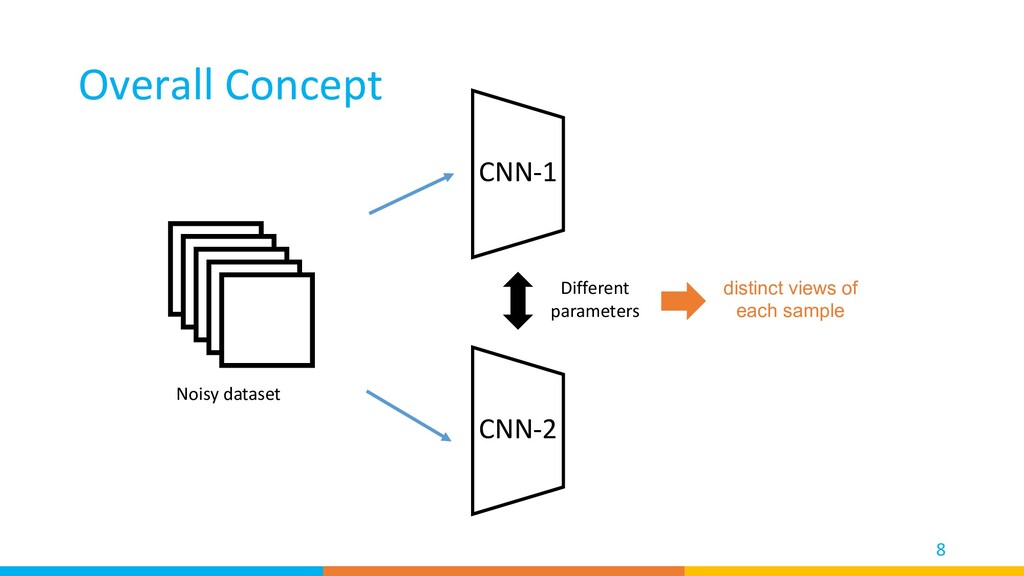
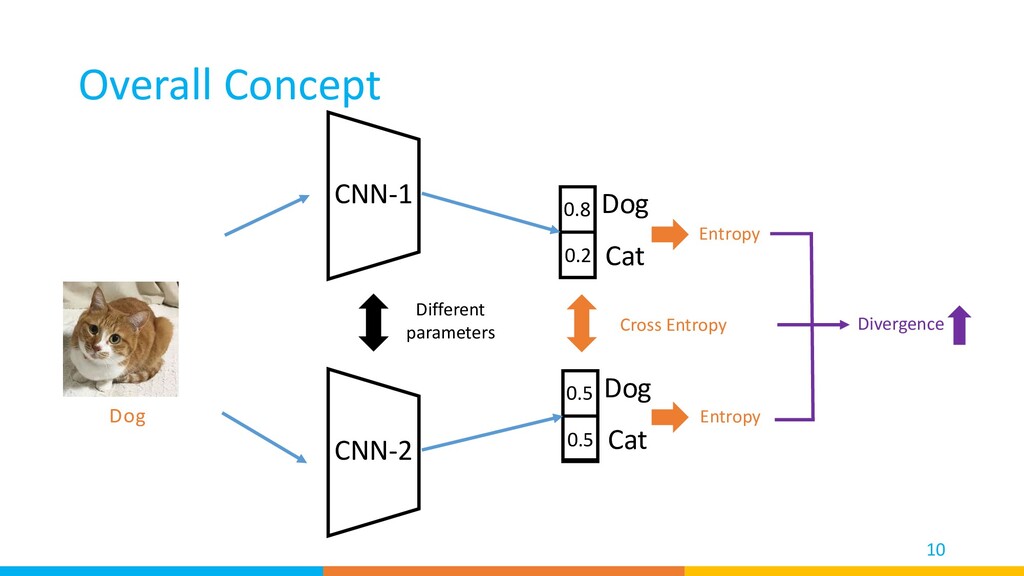
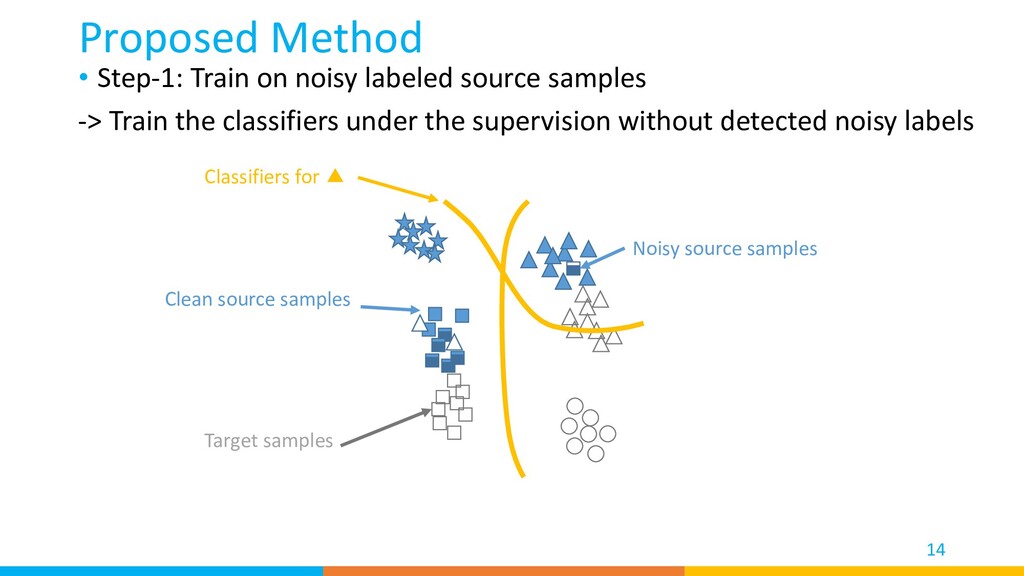
samples -> Train the classifiers under the supervision without detected