In the summer 2025 Apple released their OS updates shipping with on-device LLMs. While quite limited, you can still get quite a bit of milage out of them. This talk is going through multiple patterns that allow to mitigate many shortcomings:
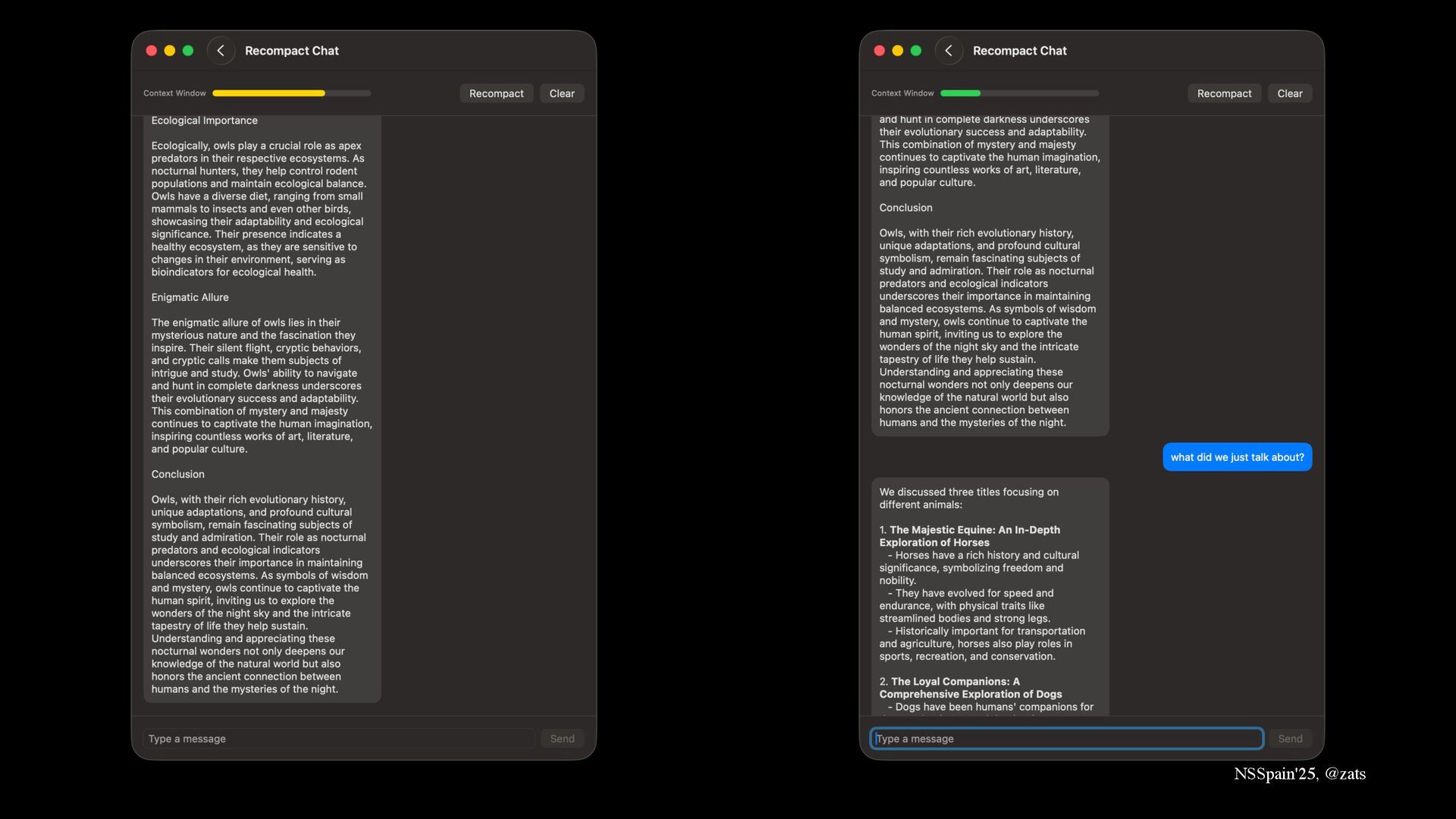
