in Conversational Systems and Human-Robot Interaction: A Review.” Comput. Speech Lang. 67 (2021): 101178. 比較対象 1. Ward, Nigel G. and Wataru Tsukahara. “Prosodic features which cue back-channel responses in English and Japanese.” Journal of Pragmatics 32 (2000): 1177-1207. 2. 山口 貴史, 井上 昂治, 吉野 幸一郎. “傾聴対話システムのための言語情報と韻律情報に基づく多様 な形態の相槌の生成 (「フィールド研究とインタラクション」および一般).” (2016). 3. Hara, Kohei, Koji Inoue, Katsuya Takanashi and Tatsuya Kawahara. “Prediction of Turn-taking Using Multitask Learning with Prediction of Backchannels and Fillers.” INTERSPEECH (2018). 4. Ruede, Robin, Markus Müller, Sebastian Stüker and Alexander H. Waibel. “Yeah, Right, Uh-Huh: A Deep Learning Backchannel Predictor.” IWSDS (2017). 5. Ortega, Daniel, Chia-Yu Li and Ngoc Thang Vu. “OH, JEEZ! or UH-HUH? A Listener-Aware Backchannel Predictor on ASR Transcriptions.” ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (2020): 8064-8068.
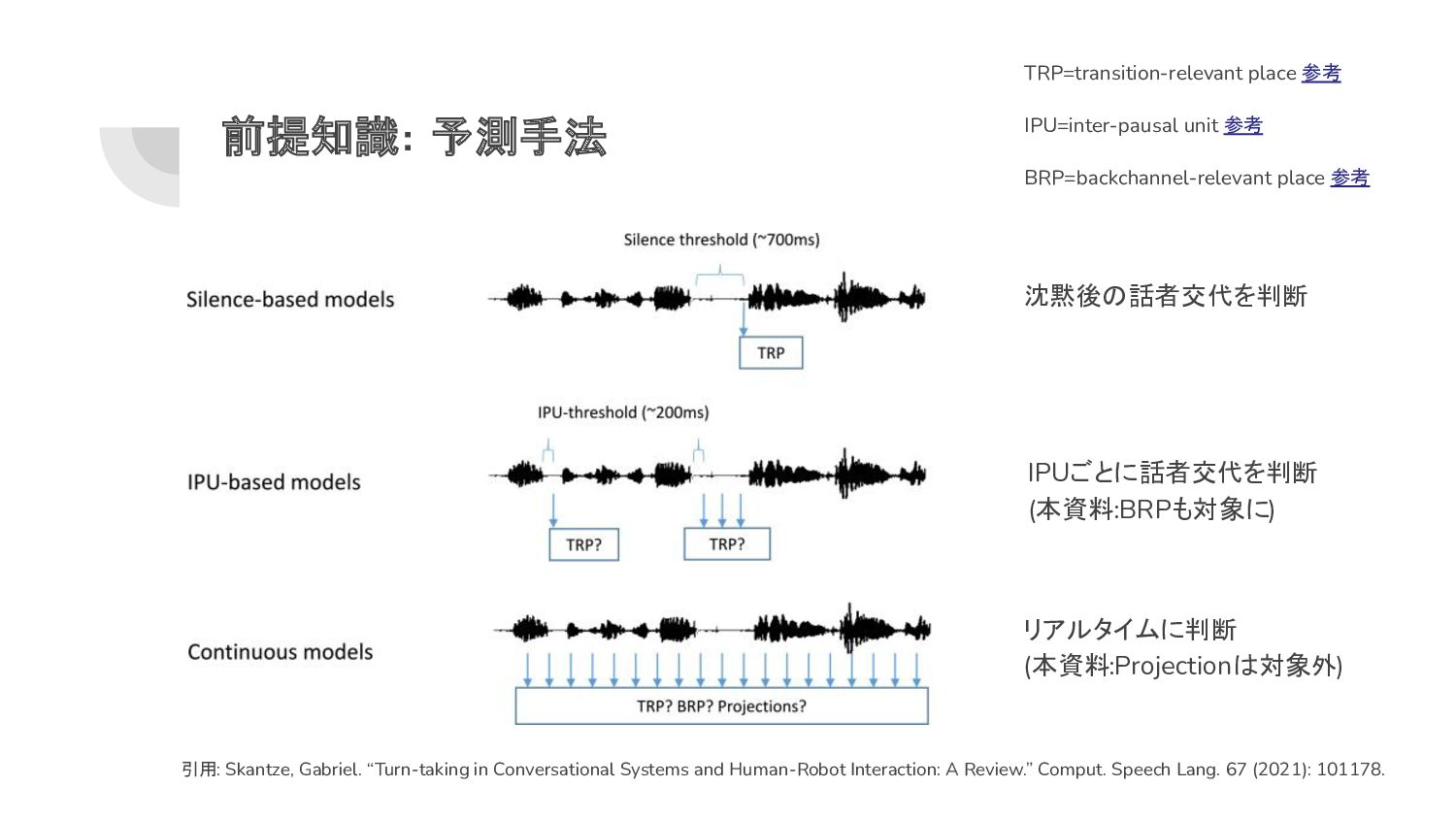
and Human-Robot Interaction: A Review.” Comput. Speech Lang. 67 (2021): 101178. TRP=transition-relevant place 参考 IPU=inter-pausal unit 参考 BRP=backchannel-relevant place 参考 リアルタイムに判断 (本資料:Projectionは対象外) IPUごとに話者交代を判断 (本資料:BRPも対象に)
