{r } i i ∼ N(b, B) ∼ PG(1, θ x ) T i ∼ N(m , V ) ω ω Notation i X κ Ω Vω mω ∈ {1, ..., t} = [x , ..., x ] 1 t = [κ , ..., κ ] = [r − 1/2, ..., r − 1/2] 1 t 1 t = diag(ω , ..., ω ) 1 t = (X ΩX + B ) T −1 −1 = V (X κ + B b) ω T −1 15
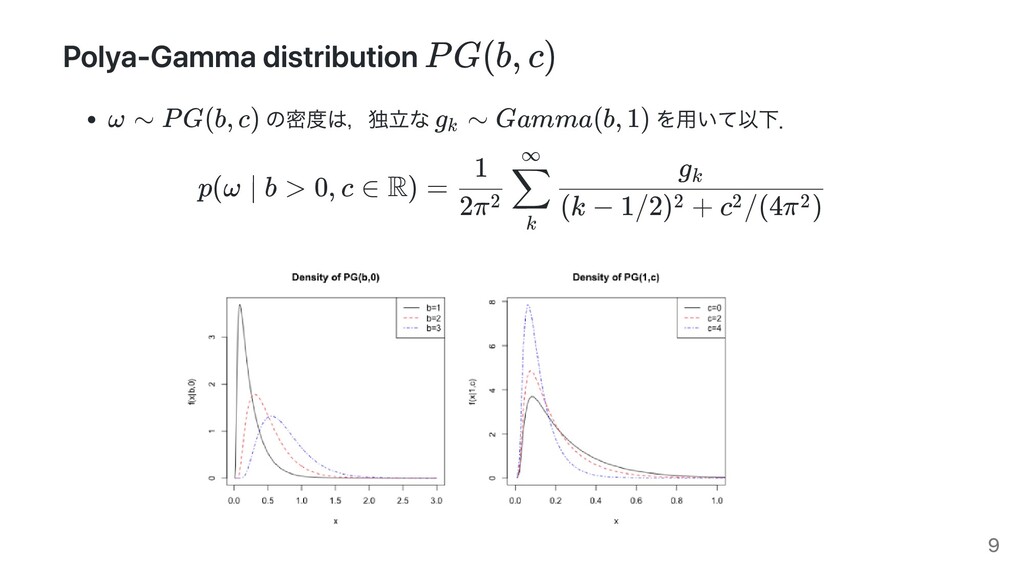
c ∈ R) = 2π2 1 k ∑ ∞ (k − 1/2) + c /(4π ) 2 2 2 g k 実は効率的な sampler がある. Saddlepoint Approximation 分布を左右で分割して,左を逆ガウス分布,右をガンマ分布で近似している (っぽい) R の BayesLogit パッケージにはすでに実装があり, でこの実装が使われる. PG(b, c) g k b > 13 19
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}