Vilas Research & Sir Frederic Bartlett Professor University of Wisconsin-Madison @GernsbacherLab Greetings, everyone. I’m Morton Ann Gernsbacher. I’m a professor in the Psychology Department. I’ve been here at the UW for 25 years and before that I was on the faculty at the University of Oregon for 10 years. I did my PhD work at the University of Texas in the early 80s.
Vilas Research & Sir Frederic Bartlett Professor University of Wisconsin-Madison @GernsbacherLab I’ve become a proponent of Open Data and Open Stimuli, and more generally replicability and transparency in research. Of course, we all know that
replicable. I teach an undergraduate Research Methods course and rather than talking about inter-item reliability and part-whole reliability and the other flavors of reliability, I cut right to change and teach that replication indexes reliability. Perhaps what feels a bit new is the
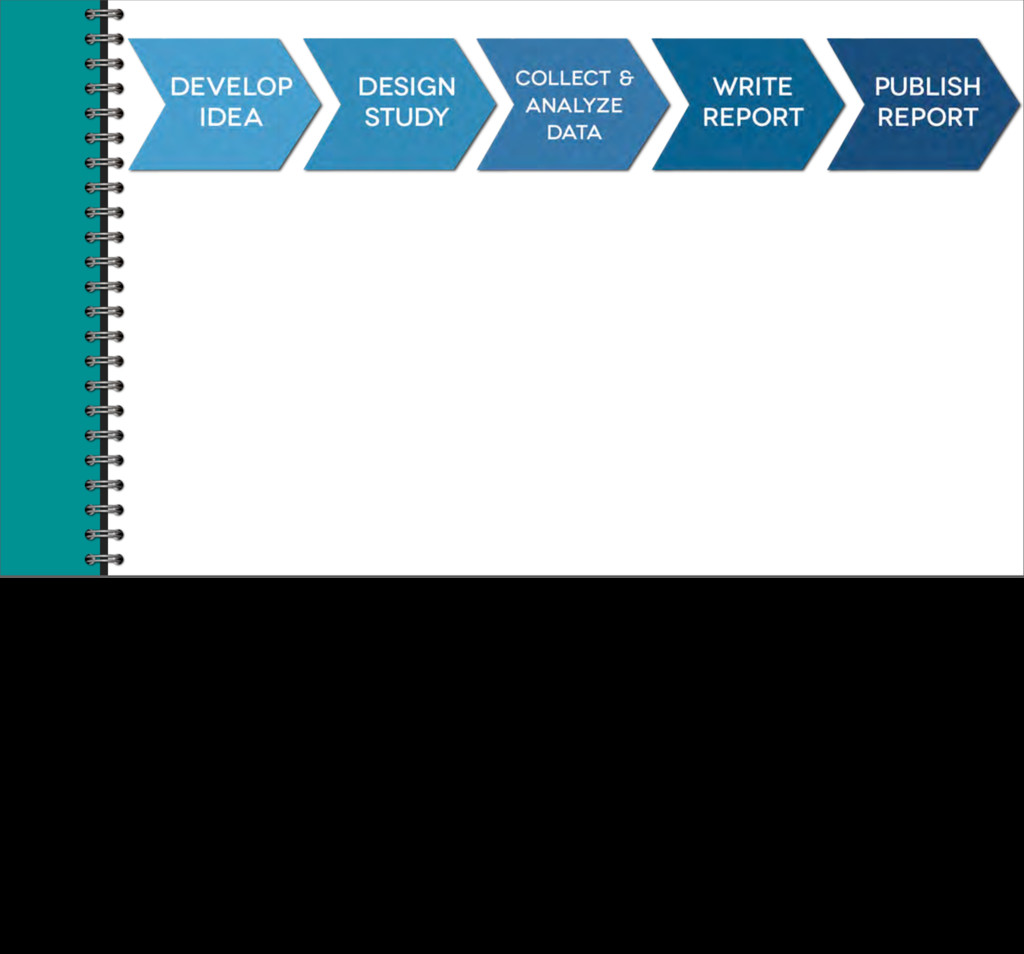
