Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Road to Kaggle master
Search
tosh
February 10, 2018
1.1k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Road to Kaggle master
tosh
February 10, 2018
More Decks by tosh
See All by tosh
Personalized Medicine Redefining Cancer Treatment Solution
toshh
1
1.1k
Featured
See All Featured
Designing for humans not robots
tammielis
254
26k
Leo the Paperboy
mayatellez
8
1.9k
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.8k
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
240
Why Your Marketing Sucks and What You Can Do About It - Sophie Logan
marketingsoph
0
280
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
Google's AI Overviews - The New Search
badams
0
1.1k
Un-Boring Meetings
codingconduct
0
350
Abbi's Birthday
coloredviolet
3
8.7k
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.7k
Fight the Zombie Pattern Library - RWD Summit 2016
marcelosomers
234
17k
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
Transcript
Road to Kaggle master 岩森俊哉
Kaggleとは Kaggleとは 自己紹介 Kaggle初級編 Kaggle中級編 Kaggle上級編
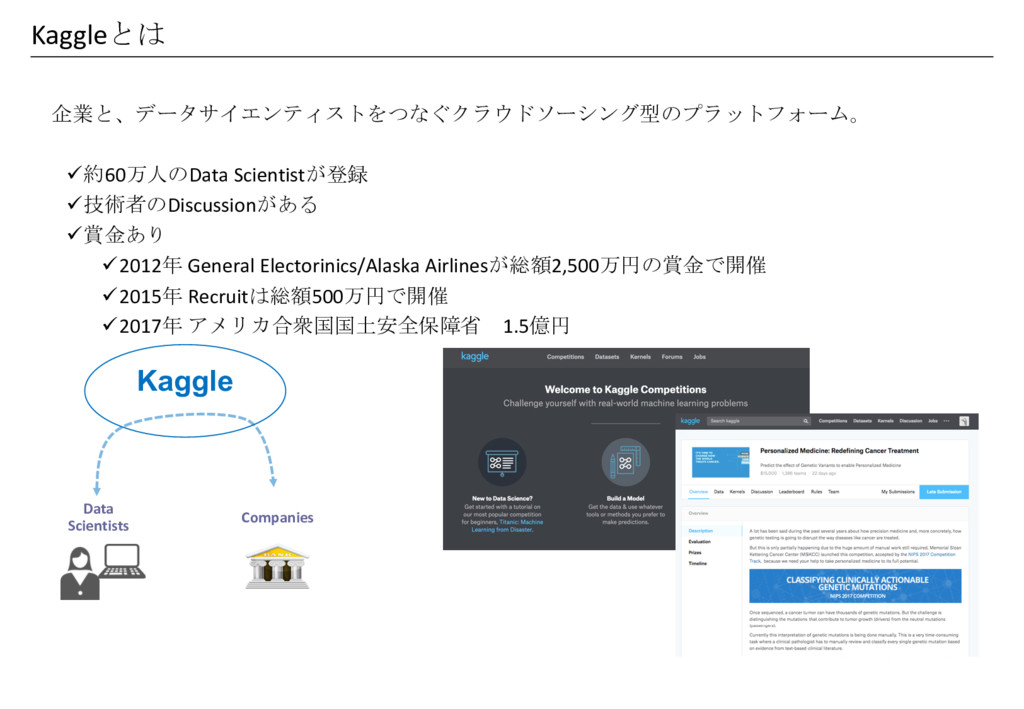
