Beyond Exponential Graph: Communication Efficient Topology for Decentralized Learning via Finite-time Convergence
Beyond Exponential Graph: Communication Efficient Topologies for Decentralized Learning via Finite-time Convergence (NeurIPS 2023)
https://arxiv.org/abs/2305.11420
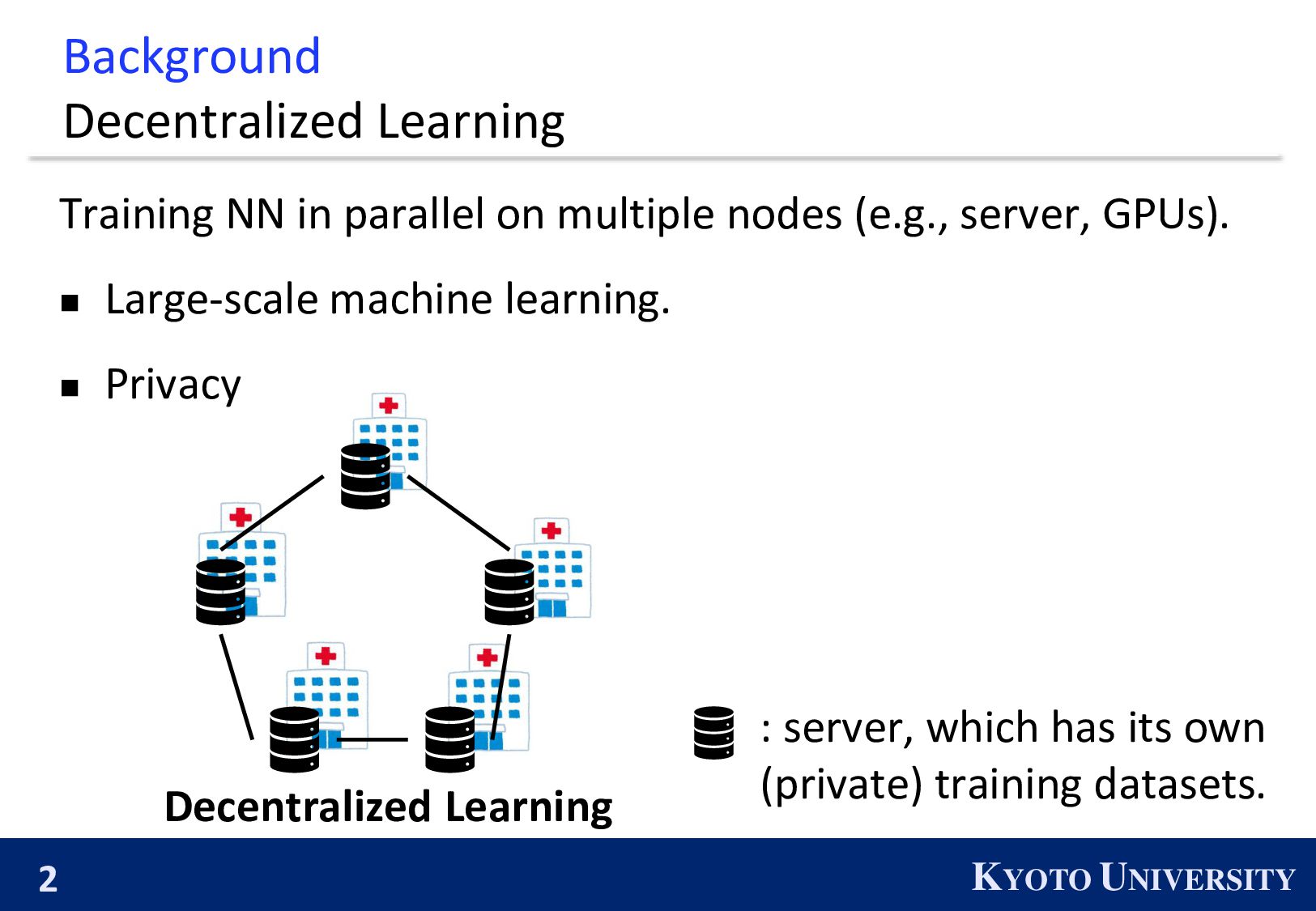
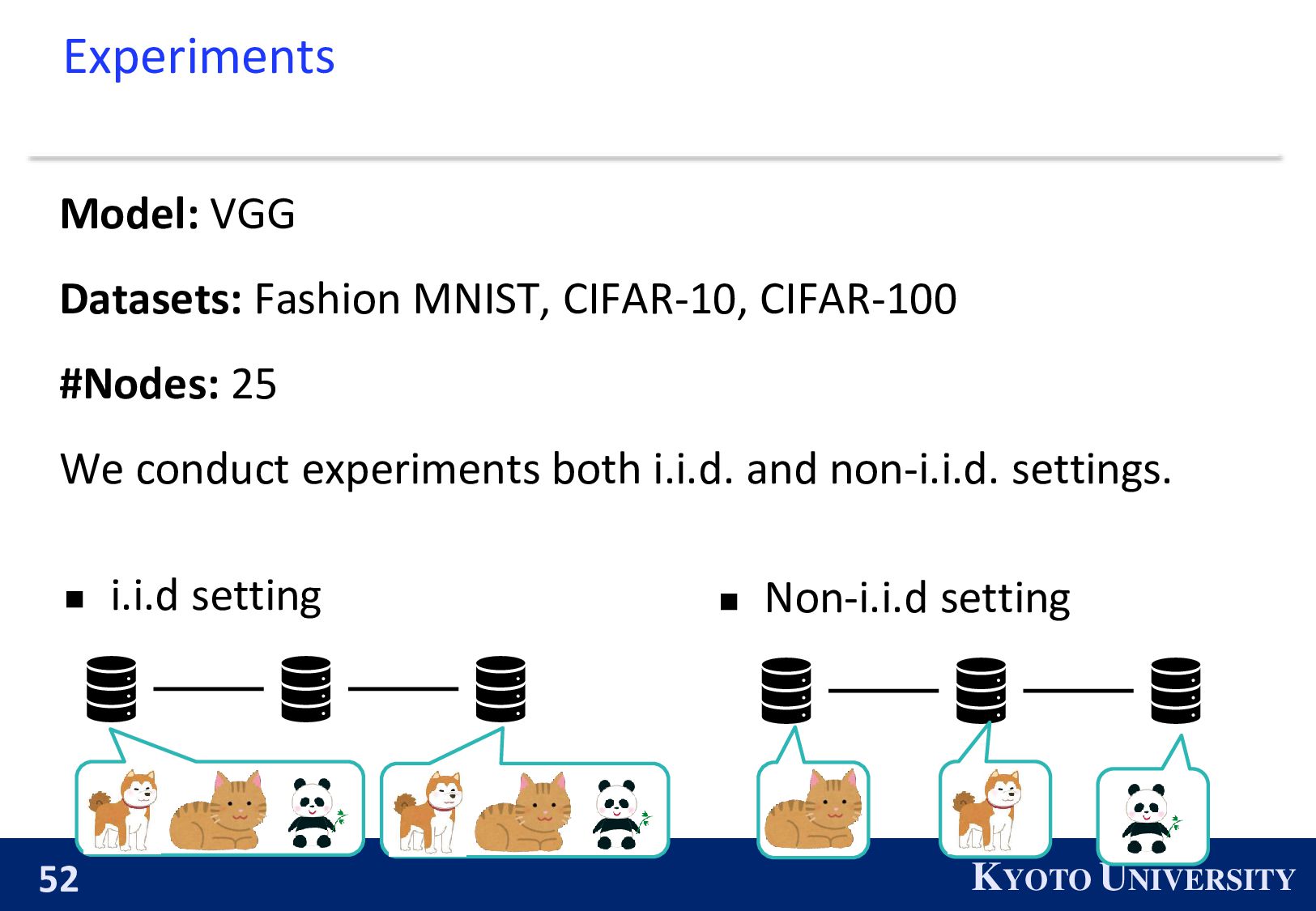
on multiple nodes (e.g., server, GPUs). ◼ Large-scale machine learning. ◼ Privacy : server, which has its own (private) training datasets. Decentralized Learning
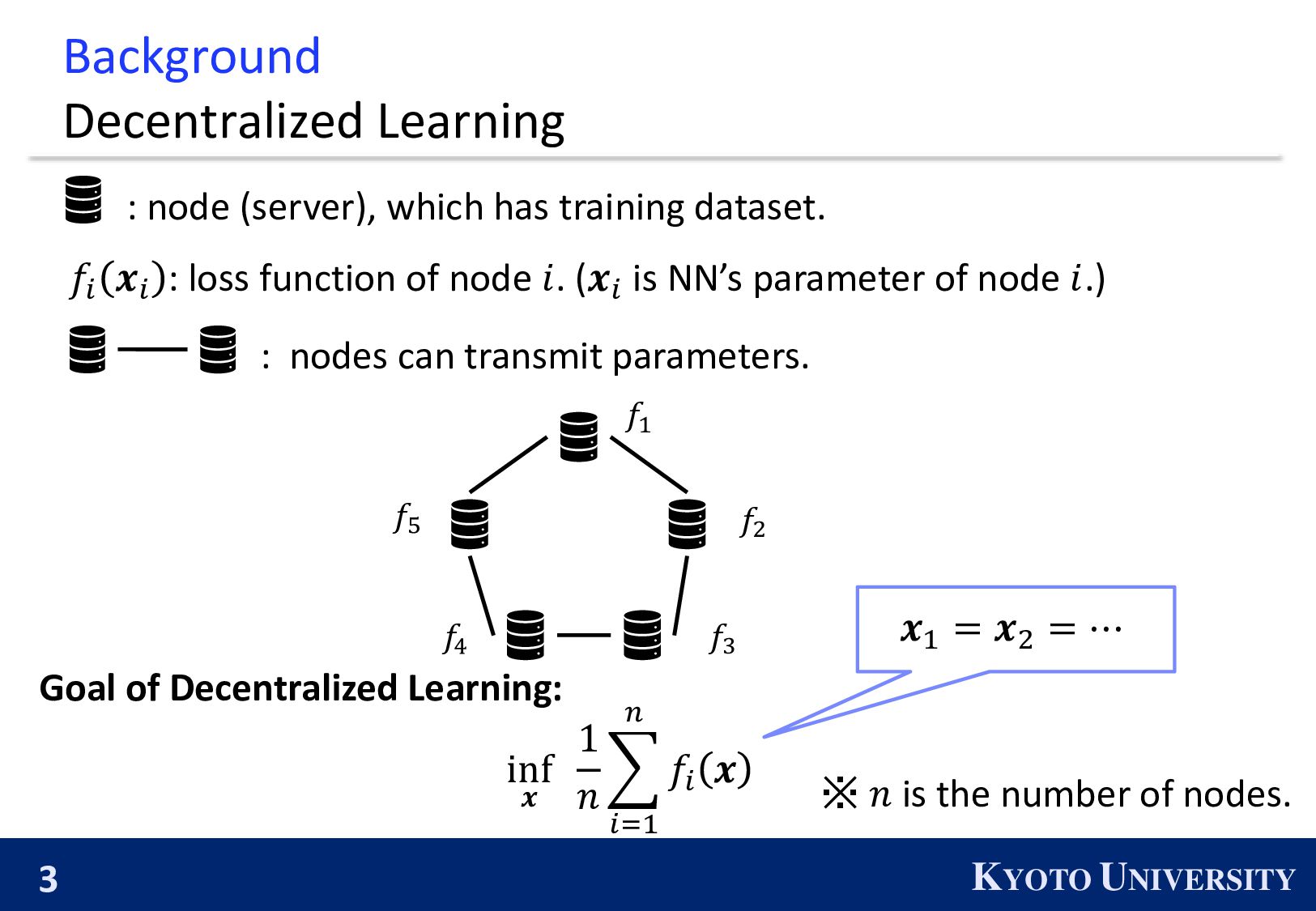
has training dataset. : nodes can transmit parameters. 𝑓𝑖 𝒙𝑖 : loss function of node 𝑖. (𝒙𝑖 is NN’s parameter of node 𝑖.) Goal of Decentralized Learning: inf 𝒙 1 𝑛 𝑖=1 𝑛 𝑓𝑖 𝒙 𝒙1 = 𝒙2 = ⋯ 𝑓5 𝑓2 𝑓1 𝑓4 𝑓3 ※ 𝑛 is the number of nodes.
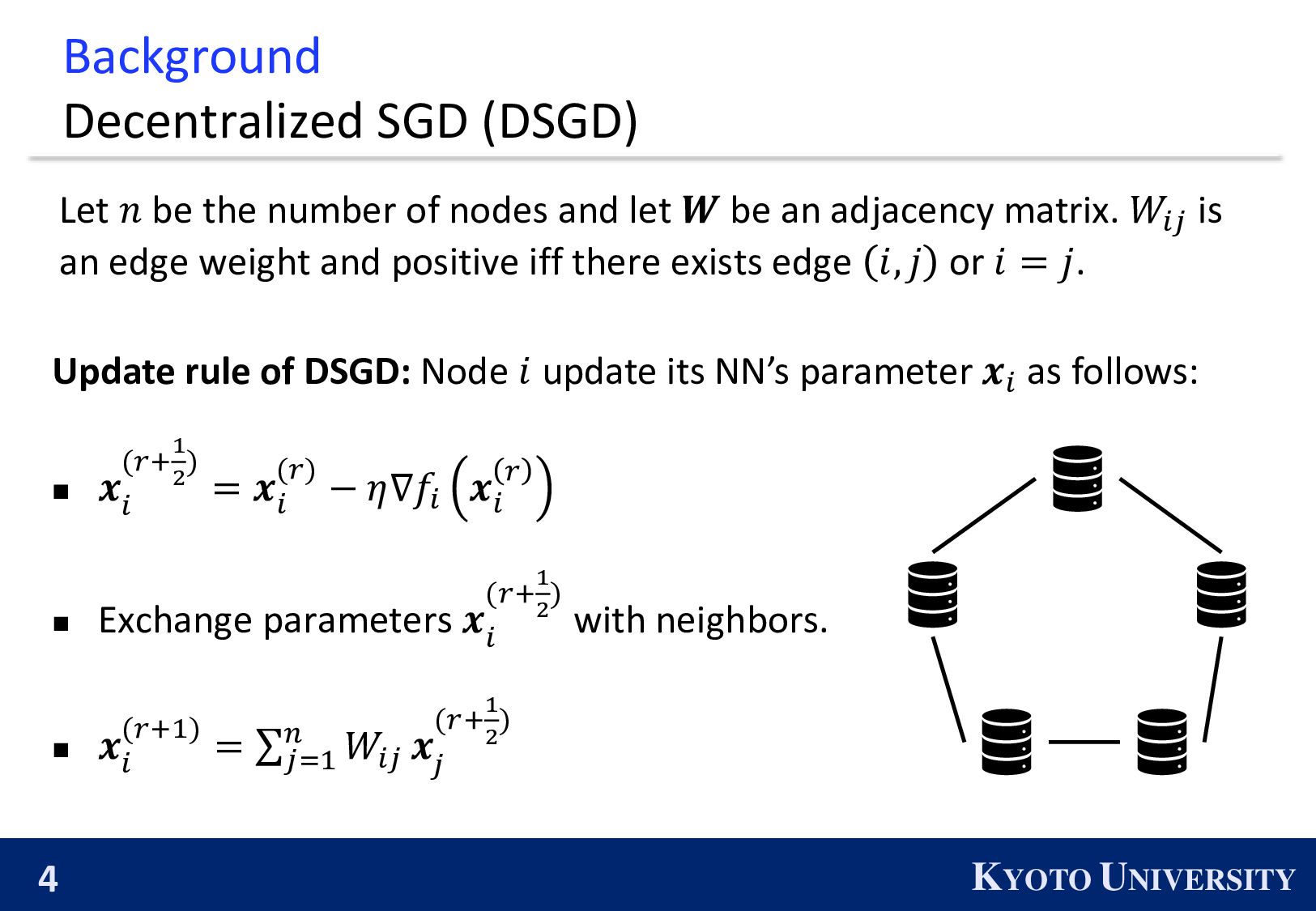
its NN’s parameter 𝒙𝑖 as follows: ◼ 𝒙 𝑖 (𝑟+1 2 ) = 𝒙 𝑖 (𝑟) − 𝜂∇𝑓𝑖 𝒙 𝑖 𝑟 ◼ Exchange parameters 𝒙 𝑖 (𝑟+1 2 ) with neighbors. ◼ 𝒙 𝑖 (𝑟+1) = σ 𝑗=1 𝑛 𝑊𝑖𝑗 𝒙 𝑗 (𝑟+1 2 ) Background Decentralized SGD (DSGD) Let 𝑛 be the number of nodes and let 𝑾 be an adjacency matrix. 𝑊𝑖𝑗 is an edge weight and positive iff there exists edge 𝑖, 𝑗 or 𝑖 = 𝑗.