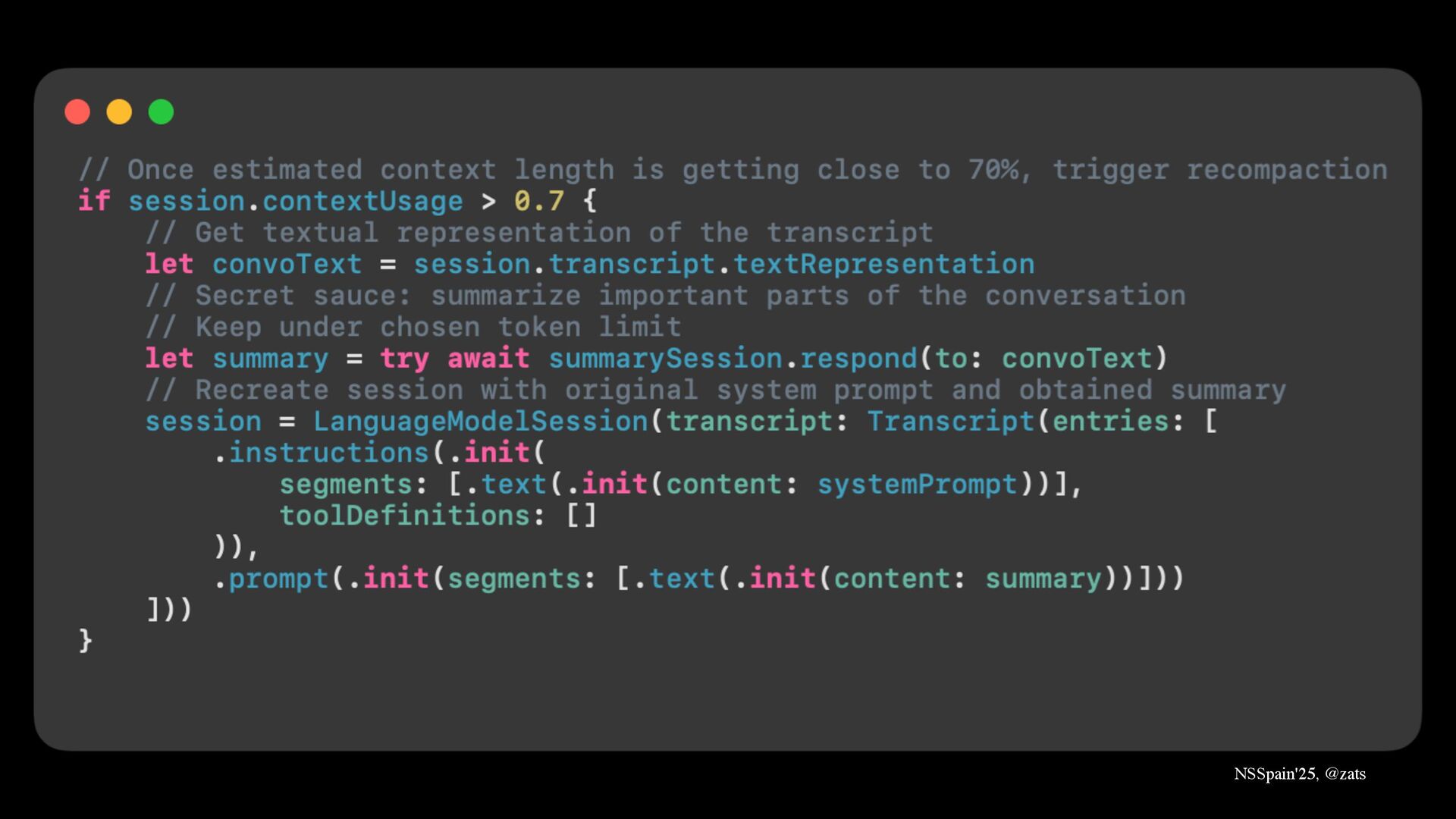
1. Short context window → Recompact chat history to create illusion of infinite chat.
