Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ユーザーのプロフィールデータを活用した推薦精度向上の取り組み
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Yudai Hayashi
June 19, 2025
Technology
770
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ユーザーのプロフィールデータを活用した推薦精度向上の取り組み
白金鉱業 Meetup Vol.19@六本木 で発表した内容です
Yudai Hayashi
June 19, 2025
More Decks by Yudai Hayashi
See All by Yudai Hayashi
技術キャッチアップ効率化を実現する記事推薦システムの構築
yudai00
4
370
Off-Policy Evaluation and Learning for Matching Markets
yudai00
0
150
ジョブマッチングプラットフォームにおける推薦アルゴリズムの活用事例
yudai00
0
170
MCP Clientを活用するための設計と実装上の工夫
yudai00
1
1.4k
人とシゴトのマッチングを実現するための機械学習技術
yudai00
1
130
MCPを理解する
yudai00
18
15k
データバリデーションによるFeature Storeデータ品質の担保
yudai00
1
290
「仮説行動」で学んだ、仮説を深め ていくための方法
yudai00
8
2.1k
相互推薦システムでのPseudo Label を活用したマッチ予測精度向上の取り組み
yudai00
1
1.2k
Other Decks in Technology
See All in Technology
QA・ソフトウェアテスト研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
3
1.7k
StepFunctionsとGraphRAGを活用した暗黙知活用のためのRAG基盤
yakumo
0
190
文字起こし基盤の信頼性
abnoumaru
0
150
新たなDBアーキテクチャ「LTAP」にDeep Dive!!
inoutk
0
150
基調講演:人とAIをつなぐIoTの今と未来 ー 「フィジカル」と「デジタル」が出会うその先へ【SORACOM Discovery 2026】
soracom
PRO
0
360
論語・武士道・産業革命から見る かわるもの、かわらないもの
ichimichi
8
1.6k
ここは地獄!つらい朝会を体験することで、チームとしてのより良い振る舞いに気づくワークショップ / The stand-up meeting from hell in the game industry
scrummasudar
0
440
データ活用研修 問いの発見と仮説構築【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
660
AI研修(Day1)【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
2.7k
大 AI 時代におけるC# の事情 ~ぶっちゃけトークを交えながら~
nenonaninu
1
540
運用を犠牲にせずコストを制御し事業成長を支える B2B SaaS ID管理基盤におけるS3 Tableのログストレージ活用
kaminashi
1
100
AIツールを導入しても生産性はあがらない? カオナビが直面した 3つの壁と乗り越え方。/ Overcoming 3 Barriers to AI-Driven Productivity at kaonavi
kaonavi
0
460
Featured
See All Featured
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
Context Engineering - Making Every Token Count
addyosmani
9
1k
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.7k
Agile that works and the tools we love
rasmusluckow