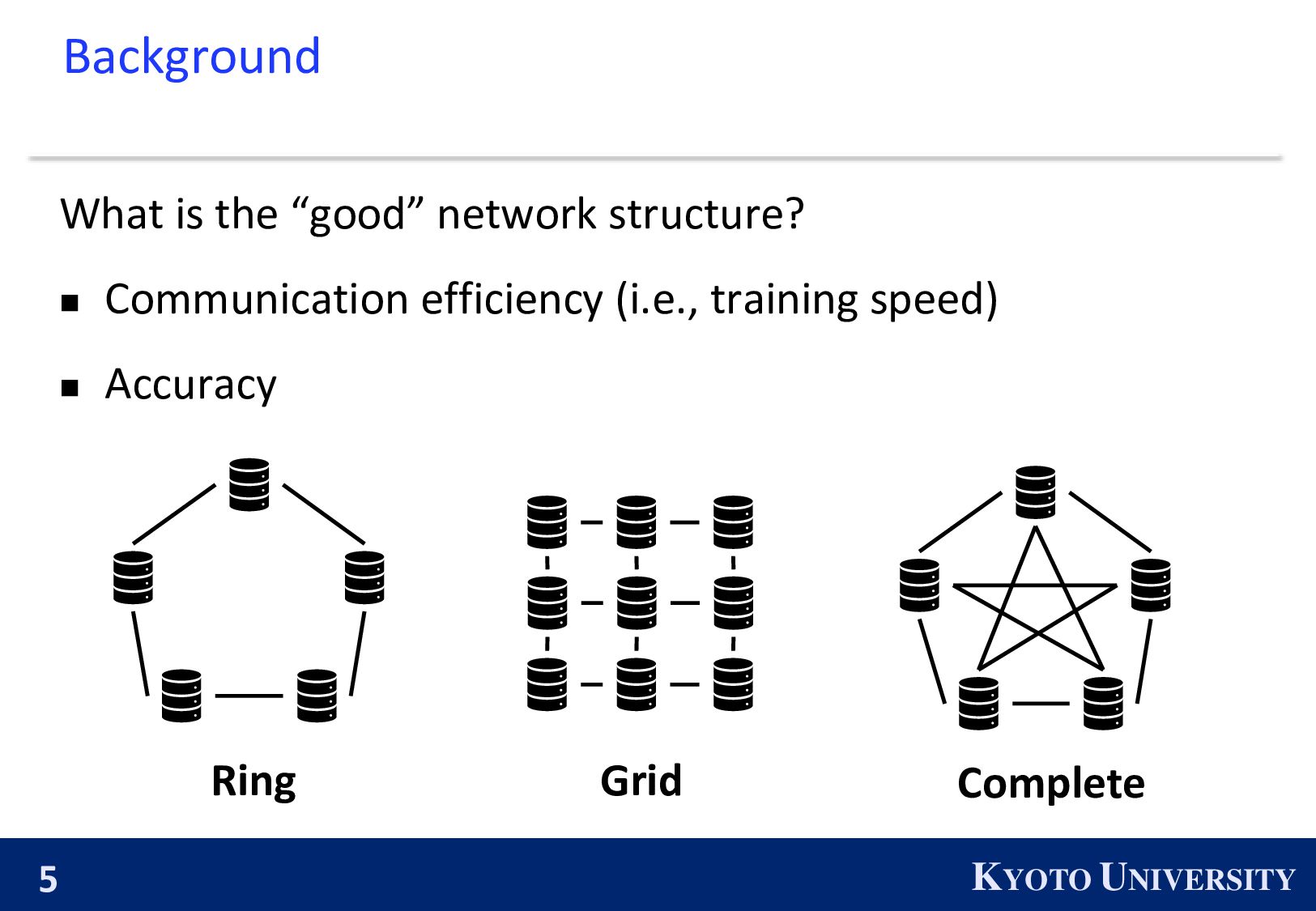
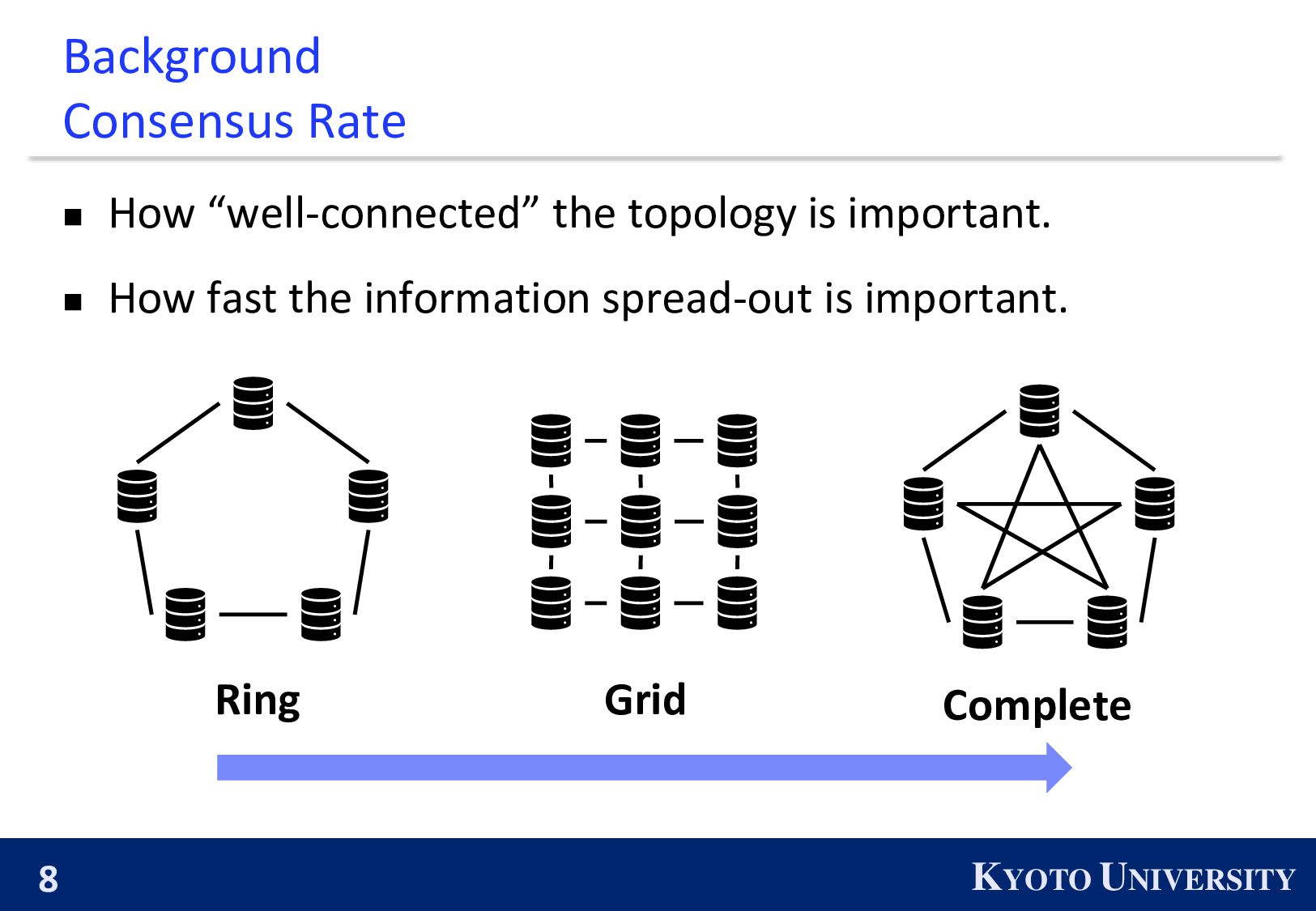
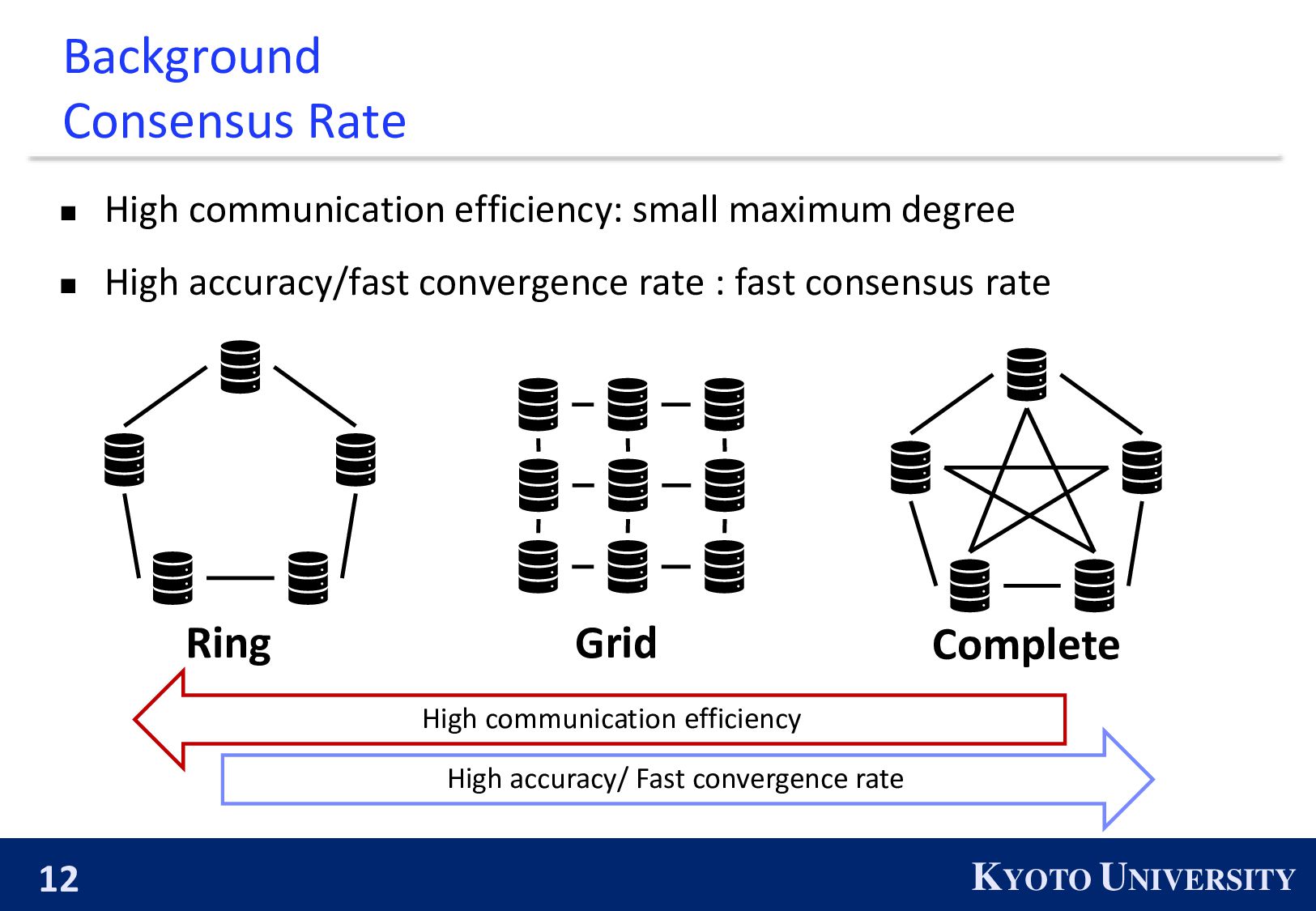
small maximum degree ◼ High accuracy/fast convergence rate : fast consensus rate Ring Complete Grid High accuracy/ Fast convergence rate High communication efficiency
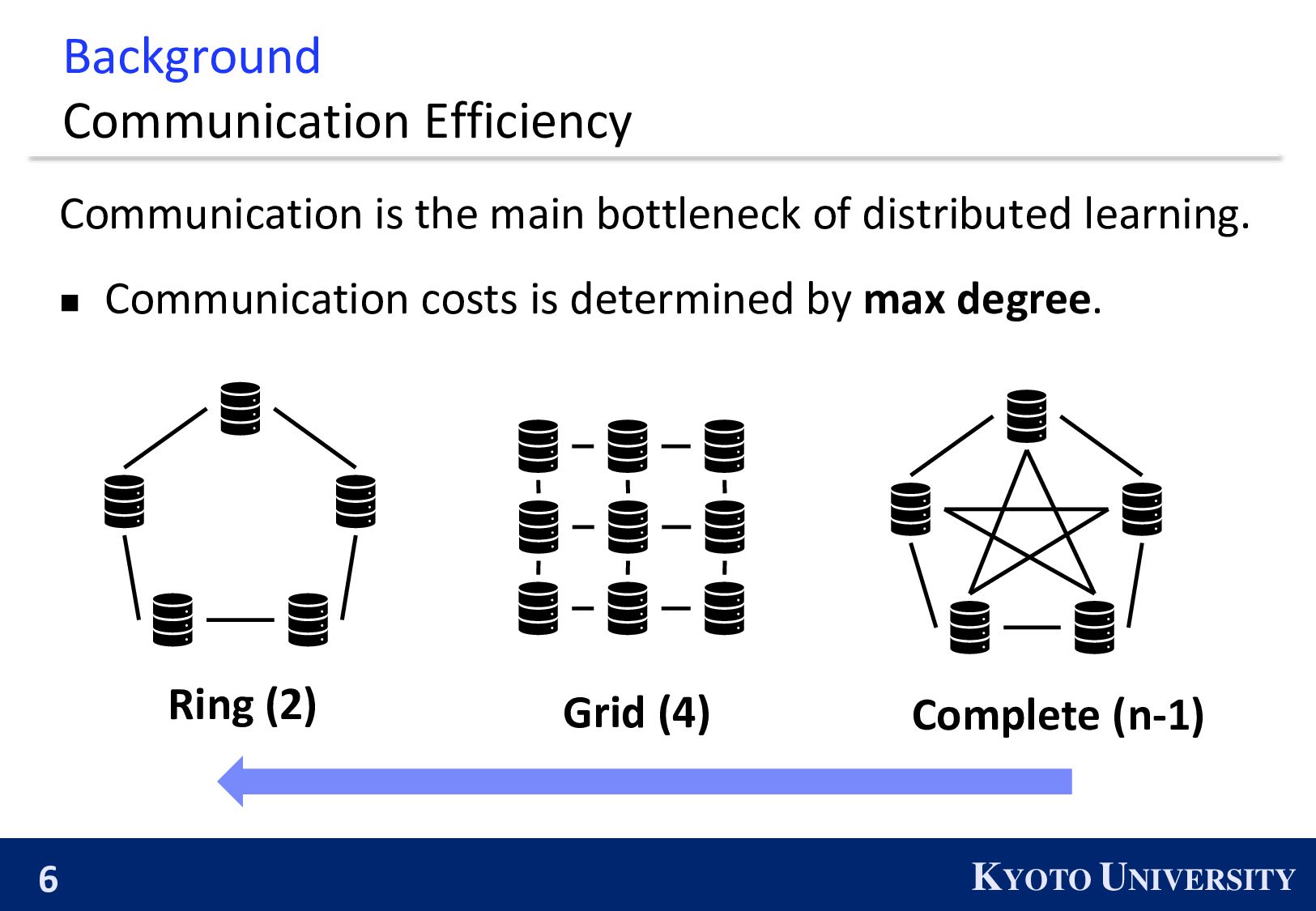
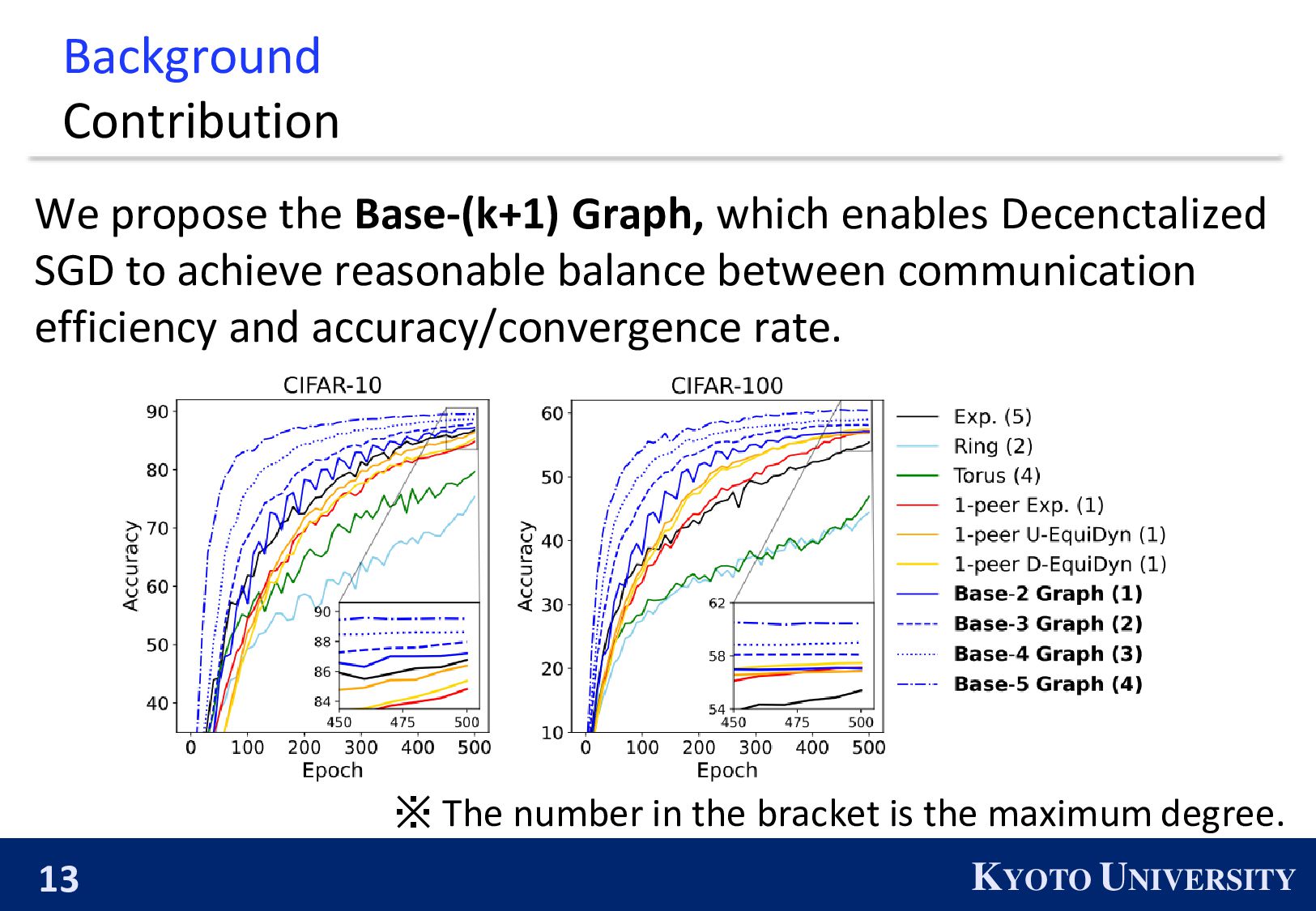
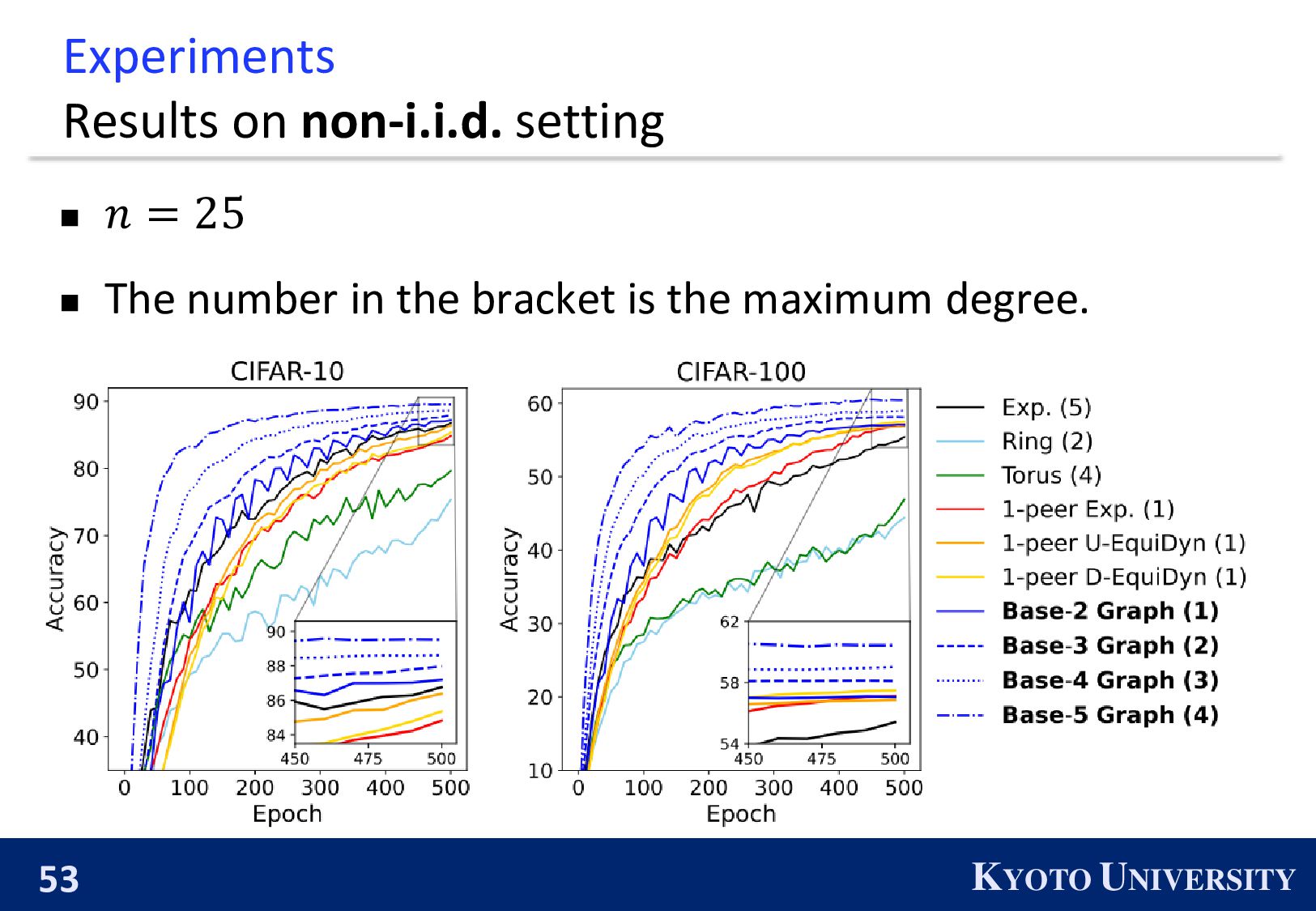
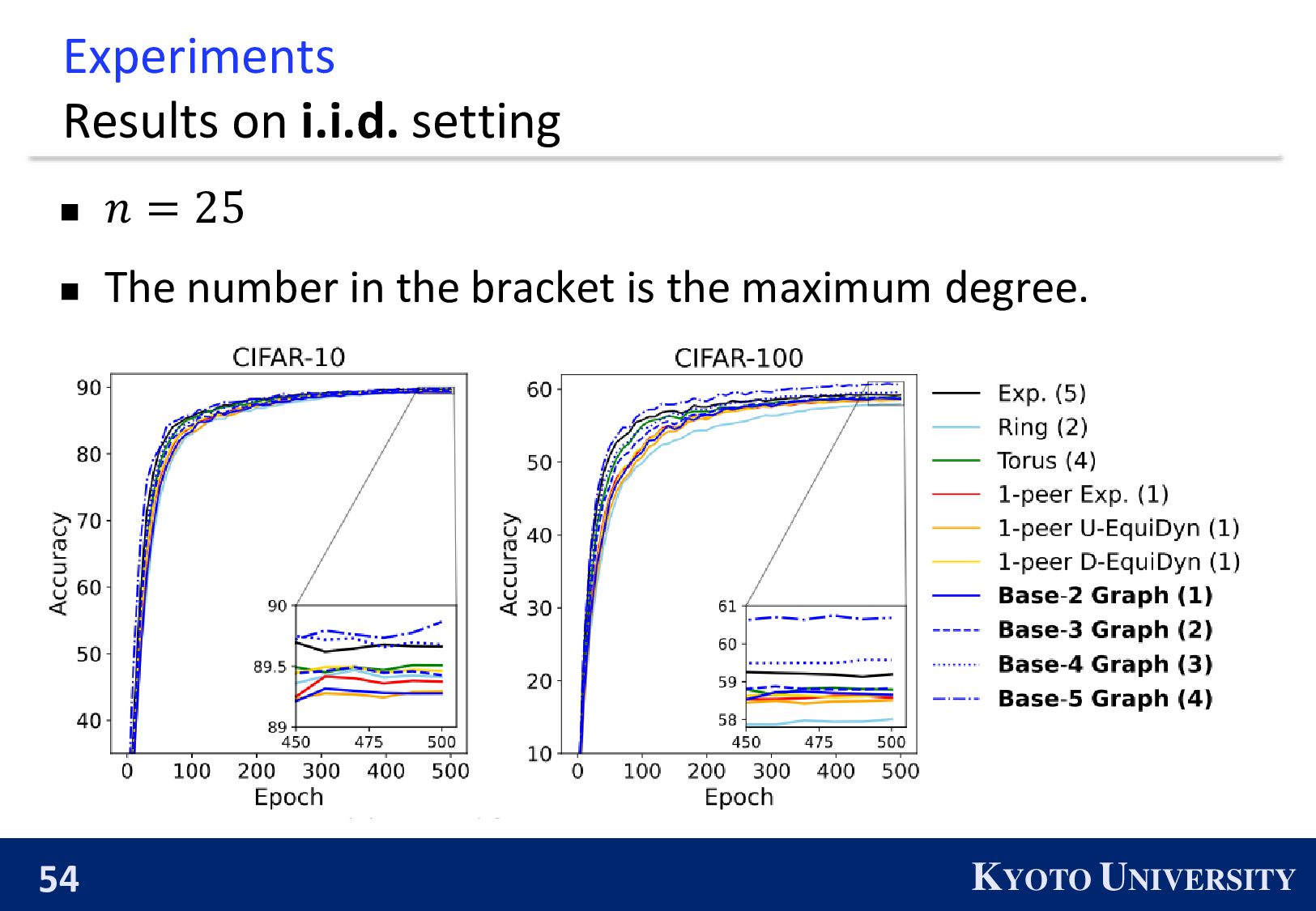
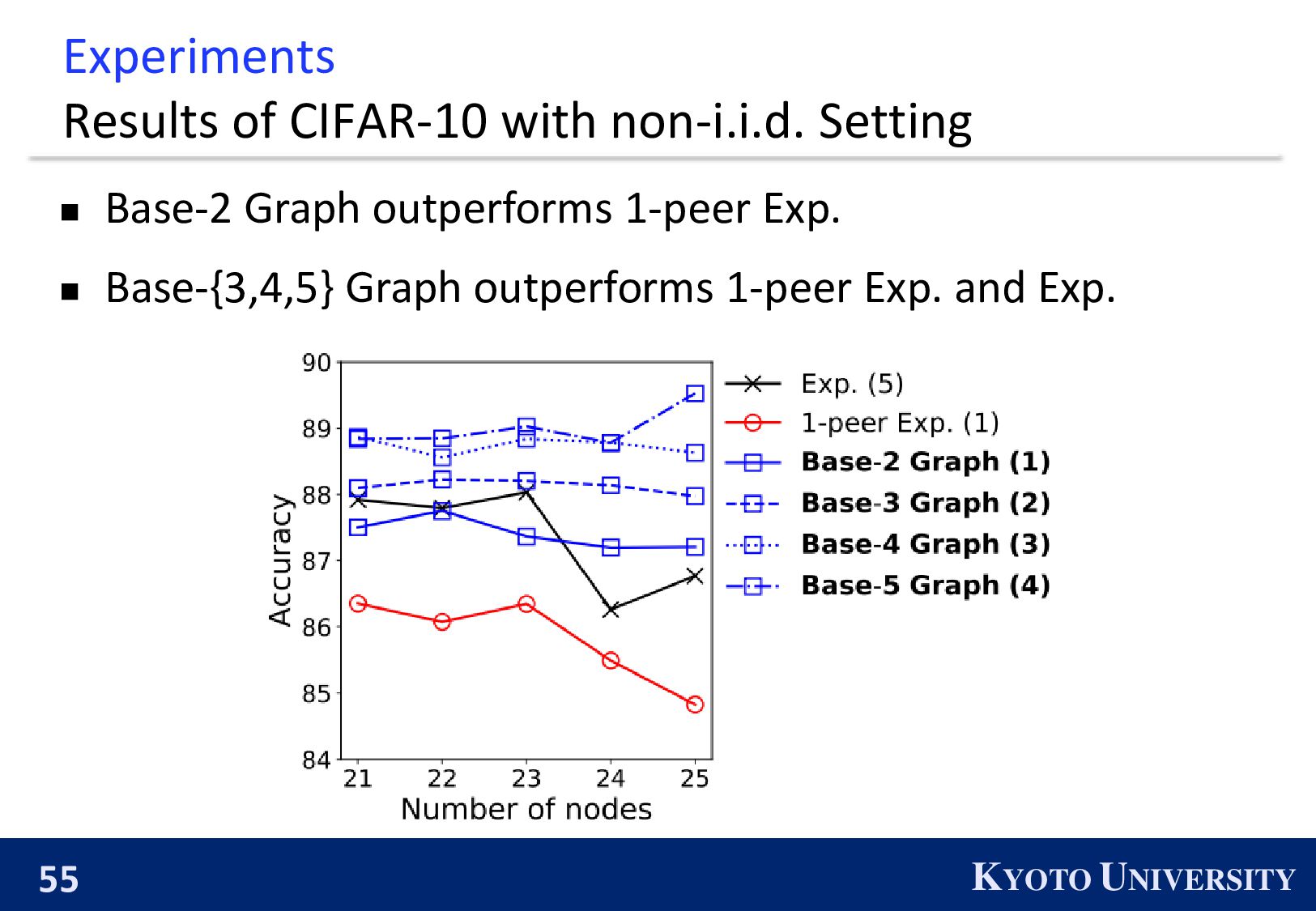