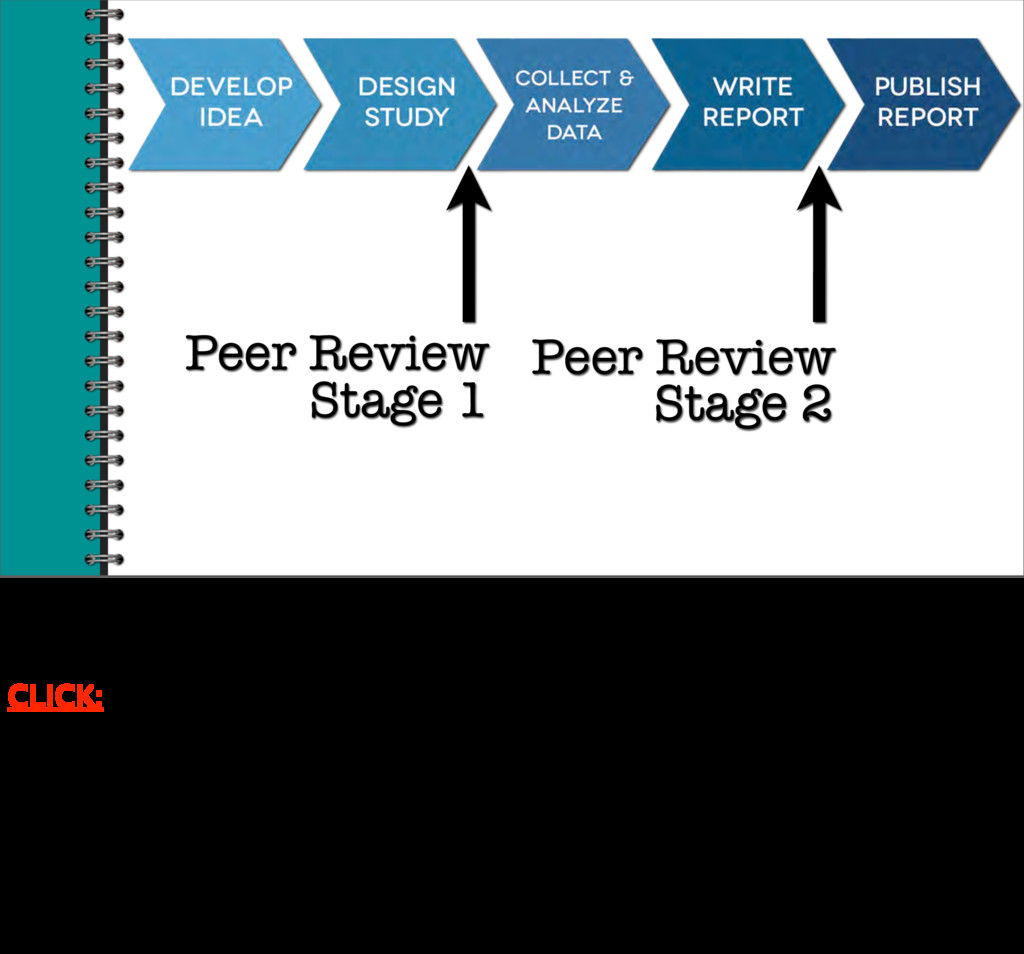
idea, collect and then analyze data, write a research report, and then publish that report. What’s different about pre-registration, and specifically, Registered Report journal articles, is that instead of submitting our report to
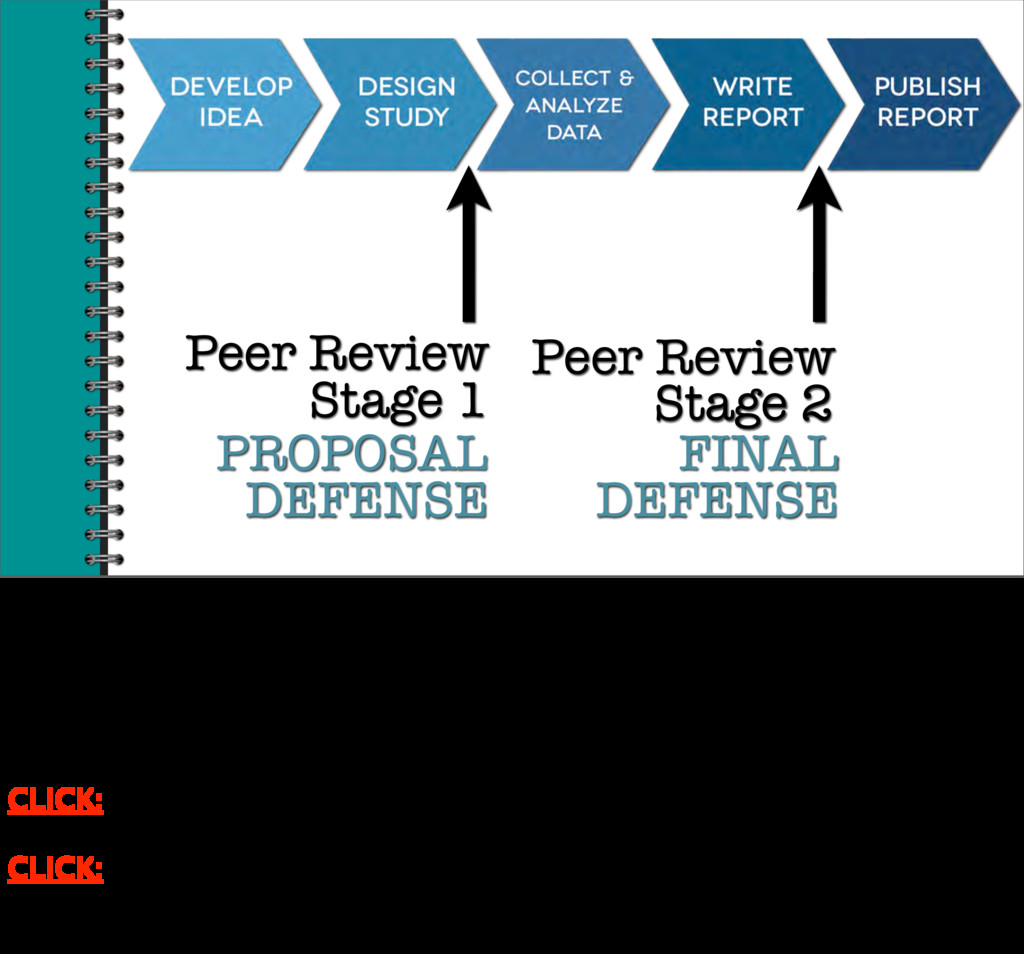
only after we’ve collected and analyzed our data, we also submit our report to peer review CLICK: BEFORE we collect and analyze our data. Steve Lindsay will explain more about Registered Reports in his presentation later in our session. But two points I want to stress now are first, that researchers can pre- register their study,
they’re not planning to submit to a journal that offers registered reports, by using websites, such as Open Science Framework and AsPredicted.org. And second, most of us are already familiar with the process of pre- registration.
FINAL DEFENSE It’s the way we wrote our dissertations, masters theses, and senior theses. We registered, and defended, our hypotheses with our committee during our CLICK: proposal defense. And, then later, during our CLICK: final defense, we defended our results and interpretation of the results.
without making our experimental materials available to reviewers – and often available to readers, too, in the appendices of our published paper. Just providing an example stimulus or two in the body of the manuscript was NOT enough.
of our experimental materials available to reviewers during peer review and to readers forever after, by using our labs’ websites rather than the journals’ limited printed pages,
my experimental materials on my lab’s website, although I’ve also begun posting additional copies on repositories, such as the Open Science Framework, which guarantees 50 years of longevity, which is more than I can promise on my lab’s website.
