bits a[0,2] 64 bits a[0,3] a[1,0] a[1,1] a[1,2] a[1,3] a[2,0] a[2,1] … 64 bits a[0,0] 64 bits a[0,1] 64 bits a[0,2] 64 bits a[0,3] a[1,0] a[1,1] a[1,2] a[1,3] a[2,0] a[2,1] … 64 bits a[0,0] 64 bits a[0,1] 64 bits a[0,2] 64 bits a[0,3] a[1,0] a[1,1] a[1,2] a[1,3] a[2,0] a[2,1] …
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![i 在外⾯ miss rate = 4/16 a[i][j] j=0 j=1 j=2](https://files.speakerdeck.com/presentations/a78540bf1bf54729a4a3be5fa1a82299/slide_27.jpg){kind=link}
![j 在外⾯ miss rate = 16/16 a[i][j] j=0 j=1 j=2](https://files.speakerdeck.com/presentations/a78540bf1bf54729a4a3be5fa1a82299/slide_28.jpg){kind=link}
![64 bits a[0,0] 64 bits a[0,1] 64 bits a[0,2] 64](https://files.speakerdeck.com/presentations/a78540bf1bf54729a4a3be5fa1a82299/slide_29.jpg){kind=link}
![你不會互換 i, j? 64 bits a[0,0] 64 bits a[0,1] 64](https://files.speakerdeck.com/presentations/a78540bf1bf54729a4a3be5fa1a82299/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
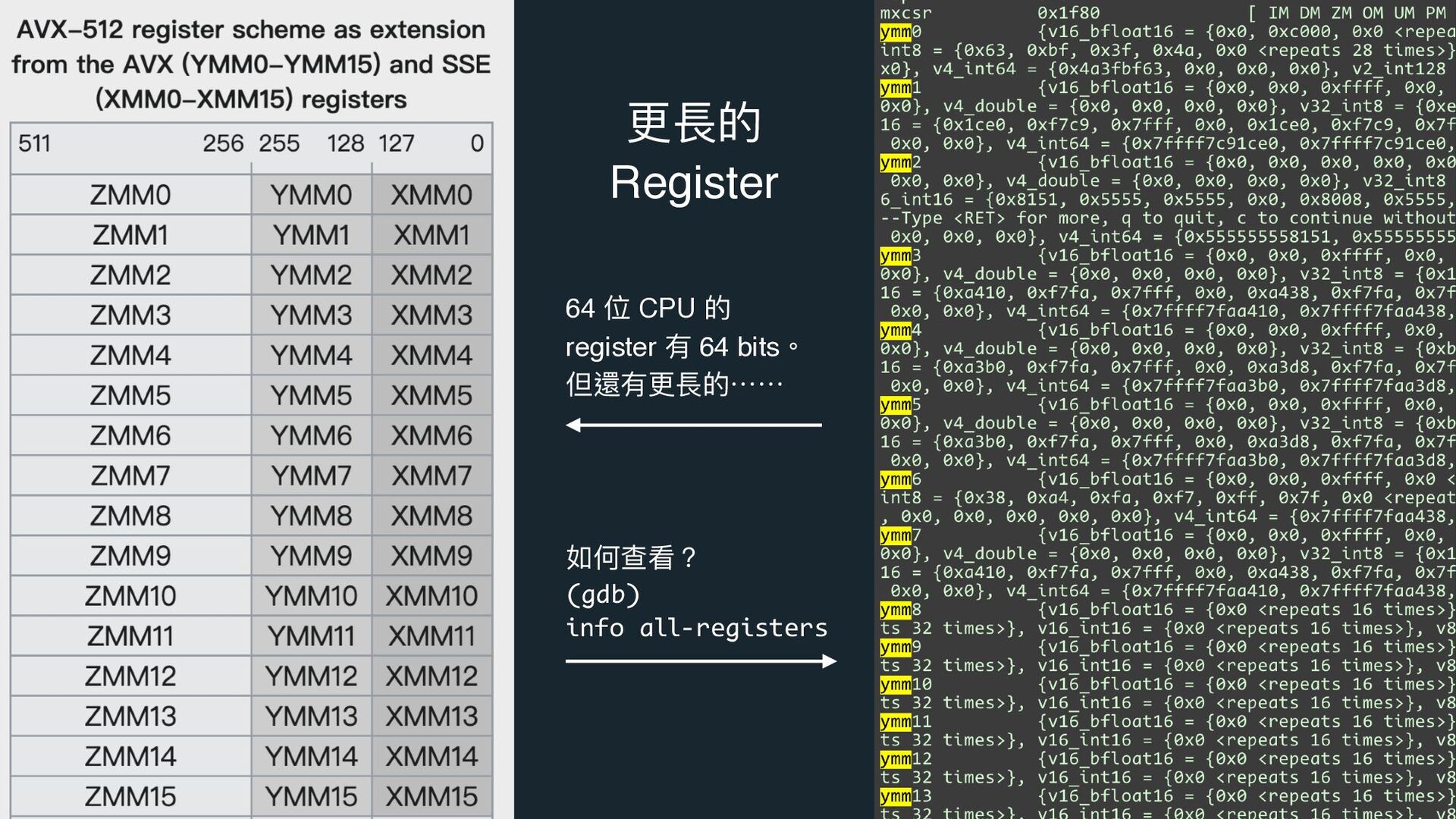{kind=link}
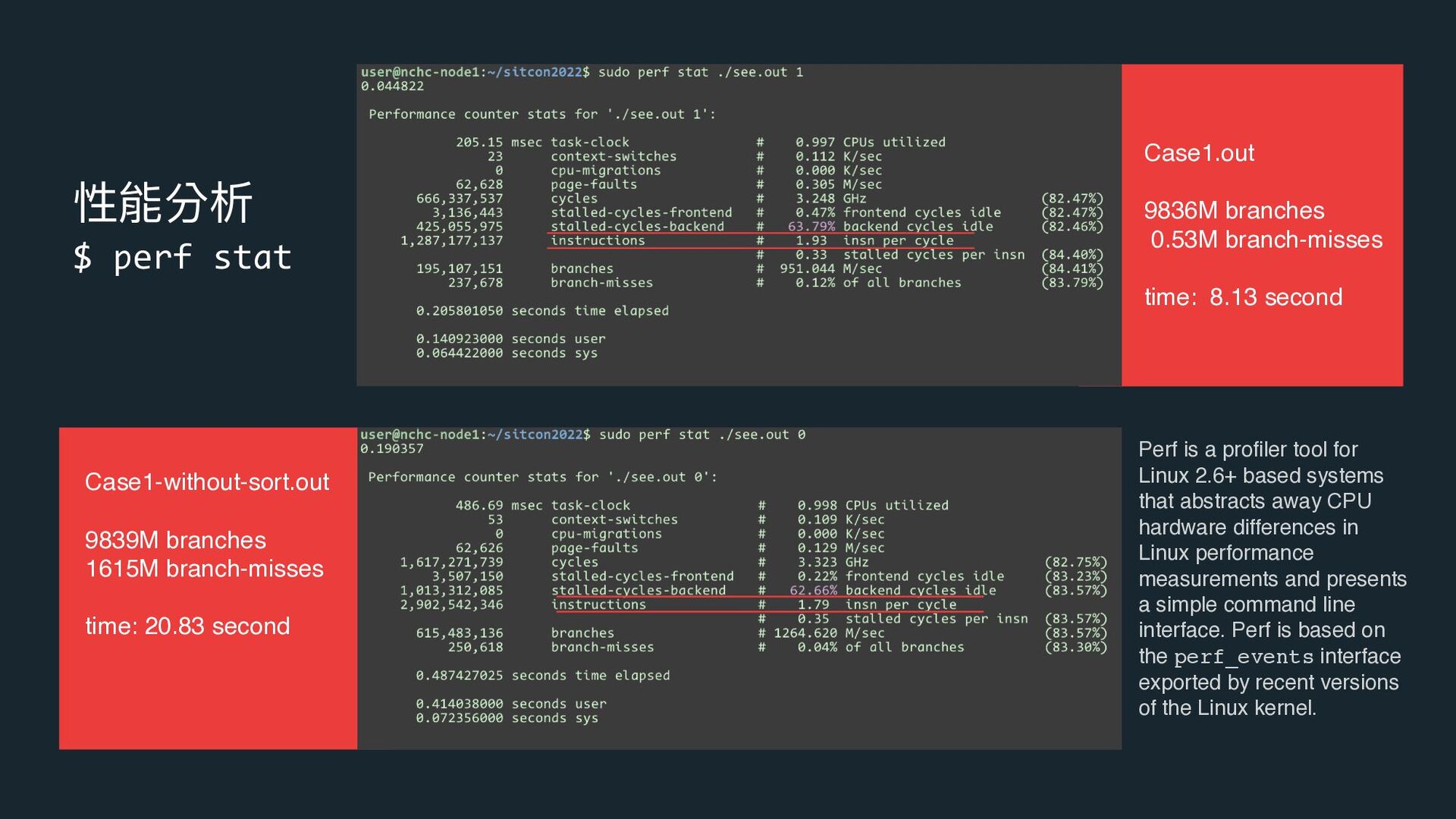{kind=link}
{kind=link}
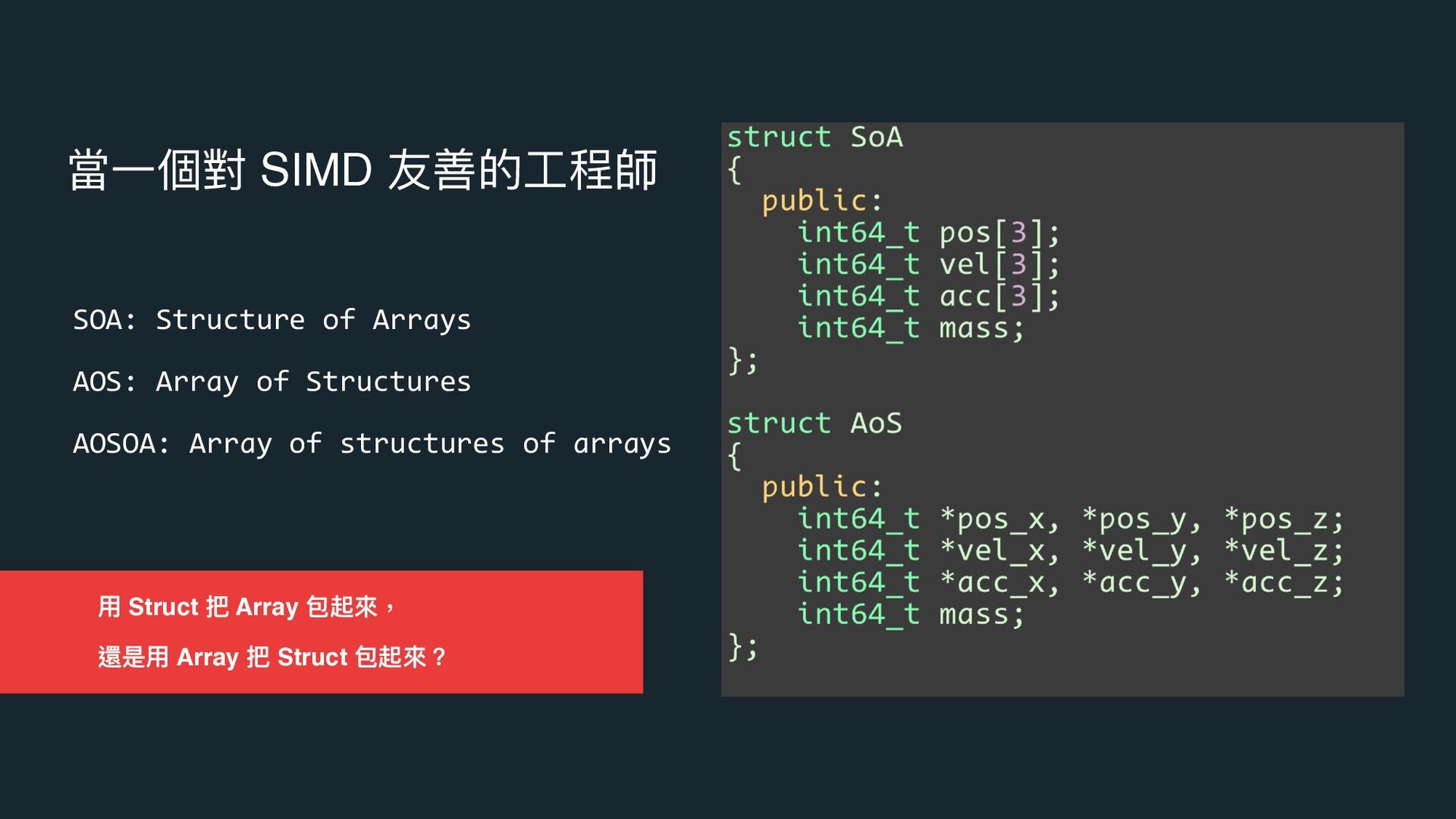{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}