China • Affiliation: Aizawa Laboratory, D3 Graduate School of Information Science and Technology The University of Tokyo • Research interest: Open-set recognition Semi-supervised learning Domain adaptation • HP: yu1ut.com 2
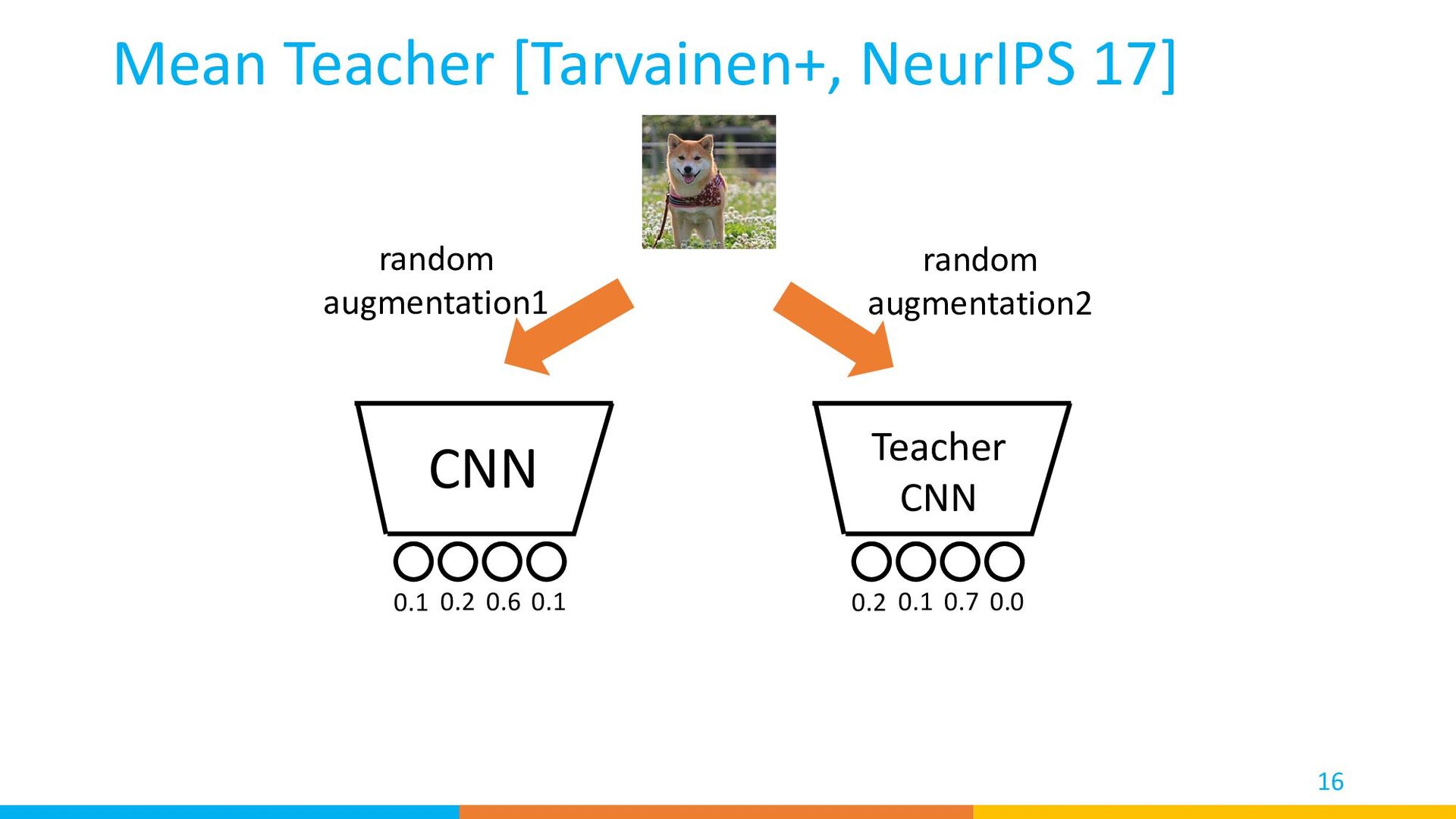
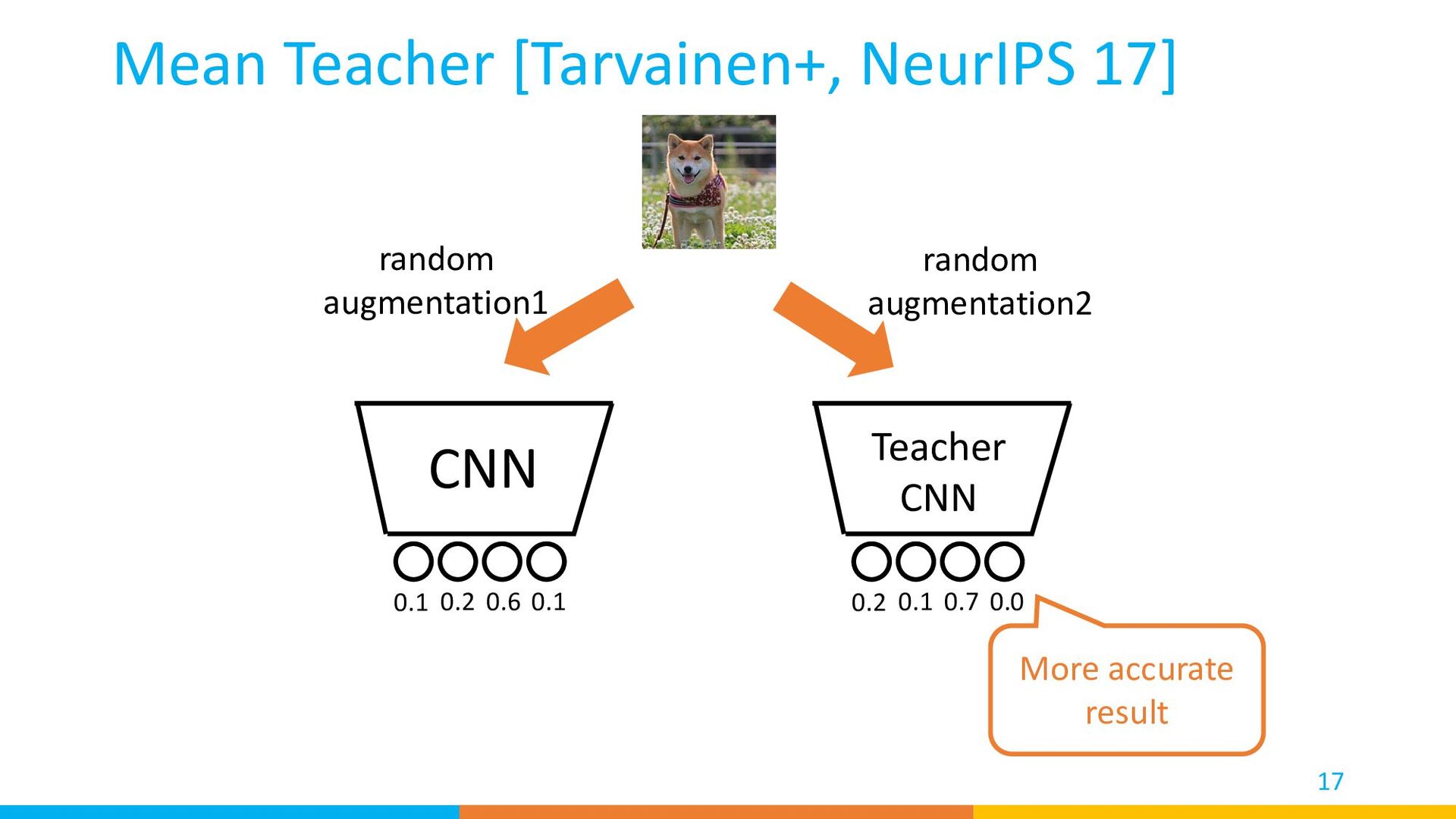
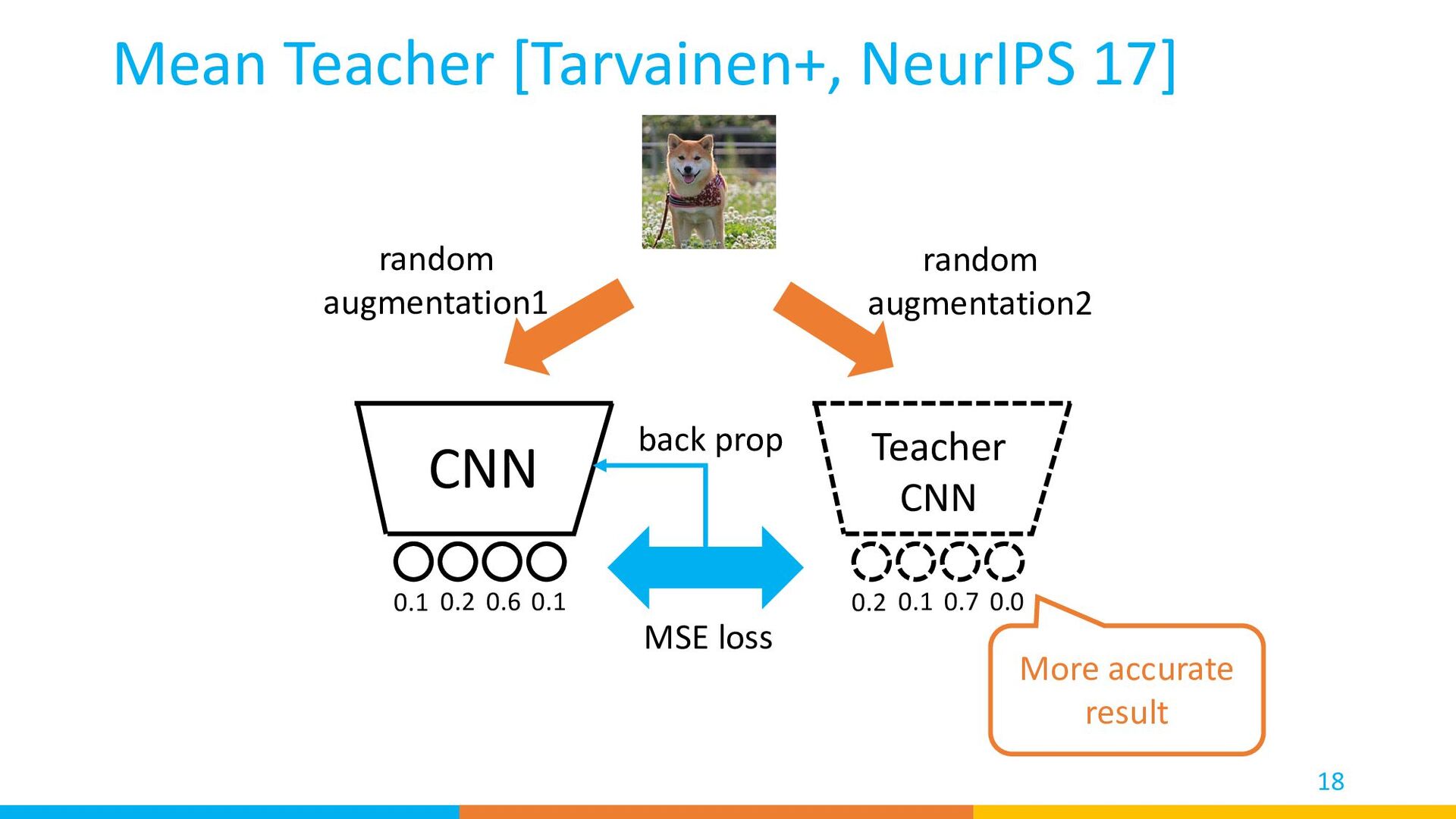
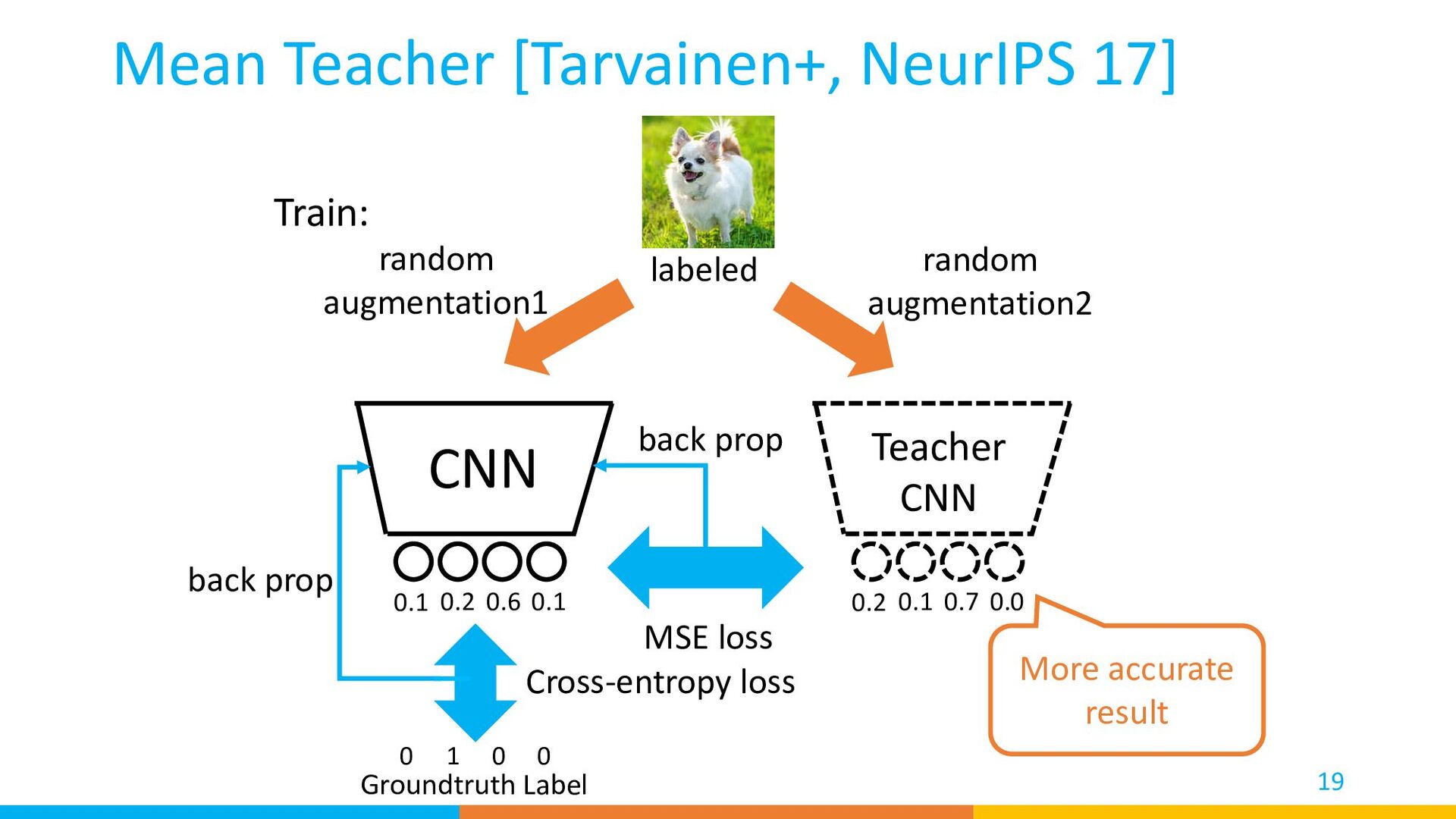
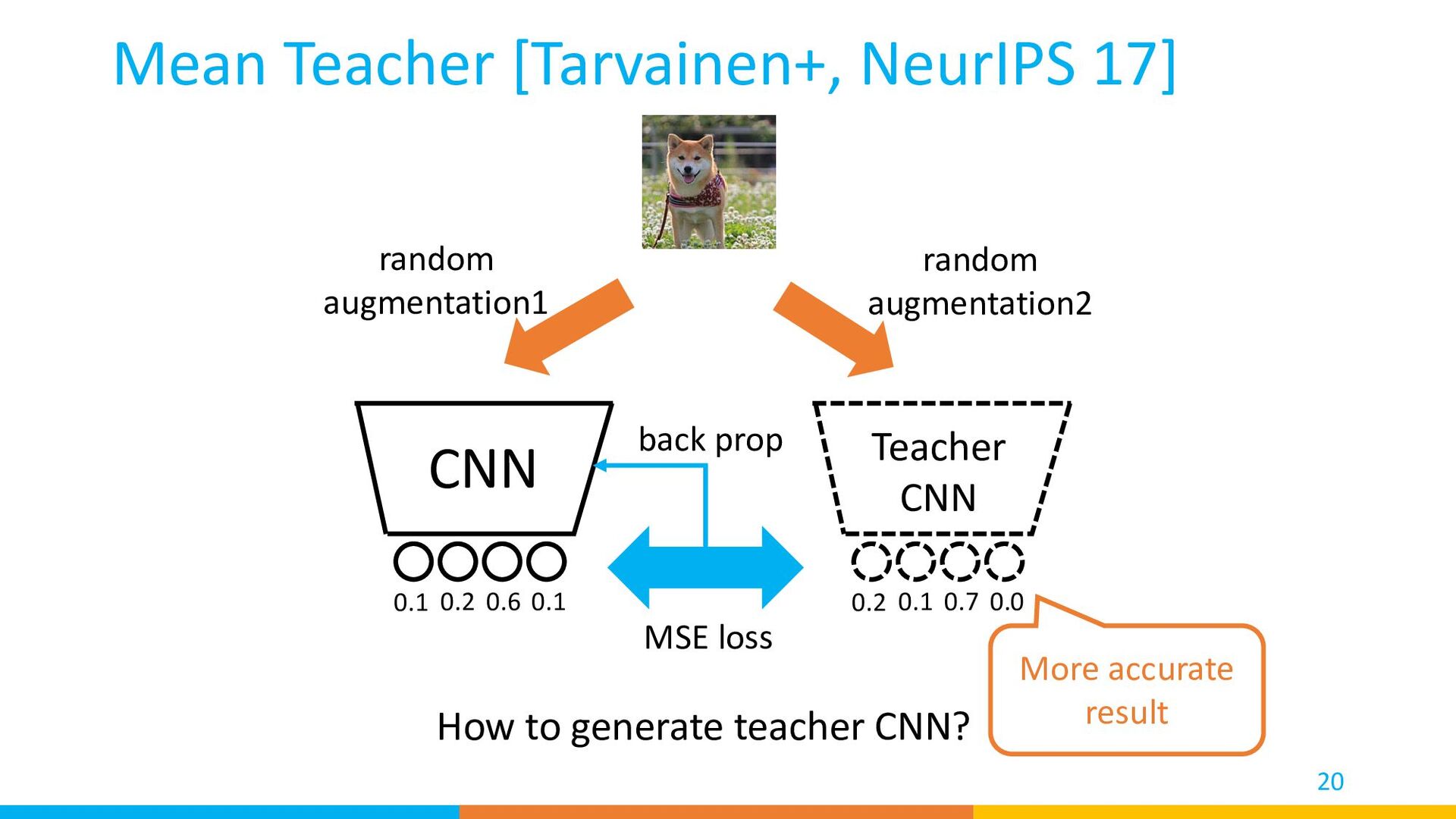
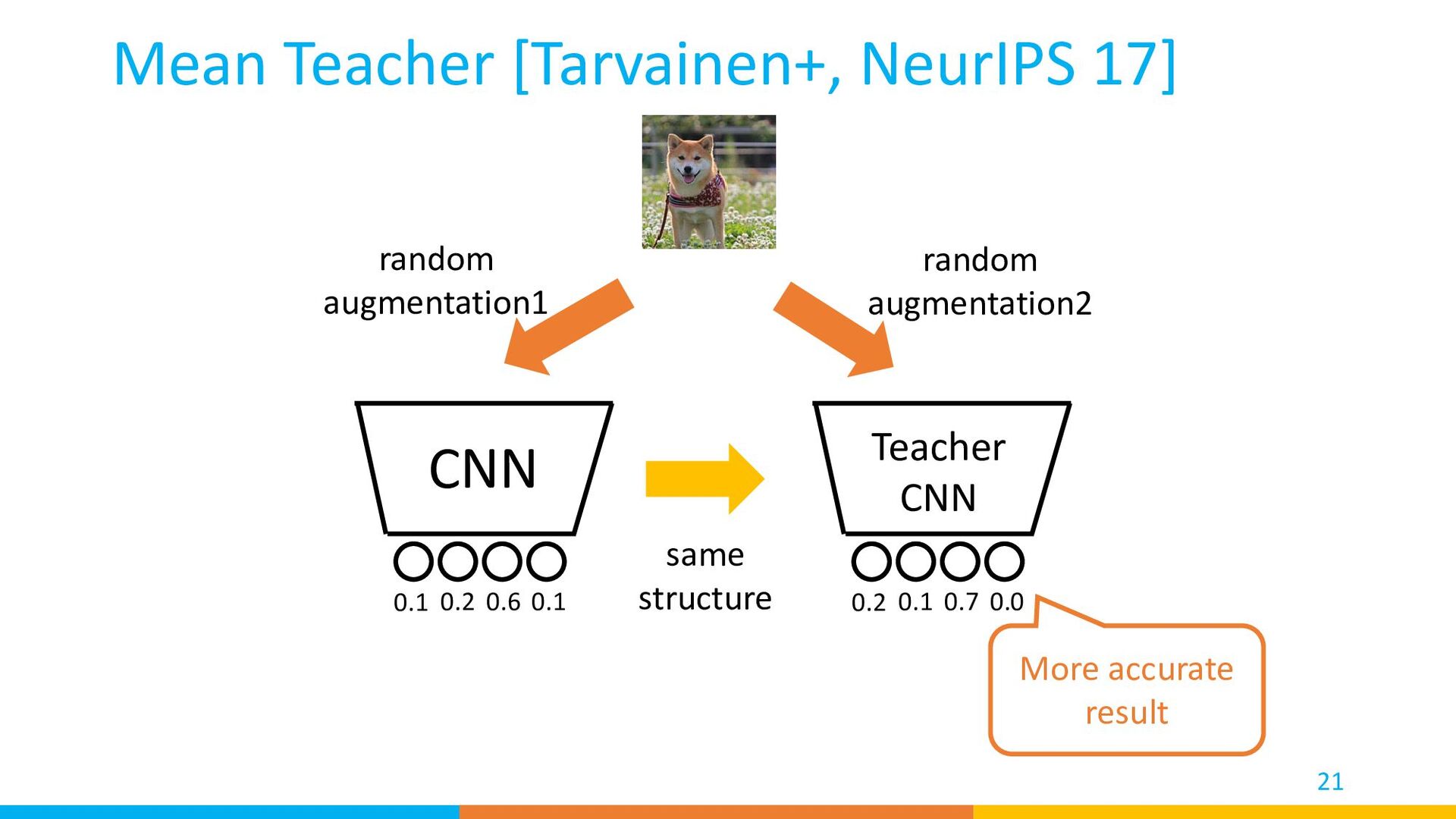
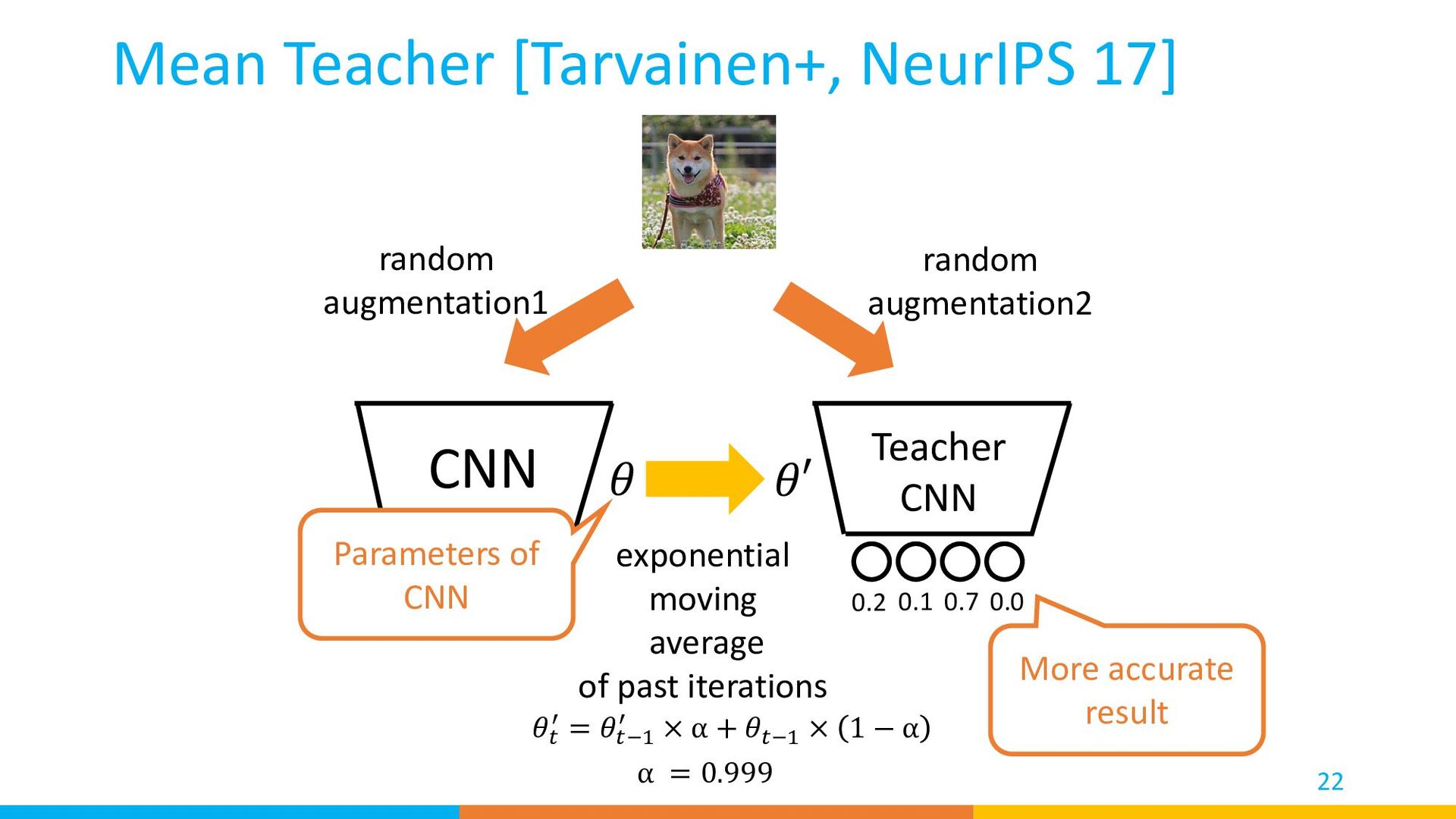