331
22k
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
330
Ruling the World: When Life Gets Gamed
codingconduct
0
290
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
Are puppies a ranking factor?
jonoalderson
1
3.7k
Practical Orchestrator
shlominoach
191
11k
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
Transcript
© 2025 Wantedly, Inc. ユーザーのプロフィールデータを活 用した推薦精度向上の取り組み 白金鉱業 Meetup Vol.19@六本木 Jun.19
2025 - Yudai Hayashi
© 2025 Wantedly, Inc. 自己紹介 林 悠大 • 経歴: ◦
2022年に応用物理分野で Ph.D取得 ◦ 2022年にウォンテッドリー株式会社に新卒入社。データサイ エンティストとして推薦システムの開発に従事 @python_walker @Hayashi-Yudai
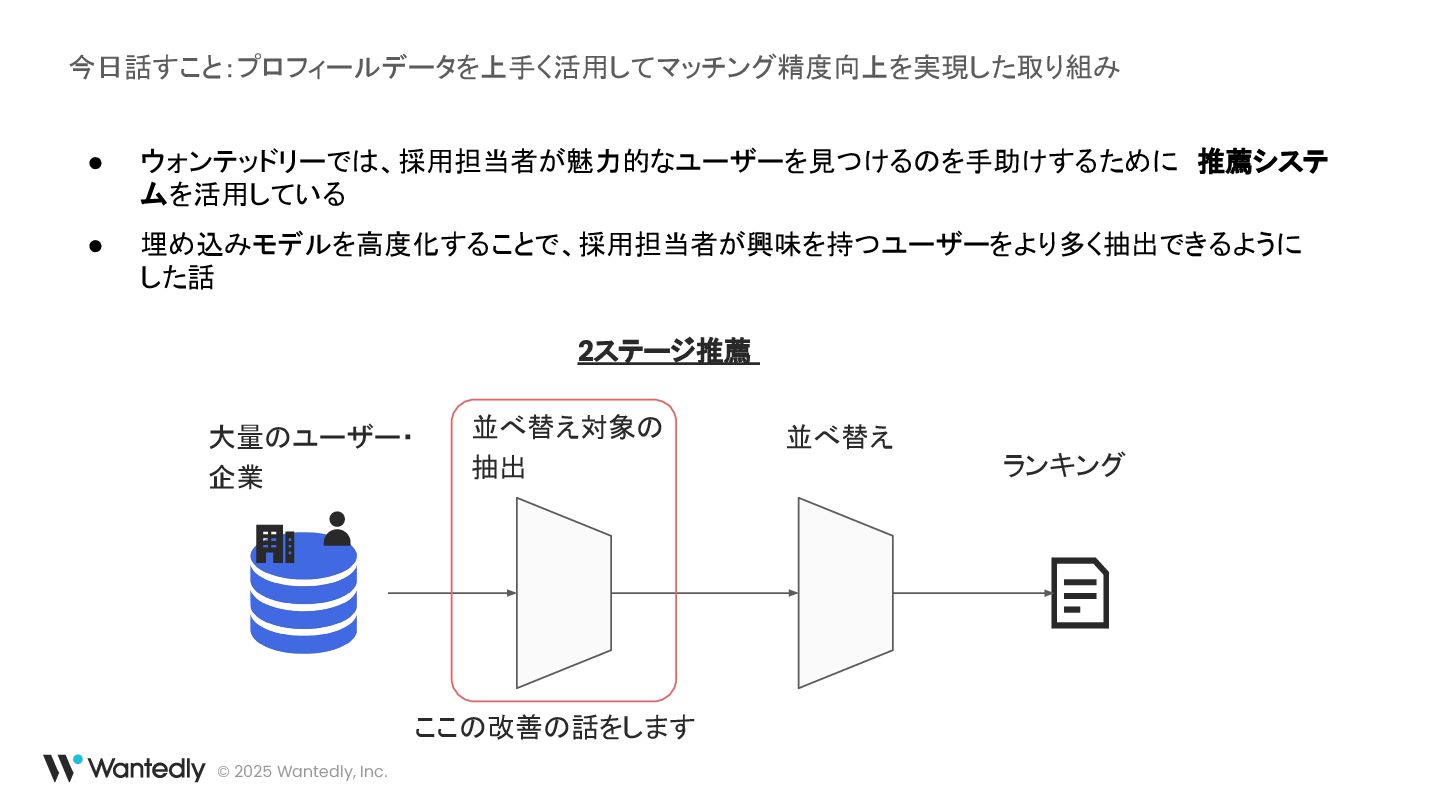
© 2025 Wantedly, Inc. 今日話すこと:プロフィールデータを上手く活用してマッチング精度向上を実現した取り組み • ウォンテッドリーでは、採用担当者が魅力的なユーザーを見つけるのを手助けするために 推薦システ ムを活用している •
埋め込みモデルを高度化することで、採用担当者が興味を持つユーザーをより多く抽出できるように した話 大量のユーザー・ 企業 ランキング 並べ替え対象の 抽出 並べ替え 2ステージ推薦 ここの改善の話をします
© 2025 Wantedly, Inc. 背景:採用担当者が過去にスカウトを送ったユーザーと似ているユーザーには興味を持つはず ユーザーの「似ている」をプロフィールを使って定量化 ? ? Aさん プロフィール
Aさんのプロフィールと似てるから スカウト送られそう Aさんのプロフィールと似てないから スカウト送られなさそう ユーザープロフィールの類似度によって並び替え候補の抽出を実現
© 2025 Wantedly, Inc. 課題:プロフィール情報の文脈まで活用できていなかった ? ? Aさん プロフィール Embedding
w2v モデル コサイン類似度 word2vecベースの手法を利用していたため、プロフィールの文脈までは 活用できていなかった
© 2025 Wantedly, Inc. 解決策:より高度な埋め込みモデルの利用 • multilingual-e5-small という埋め込みモデルを利 用するように変更 ◦
文脈情報を埋め込みに反映 ◦ 日本語を含む多言語の文章に対応 ◦ トークン長は512 • ウォンテッドリーのプロフィールは文章量が多いケース が多い ◦ 各パートを分割して、それぞれで Embeddingを 計算し、平均を利用 Attentionベースの手法を利用することで、より ”似 ている”の解像度を上げられることを期待
© 2025 Wantedly, Inc. 解決策:なぜmultilingual-e5-smallか • よりトークン長の長いモデル (RoSEtta-base-ja; 1,024トークン)も試したが、E5系の方がRecallが高 かった
◦ プロフィールを分割して Embedding化したことで、短いトークン長でも十分だった可能性 ◦ 扱えるトークン長が長くなる点よりも、モデル自体の我々のタスクにおける性能差で E5の方が勝って いた可能性 • E5系の中でもモデルサイズごとの比較をしたが、 multilingual-e5-small のRecall性能が最も良かっ た ◦ JMTEBでは、STS (=Semantic Text Similarity) において large < base < small という性能に なっているので、これと整合性のある結果 https://github.com/sbintuitions/JMTEB /blob/main/leaderboard.md#sts 一言で言うと「色々試した中でこれが一番良かったから」 もう少し考察すると...