noisy labels Clean source samples Classifiers for ▲ Target samples Noisy source samples
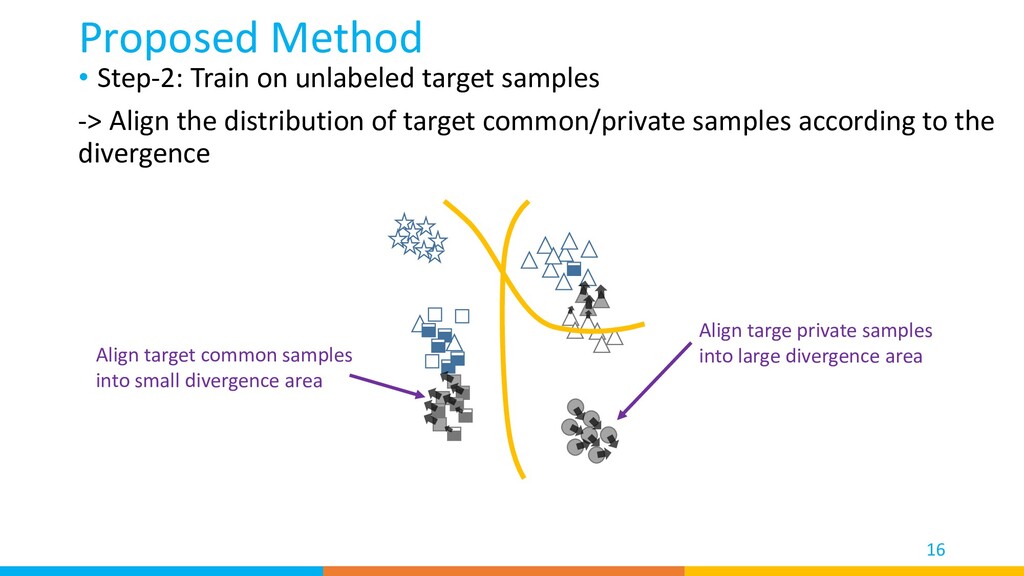
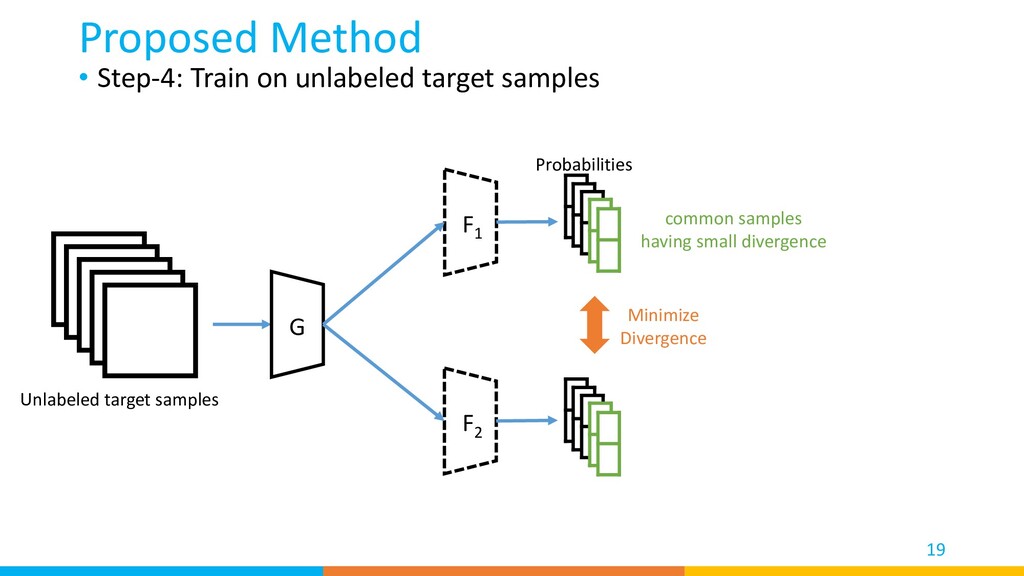
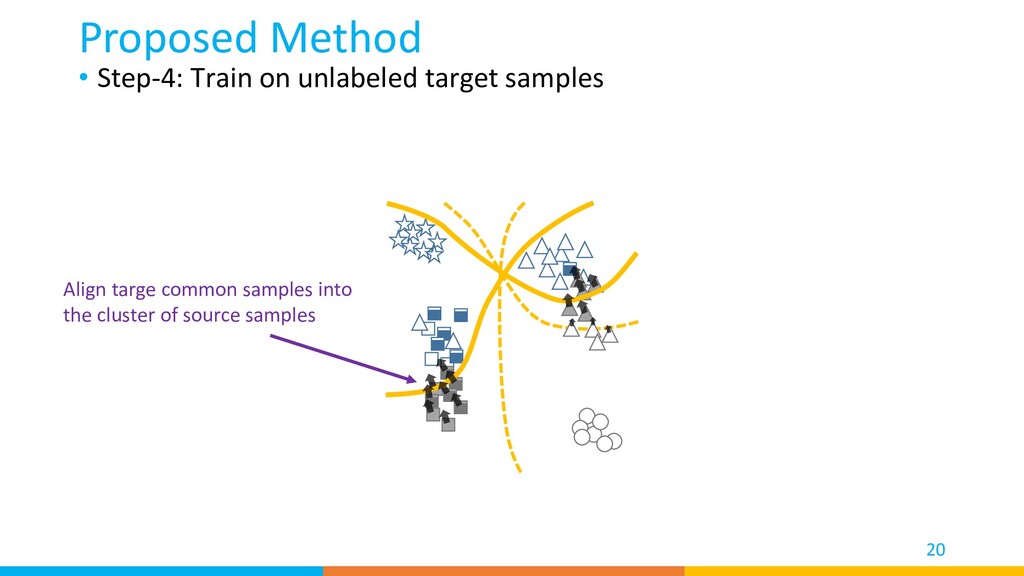