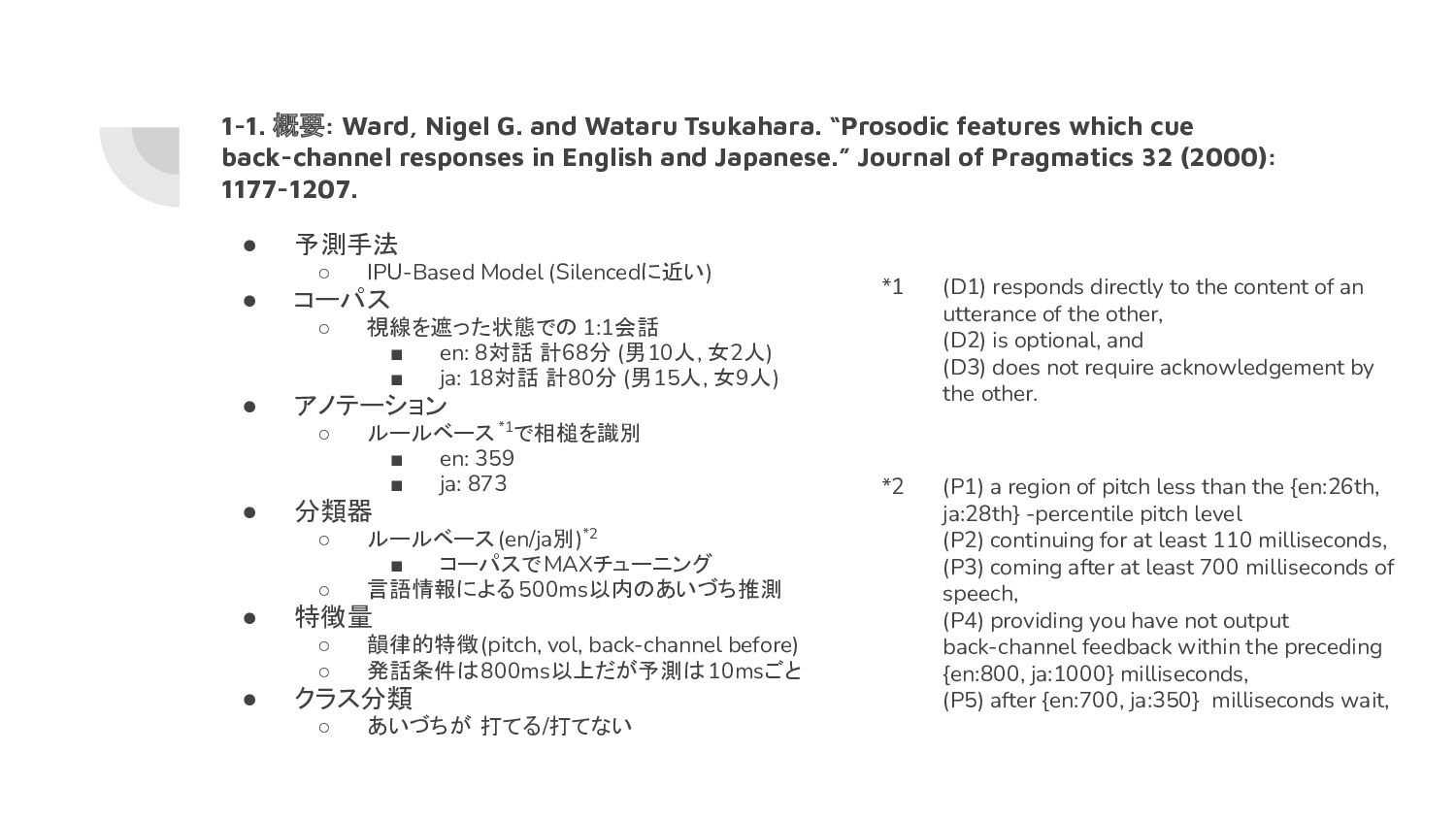
which cue back-channel responses in English and Japanese.” Journal of Pragmatics 32 (2000): 1177-1207. • 予測手法 ◦ IPU-Based Model (Silencedに近い) • コーパス ◦ 視線を遮った状態での 1:1会話 ▪ en: 8対話 計68分 (男10人, 女2人) ▪ ja: 18対話 計80分 (男15人, 女9人) • アノテーション ◦ ルールベース*1で相槌を識別 ▪ en: 359 ▪ ja: 873 • 分類器 ◦ ルールベース(en/ja別)*2 ▪ コーパスでMAXチューニング ◦ 言語情報による 500ms以内のあいづち推測 • 特徴量 ◦ 韻律的特徴(pitch, vol, back-channel before) ◦ 発話条件は800ms以上だが予測は 10msごと • クラス分類 ◦ あいづちが 打てる/打てない *2 *1 (P1) a region of pitch less than the {en:26th, ja:28th} -percentile pitch level (P2) continuing for at least 110 milliseconds, (P3) coming after at least 700 milliseconds of speech, (P4) providing you have not output back-channel feedback within the preceding {en:800, ja:1000} milliseconds, (P5) after {en:700, ja:350} milliseconds wait, (D1) responds directly to the content of an utterance of the other, (D2) is optional, and (D3) does not require acknowledgement by the other.
