Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
SREKaigi2026_ゼロからはじめるSRE一人運用から複数プロダクト_SREチー...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
ybalexdp
January 30, 2026
1.5k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
SREKaigi2026_ゼロからはじめるSRE一人運用から複数プロダクト_SREチーム立ち上げまでの軌跡.pdf
ybalexdp
January 30, 2026
More Decks by ybalexdp
See All by ybalexdp
“ 人とAI ”が共創するエンジニアリングの実践と未来
ybalexdp
0
600
Featured
See All Featured
WCS-LA-2024
lcolladotor
0
750
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
180
Skip the Path - Find Your Career Trail
mkilby
1
170
AI: The stuff that nobody shows you
jnunemaker
PRO
9
840
Dealing with People You Can't Stand - Big Design 2015
cassininazir
367
27k
Documentation Writing (for coders)
carmenintech
77
5.4k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
200
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2.1k
The Limits of Empathy - UXLibs8
cassininazir
1
530
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.5k
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
Transcript
ゼロからはじめる SRE: 一人運用から複数プロダクト・ SREチーム立ち上げまで の軌跡 2026/1/31 SRE Kaigi 2026 籔下
直哉 / @ybalexdp 株式会社TalentX 上席執行役員CTO
自己紹介 籔下 直哉(やぶした なおや) Naoya Yabushita X:@ybalexdp 株式会社TalentX 上席執行役員 CTO
大手メーカーにてプライベートIaaS基盤を中心にNFV/SDN領 域やWeb領域での開発を担当。 2018年TalentXに入社し、その後Tech Lead / EMとして技術 及び開発組織全般を管掌。2023年執行役員CTOに就任 2
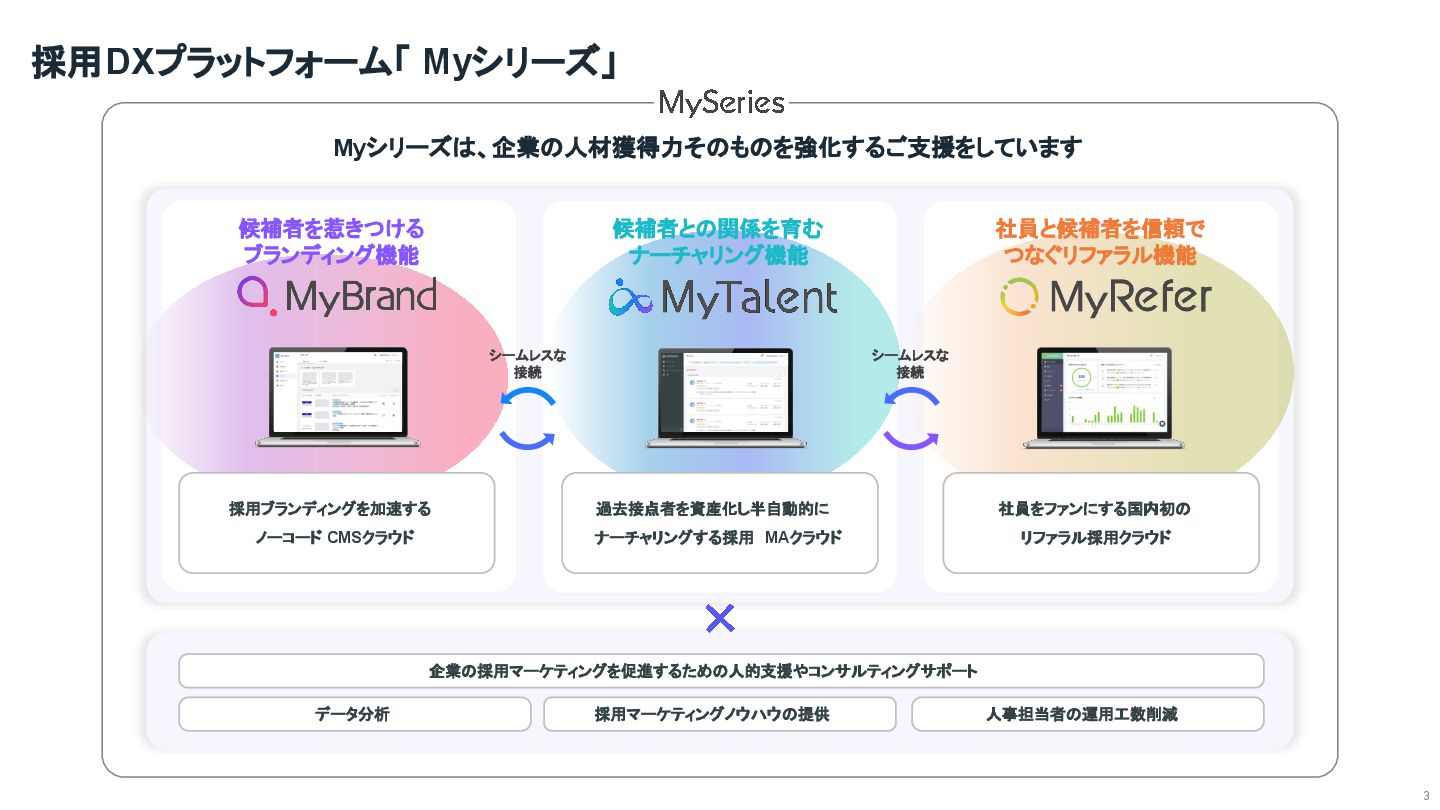
採用DXプラットフォーム「 Myシリーズ」 3 企業の採用マーケティングを促進するための人的支援やコンサルティングサポート 採用マーケティングノウハウの提供 人事担当者の運用工数削減 データ分析 候補者を惹きつける
