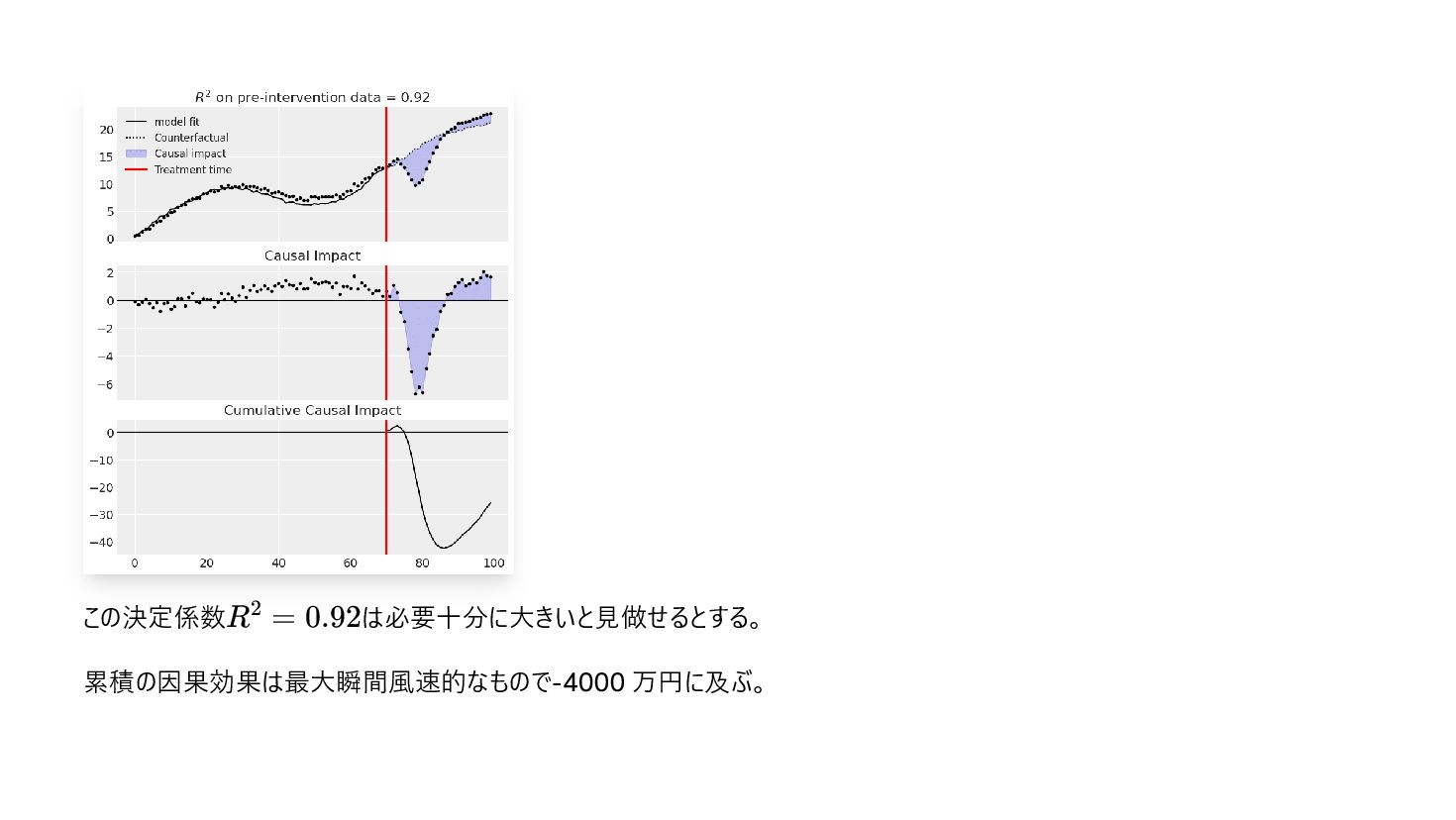{kind=link}
