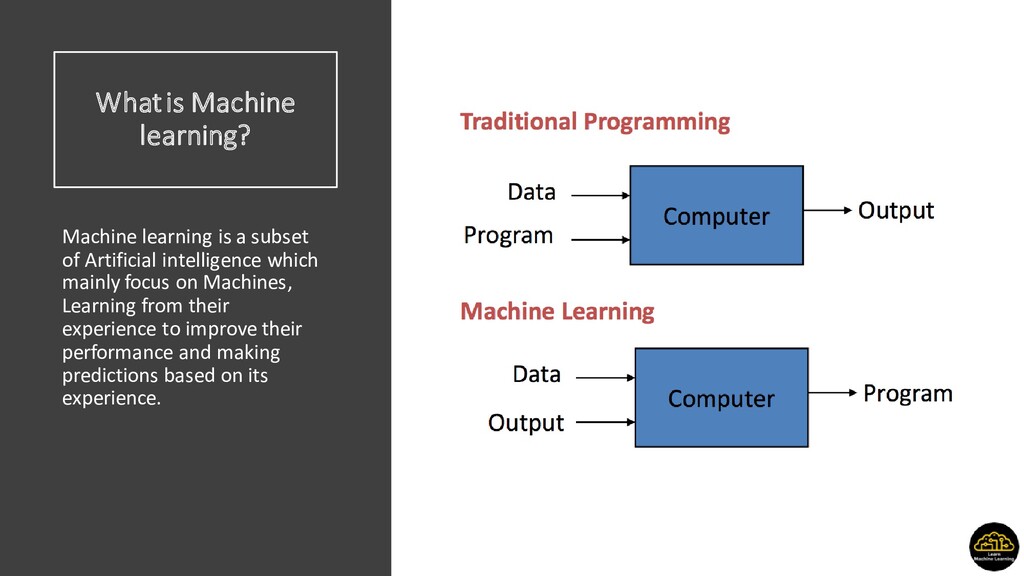
Artificial intelligence which mainly focus on Machines, Learning from their experience to improve their performance and making predictions based on its experience.
or the machines to make data-driven decisions rather than being explicitly programmed for carrying out a certain task. • These programs or algorithms are designed in a way that they learn and improve over time when are exposed to new data. • In simple terms it find the patterns in the data.
explicitly. Even if we had a good idea about how to do it, the program might become really complicated. Scalability - Ability to perform on large amounts of information.
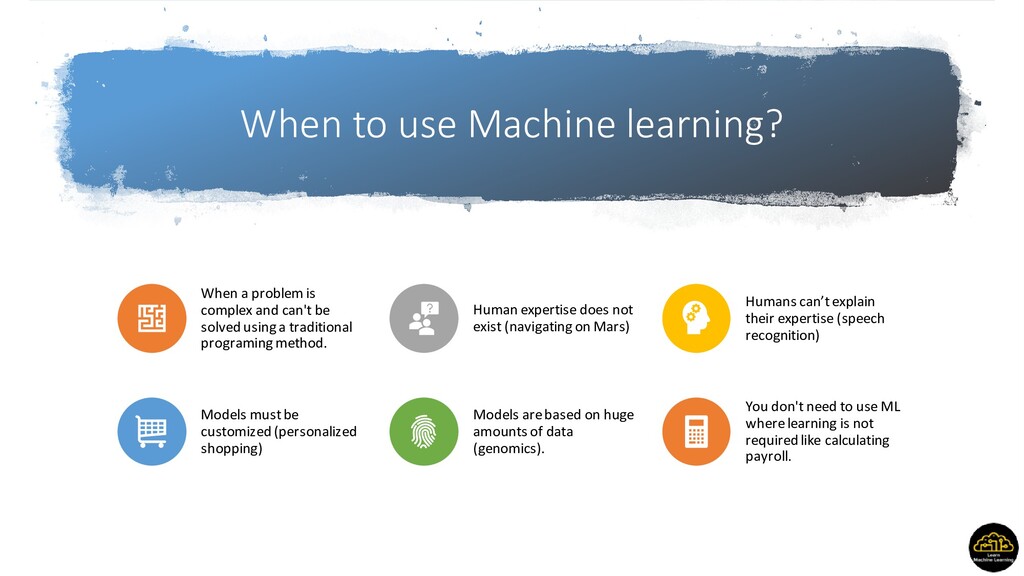
and can't be solved using a traditional programing method. Human expertise does not exist (navigating on Mars) Humans can’t explain their expertise (speech recognition) Models must be customized (personalized shopping) Models are based on huge amounts of data (genomics). You don't need to use ML where learning is not required like calculating payroll.