which enables Decenctalized SGD to achieve reasonable balance between communication efficiency and accuracy/convergence rate. ※ The number in the bracket is the maximum degree.
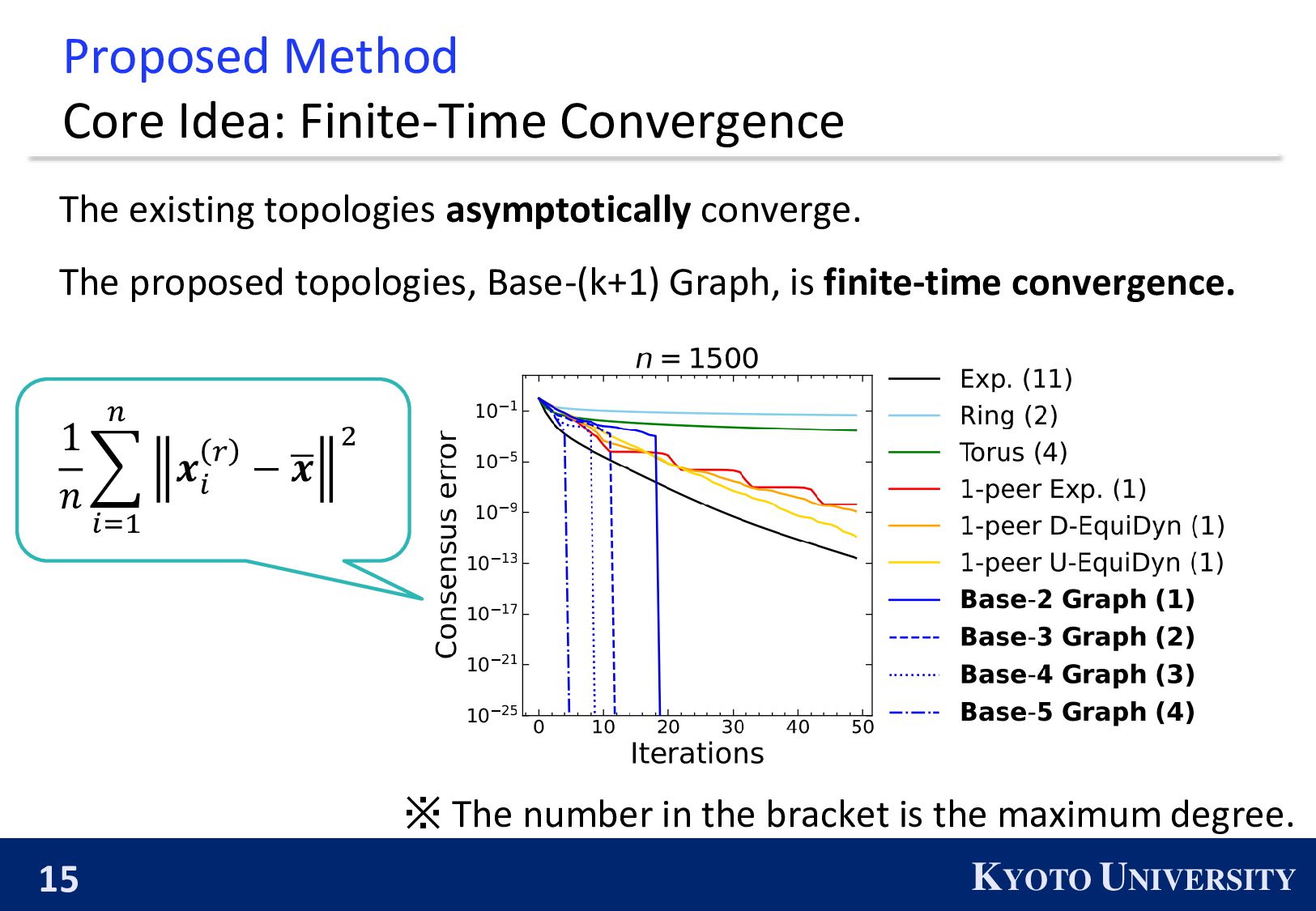
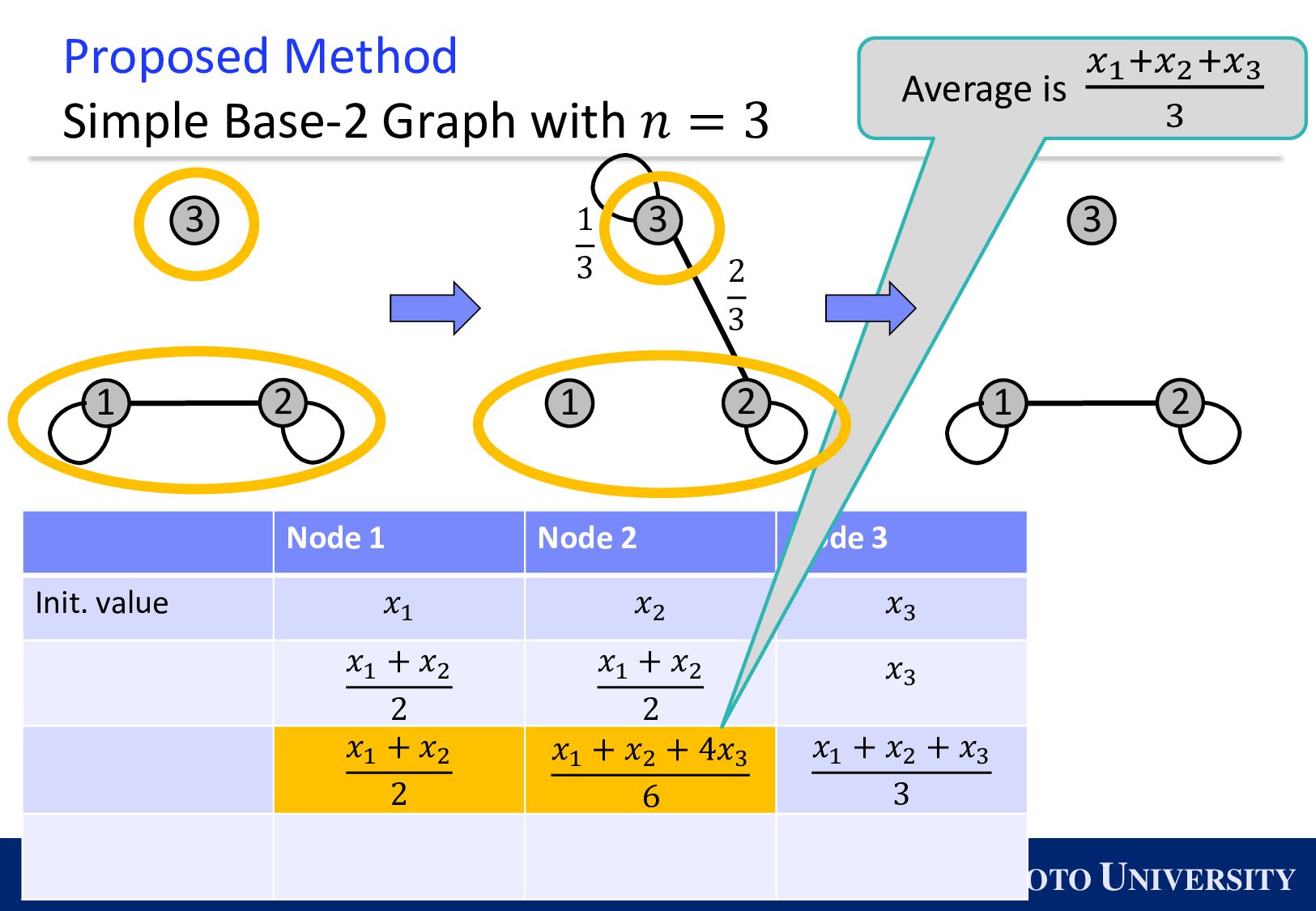
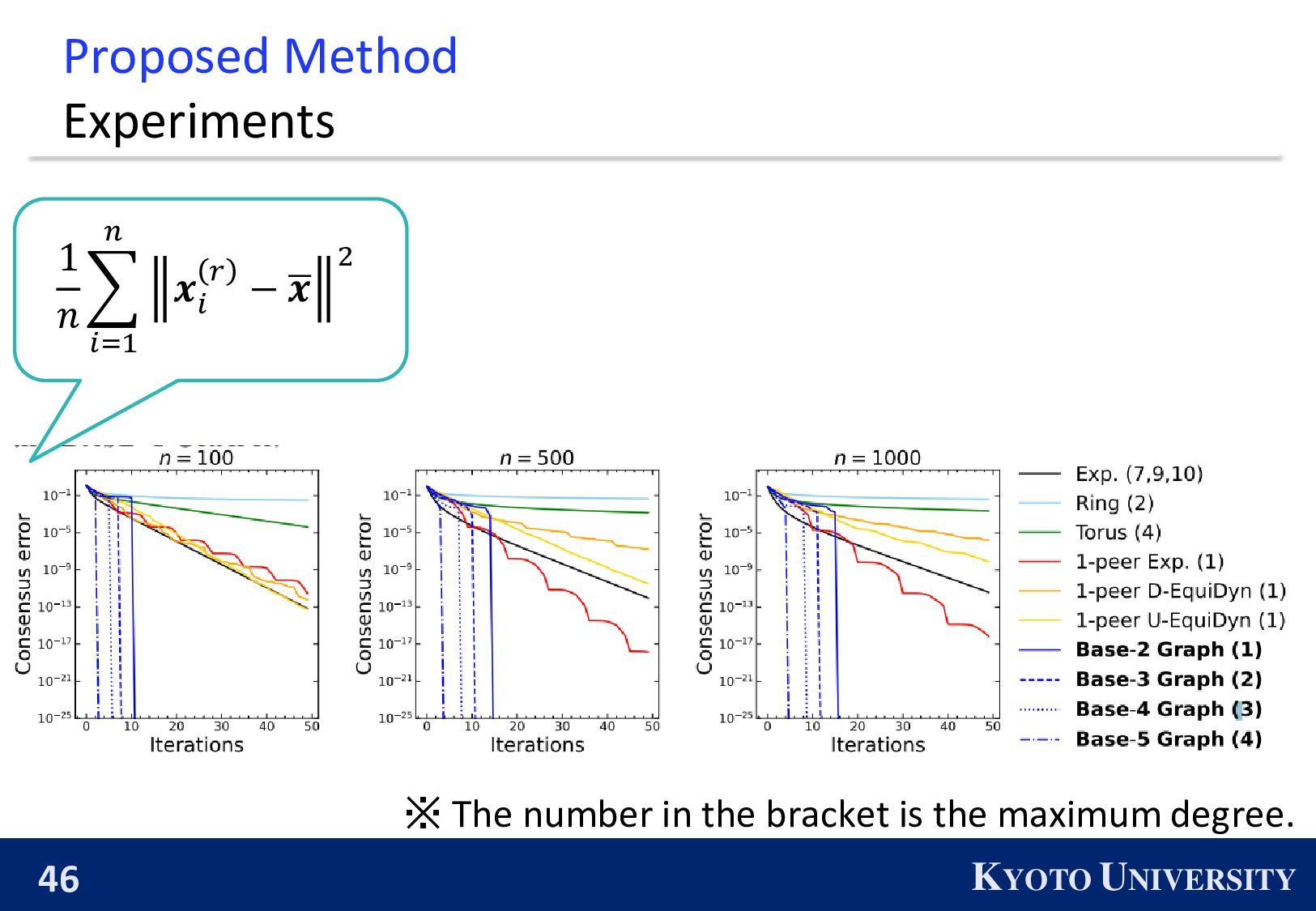
existing topologies asymptotically converge. The proposed topologies, Base-(k+1) Graph, is finite-time convergence. 1 𝑛 𝑖=1 𝑛 𝒙 𝑖 𝑟 − ഥ 𝒙 2 ※ The number in the bracket is the maximum degree.