I send my data to other colleagues to check, and they send me their data to check. We try to reproduce each other’s reported results prior to each of us posting our data -- or submitting our manuscripts. A fourth step toward greater research transparency is
reproducibility through transparency. We can pre-register our study’s goals and analysis plans; we can make our study’s research materials available to everyone; we can make our study’s data available to everyone; and we can make our final research report available to everyone.
system may be a major barrier for achieving transparency in research.” UNQUOTE Similarly, this past September, the Science Ministers of Canada, France, Germany, Italy, Japan, the U.K., and the U.S., aka:
workshops to QUOTE “Recommend specific solutions in policy, … incentives and requirements that would facilitate Open Science.” UNQUOTE But why wait for an august agency to offer recommendations?
perhaps better put Investigator-enhancement reasons for Open Science, and in particular Open Data and Open Materials. I’ll begin by describing a couple of the QUOTE “selfish reasons to work reproducibly” articulated by Florian Markowetz in a 2015 article in Genomic Biology. Markowetz begins by relating the headline
in The New York Times in the summer 2011. The New York Times article describes how to scientists had discovered QUOTE “lethal data analysis problems in a series of high-impact papers by breast cancer researchers from Duke University. UNQUOTE. As Markowetz notes, the errors the two scientists identified QUOTE “could have easily been spotted by any co-author before submitting the paper.
spot-checked on a standard laptop. You do not have to be a statistics wizard to realize that patient numbers differ, labels got swapped or samples appear multiple times with conflicting annotations in the same data set.” UNQUOTE But no one had noticed them. I agree with Markowetz that had the Duke cancer researchers
done as I’ve begun to do -- swap data checking with another lab, these errors would have been caught prior to publication. But they weren’t and, as the New York Times reported, bright promise in cancer testing fell apart. Markowetz also notes that making one’s data, materials, and methods makes it easier
all my data, materials, analysis code, and the like packaged in such a way that others can see them allows me to also easily access them. Another selfish reason is that research that is publicly documented is more likely to be
mistakes. Keep your project organized, name your files and directories in some informative way, store your data and code at a single backed-up location. Don’t spread your data over different servers, laptops and hard drives. At the lowest level, working reproducibly just means avoiding beginners’ mistakes. Keep your project organized, name your files and directories in some informative way, store your data and code at a single backed-up location. Don’t spread your data over different servers, laptops and hard drives.
learn some tools of computational reproducibility. In general, reproducibility is improved when there is less clicking and pasting and more scripting and coding. To achieve the next levels of reproducibility, you need to learn some tools of computational reproducibility. In general, reproducibility is improved when there is less clicking and pasting and more scripting and coding.
learn some tools of computational reproducibility. In general, reproducibility is improved when there is less clicking and pasting and more scripting and coding. Merkowitz recommends doing analyses in R or Python and documenting analysis using knitR or IPython notebooks. Because these tools help merge descriptive text with analysis code into dynamic documents that can be automatically updated every time the data or code change.
system like git on a collaborative platform such as GitHub. Finally, if you want to become a pro, learn to use docker, which will make your analysis self- contained and easily transportable to different systems. As a next step, Merkowitz recommends learning how to use a version- control system like git on a collaborative platform such as GitHub. Finally, if you want to become a pro, learn to use docker, which will make your analysis self-contained and easily transportable to different systems. UNQUOTE I admit that I’m at level 2.
some informative way, store your data and code at a single backed-up location. Don’t spread your data over different servers, laptops and hard drives. ... learn some tools of computational reproducibility. I keep my project organized, I name my files and directories in some informative way, I store my data and code at a single backed-up location. I don’t spread my data over different servers, laptops and hard drives. And I’ve learned some tools of computational reproducibility. I’m not yet at the github or docker level, but plan to move there soon.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Morton Ann Gernsbacher @GernsbacherLab www.GernsbacherLab.org [email protected] Thank you.](https://files.speakerdeck.com/presentations/483e589b6edb4511bee7555bef3fc47f/slide_42.jpg){kind=link}