cue back-channel responses in English and Japanese.” Journal of Pragmatics 32 (2000): 1177-1207. accuracy | ja | max ⇒ 0.34 • Coverageという概念を導入 ◦ 当時パラメータ最適化と他ルールとの 比較ができなかったため導入 (?) • en, ja ともに低精度 ◦ ja: 言語情報だけでも多少精度あり
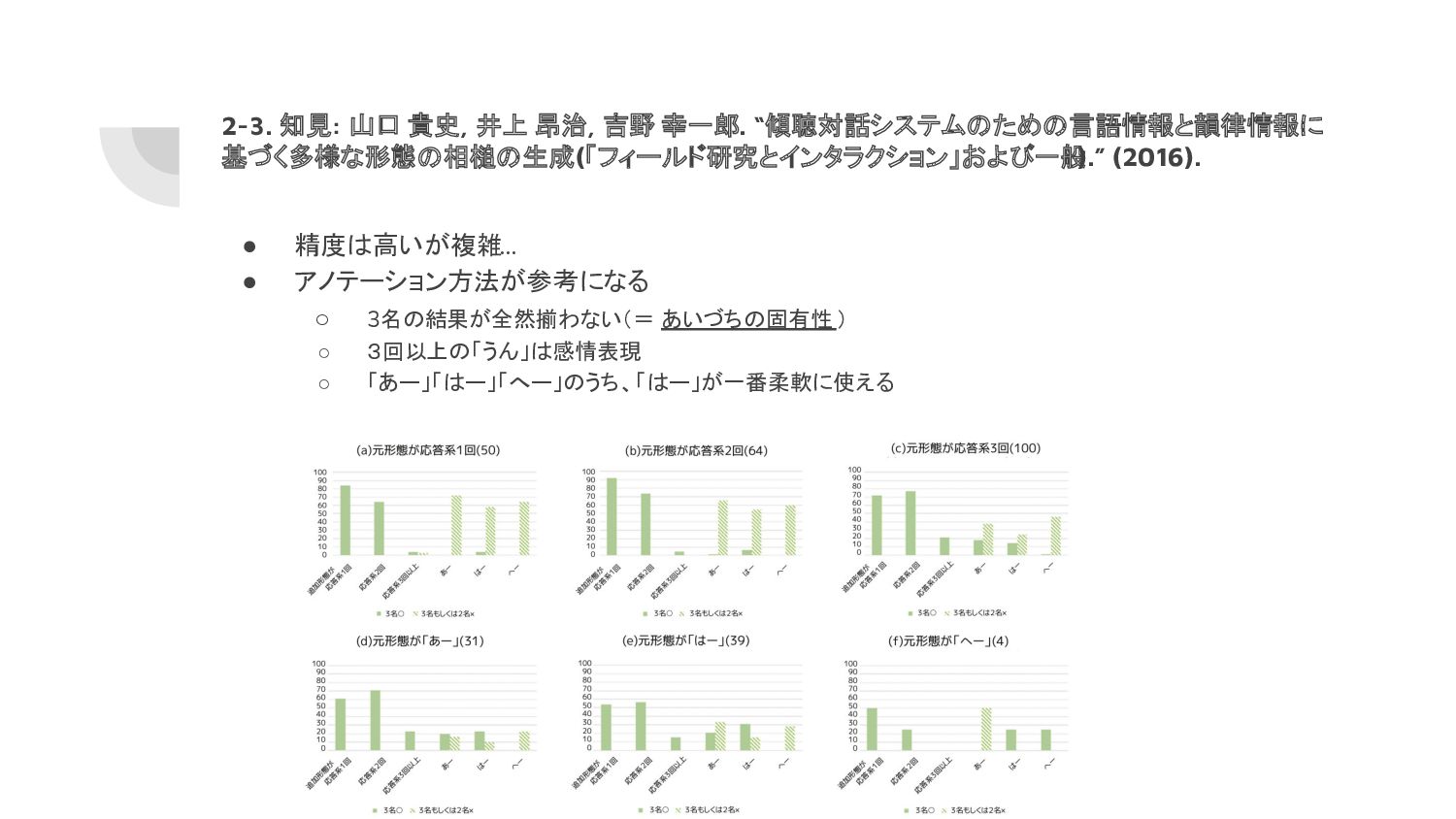
石井 裕, 音声相槌を 伴う音声駆動型身体引き込みキャラクタシステ ム, 日本機械学会論文集 , 2019, 85 巻, 880 号, p. 19-00159 ▪ Ishi, Carlos Toshinori, Chaoran Liu, Hiroshi Ishiguro and Norihiro Hagita. “Head motion during dialogue speech and nod timing control in humanoid robots.” 2010 5th ACM/IEEE International Conference on Human-Robot Interaction (HRI) (2010): 293-300. • 具体的に音律をみてルール形成をしている ため、こういった論文は原点に立ち戻る際に 有用かもしれない 1-3. 知見: Ward, Nigel G. and Wataru Tsukahara. “Prosodic features which cue back-channel responses in English and Japanese.” Journal of Pragmatics 32 (2000): 1177-1207.
a will to take a turn. 前提知識: Filler 引用: Hara, Kohei, Koji Inoue, Katsuya Takanashi and Tatsuya Kawahara. “Prediction of Turn-taking Using Multitask Learning with Prediction of Backchannels and Fillers.” INTERSPEECH (2018).
