本資料は CNDT2023 の登壇資料です
- CFP
- Google Docs版
noteでは2023年9月に本番環境の全アプリケーションがKubernetes(EKS)で稼働させることができました。私たちはただKubernetesへの移行だけではなく、長年運用されてきたレガシーインフラの課題を解決するための多くの改善を併せて実施しました。特に、アプリケーションのパフォーマンスを維持するためのロードテスト、オブザーバビリティの強化、コンテナをデプロイするためにオートスケールするGithubActionsランナーを構築した事例、Kubernetesの仕組みをフルに活用し開発環境の即時展開を可能にしたシステムの事例など、このプロジェクトを通じて遭遇した課題やそれを乗り越えるための施策を実例を交えて詳細に解説します
{kind=link}
{kind=link}
{kind=link}
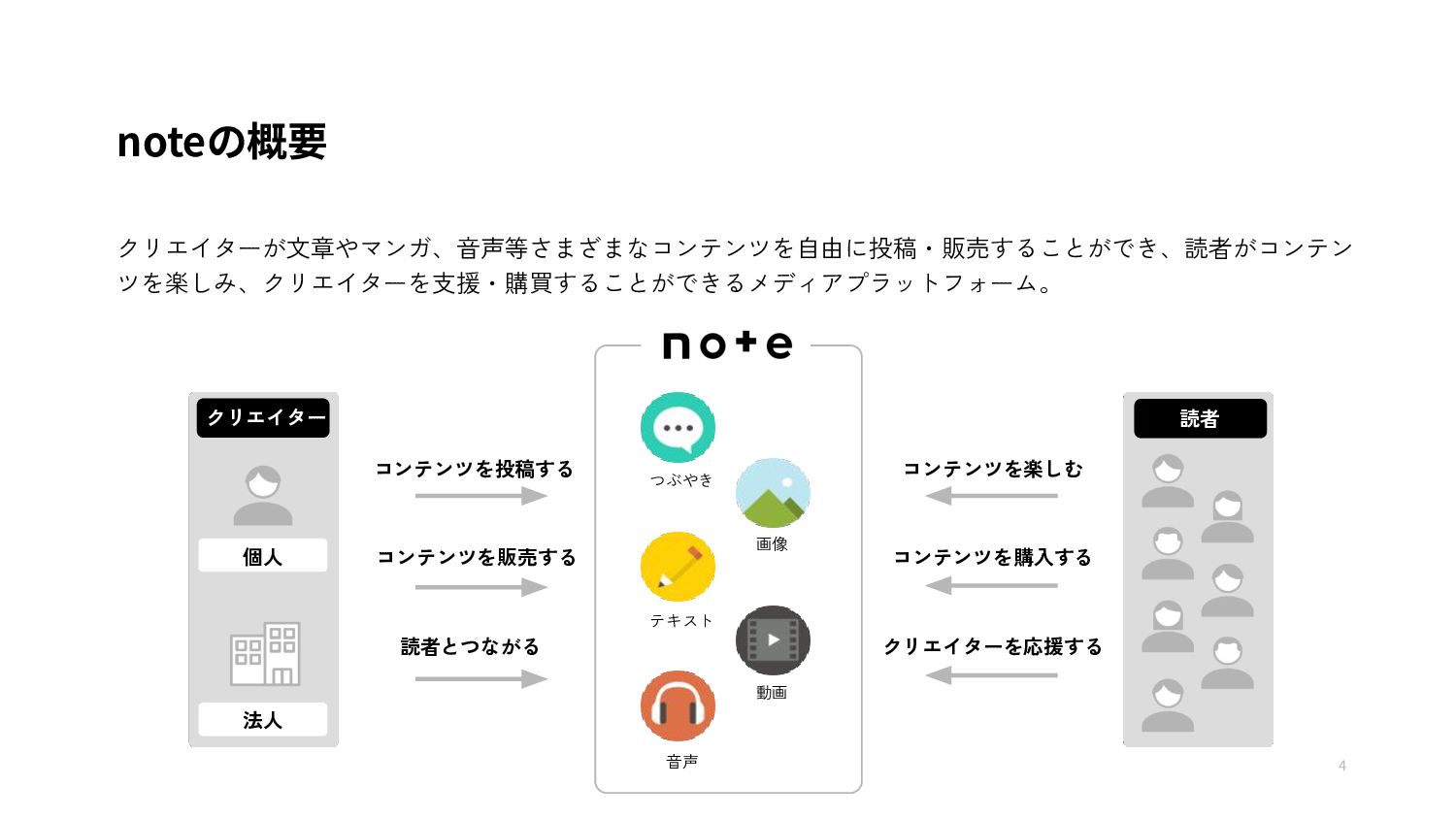{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
