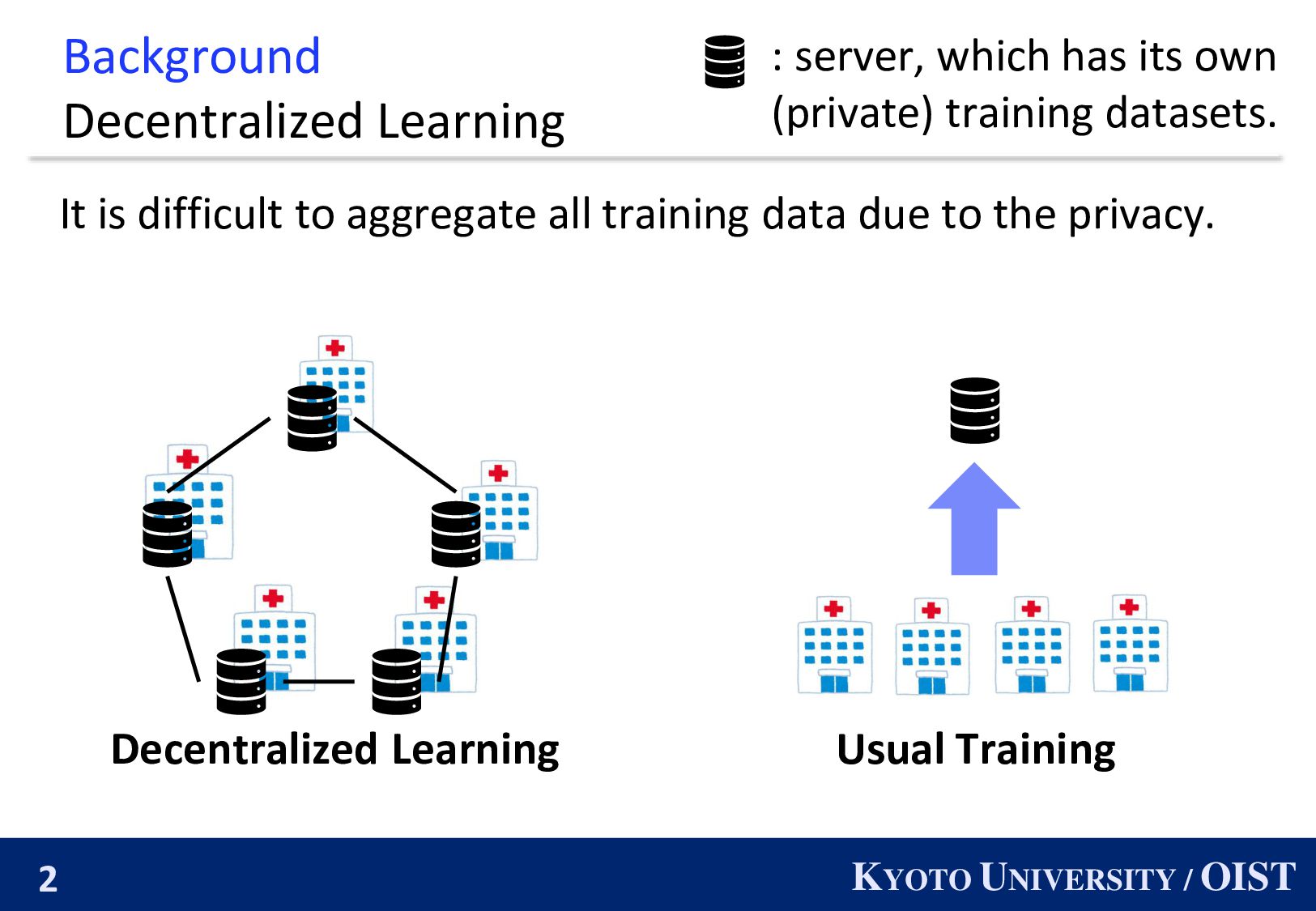
difficult to aggregate all training data due to the privacy. : server, which has its own (private) training datasets. Decentralized Learning Usual Training
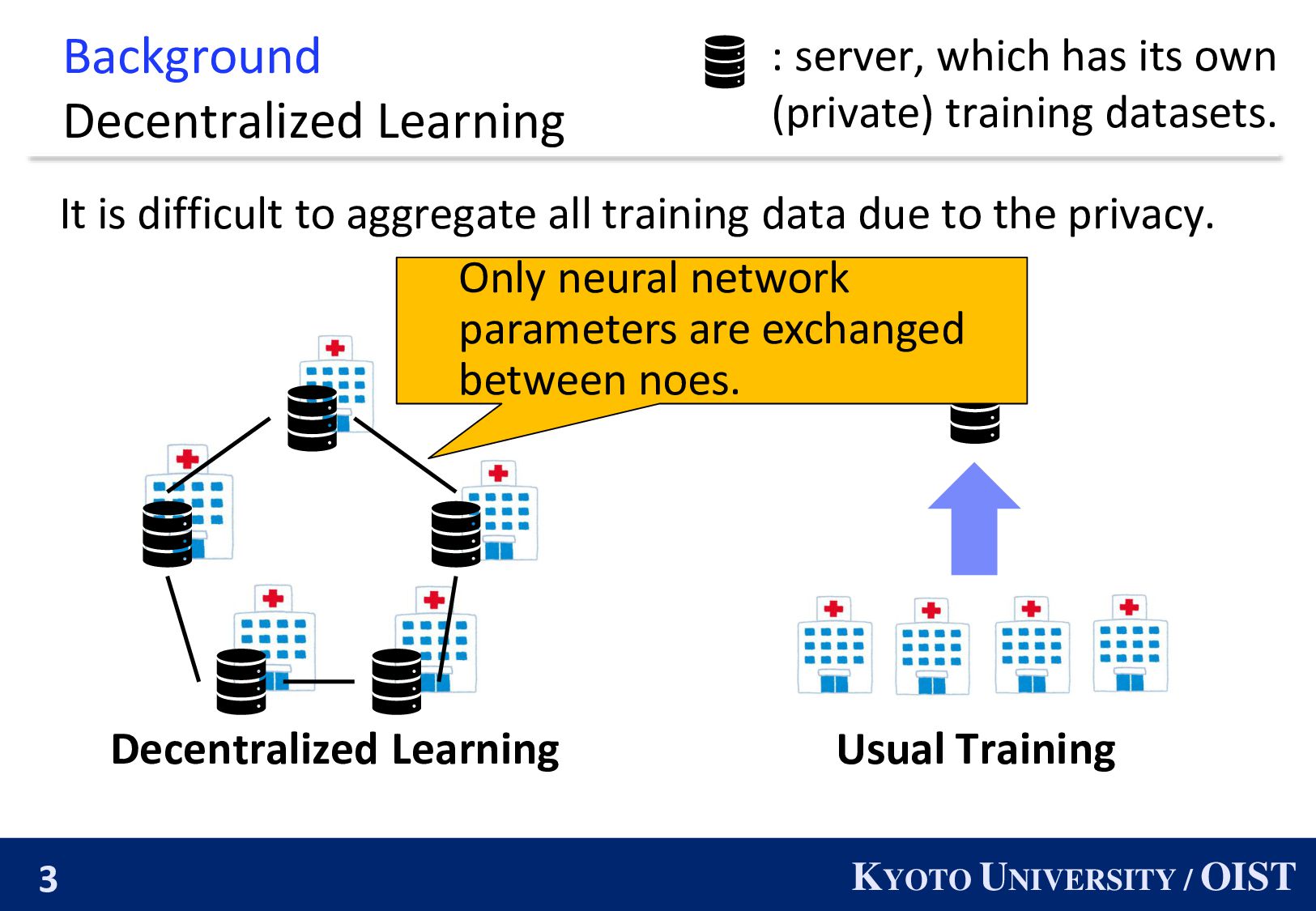
difficult to aggregate all training data due to the privacy. : server, which has its own (private) training datasets. Decentralized Learning Usual Training Only neural network parameters are exchanged between noes.