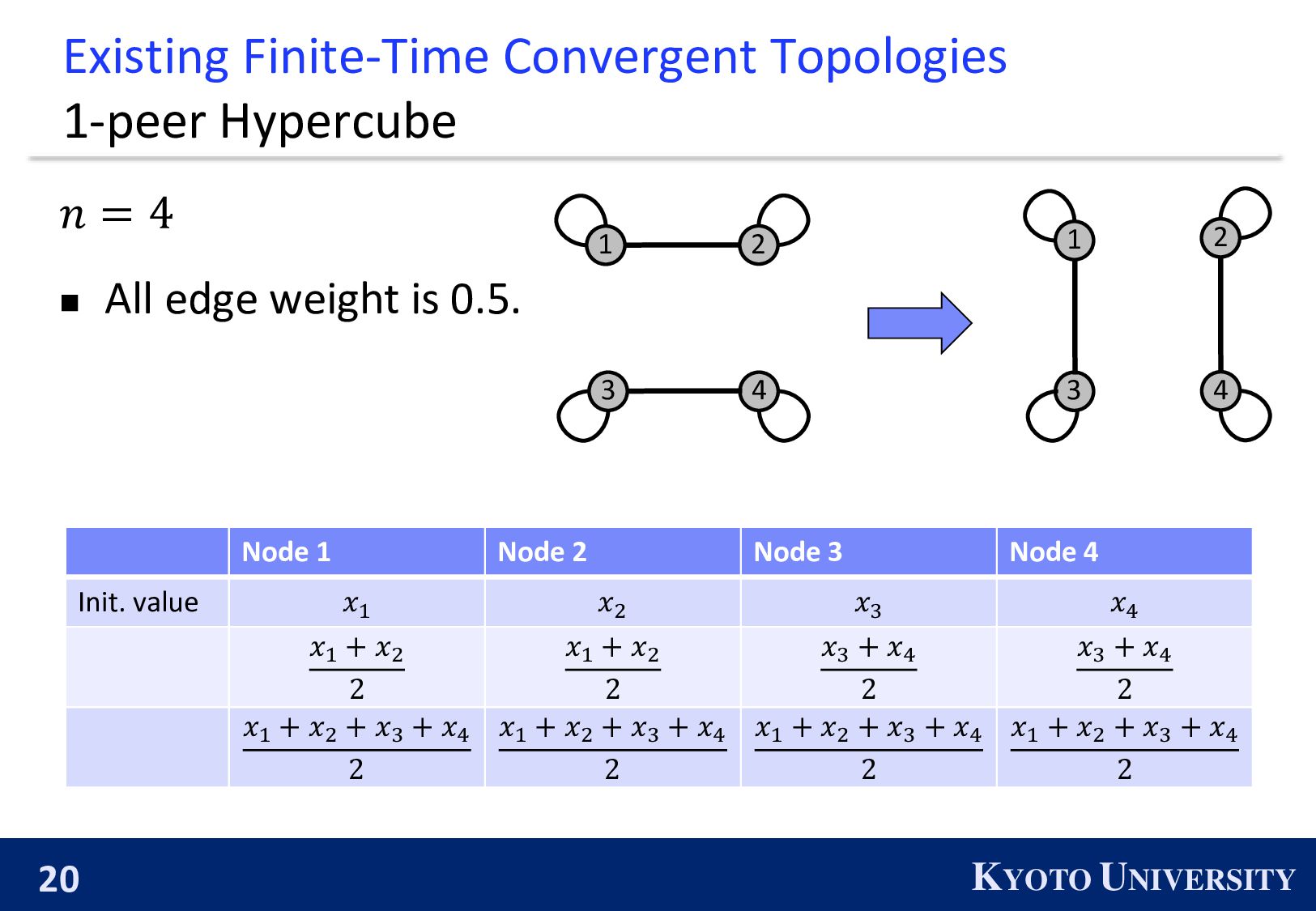
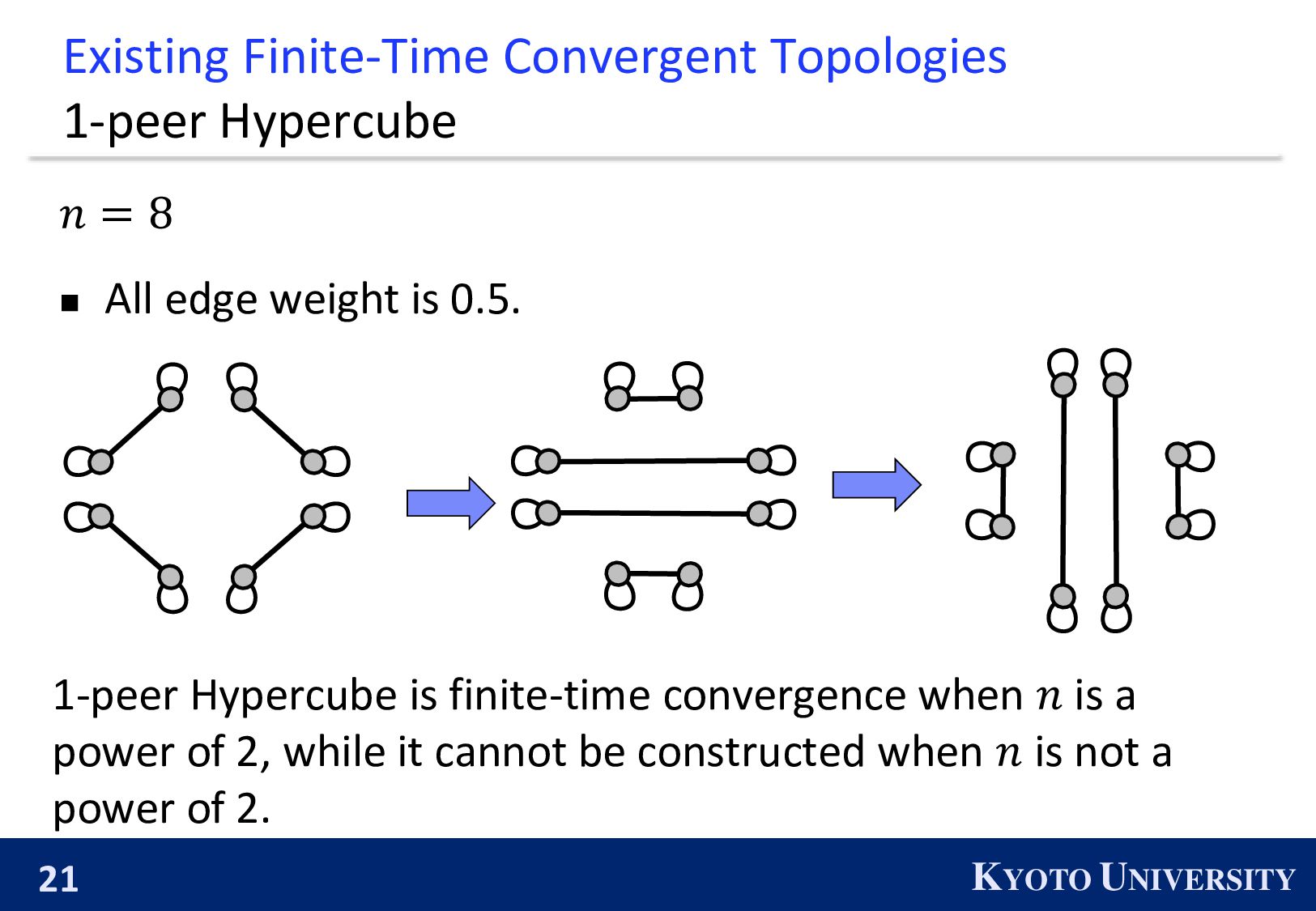
Max Degree #Nodes 𝒏 1-peer Hypercube 1 A power of 2 1-peer Exp. Graph 1 A power of 2 Base-(k+1) Graph 𝑘 Arbitrary number of nodes ◼ 1-peer Hypercube is not constructed when 𝑛 is not power of 2. ◼ 1-peer Exp. is not finite-time convergence when 𝑛 is not power of 2.
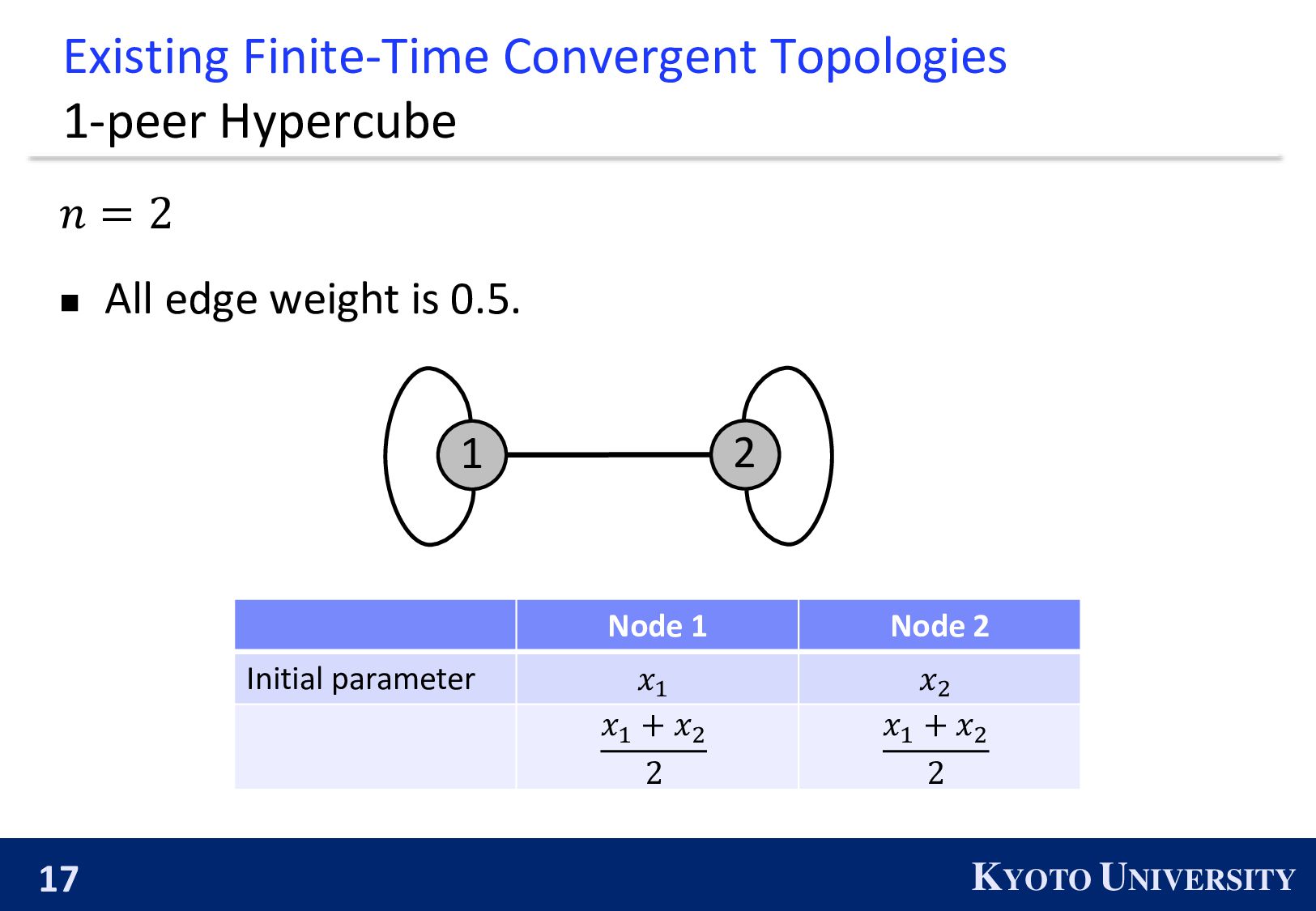
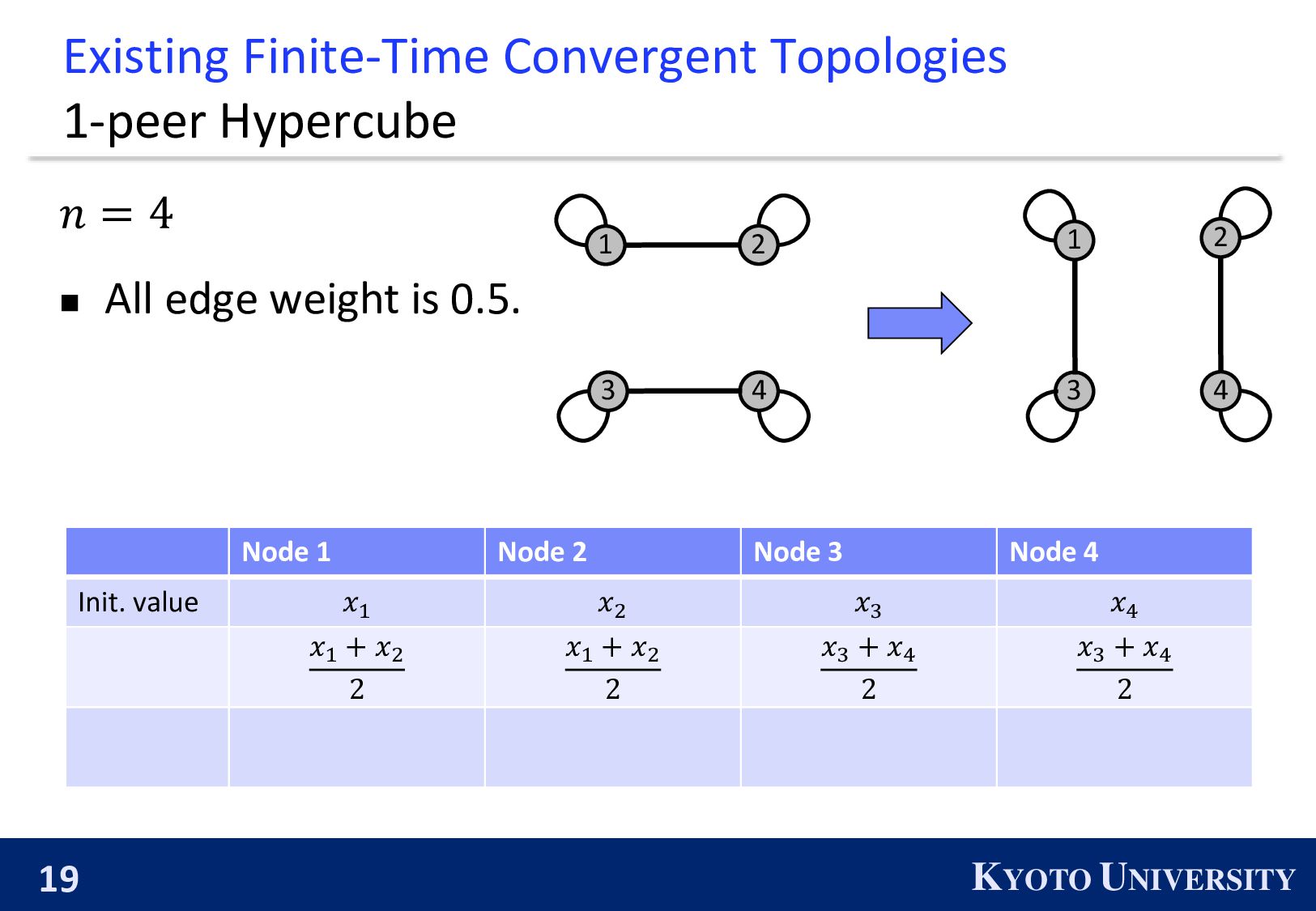
= 8 ◼ All edge weight is 0.5. 1-peer Hypercube is finite-time convergence when 𝑛 is a power of 2, while it cannot be constructed when 𝑛 is not a power of 2.