result MSE loss back prop 0 1 0 0 back prop Groundtruth Label Train: Mean Teacher [Tarvainen+, NeurIPS 17] Cross-entropy loss labeled 0.1 0.2 0.6 0.1 0.2 0.1 0.7 0.0
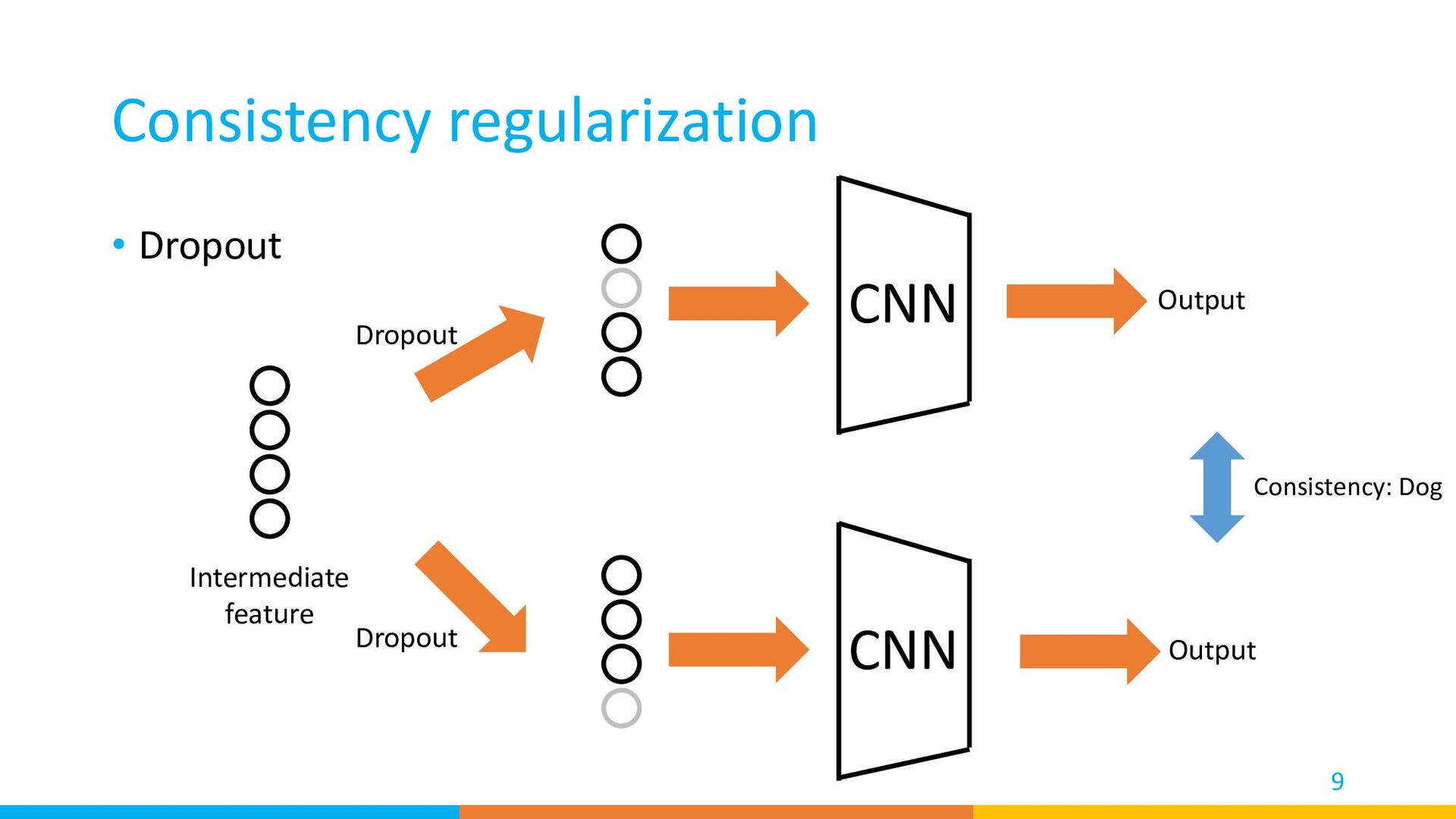
• Training Unlabeled Sample prediction pseudo label one-hot CNN CNN CNN prediction prediction prediction back prop Cross-entropy loss same network same network
≠ The performance in real-world • vs self-supervised learning • When the dataset is large enough, fine-tuning self-supervised models is enough? • vs zero-shot prediction (e.g. CLIP) • Is CLIP enough for most datasets? 50
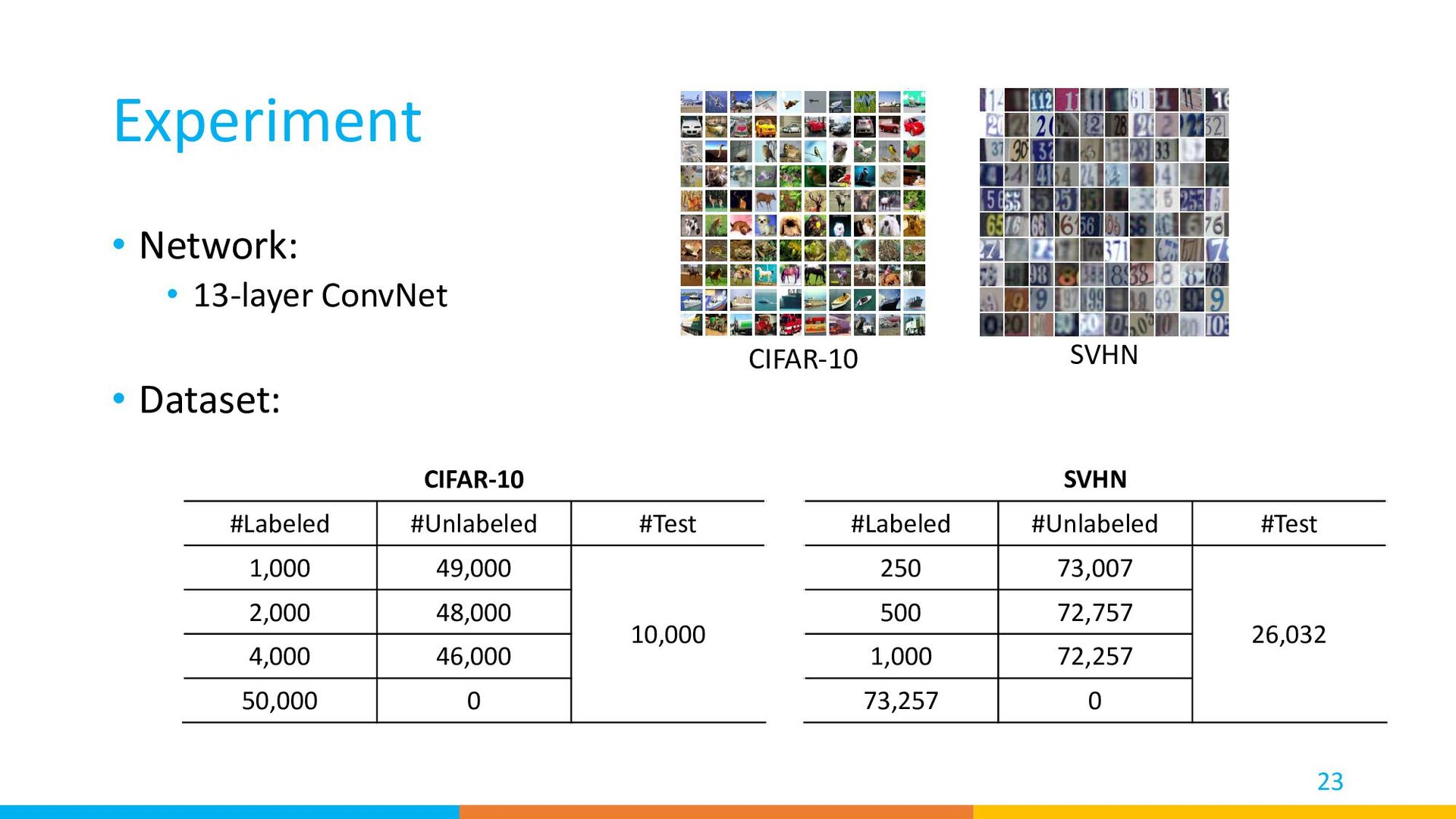
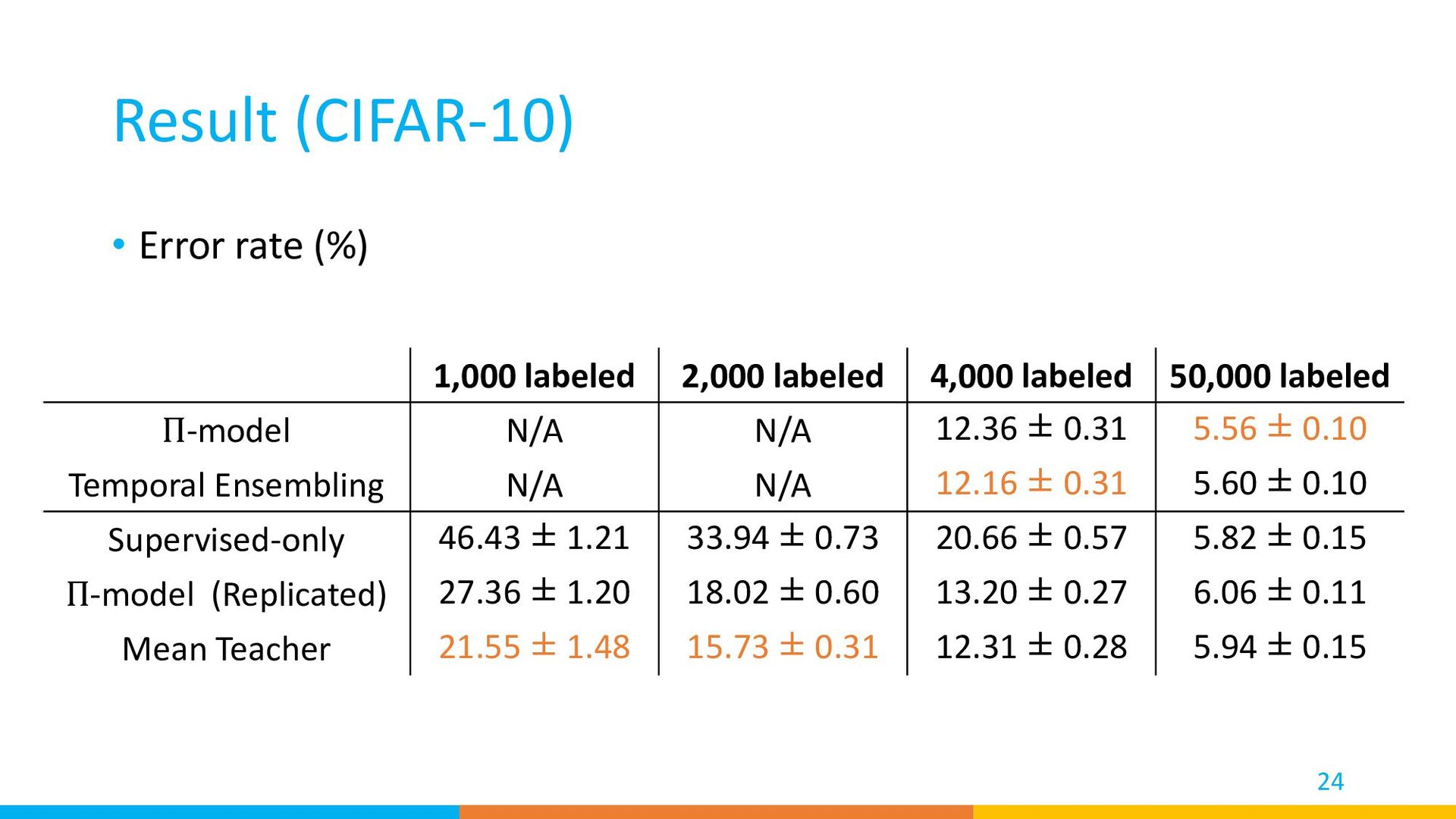