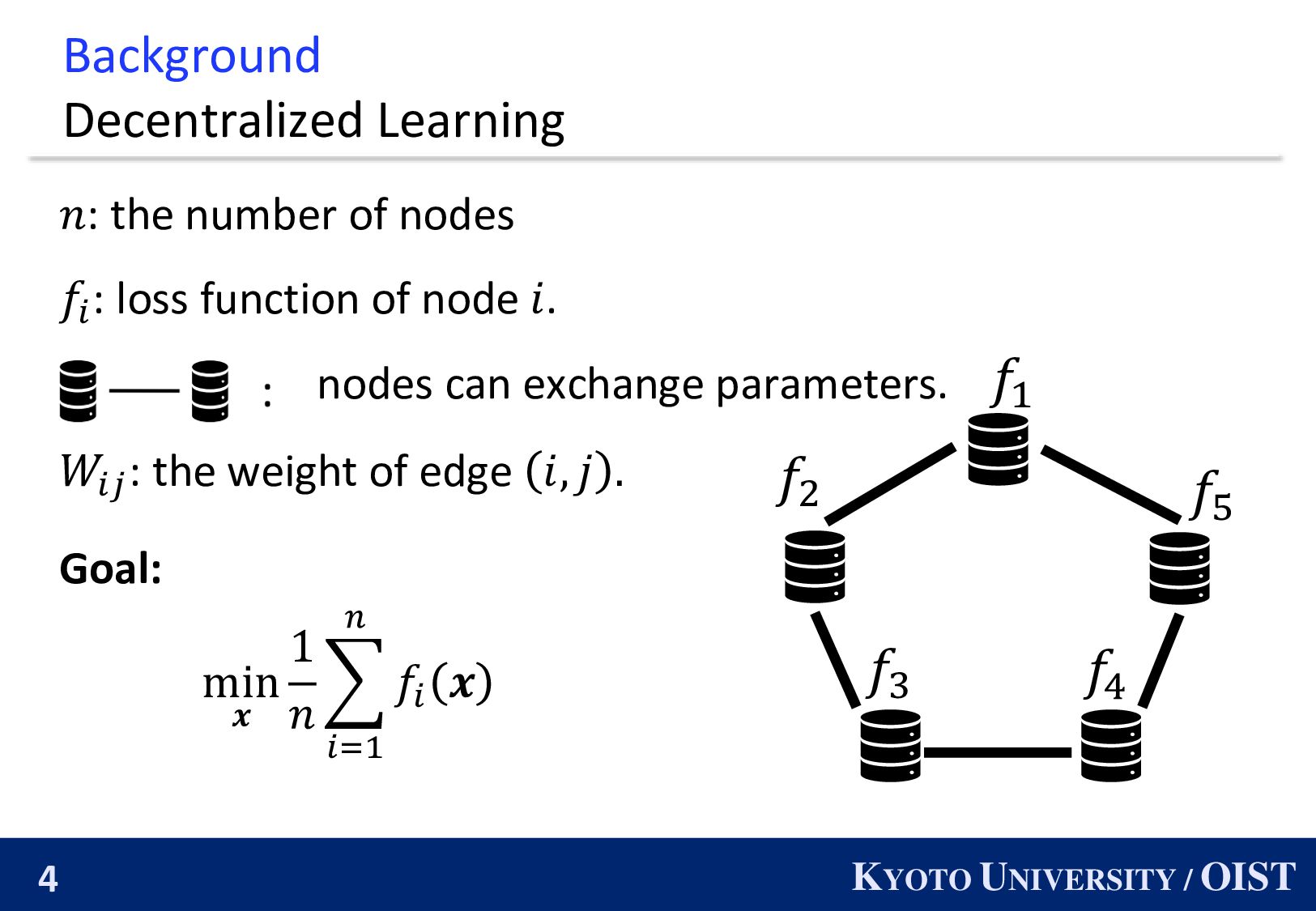
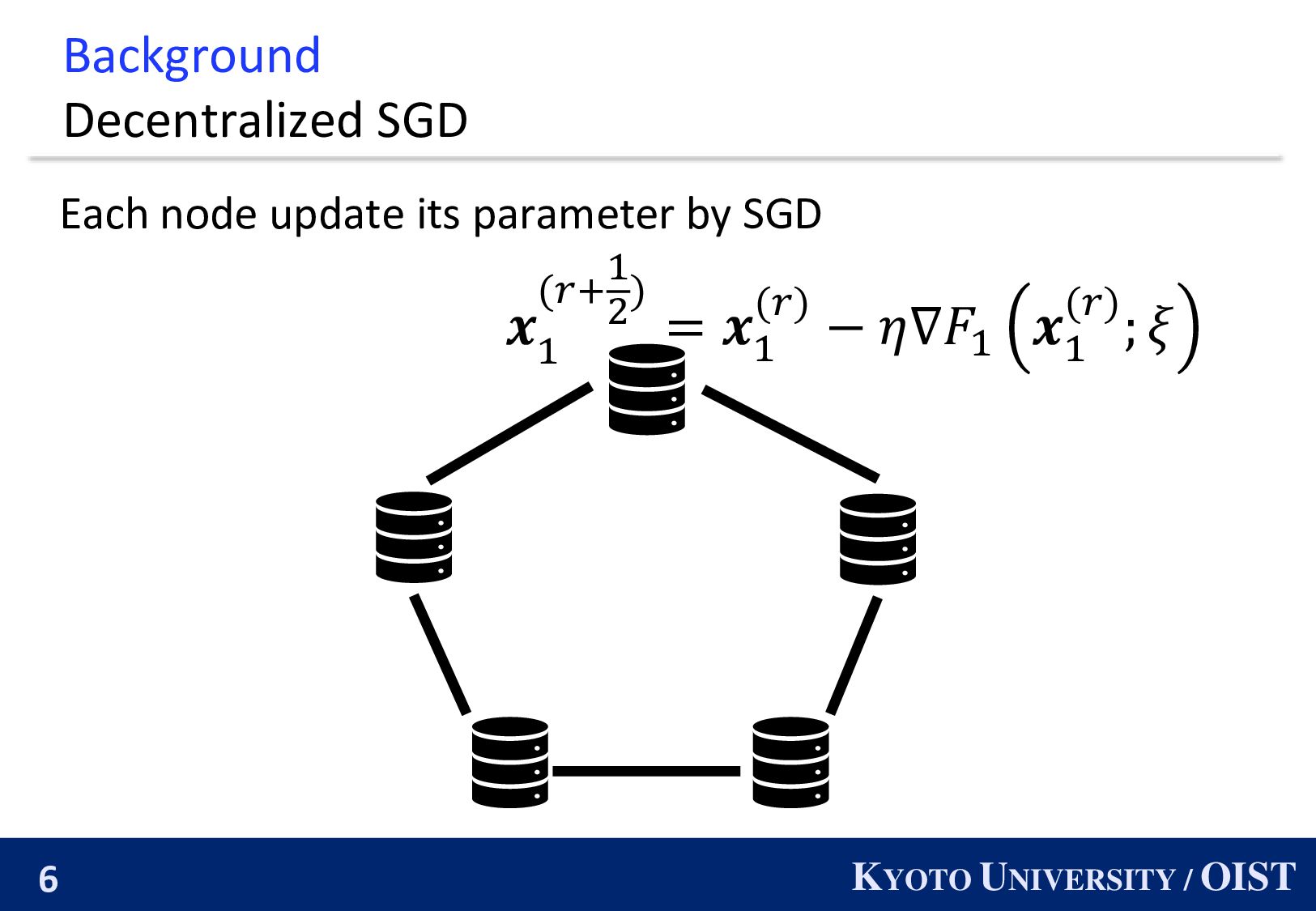
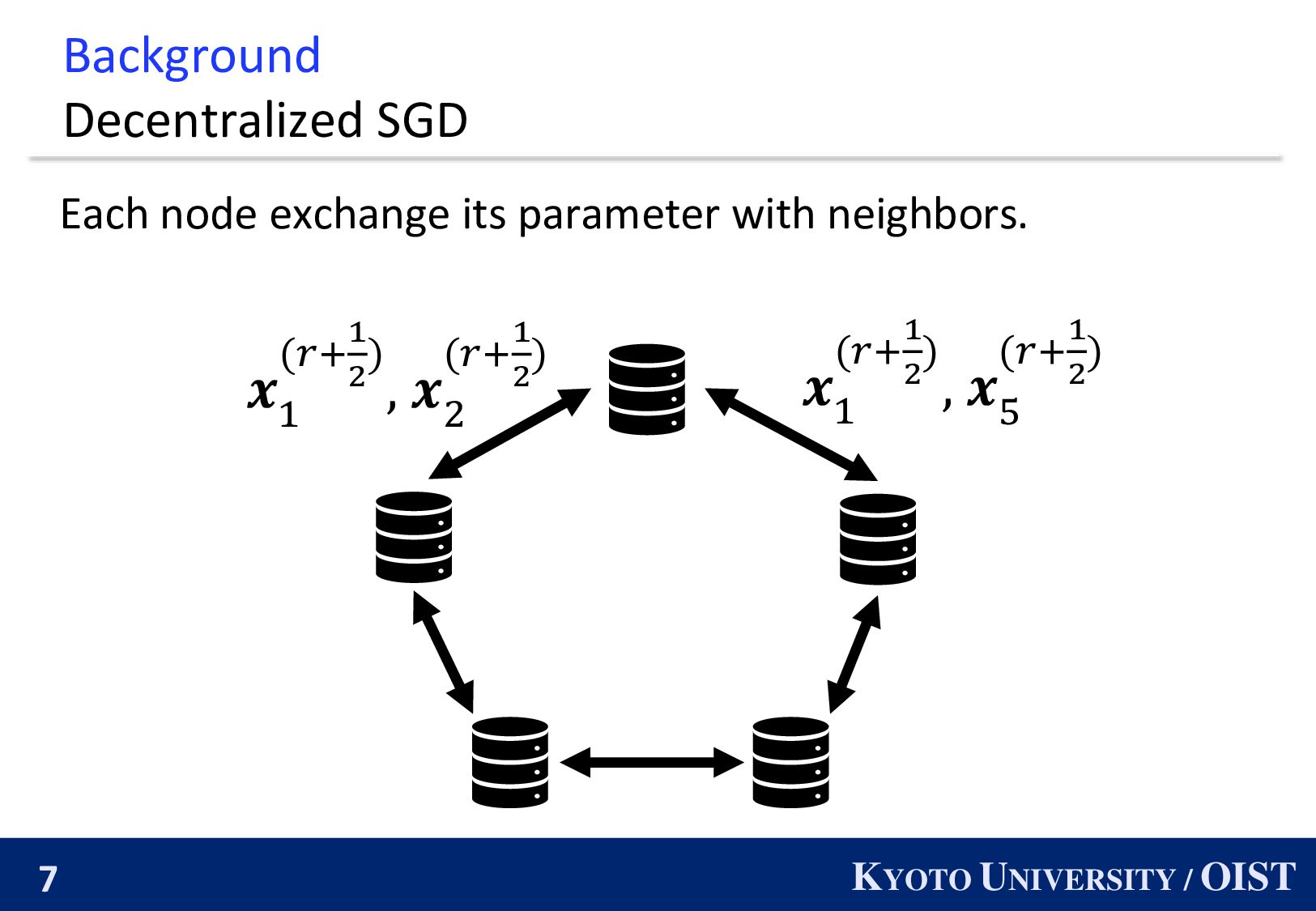
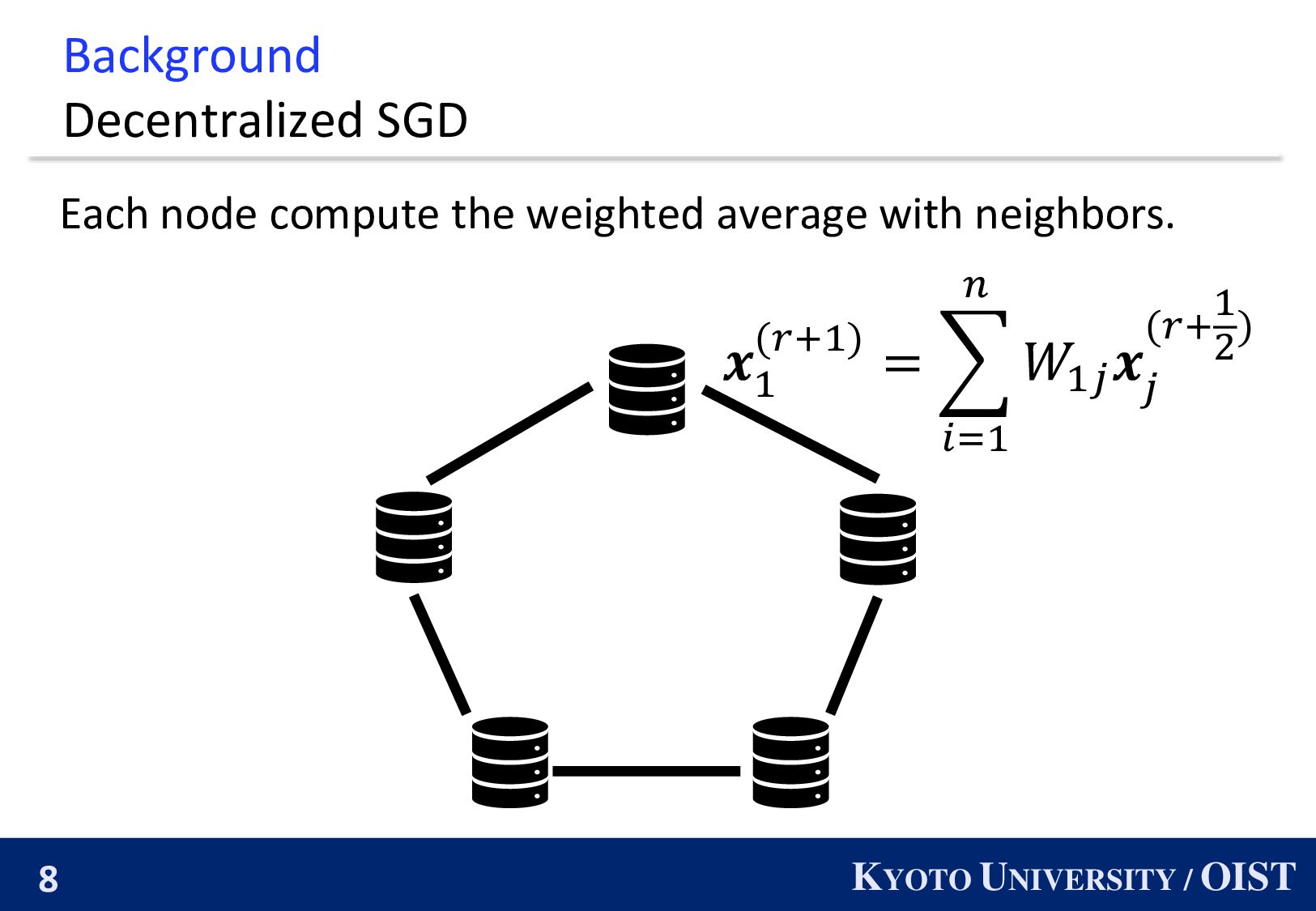
𝑓3 𝑓4 𝑓5 𝑛: the number of nodes 𝑓𝑖 : loss function of node 𝑖. nodes can exchange parameters. 𝑊𝑖𝑗 : the weight of edge 𝑖, 𝑗 . Goal: min 𝒙 1 𝑛 𝑖=1 𝑛 𝑓𝑖 𝒙