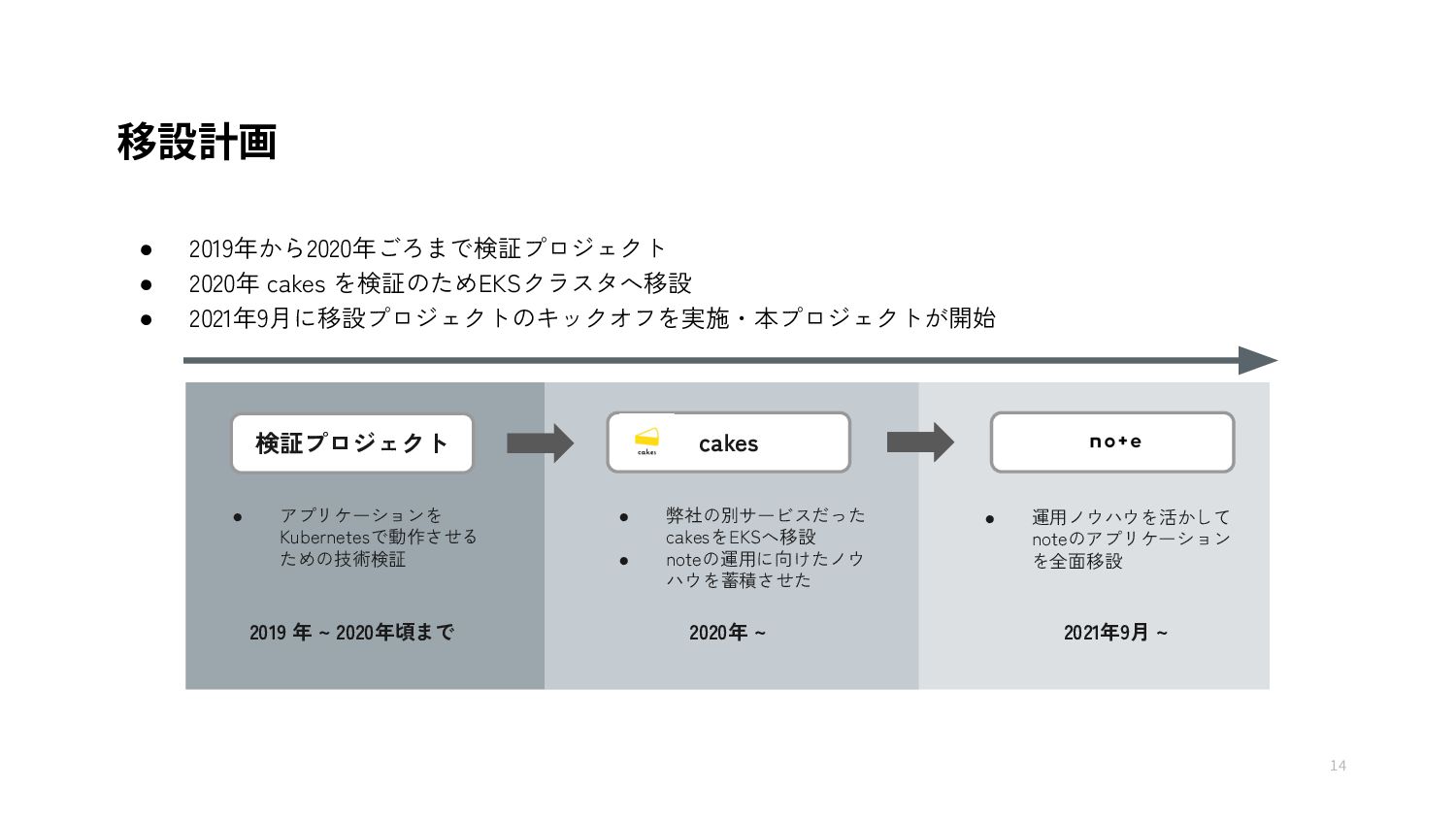
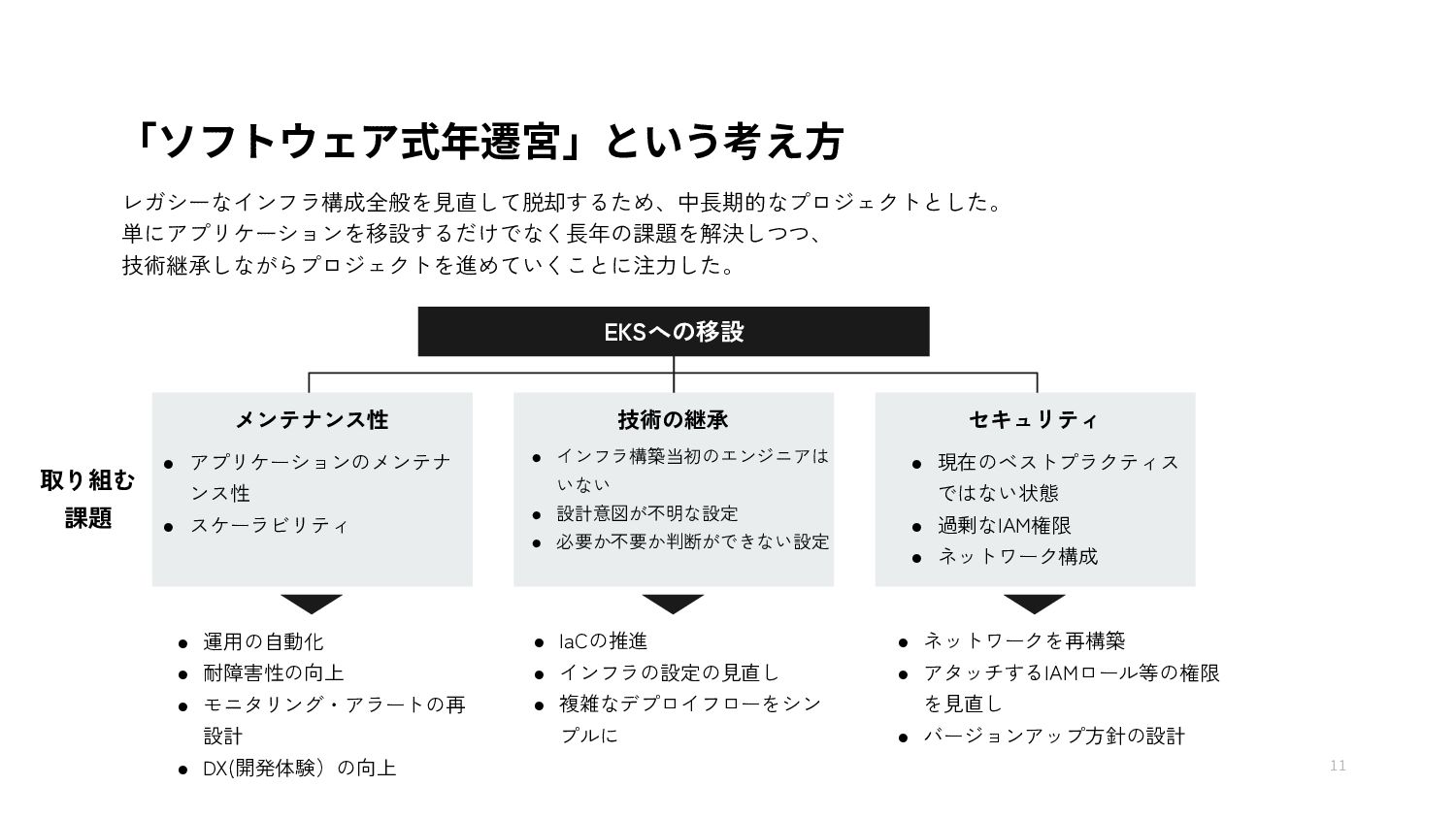{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
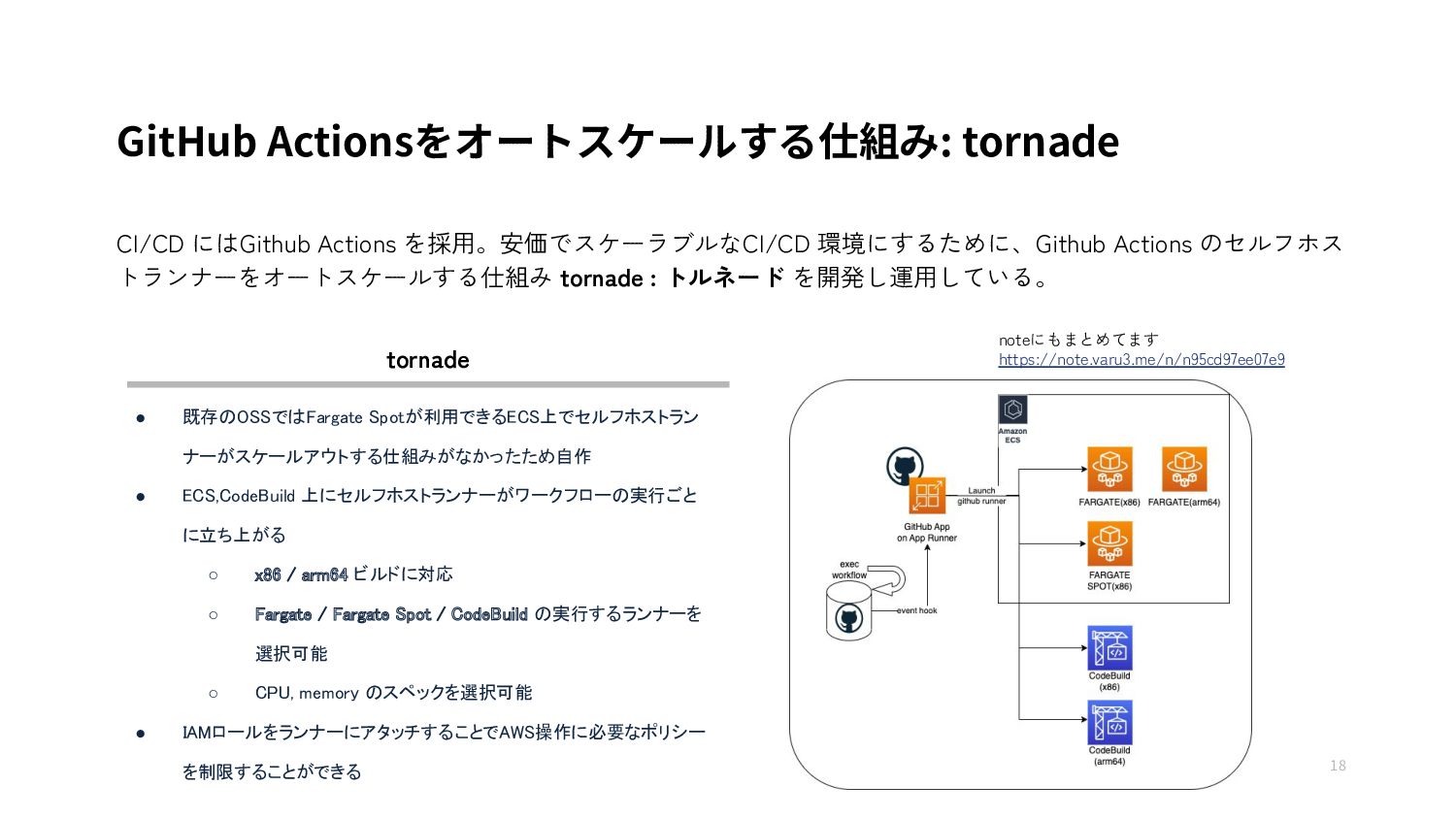{kind=link}