ブランディング機能 候補者との関係を育む ナーチャリング機能 社員と候補者を信頼で つなぐリファラル機能 Myシリーズは、企業の人材獲得力そのものを強化するご支援をしています シームレスな 接続 シームレスな 接続 過去接点者を資産化し半自動的に ナーチャリングする採用 MAクラウド 社員をファンにする国内初の リファラル採用クラウド 採用ブランディングを加速する ノーコード CMSクラウド
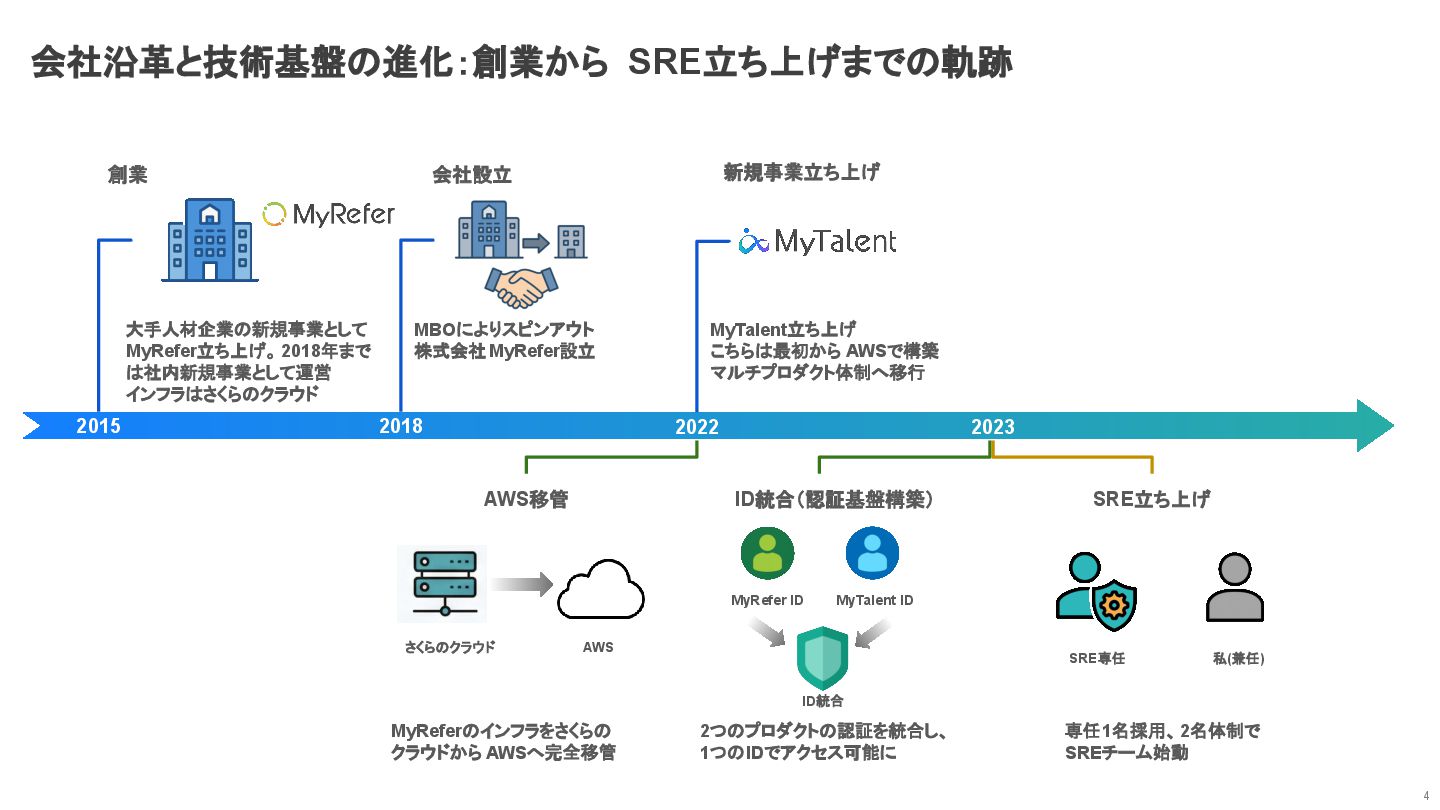
会社沿革と技術基盤の進化:創業から SRE立ち上げまでの軌跡 4 創業 2015 大手人材企業の新規事業として MyRefer立ち上げ。 2018年まで は社内新規事業として運営 インフラはさくらのクラウド
2018 会社設立 MBOによりスピンアウト 株式会社MyRefer設立 2022 新規事業立ち上げ MyTalent立ち上げ こちらは最初から AWSで構築 マルチプロダクト体制へ移行 AWS移管 さくらのクラウド AWS MyReferのインフラをさくらの クラウドから AWSへ完全移管 2023 ID統合(認証基盤構築) SRE立ち上げ MyRefer ID MyTalent ID ID統合 2つのプロダクトの認証を統合し、 1つのIDでアクセス可能に SRE専任 私(兼任) 専任1名採用、2名体制で SREチーム始動
アジェンダ 5 1. AWS移管前 2. AWS移管後 3. SRE立ち上げ
6 AWS移管前
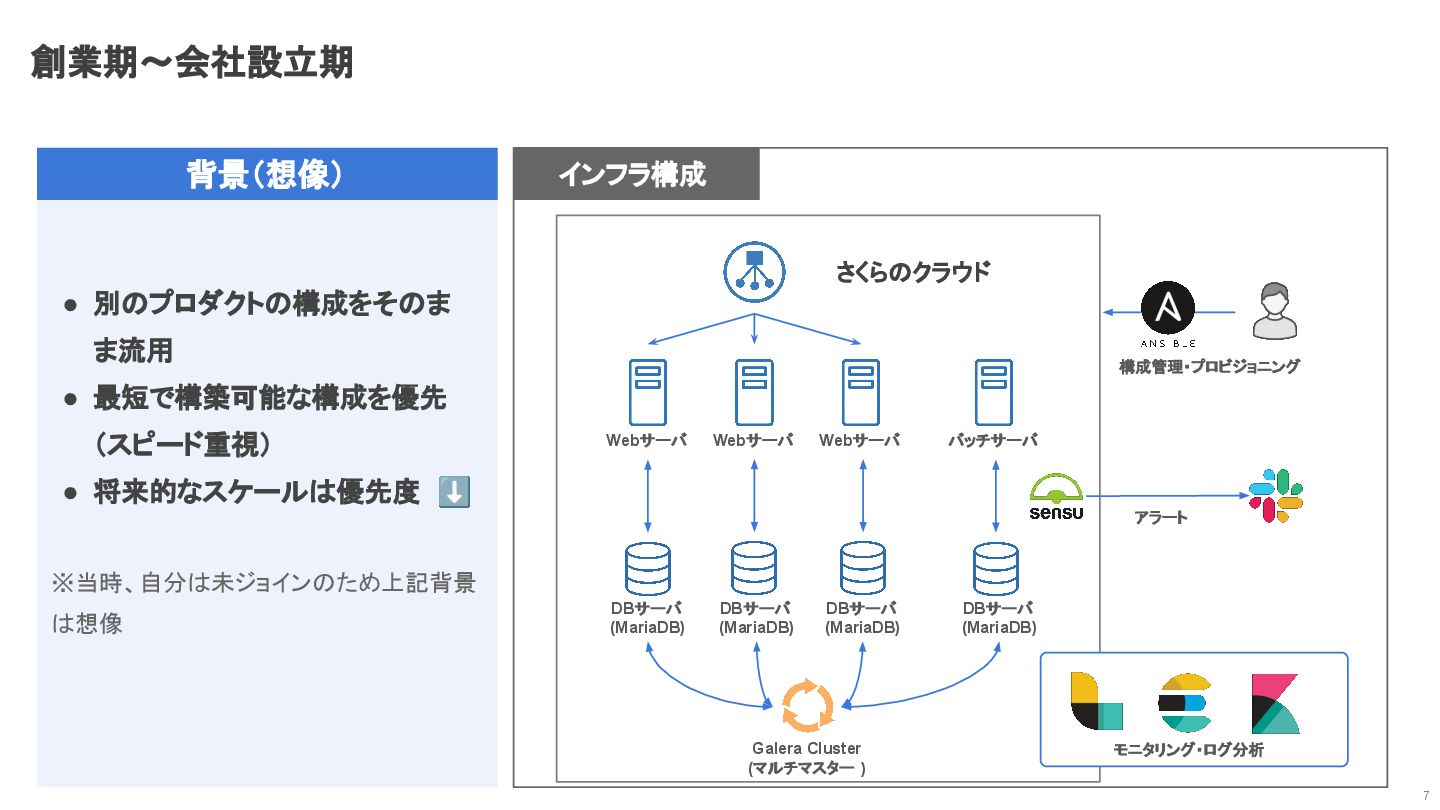
創業期〜会社設立期 7 背景(想像) • 別のプロダクトの構成をそのま ま流用 • 最短で構築可能な構成を優先 (スピード重視) •
将来的なスケールは優先度 ⬇ ※当時、自分は未ジョインのため上記背景 は想像 インフラ構成 さくらのクラウド Webサーバ Webサーバ Webサーバ DBサーバ (MariaDB) バッチサーバ DBサーバ (MariaDB) DBサーバ (MariaDB) DBサーバ (MariaDB) Galera Cluster (マルチマスター ) 構成管理・プロビジョニング アラート モニタリング・ログ分析
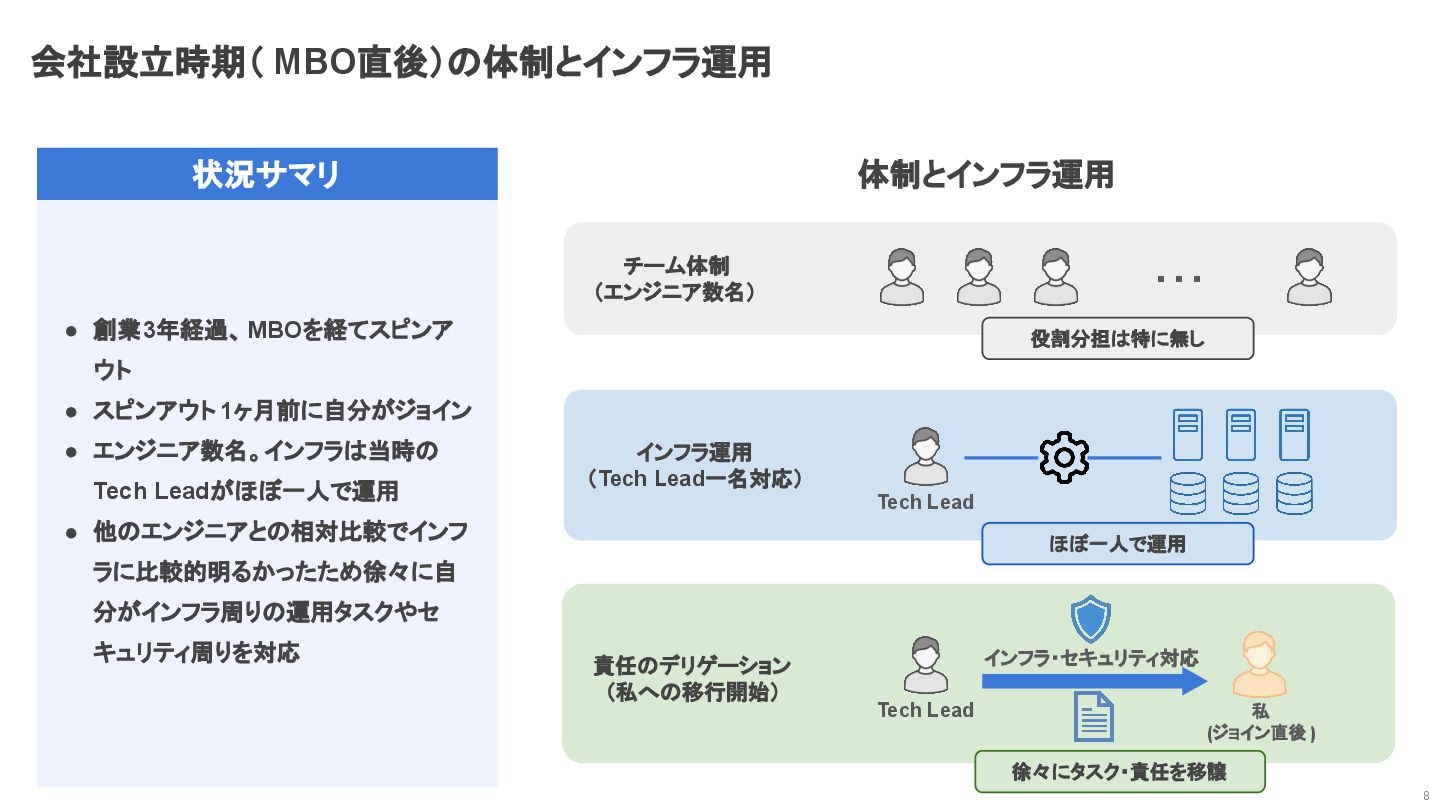
会社設立時期( MBO直後)の体制とインフラ運用 8 状況サマリ • 創業3年経過、MBOを経てスピンア ウト • スピンアウト 1ヶ月前に自分がジョイン
• エンジニア数名。インフラは当時の Tech Leadがほぼ一人で運用 • 他のエンジニアとの相対比較でインフ ラに比較的明るかったため徐々に自 分がインフラ周りの運用タスクやセ キュリティ周りを対応 体制とインフラ運用 チーム体制 (エンジニア数名) ・・・ 役割分担は特に無し インフラ運用 (Tech Lead一名対応) Tech Lead ほぼ一人で運用 責任のデリゲーション (私への移行開始) Tech Lead 私 (ジョイン直後 ) インフラ・セキュリティ対応 徐々にタスク・責任を移譲
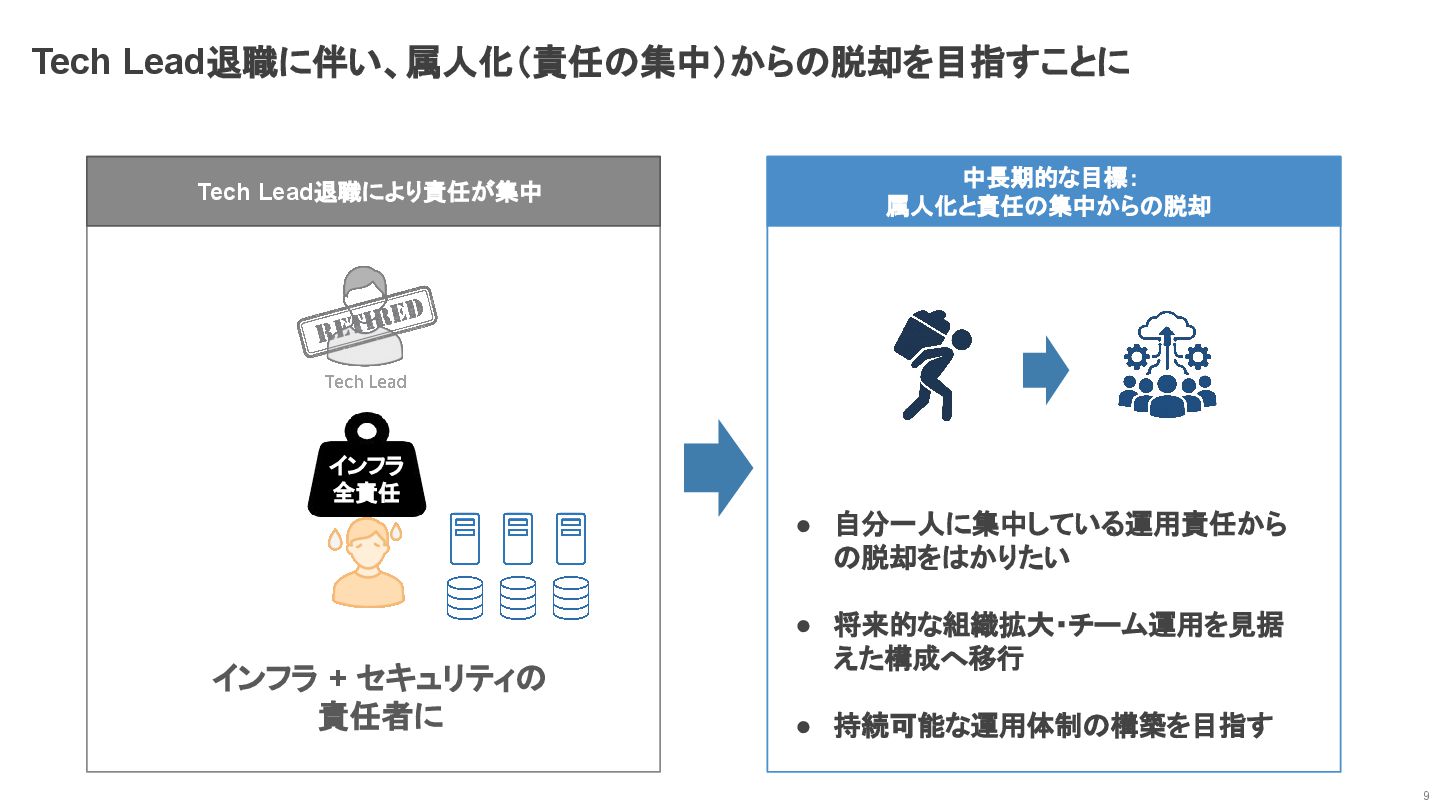
Tech Lead退職に伴い、属人化(責任の集中)からの脱却を目指すことに 9 Tech Lead退職により責任が集中 インフラ 全責任 インフラ + セキュリティの