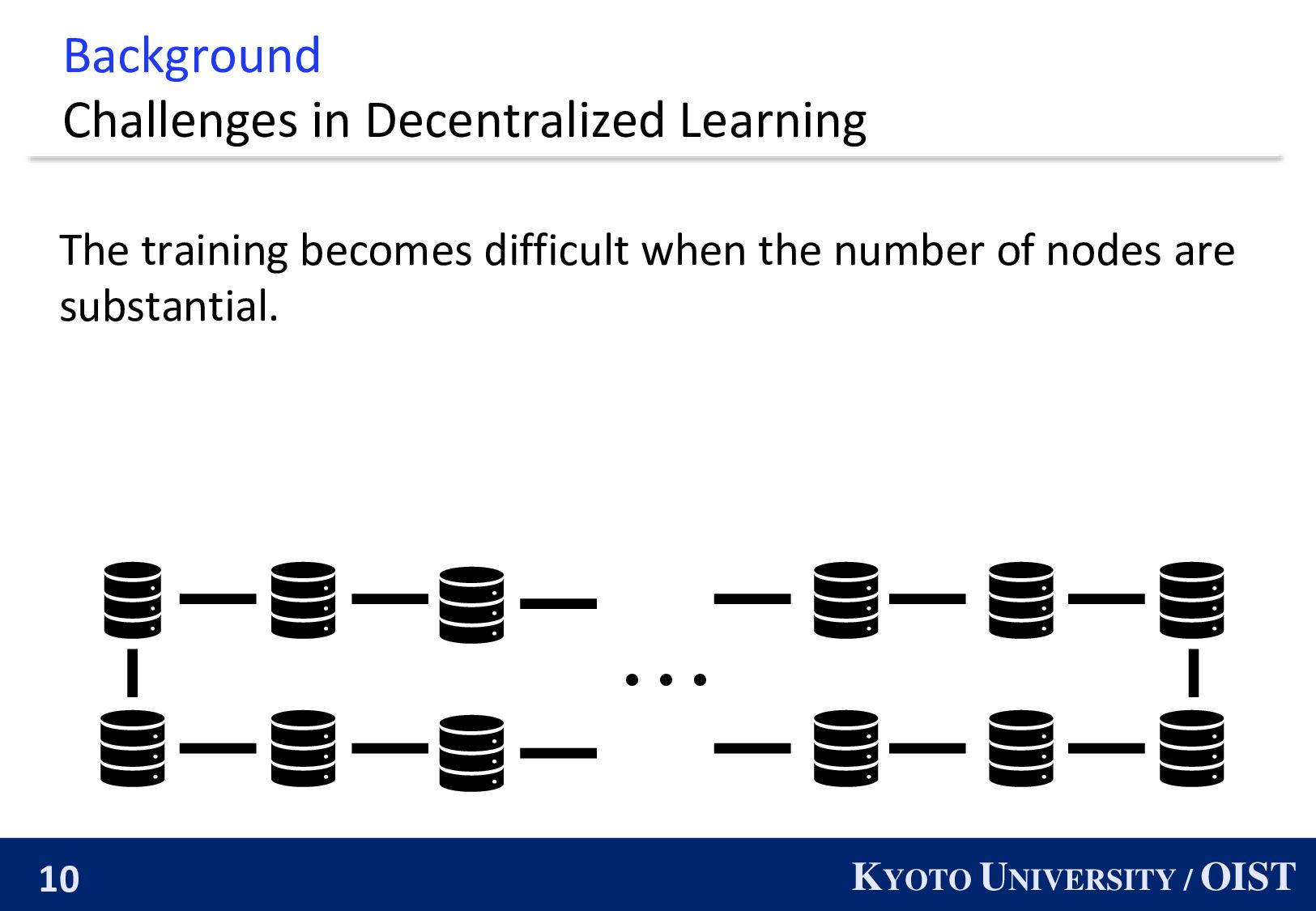
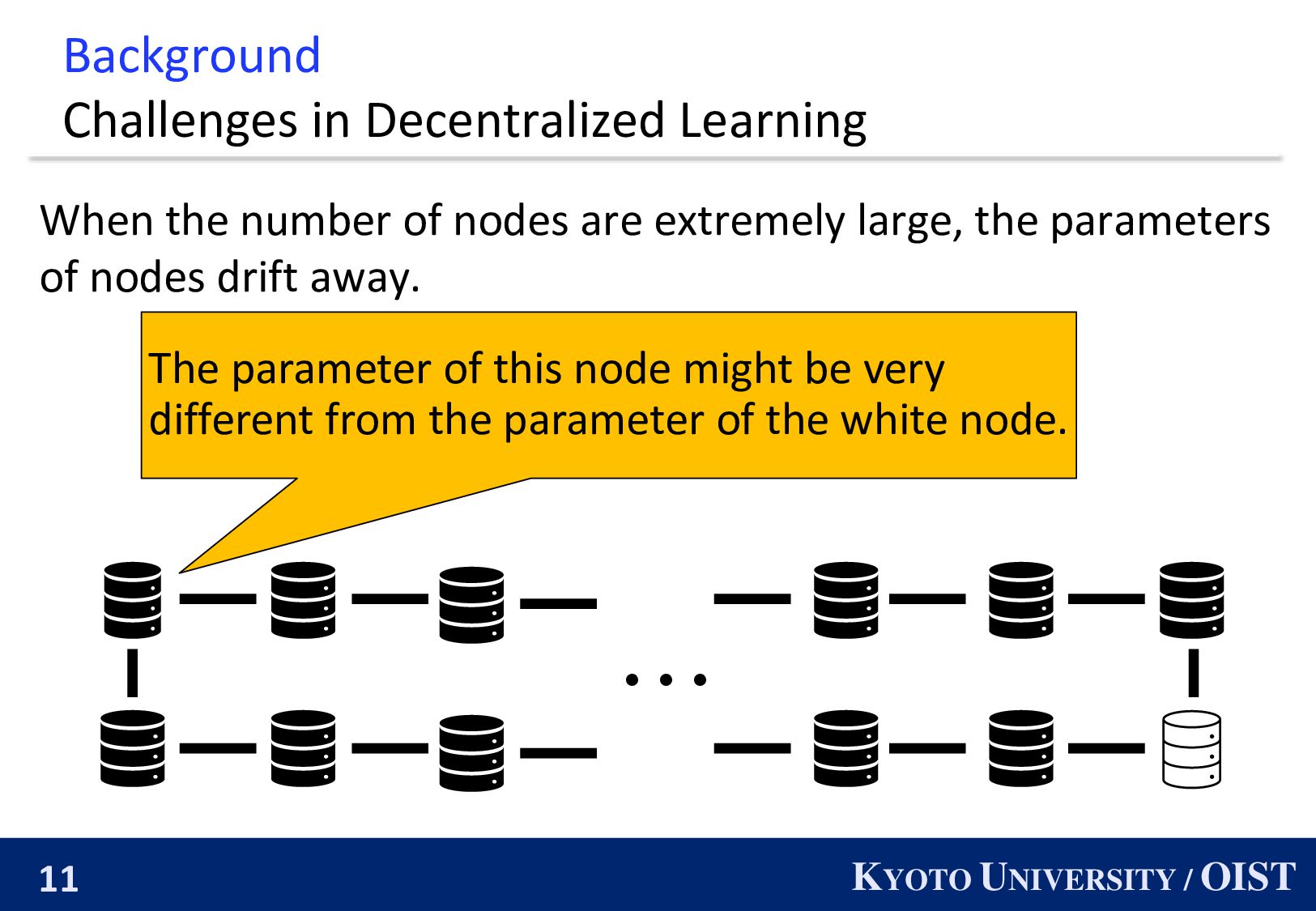
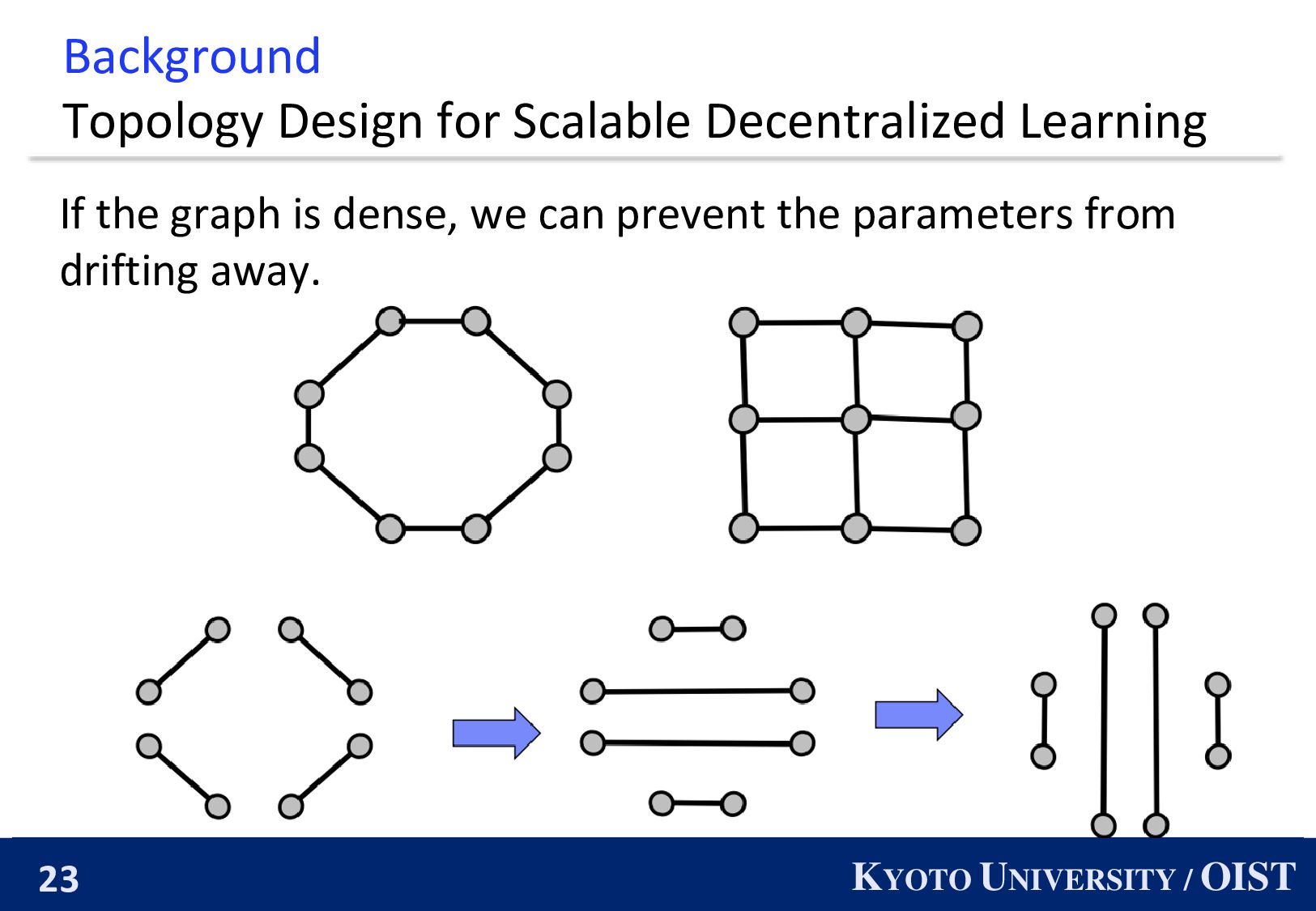
When the number of nodes are extremely large, the parameters of nodes drift away. ・・・ The parameter of this node might be very different from the parameter of the white node.