{kind=link}
{kind=link}
{kind=link}
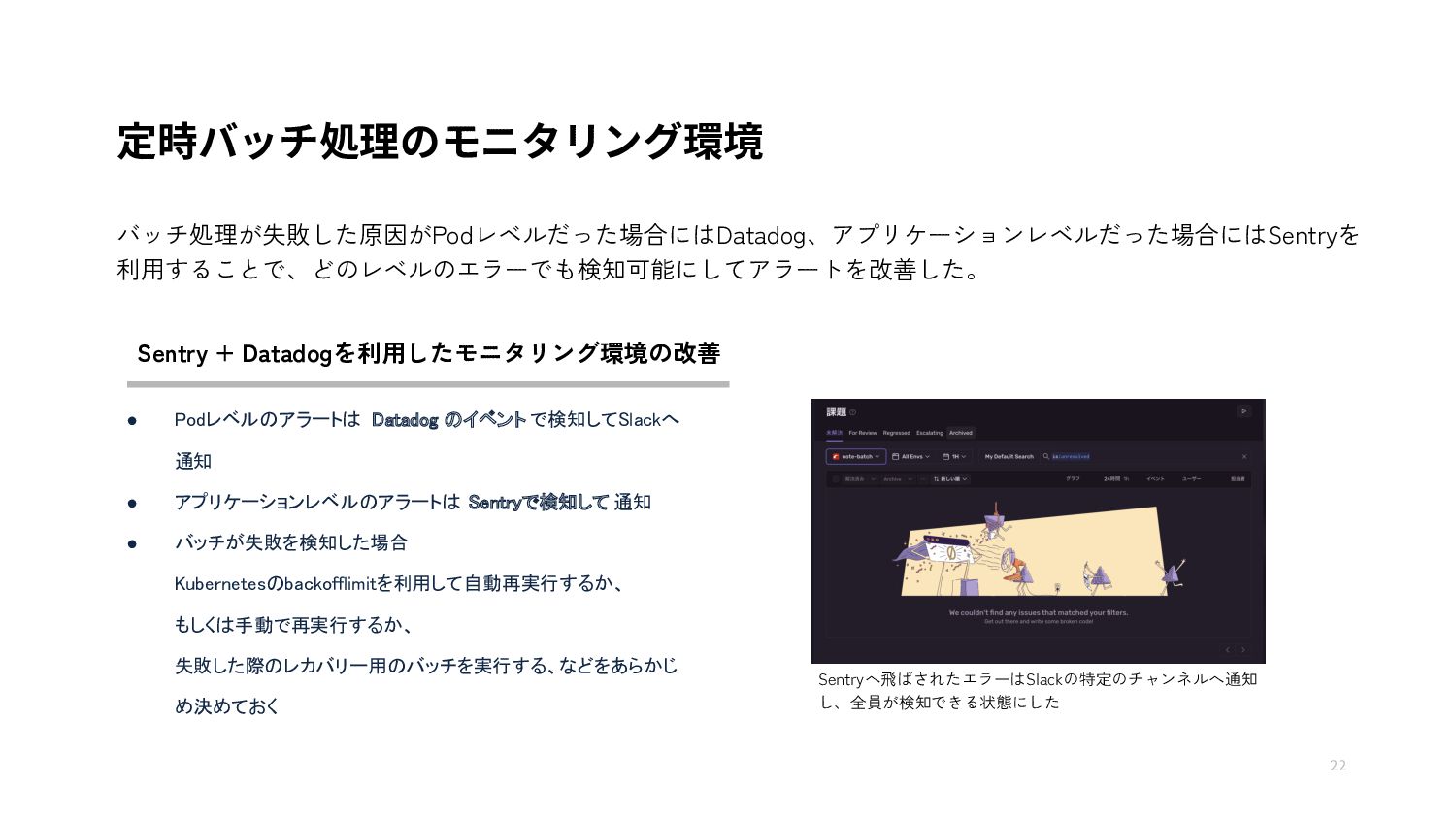{kind=link}
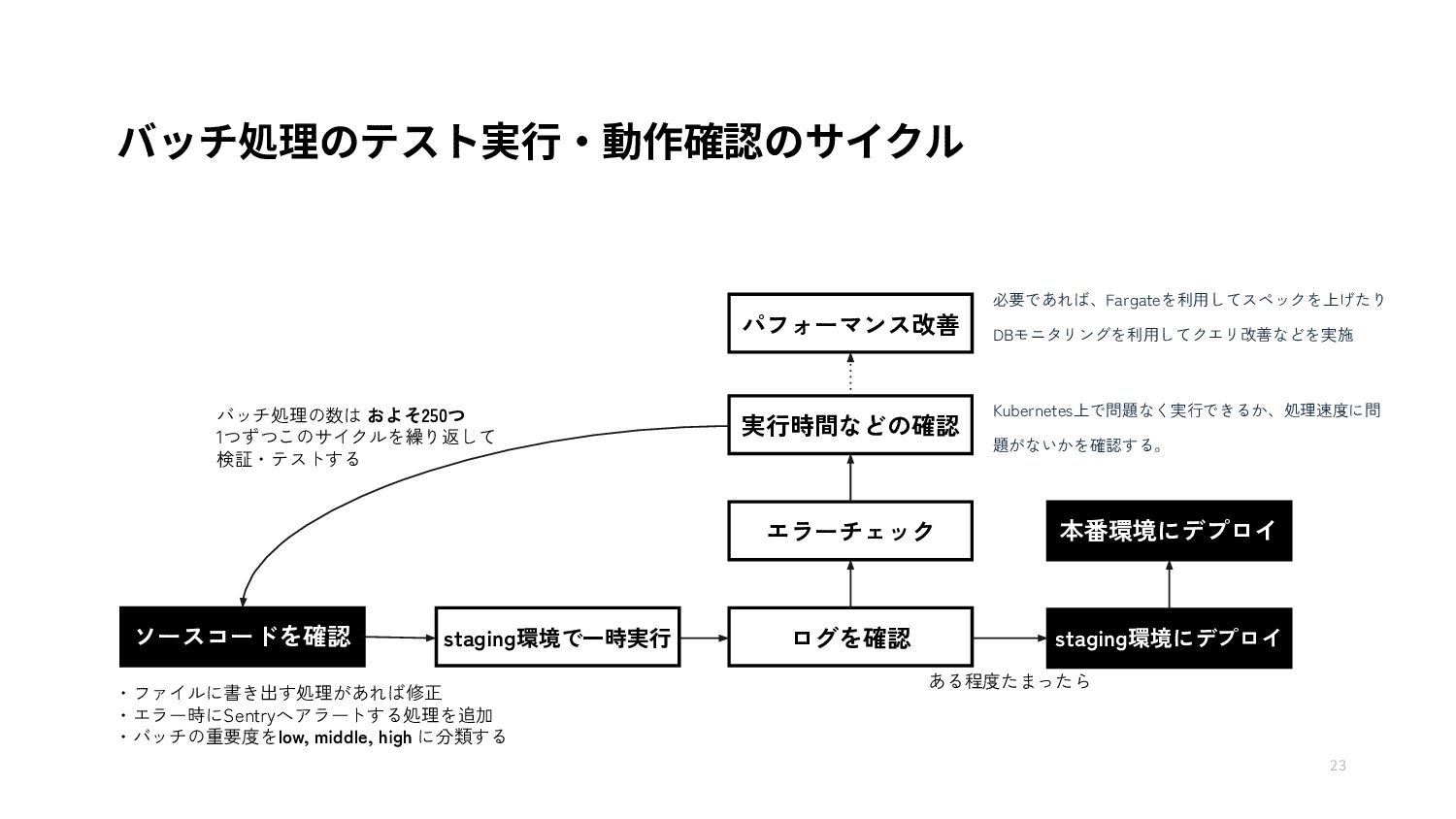{kind=link}
