# 大規模障害から見るAWSのバックエンド
#### 2019/09/25 #awswakaran_tokyo
### 株式会社ドリコム インフラストラクチャー部
中村 昴 (@varu3)
---
# 自己紹介
- ばるさん
- twitter: varu_3
- github: varusan
- Blog: https://varu3.hatenablog.com/
- インフラストラクチャー部
- 弊社で運用しているソーシャルゲーム、WEBサービスの主にインフラ部分を管理している部署です
- 社内サービス(GitLabやRPMパッケージ)
- AWS, GCP, 国内パブリッククラウド, Kubernetesなど
---
# 2019年8月23日....
---
# 止まるインスタンス...
# 鳴り止まないアラート...
# 流速が増すTwitterのTL...
# 加熱する報道...
# 祈りの声...
# 悲鳴…
---
# AWSの大規模障害
- 日本時間 2019年8月23日 12:36 より、東京リージョン (AP-NORTHEAST-1) の単一のアベイラビリティゾーンで、オーバーヒートにより一定の割合の EC2 サーバの停止が発生しました。
- いわゆるAZ障害、ゾーン障害
---
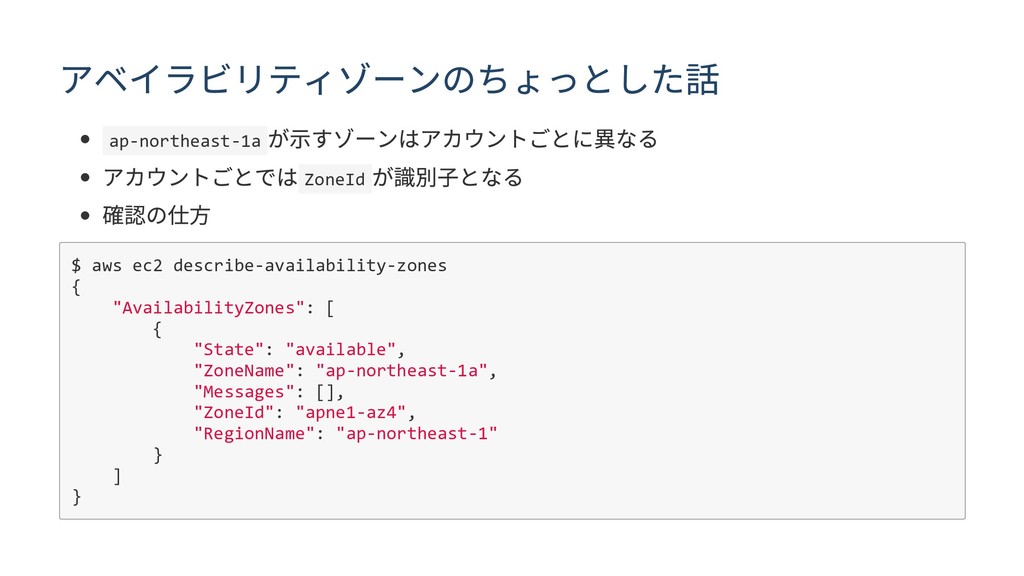
# アベイラビリティゾーンのちょっとした話
- `ap-northeast-1a`が示すゾーンはアカウントごとに異なる
- アカウントごとでは`ZoneId`が識別子となる
- 確認の仕方
```
$ aws ec2 describe-availability-zones
{
"AvailabilityZones": [