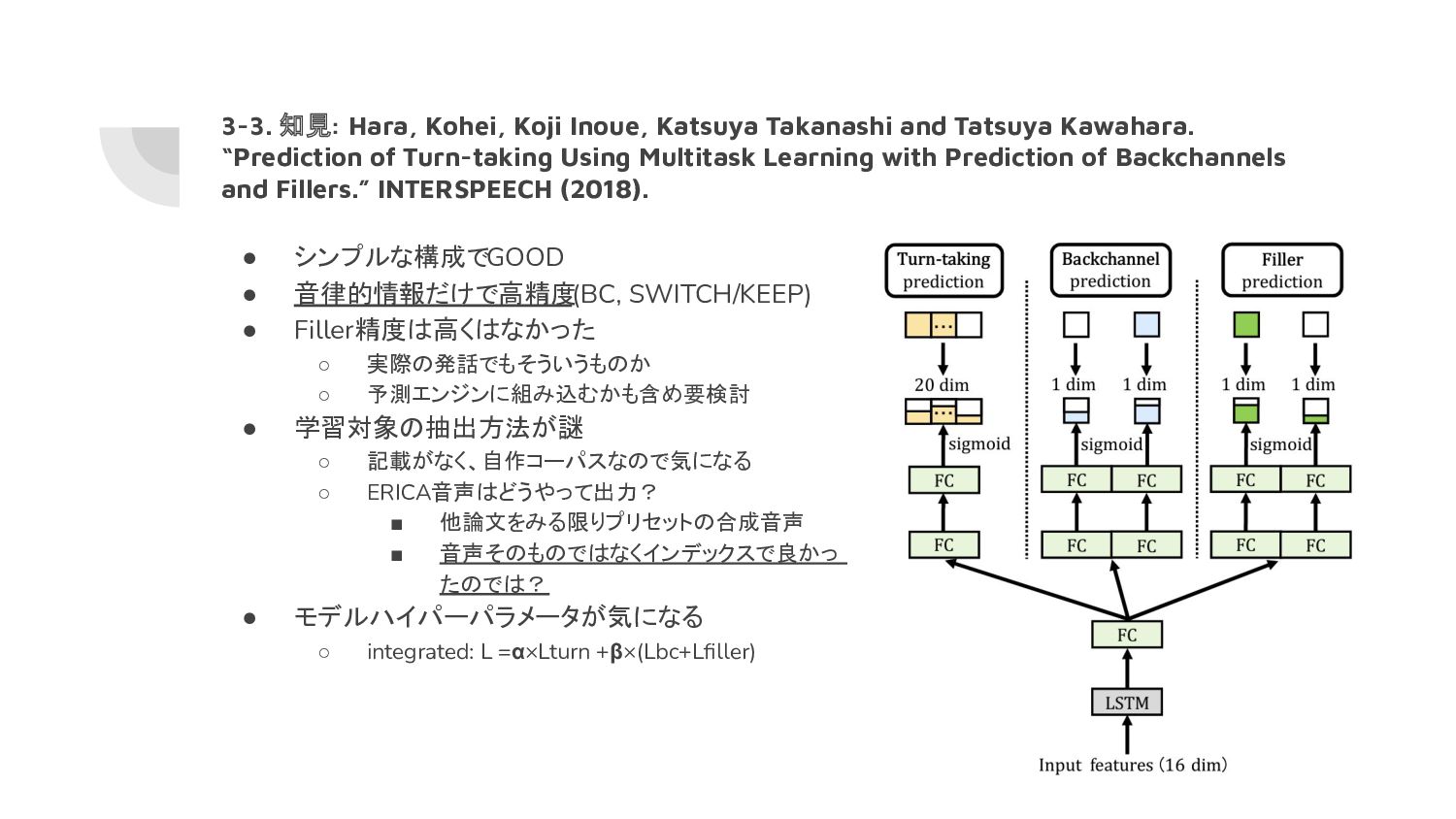
▪ K. Inoue, P. Milhorat, D. Lala, T. Zhao, and T. Kawahara, “Talking with ERICA, an autonomous android.” in SIGdial, 2016, pp. 212–215. ◦ 15セッションx10分x2種(仕事話/身の上話) • アノテーション ◦ SWITCH/KEEP, BC/NOT, Filler/NOT を分類*1 ◦ 学習対象の抽出方法は不明 • 分類器 ◦ LTSM • 特徴量 ◦ 韻律的特徴1000ms*2 ◦ 200ms<=IPU<400ms • クラス分類 ◦ 各分類を別々に [0, 1]で予測 ▪ モデル: 別々(baseline)/同一(integrated) の 2種 3-1. 概要: Hara, Kohei, Koji Inoue, Katsuya Takanashi and Tatsuya Kawahara. “Prediction of Turn-taking Using Multitask