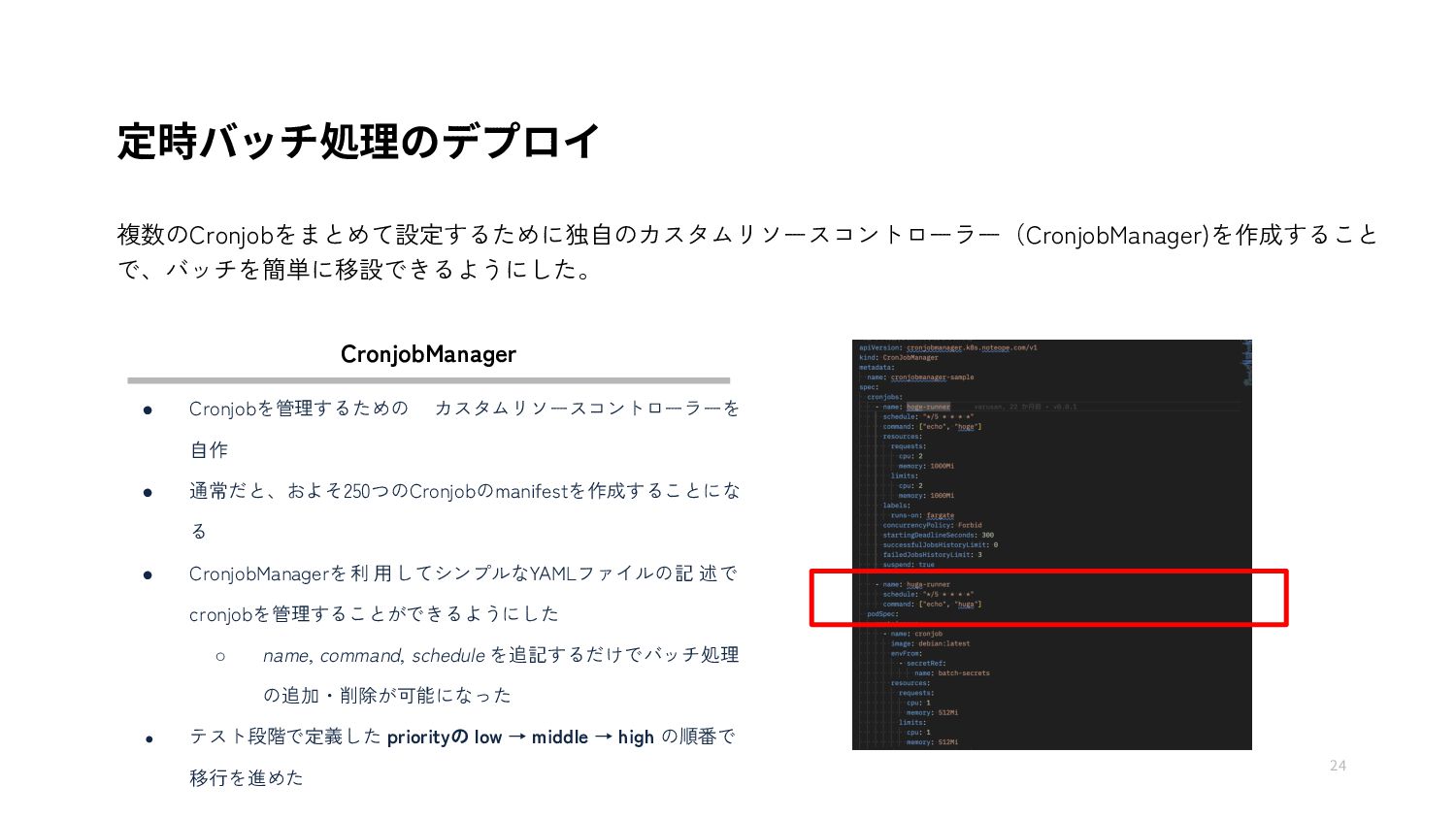{kind=link}
{kind=link}
{kind=link}
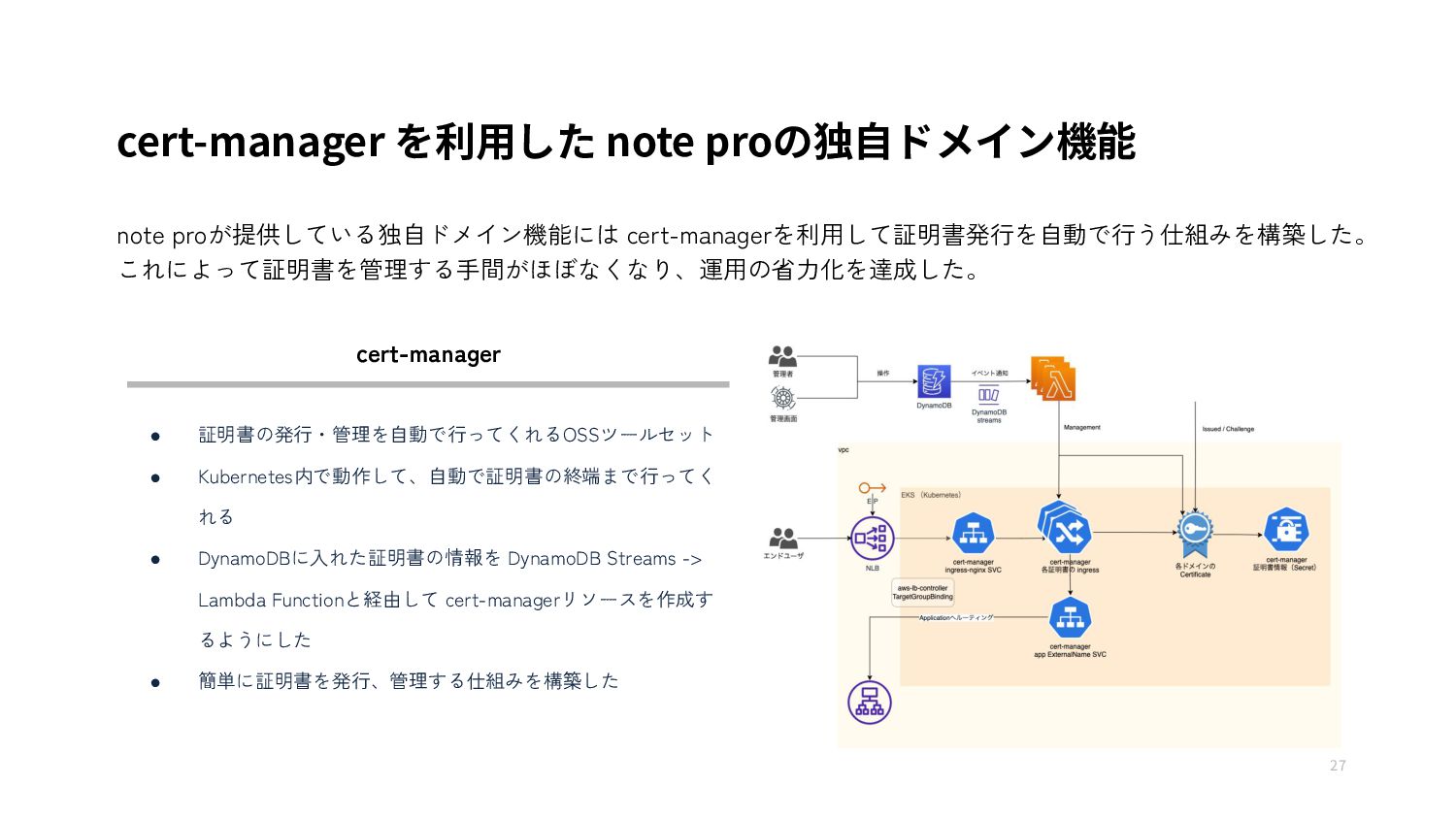{kind=link}
{kind=link}
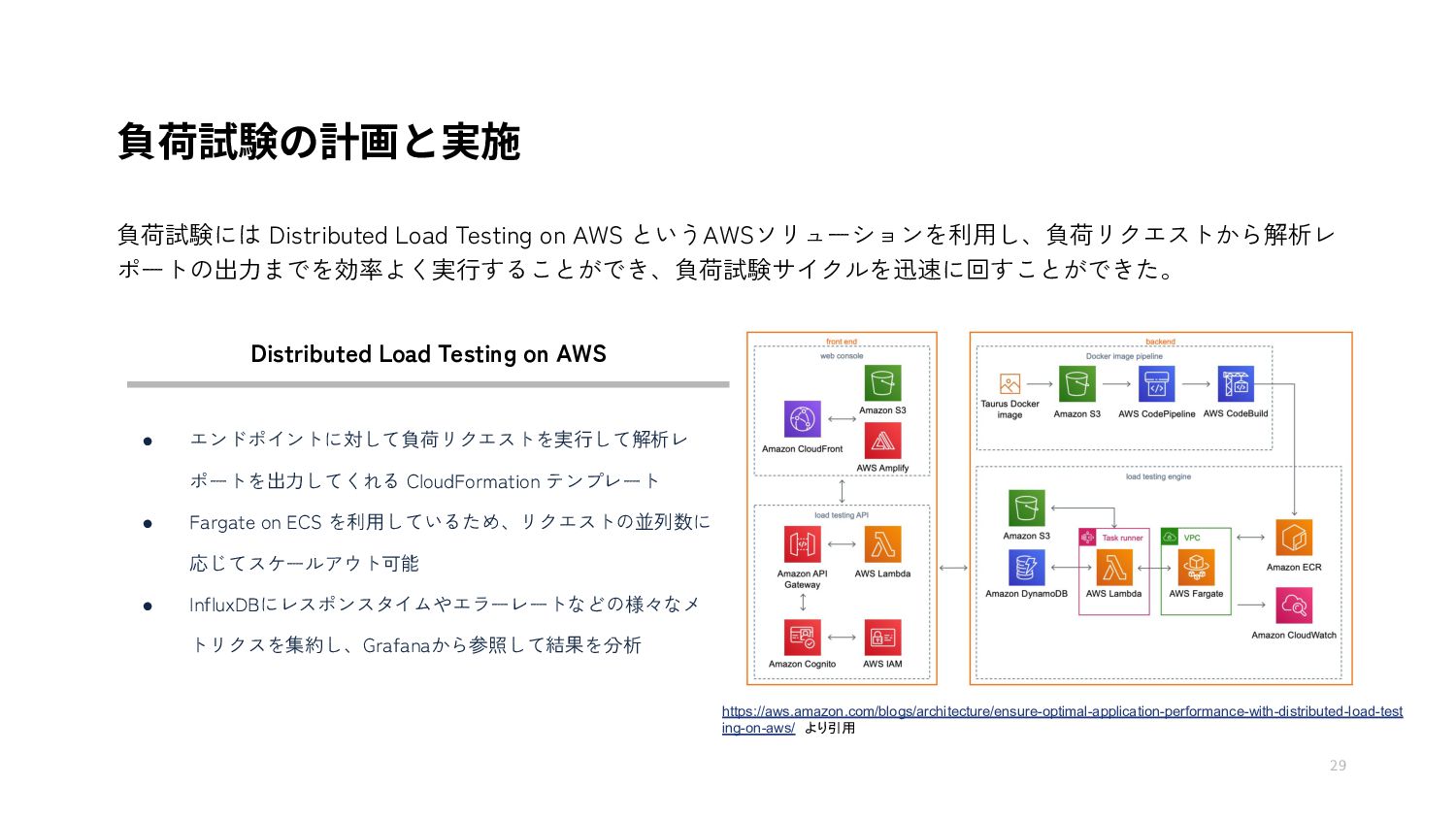{kind=link}