企業と、データサイエンティストをつなぐクラウドソーシング型のプラットフォーム。 ü約60万人のData Scientistが登録 ü技術者のDiscussionがある ü賞金あり ü2012年 General Electorinics/Alaska Airlinesが総額2,500万円の賞金で開催 ü2015年
Recruitは総額500万円で開催 ü2017年 アメリカ合衆国国土安全保障省 1.5億円 Kaggleとは Data Scientists Kaggle Companies
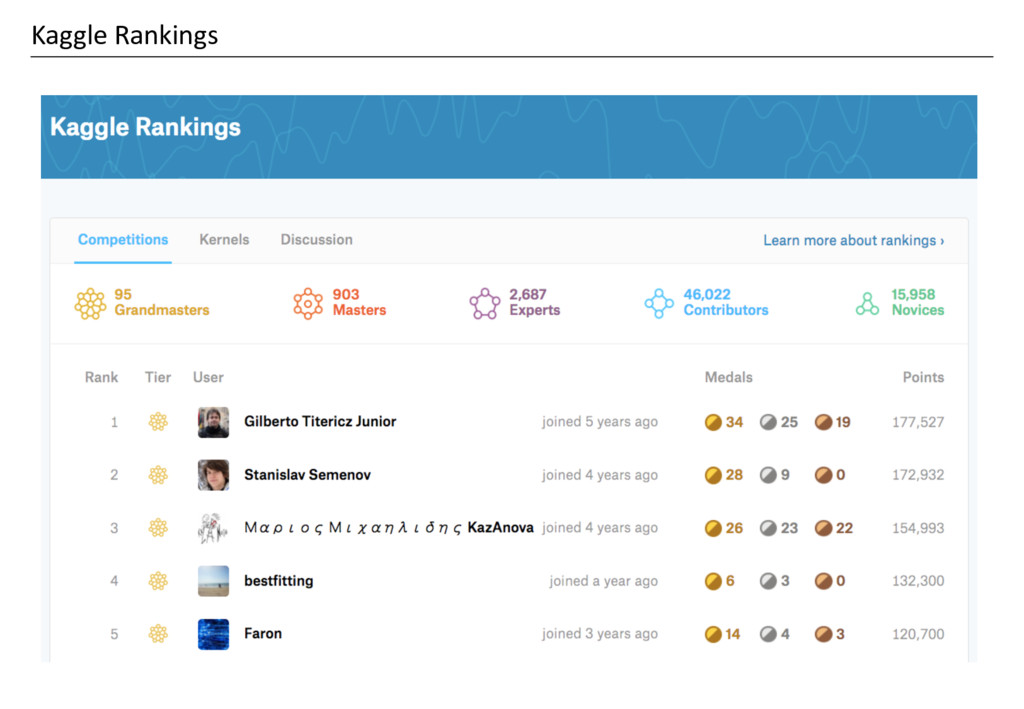
Kaggle Rankings
モデル構築の一般的な流れとその中におけるKaggle 1.データ受領 データ理解 モデル構築 3-2.性能評価 2.データ理解 3.モデル構築 4.業務評価 5.改善対応策 2-1.データの理解
データ理解し、重要な情報の特定を行う 2-2.課題の理解 機械学習を用いて解くべき課題の理解 真のデータと予測データを比較し、性能評価 3-3.改善 性能向上のために、改善ポイントを整理 2-3-.特徴量抽出 データを加工し、判断材料となる要素を抽出する 3-1.モデル作成 機械学習アルゴリズムを適用して学習
自己紹介 Kaggleとは 自己紹介 Kaggle初級編 Kaggle中級編 Kaggle上級編
岩森俊哉 (Toshiya Iwamori) 学生時代には数学科に所属し、流体の数学的解析の研究に従事。 Sierに入社後、金融のデリバリーやデータサイエンティストとして業務分析を経験。 Kaggleには2年前より始め、日々奮闘中。 ヘルスケア・ライフサイエンス領域における疾患の分類、医療の専門文書分類などへの機 械学習の応用が専門。 Finished Competition
rank 2017/8/14 Instacart Market Basket Analysis 56 / 2623 2017/10/2 Personalized Medicine: Redefining Cancer Treatment 4 / 1386 2018/1/15 Corporación Favorita Grocery Sales Forecasting 49 / 1675 2018/2/6 Recruit Restaurant Visitor Forecasting 51 / 2216
Kaggleとは 自己紹介 Kaggle初級編 Kaggle中級編 Kaggle上級編 Kaggle初級編
Kaggle初級編– 初サブミット Titanicのチュートリアルでモデルを構築、実行!! 初サブミットに感動!!
