Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
情報検索の基礎#20/IntroductionToInformationRetrieval-20
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
yamasa
November 03, 2019
0
130
情報検索の基礎#20/IntroductionToInformationRetrieval-20
yamasa
November 03, 2019
Tweet
Share
Featured
See All Featured
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
120
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
31
3.1k
Dealing with People You Can't Stand - Big Design 2015
cassininazir
367
27k
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
170
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
62
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
1
440
Automating Front-end Workflow
addyosmani
1371
200k
How to Think Like a Performance Engineer
csswizardry
28
2.4k
The untapped power of vector embeddings
frankvandijk
1
1.6k
Building a Scalable Design System with Sketch
lauravandoore
463
34k
A Modern Web Designer's Workflow
chriscoyier
698
190k
Faster Mobile Websites
deanohume
310
31k
Transcript
名古屋検索勉強会 #21 ウェブ検索の基礎 t-sayama
19章の概要 • 19.1:背景と歴史 • 19.2:ウェブの特徴 • 19.3:経済モデルとしての宣伝 • 19.4:検索のユーザーエクスペリエンス •
19.5:インデックスのサイズと推定 • 19.6:ほぼ複製とシングリング
19章の概要 • ウェブが持つグラフ的な側面 • ウェブが持つ商業的な側面 • 検索エンジンが持つインデックスサイズの相対的な推定 • ほぼ同一内容のウェブページを如何に判定するか
19.1 背景と歴史
19.1 背景と歴史 • HTMLとURLによりコンテンツ作成者(未熟なものを含み)が急速に増 えていった • Webの世界では基本的に、コンテンツ作成者以外から発見され、使 われなければ価値がない • この”発見”の試みは以下の2つのカテゴリーに分かれる
• フルテキスト索引検索(Altavista、Excite、Infoeekなど) • カテゴリー分類(Yahoo!) • カテゴリー分類は、分類をノードに割り当てるためほとんど手作業に よる編集が必要 →ウェブのページが増えるのに応じてスケールすることが難しい
19.2 ウェブの特徴
19.2 ウェブの特徴 • 中央集権的な制御を持たない分散化されたコンテンツ出版 • たくさんの自然言語が使用されたコンテンツ • 文法、スタイルの膨大な多様性 • 真実、うそ、矛盾、憶測が含まれたコンテンツ
↓ これらの特徴がウェブコンテンツのインデックス付けを困難にする
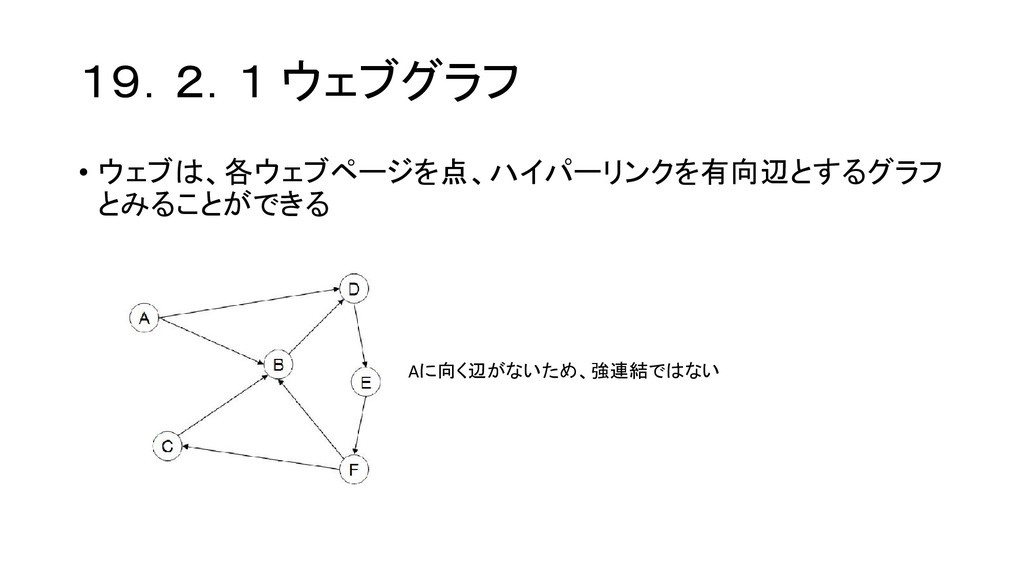