責任者に 中長期的な目標: 属人化と責任の集中からの脱却 • 自分一人に集中している運用責任から の脱却をはかりたい • 将来的な組織拡大・チーム運用を見据 えた構成へ移行 • 持続可能な運用体制の構築を目指す
中長期的な視点とレガシー脱却のジレンマ 10 解決策のジレンマ: フルリプレイスの時間的制約 現状(当時)の課題: レガシーな構成による採用の壁 アプリケーション・インフラ共に かなりレガシーな構成 将来、エンジニア採用で苦戦が予想される 魅力不足、スキルミスマッチの懸念
フルリプレイスには相当の時間が必要 ビジネススピードは落とせない 一足飛びの解決は困難 将来を見据えつつ現実的な最適解を模索する必要があった
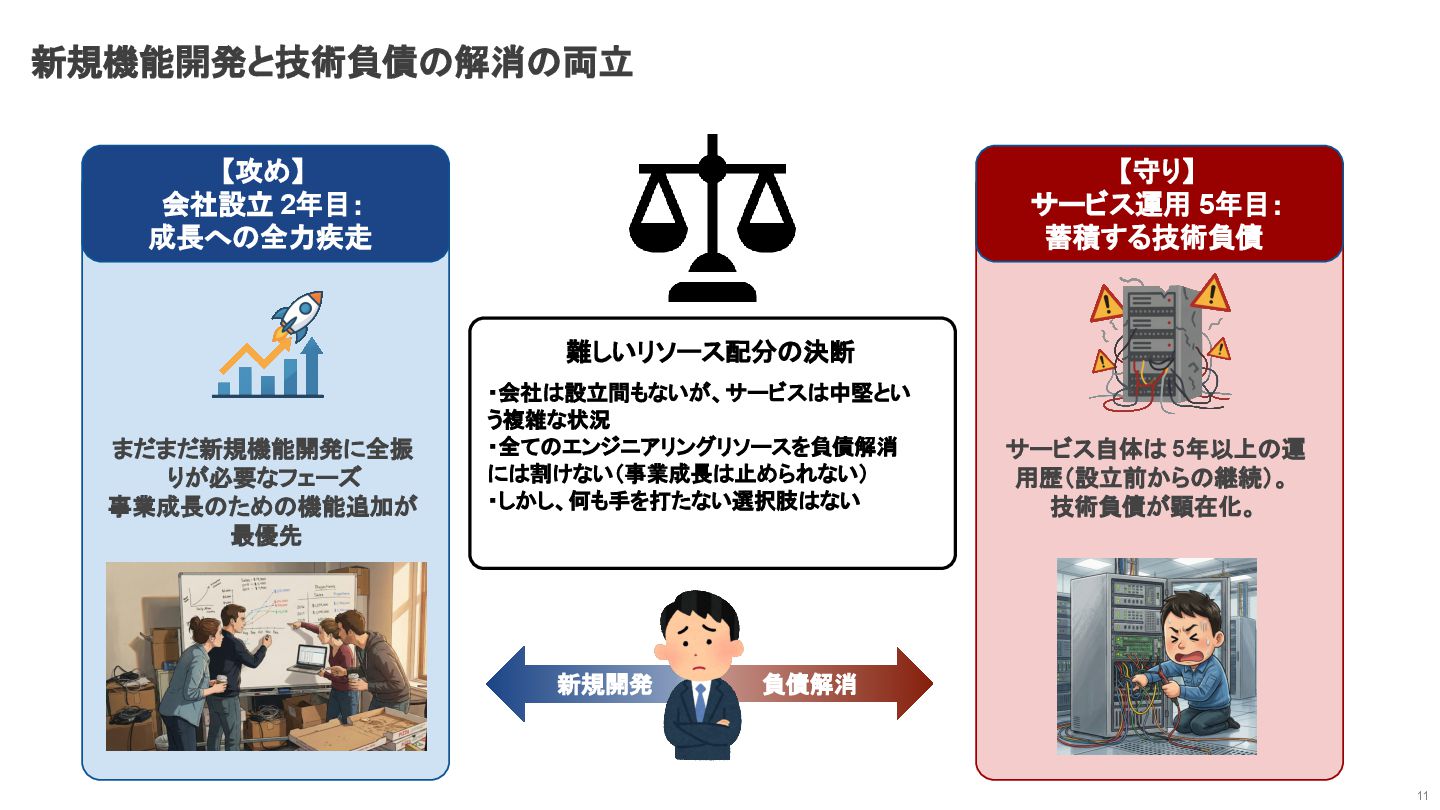
新規機能開発と技術負債の解消の両立 11 【攻め】 会社設立 2年目: 成長への全力疾走 まだまだ新規機能開発に全振 りが必要なフェーズ 事業成長のための機能追加が 最優先
難しいリソース配分の決断 ・会社は設立間もないが、サービスは中堅とい う複雑な状況 ・全てのエンジニアリングリソースを負債解消 には割けない(事業成長は止められない) ・しかし、何も手を打たない選択肢はない 新規開発 負債解消 【守り】 サービス運用 5年目: 蓄積する技術負債 サービス自体は 5年以上の運 用歴(設立前からの継続)。 技術負債が顕在化。
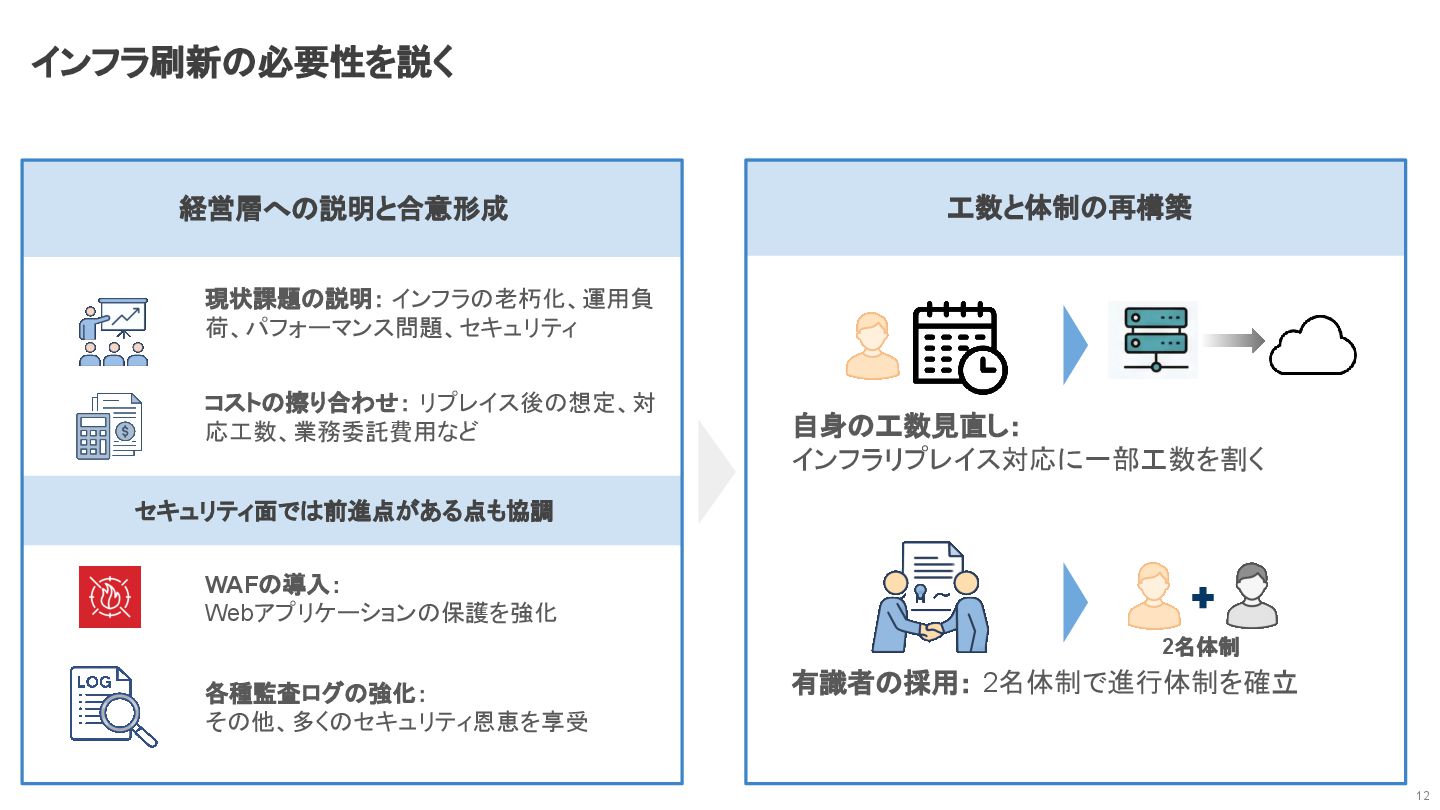
経営層への説明と合意形成 セキュリティ面では前進点がある点も協調 インフラ刷新の必要性を説く 12 現状課題の説明: インフラの老朽化、運用負 荷、パフォーマンス問題、セキュリティ コストの擦り合わせ: リプレイス後の想定、対 応工数、業務委託費用など
WAFの導入: Webアプリケーションの保護を強化 各種監査ログの強化: その他、多くのセキュリティ恩恵を享受 工数と体制の再構築 自身の工数見直し: インフラリプレイス対応に一部工数を割く 有識者の採用: 2名体制で進行体制を確立 2名体制
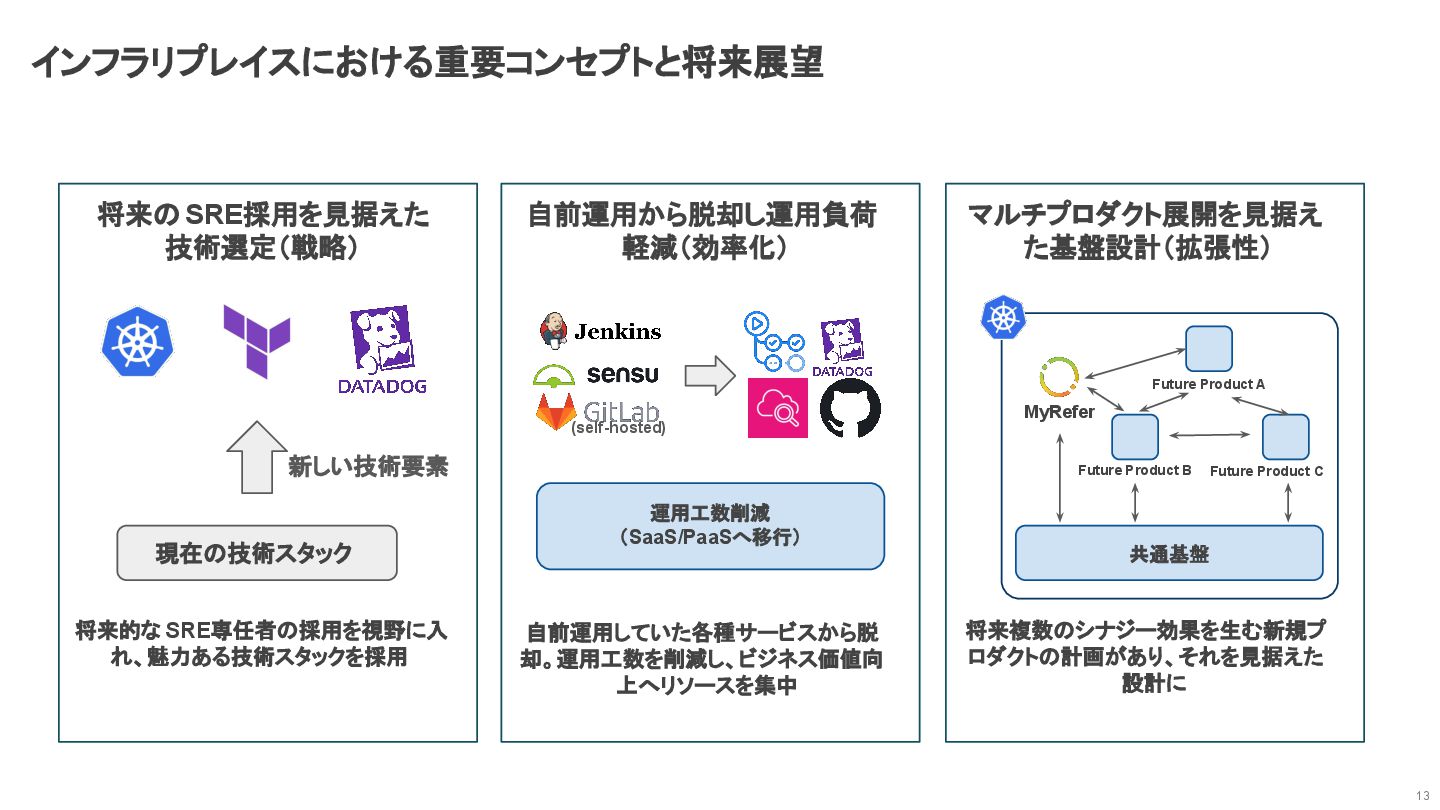
インフラリプレイスにおける重要コンセプトと将来展望 13 将来のSRE採用を見据えた 技術選定(戦略) 新しい技術要素 現在の技術スタック 将来的な SRE専任者の採用を視野に入 れ、魅力ある技術スタックを採用 自前運用から脱却し運用負荷
軽減(効率化) (self-hosted) 運用工数削減 (SaaS/PaaSへ移行) 自前運用していた各種サービスから脱 却。運用工数を削減し、ビジネス価値向 上へリソースを集中 マルチプロダクト展開を見据え た基盤設計(拡張性) MyRefer Future Product A Future Product C Future Product B 共通基盤 将来複数のシナジー効果を生む新規プ ロダクトの計画があり、それを見据えた 設計に
インフラリプレイスにおける重要コンセプトと将来展望 14 (self-hosted) 運用工数削減 (SaaS/PaaSへ移行) 自前運用していた各種サービスから脱 却。運用工数を削減し、ビジネス価値向 上へリソースを集中 自前運用から脱却し運用負荷 軽減(効率化)
MyRefer Future Product A Future Product C Future Product B 共通基盤 将来複数のシナジー効果を生む新規プ ロダクトの計画があり、それを見据えた 設計に マルチプロダクト展開を見据え た基盤設計(拡張性) 新しい技術要素 現在の技術スタック 将来的な SRE専任者の採用を視野に入 れ、魅力ある技術スタックを採用 将来のSRE採用を見据えた 技術選定(戦略)