Kaggle初級編– xgboost使用上の注意 ただxgboostを意味もわからずにいじるだけの日々 モデル xgboost使え ば、もっと精 度出るよ もっと精度が 欲しい もっと高度な
モデルが必要 1度だけなら…. 精度でない 苦しい
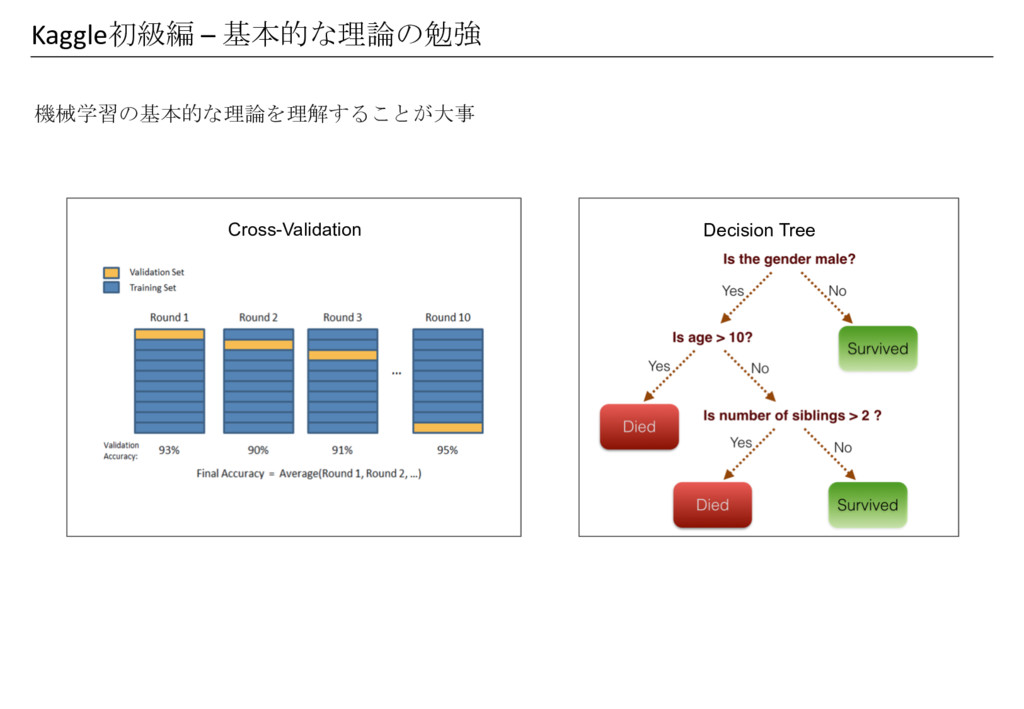
機械学習の基本的な理論を理解することが大事 Kaggle初級編 – 基本的な理論の勉強 Decision Tree Cross-Validation
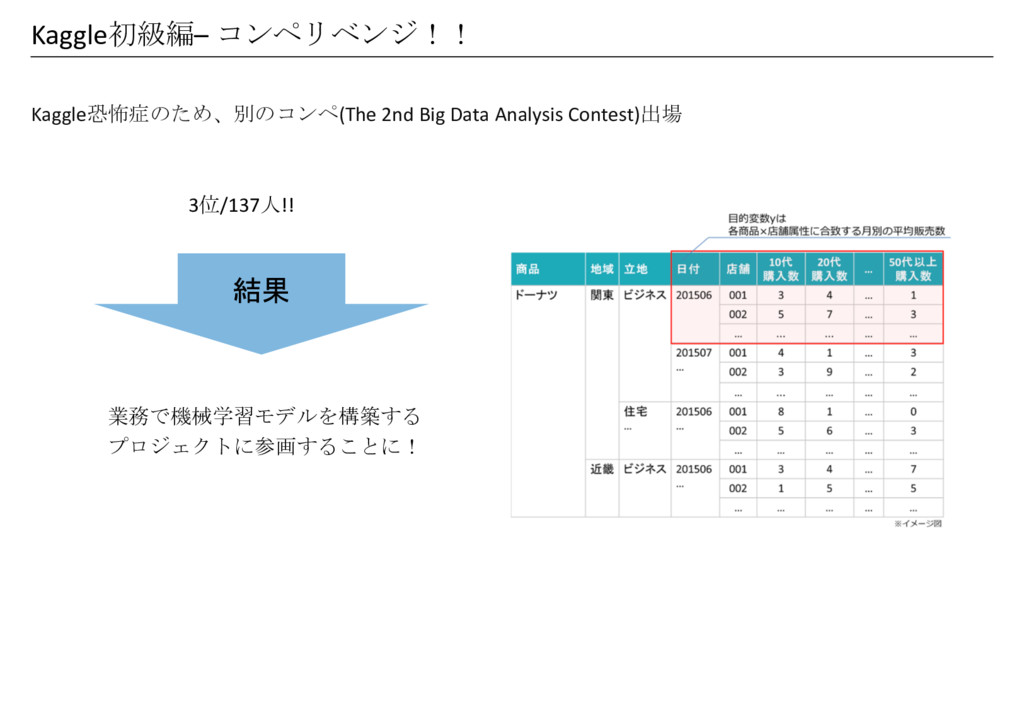
Kaggle初級編– コンペリベンジ!! Kaggle恐怖症のため、別のコンペ(The 2nd Big Data Analysis Contest)出場 3位/137人!! 業務で機械学習モデルを構築する