Learning with Prediction of Backchannels and Fillers.” INTERSPEECH (2018). *2 *1
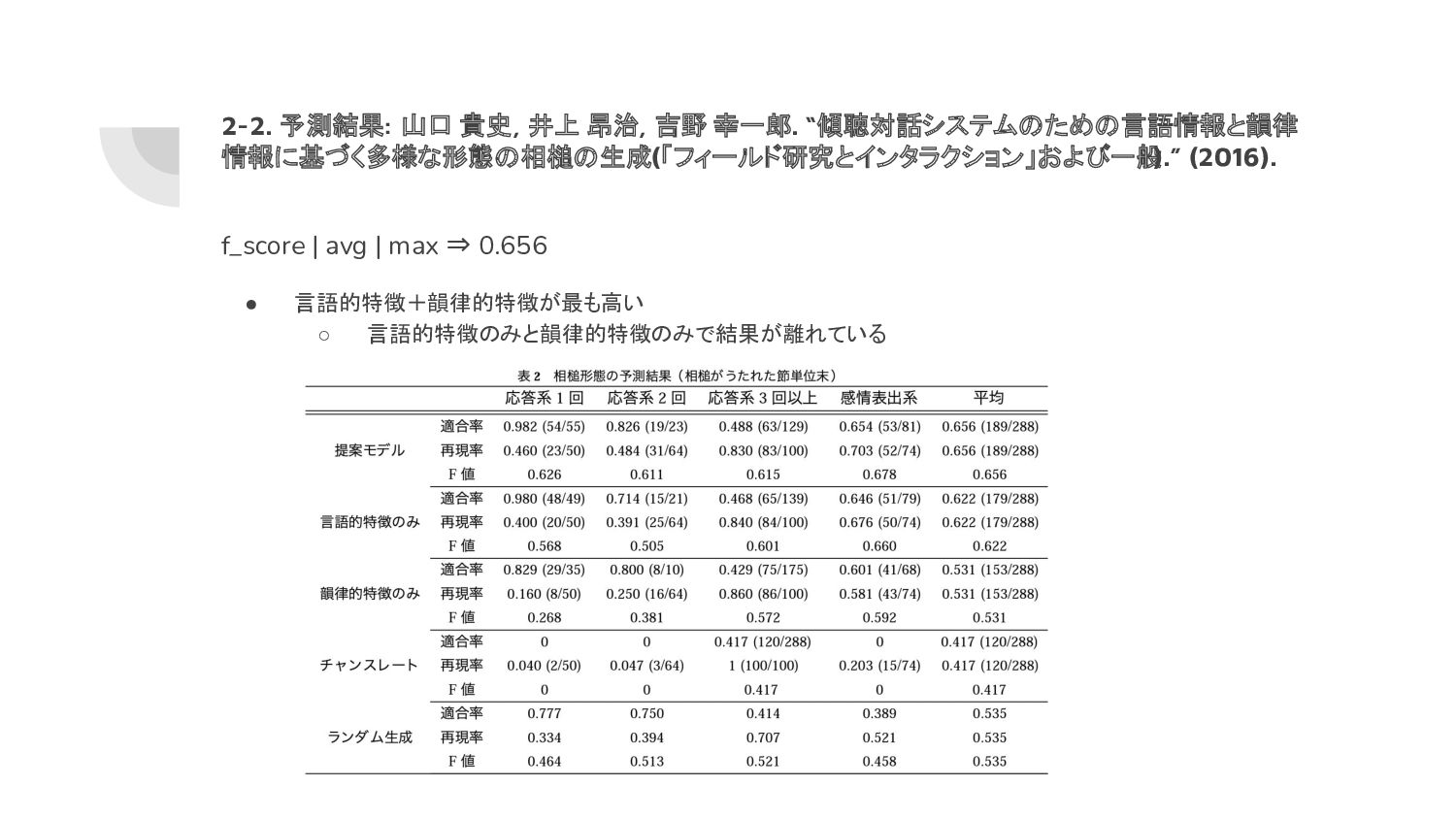
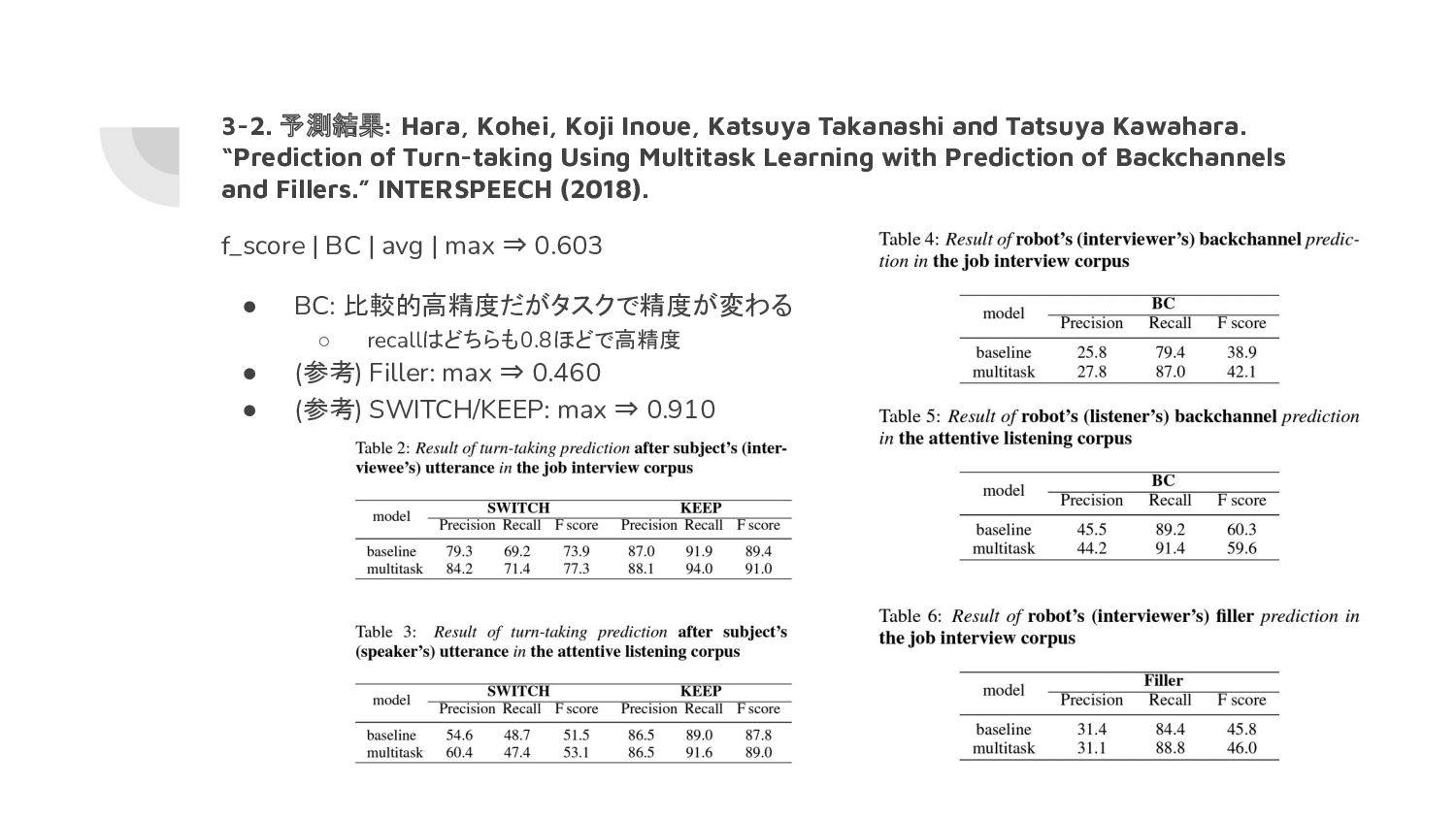
Kawahara. “Prediction of Turn-taking Using Multitask Learning with Prediction of Backchannels and Fillers.” INTERSPEECH (2018). f_score | BC | avg | max ⇒ 0.603 • BC: 比較的高精度だがタスクで精度が変わる ◦ recallはどちらも0.8ほどで高精度 • (参考) Filler: max ⇒ 0.460 • (参考) SWITCH/KEEP: max ⇒ 0.910
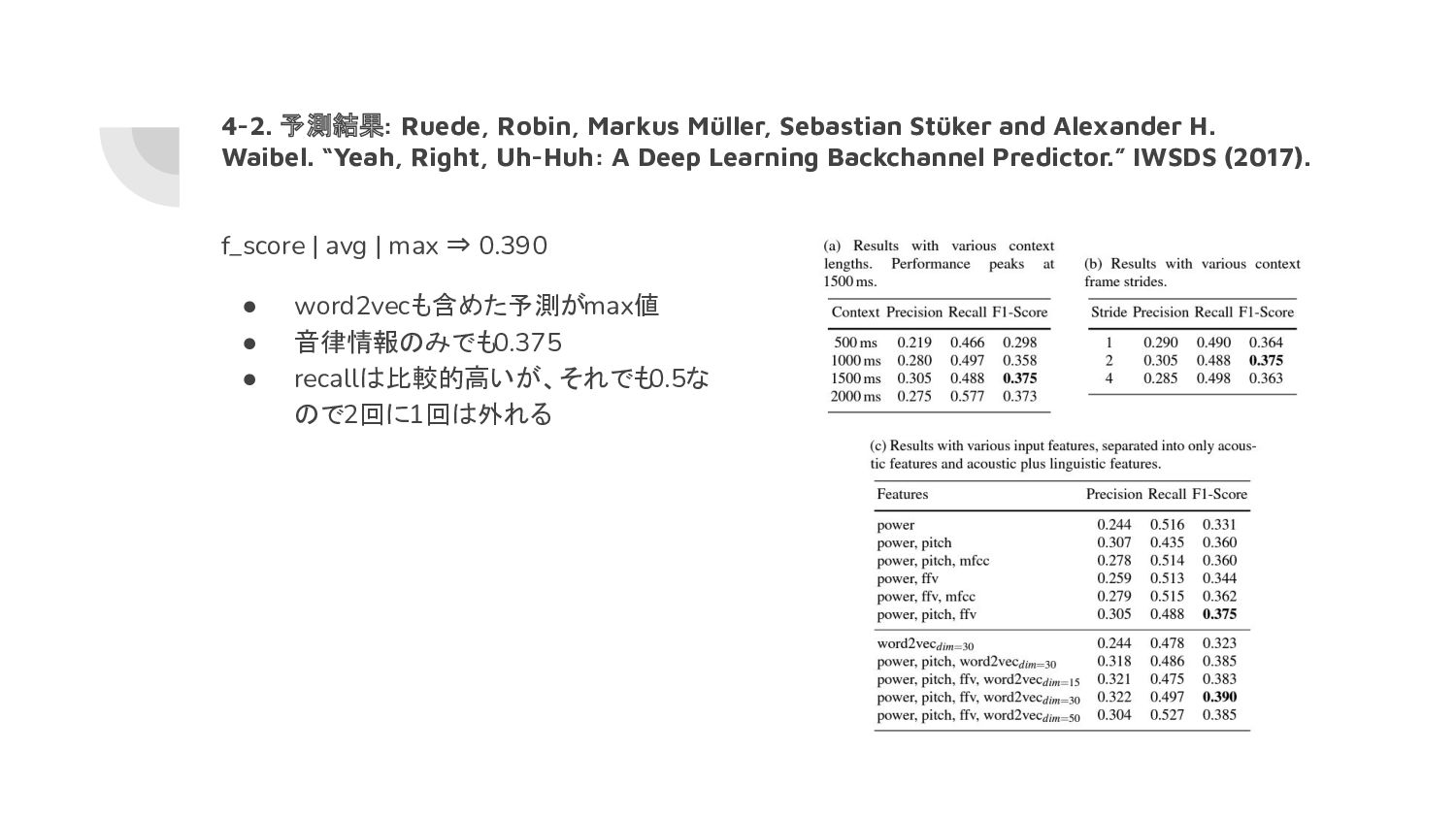