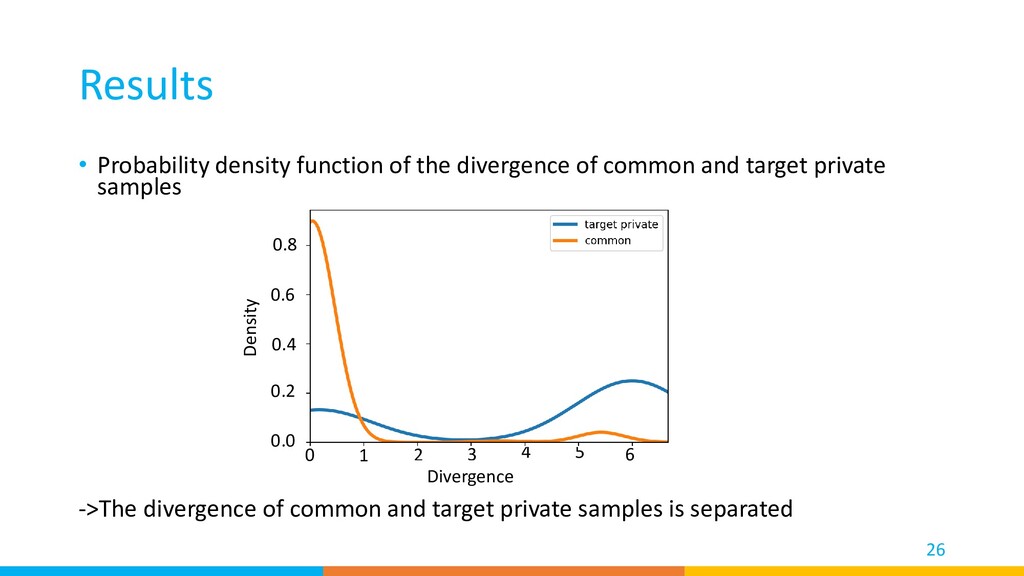
distribution of target common/private samples according to the divergence Proposed Method 16 Align target common samples into small