プロジェクトに参画することに! 結果
Kaggle中級編 Kaggleとは 自己紹介 Kaggle初級編 Kaggle中級編 Kaggle上級編
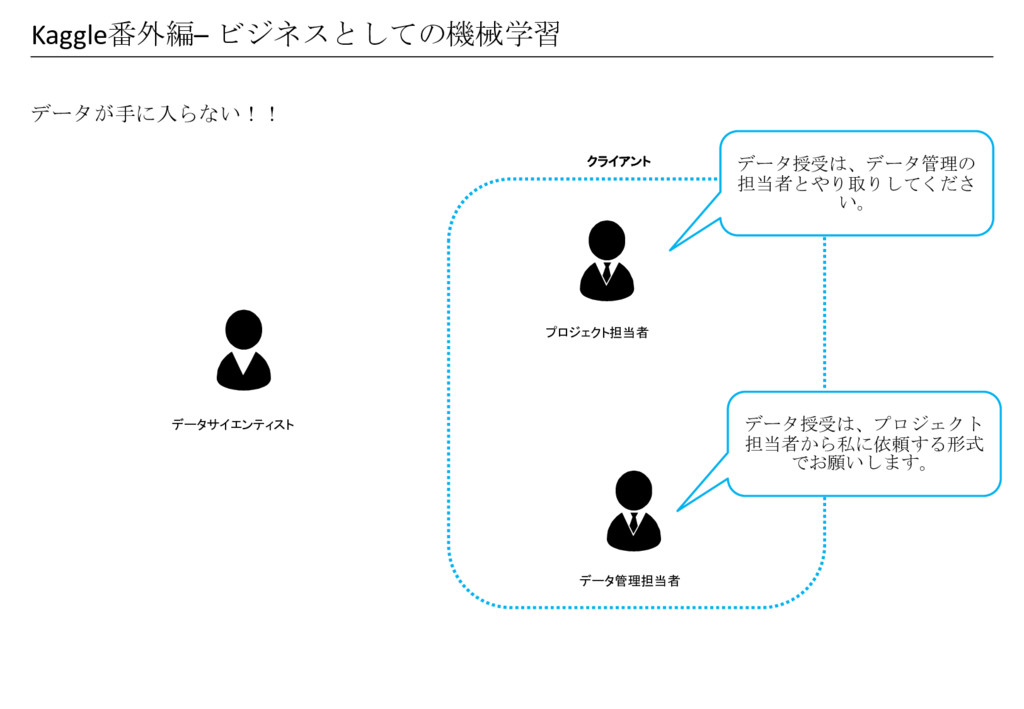
Kaggle番外編– ビジネスとしての機械学習 データが手に入らない!! データサイエンティスト プロジェクト担当者 データ管理担当者 クライアント データ授受は、データ管理の 担当者とやり取りしてくださ い。
データ授受は、プロジェクト 担当者から私に依頼する形式 でお願いします。
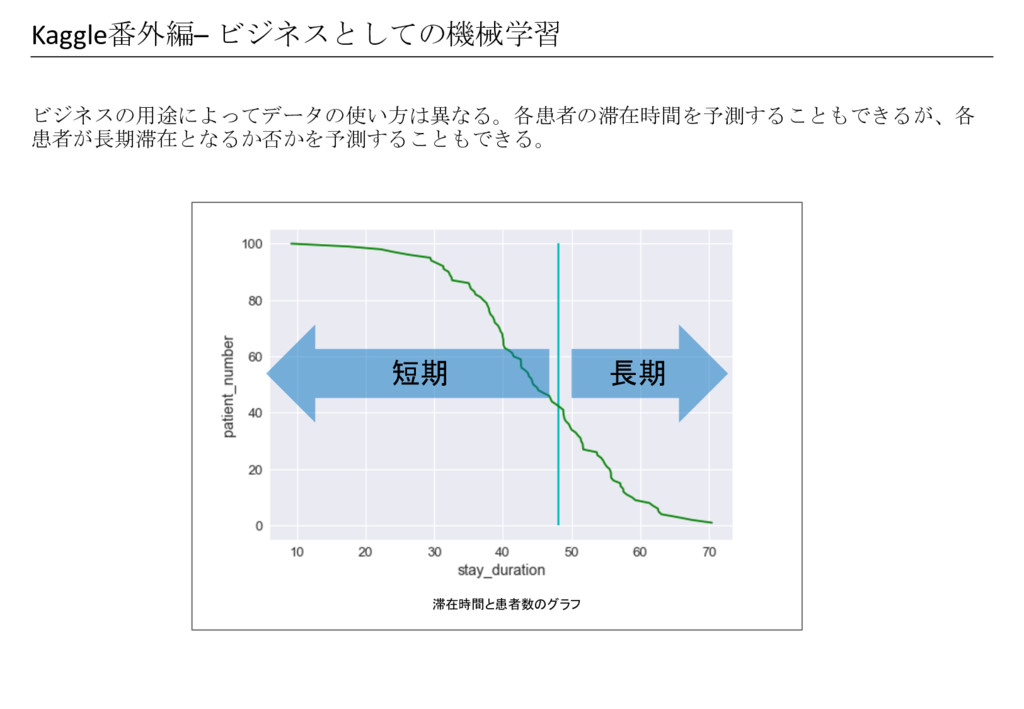
Kaggle番外編– ビジネスとしての機械学習 ビジネスの用途によってデータの使い方は異なる。各患者の滞在時間を予測することもできるが、各 患者が長期滞在となるか否かを予測することもできる。 長期 短期 滞在時間と患者数のグラフ