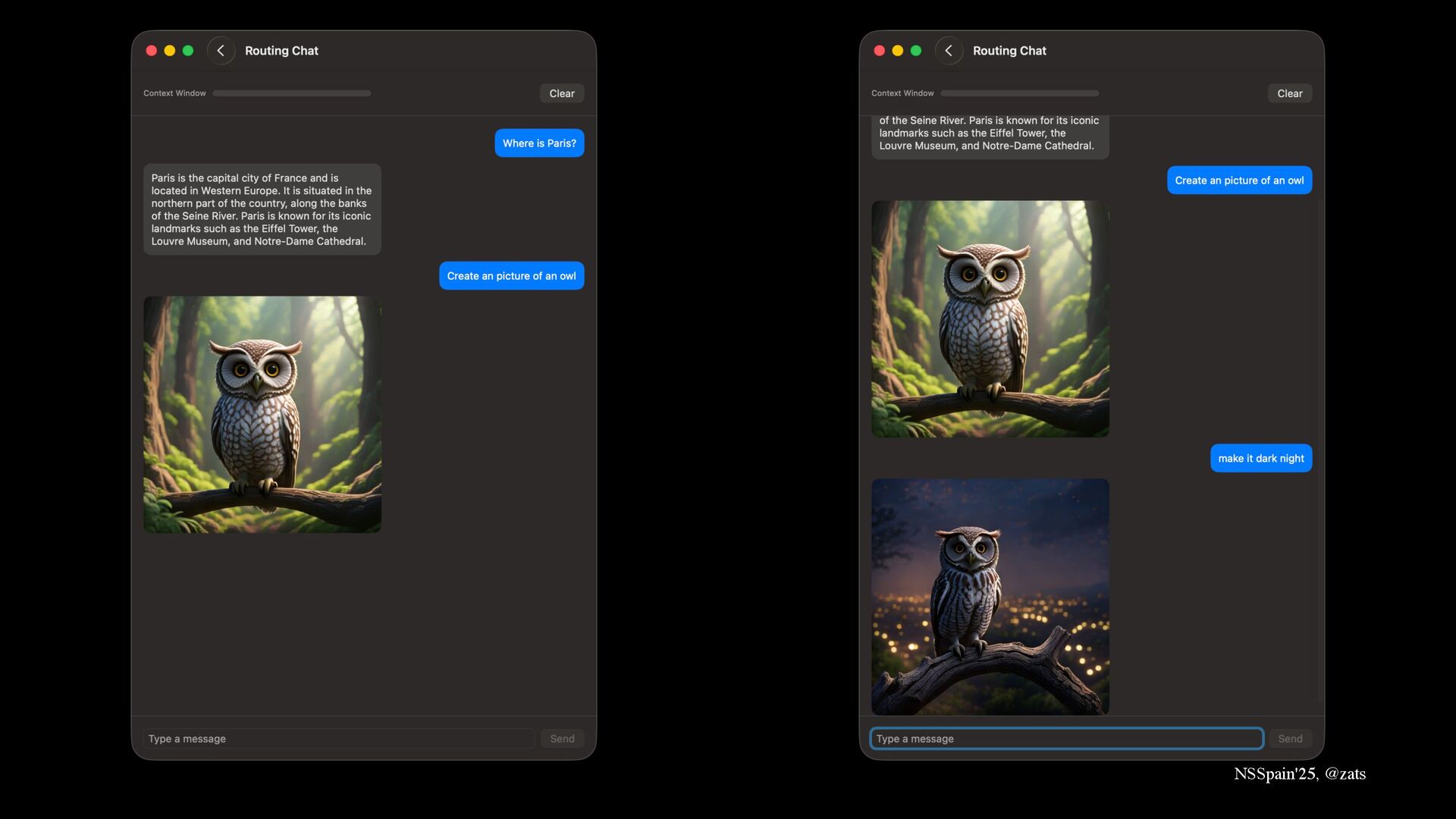
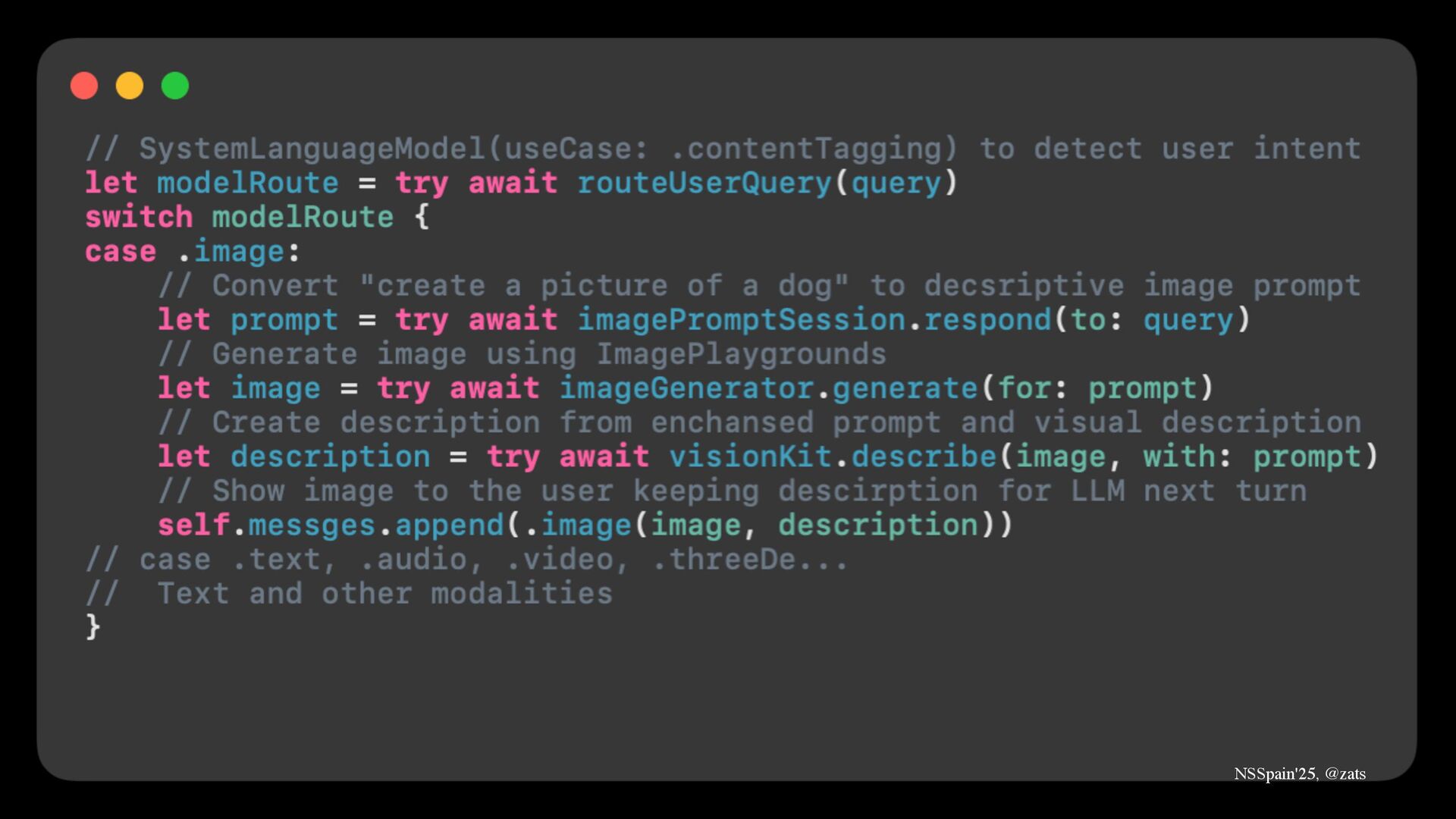