divergence area Align targe private samples into large divergence area
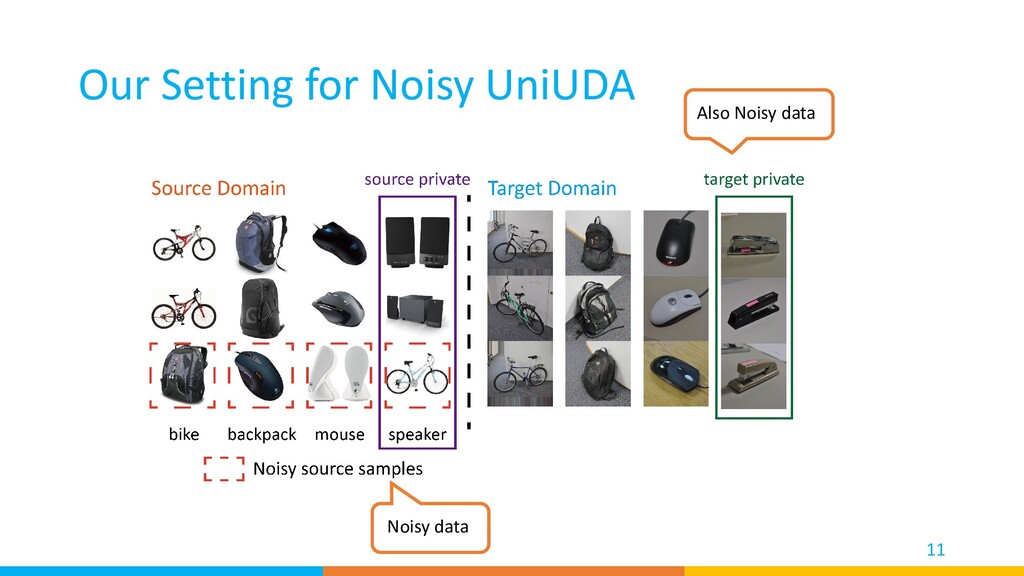
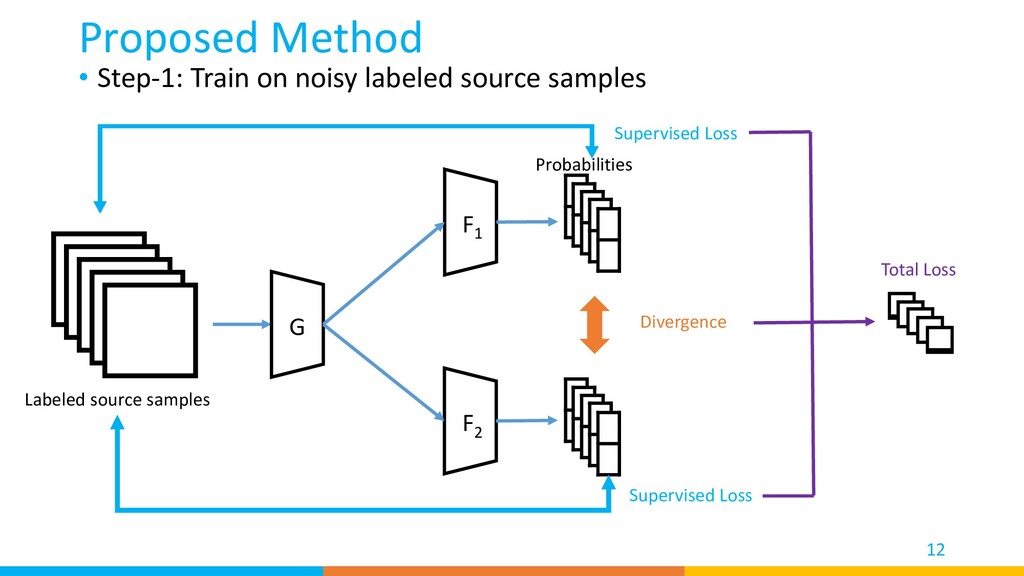
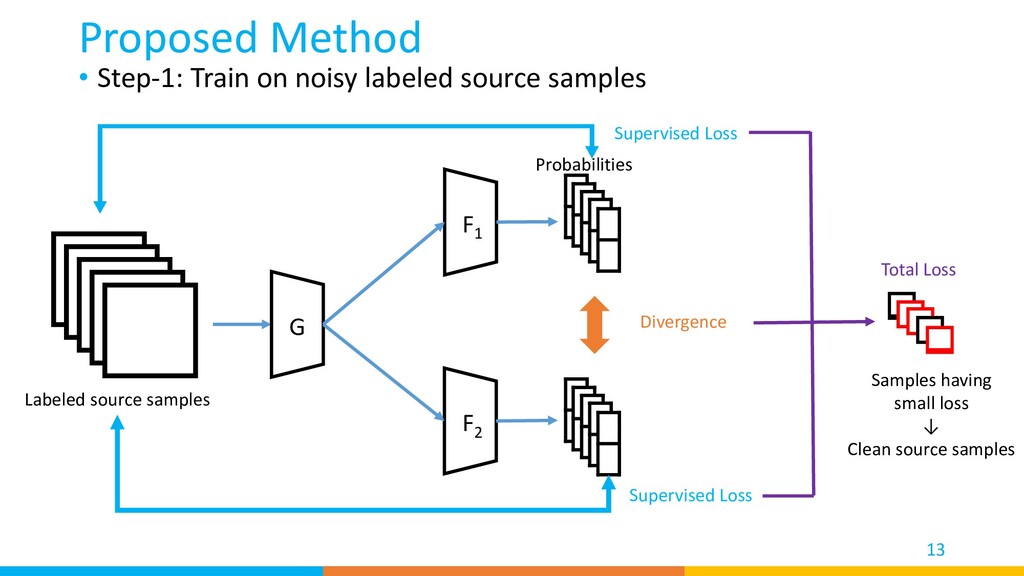