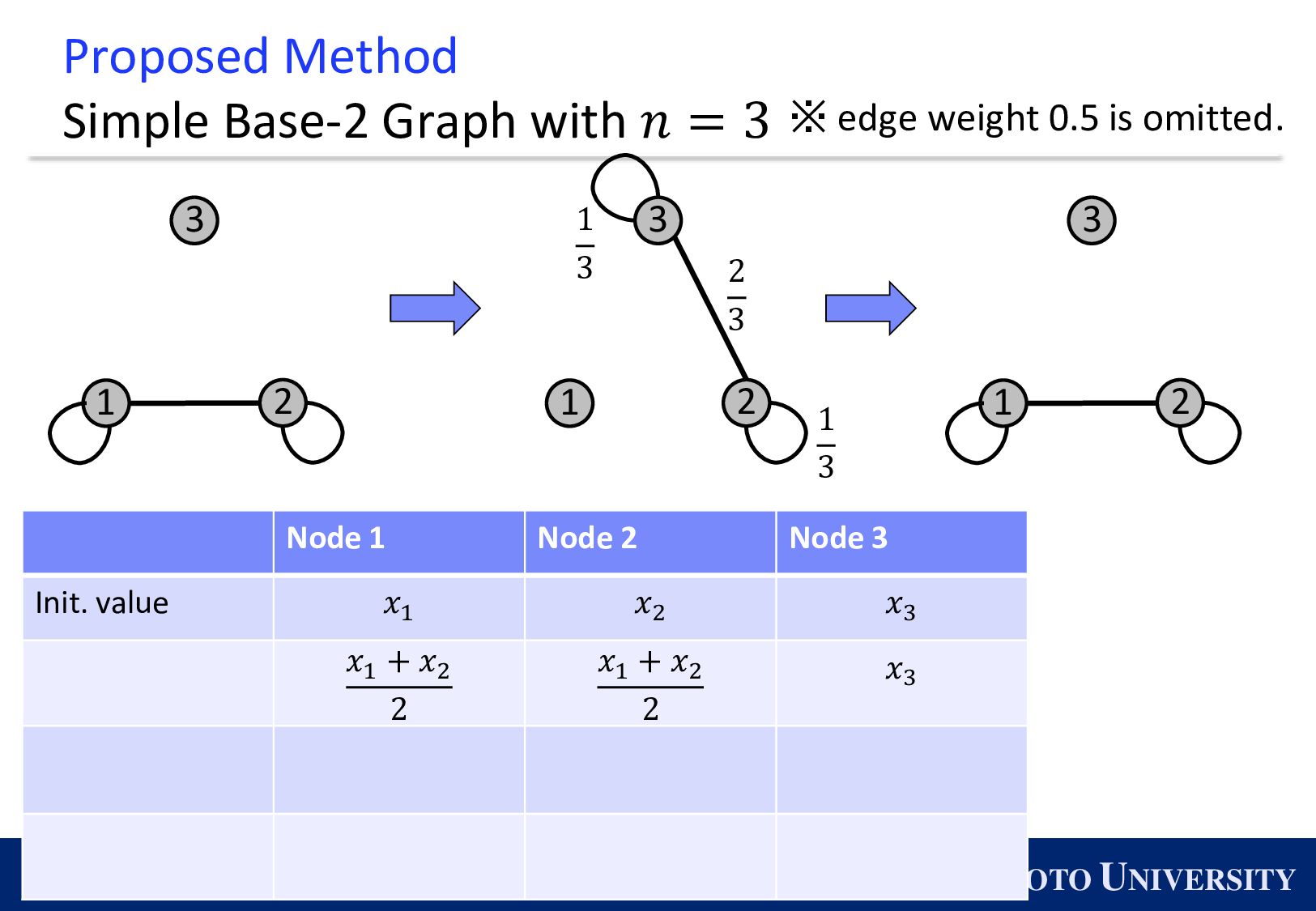
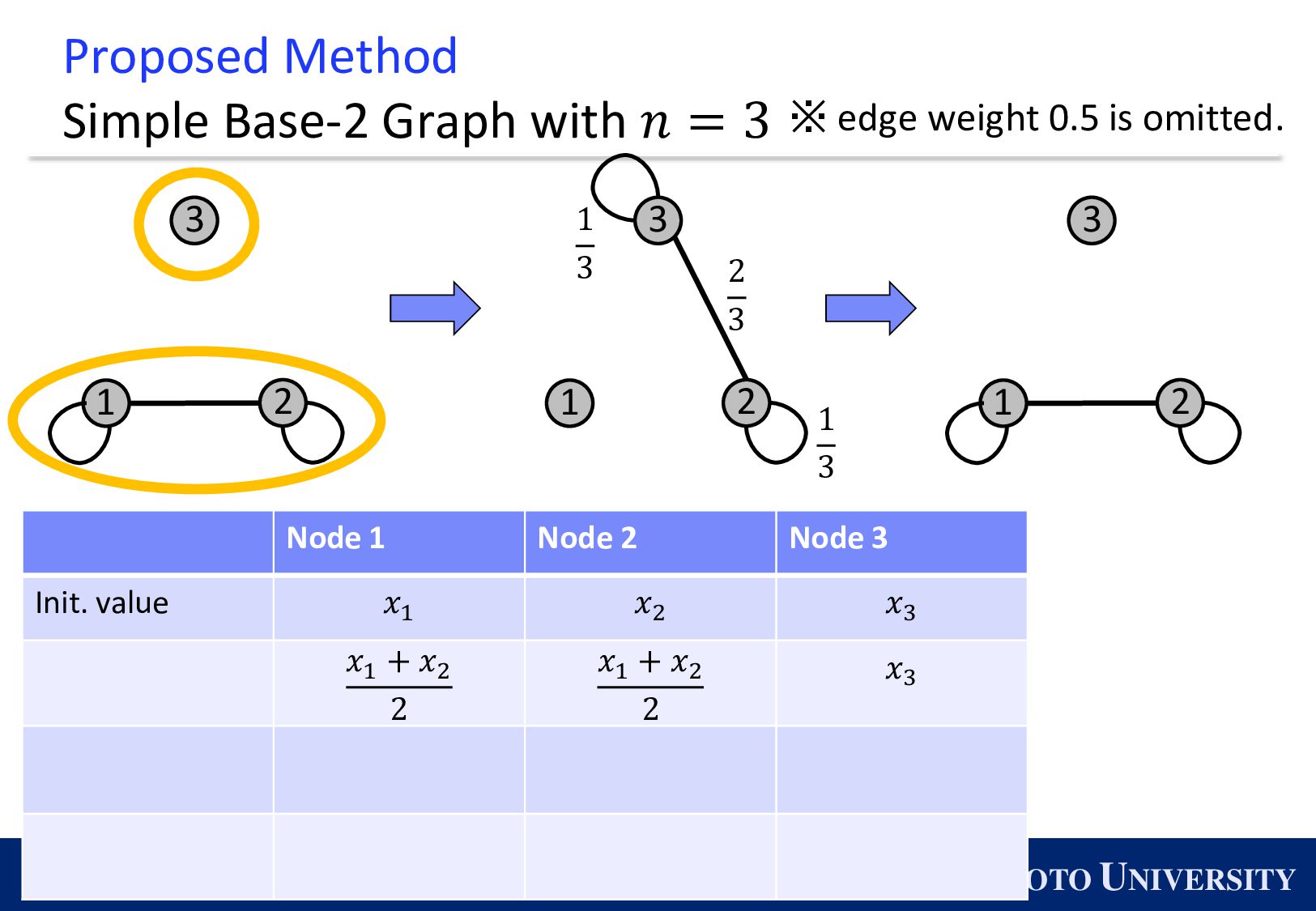
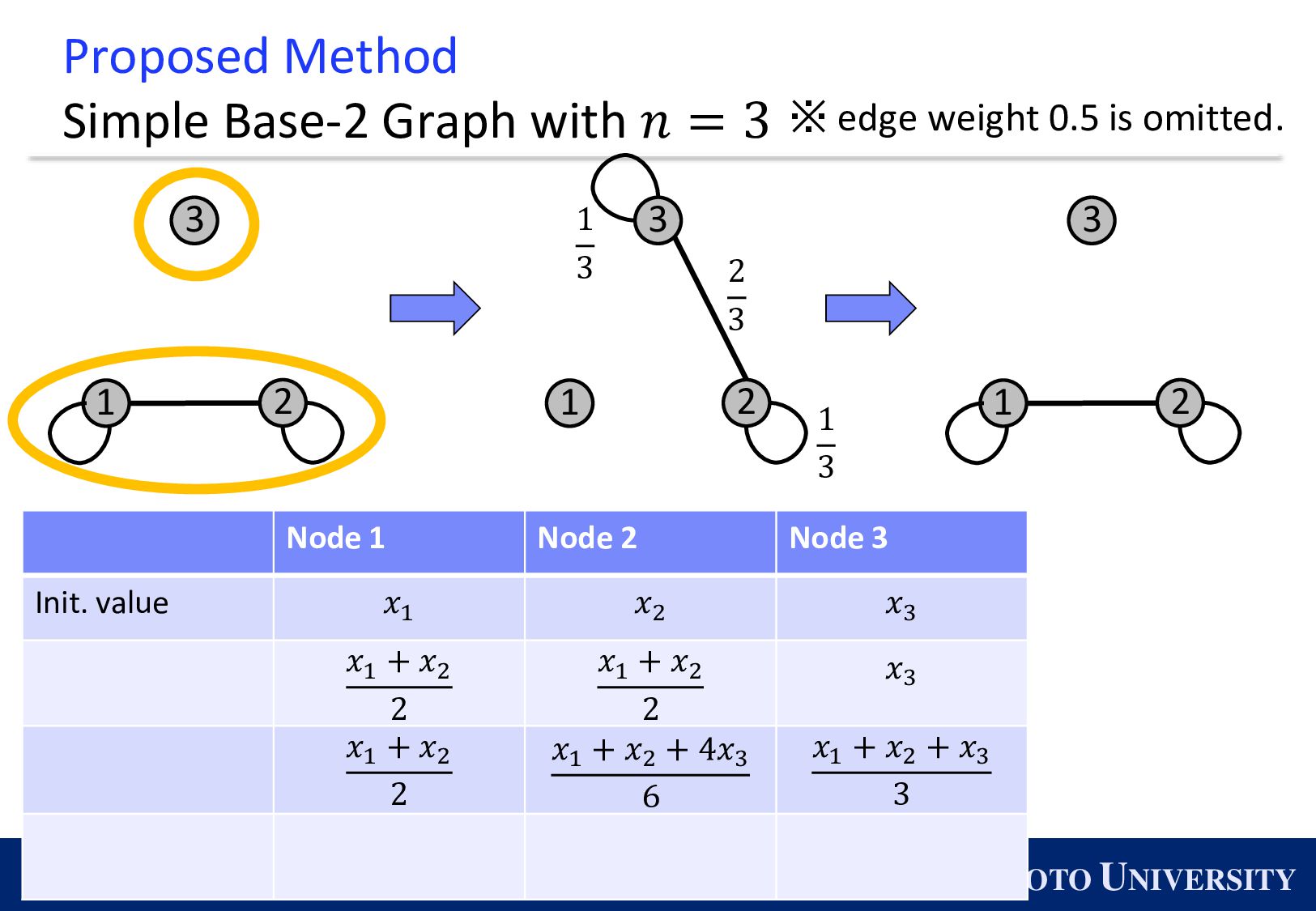
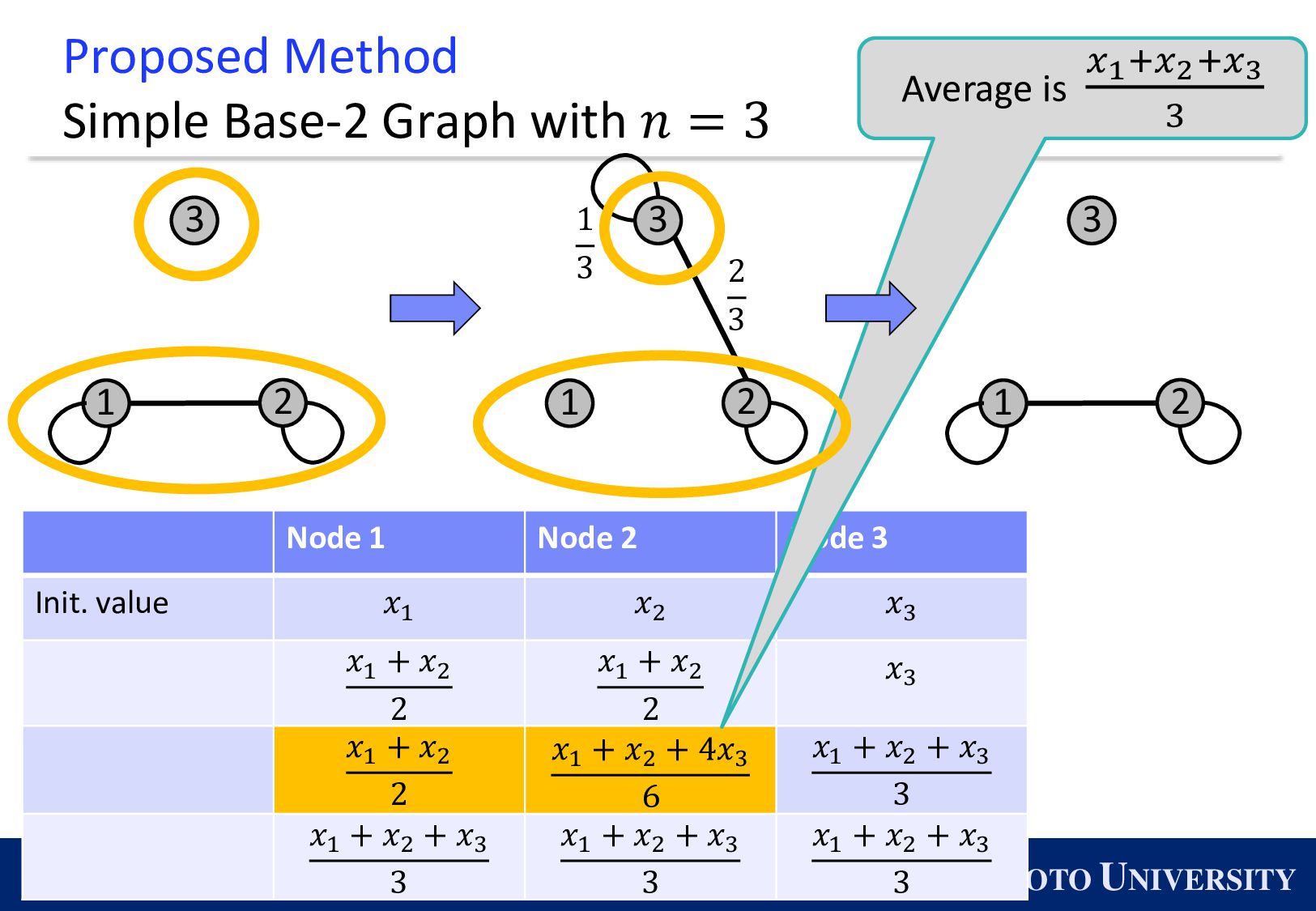
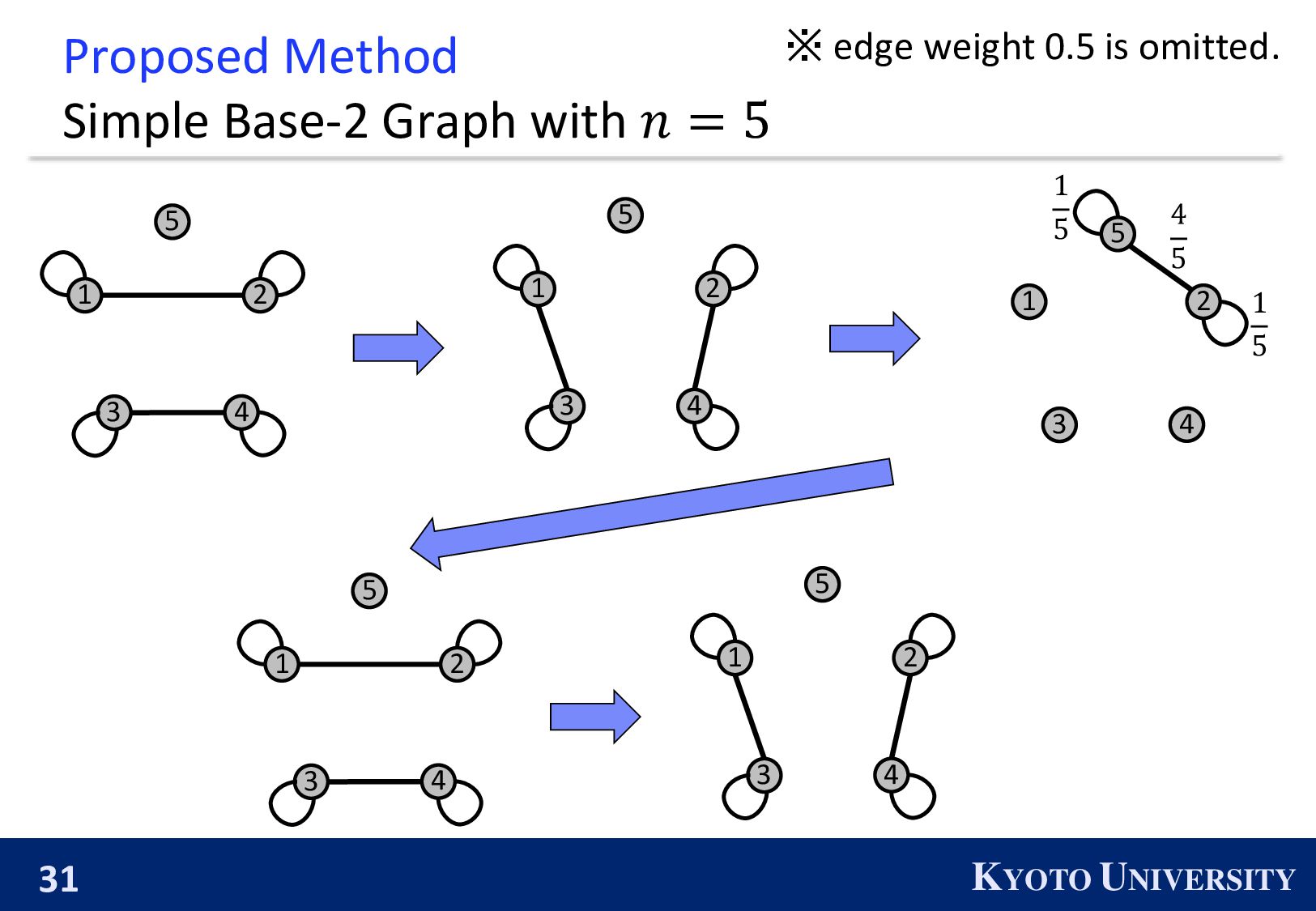
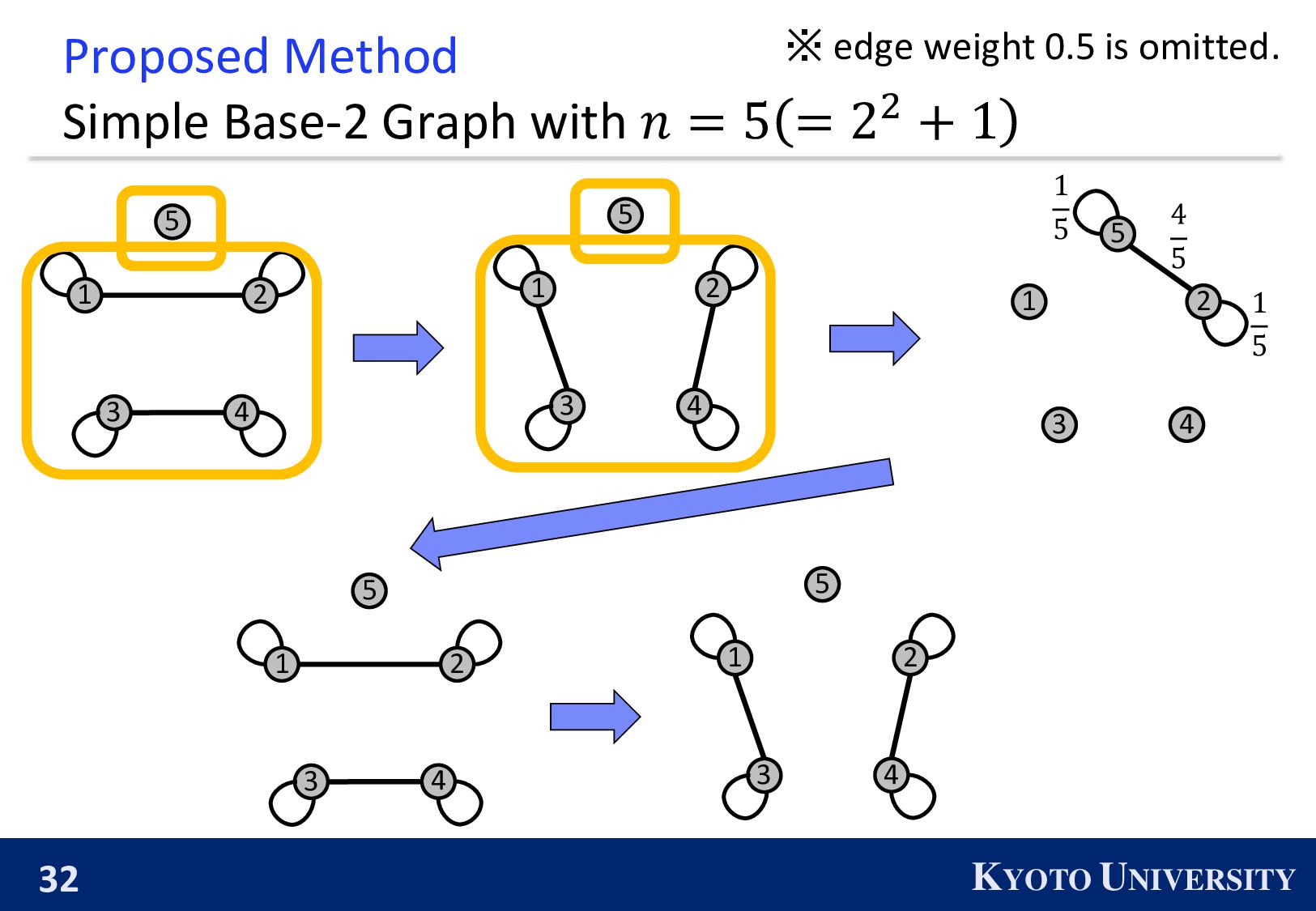
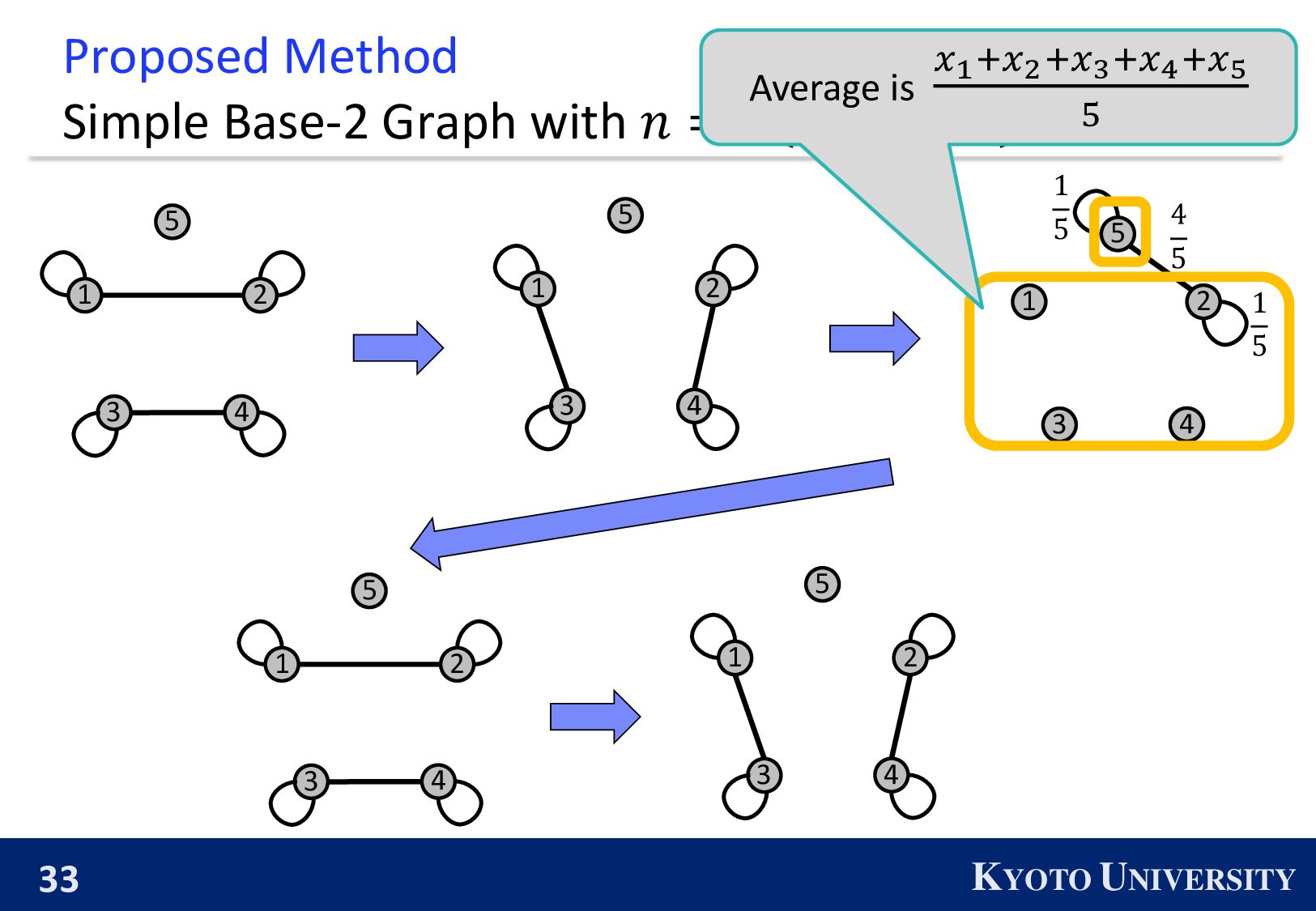
the Base-2 Graph: ◼ It is finite-time convergence for any 𝑛. ◼ Its maximum degree is 1. Topology Max Degree #Nodes 𝒏 1-peer Hypercube 1 A power of 2 1-peer