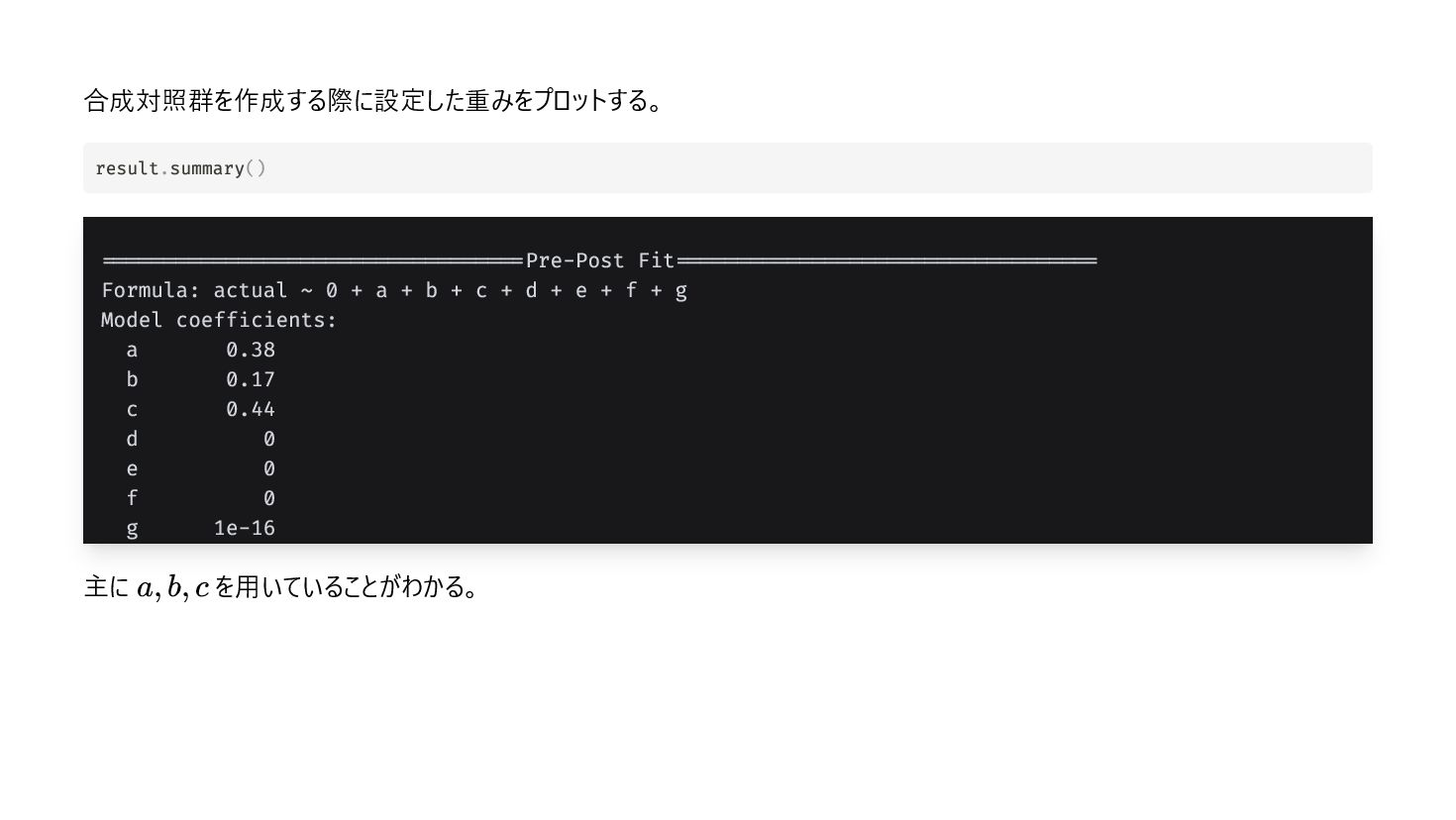{kind=link}