H. Waibel. “Yeah, Right, Uh-Huh: A Deep Learning Backchannel Predictor.” IWSDS (2017). • 予測手法 ◦ Continuous-Based Model • コーパス ◦ 公開コーパス ▪ J. J. Godfrey, E. C. Holliman and J. McDaniel, "SWITCHBOARD: telephone speech corpus for research and development," [Proceedings] ICASSP-92: 1992 IEEE International Conference on Acoustics, Speech, and Signal Processing, 1992, ◦ 2438会話 ▪ 5秒以上一方的に会話しているデータのみ • アノテーション ◦ top 150 most common unique BC ◦ 公開アラインメントデータ ▪ Harkins, D., et al.: ISIP switchboard word alignments (2003). URL https://www.isip. piconepress.com/projects/switchboard/ • 分類器 ◦ LSTM • 特徴量 ◦ 音律特徴量(power,pitch,f0)を色々調整 ▪ lengths (500ms to 2000ms), strides (1 to 4 frames) ◦ word2vecも適用 • クラス分類 ◦ No-BC / BCで予測 ▪ No-BCの学習データ: BCを打つ数秒前の発話
音律情報のみでも0.375 • recallは比較的高いが、それでも 0.5な ので2回に1回は外れる 4-2. 予測結果: Ruede, Robin, Markus Müller, Sebastian Stüker and Alexander H. Waibel. “Yeah, Right, Uh-Huh: A Deep Learning Backchannel Predictor.” IWSDS (2017). *1
• 実用的な予測によるあいづち出力ロジックも記載 ◦ ガウシアンフィルタで滑らかにした値が最大値を迎えたタイミングであいづちを出力 ◦ デモ動画 https://streamable.com/dycu1 4-3. 