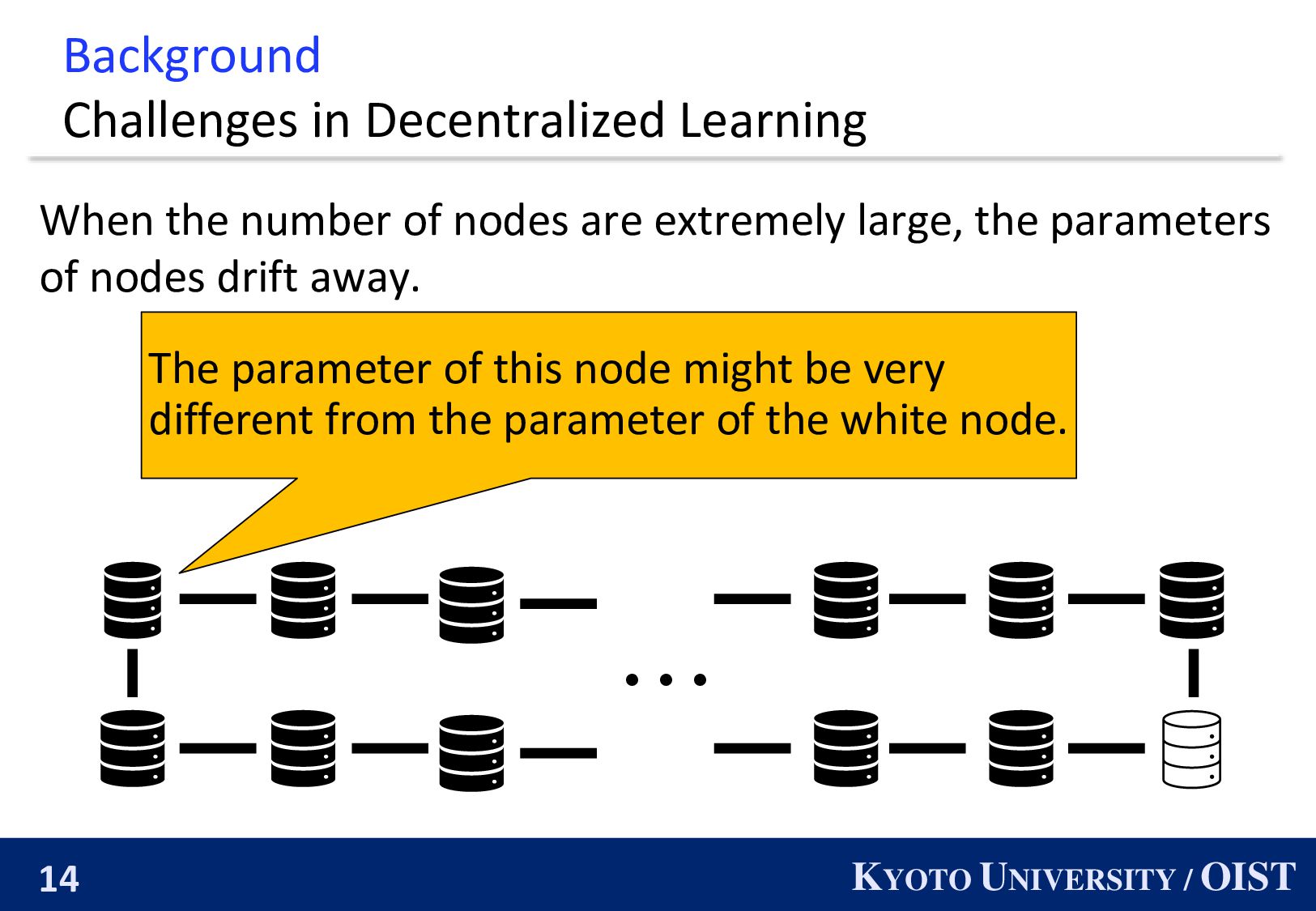
When the number of nodes are extremely large, the parameters of nodes drift away. ・・・ The parameter of this node might be very different from the parameter of the white node.
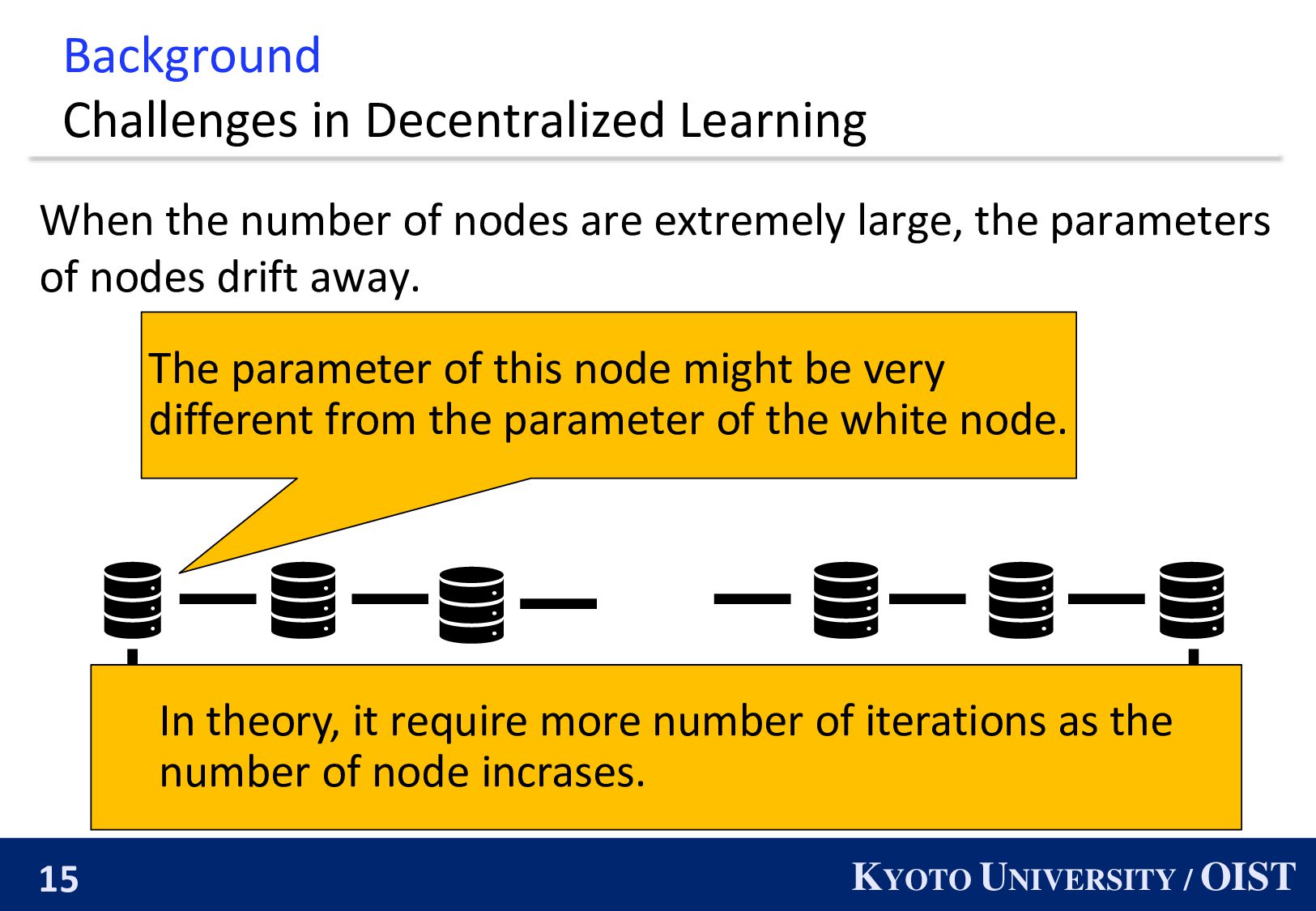
When the number of nodes are extremely large, the parameters of nodes drift away. ・・・ The parameter of this node might be very different from the parameter of the white node. In theory, it require more number of iterations as the number of node incrases.