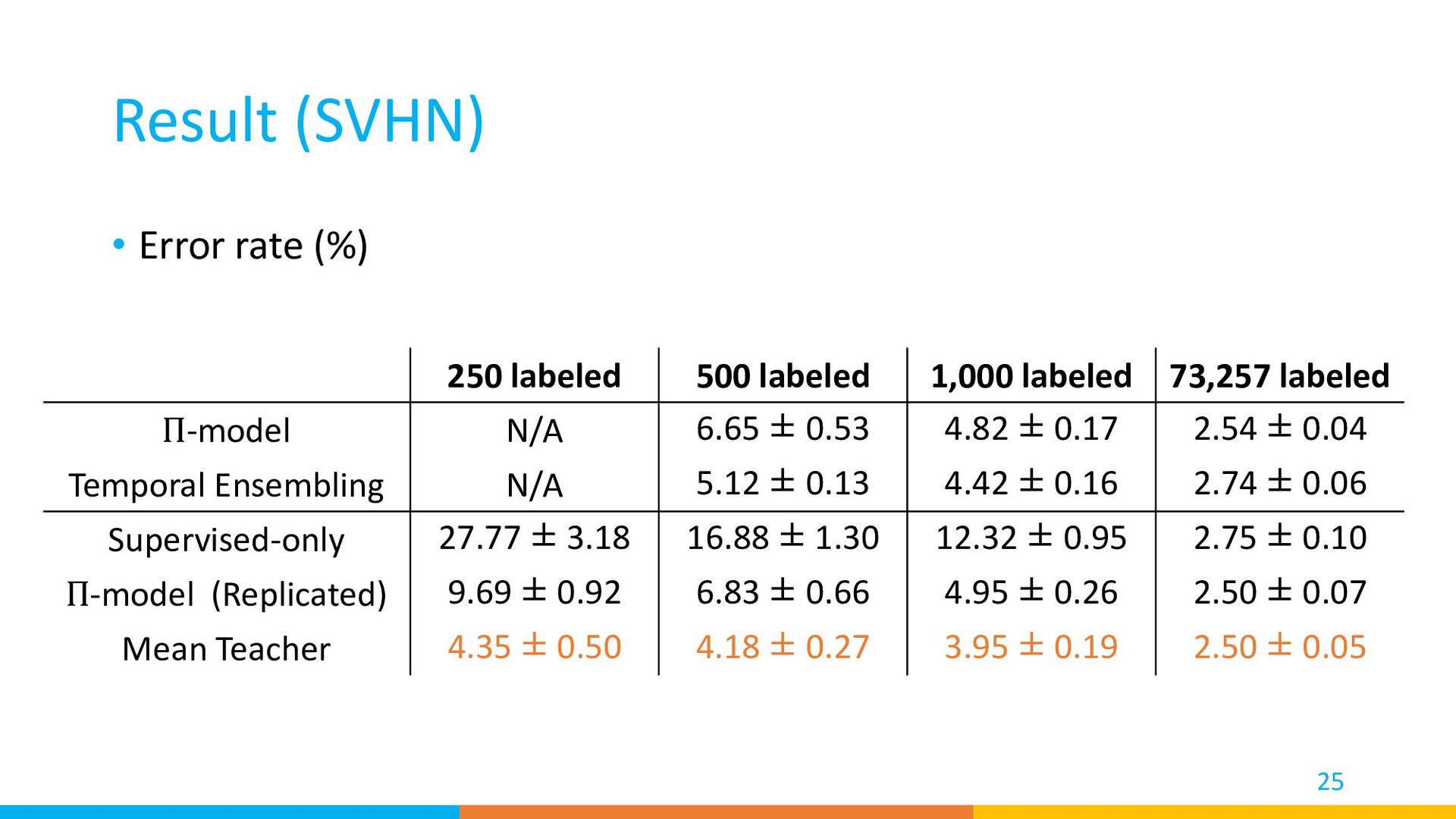
to train a model when only limited labeled data is available. • Recent methods can train a high performance model even when only 40 labeled samples are labeled. • Self-supervised learning and pretrained vision-and-language models are challenging semi-supervised learning. 51
{kind=link}
{kind=link}
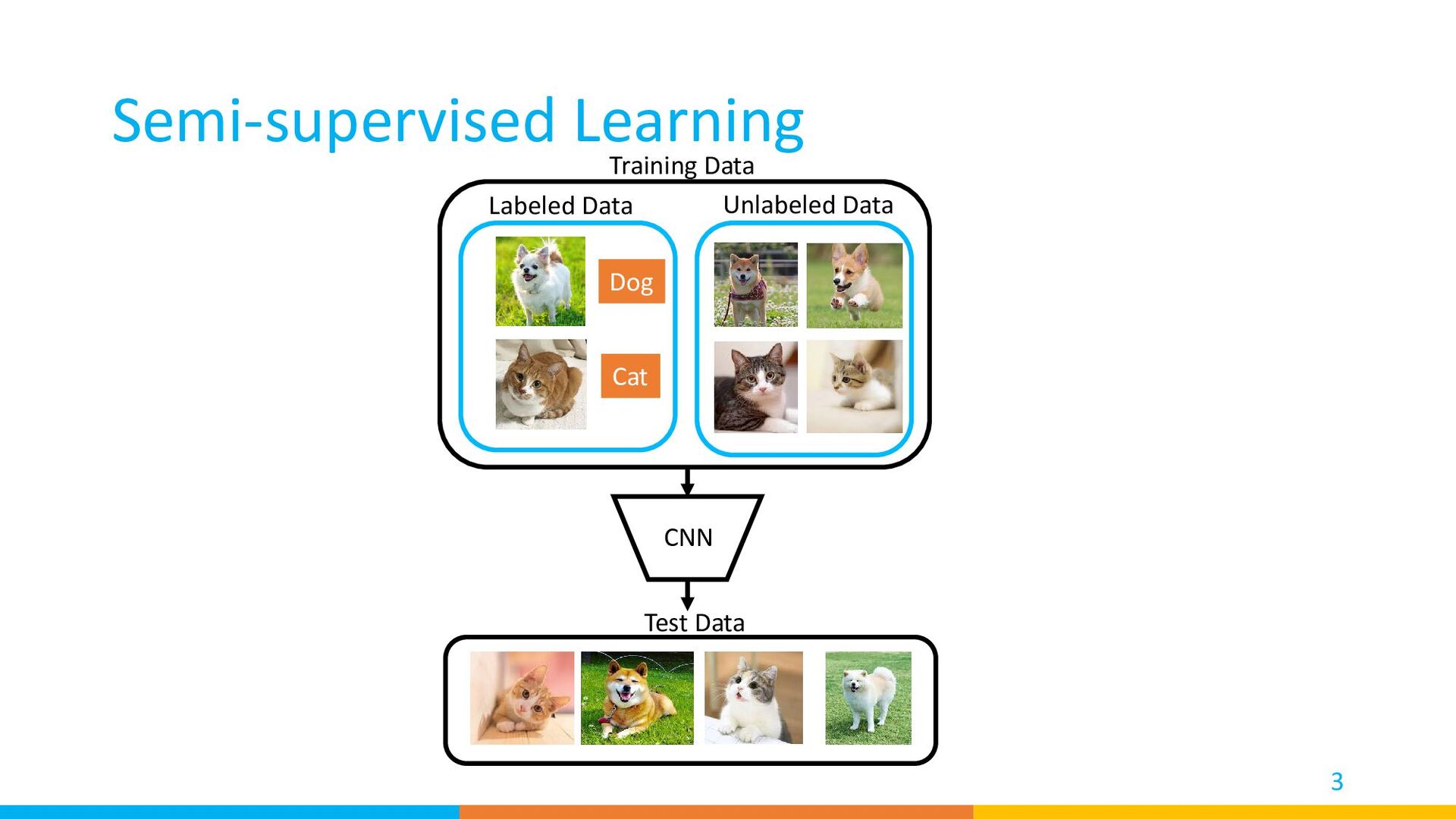{kind=link}
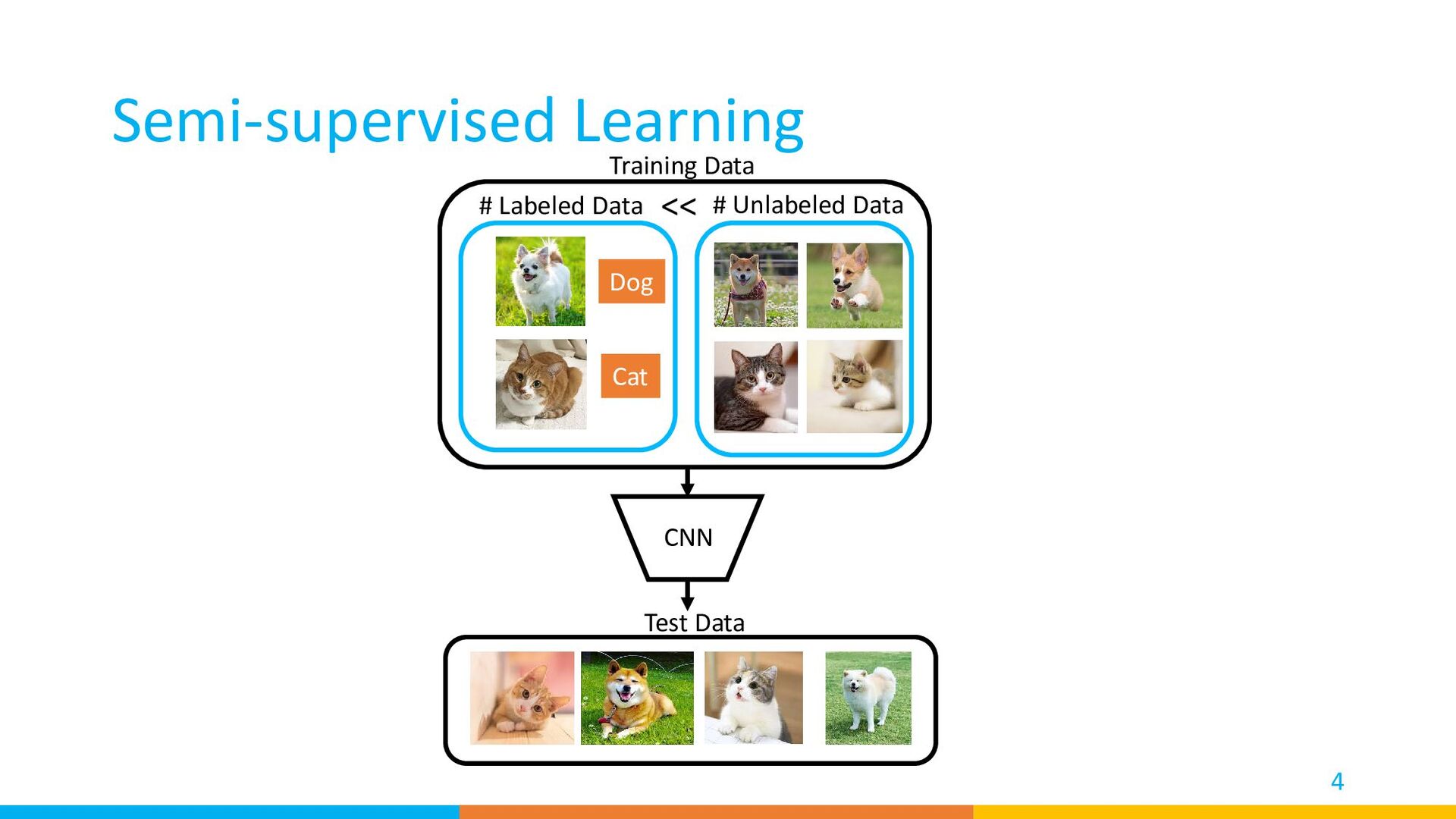{kind=link}
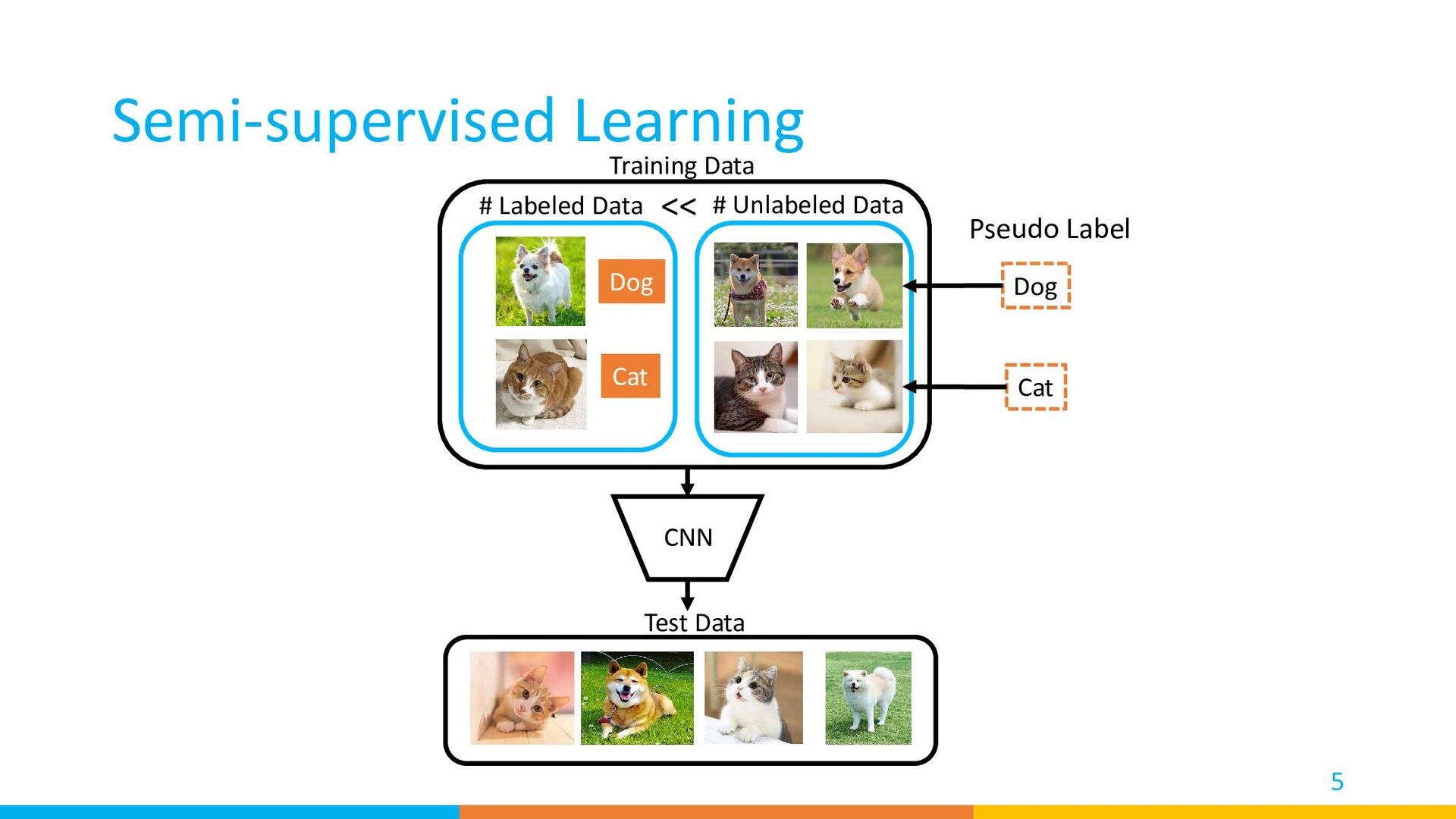{kind=link}
{kind=link}
{kind=link}
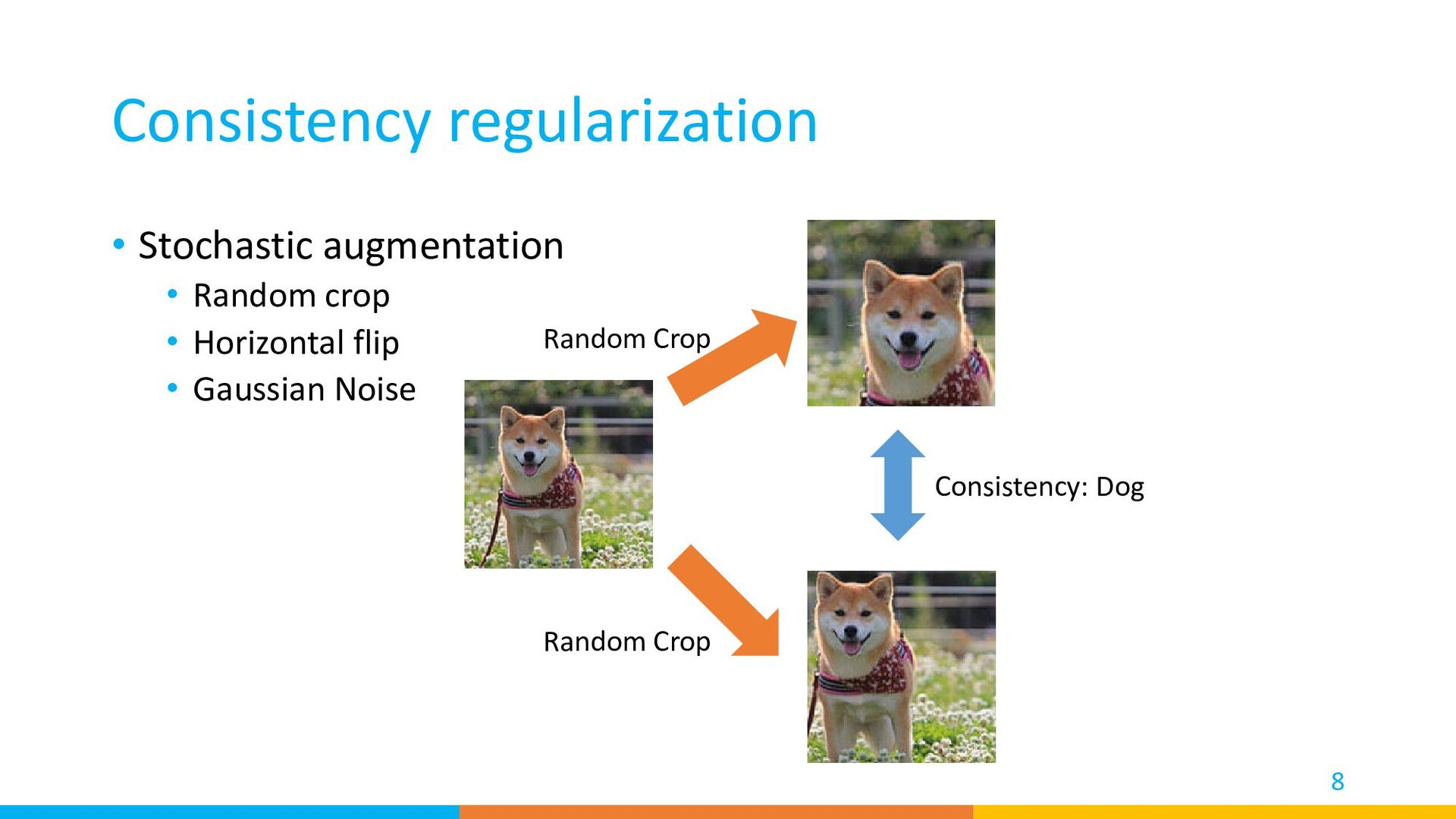{kind=link}
{kind=link}