知見: Ruede, Robin, Markus Müller, Sebastian Stüker and Alexander H. Waibel. “Yeah, Right, Uh-Huh: A Deep Learning Backchannel Predictor.” IWSDS (2017).
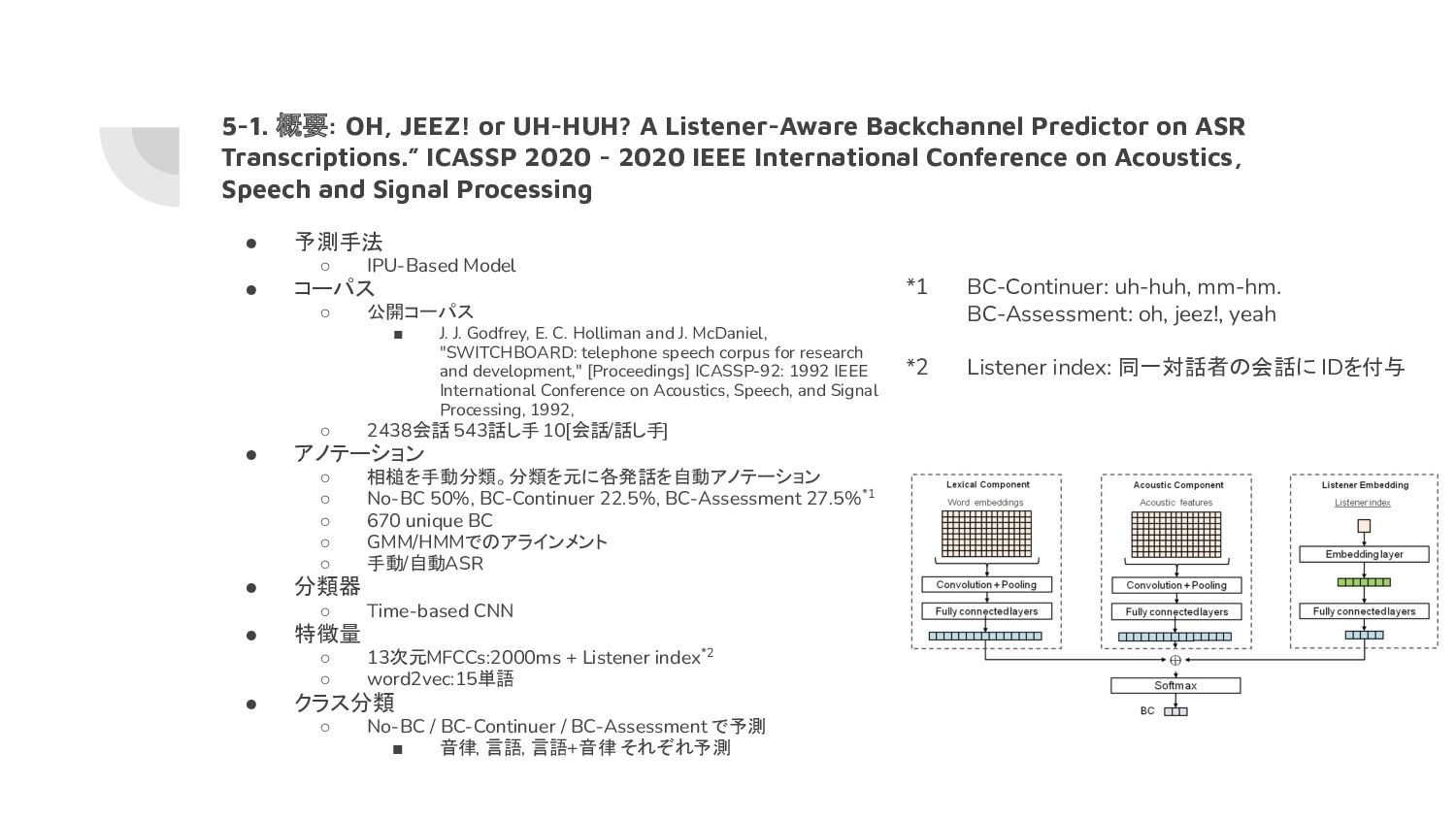
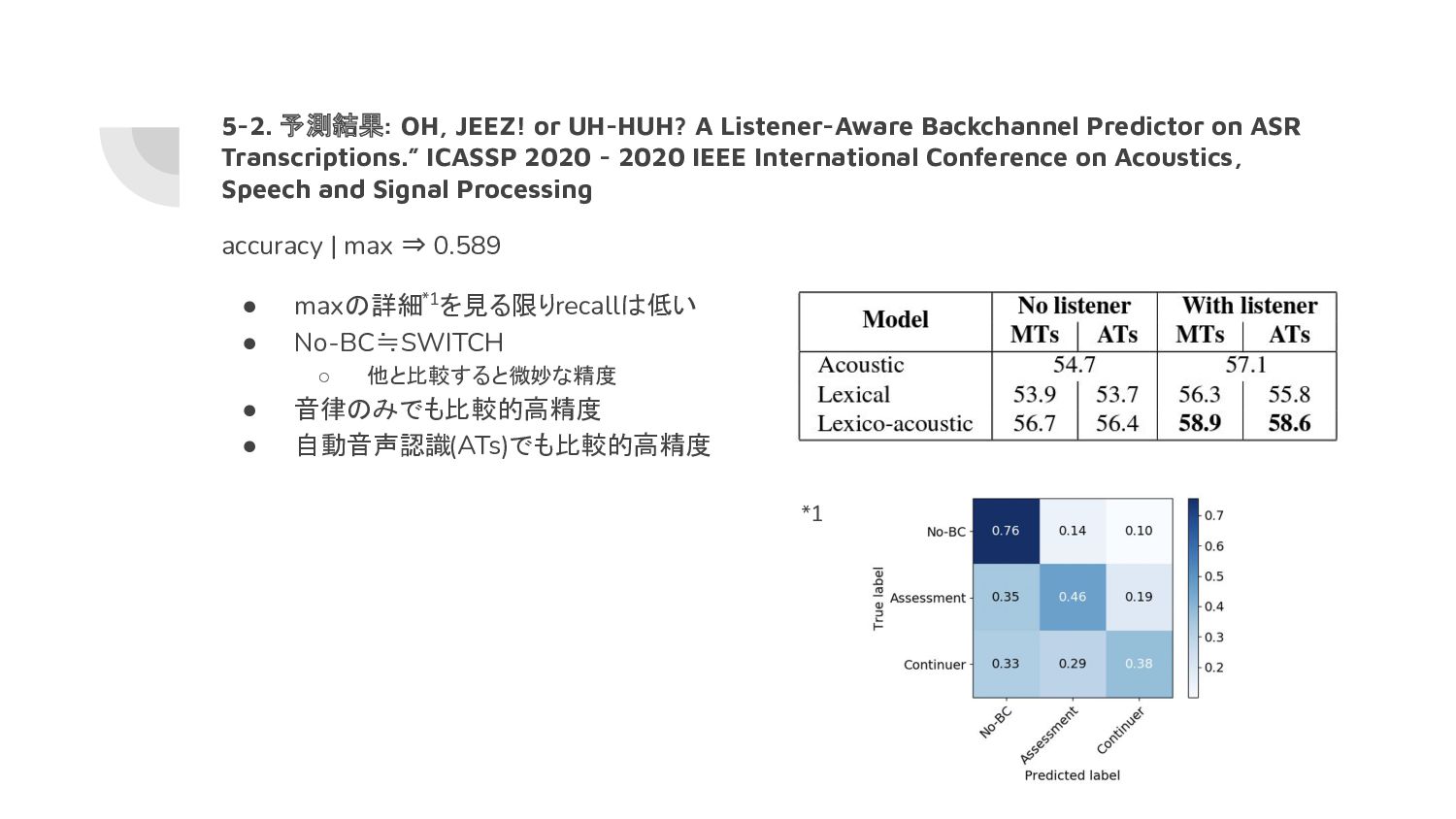
他と比較すると微妙な精度 • 音律のみでも比較的高精度 • 自動音声認識(ATs)でも比較的高精度 5-2. 予測結果: OH, JEEZ! or UH-HUH? A Listener-Aware Backchannel Predictor on ASR Transcriptions.” ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing *1
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}