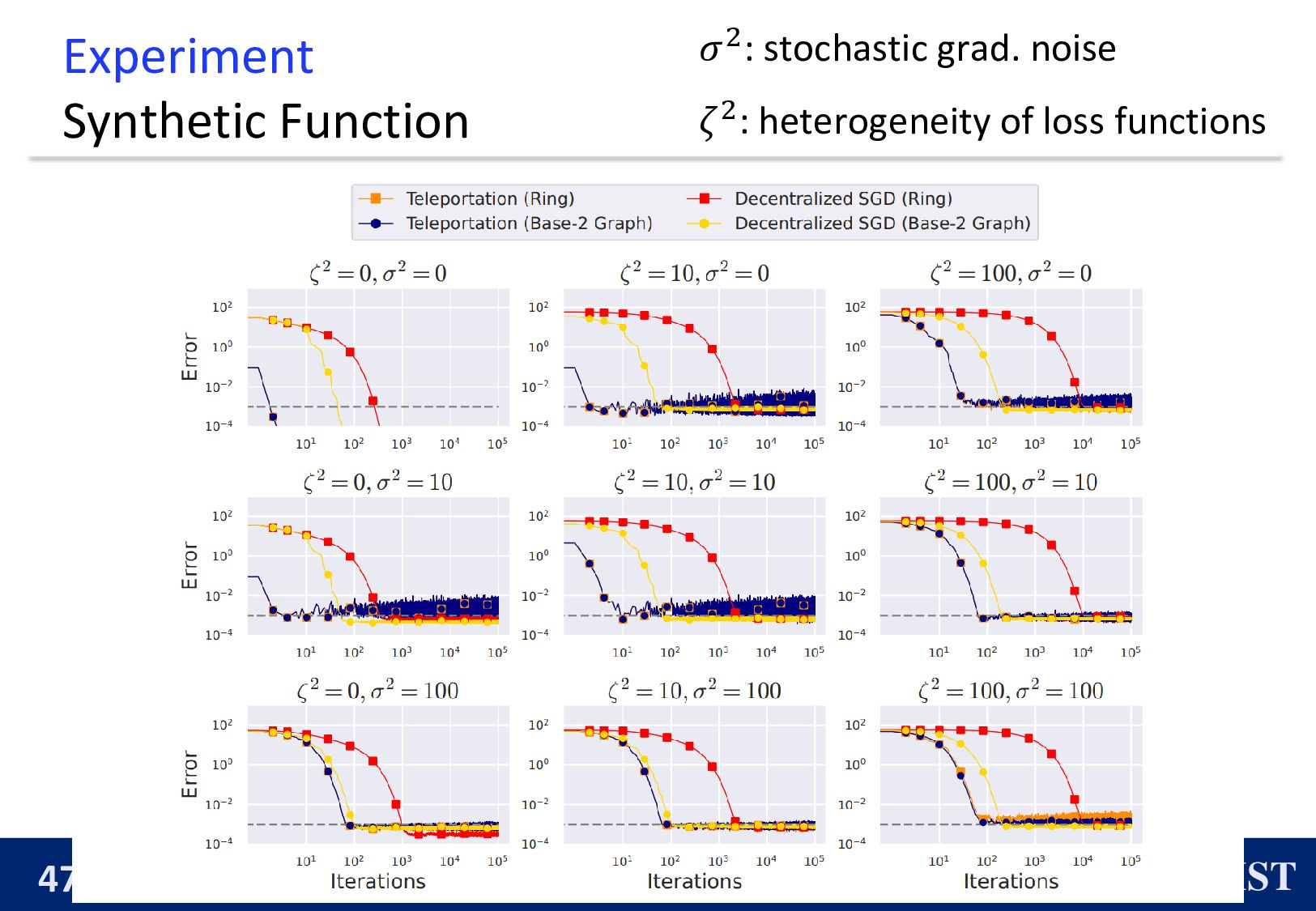
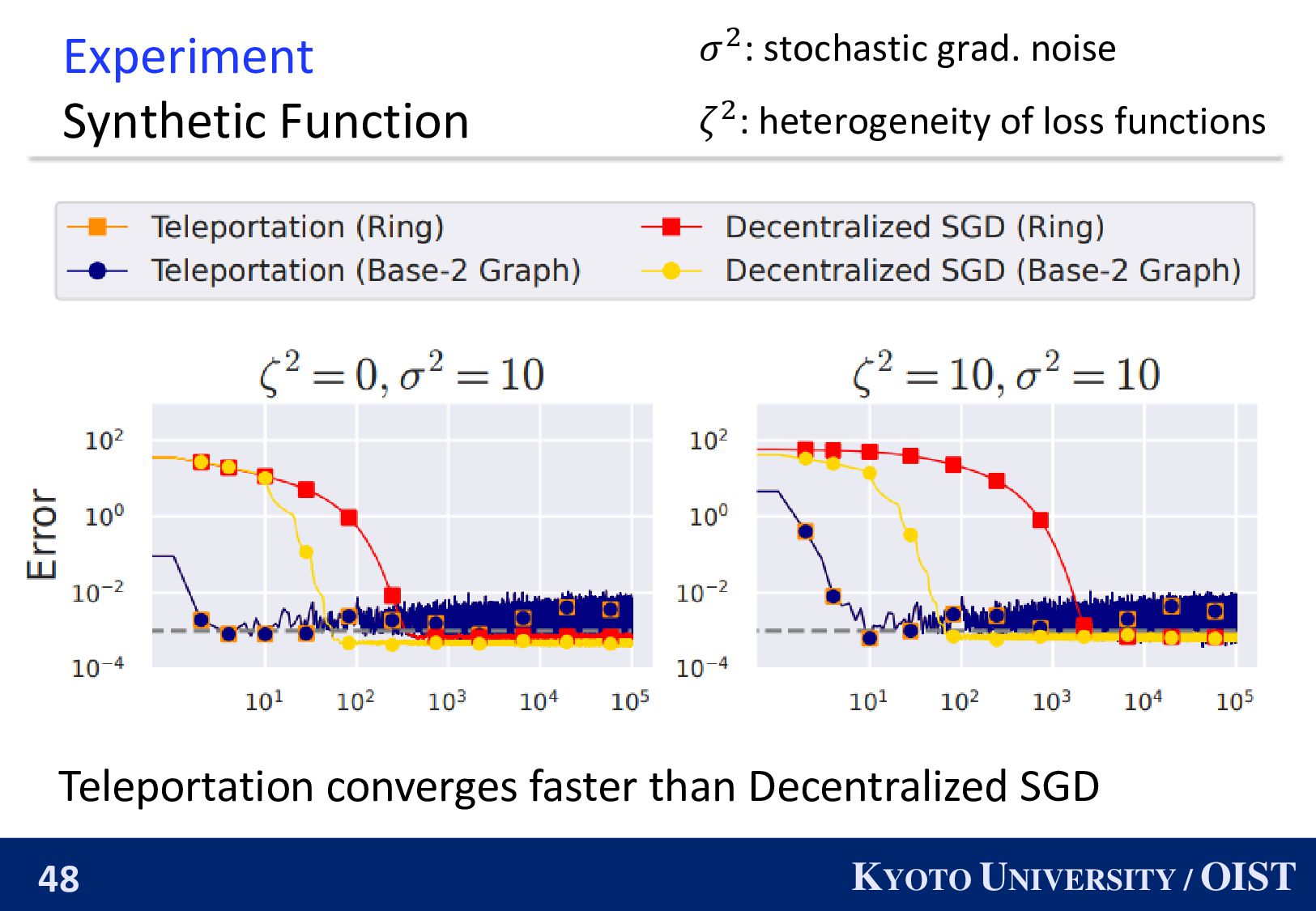
Convergence Rate of Decentralized SGD with Ring Decentralized SGD with ring converges with the following rate: 1 𝑇 𝑡=0 𝑇−1 E ∇𝑓 ഥ 𝒙 𝑡 2 ≤ 𝑂 1 𝑛𝑇 + 𝑛4 𝑇2 1 3 + 𝑛2 𝑇 . 𝑛: #nodes 𝑇: #iteration ◼ It requires more iterations 𝑇 as 𝑛 is substantially large.
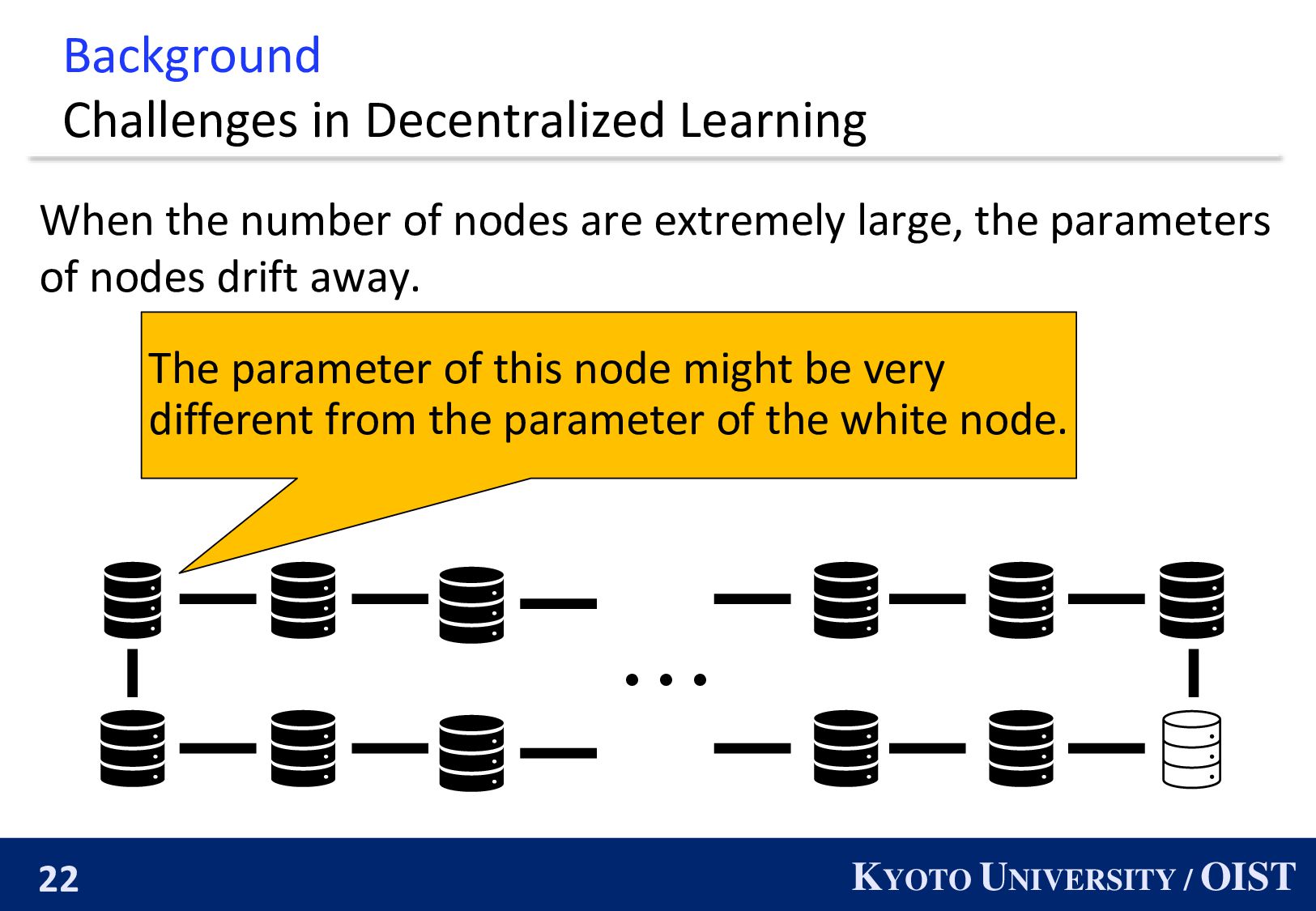
When the number of nodes are extremely large, the parameters of nodes drift away. ・・・ The parameter of this node might be very different from the parameter of the white node.