19.2.1 ウェブグラフ • ウェブは、各ウェブページを点、ハイパーリンクを有向辺とするグラフ とみることができる Aに向く辺がないため、強連結ではない
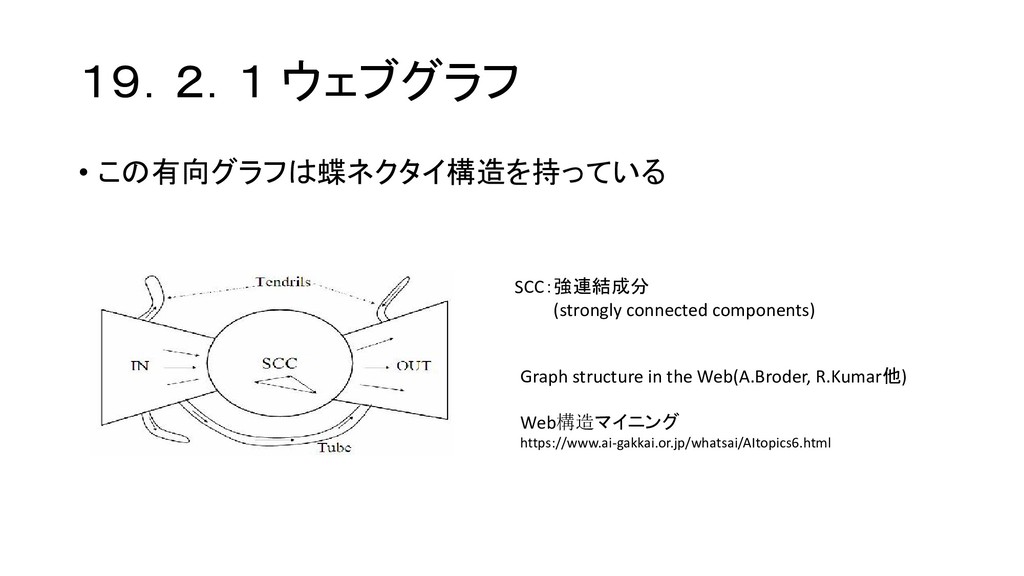
19.2.1 ウェブグラフ • この有向グラフは蝶ネクタイ構造を持っている SCC:強連結成分 (strongly connected components) Graph structure
in the Web(A.Broder, R.Kumar他) Web構造マイニング https://www.ai-gakkai.or.jp/whatsai/AItopics6.html
19.2.2 スパム 多くのコンテンツ作成者は商業的動機を持っており、 検索エンジンの検索結果が将来の購買者を獲得する重要な手段 ↓ スパムが必然的に登場する ↓ SEO
19.3 経済モデルとしての宣伝
19.3 経済モデルとしての宣伝 • ウェブの初期では、企業はウェブページ上でグラフィカルなバナー広 告を使った ・ブランディングのため ・広告の表示回数によりコストが掛かるモデル • Goto(Overture)による入札のモデルの開拓 •
スポンサー付き検索・検索広告 ・ユーザーと広告主を強く結び付けられる ・クリック単位によりコストが掛かるモデル ↓ またまた必然的にクリックスパムが現れる
19.4 検索のユーザーエクスペリエンス
19.4 検索のユーザーエクスペリエンス • ユーザートラフィックが増えれば、ウェブ検索エンジンがスポンサー から得られる売上が上がる ↓ どうすればユーザートラフィックを上げられるのか? Googleは競争相手の費用で?トラフィックを増やせる方式を見出した (Here Google
identified two principles that helped it grow at the expense of its competitors) 1. 再現率より関連性・適合率に焦点 2. 軽い(lightweight)検索結果
19.4.1 ユーザーのクエリー要求 • 情報型クエリー ・広い話題(クエリー)に対し、一般的な情報を探す • 探索型クエリー ・あるメーカーのホームページなど、特定のページを検索 • 取引型クエリー
・ある商品を購入するサイトやホテルの予約サイトなどを検索 ↓ 分類としては分けられるが、実際に識別するのは難しい 検索エンジンは上記のクエリーの適合状況より、競合とのインデックス の大小に注意を払う必要があった(次節への前振り)
19.5 インデックスのサイズと推定
19.5 インデックスのサイズと推定 • ある2つの検索エンジンのインデックスのサイズついて比較する場 合、以下の2つの理由から比較は不正確である ・検索エンジンはインデックス付けされていないページを返すことができる ・検索エンジンはそれぞれ独自の層や分類分けをしており、 すべてのインデックスが捜査されるわけでなない End Of
Size Wars? Google Says Most Comprehensive But Drops Home Page Count https://www.searchenginewatch.com/2005/09/26/end-of-size-wars-google-says-most-comprehensive-but-drops-home-page-count/
19.5 インデックスのサイズと推定 • 前ページの課題があるが、 2つの仮定により、相対的なインデックスサイズを推定する 1)各検索エンジンが部分集合として選択するウェブの世界が 有限であること 2)各検索エンジンが一様に選ばれた部分集合を選ぶこと