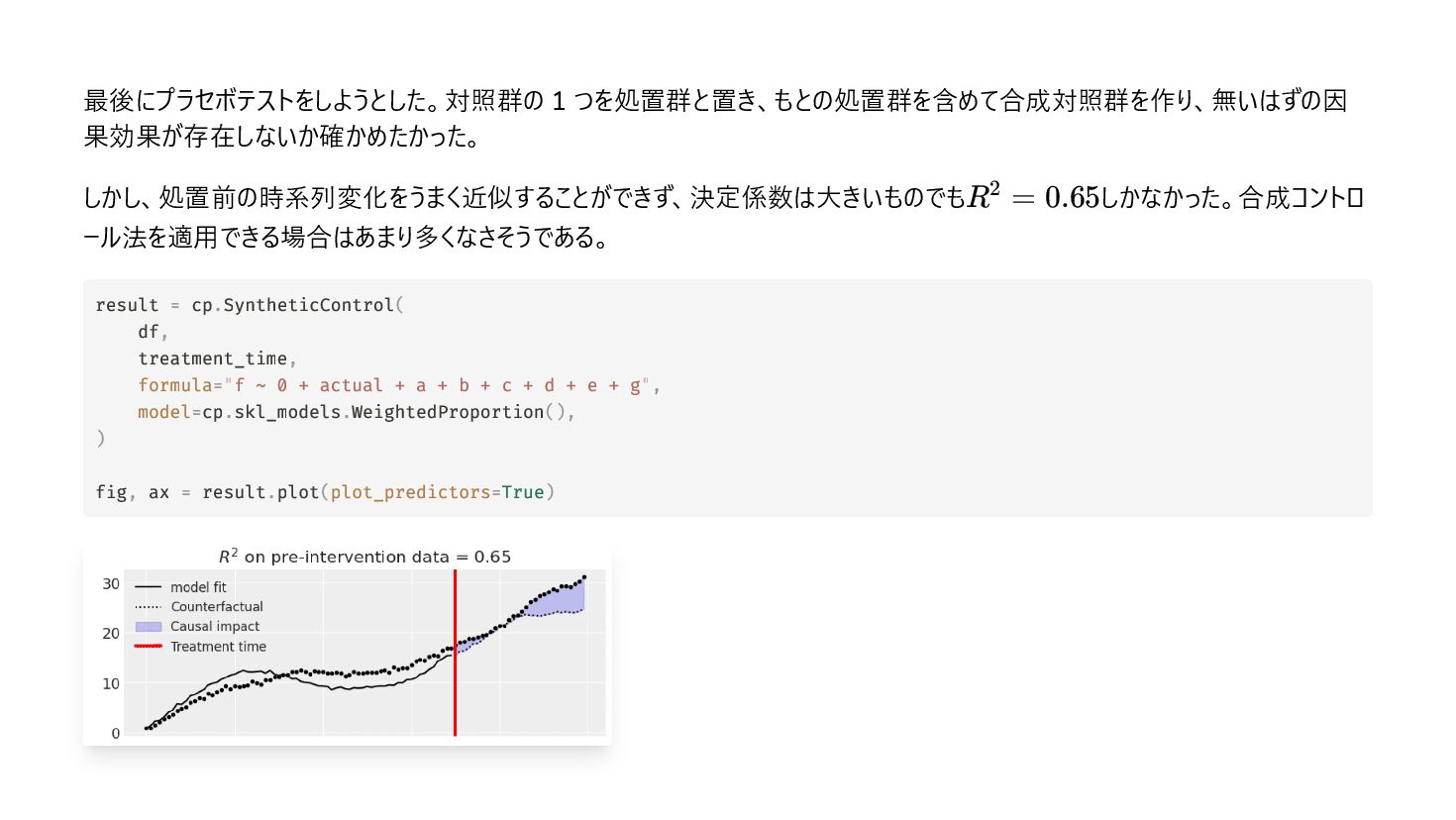{kind=link}
{kind=link}