{
"State": "available",
"ZoneName": "ap-northeast-1a",
"Messages": [],
"ZoneId": "apne1-az4",
"RegionName": "ap-northeast-1"
}
]
}
```
---
# 弊社で起きた事
---
# その1
# EC2インスタンスのステータスチェックに失敗する
---
## 発生直後
- 稼働中のインスタンスのAWS上でのステータスチェックが失敗し、疎通ができなくなった。
- 止まるインスタンスは 3 AZのうちの 1 つのAZのみ
- 大半のインスタンスは`強制停止` → `起動`で復旧たが、一部立ち上がらないインスタンスもあった
- 立ち上がらなかったインスタンスを、AMIイメージを取得してそのAMIから立ち上げようとするも失敗
- EBSスナップショットも取れない状態
---
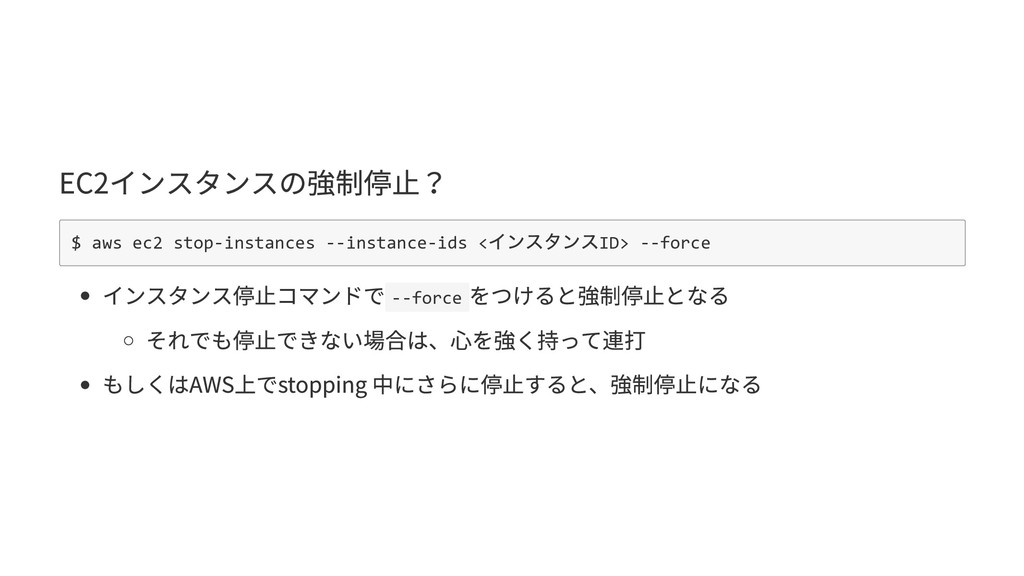
## EC2インスタンスの強制停止?
``` bash
$ aws ec2 stop-instances --instance-ids <インスタンスID> --force
```
- インスタンス停止コマンドで`--force`をつけると強制停止となる
- それでも停止できない場合は、心を強く持って連打
- もしくはAWS上でstopping 中にさらに停止すると、強制停止になる
---
# 対応策
- 止まったら困るインスタンス(絶賛開発中のサーバとか)は日次スナップショットを取っておく
- EBSのスナップショットはS3に保存される
- S3は最低3つのAZに冗長化されて保存される
- そのため、他のAZでも起動できる(はず)
