5 anos de experiência liderando equipes ágeis e construindo aplicações web. Ex-integrante da Evolux, atualmente trabalha com web scraping utilizando Python e Scrapy na Scrapinghub.
rápido e integrar sistemas de maneira mais eficiente. Tem sido muito usada na Ciência de Dados em conjunto com diversas bibliotecas como Pandas e Numpy, principalmente devido a sua facilidade e poder.
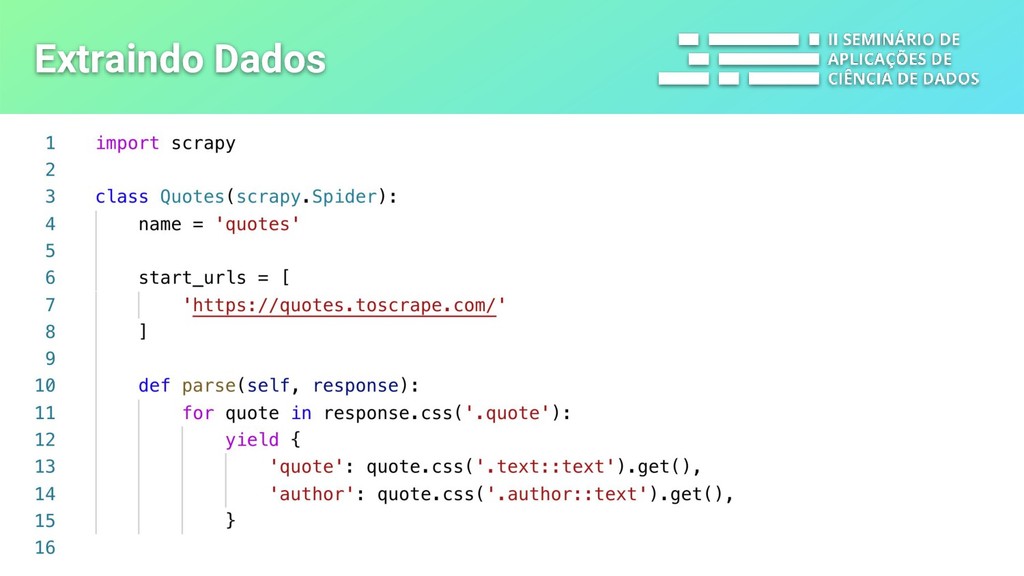
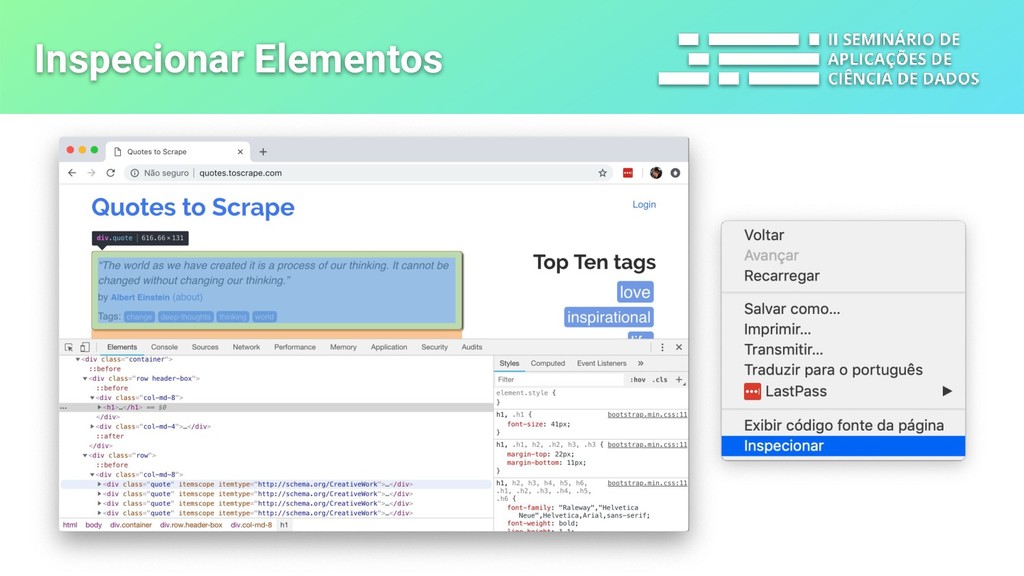
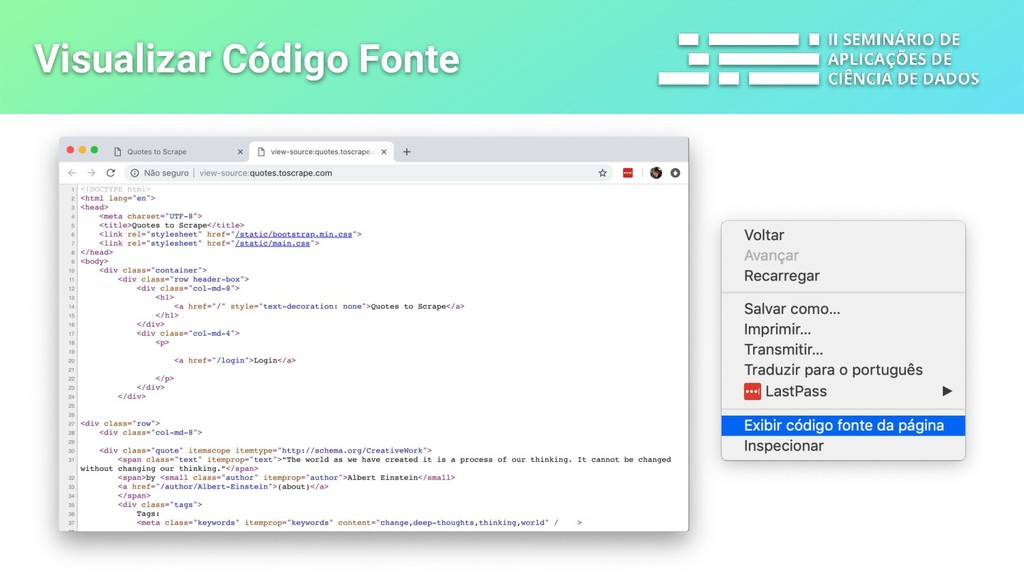
a extração dos dados que você precisa de páginas web e outras fontes. Tudo isso de maneira rápida, simples e extensível. - sessões/cookies - redirecionamentos - pipelines e middlewares
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![$ scrapy runspider quotes.py (...) [INFO] Parsing https://quotes.toscrape.com/ (...) Executando](https://files.speakerdeck.com/presentations/e44088ada77648548a45a107c87fc347/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![$ scrapy runspider quotes.py (...) [DEBUG] Scraped from <200: https://quotes…>](https://files.speakerdeck.com/presentations/e44088ada77648548a45a107c87fc347/slide_13.jpg){kind=link}
![$ scrapy runspider quotes.py -o quotes.json (...) [INFO] Stored json](https://files.speakerdeck.com/presentations/e44088ada77648548a45a107c87fc347/slide_14.jpg){kind=link}
{kind=link}
![$ scrapy runspider quotes.py -o quotes.json (...) [DEBUG] Scraped from](https://files.speakerdeck.com/presentations/e44088ada77648548a45a107c87fc347/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
![Obrigado! Victor Torres victortorres.net.br github.com/victor-torres linkedin.com/in/victorpaivatorres [email protected]](https://files.speakerdeck.com/presentations/e44088ada77648548a45a107c87fc347/slide_19.jpg){kind=link}