develop a method that can completely alleviate the degradation caused by a large number of nodes? Convergence Rate of Proposed Method (Informal) We can achieve: 1 𝑇 𝑡=0 𝑇−1 E ∇𝑓 ഥ 𝒙 𝑡 2 ≤ 𝑂 1 𝑛𝑇 + 1 𝑇 4 7 + 1 𝑇 3 5 + 1 𝑇 .
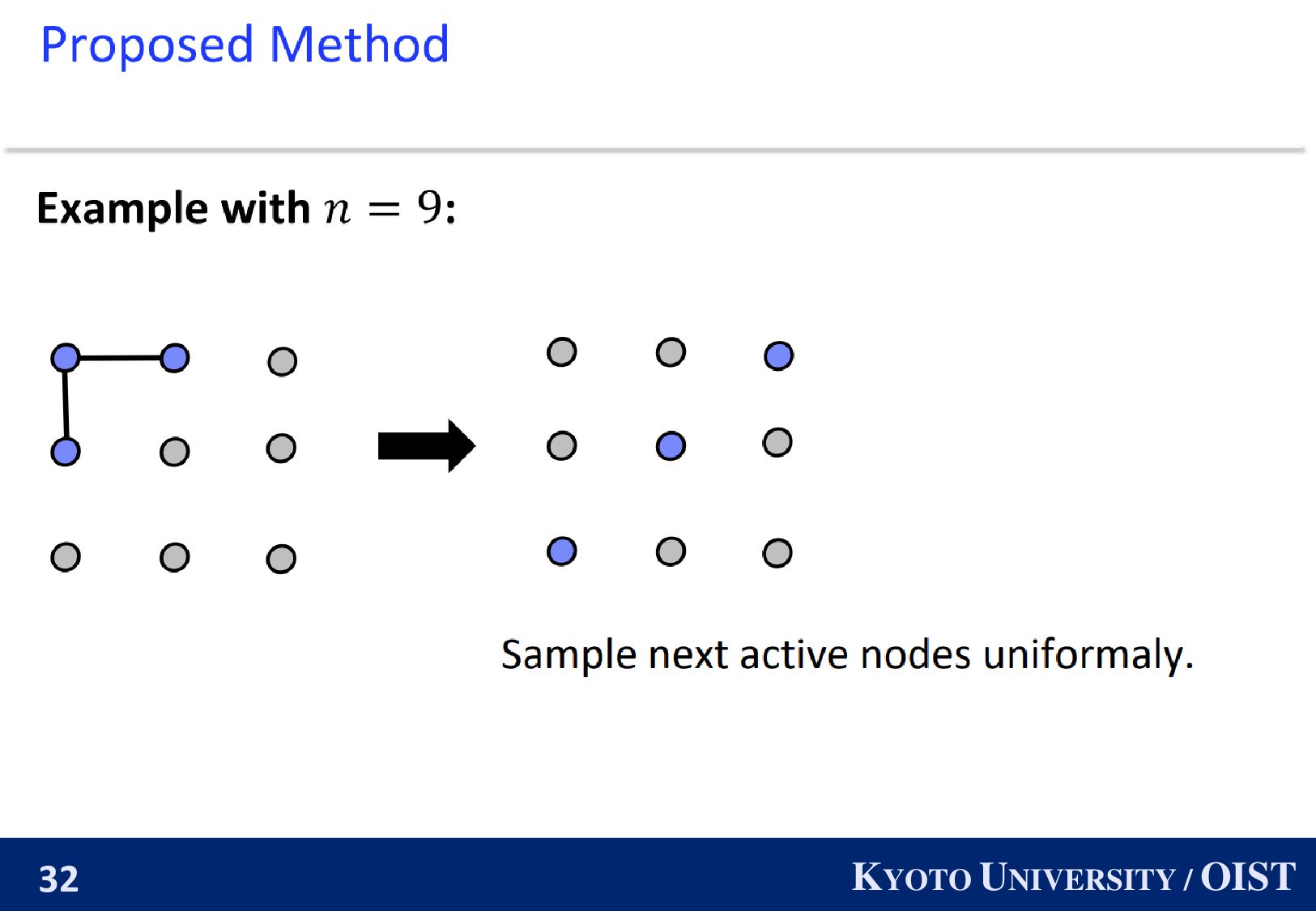
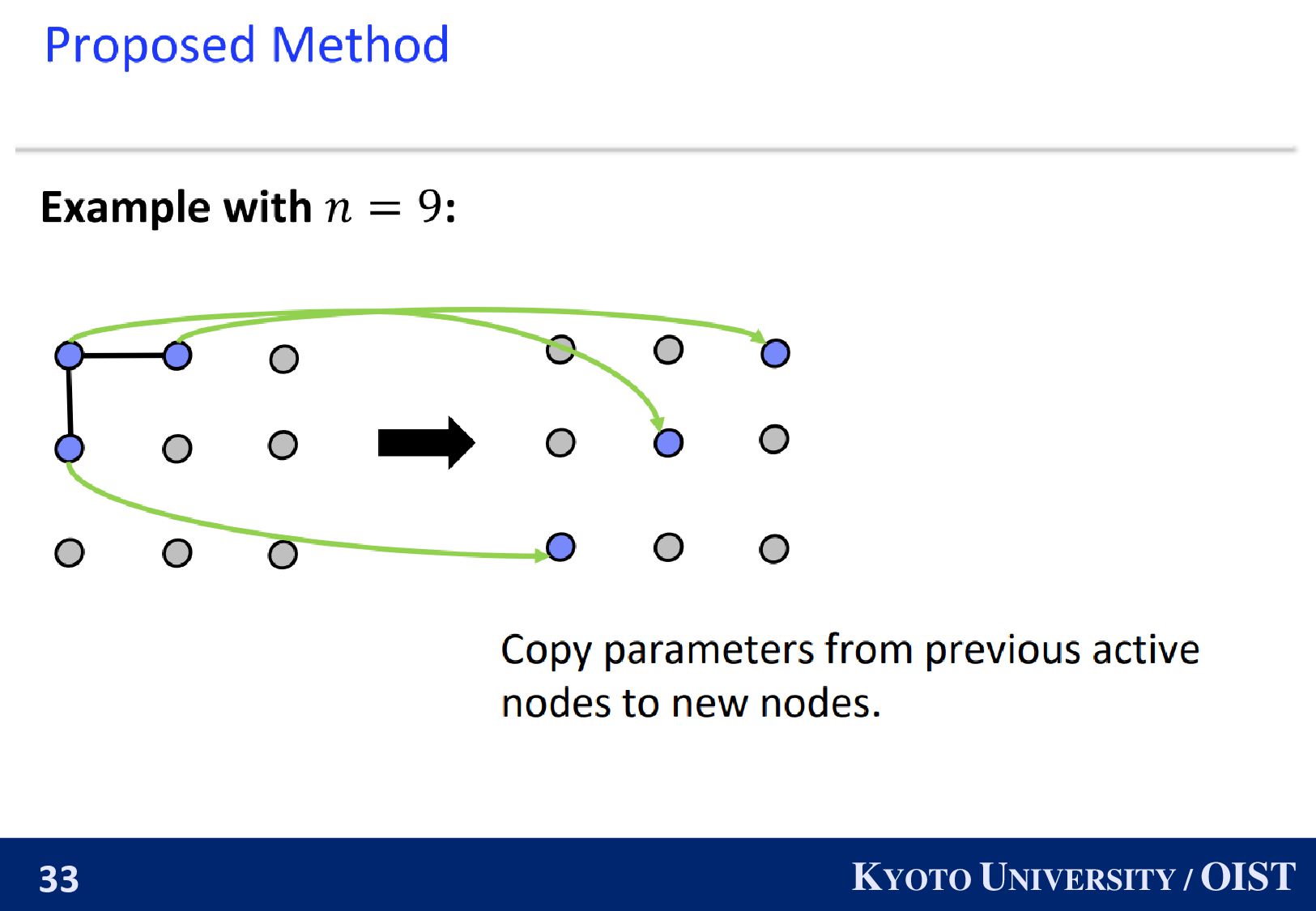
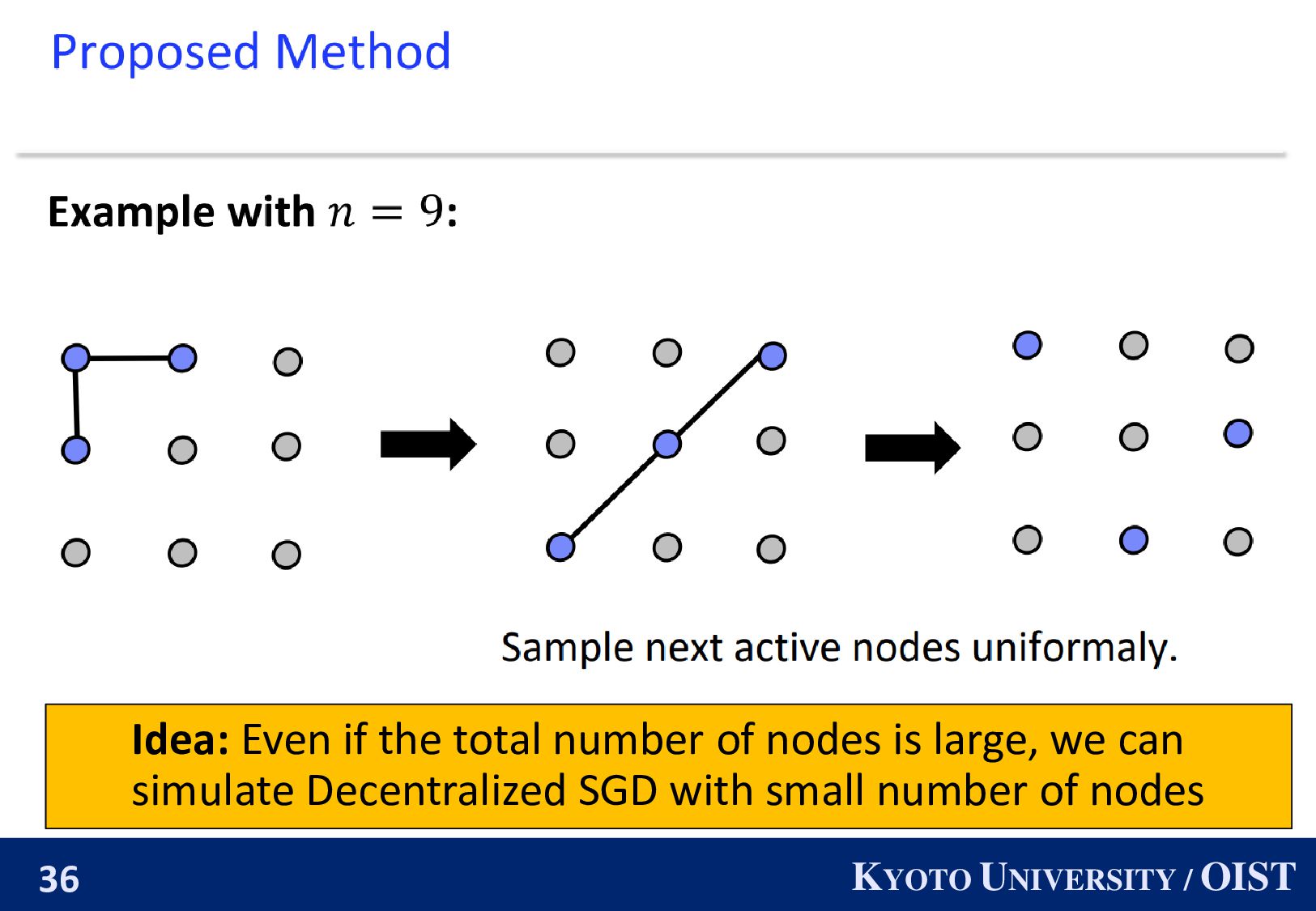
The parameters of nodes drift away since the number of nodes is large. Idea: Even if the total number of nodes is large, we can simulate Decentralized SGD with small number of nodes ・・・
The mixing matrix 𝑊𝑘 ∈ 0,1 𝑘×𝑘 has a spectral gap 𝑝𝑘 . Convergence Rate of Teleportation Let 𝑘 be the number of active nodes, we can achieve: 𝑂 𝐿𝑟0 𝜎2 + 1 − 𝑛 − 1 𝑘 − 1 𝜁2 𝑘𝑇 + 𝐿2𝑟0 2 𝜎2 + 𝜁2 𝑇2𝑝𝑘 1 3 + 𝐿𝑟0 𝑝𝑘 𝑇 , where 𝑟0 ≔ 𝑓 𝑥 0 − 𝑓⋆. 𝑝𝑘 depends on the small graph consisting of only active nodes. 𝑛: #nodes 𝑇: #iteration