{kind=link}
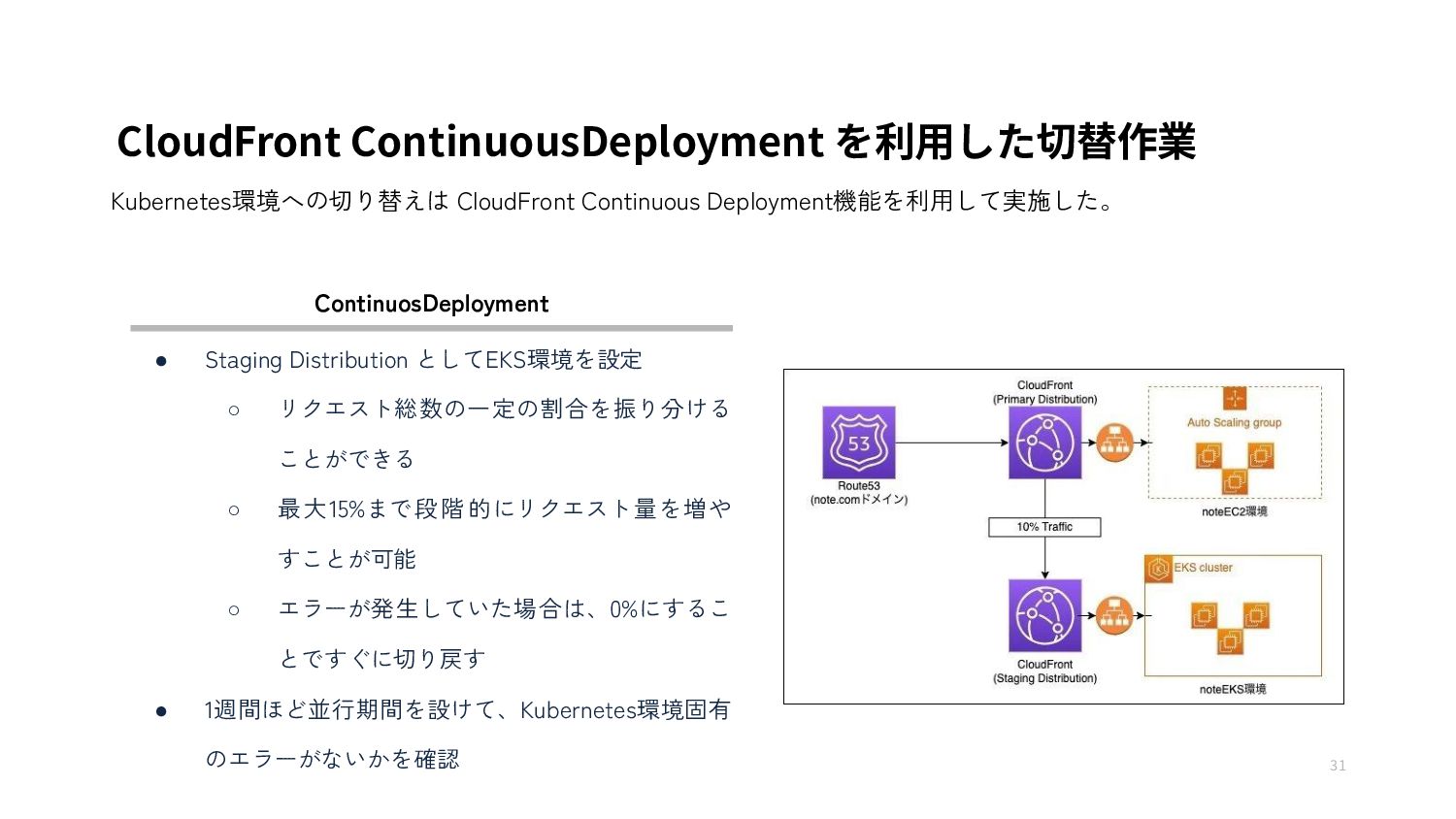{kind=link}
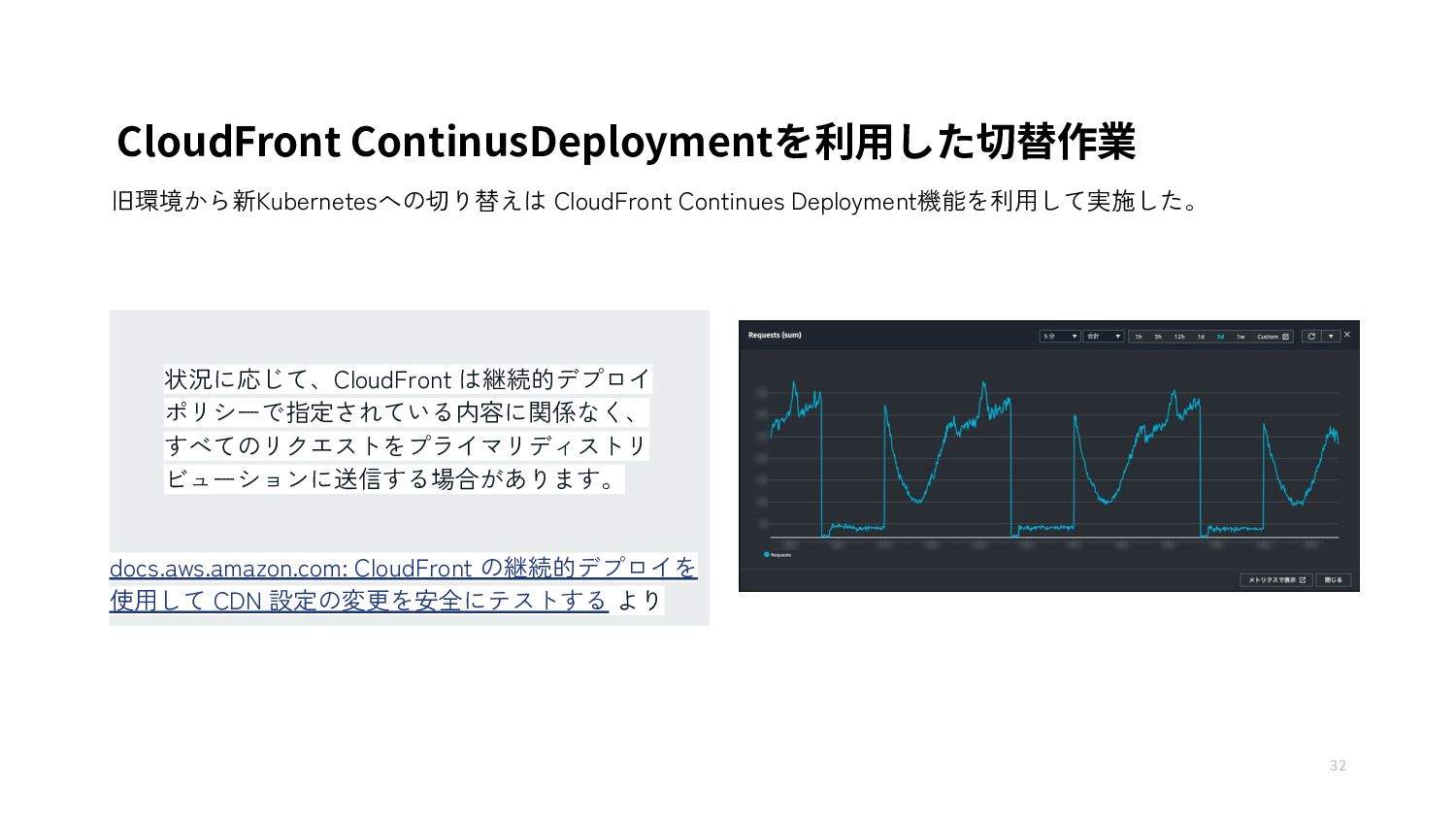{kind=link}
{kind=link}
{kind=link}
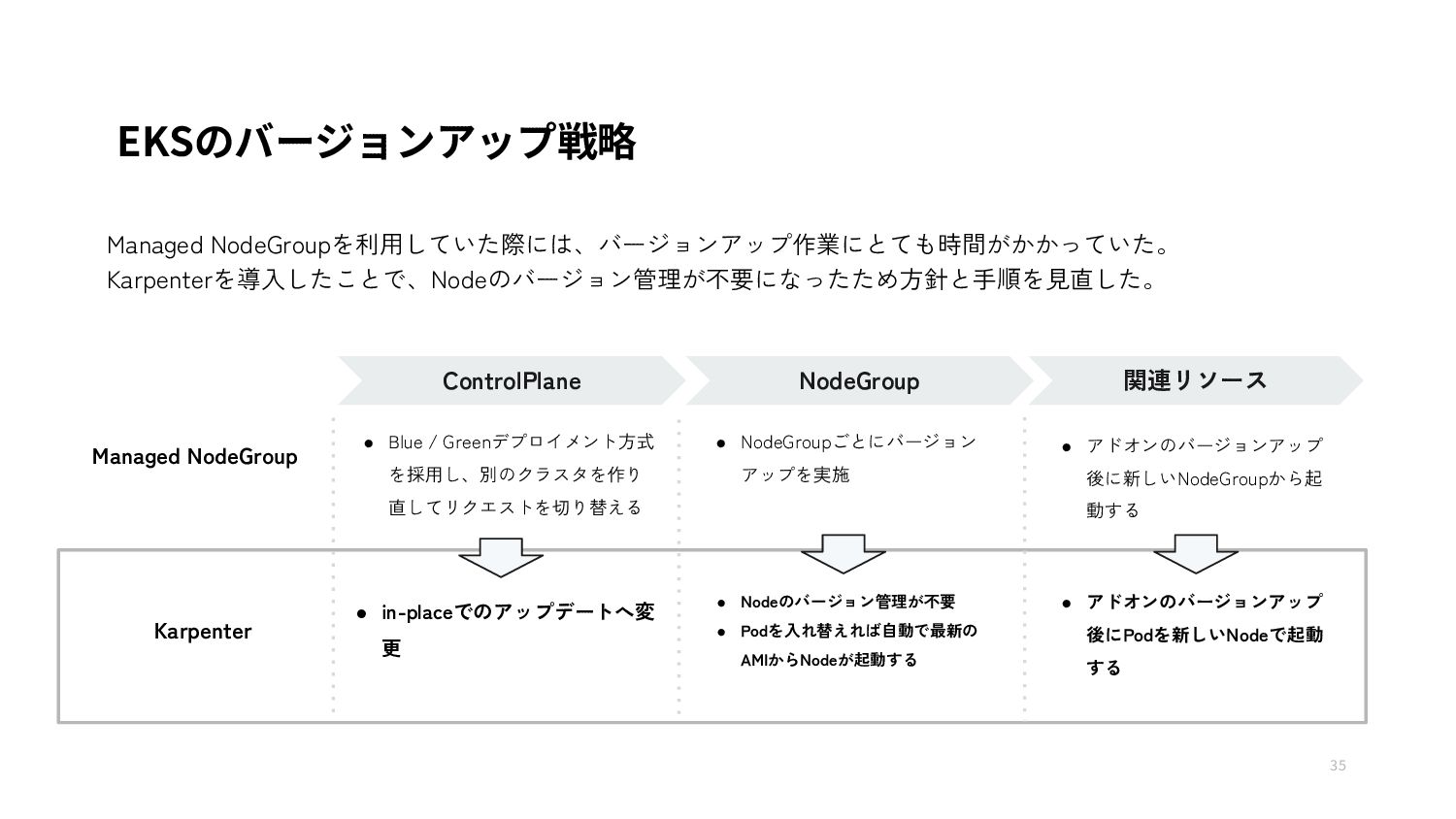{kind=link}