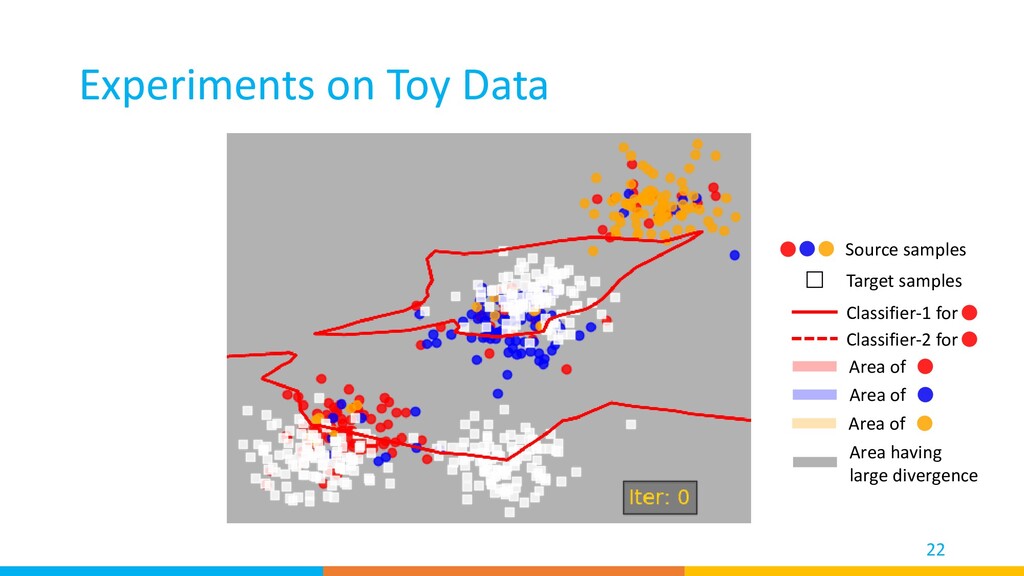
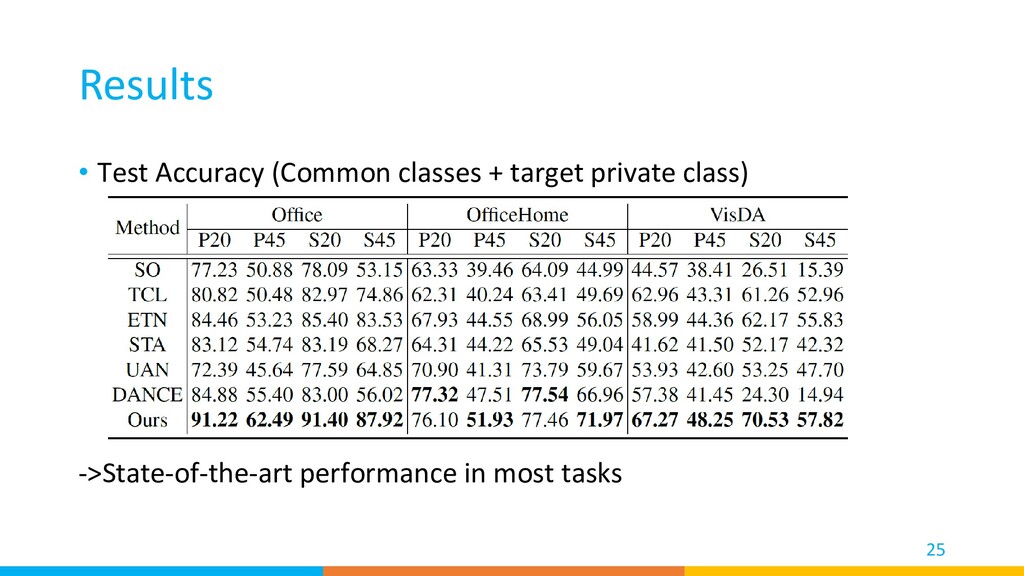
We used two classifiers to find clean source samples, reject target private classes, and find important target samples