Exp. Graph 1 A power of 2 Base-(k+1) Graph 𝑘 Arbitrary number of nodes
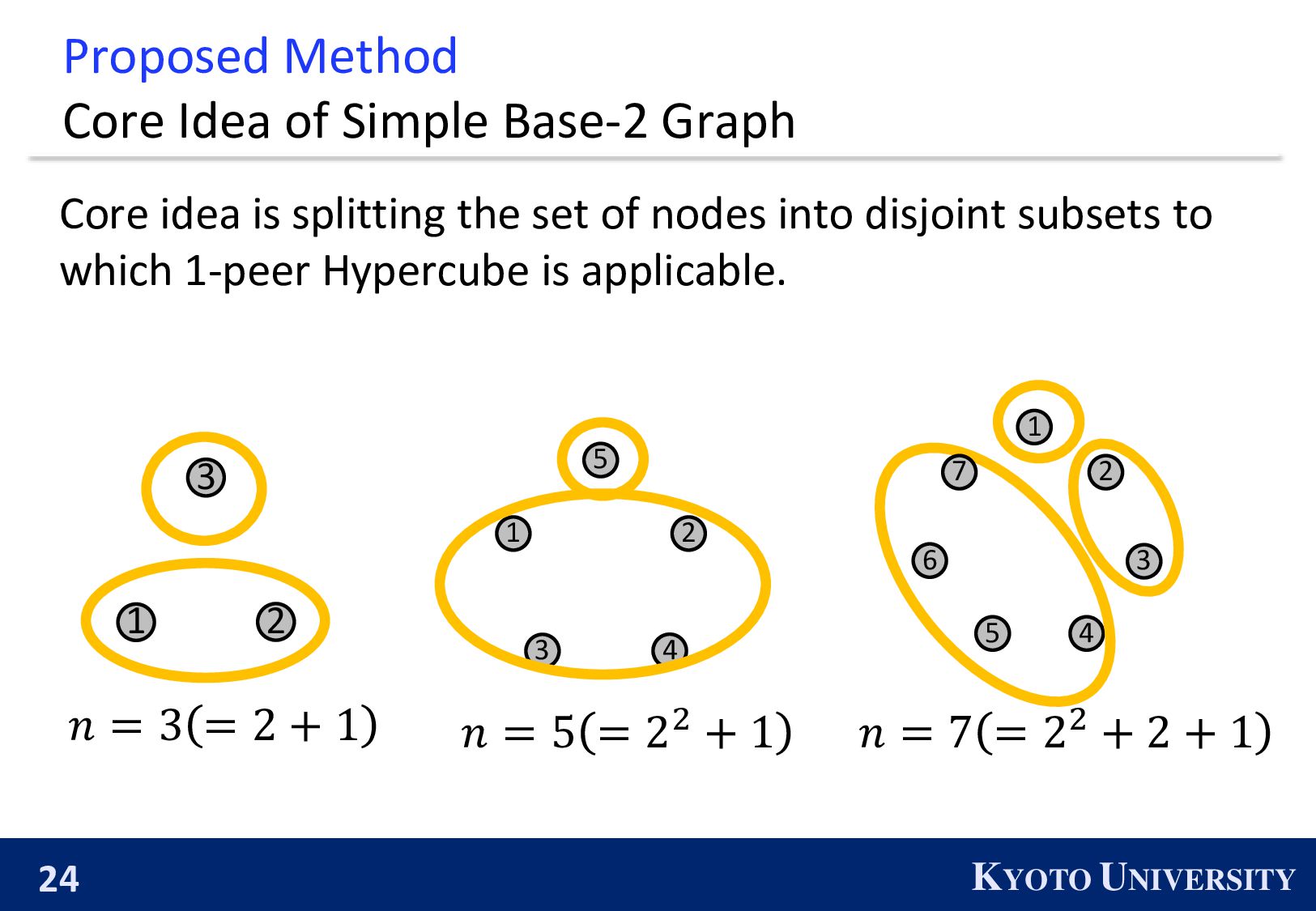
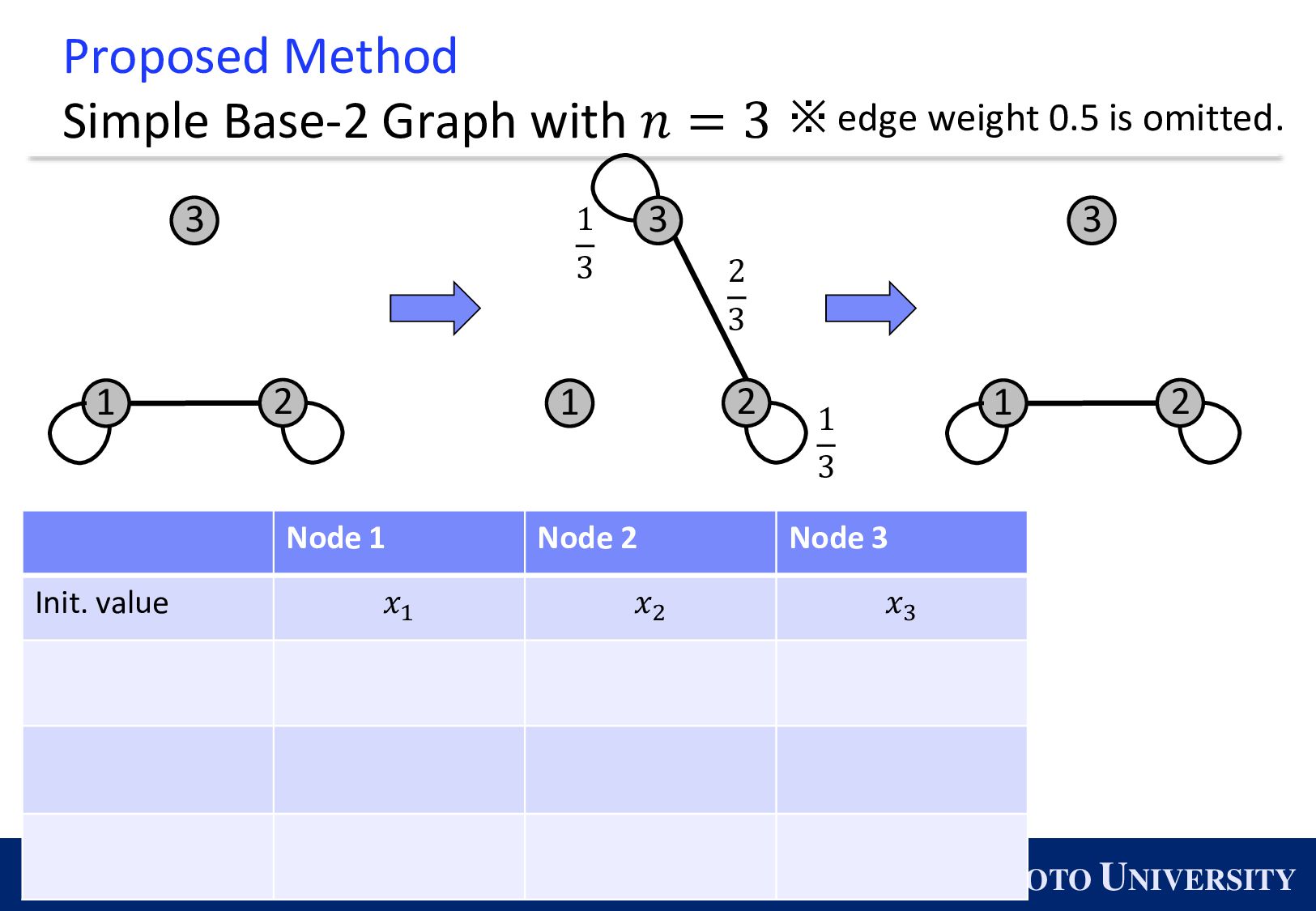
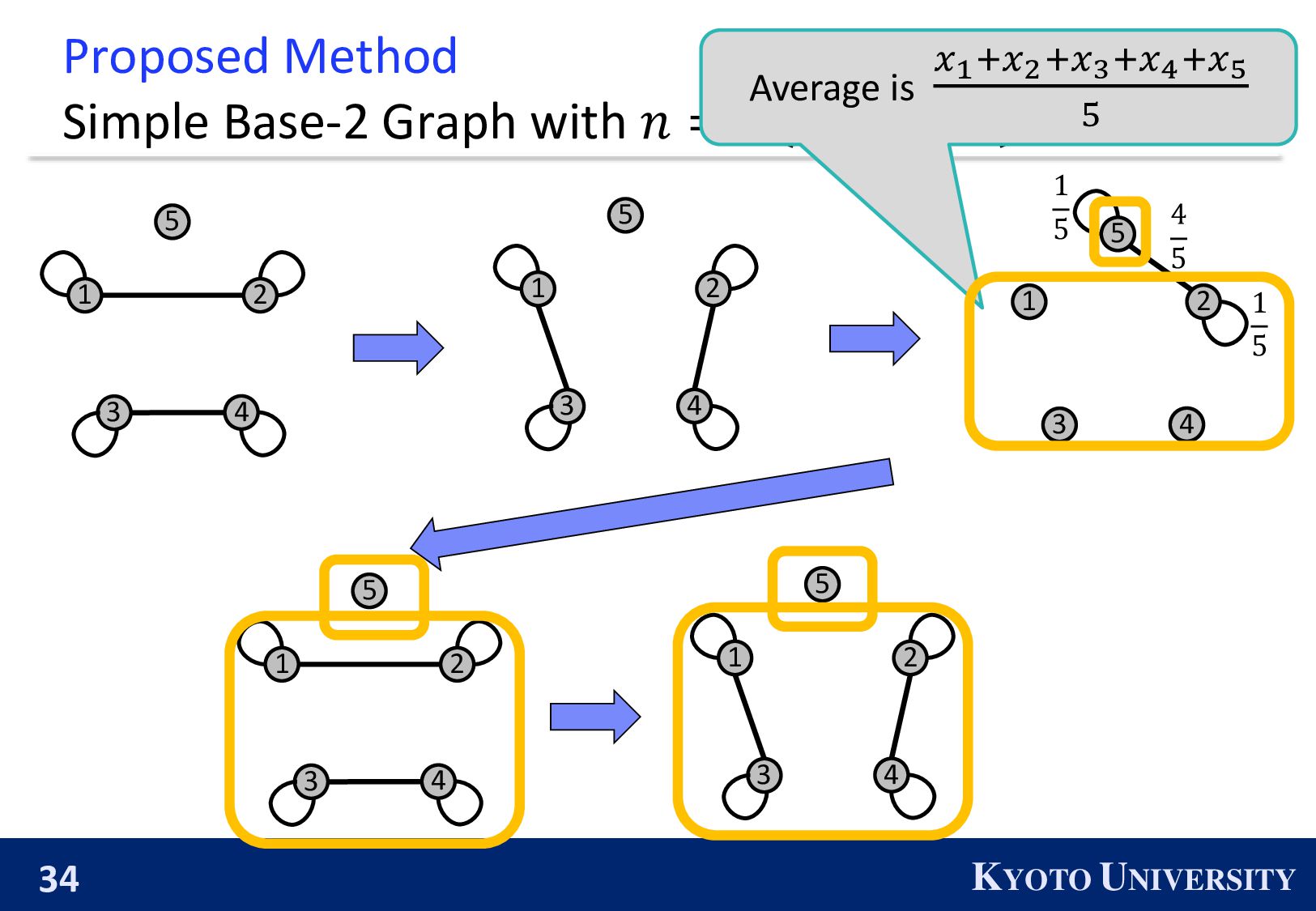
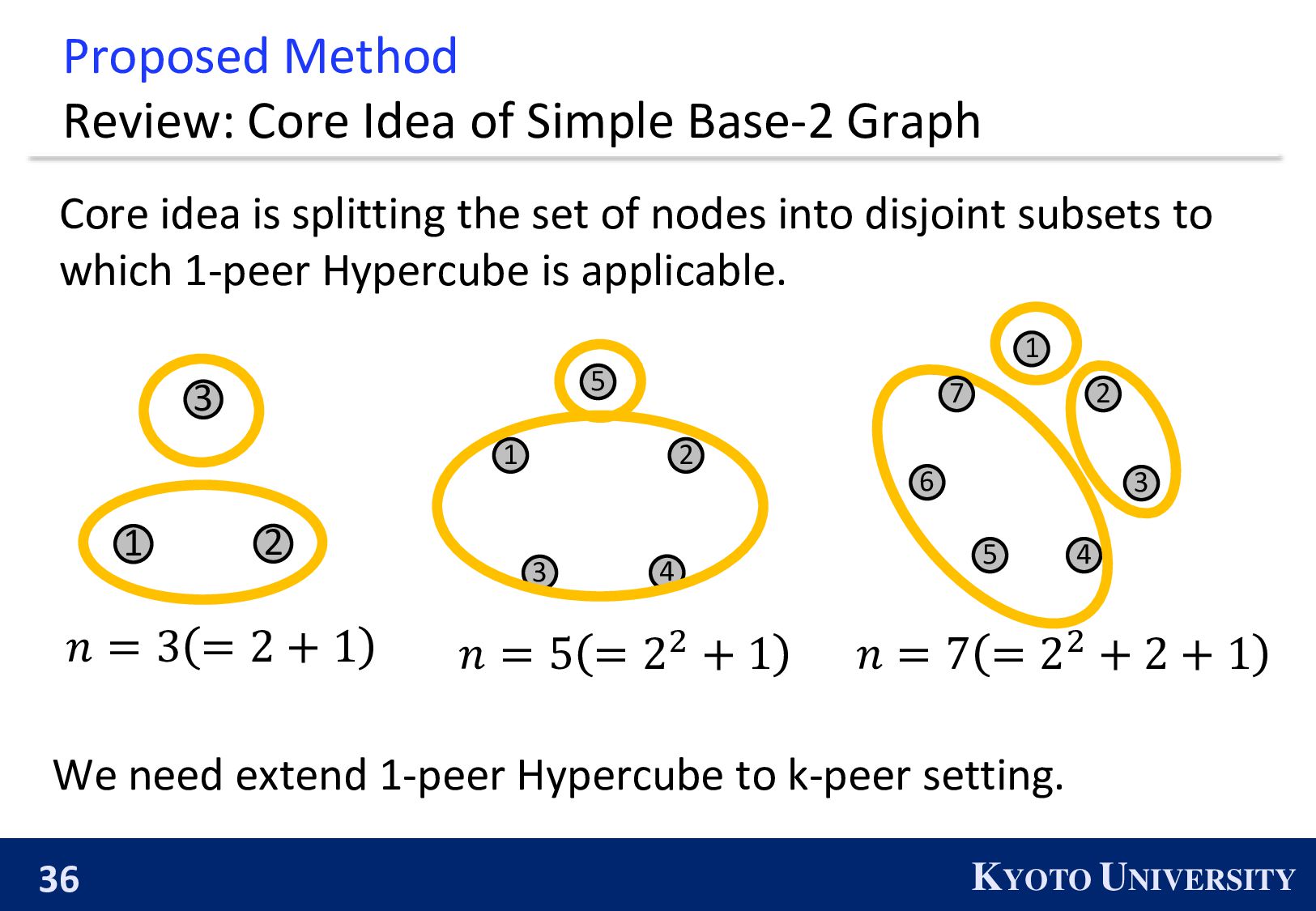
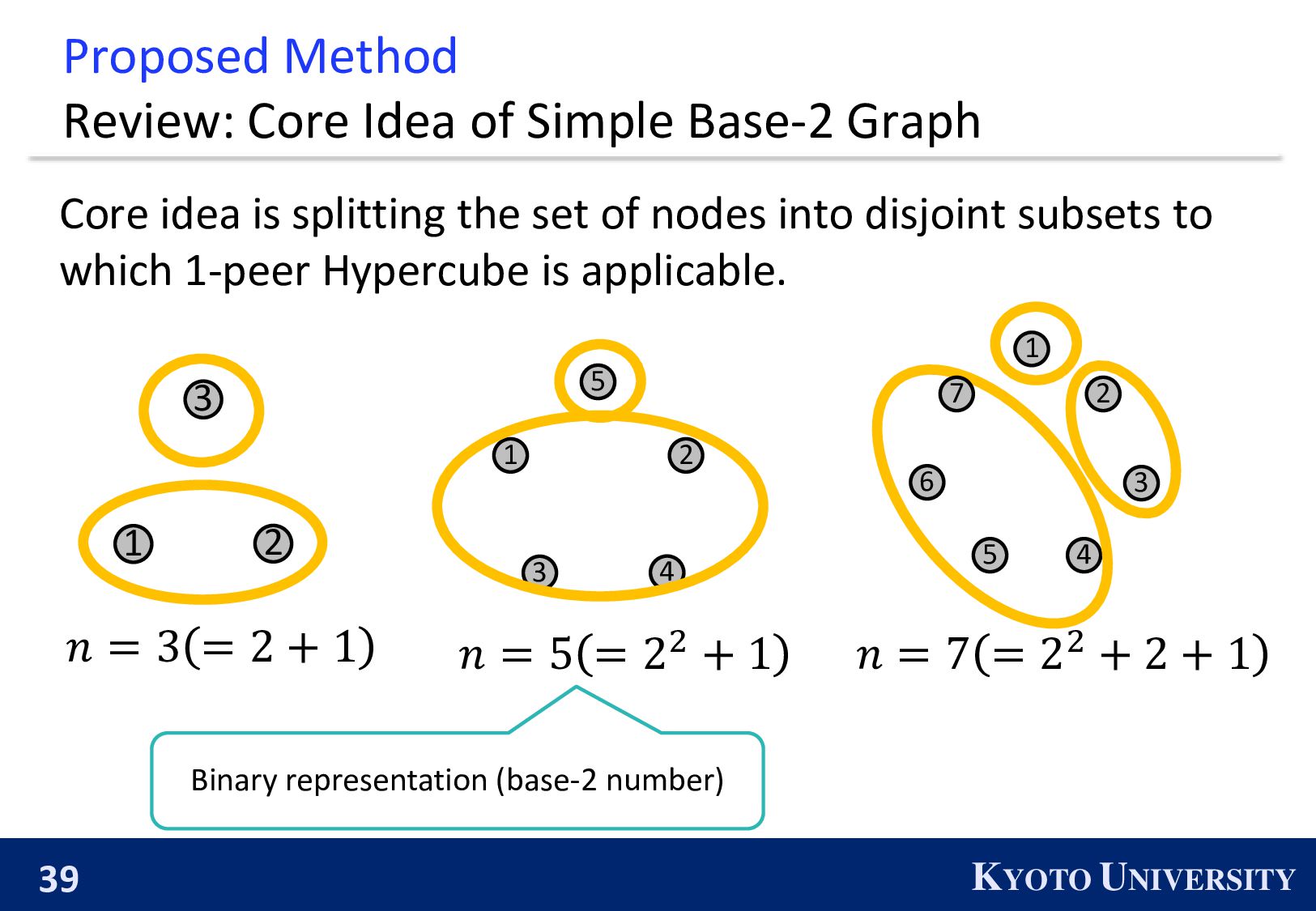
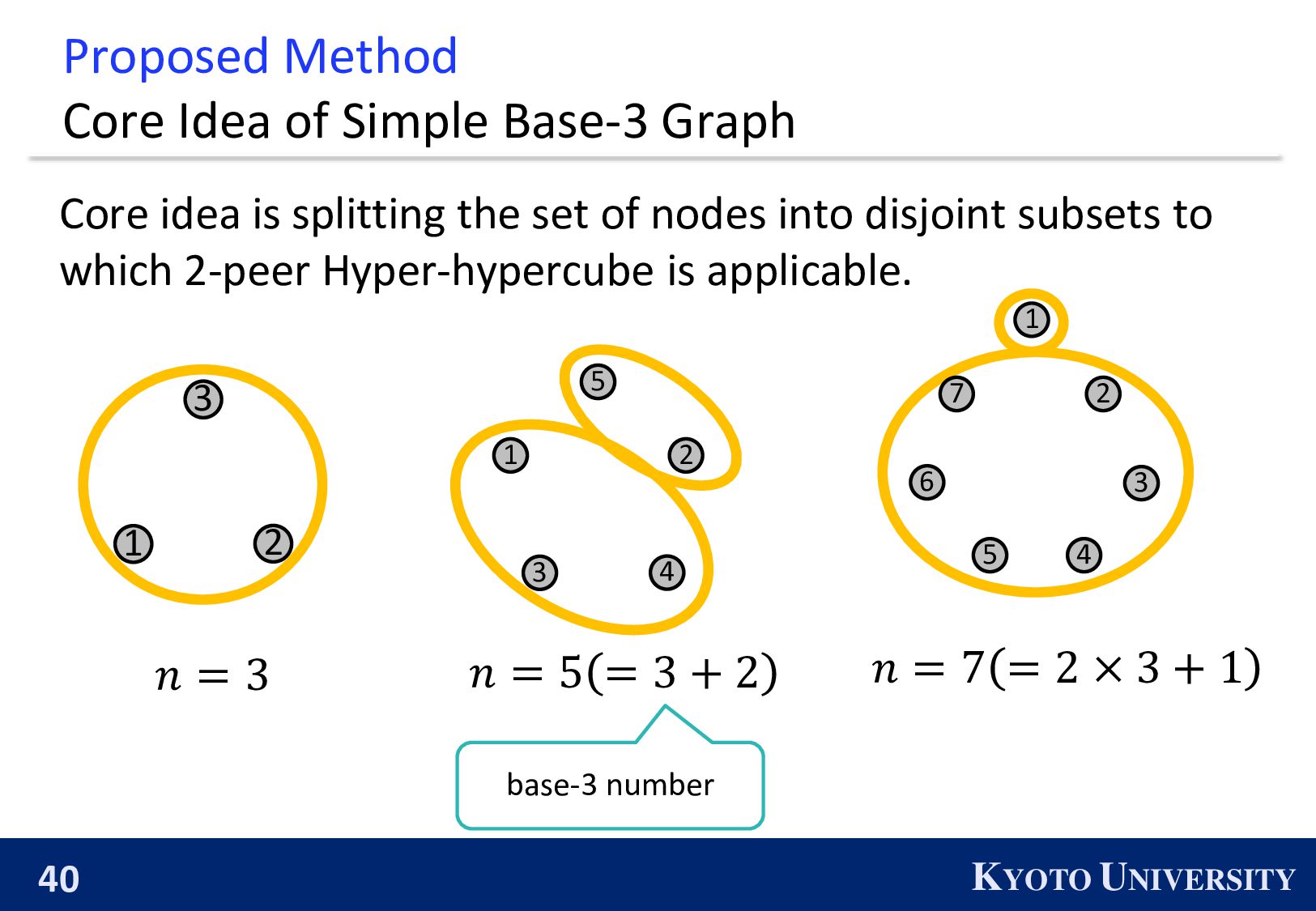
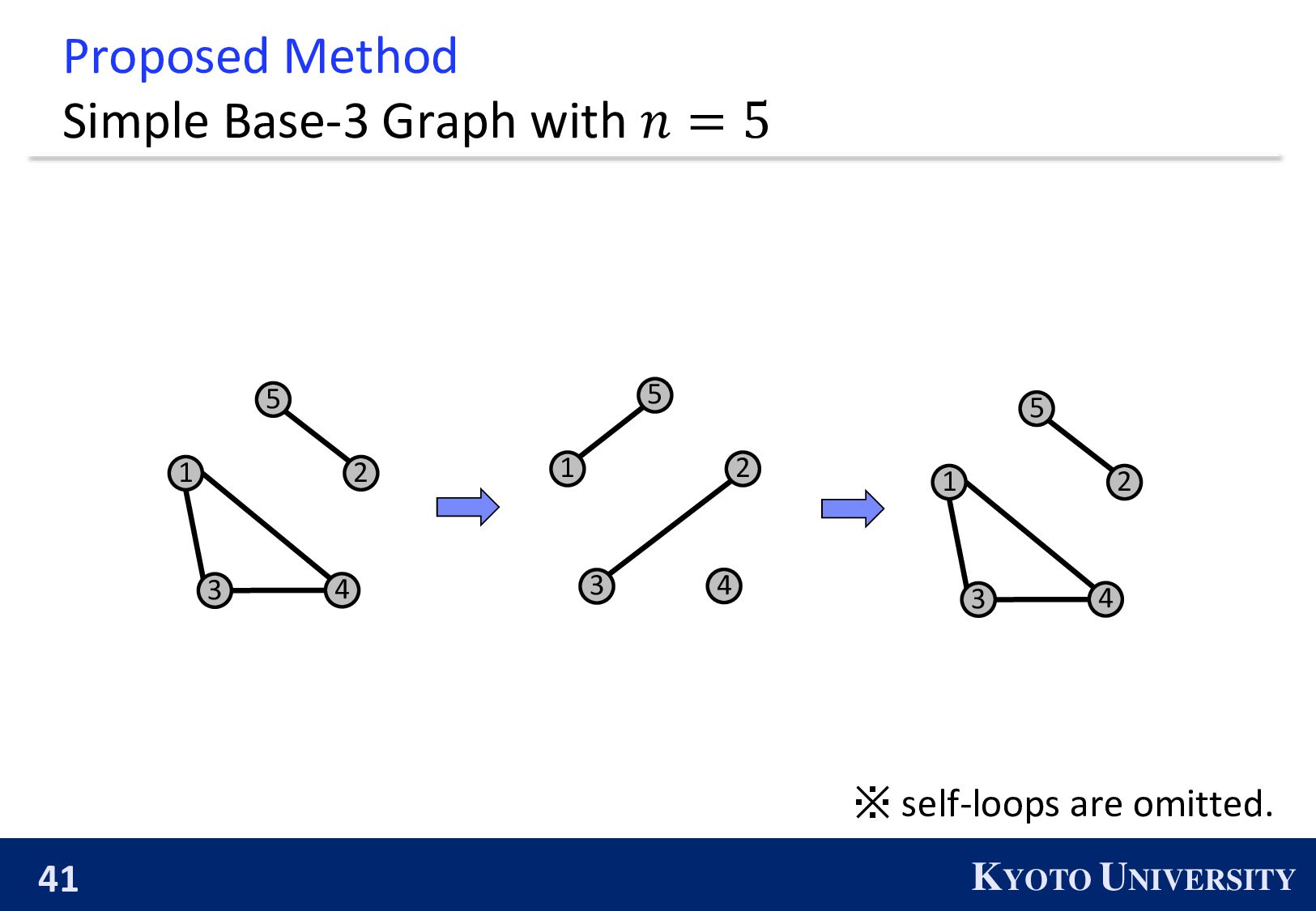
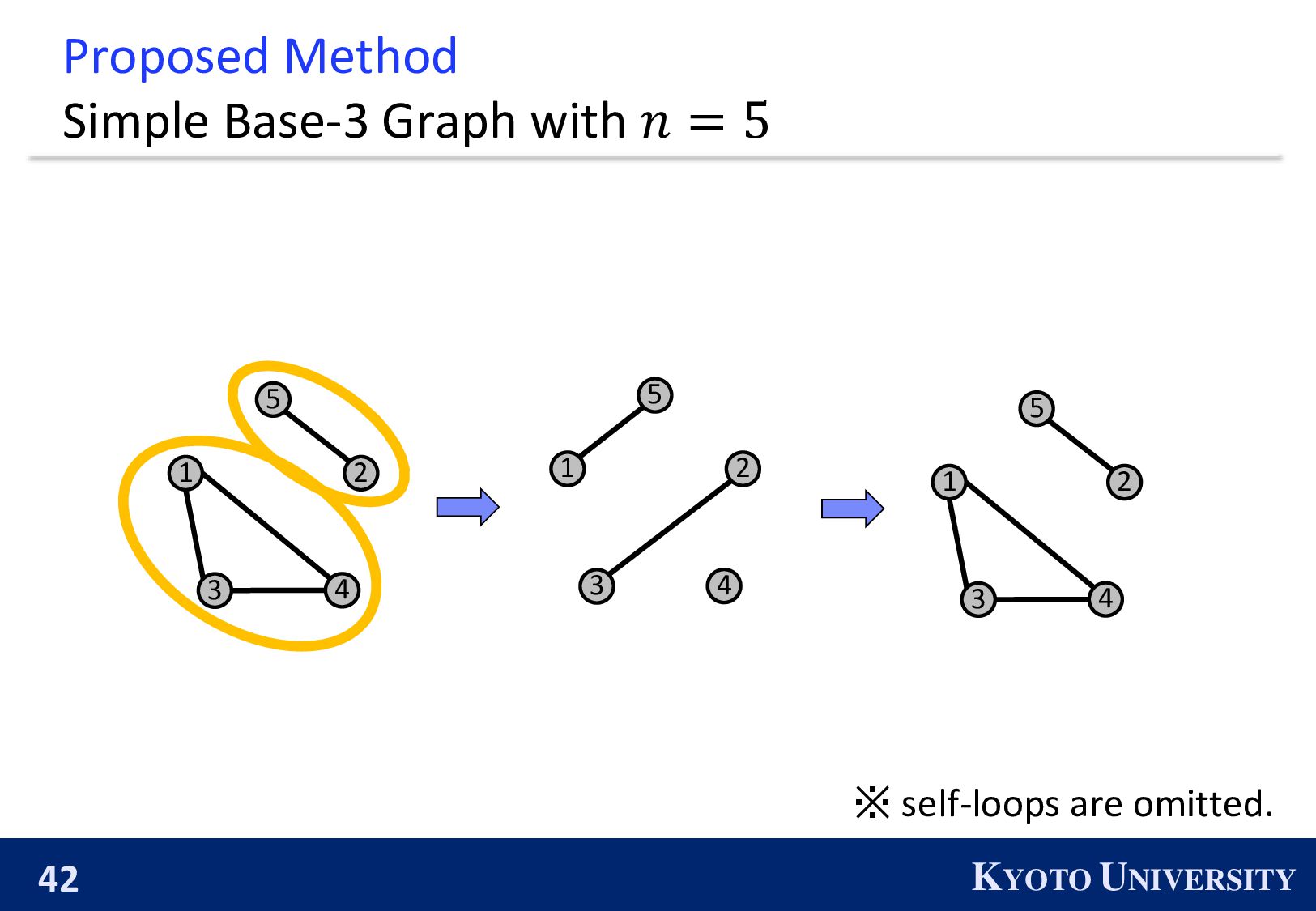
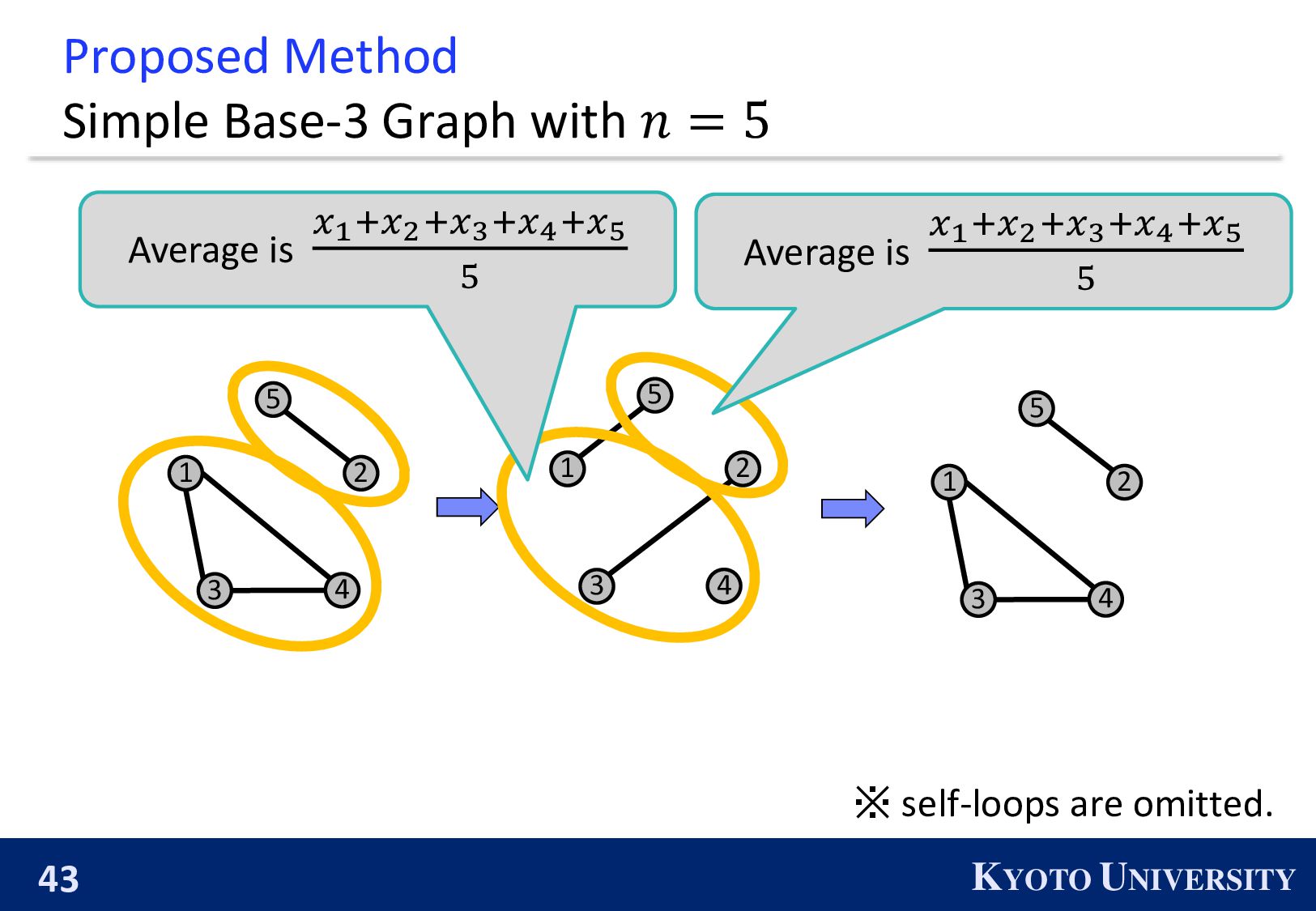