© 2025 Wantedly, Inc. 結果:定性的に文脈的に似ているユーザーを抽出できるようになった Input “データを解析することによってユーザーが求めていることを発見し、より良い体験を届けられるようなデータエ ンジニアになりたい” • データを駆使
してマーケティングを革新したい。データ分析から得られるインサイトを基に、 Web広告やチ ラシなど... • エンジニア として働きたい。アプリ開発をしたい 変更前 変更後 (E5) • データサイエンティストや機械学習エンジニア など、ユーザーにもっと近い立場 に立って仕事したい。 • ログなどのデータを使用 して、ユーザーにとって最適解 を見つけること。
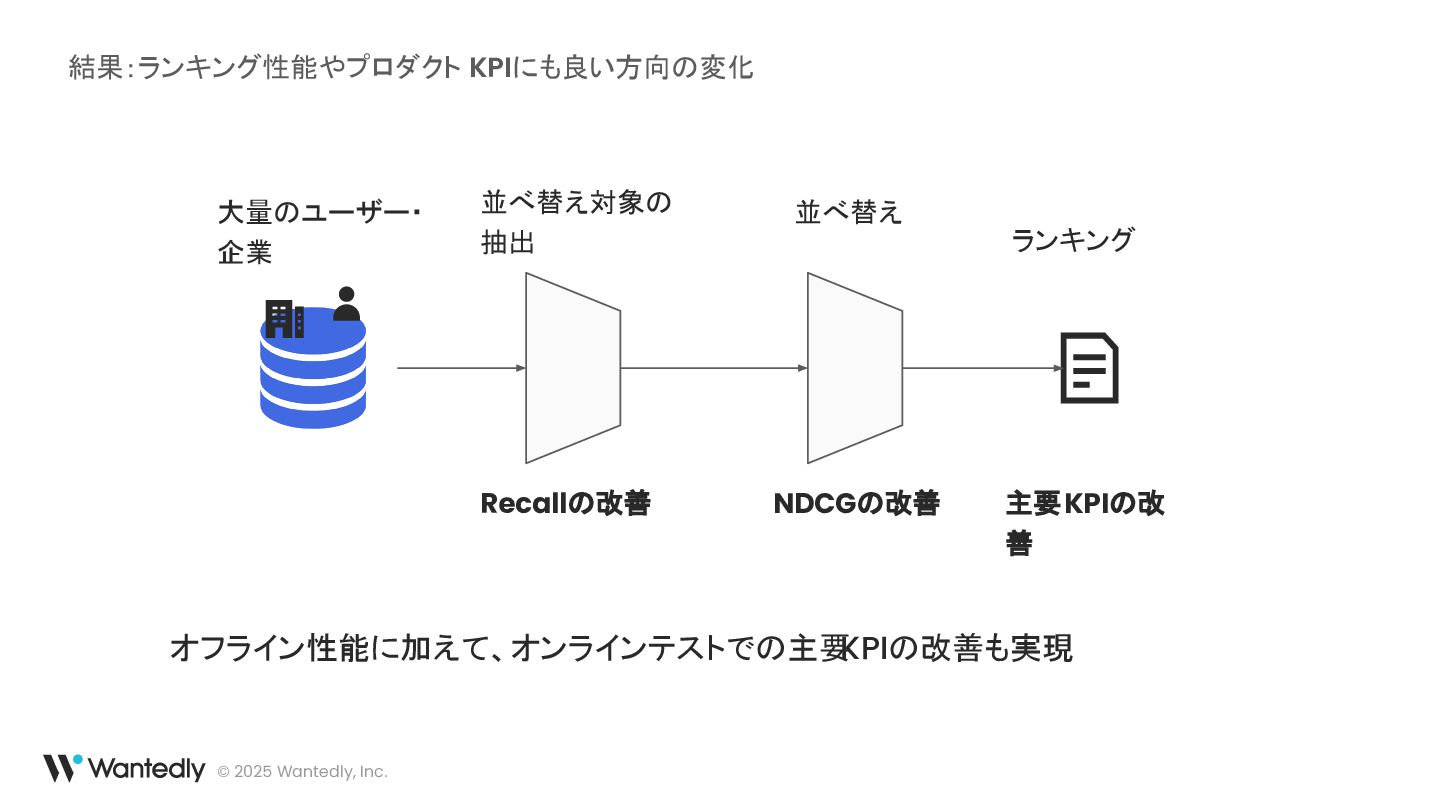
© 2025 Wantedly, Inc. 結果:ランキング性能やプロダクト KPIにも良い方向の変化 大量のユーザー・ 企業 ランキング 並べ替え対象の
抽出 並べ替え Recallの改善 NDCGの改善 オフライン性能に加えて、オンラインテストでの主要 KPIの改善も実現 主要KPIの改 善
© 2025 Wantedly, Inc. まとめ • 埋め込みモデルを改善することで、推薦精度を高めることができた取り組みについて紹介 • 並べ替え候補の抽出ロジックの改善を、後段のランキング性能や主要 KPIの改善まで伝播させることがで
きた ◦ プロフィールをパートごとに分割して平均することで、広い範囲の情報を Embeddingに含められる ようにした ◦ これまでより文脈的に似ているユーザーが抽出できていることを定性的に確認 ◦ オンラインテストにより主要 KPIが改善していることを確認
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}