振り返り: SRE採用を見据えた技術選定 15 新しい技術要素 現在の技術スタック 将来的な SRE専任者の採用を視野に入 れ、魅力ある技術スタックを採用 将来のSRE採用を見据えた 技術選定(戦略)
・結果論だが現在の SRE専任者は Terraformに精通 ・採用時に datadogやk8sの採用で一定の応募自体は獲得できた 良かった点:現在のSRE専任者の採用 ・0からのアーキテクチャ構築機会に欲が出た ・当時の身の丈に合わない選定をしてしまった 失敗した点:欲と流行の代償
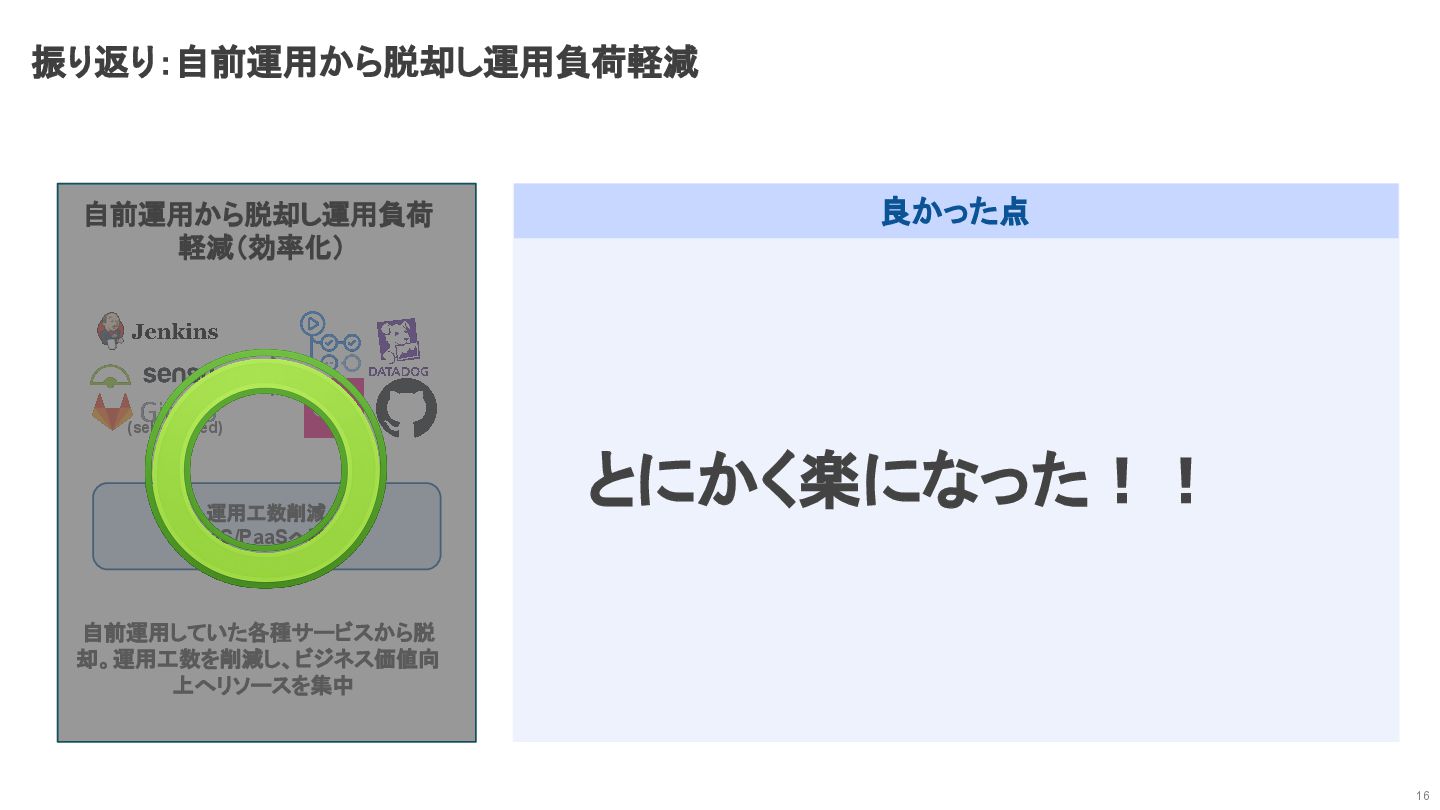
振り返り:自前運用から脱却し運用負荷軽減 16 とにかく楽になった!! 良かった点 (self-hosted) 運用工数削減 (SaaS/PaaSへ移行) 自前運用していた各種サービスから脱 却。運用工数を削減し、ビジネス価値向
上へリソースを集中 自前運用から脱却し運用負荷 軽減(効率化)
振り返り:マルチプロダクト展開を見据えた基盤設計 17 MyRefer Future Product A Future Product C Future
Product B 共通基盤 将来複数のシナジー効果を生む新規プ ロダクトの計画があり、それを見据えた 設計に マルチプロダクト展開を見据え た基盤設計(拡張性) 背景と目的:将来的なシナジー創出を見据えて ・複数プロダクト連携による相乗効果(シナジー)の創出を計画 ・新規事業の迅速な立ち上げと即時連携が可能な状態が目標 アーキテクチャ選定の背景 ・モダンな技術トレンドへの意識 ・プロダクト横断の「共通 API」 ・将来的な ID統合を見据える EKSをベースとした マイクロサービスライク な構成
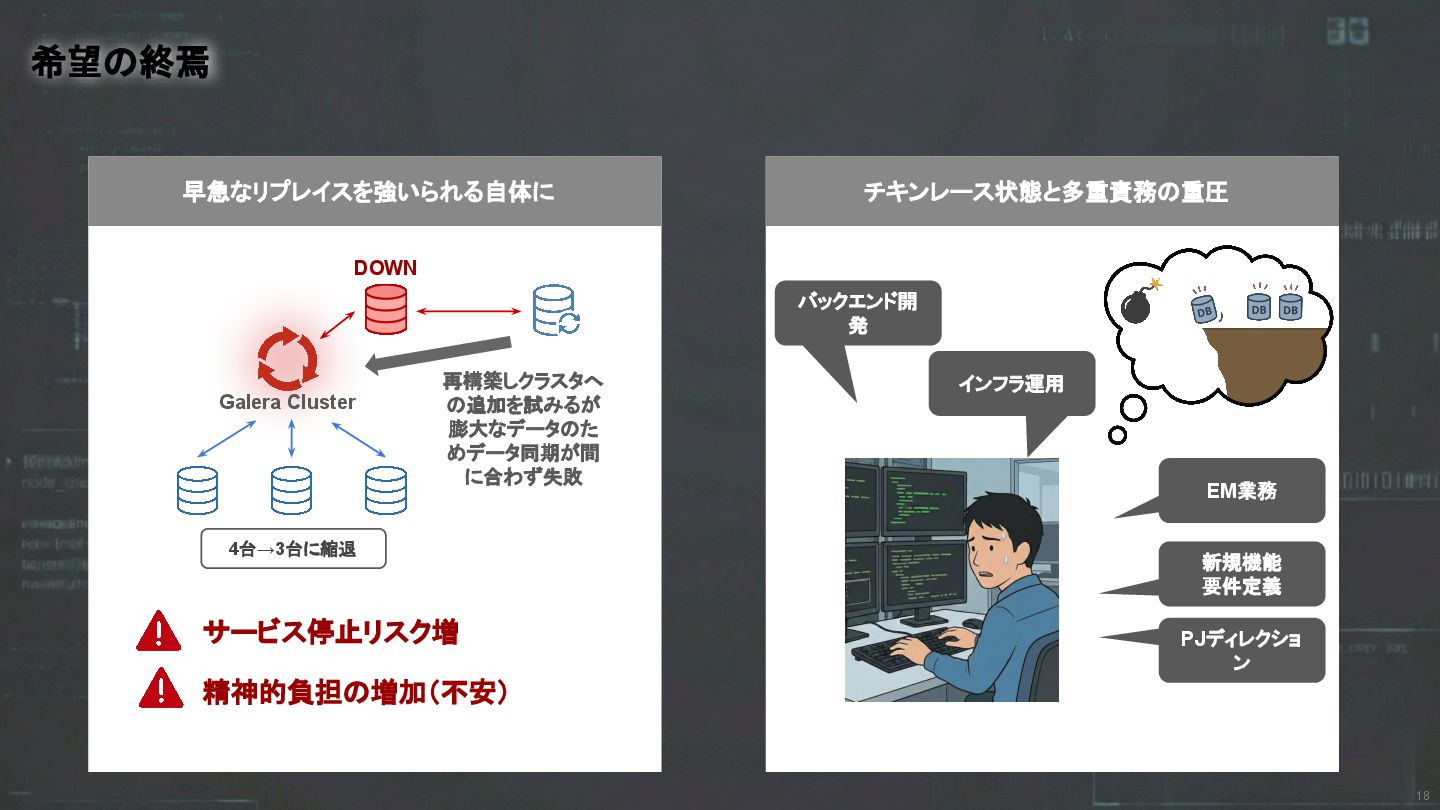
チキンレース状態と多重責務の重圧 18 希望の終焉 早急なリプレイスを強いられる自体に Galera Cluster DOWN 再構築しクラスタへ の追加を試みるが 膨大なデータのた
めデータ同期が間 に合わず失敗 4台→3台に縮退 サービス停止リスク増 精神的負担の増加(不安) バックエンド開 発 インフラ運用 新規機能 要件定義 PJディレクショ ン EM業務
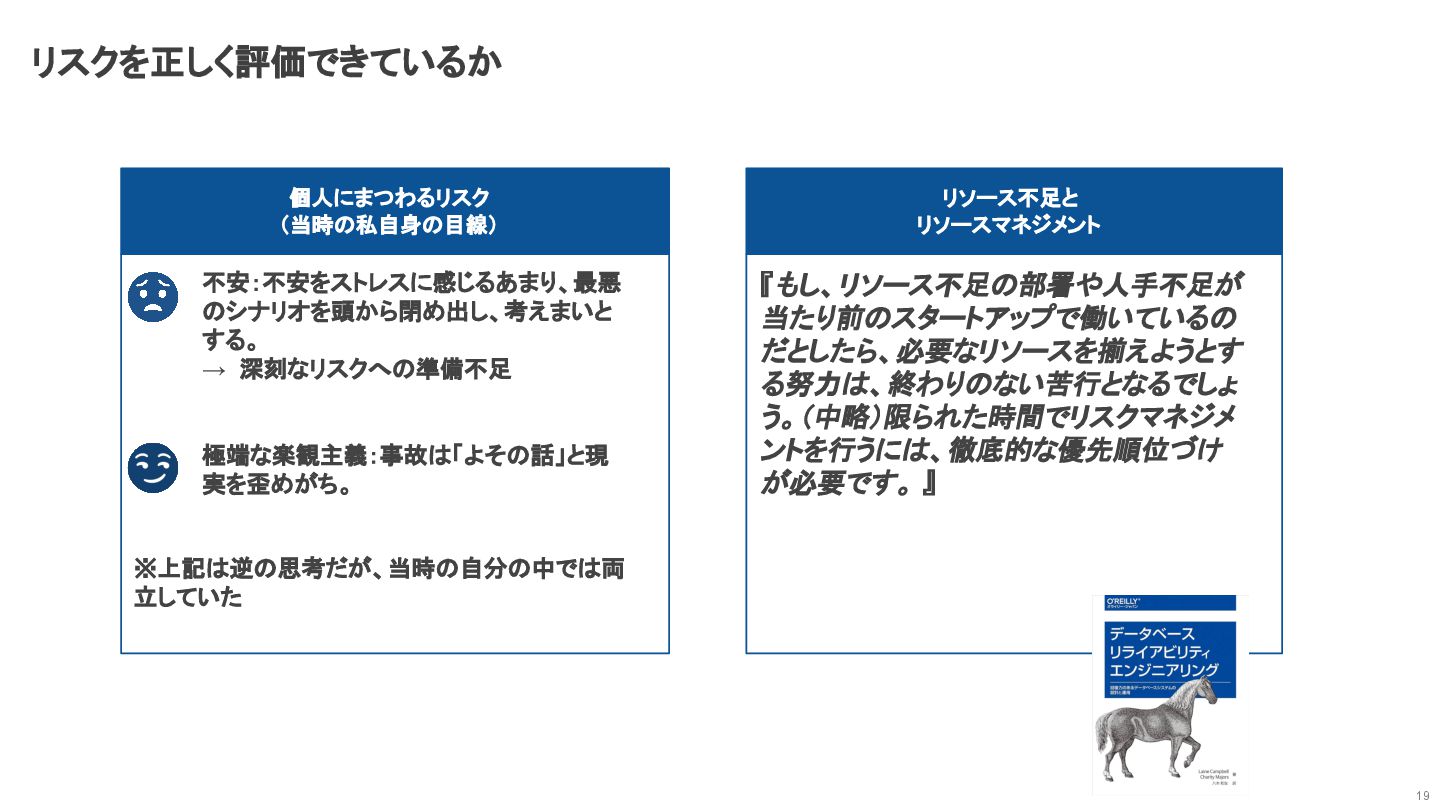
リスクを正しく評価できているか 19 個人にまつわるリスク (当時の私自身の目線) 不安:不安をストレスに感じるあまり、最悪 のシナリオを頭から閉め出し、考えまいと する。 → 深刻なリスクへの準備不足
極端な楽観主義:事故は「よその話」と現 実を歪めがち。 リソース不足と リソースマネジメント 『もし、リソース不足の部署や人手不足が 当たり前のスタートアップで働いているの だとしたら、必要なリソースを揃えようとす る努力は、終わりのない苦行となるでしょ う。(中略)限られた時間でリスクマネジメ ントを行うには、徹底的な優先順位づけ が必要です。 』 ※上記は逆の思考だが、当時の自分の中では両 立していた
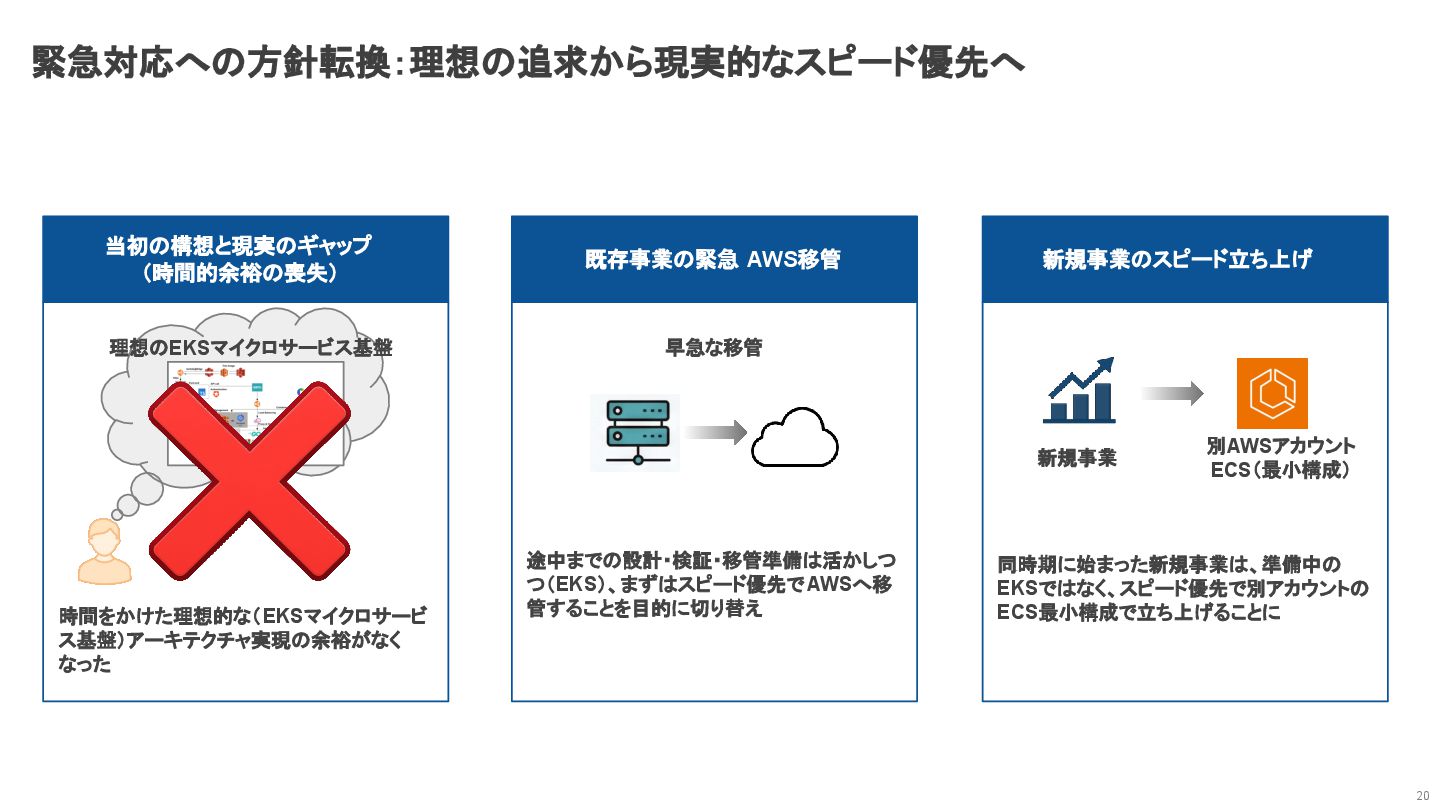