- 障害時にはバックアップからインスタンスを起動する
- 本番環境
- MultiAZ構成
- オートスケールしなくても台数を固定してオートスケーリンググループで管理する
- 問題が起きたインスタンスを削除して他AZで立ち上げる
---
# その2
# Elasticache(Memcached)でのパフォーマンスが低下する
---
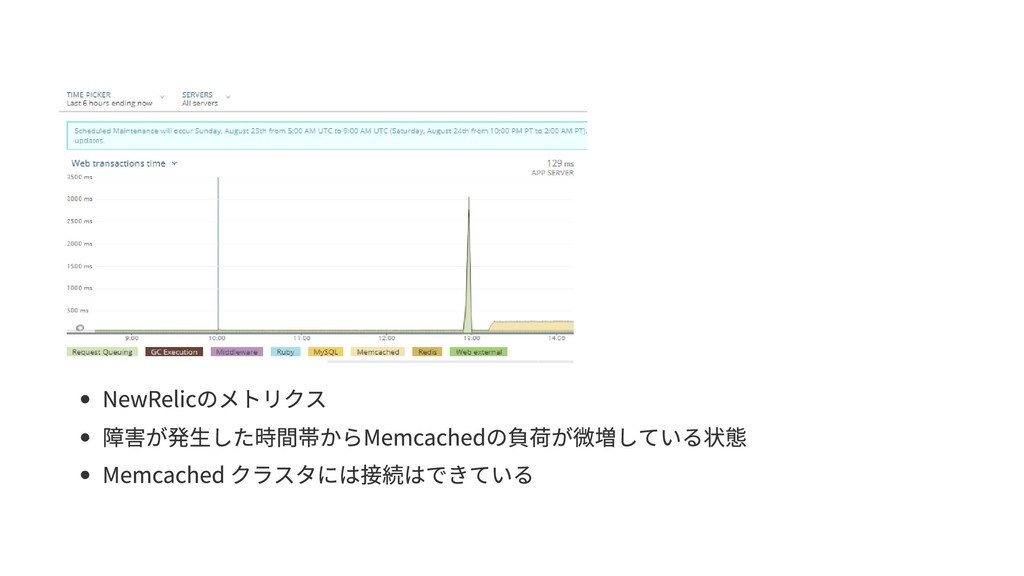
- NewRelicのメトリクス
- 障害が発生した時間帯からMemcachedの負荷が微増している状態
- Memcached クラスタには接続はできている
---
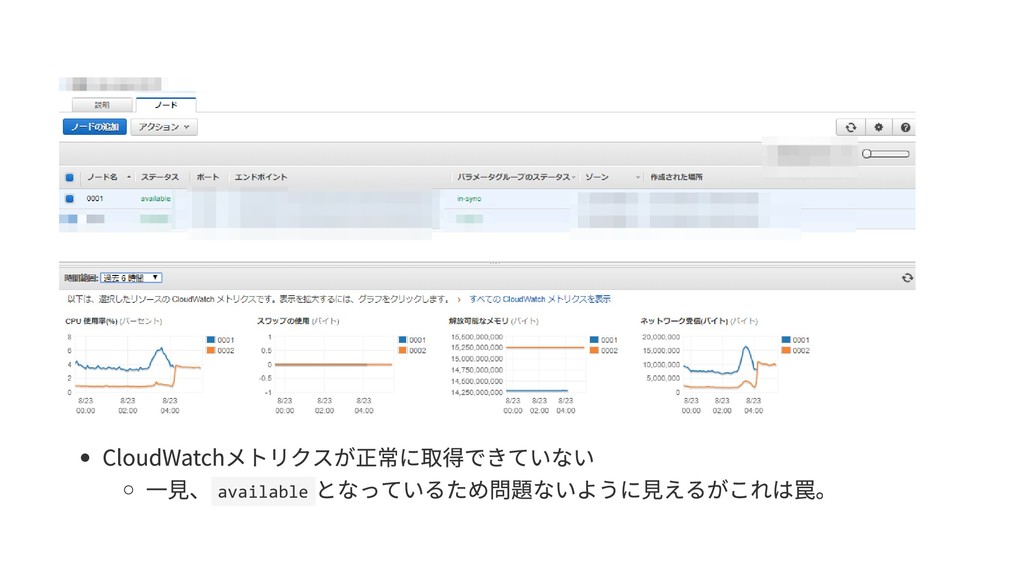
- CloudWatchメトリクスが正常に取得できていない
- 一見、`available`となっているため問題ないように見えるがこれは罠。
---
# なぜMemcachedでも影響が?
- EC2とEBSを基盤として動作しているため
- その他にもRDS、 Redshift、 ElastiCache および Workspace なども。
- 当初、障害が起きているとアナウンスされたのは、AWSではEC2, EBSのみだった
- 該当サービスがなくてよかった、と安心してはいけない。
- むしろEC2の障害だと大きく影響範囲が広がる可能性を考慮する。
---
# その3.
# ALBで5xxエラーが発生
---
- 障害発生時からALBで5xxエラーが増加。
- ALBログを確認したところ` "actions_executed": "waf-failed"` と出ていた
- このALBはWAFと紐づけていた
---
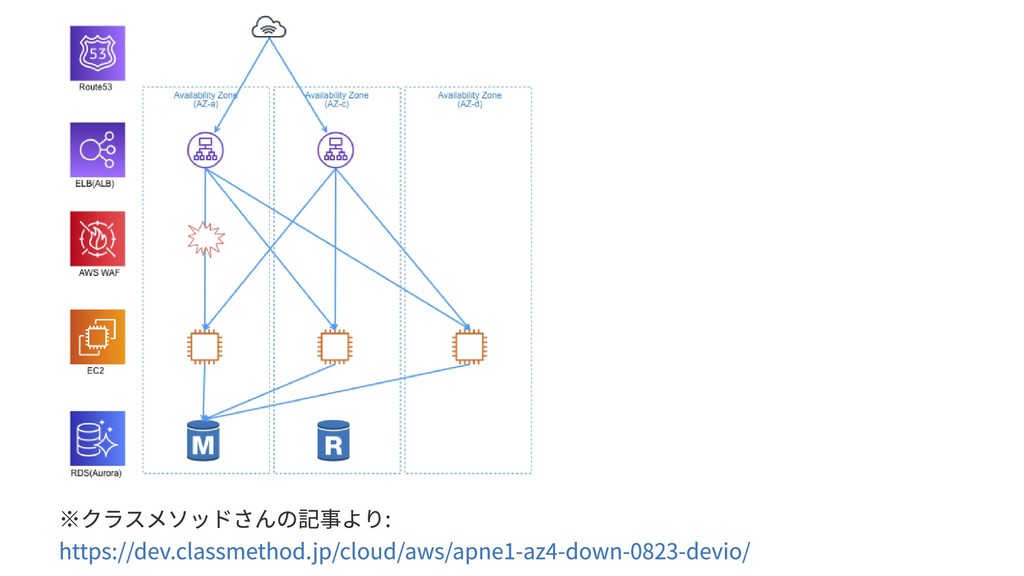
# どういうことか
## 本来の挙動
1. ALBのリクエストはAWS WAFへ転送される
1. AWS WAF はリクエストのブロックもしくは許可する
1. 許可されたリクエストは本来のリクエスト先へ