2. Routing → Make your own multimodal model without waiting for Apple to ship it.
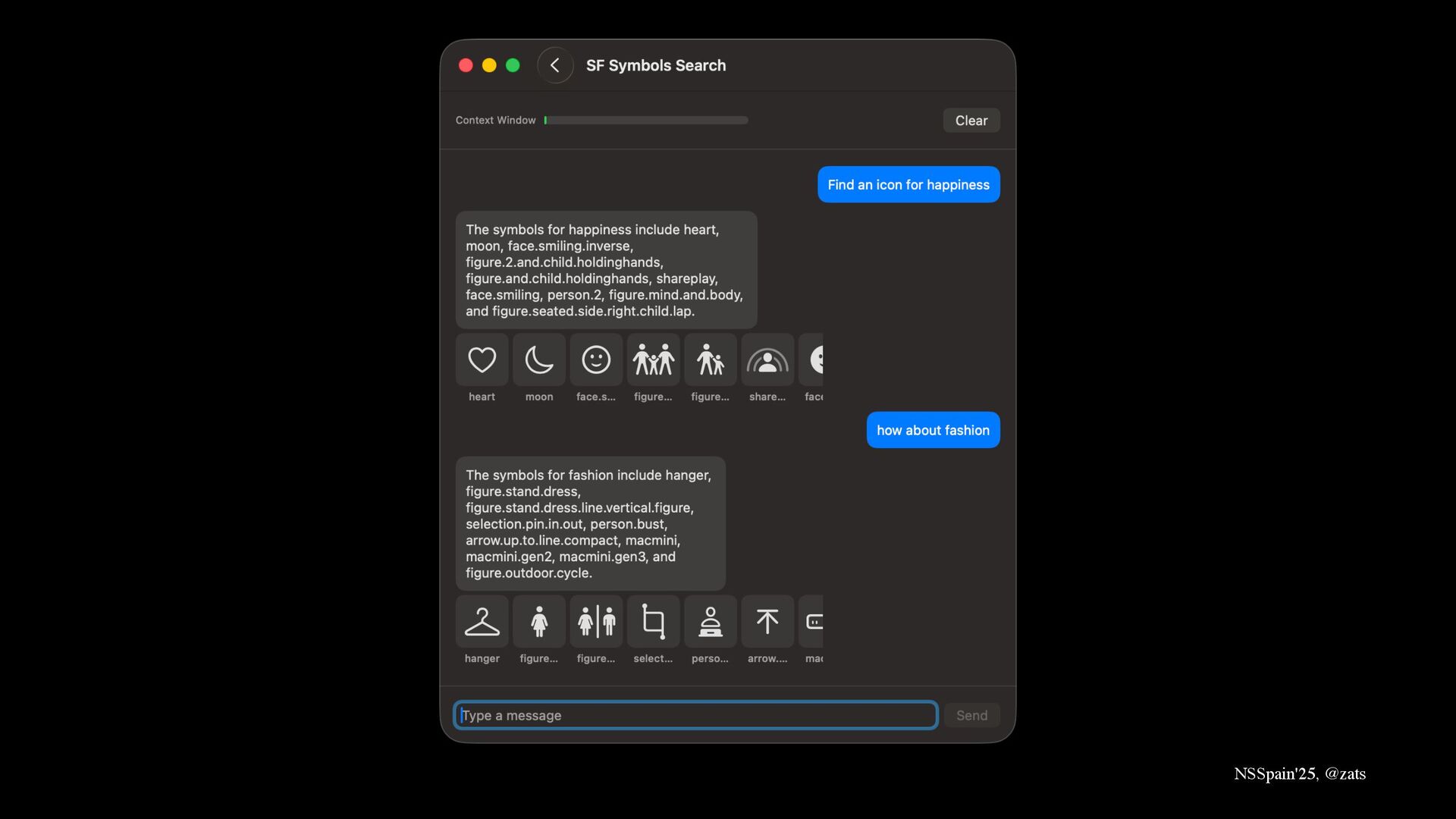