while commuting • Video surveillance • Social media services • Email span and malware filtering • Online customer support • Search engine • Personalization • Fraud detection
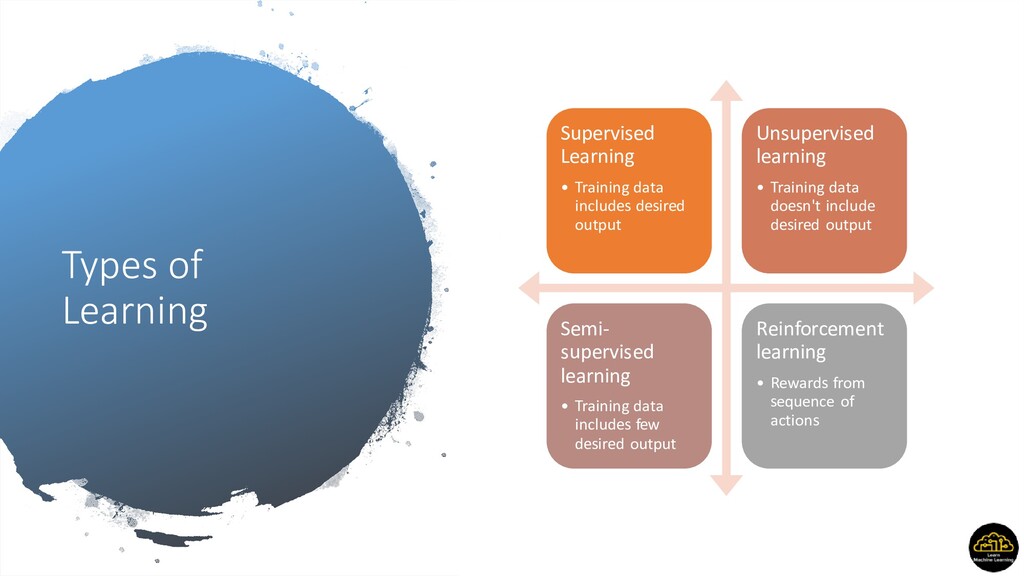
output Unsupervised learning • Training data doesn't include desired output Semi- supervised learning • Training data includes few desired output Reinforcement learning • Rewards from sequence of actions
• The goal of supervised learning is to find an unknown function which maps the relation between input and output. • Y = f(X) + e; f(X) = function, Y = output, X = input and e = irreducible error. • Using the input data we generate a function which maps the input and output. • 2 types of supervised learning • Regression • Classification
of unsupervised learning is to model the underlying structure or hidden structure or distribution in the data in order to learn more about the data. • Here algorithms are left to their devises to discover and present the interesting structure in the data. • Two types of Unsupervised learning algorithms • Clustering • Association
and unsupervised learning. • Mostly we will have a combination of labeled and unlabeled data. • You can use unsupervised learning to discover and learn the structure in the input data. • You can also use supervised learning to make predictions of unlabeled data using transfer learning or classic algorithms techniques and feed them back to the supervised learning algorithm to improve the performance.
learning the target function that maps the input and output. Y = f(X) + e • Here the function f which maps the relation between input and output is generally unknown. We estimate f based on the observed data. • 2 ways to estimate f • Parametric methods • Non-Parametric methods
set of parameters of fixed size. No matter how much data you throw it doesn’t change its mind. Examples Linear regression Logistic regression Linear SVM Simple NN's
these methods are highly constrained to the specified form Limited complex: These methods are more suited to simpler forms Poor fit: In practice the methods are unlikely to match the underlying mapping function.
and have no prior knowledge about it or when you don't want to worry about the feature selection. No of parameters is infinite and complexity of the model grows with the increase in training data. Examples KNN Decision trees Kernal SVM
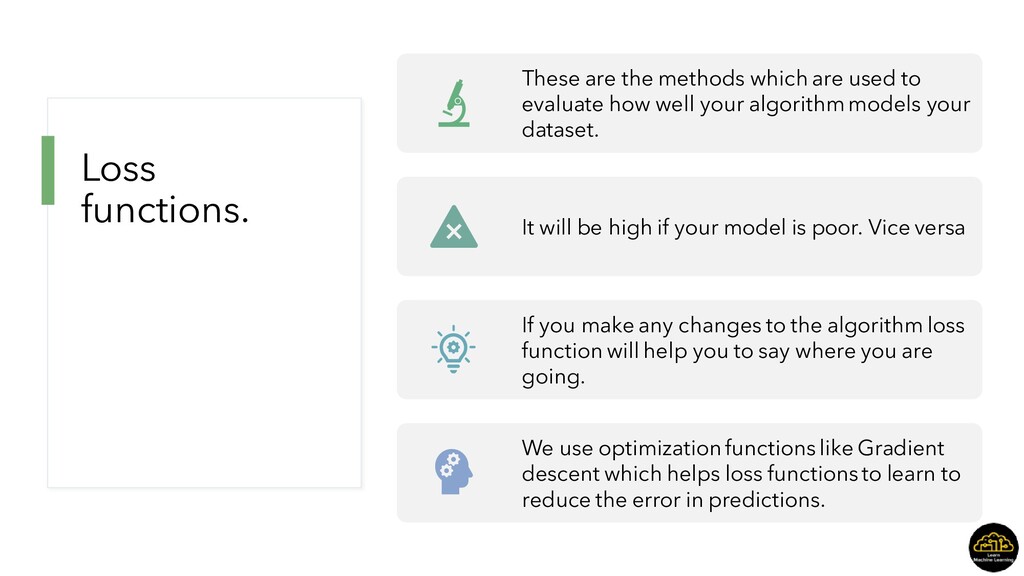
evaluate how well your algorithm models your dataset. It will be high if your model is poor. Vice versa If you make any changes to the algorithm loss function will help you to say where you are going. We use optimization functions like Gradient descent which helps loss functions to learn to reduce the error in predictions.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}