## 障害発生時
- 障害が発生したAZへルーティングされたWAF上で問題が発生した
- 本来の挙動でいうと2.の部分
---
※クラスメソッドさんの記事より:
https://dev.classmethod.jp/cloud/aws/apne1-az4-down-0823-devio/
---
# 対応
- WAFを無効にする
- ALBのサブネットから問題が起きたリージョンを外す
- ALBは最低 2 AZが必要なため、3 AZ目のサブネットの設定をしておく
---
# 障害時の情報源
- AWS Personal Health Dashboard
- 各アカウントごとにAWSコンソールから参照できる
- 公式の(おそらく)一番確かで早い情報
- 報告されない事象もある(EC2がバックエンドだったものなど)
- AWS Service Health Dashboard
- https://status.aws.amazon.com/
- 探しやすい、一覧性がある
- ただし情報は即座には反映されない(体感、ラグがある)
- Twitter
- 情報の精度としては玉石混合
- みんなが大変そうなのはわかる。
---
# まとめ
- 単一インスタンスは定期的にスナップショットを取ることが必要だよ
- 本番環境では、オートスケーリンググループでインスタンスを管理して、柔軟にインスタンス数やAZを変更できることが大事だよ
- EC2の障害はEC2以外にも、他のEC2がバックエンドで使われているフルマネージドサービスにも影響を及ぼすよ
- 障害を辿るとAWSのバックエンドがチョットワカルようになるよ
- 情報を逐一確認しながら、自分たちのアカウントではどのように影響が出ているかを確認することが大事だよ
---
# 最後に
- 弊社ではこのような事例があったものの幸いなことに、本番環境への影響は最低限に止めることができました。
- AWSの中の人やサービス対応におわれた方々、本当にお疲れ様でした!!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}