19.5 インデックスのサイズと推定 1.検索エンジンE1のインデックスからランダムなページを選ぶ 2.検索エンジンE2に「1.」のページがあるかを調べる 1’.検索エンジンE2のインデックスからランダムなページを選ぶ 2’.検索エンジンE1に「1’.」のページがあるか調べる 3.「1.」~「2’.」を繰り返し、E1のページがE2に含まれる割合xと E2のページがE1に含まれる割合yを求める x y
E E E y E x 2 1 2 1 i E を検索エンジン Ei i E のインデックスサイズとすると
19.6 ほぼ複製とシングリング
19.6 ほぼ複製とシングリング • ウェブページはコンテンツの複数のコピーを含んでいる ・ある評価によると40%がほかのページ複製 ・さらにその多くが単純な複製(ミラーリングなどを含む) • これらの複製をインデックス付けから回避する方法 ・単純な複製の場合、ウェブページのフィンガープリントを見る ・ほぼ複製(near
duplication)の場合、シングリング(shingling)が有効 シングリングの定義 ・正整数kと文書dの一連の用語において、dのkシングリングを dの全てのk個の用語の引き続きの集合とする
19.6 ほぼ複製とシングリング 例) dの文書を以下としたとき ・「a rose is a rose is
a rose」 4シングリング(k=4)の各シングルは、以下の通り ・「a rose is a」 ・「rose is a rose」 ・「is a rose is a」
19.6 ほぼ複製とシングリング • ある2つのシングルの集合がほぼ同じであれば、 それらのウェブページはほぼ複製のはずである • ただし、全てのウェブページに対し、全てのシングリングを行うのは 非常に大きな計算量が必要となる ↓ シングリングの計算を効率化する必要がある
19.6 ほぼ複製とシングリング 1.ジャカール係数(p.54参照)により、 2つの集合の重なりの度合いを測り、 一定の閾値(0.9など)を超えている場合にほぼ重複とする ↓ 文書比較の手法であり、まだ計算量は大きい そこでシングルのスケッチでジャカール係数を求める
j d S を文書 j d のシングルの集合とした場合、 2つの集合間のジャカール係数は 2 1 2 1 2 1 / , d S d S d S d S d S d S J
19.6 ほぼ複製とシングリング 2.各シングルをハッシュ値にマッピングする j d H を
j d S から計算したハッシュ値の集合とする 3.「2.」を更にランダムな整数値から整数値への置換を行う (これにより後述する最小の整数がランダムに決定される) j d を j d H からランダムに置換した整数値の集合とする
19.6 ほぼ複製とシングリング 4.「3.」の中で最小の整数を選択し、2つの集合間で比較する 5.「3.」~「4.」を200回繰り返し、一致する確率を求める =ジャカール係数となる ※「3.」の置換は都度変更する を の中の最小値とする
j d
19.6 ほぼ複製とシングリング さらなる効率化のために ・似通った文書をクラスター化する (17.2節) ・スケッチ中の をソートし、さらにシングリングして、 超シングルの集合を作成し、重なりを測る
参考文献 • https://nlp.stanford.edu/IR-book/html/htmledition/web-search-basics-1.html • https://nlp.stanford.edu/IR-book/ppt/ • ウェブ構造マイニング https://www.ai-gakkai.or.jp/whatsai/AItopics6.html • シングリング
https://www.cs.princeton.edu/courses/archive/spring05/cos598E/bib/Princeton.pdf スケッチを作成するときにハッシュに対して行う操作(π)を200の剰余とするとスッキリ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}