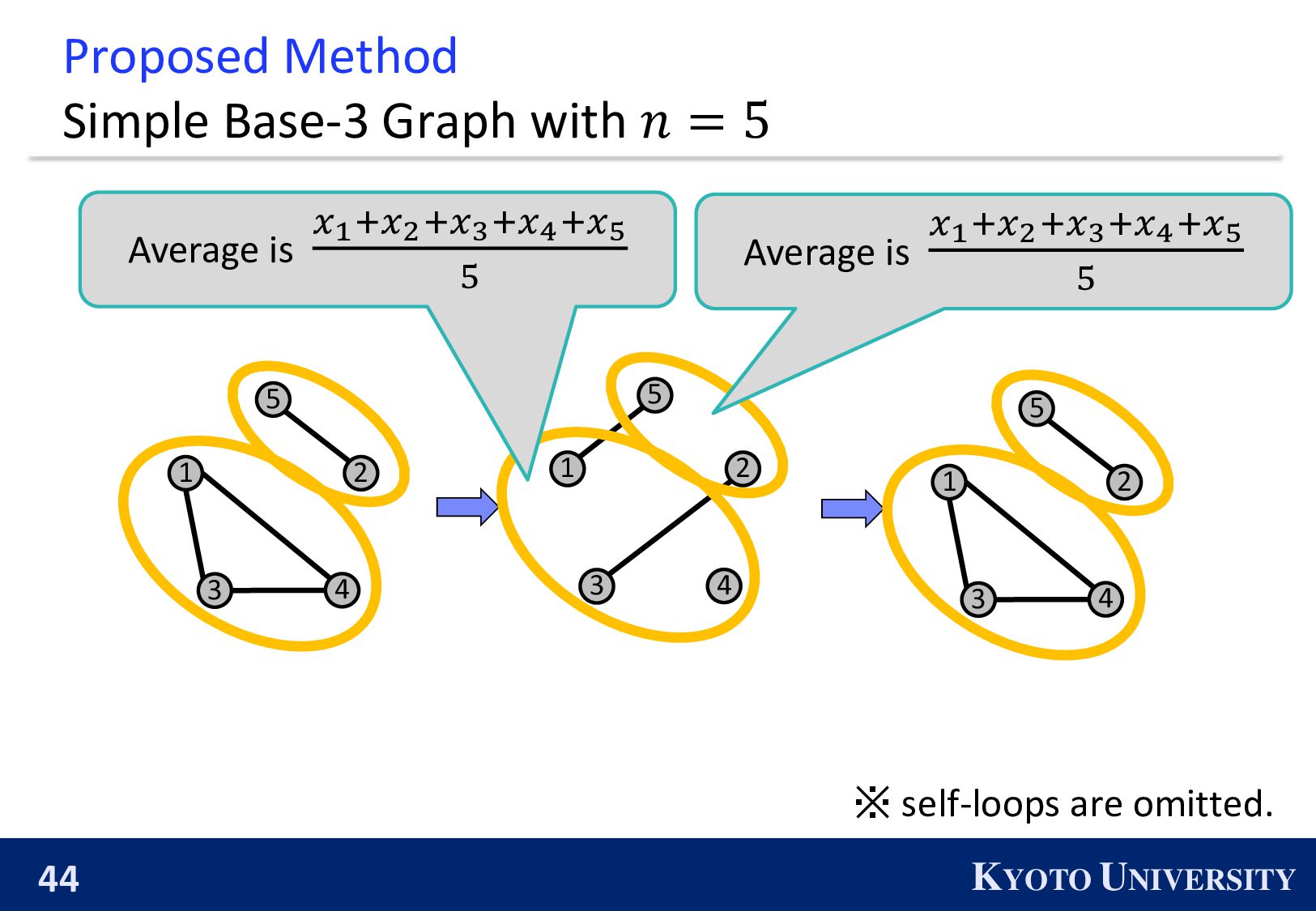
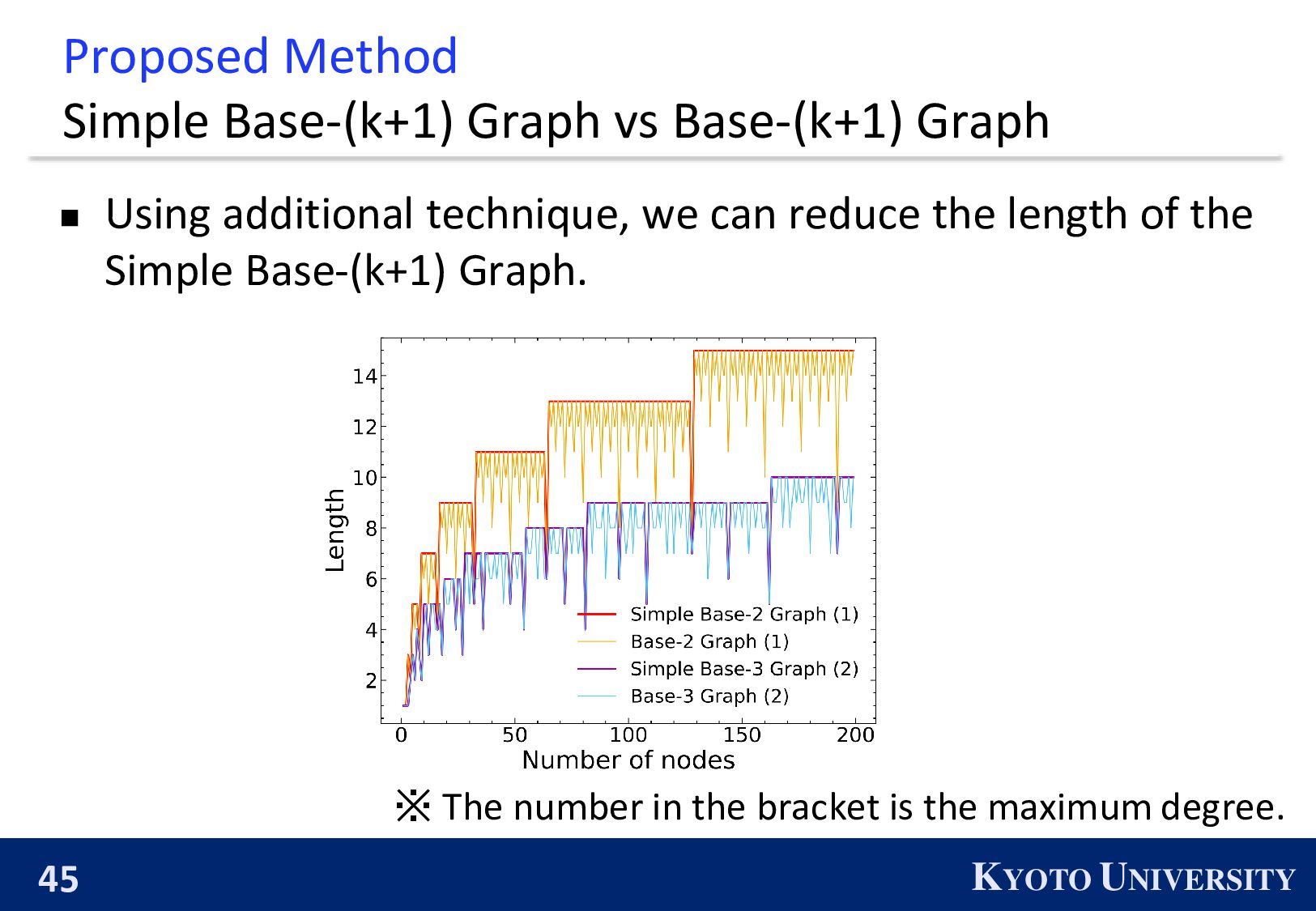
Simple Base-2 Graph: ◼ Its maximum degree is only 1. ◼ It is finite-time convergence for any 𝑛. Next, we propose the Simple Base-(k+1) Graph: ◼ Its maximum degree is 𝑘. ◼ It is finite-time convergence for any 𝑛.
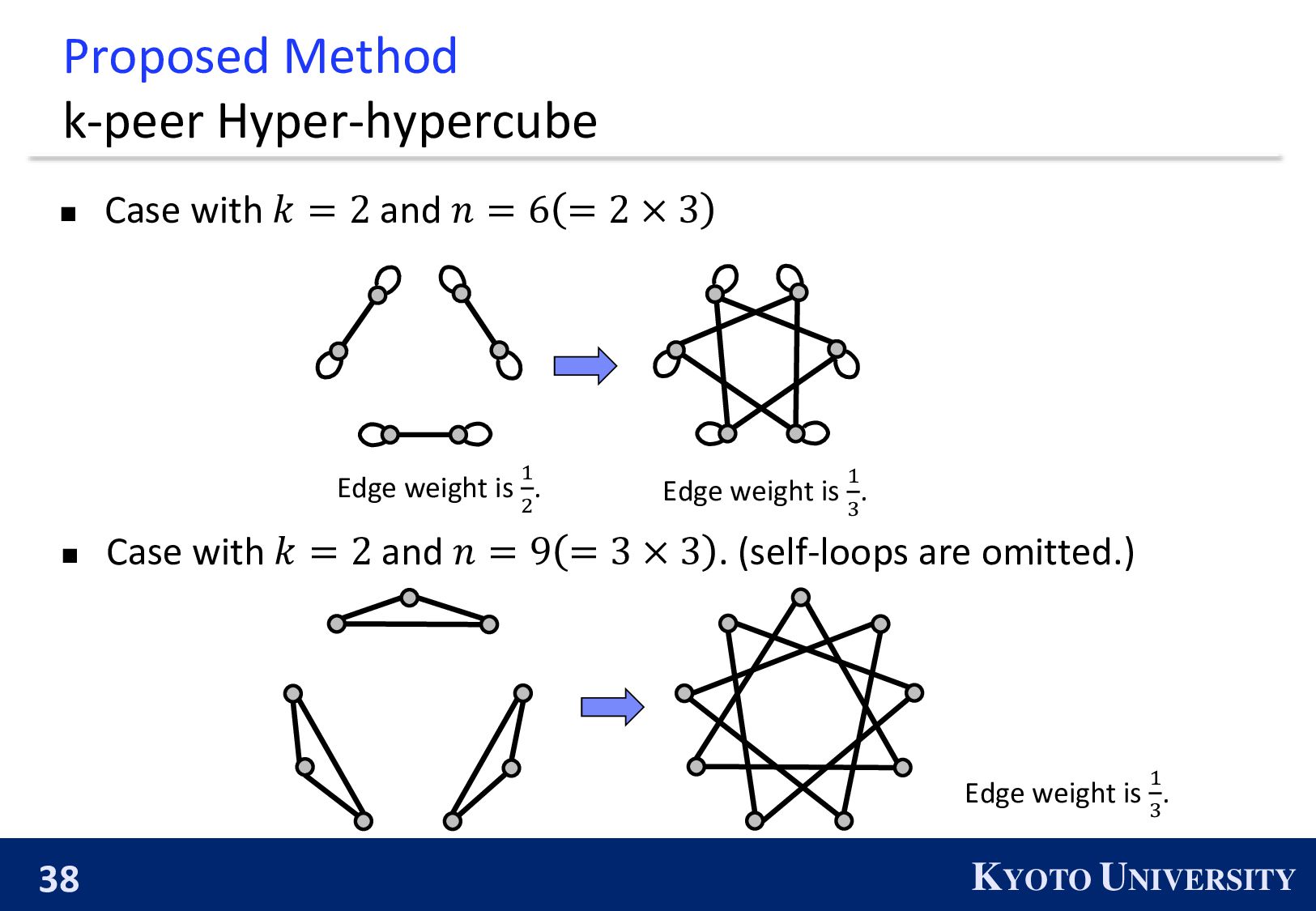
be constructed when 𝑛 is a power of 2. ◼ 𝑛 is a power of 2 ⇔ The primal factors of 𝑛 is not larger than 2. 