that contribute most to the model’s adaptation. • Our method achieved high performance on a diverse set of benchmarks. 27
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
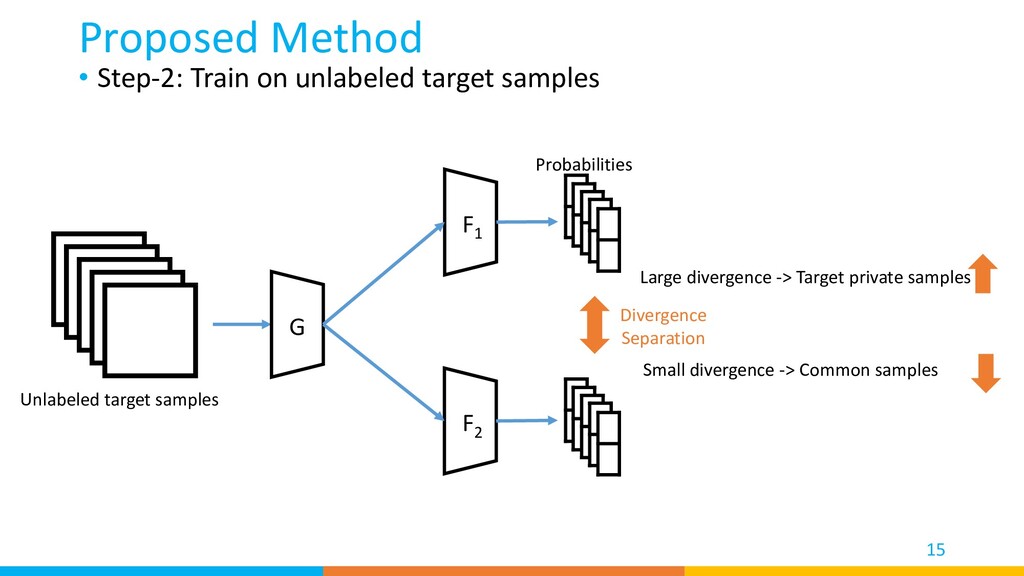{kind=link}
{kind=link}
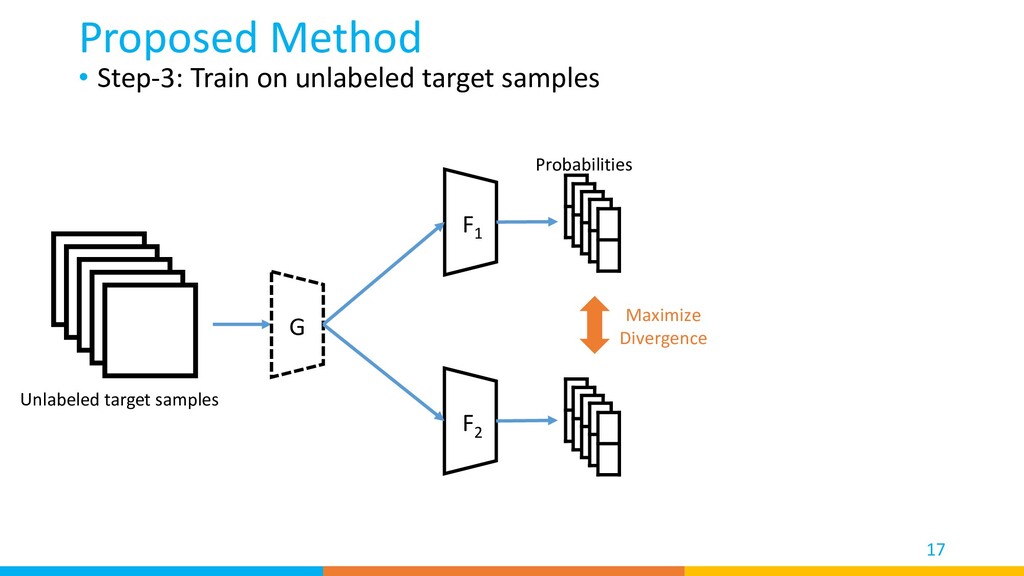{kind=link}
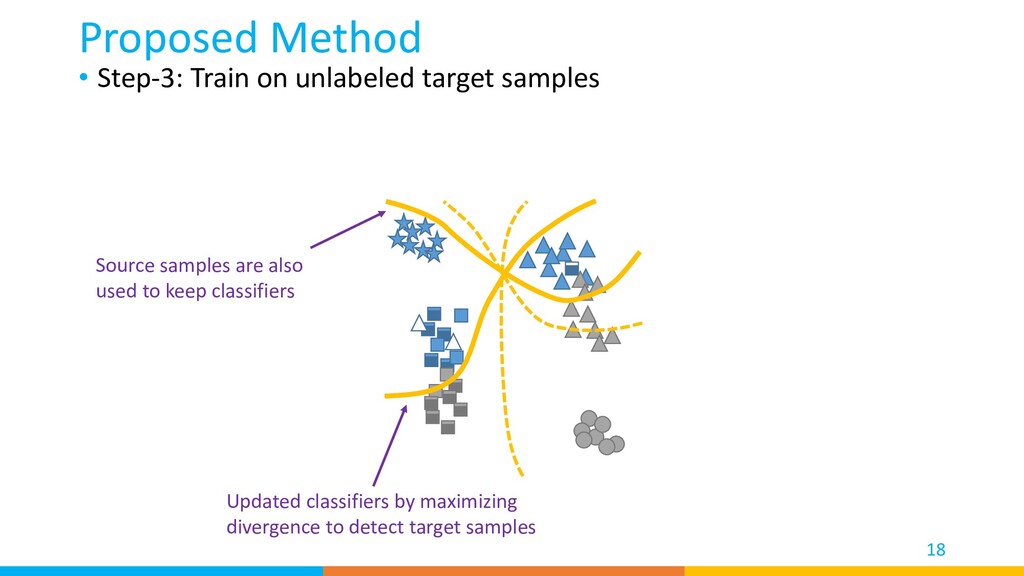{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}