{kind=link}
![11 random augmentation1 Π-model [Rasmus+, NeurIPS 15] 0.2 0.1 0.7](https://files.speakerdeck.com/presentations/2e67355703c5435e824fec4a383b6033/slide_10.jpg){kind=link}
![12 random augmentation1 Π-model [Rasmus+, NeurIPS 15] 0.2 0.1 0.7](https://files.speakerdeck.com/presentations/2e67355703c5435e824fec4a383b6033/slide_11.jpg){kind=link}
![13 random augmentation Temporal Ensembling [Laine+, ICLR 17] CNN w/](https://files.speakerdeck.com/presentations/2e67355703c5435e824fec4a383b6033/slide_12.jpg){kind=link}
![14 random augmentation Temporal Ensembling [Laine+, ICLR 17] CNN w/](https://files.speakerdeck.com/presentations/2e67355703c5435e824fec4a383b6033/slide_13.jpg){kind=link}
![15 random augmentation Temporal Ensembling [Laine+, ICLR 17] CNN w/](https://files.speakerdeck.com/presentations/2e67355703c5435e824fec4a383b6033/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![MixMatch [Berthelot+, NeurIPS 19] 29 CNN Unlabeled Sample random augmentation](https://files.speakerdeck.com/presentations/2e67355703c5435e824fec4a383b6033/slide_28.jpg){kind=link}
![MixMatch [Berthelot+, NeurIPS 19] 30 Mixup Unlabeled Sample Pseudo