緊急対応への方針転換:理想の追求から現実的なスピード優先へ 20 当初の構想と現実のギャップ (時間的余裕の喪失) 理想のEKSマイクロサービス基盤 時間をかけた理想的な(EKSマイクロサービ ス基盤)アーキテクチャ実現の余裕がなく なった 既存事業の緊急 AWS移管
早急な移管 途中までの設計・検証・移管準備は活かしつ つ(EKS)、まずはスピード優先でAWSへ移 管することを目的に切り替え 新規事業のスピード立ち上げ 新規事業 別AWSアカウント ECS(最小構成) 同時期に始まった新規事業は、準備中の EKSではなく、スピード優先で別アカウントの ECS最小構成で立ち上げることに
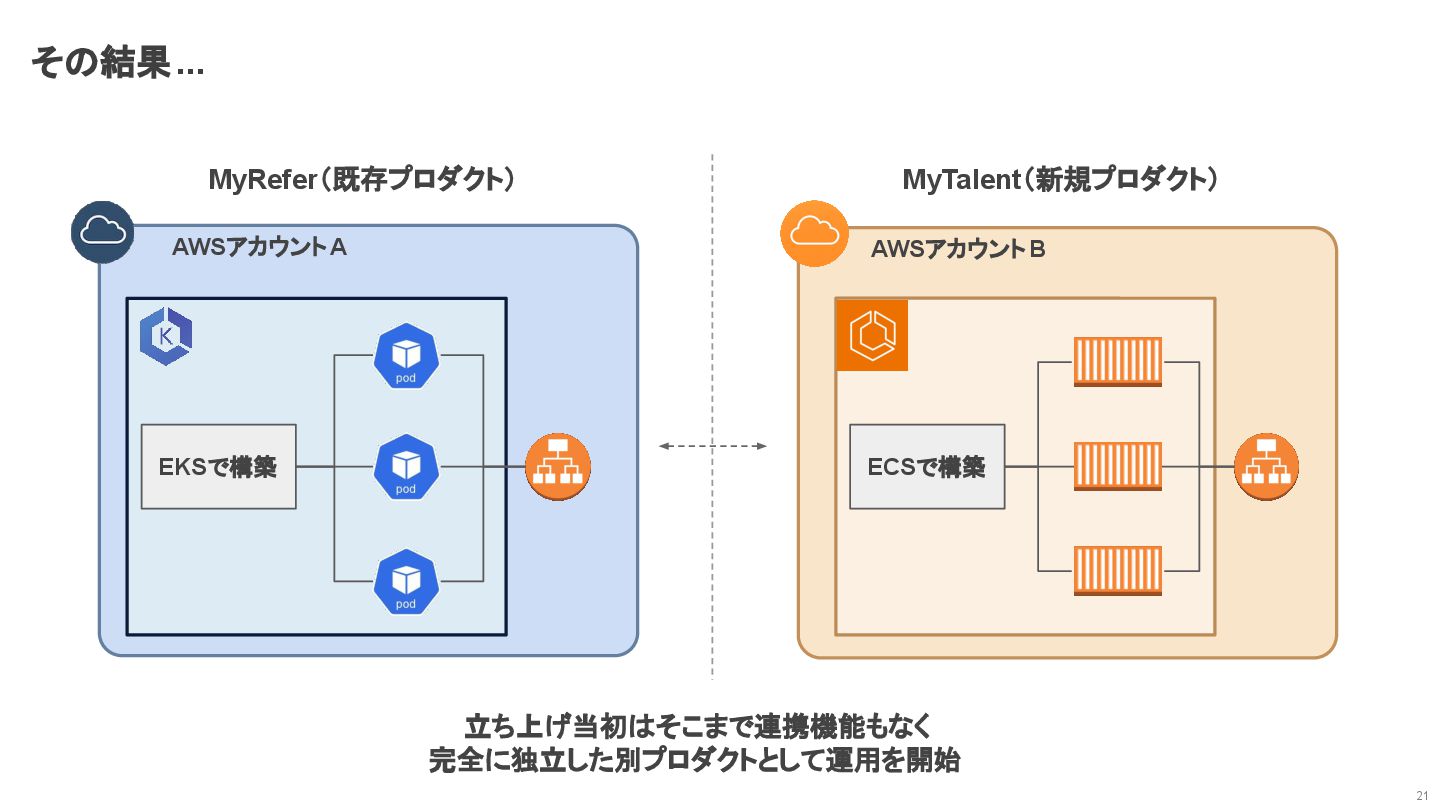
その結果... 21 MyRefer(既存プロダクト) AWSアカウント A MyTalent(新規プロダクト) AWSアカウント B EKSで構築 ECSで構築
立ち上げ当初はそこまで連携機能もなく 完全に独立した別プロダクトとして運用を開始
22 AWS移管後
23 (妥協案ではあるが) 無事移管完遂!精神的重圧から解放 一旦の構成とはいえ、移管を機に SRE的な活動にも注力 まずはSLI/SLOを定義し、可視化するところからトライを開始
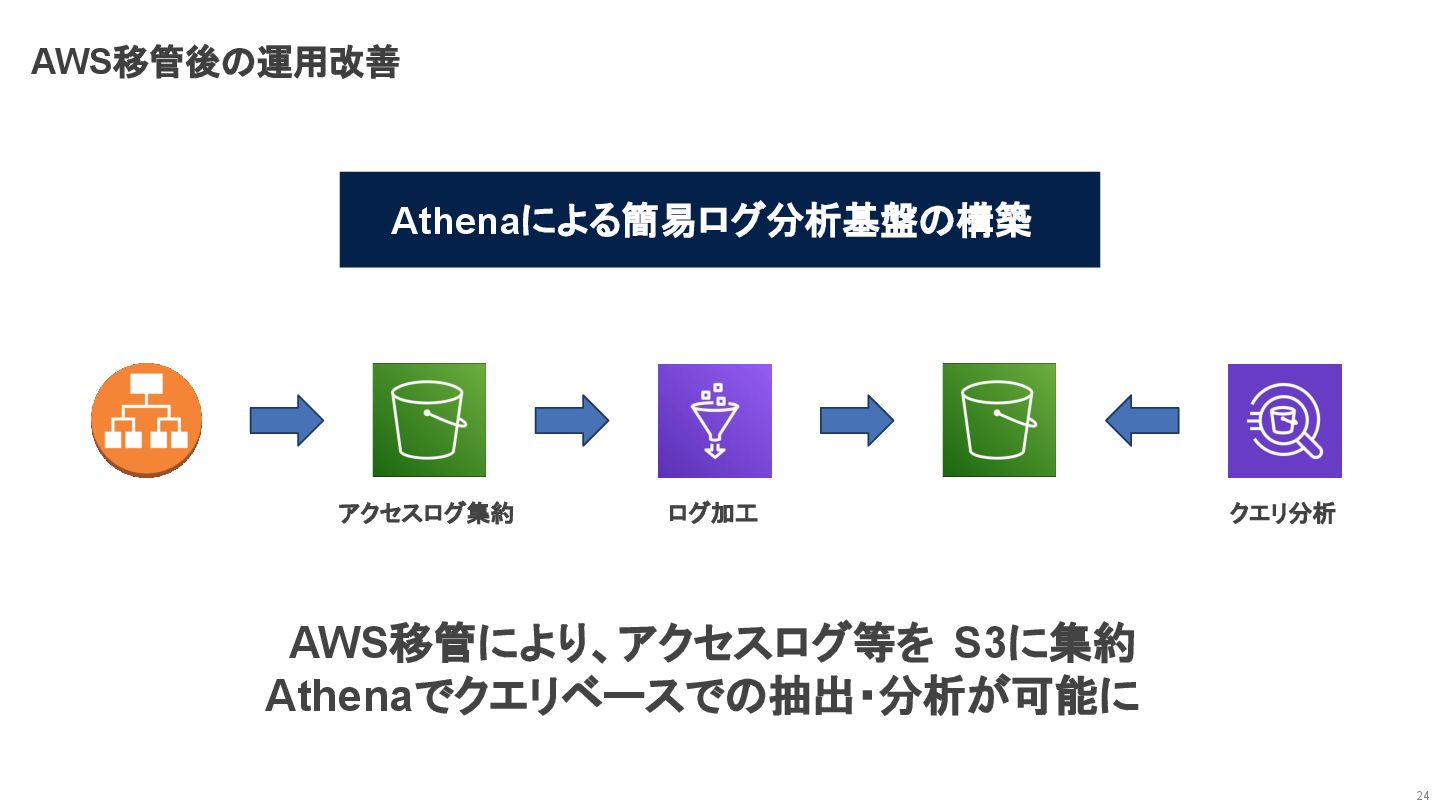
AWS移管後の運用改善 24 アクセスログ集約 ログ加工 クエリ分析 AWS移管により、アクセスログ等を S3に集約 Athenaでクエリベースでの抽出・分析が可能に Athenaによる簡易ログ分析基盤の構築
AWS移管後の運用改善 25 セキュリティチェックで SLAの有無やSLOについての設問が多く SLOを策定すべく動き出す 当時検討(理想) 現実 API API …
API … 重さ … API特性に応じた重要度係数など、より顧客体験に直 結した定義が理想だが、複雑で管理負荷が高い 顧客体験ベースの稼働率 稼働率 = 100% まずはシンプルに、全リクエストに対する 5xxエラー率 をベースに稼働率を定義し、可視化・観測を開始
26 SRE活動に腰を据えて 取り組もうとしたが
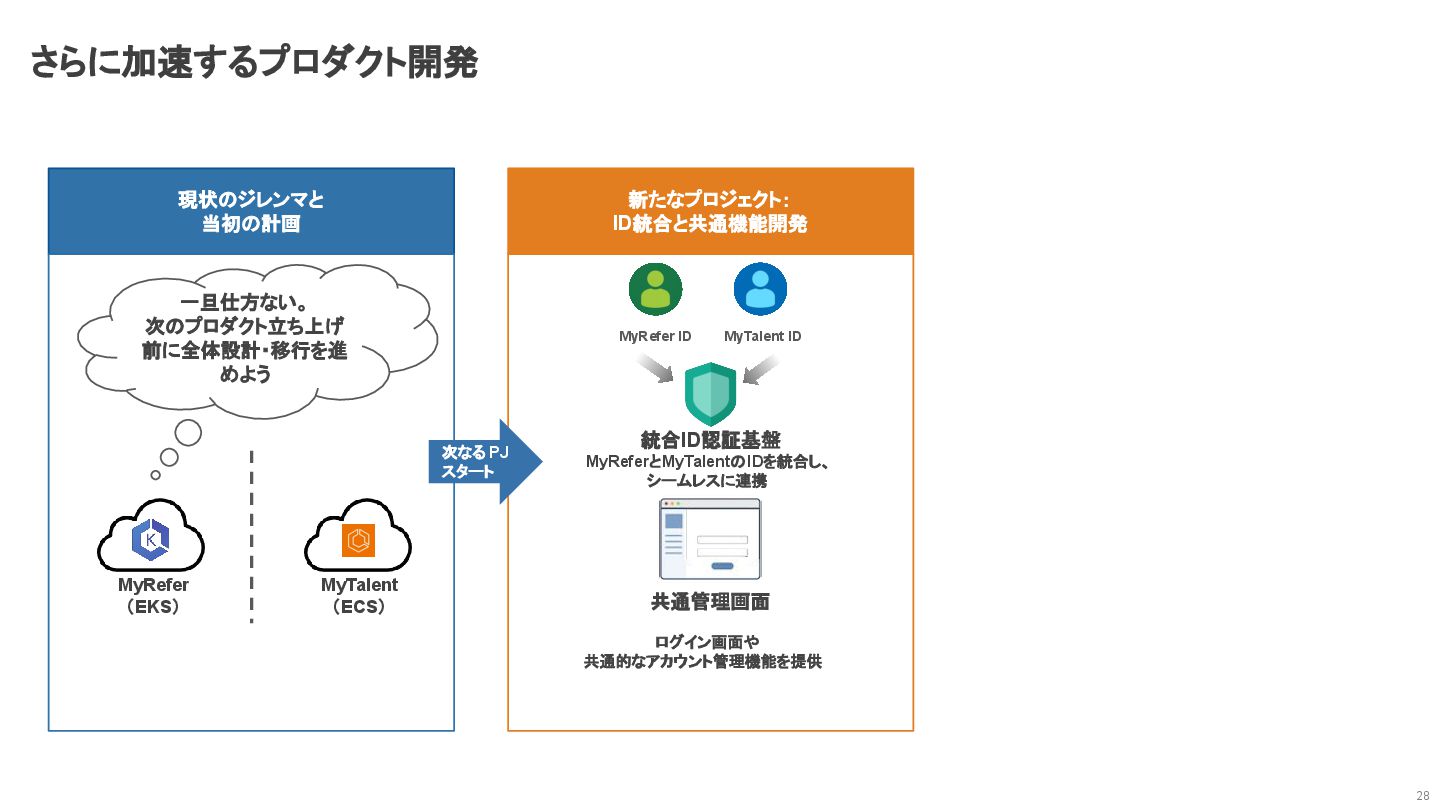
さらに加速するプロダクト開発 27 現状のジレンマと 当初の計画 一旦仕方ない。 次のプロダクト立ち上げ 前に全体設計・移行を進 めよう MyRefer (EKS)
MyTalent (ECS)
さらに加速するプロダクト開発 28 新たなプロジェクト: ID統合と共通機能開発 MyRefer ID MyTalent ID 統合ID認証基盤 MyReferとMyTalentのIDを統合し、
シームレスに連携 現状のジレンマと 当初の計画 一旦仕方ない。 次のプロダクト立ち上げ 前に全体設計・移行を進 めよう MyRefer (EKS) MyTalent (ECS) 次なる PJ スタート 共通管理画面 ログイン画面や 共通的なアカウント管理機能を提供
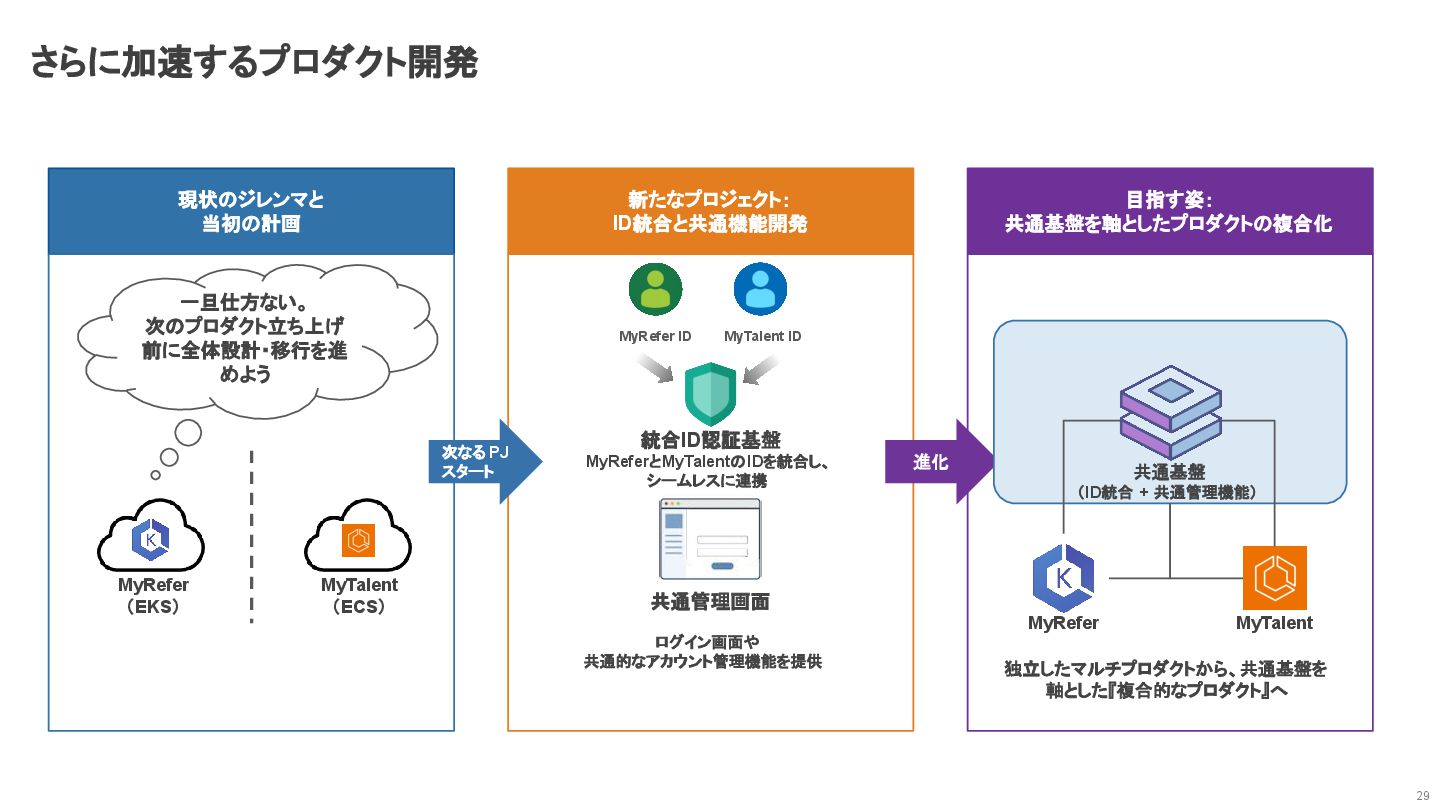
さらに加速するプロダクト開発 29 現状のジレンマと 当初の計画 一旦仕方ない。 次のプロダクト立ち上げ 前に全体設計・移行を進 めよう MyRefer (EKS)