1 2 3 4 2 4 1 3 We propose the k-peer Hyper-hypercube, which can be constructed when the primal factors of 𝑛 is not larger than 𝑘 + 1.
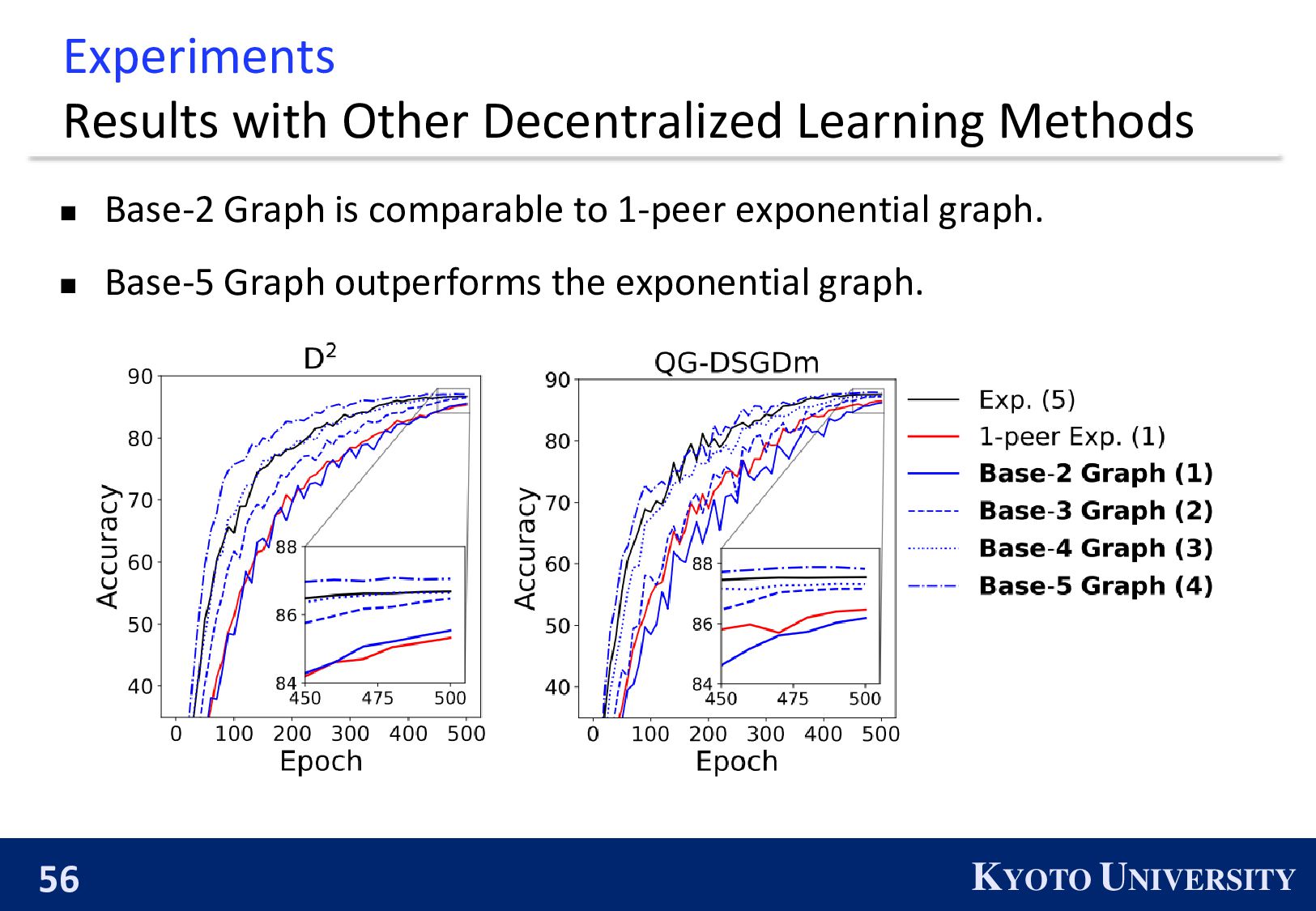
convergence for any 𝑛 and 𝑘. ◼ Theoretically: Faster convergence rate and fewer communication costs than the exp. graph. ◼ Experimentally: Reasonable balance between accuracy and communication efficiency.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}