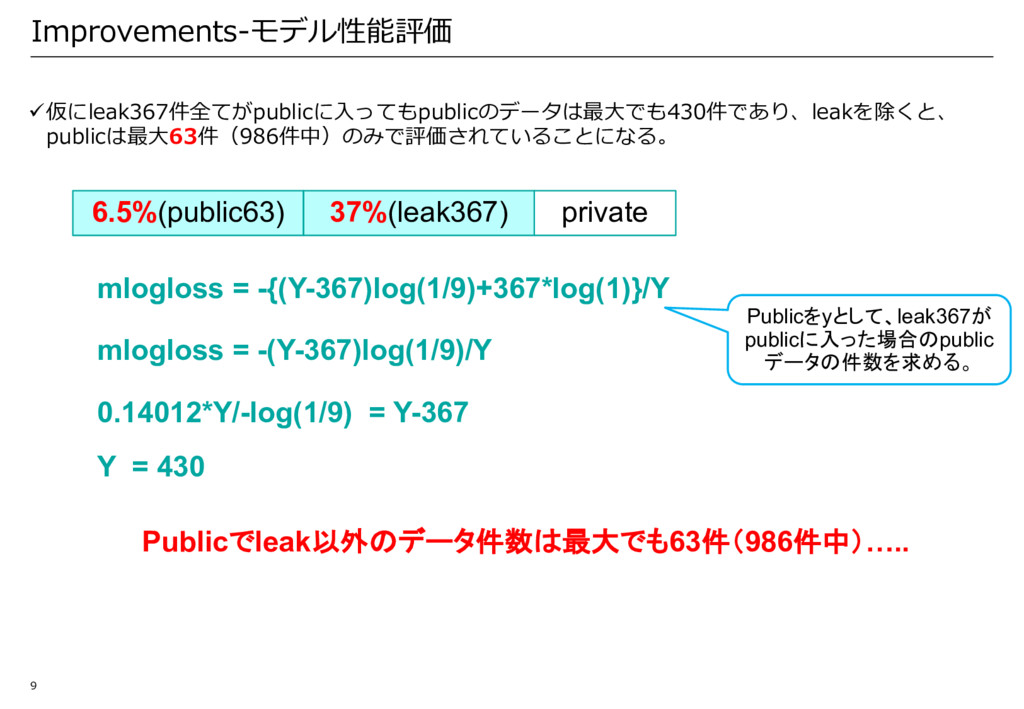
テストデータ: ü学習データ:3,322件 üテストデータ Phase1データ: 5669件 Phase2(最終評価)データ: 987件 ü内容: ü Gene:突然変異した細胞の場所 ü Variation:アミノ酸変化種別 ü Text:テキスト形式の臨床的エビデンス(約50,000⽂字) ü Class:病理診断の結果 2. 評価⽅法: 2 ID Gene Variation Text Class 0 FAM5 8A Truncatin g Mutation s Cyclin-dependent kinases (CDKs) regulate... 1 1 CBL W802* cell lung canc... 2
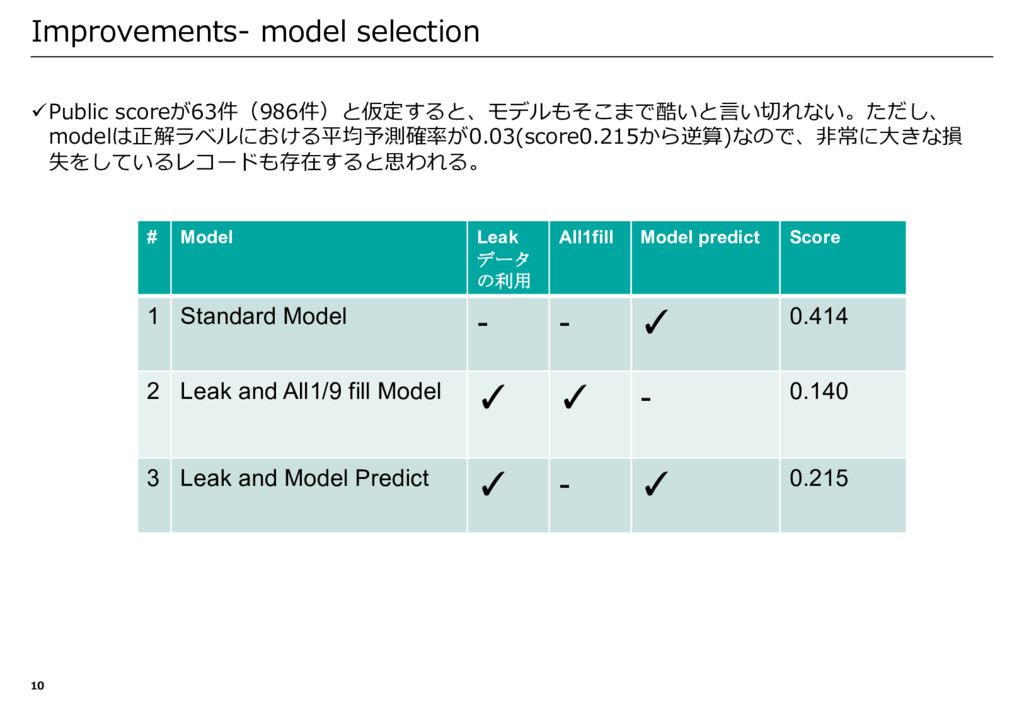
Model predict Public Score 1 Standard Model - - ✓ 0.414 2 Leak and All1fill Model ✓ ✓ - 0.140 3 Leak and Model Predict ✓ - ✓ 0.215 4 Leak and Weighted Average ✓ ✓ ✓ 0.1367
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}