MyTalent (ECS) 目指す姿: 共通基盤を軸としたプロダクトの複合化 進化 MyRefer MyTalent 共通基盤 (ID統合 + 共通管理機能) 独立したマルチプロダクトから、共通基盤を 軸とした『複合的なプロダクト』へ 新たなプロジェクト: ID統合と共通機能開発 MyRefer ID MyTalent ID 統合ID認証基盤 MyReferとMyTalentのIDを統合し、 シームレスに連携 共通管理画面 ログイン画面や 共通的なアカウント管理機能を提供 次なる PJ スタート
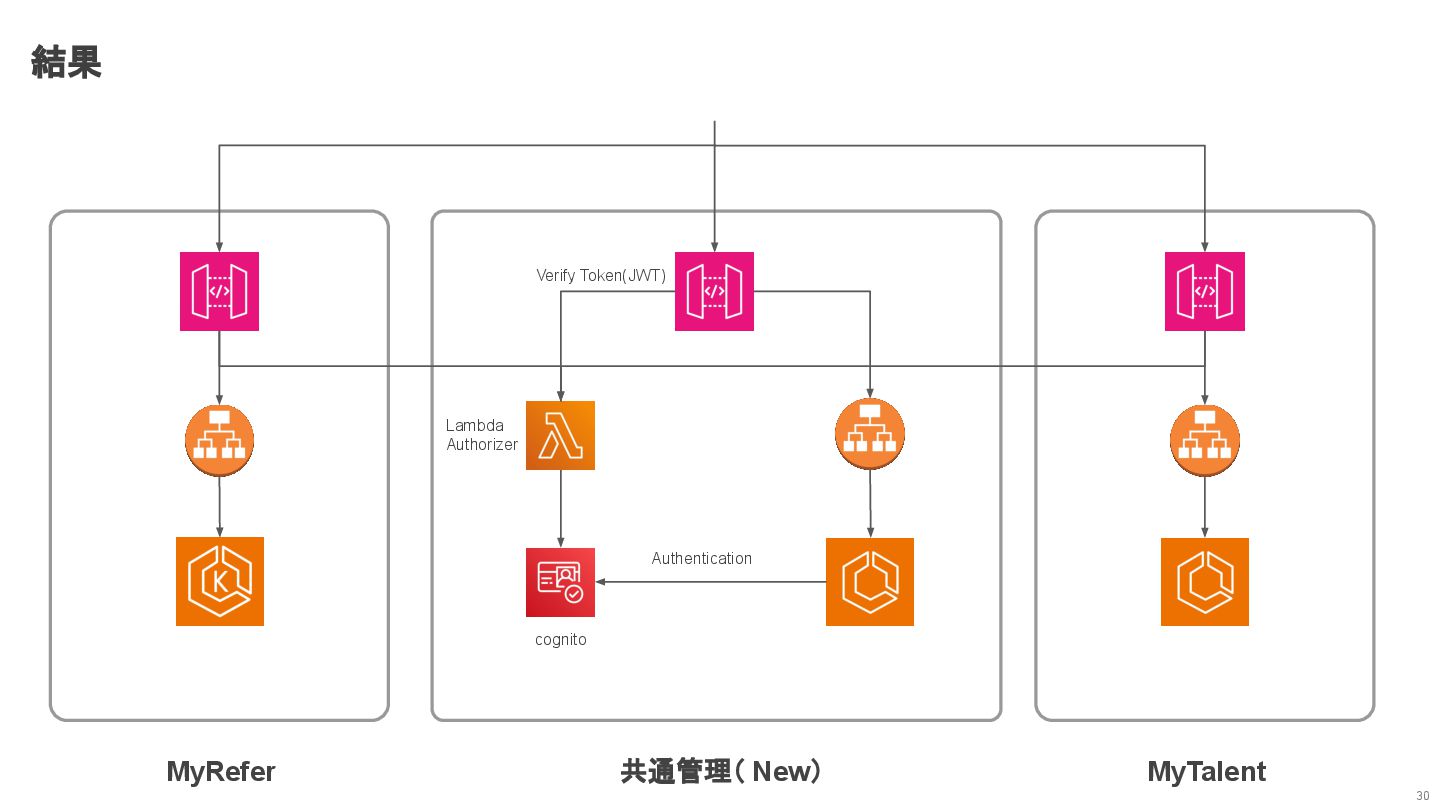
結果 30 MyRefer MyTalent 共通管理( New) Lambda Authorizer cognito Verify
Token(JWT) Authentication
31 SRE立ち上げ
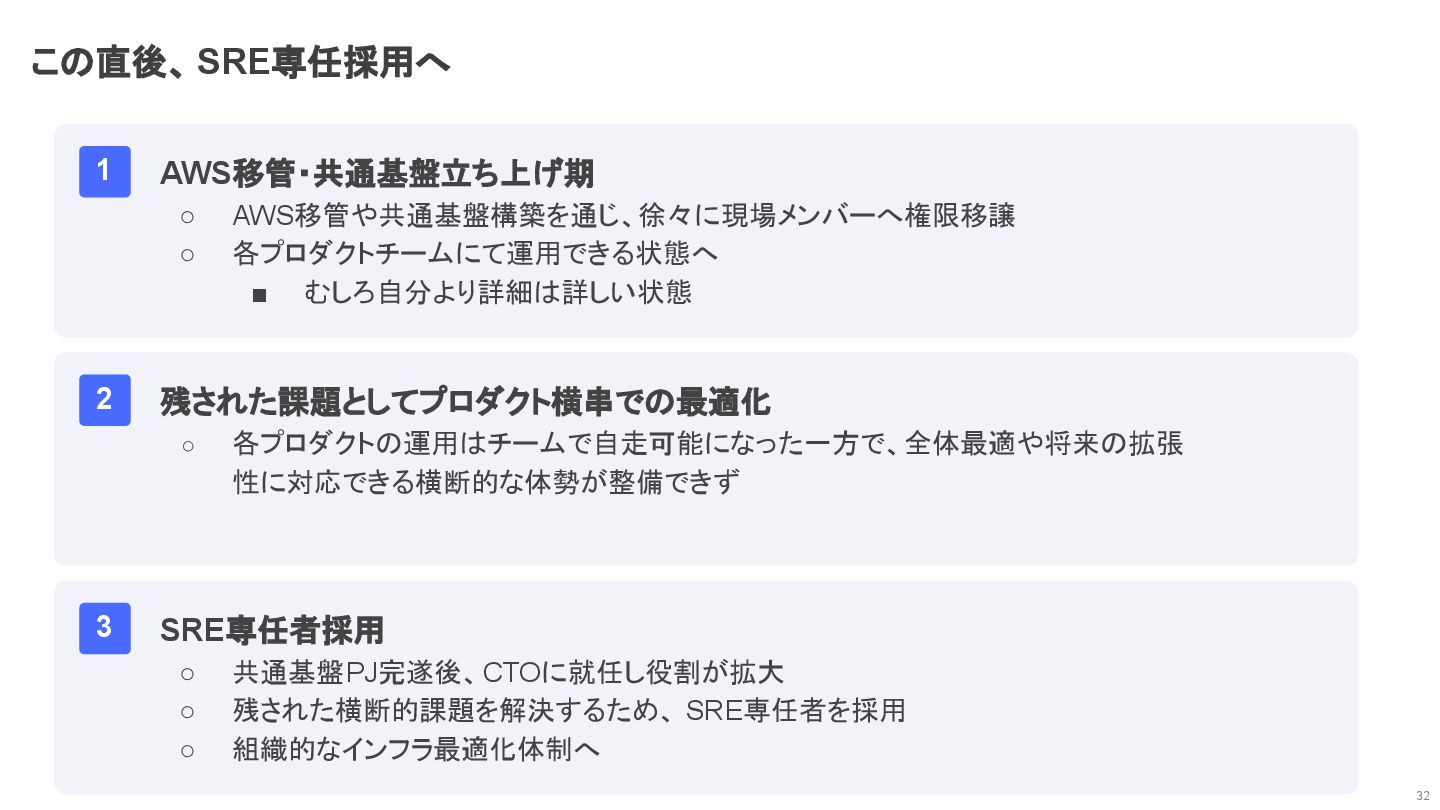
この直後、 SRE専任採用へ 32 AWS移管・共通基盤立ち上げ期 ◦ AWS移管や共通基盤構築を通じ、徐々に現場メンバーへ権限移譲 ◦ 各プロダクトチームにて運用できる状態へ ▪ むしろ自分より詳細は詳しい状態
1 • 残された課題としてプロダクト横串での最適化 ◦ 各プロダクトの運用はチームで自走可能になった一方で、全体最適や将来の拡張 性に対応できる横断的な体勢が整備できず 2 • SRE専任者採用 ◦ 共通基盤PJ完遂後、CTOに就任し役割が拡大 ◦ 残された横断的課題を解決するため、 SRE専任者を採用 ◦ 組織的なインフラ最適化体制へ 3
SRE専任チーム立ち上げた後、着手した内容 33 ① モニタリング整備と SLI/SLOを各チームで意識する文化醸成 ② インフラコストのモニタリング強化とコストカット施策の実行 ③ 体系的なセキュリティ強化 ④
IaC周りの整備
① モニタリング整備と SLI/SLOを各チームで意識する文化醸成 34 APIの5xx系のレスポンス率をベースに可視化はしていたが、「とりあえず見てみよう」というレベル。 チームでその数字を意識するところまで文化醸成できておらず、ほぼ形骸化。 Before :APIベースでの稼働率の「とりあえず」可視化 After :目的を再定義し、開発チームのアクションに連動するように設計
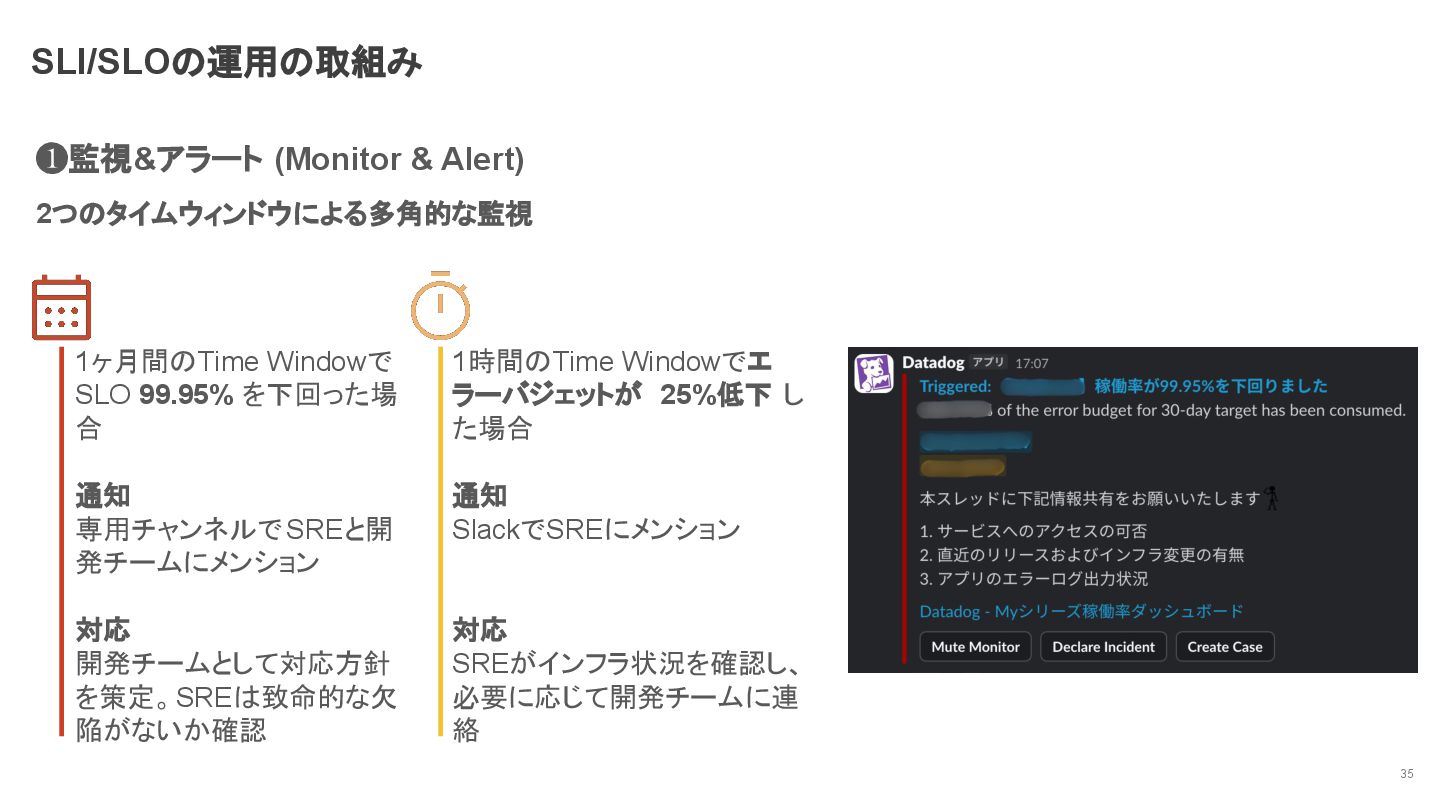
SREだけではなく開発チームが意識する SLOが満たされない状況を開発チームが自ら回避できる SLOを下回った際に開発チームがアクションできる 目的を明確に 目的を満たすために、アクセスログのステータスコードだ けに収まらない範囲での SLI/SLOを定義し、モニタリング を強化する方針もあった モニタリング強化の優先度や時間軸の関係でまずは現状 のSLI/SLOで文化醸成する方向とした SLI/SLO自体は変えずに文化醸成にフォーカス
1時間のTime Windowでエ ラーバジェットが 25%低下 し た場合 通知 SlackでSREにメンション 対応 SREがインフラ状況を確認し、
必要に応じて開発チームに連 絡 1ヶ月間のTime Windowで SLO 99.95% を下回った場 合 通知 専用チャンネルでSREと開 発チームにメンション 対応 開発チームとして対応方針 を策定。SREは致命的な欠 陥がないか確認 ❶監視&アラート (Monitor & Alert) 2つのタイムウィンドウによる多角的な監視 SLI/SLOの運用の取組み 35
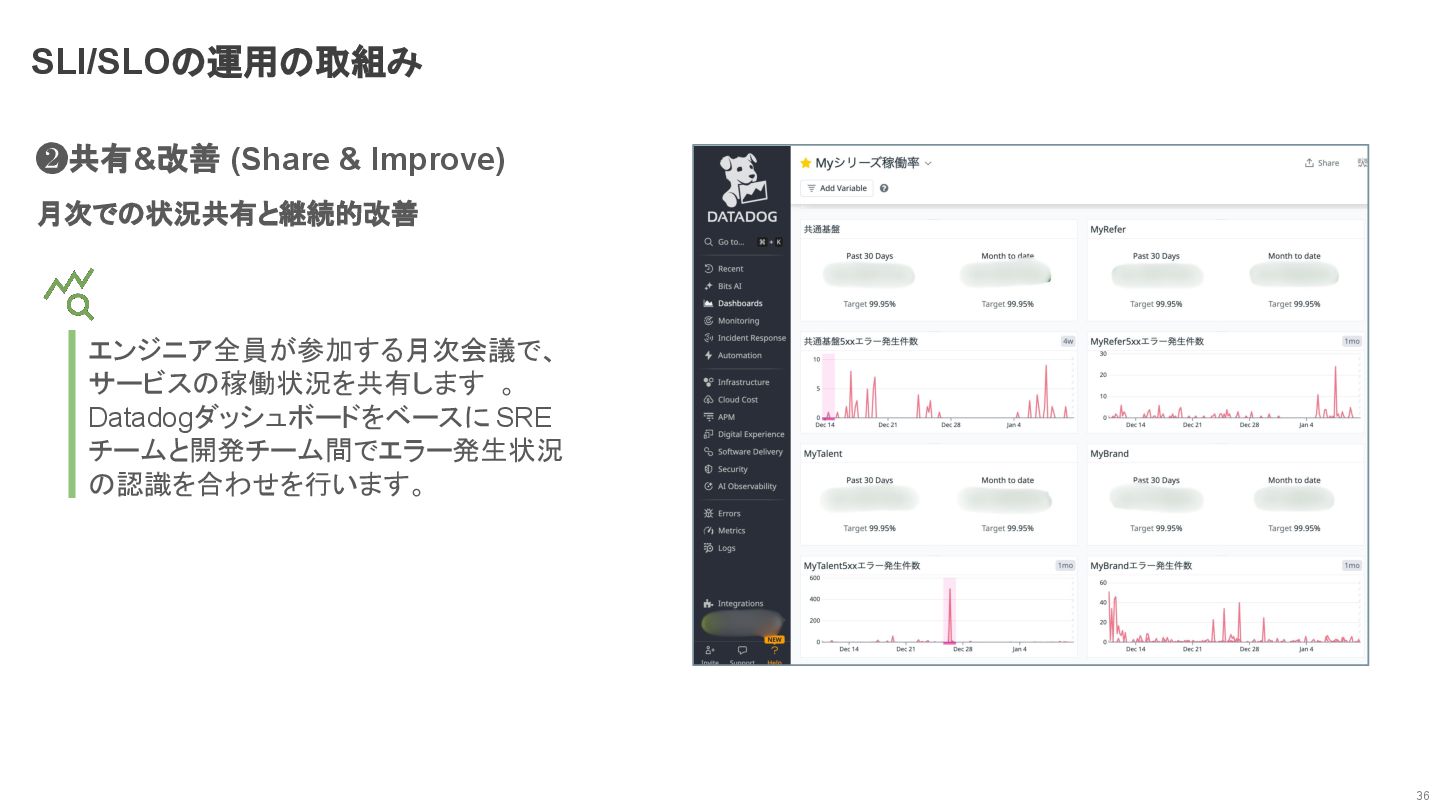