label:](https://files.speakerdeck.com/presentations/2e67355703c5435e824fec4a383b6033/slide_29.jpg){kind=link}
![ReMixMatch [Berthelot+, ICLR 20] 31 CNN weak augmentation pseudo label](https://files.speakerdeck.com/presentations/2e67355703c5435e824fec4a383b6033/slide_30.jpg){kind=link}
![ReMixMatch [Berthelot+, ICLR 20] 32 Mixup Unlabeled Sample Pseudo label:](https://files.speakerdeck.com/presentations/2e67355703c5435e824fec4a383b6033/slide_31.jpg){kind=link}
![• Training (Rotation predicting) ReMixMatch [Berthelot+, ICLR 20] 33 Unlabeled](https://files.speakerdeck.com/presentations/2e67355703c5435e824fec4a383b6033/slide_32.jpg){kind=link}
![FixMatch [Sohn+, NeurIPS 20] 34 CNN weak augmentation strong augmentation](https://files.speakerdeck.com/presentations/2e67355703c5435e824fec4a383b6033/slide_33.jpg){kind=link}
{kind=link}
![Experiment • Realistic Evaluation of Semi-Supervised Learning [Oliver+, NeurIPS 18]](https://files.speakerdeck.com/presentations/2e67355703c5435e824fec4a383b6033/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Recent methods • Dash [Xu+, ICML 21] • CoMatch [Li+,](https://files.speakerdeck.com/presentations/2e67355703c5435e824fec4a383b6033/slide_39.jpg){kind=link}