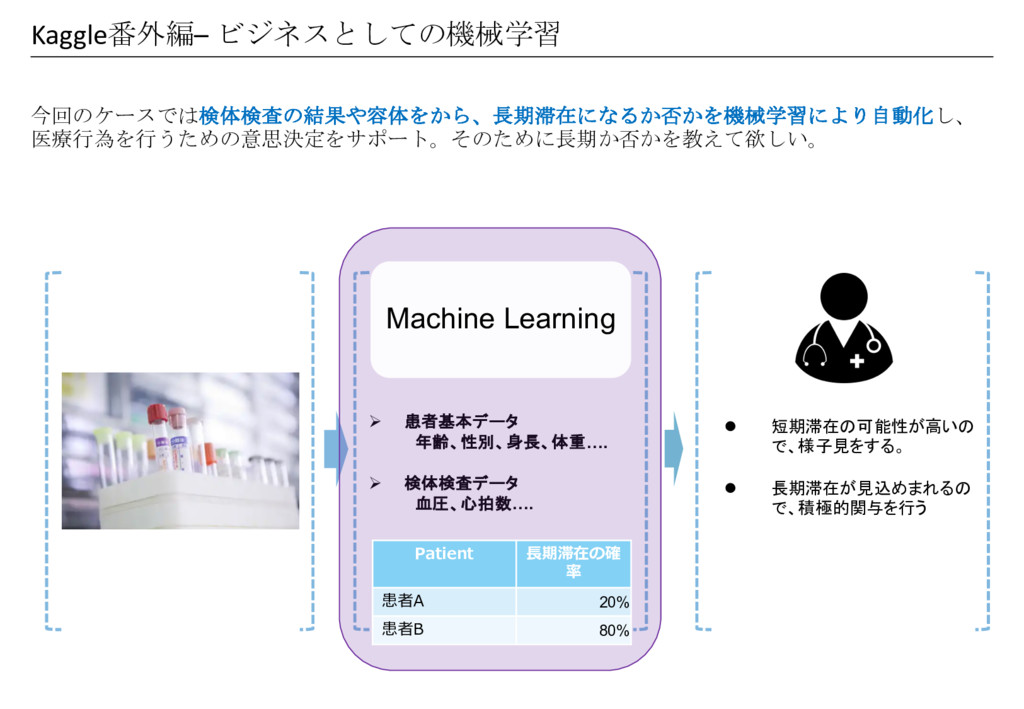
Kaggle番外編– ビジネスとしての機械学習 今回のケースでは検体検査の結果や容体をから、長期滞在になるか否かを機械学習により自動化し、 医療行為を行うための意思決定をサポート。そのために長期か否かを教えて欲しい。 l 短期滞在の可能性が高いの で、様子見をする。 l 長期滞在が見込めまれるの で、積極的関与を行う
Ø 患者基本データ 年齢、性別、身長、体重…. Ø 検体検査データ 血圧、心拍数…. Machine Learning Patient ⻑期滞在の確 率 患者A 20% 患者B 80%