the number of active nodes 𝑘, we get Convergence Rate of Proposed Method If we use ring as the topology and set 𝑘 as follows: 𝑘 = max 1, min 𝑇 𝜎2 + 𝜁2 𝐿𝑟0 1 5 , 𝑇 𝜎2 + 𝜁2 𝐿𝑟0 1 7 , 𝑛 we can achieve: 𝑂 𝐿𝑟0 𝜎2 𝑛𝑇 + 𝐿2𝑟0 2 𝜎2 + 𝜁2 3 4 𝑇 4 7 + 𝐿2𝑟0 2 𝜎2 + 𝜁2 2 3 𝑇 3 5 + 𝐿𝑟0 𝑇 , where 𝑟0 ≔ 𝑓 𝑥 0 − 𝑓⋆. 𝑛: #nodes 𝑇: #iteration
the number of active nodes 𝑘, we get Convergence Rate of Proposed Method If we use ring as the topology and set 𝑘 as follows: 𝑘 = max 1, min 𝑇 𝜎2 + 𝜁2 𝐿𝑟0 1 5 , 𝑇 𝜎2 + 𝜁2 𝐿𝑟0 1 7 , 𝑛 we can achieve: 𝑂 𝐿𝑟0 𝜎2 𝑛𝑇 + 𝐿2𝑟0 2 𝜎2 + 𝜁2 3 4 𝑇 4 7 + 𝐿2𝑟0 2 𝜎2 + 𝜁2 2 3 𝑇 3 5 + 𝐿𝑟0 𝑇 , where 𝑟0 ≔ 𝑓 𝑥 0 − 𝑓⋆. The convergence rate consistently improve as 𝑛 increases!
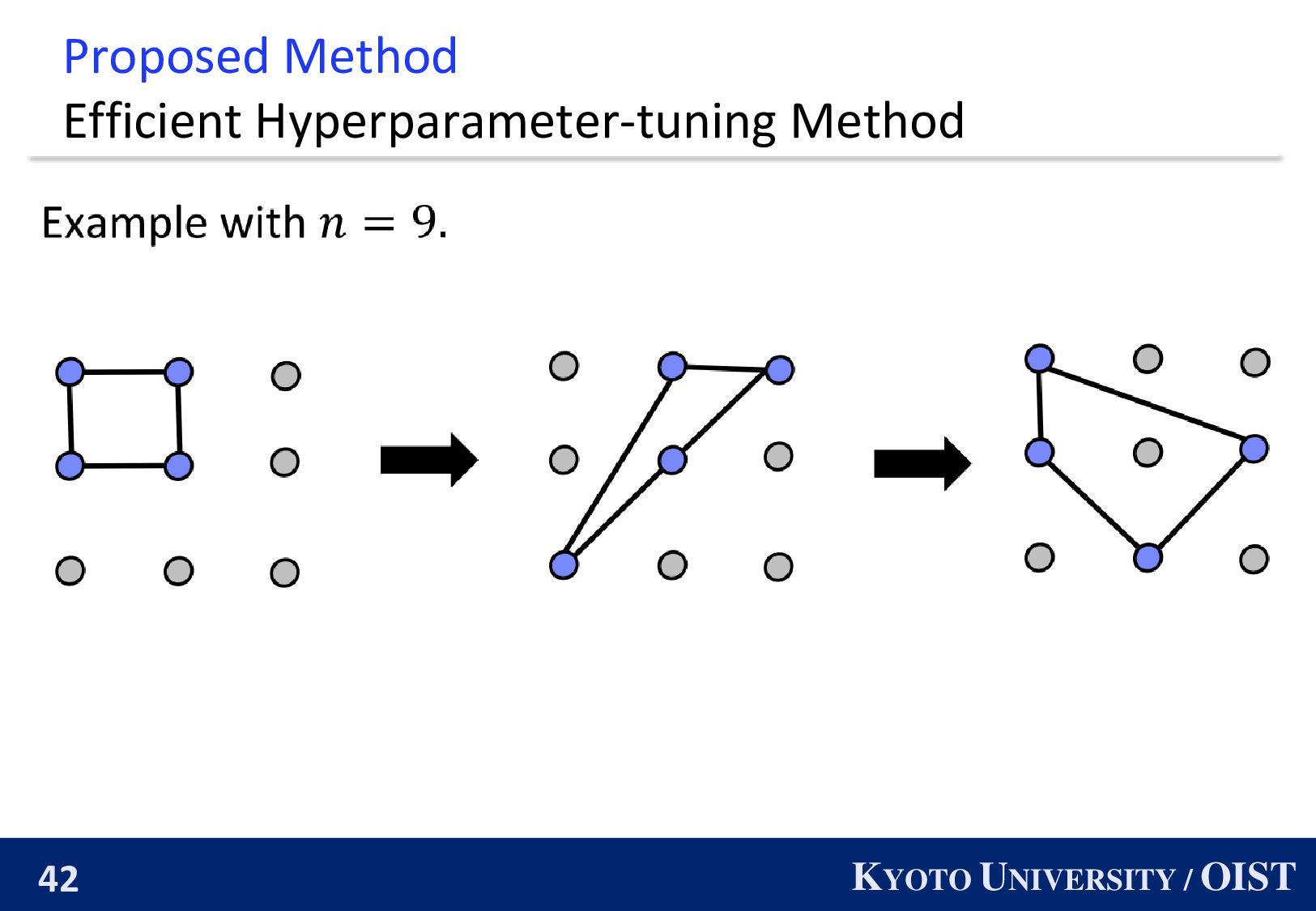
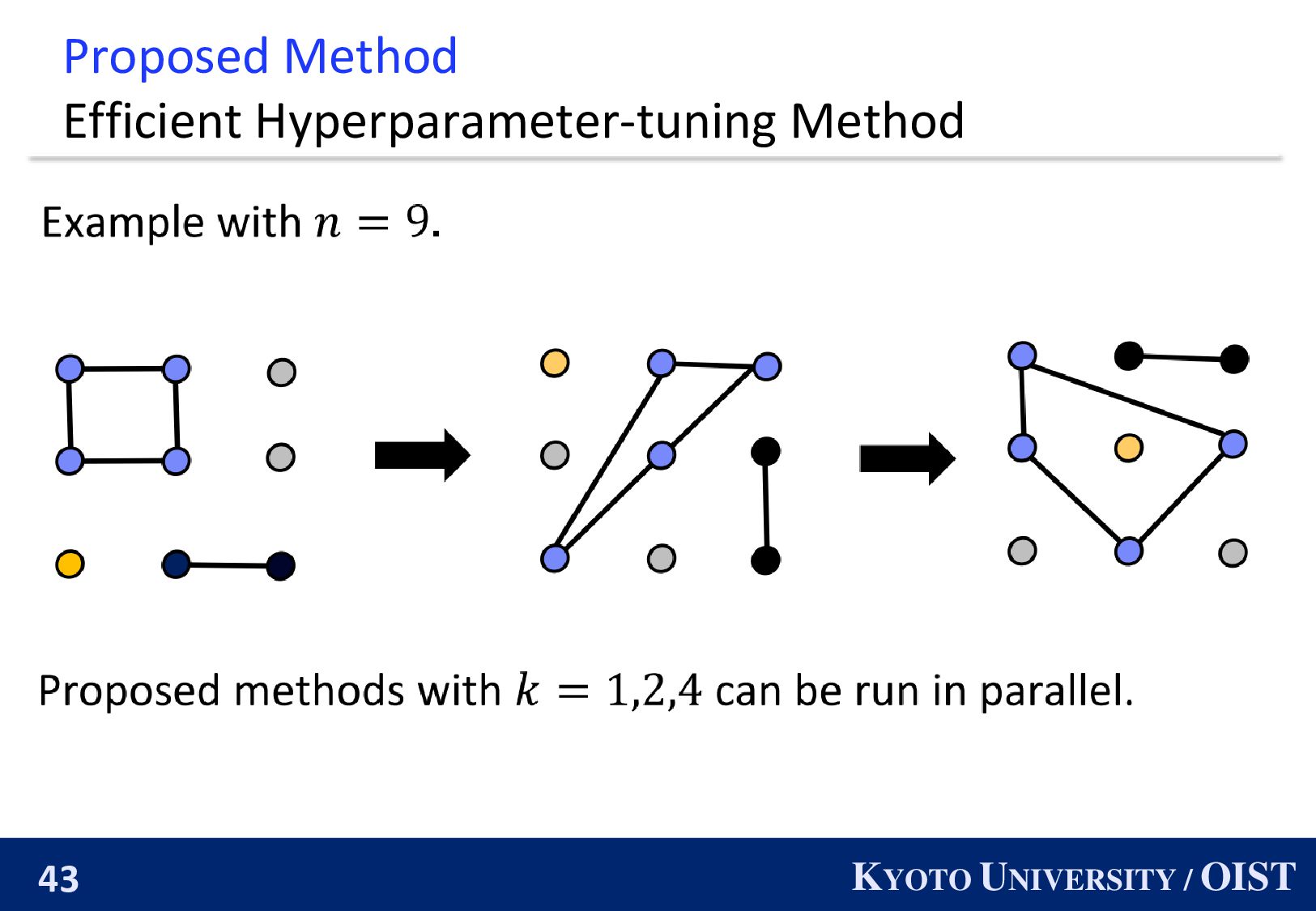
Can we develop an efficient hyperparameter-tuning method? We must tune the number of active nodes 𝑘 from 1 to 𝑛. Grid search requires 𝑛𝑇 iterations Yes! We can obtain the proper 𝑘 within 2𝑇 iterations.
