Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
記憶プロセスとLTM
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
yoshitakaebihara
November 20, 2025
130
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
記憶プロセスとLTM
AGI福岡第8回 登壇資料
yoshitakaebihara
November 20, 2025
More Decks by yoshitakaebihara
See All by yoshitakaebihara
昔話 設計地蔵と働く人
yoshitakaebihara
0
89
rules改善サイクル by Y.Ebihara
yoshitakaebihara
0
140
Agent内model移行の観測
yoshitakaebihara
0
160
風土に合わせたRAG改善
yoshitakaebihara
0
87
Featured
See All Featured
Accessibility Awareness
sabderemane
1
140
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
2
860
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.3k
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
200
Navigating Team Friction
lara
192
16k
The SEO Collaboration Effect
kristinabergwall1
1
490
Amusing Abliteration
ianozsvald
1
200
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
590
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
590
AI: The stuff that nobody shows you
jnunemaker
PRO
8
710
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
Discover your Explorer Soul
emna__ayadi
2
1.1k
Transcript
記憶プロセスとLTM NOV., 2025 at AGI-FUKUOKA Y. Ebihara - 編集可能記憶への試み -
着想 ・ 「Long term memoryは、 入出力をstr insert & vector化 !」
上記を起点とし、 更なる表現力 / 運用性 / 柔軟性向上を目指し、 ‘人間の記憶過程’ に基づく RAG機能拡張を試みました。
記憶のプロセス ・ 人間の記憶 3要素 記銘 : 覚える 保持 : 保つ
想起 : 思い出す → 本発表は 「保持」 に着目
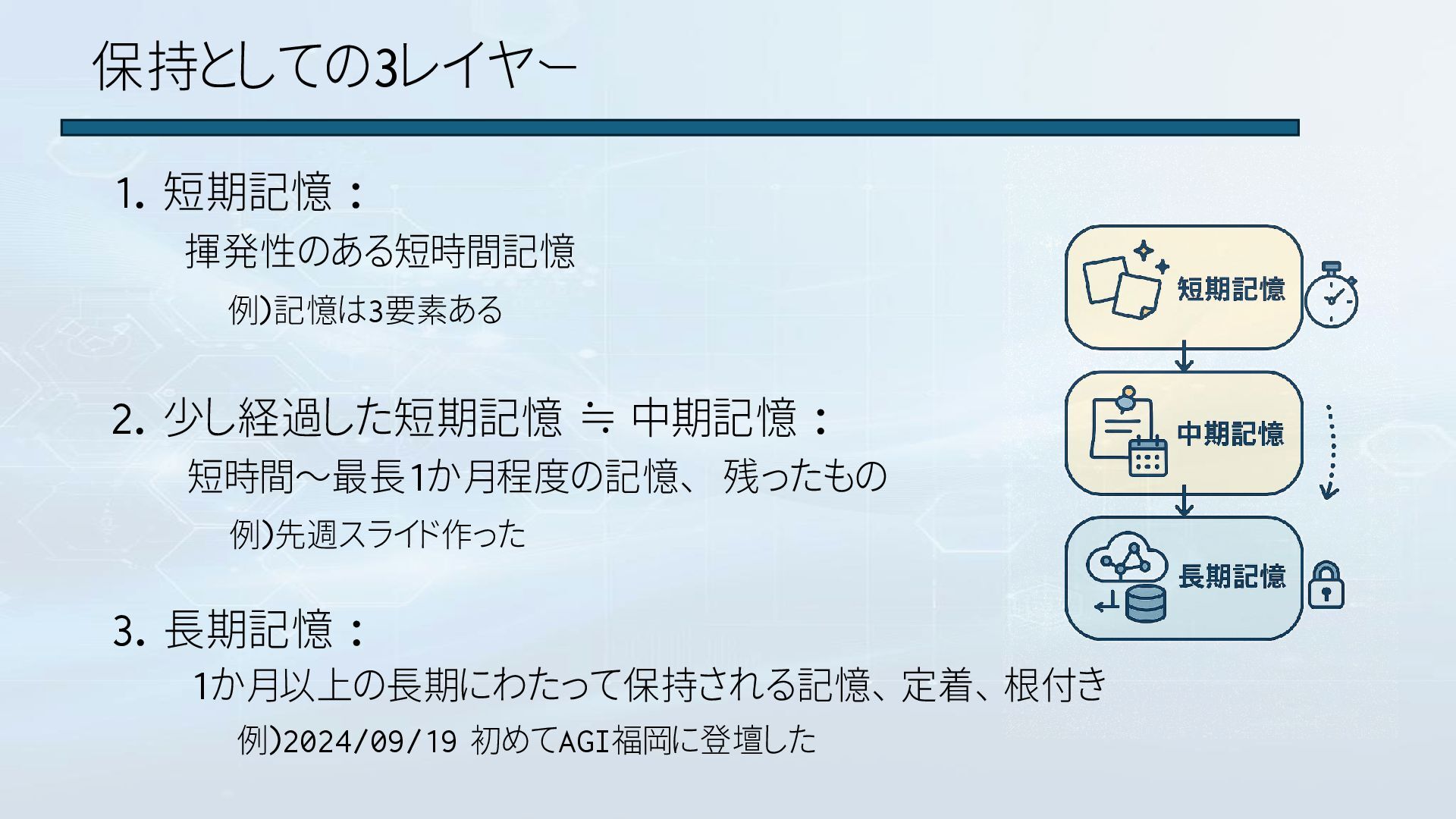
保持としての3レイヤー 1. 短期記憶 : 揮発性のある短時間記憶 2. 少し経過した短期記憶 ≒ 中期記憶 :
3. 長期記憶 : 例)2024/09/19 初めてAGI福岡に登壇した 短時間~最長1か月程度の記憶、 残ったもの 1か月以上の長期にわたって保持される記憶、 定着、 根付き 例)記憶は3要素ある 例)先週スライド作った