Kaggle中級編– 特徴量の作成技法 üKaggleの過去コンペのsolutionやkernelが参考になる。 üJupyter notebookを使って、データの可視化を行い、特徴を探す。 Jupyter notebookを使用して、データを眺める
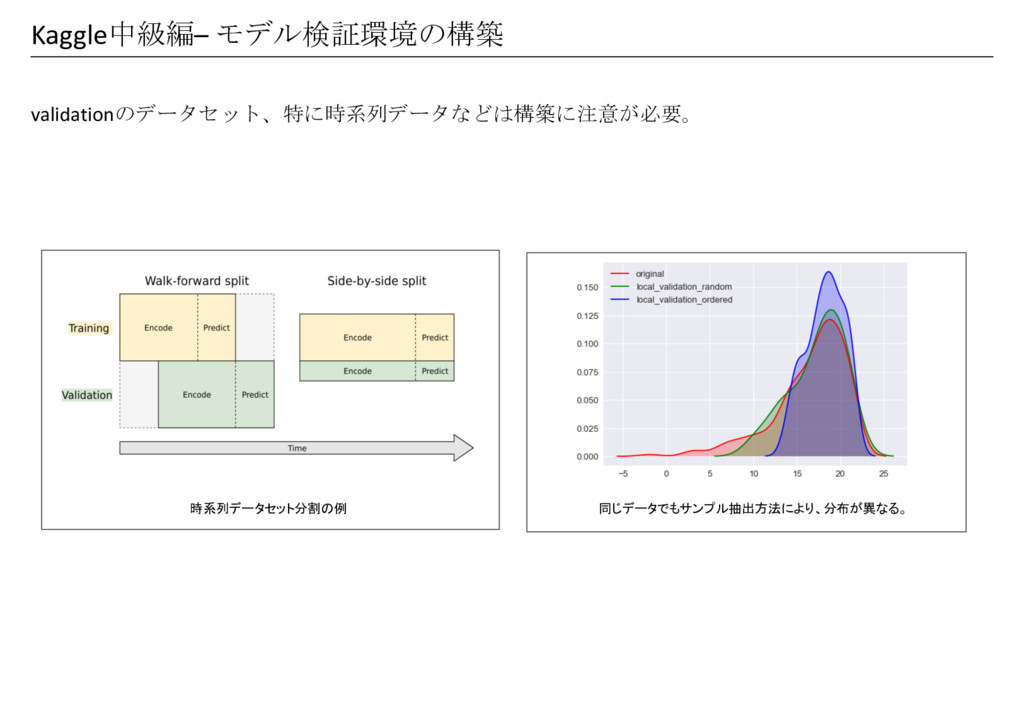
Kaggle中級編– モデル検証環境の構築 validationのデータセット、特に時系列データなどは構築に注意が必要。 時系列データセット分割の例 同じデータでもサンプル抽出方法により、分布が異なる。
Kaggle上級編 Kaggleとは 自己紹介 Kaggle初級編 Kaggle中級編 Kaggle上級編
Kaggle上級編– 評価指標への最適化 ü 評価指標の最適化。 例としてloglossは、モデルが正解ラベルの確率を低く出力した場合、不正解となった場合には評 価結果が著しく悪化する。