You need to keep your application running. Downtime costs you money, in some cases a lot, and in the worst case it can destroy a company.
Let us talk about architectural styles and other approaches to make your system more resilient. Failures are normal and everything will fail at some point of time: be prepared, even if you are not working for Netflix, Google or Amazon.
We will have a quick look at tools out there to set up some simple "chaos" or better resilience tests to ensure your stack is running.
This talk covers:
1) Why is resilience important for Microservice (especially)
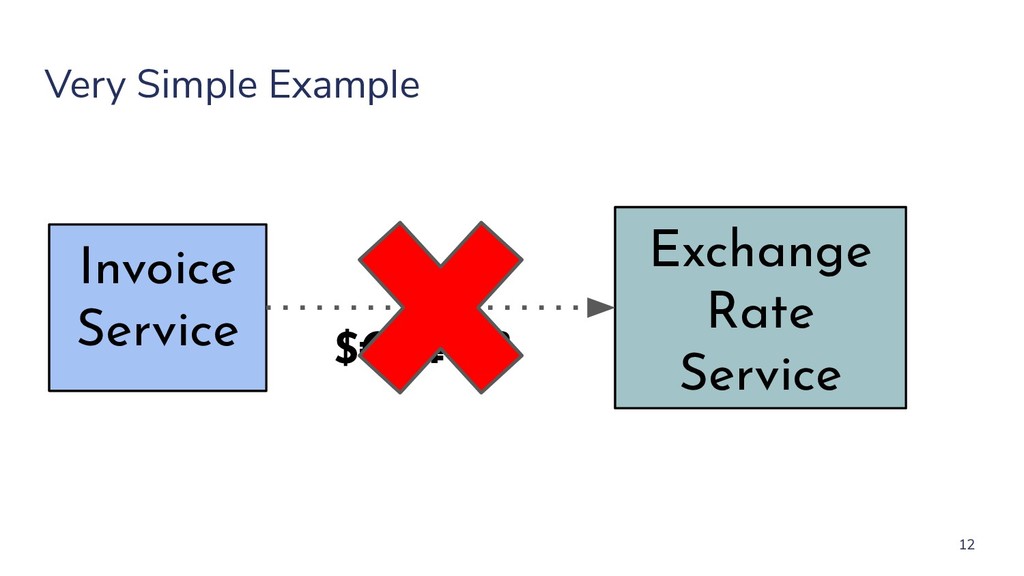
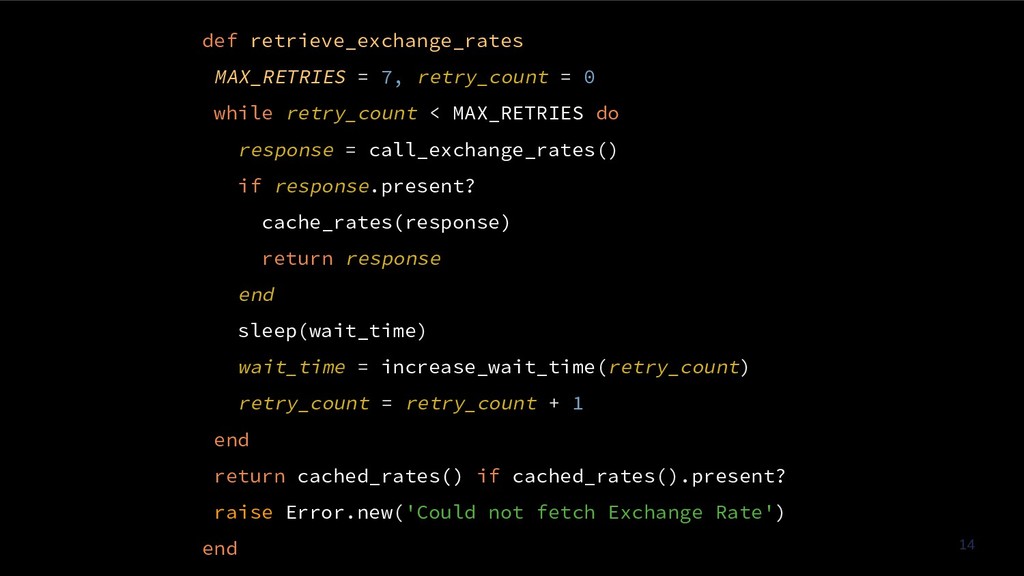
2) Best practices for designing resilient distributed architectures
3) Testing resilience in applications
We are going to talk more about general concepts rather than discussing how to configure and setup tool x, y, z. The concepts should be applicable