❷共有&改善 (Share & Improve) 月次での状況共有と継続的改善 36 SLI/SLOの運用の取組み エンジニア全員が参加する月次会議で、 サービスの稼働状況を共有します 。
Datadogダッシュボードをベースに SRE チームと開発チーム間でエラー発生状況 の認識を合わせを行います。
② インフラコストのモニタリング強化とコストカット施策の実行 37 直近1年の実績をベースに、感覚的な予算策定 「これくらいに抑えれればいいな」というザックリとした目標 Before :インフラコストに関して感覚的な予測と管理 After :計画的・経営連動型の最適化 ①
多角的な妥当性評価 プロダクトごとの構成差や、MRR比で の妥当性など、多角的な観点で計画 を再精査 ② 経営との連動 RIやSaving Planの前払い条件(期 間、率)などを経営と連動して戦略的 に決定 足元のキャッシュ優先 or 中長期目 線での支出抑制優先など ③ 運用方針の明確化 極限までのコスト削減ではなく、予測 超過時にコスパの良い削減策を検討 ・実行する方針へ
DashBoard 前月と比較したサービス毎の使 用料金上昇率を把握 予算(Budget) 当月のAWS予算に対する利用 料金の着地予測を週次の振り返 りで確認 コスト異常検知 予定外の新規リソース作成およ び通常の利用と異なる料金の発
生を検知 インフラコストのコスト監視に関する運用方針 最もビジネスインパクト があり、かつ金額の変動リスクのあるAWS料金を中心に監視し 予期せぬ高騰を早期に検知 する 活用する AWS Cost Explorerの機能
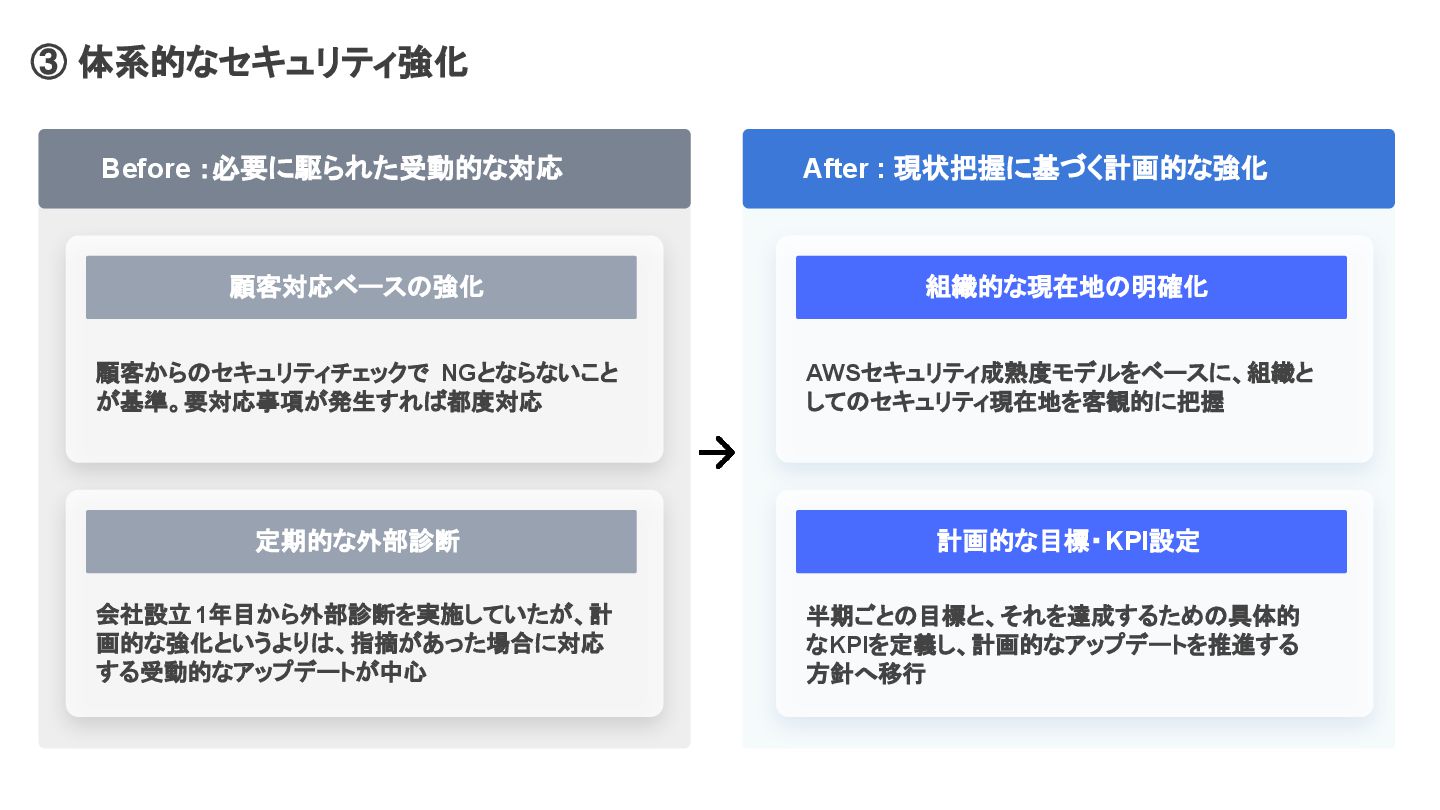
③ 体系的なセキュリティ強化 Before :必要に駆られた受動的な対応 After : 現状把握に基づく計画的な強化 AWSセキュリティ成熟度モデルをベースに、組織と してのセキュリティ現在地を客観的に把握 組織的な現在地の明確化
半期ごとの目標と、それを達成するための具体的 なKPIを定義し、計画的なアップデートを推進する 方針へ移行 計画的な目標・KPI設定 顧客からのセキュリティチェックで NGとならないこと が基準。要対応事項が発生すれば都度対応 顧客対応ベースの強化 会社設立1年目から外部診断を実施していたが、計 画的な強化というよりは、指摘があった場合に対応 する受動的なアップデートが中心 定期的な外部診断
AWS成熟度モデルに基づく 体系的アプローチ 優先順位付けによる最適化 : セキュリティ対策の導入に明確な優先順位を付 け、リスク軽減とコストパフォーマンスを両立 さ せる プロダクト横断での標準化 :
全てのプロダクトに共通のセキュリティ施策を 横断的に実装 し、 プラットフォーム全体のセキュリティレベルを底 上げする AWS成熟度モデルの採用 40 セキュリティ運用の 戦略的課題 スコープの曖昧さ : セキュリティ施策は、投資対効果を考慮しつつ 「何 をどこまでやるか」 を見極めるのが本質的に難しい 複合型プロダクトの特性 : 当社プラットフォームは複数のプロダクトで構成され るため、特定プロダクトのセキュリティだけが完璧 でも意味はない
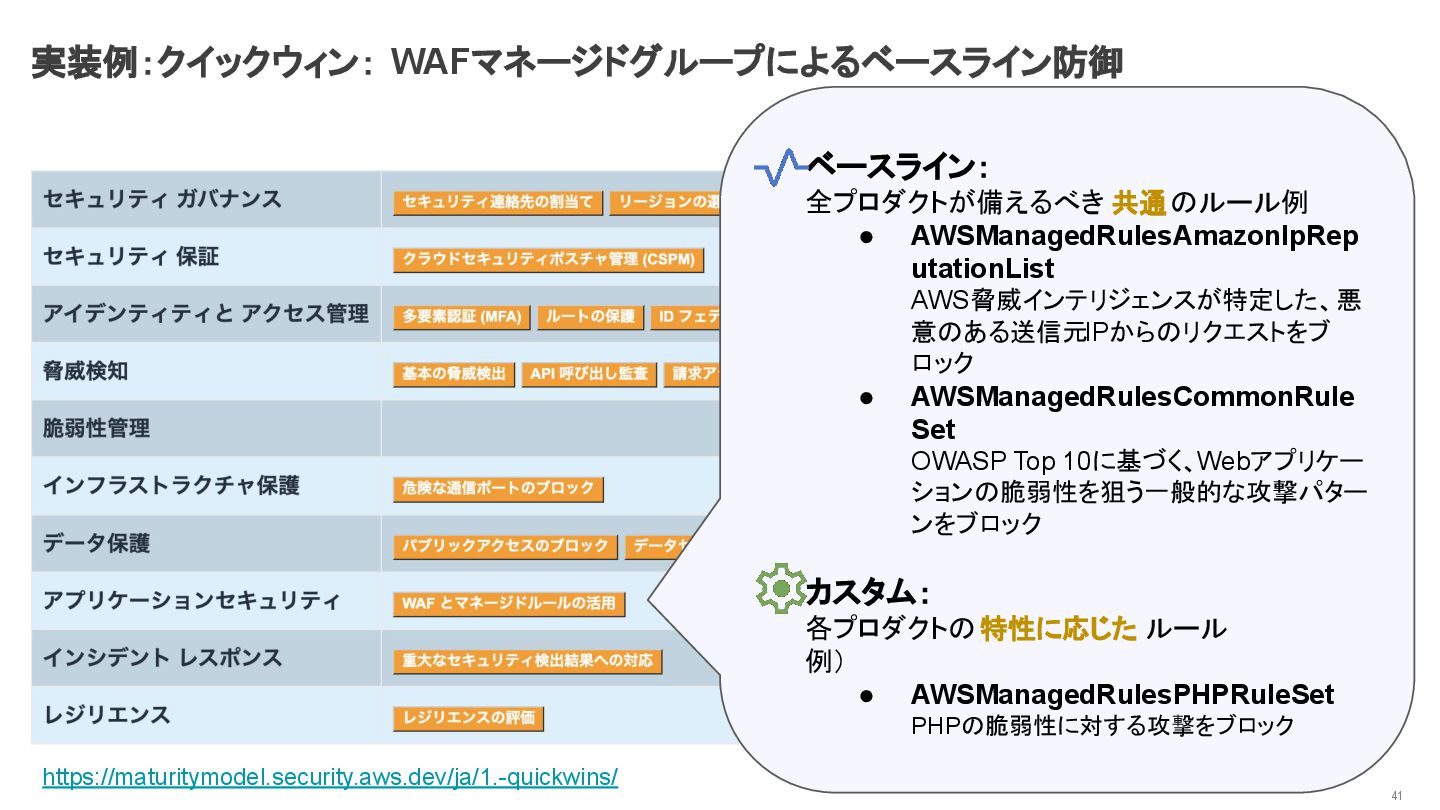
実装例:クイックウィン: WAFマネージドグループによるベースライン防御 41 ベースライン: 全プロダクトが備えるべき 共通のルール例 • AWSManagedRulesAmazonIpRep