◼ Grid search on 𝐾 can find a proper 𝑘. ◼ Moreover, this grid search can run in parallel. Key Lemma Let 𝐾 define 𝐾 ≔ 1, 2, 4, 8, … , 2ہlog2(𝑛+1 ] ) −1 . For any 𝑘⋆ < 𝑛, there exists 𝑘 ∈ 𝐾 such that 𝑘⋆ 4 < 𝑘 ≤ 𝑘⋆. Furthermore it holds that σ𝑘∈𝐾 𝑘 ≤ 𝑛.
Theorem (Informal) This hyperparameter-tuning methods achieve exactly the same convergence rate as that with the optimal 𝑘⋆. 1. Run Teleportation with ∀𝑘 ∈ 𝐾 in parallel. 2. Run Teleportation with 𝑛. (full activation.) 3. Chose the best parameters. We can obtain the proper 𝑘 within 2𝑇 iterations.
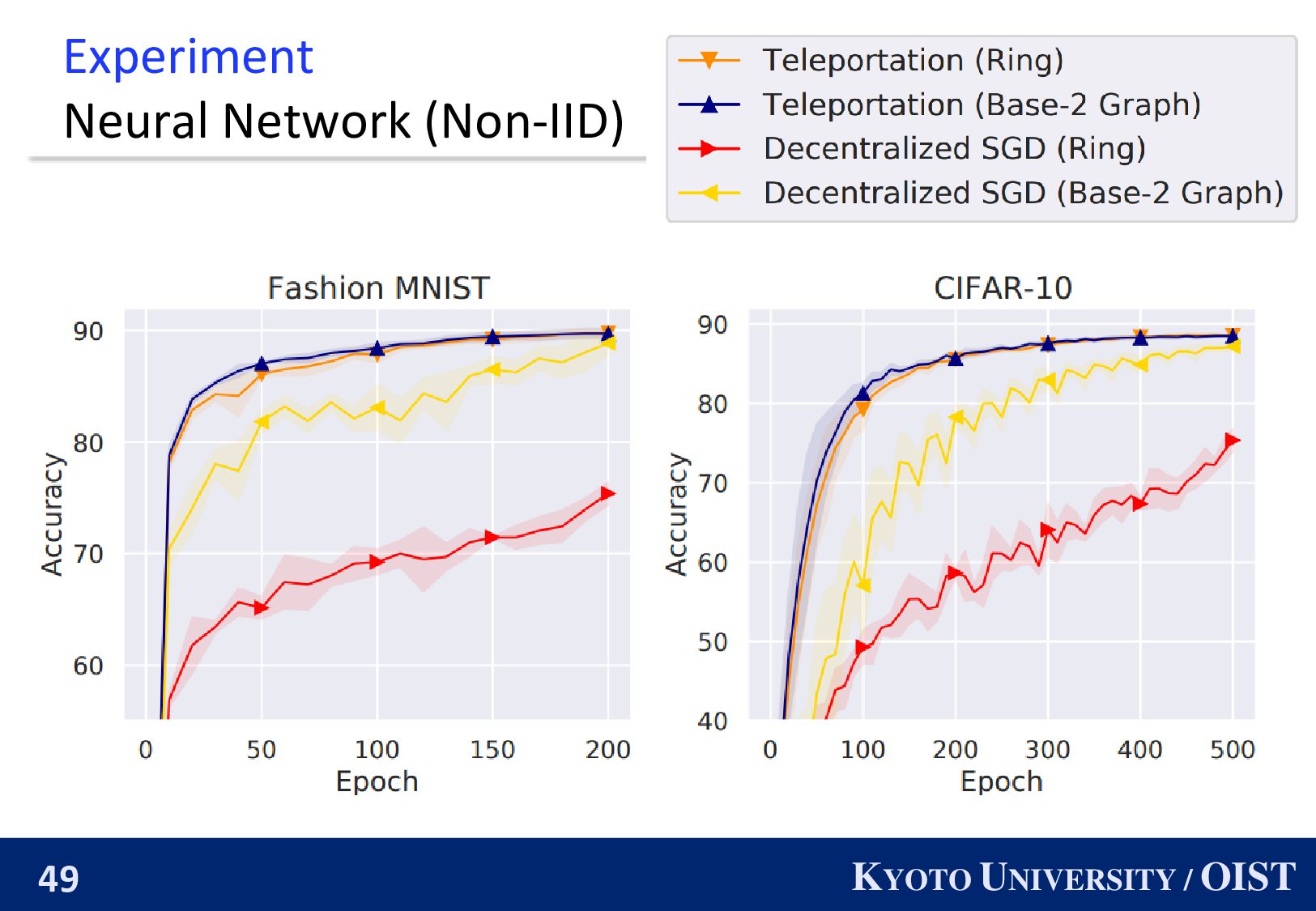
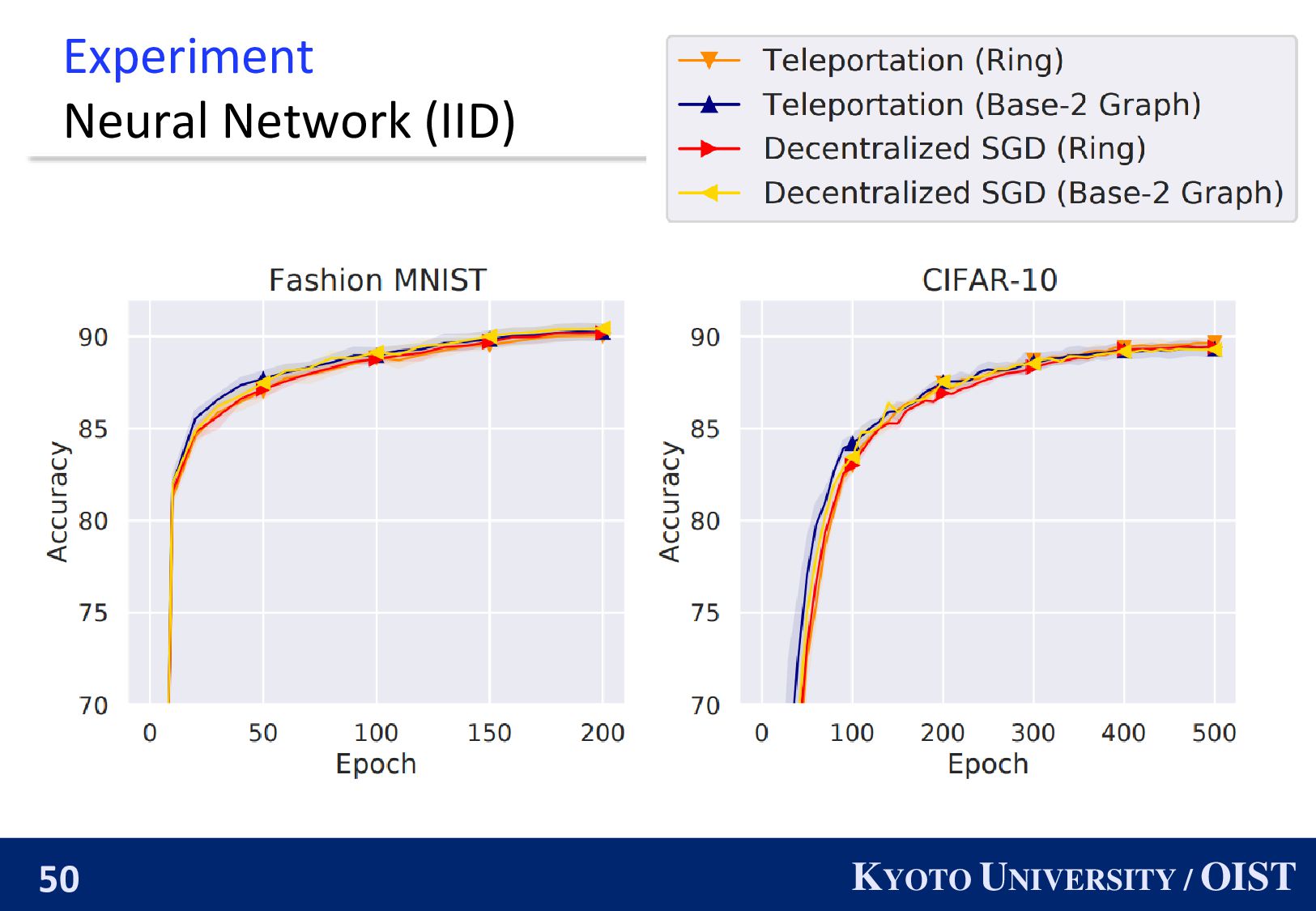
The convergence rate of Teleportation does not degrade as 𝑛 increases. ◼ We also propose an efficient hyperparameter-tuning method. ◼ We numerically demonstrate the effectiveness. paper
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}