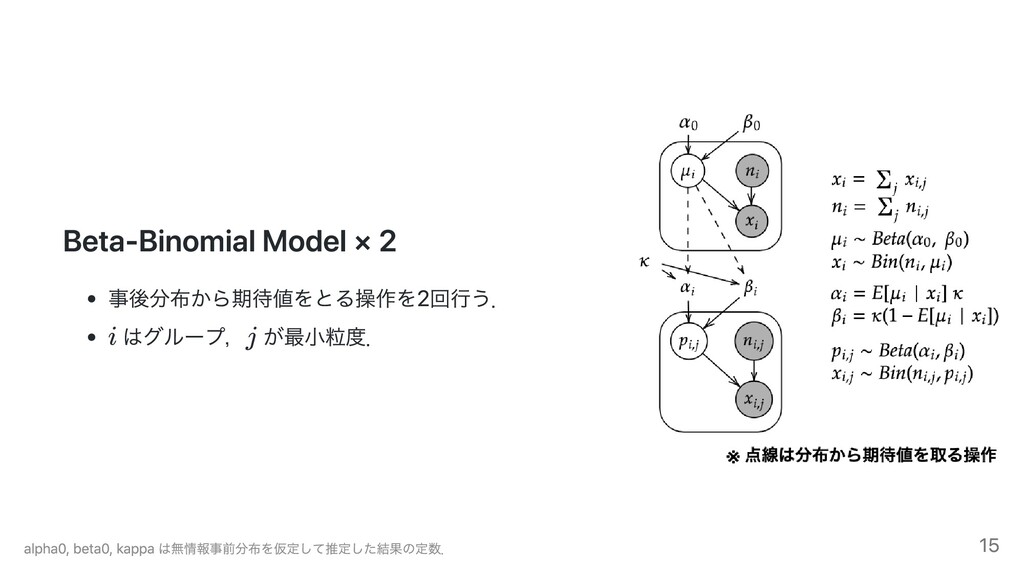
= x ˉ x n 1 i ∑ i w ∝ (x − n 1 i ∑ i ) x ˉ 2 i ∈ {1, .., n} x ∼ i N(θ , σ ) i 2 θ i = θ i ^ x i = θ i S ^ (1 − w)x + i wx ˉ w は実際は σ や n にも依存.また,誤差は何度もサンプリングした結果の誤差.詳しくは 『ベイズモデリングの世界 第Ⅱ 部』 6
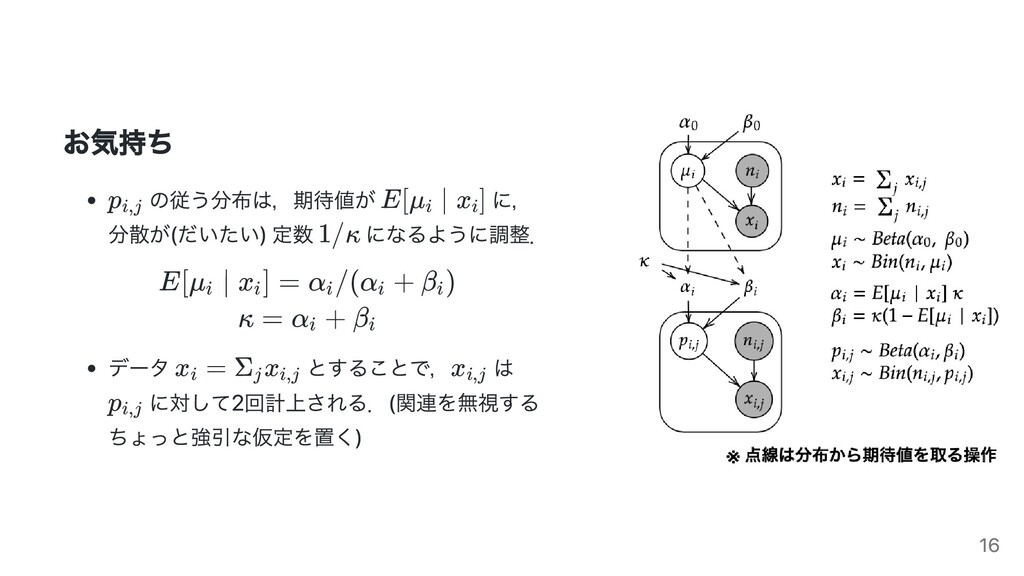
E[μ ∣ x ] i i = E ∣ x [ α + β + (n − x ) i i i,j i,j α + x i i,j i ] = E ∣ x [ κ + (n − x ) i,j i,j μ κ + x i i,j i ] = (E μ ∣ x κ + x ) κ + (n − x ) i,j i,j 1 [ i i] i,j = α + β + (n − x ) 0 0 i i α + x 0 i 17
Using Regression and Multilevel/Hierarchical Models" 丹後 俊郎,死亡指標の経験的ベイズ推定量について,応⽤統計学,1988,17巻,2号,p.81-96 LIVESENSE DATA ANALYTICS BLOG,階層ベイズによる⼩標本データの⽐率の推定 21
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![挙動 E[p ∣ x , x ] i,j i i,j](https://files.speakerdeck.com/presentations/a49d7bbae5394294a5ca50c952916dd9/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}