保持メカニズム < 人間の場合 > Step-1 : まずは、 海馬にエピソードを短期保存 (一時保存) Step-3
: 脱力時間、 睡眠、 再想起、 反復、 情動タグ付等をトリガーとし、 Step-2 : 繰り返す事で、 長めの短期記憶として保持 or 破棄 (忘却) ↓ 保持情報は長期記憶として大脳皮質に転送 ・ 統合 ・ 固定化 ↓ * 睡眠中に海馬がその日の活動パターンをリプレイしているのでは という観測もありました 米国 国立医学図書館アーカイブ : https://pmc.ncbi.nlm.nih.gov/articles/PMC7898724/
LLMへの適用 文脈としてはSTM/LTM (short term memory/long term memory) ↓ 身近な手法でappへ落とし込み <
LLMの場合 > どの項目を何で再現したか見て行きましょう
実施事項 これらを基に 該当する内容/案件 = 過去の記憶 を特定し、 [input, reply, tag, summary]をcontextへ挿入可能としました。
短期記憶 ↓ → = user inputとassistant replyの文字列そのもの ・ 同一session内保持 ・
鮮明な内容の再現 保存時 : json.append / st.session_state / react useState等 内容を横パス出来れば良いので、 手法は無数にあります。 参照時 : contextに含める
少し経過した短期記憶-1 ↓ ・ 記憶に残っている概要 ・ 主要素を圧縮したメタ情報の再現 (結論と決定事項 ・ 因果関係 ・
何故ロジック ・ スタンス ・ トーン) = 細かい部分を省略したsummary 保存時 : inputとreplyを str保持、 summarize、 vector化 参照時 : keyword & vector retriever
少し経過した短期記憶-2 ↓ ・ 記憶に残っている単語 ・ 思い出すhook(手掛り)の再現 = 固有名詞でtag付け (キーワード ・
人名 ・ 事象 / 単語連想の再現は keyword retrieverで直hit) 保存時 : tag抽出 1. inputとreplyから固有名詞を複数抽出 2. tag集積所になければ新規追加 (出現回数 = 1 としてinsert) 参照時 : keyword retriever
少し経過した短期記憶-3 ↓ ・ 頻出の再現 ・ 再固定化 ・ 反復 ・ 優先順位の再現
(登場回数に従い 優先順位設定 / 紐づいた他要素も優先優劣有) = tagの重み付け 保存時 : tag追加時、 既存があれば 出現頻度へ加算 下図+=1より、 user嗜好が明確になれば より正確な重み付けを期待出来る 参照時 : keyword retrieve 前頁の ‘固有名詞の複数抽出’ は ここでも有効
長期記憶 ↓ ・ 記憶の固定化 ・ 海馬→大脳皮質に転送の再現 (海馬 : 記憶内容str, summary
-> 大脳皮質 : vector storeへ転送) = vector化 & vector store格納 保存時-1 : summaryをvector化 & upsert(短期記憶-1で済) 保存時-2 : inputとreplyも 個別列としてvector storeへ格納 参照時 : vector retriever (質問だけ覚えている or 答えだけ覚えている現象の再現)
記憶の編集 採取した後は・・ 記憶を自由に 追加、 編集、 削除したくなりますよね ?!