{kind=link}
{kind=link}
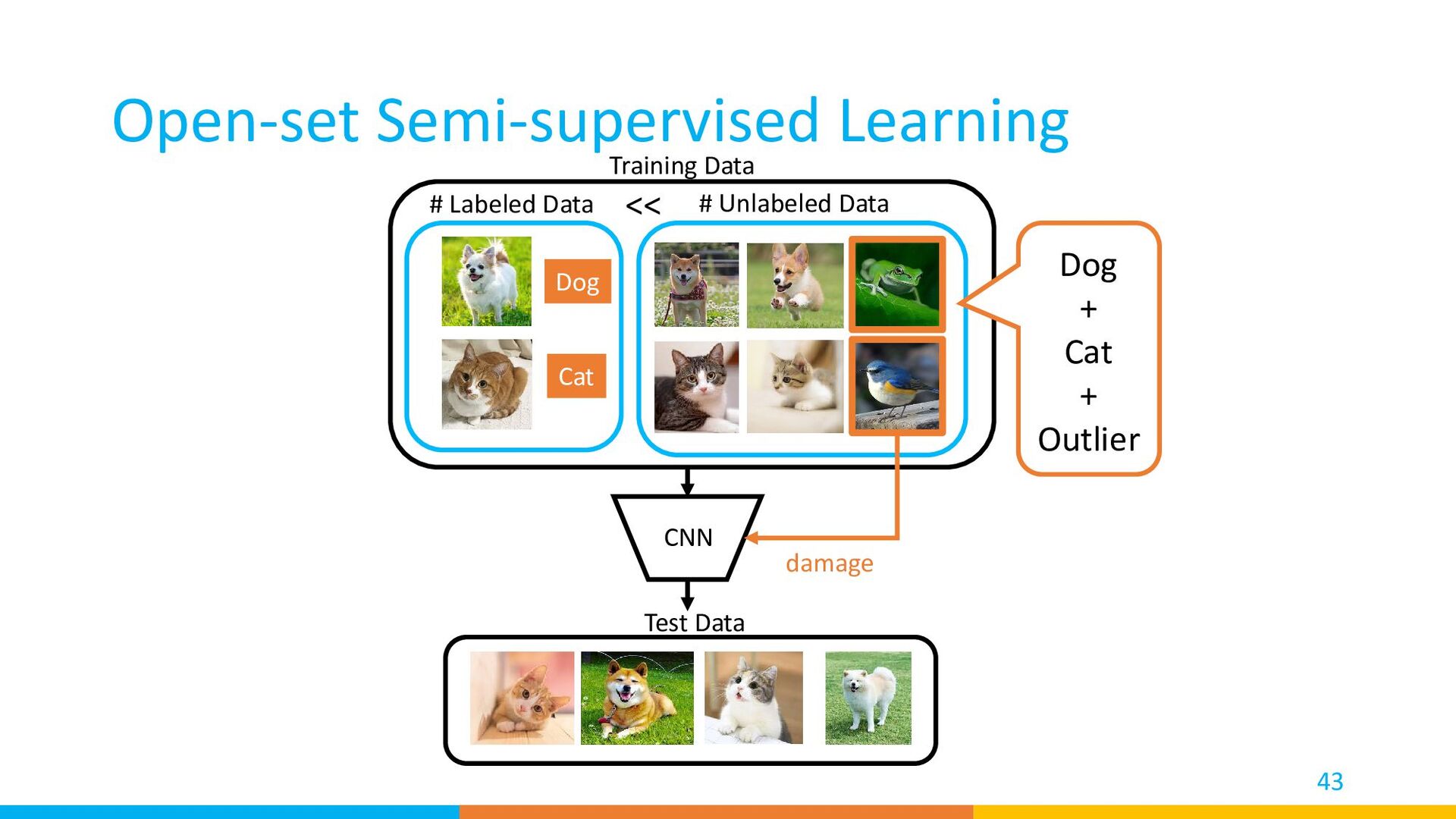{kind=link}
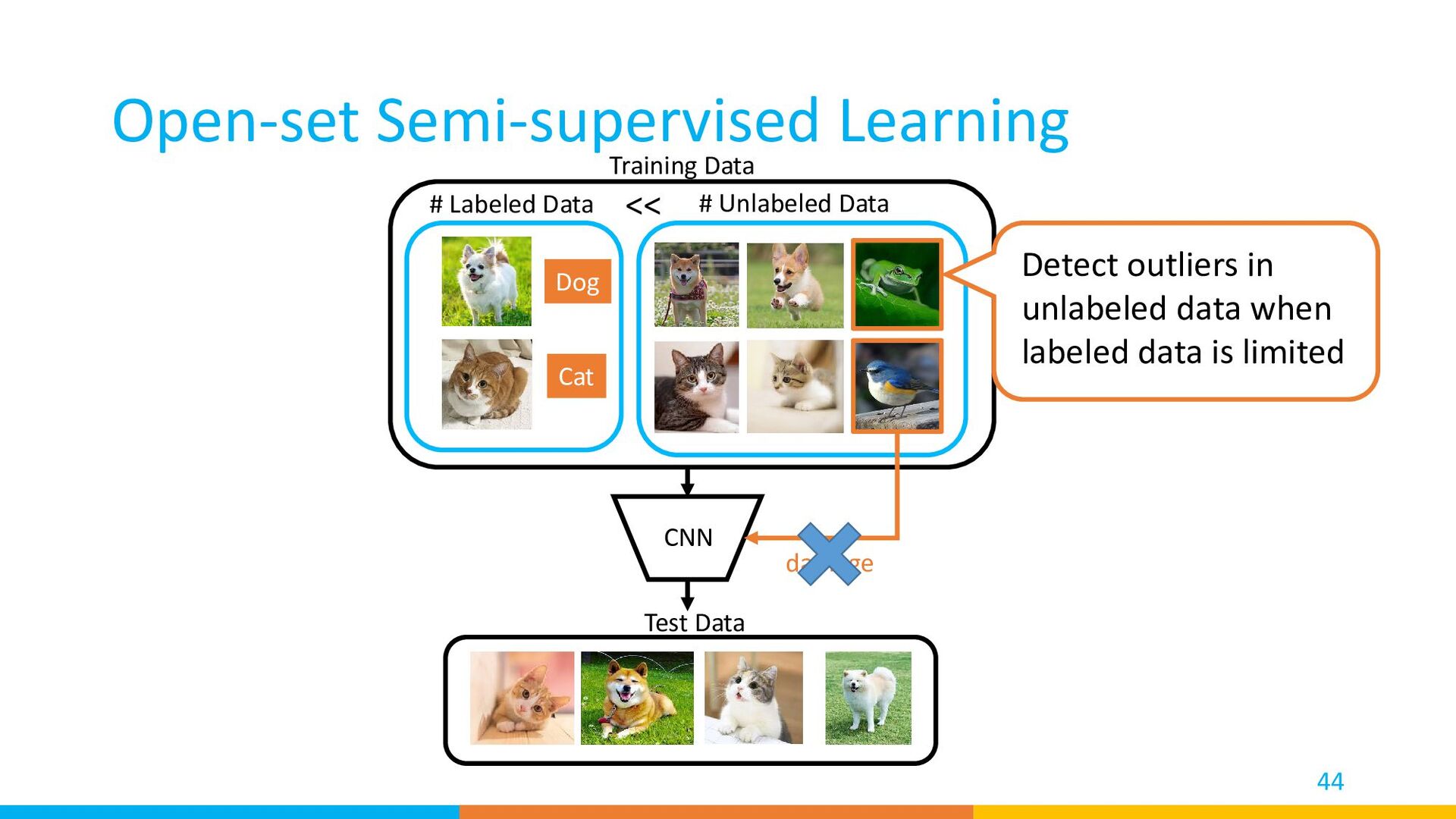{kind=link}
{kind=link}
![Multi-Task Curriculum Framework [Yu+, ECCV 20] 46 CNN Class Label](https://files.speakerdeck.com/presentations/2e67355703c5435e824fec4a383b6033/slide_45.jpg){kind=link}
![Multi-Task Curriculum Framework [Yu+, ECCV 20] 47 • Framework Detect](https://files.speakerdeck.com/presentations/2e67355703c5435e824fec4a383b6033/slide_46.jpg){kind=link}
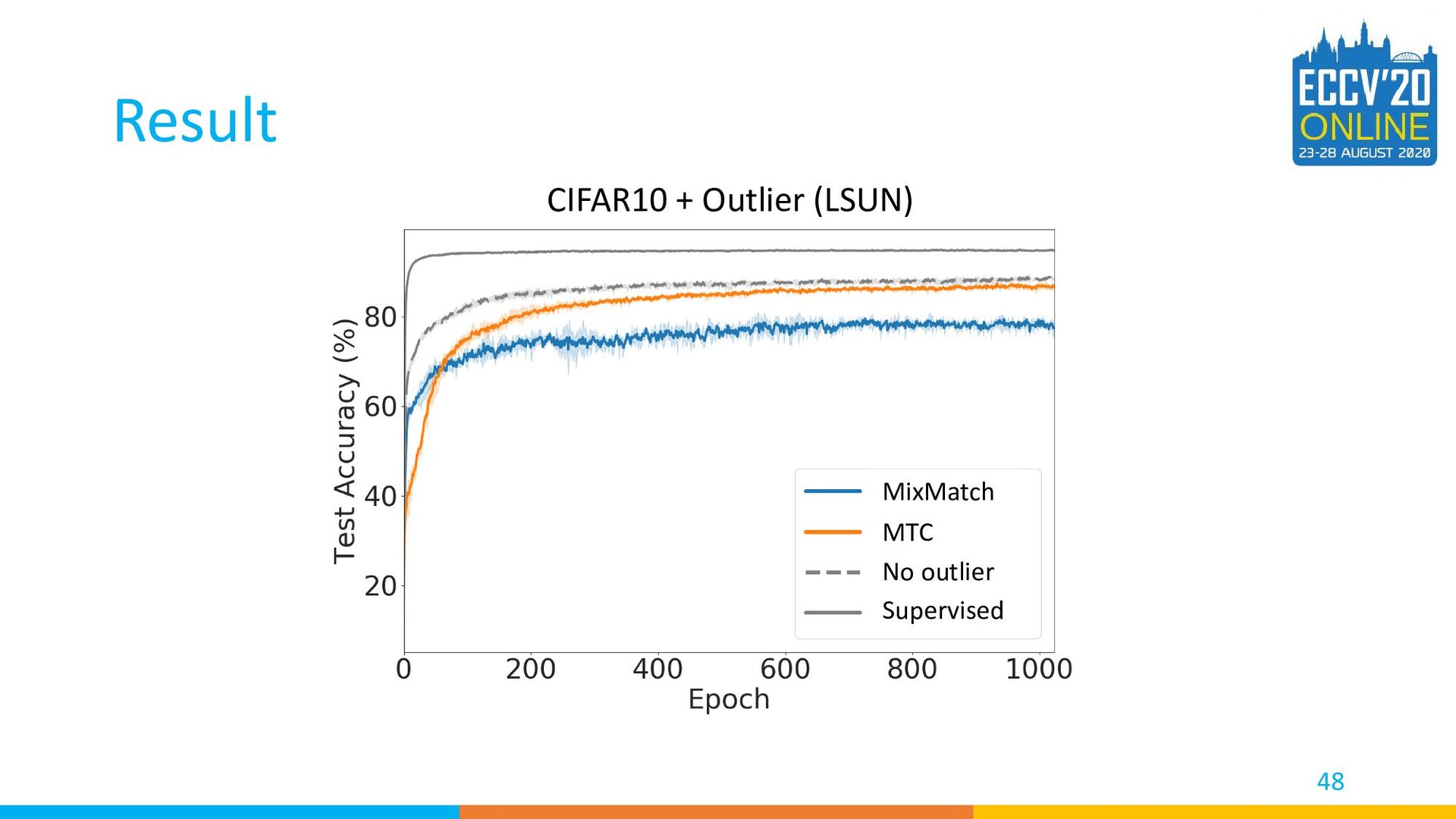{kind=link}
{kind=link}
{kind=link}
{kind=link}