utationList AWS脅威インテリジェンスが特定した、悪 意のある送信元IPからのリクエストをブ ロック • AWSManagedRulesCommonRule Set OWASP Top 10に基づく、Webアプリケー ションの脆弱性を狙う一般的な攻撃パター ンをブロック カスタム: 各プロダクトの特性に応じた ルール 例) • AWSManagedRulesPHPRuleSet PHPの脆弱性に対する攻撃をブロック https://maturitymodel.security.aws.dev/ja/1.-quickwins/
④ IaC周りの整備 42 AWS移管は手作業も多く、実際のリソースからコード化するところで止まっていた 再現性や拡張性に課題があった Before :手作業での構築と後追いのコード化 After :再現性の確保とモジュール化による標準化 ①
新プロダクトでの再現 今後の新規プロダクト立ち上げに備 え、新規AWSアカウントに同等の構 成を迅速に作成できる状態へ改善。 ② Moduleの導入・整備 共通部分をModule化し、再利用性と 管理性を向上。 標準化を推進。 ③ 開発者との境界線整備 開発チームとの責任範囲や連携フ ローを整備し、効率的な協業体制を 構築。
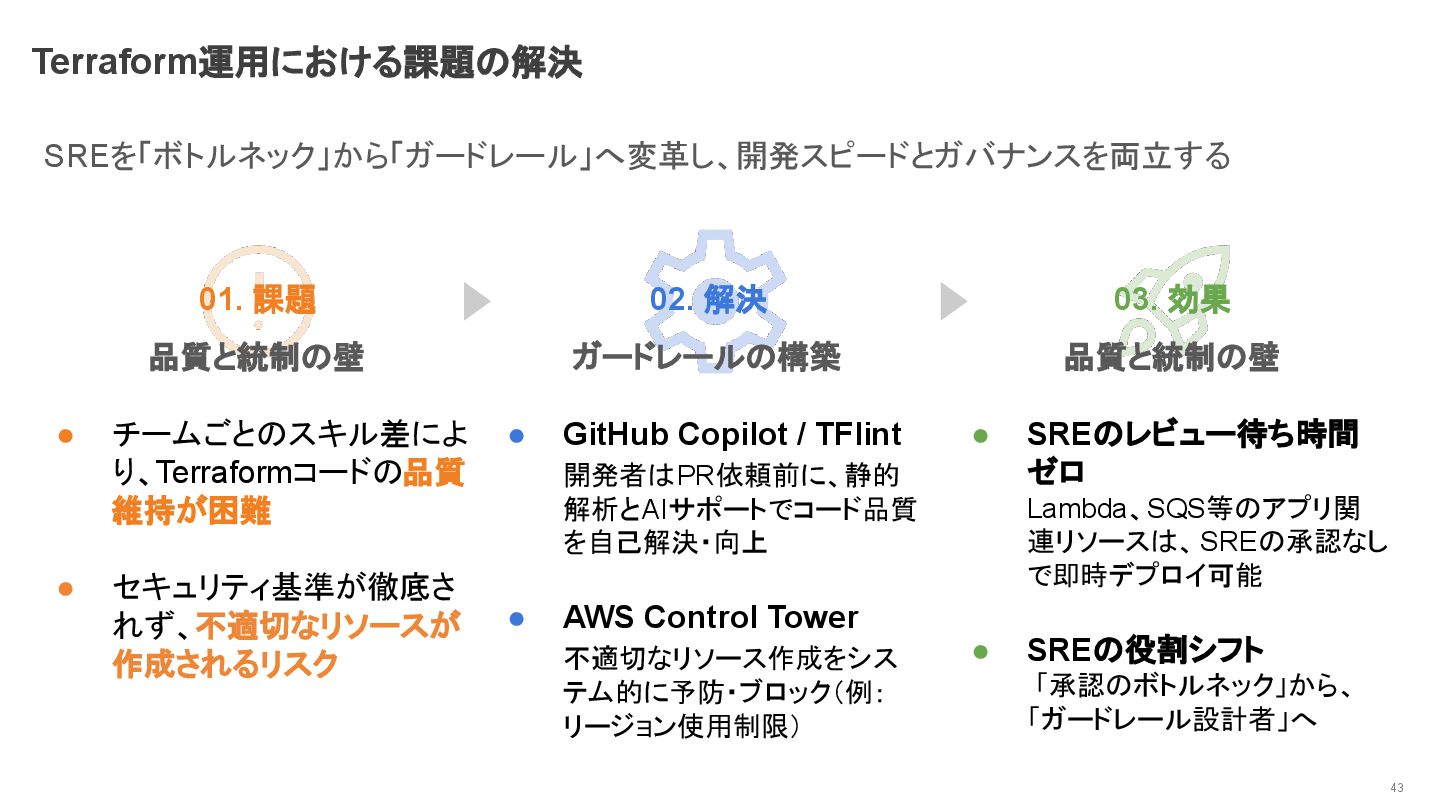
01. 課題 品質と統制の壁 • チームごとのスキル差によ り、Terraformコードの品質 維持が困難 • セキュリティ基準が徹底さ れず、不適切なリソースが
作成されるリスク 03. 効果 品質と統制の壁 • SREのレビュー待ち時間 ゼロ Lambda、SQS等のアプリ関 連リソースは、SREの承認なし で即時デプロイ可能 • SREの役割シフト 「承認のボトルネック」から、 「ガードレール設計者」へ 02. 解決 ガードレールの構築 • GitHub Copilot / TFlint 開発者はPR依頼前に、静的 解析とAIサポートでコード品質 を自己解決・向上 • AWS Control Tower 不適切なリソース作成をシス テム的に予防・ブロック(例: リージョン使用制限) Terraform運用における課題の解決 43 SREを「ボトルネック」から「ガードレール」へ変革し、開発スピードとガバナンスを両立する
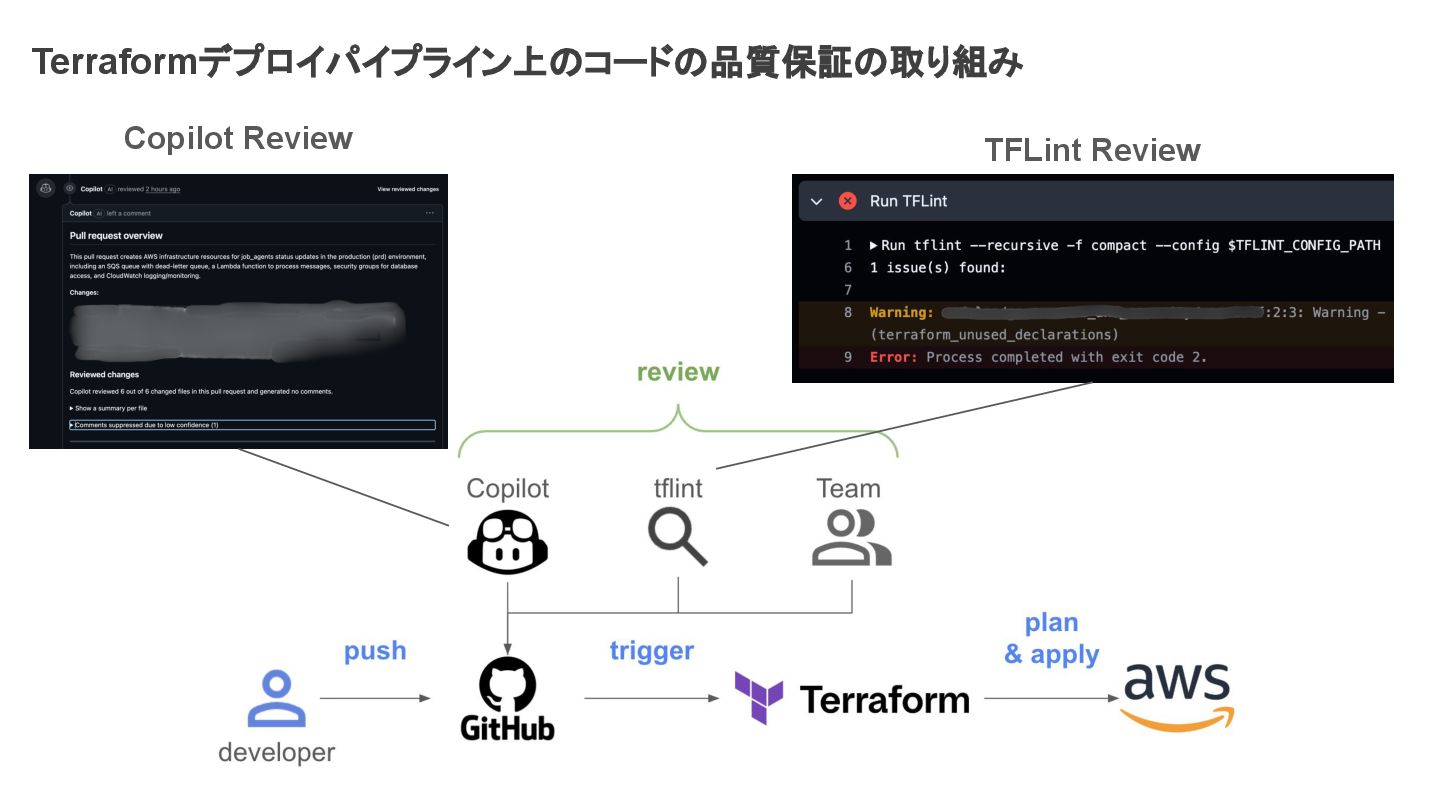
Terraformデプロイパイプライン上のコードの品質保証の取り組み Copilot Review TFLint Review
まとめと振り返り 45 Tech Lead時代 → “コスト意識の不足 ” CTO時代 → “経営視座の習得
” 当時AWS移管を意思決定した頃は経営観点の視座は 持ち合わせていなかった 身の丈に合わない技術選定 オーバーエンジニアリング → 結果:将来の負債リスク増大 → 結果:全体最適、持続可能な基盤へと改善 経営と連動した意思決定の重要性を痛感 SRE立ち上げ時に実践 SLI/SLO:開発チームと共通言語を持つための 文化作り インフラコスト: 単なる節約ではなく、 経営判断 セキュリティ: 顧客信頼を守るための 計画的な投資 laC: 開発速度とガバナンスを両立する ガードレール 過去の反 省 現在の学び
ありがとうございました 46 私との カジュアル面談 TalentX採用 サイト
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}