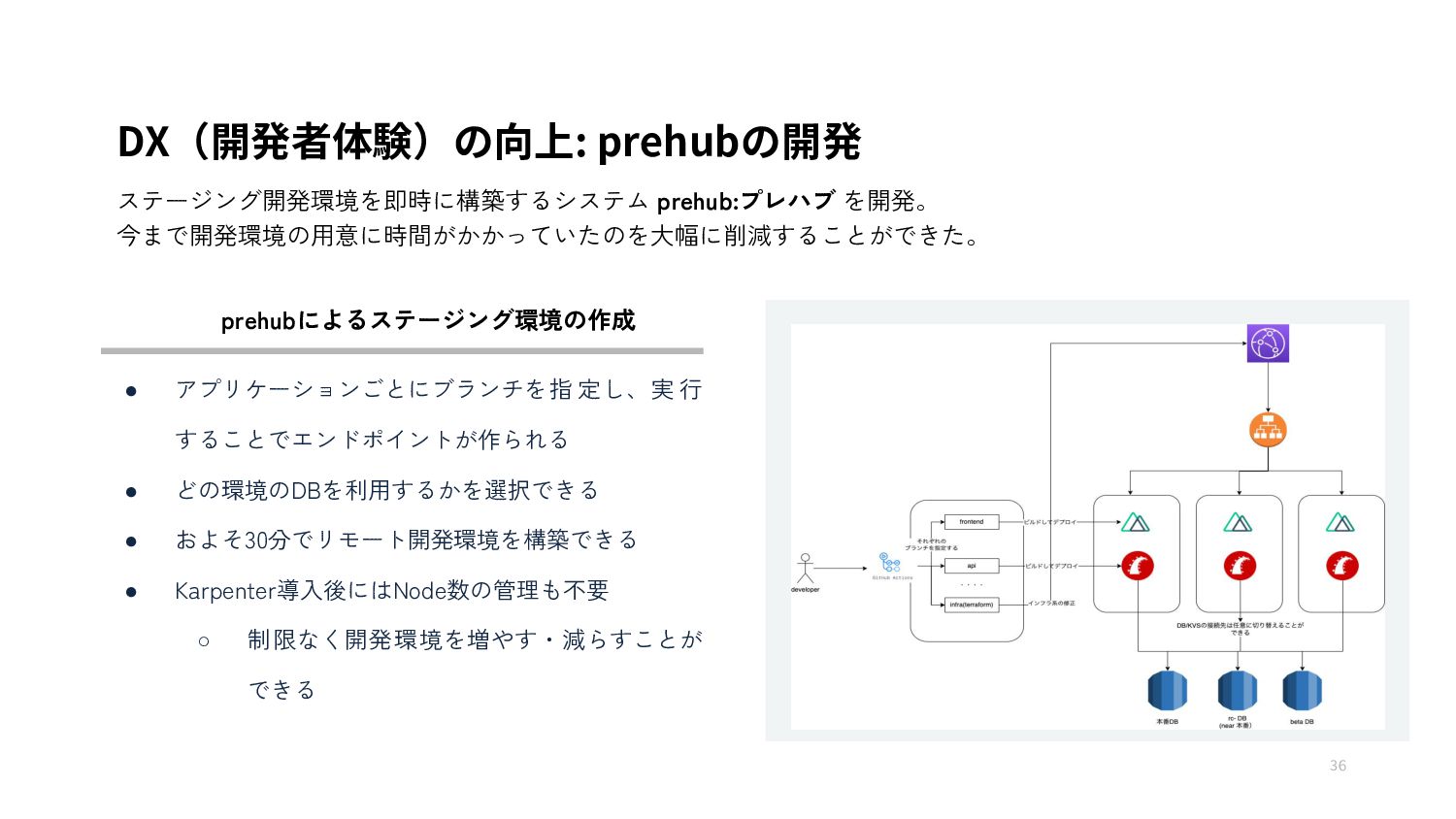{kind=link}
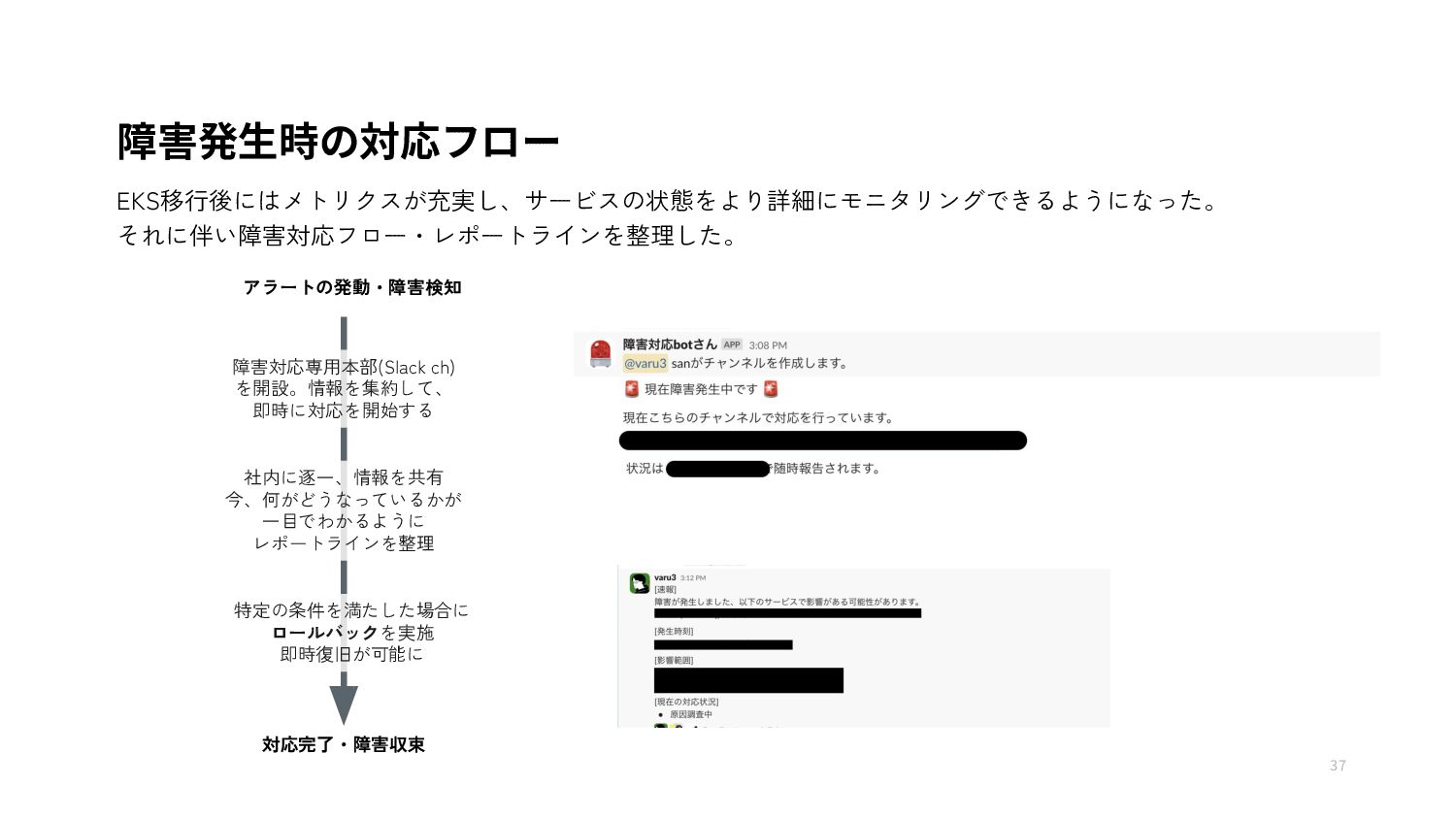{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}