そのため、不正解時にスコアを低くし過ぎないなどの補正する。 Light GBMによる予測結果 重みつけ平均で最適化した予測結果 予測値が0に近いほどlog
lossの値は大きい
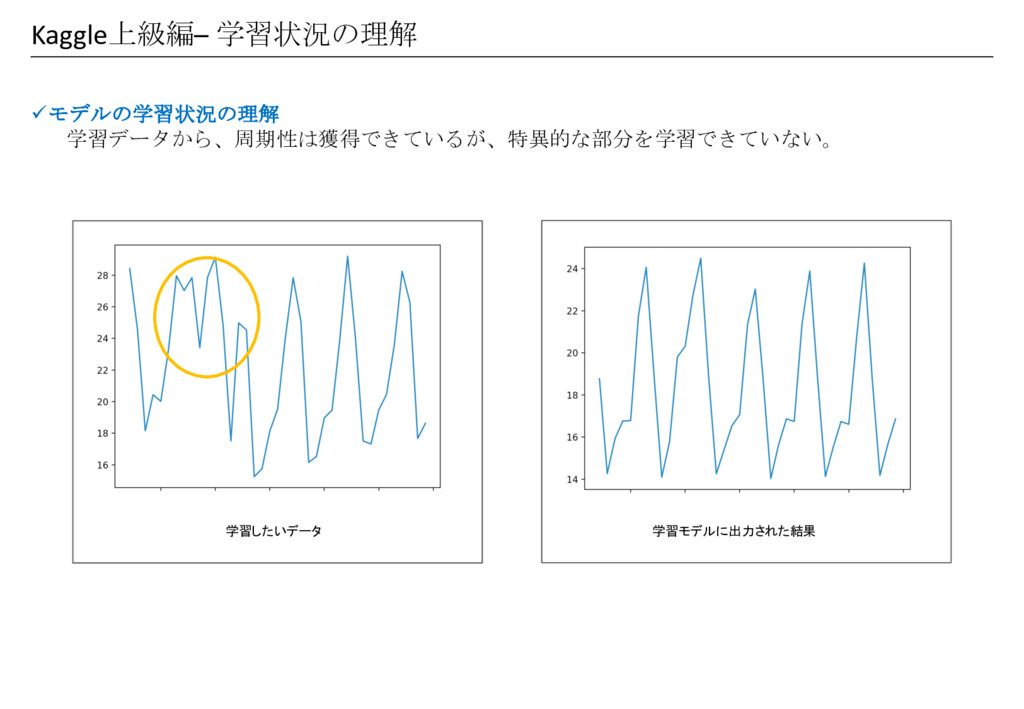
Kaggle上級編– 学習状況の理解 üモデルの学習状況の理解 学習データから、周期性は獲得できているが、特異的な部分を学習できていない。 学習したいデータ 学習モデルに出力された結果
Kaggle上級編– hyper pameter GCPやAWSでのhyper parameter tuning 機械学習モデル
End
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}