記憶の編集 1. 記憶を新たに埋込みたい -> 追加可能にしました 2. 記憶を編集したい -> 全て編集可能にしました 3.
記憶を消したい -> is_active論理削除で再現 (忘れていた記憶を蘇らせる時は Flag = Trueにする) 記憶editorを作成
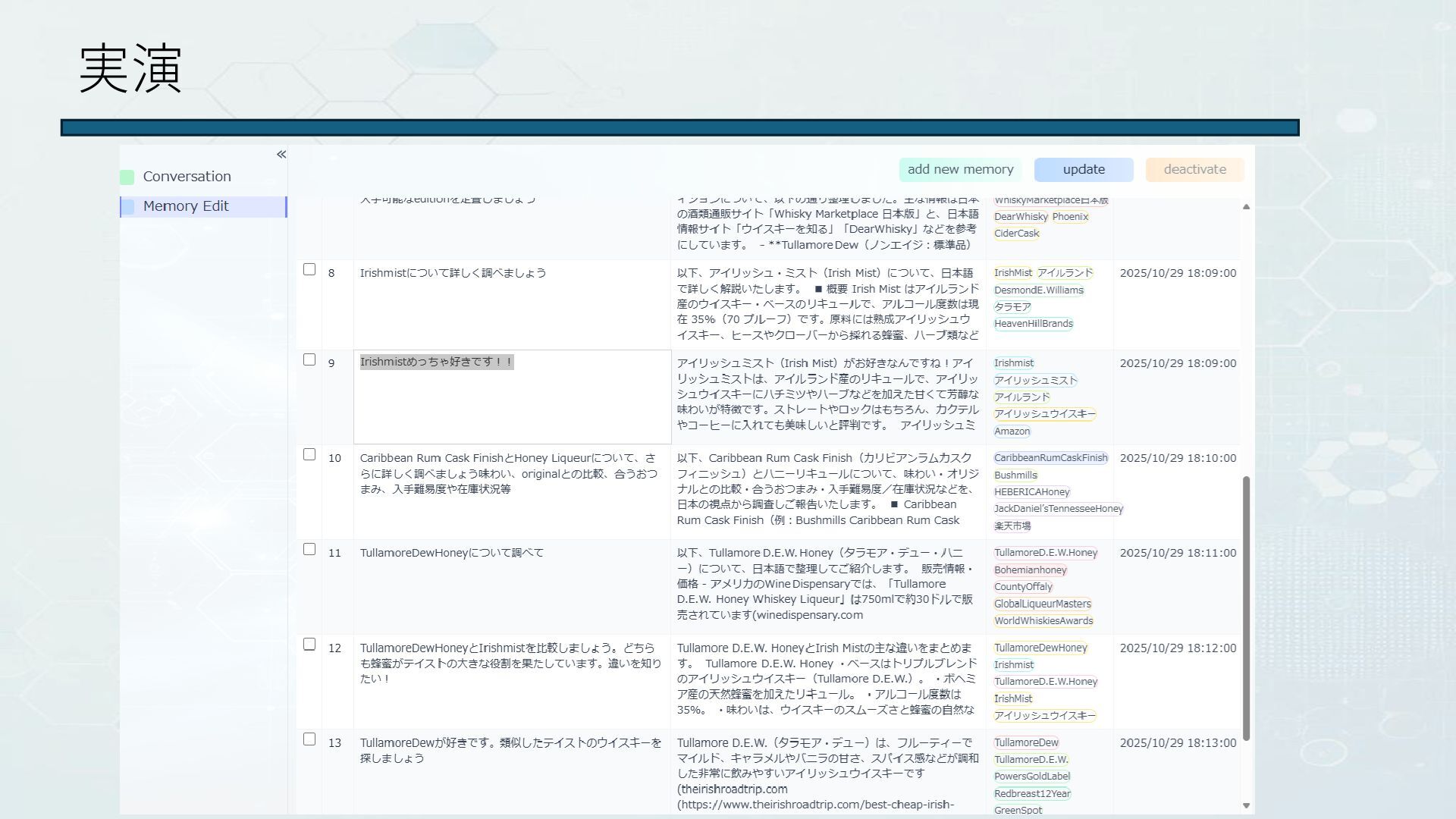
実演
まとめ AA : 記憶は [str保存、 summarize、 tag抽出、 vector化] により、 BB
: 記憶操作が可能なのはロマンありますね! CC : 人間記憶の完全再現は、 課題が多く 更なる要素が必要 RAGとしてある程度再現可能 やはり、 記憶は自由に編集したい!! 性格嗜好 環境 思考パターン 生い立ち等
- 3国間海外取引~国内取引~倉庫~営業~業務 を経験 / 業界歴 19 年 - 社内効率化 &
フロー改善の情報系部署 About me ・ Name : エビハラ ヨシタカ X @kuro_yos ・ 最近ハマっているもの : ebhr-san - SonarQube静的解析 : coding agent出口戦略/reviewフォローの一端 実装しました! Linter通りました! しかしダメでした! 確認します! への対策として - ベランダ菜園始めました : データ採取しまくって自動化ポイント探り中 将来的に、 小さい農地購入し ウイークデー自動化したい 気象庁が、 活用可能な ‘過去の気象データ’ を公開していて感動した。 有難く利用させていただきます 二等無人航空機操縦士取得して遠隔モニターしたい ・ 船舶業界の独立系専門商社
Thank you for your attention ご清聴ありがとうございました。
Appendix-1 : 掘り下げ より人間らしく 「不完全性」 を再現したいとしたら?! 1. 興味は無いけど覚えている映像や言葉は どう表現したら良いだろうか?! 例
: 幼稚園の頃の局部的な記憶、 初めてのXX、 キャパに収まらない出来事・・ React useEffectや イベント駆動Azure Functions的な? 何かの条件?! 2. 記憶のランダムな擦り替わり/思い違い はどう表現したら良いだろうか? 例 : 記憶に希望が乗ってしまうケースや ストーリー再構成・・ 閾値に沿って(98%の整合性)再要約?! 誤ったdatetime2でinsertしてみたり
Appendix-2 : RAG手法 1. tagや固有名詞抽出 2. vector比較 日本語と英語が混ざるケースが多い場合、 spacyやstanza等で cosine
similarity & euclidean distance 2段階絞込み 日英 2-pipeline 形態素解析ルーティングは未実施 (= LLM任せです) keyword hit rate集計 & vector比較の後、 re-ranker適用 3. re-ranker 各colを100分率算出 → top-scoreの30%以下drop → 最終sort
Appendix-3 : 発見 Long term memoryを実装してゆく中で、 興味深い事実が!!!! 大好きなリキュールの本がIrelandで出版されていたッッ Irish Mist:
the story of Tullamore's legendary liqueur 1945–1985 - Offaly History
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![実施事項 これらを基に 該当する内容/案件 = 過去の記憶 を特定し、 [input, reply, tag, summary]をcontextへ挿入可能としました。](https://files.speakerdeck.com/presentations/3b8a56a3a38146fca29a4885136102f6/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![まとめ AA : 記憶は [str保存、 summarize、 tag抽出、 vector化] により、 BB](https://files.speakerdeck.com/presentations/3b8a56a3a38146fca29a4885136102f6/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}