to a simple web application as well as for larger systems with tons of legacy code written in a rather exotic language only some retired guys can understand.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
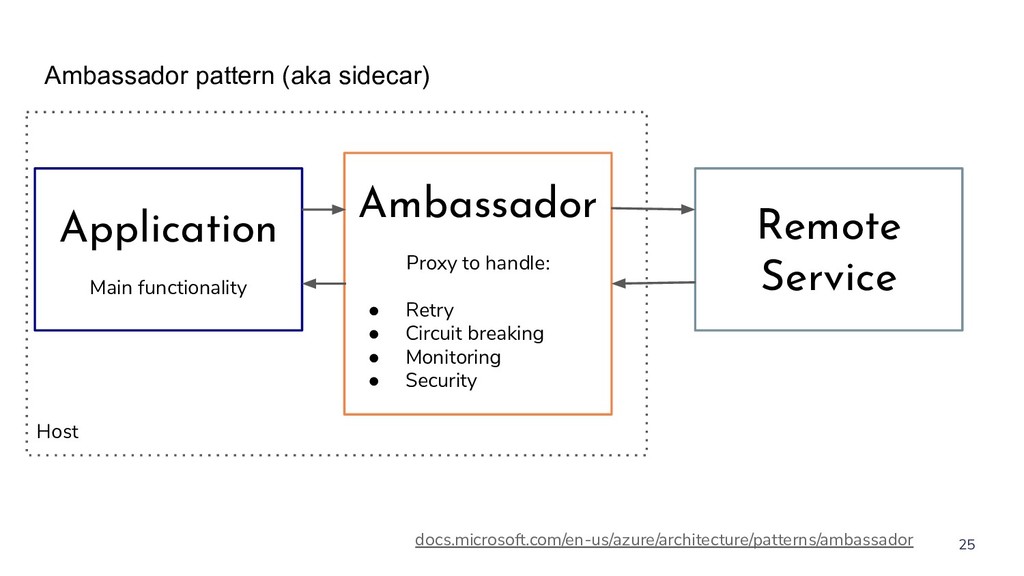{kind=link}
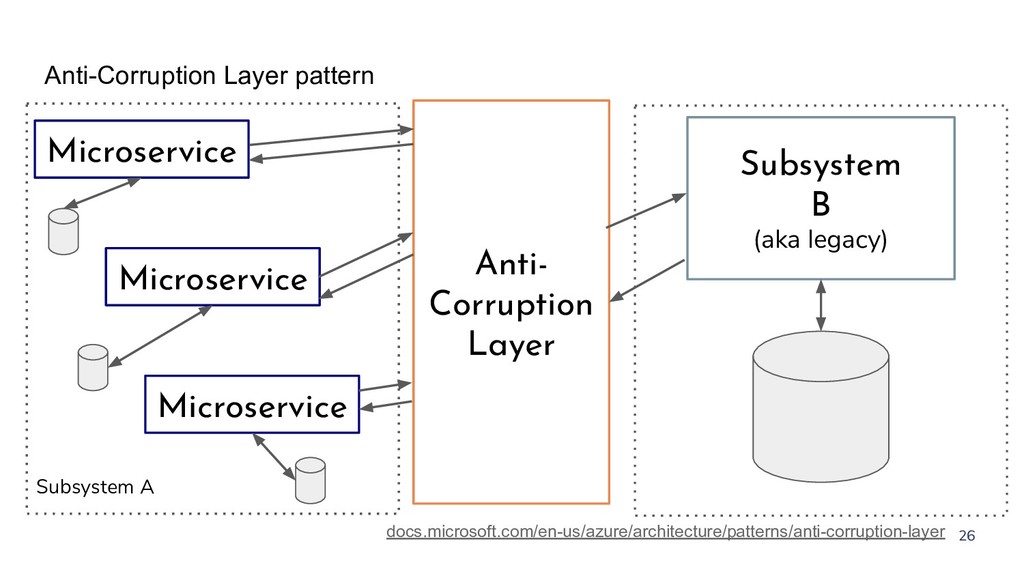{kind=link}
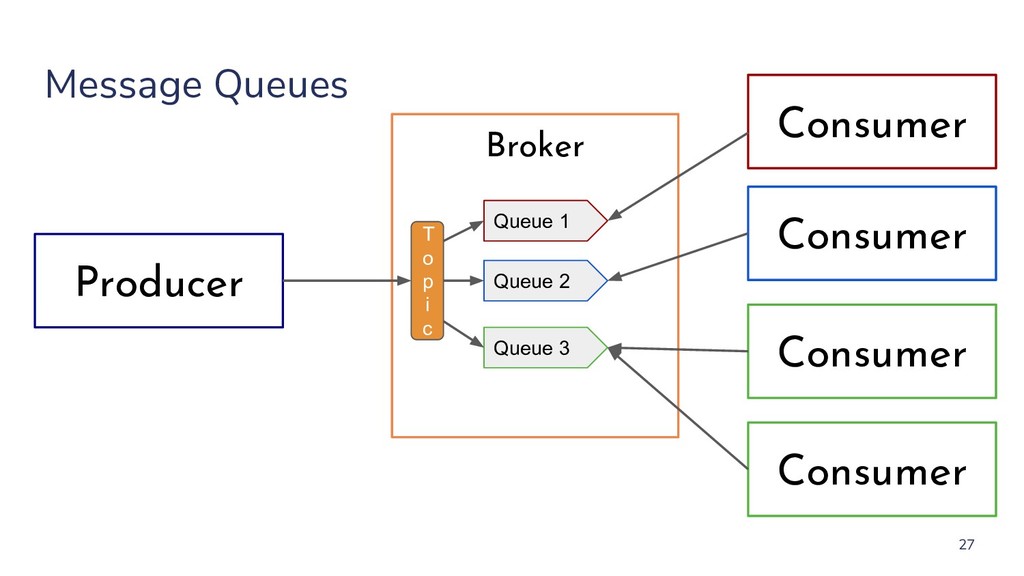{kind=link}
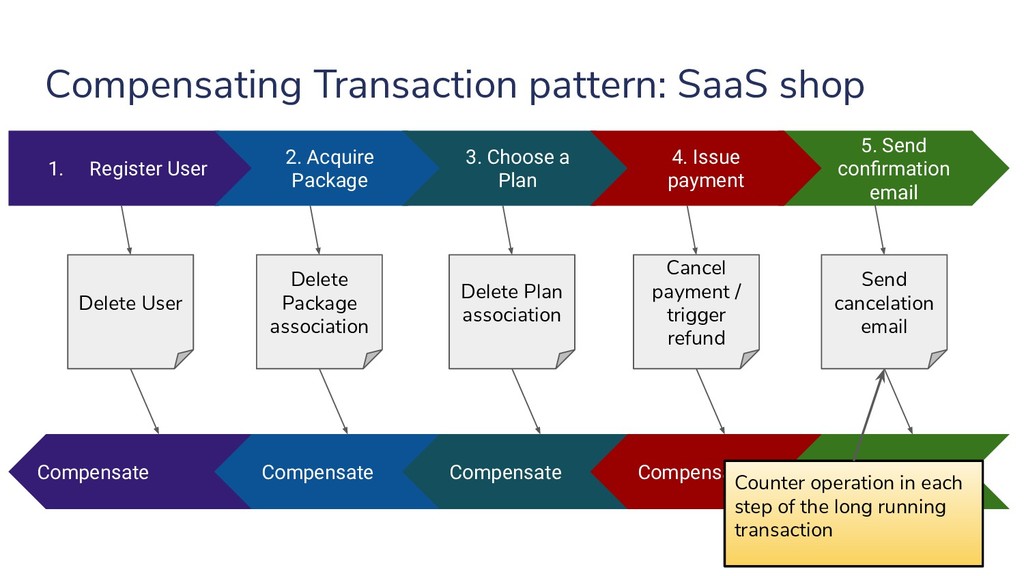{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}