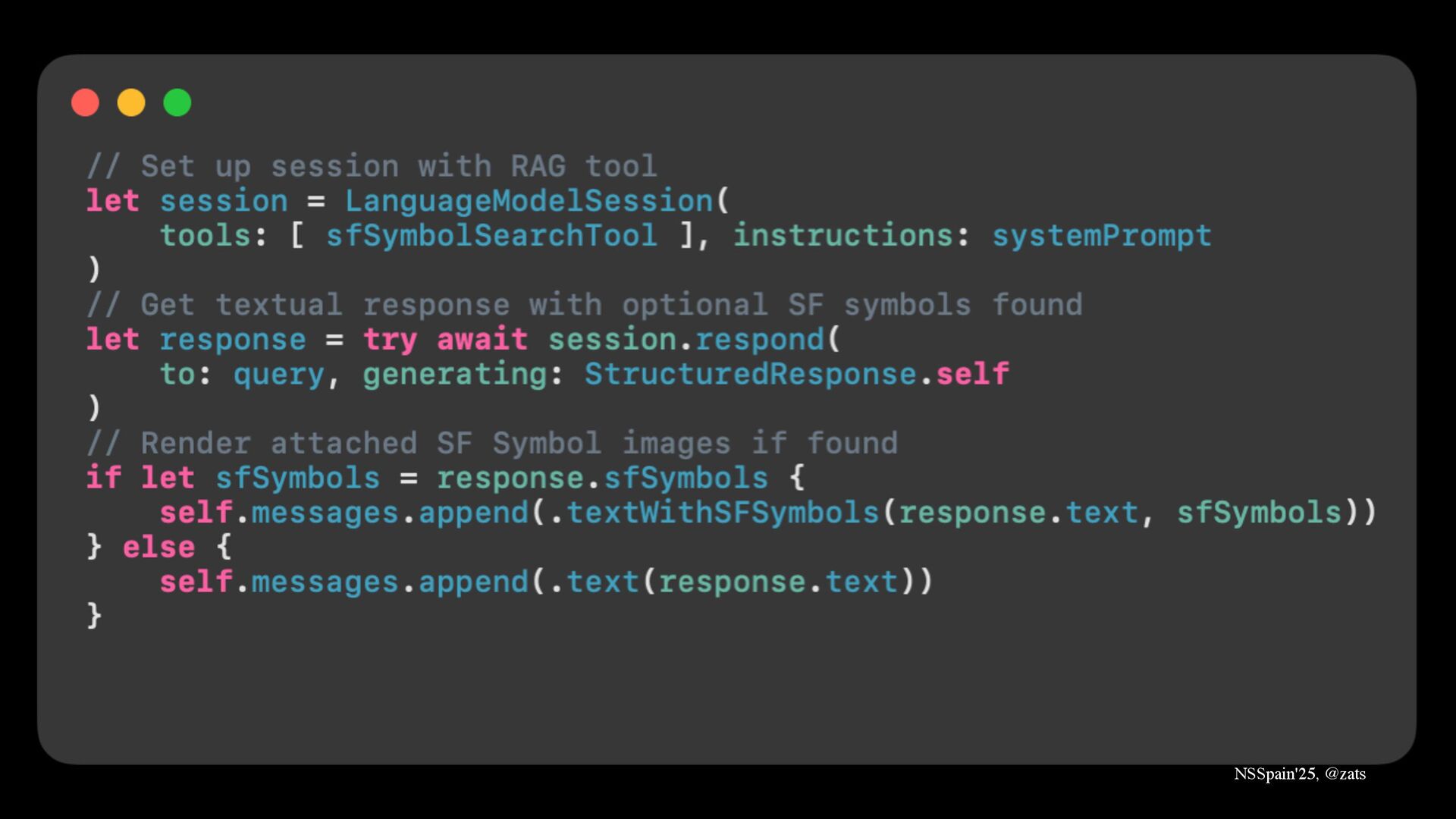
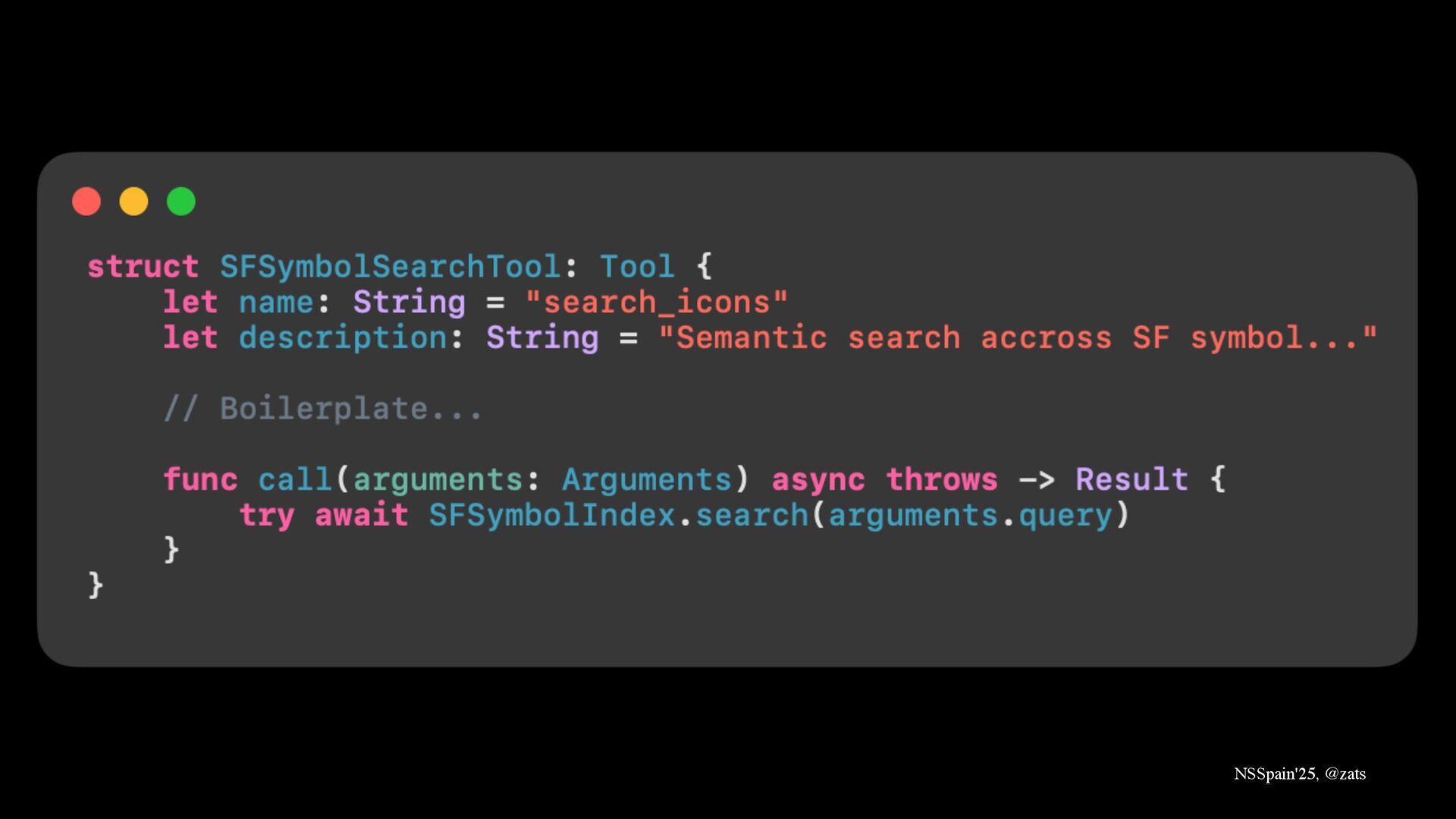
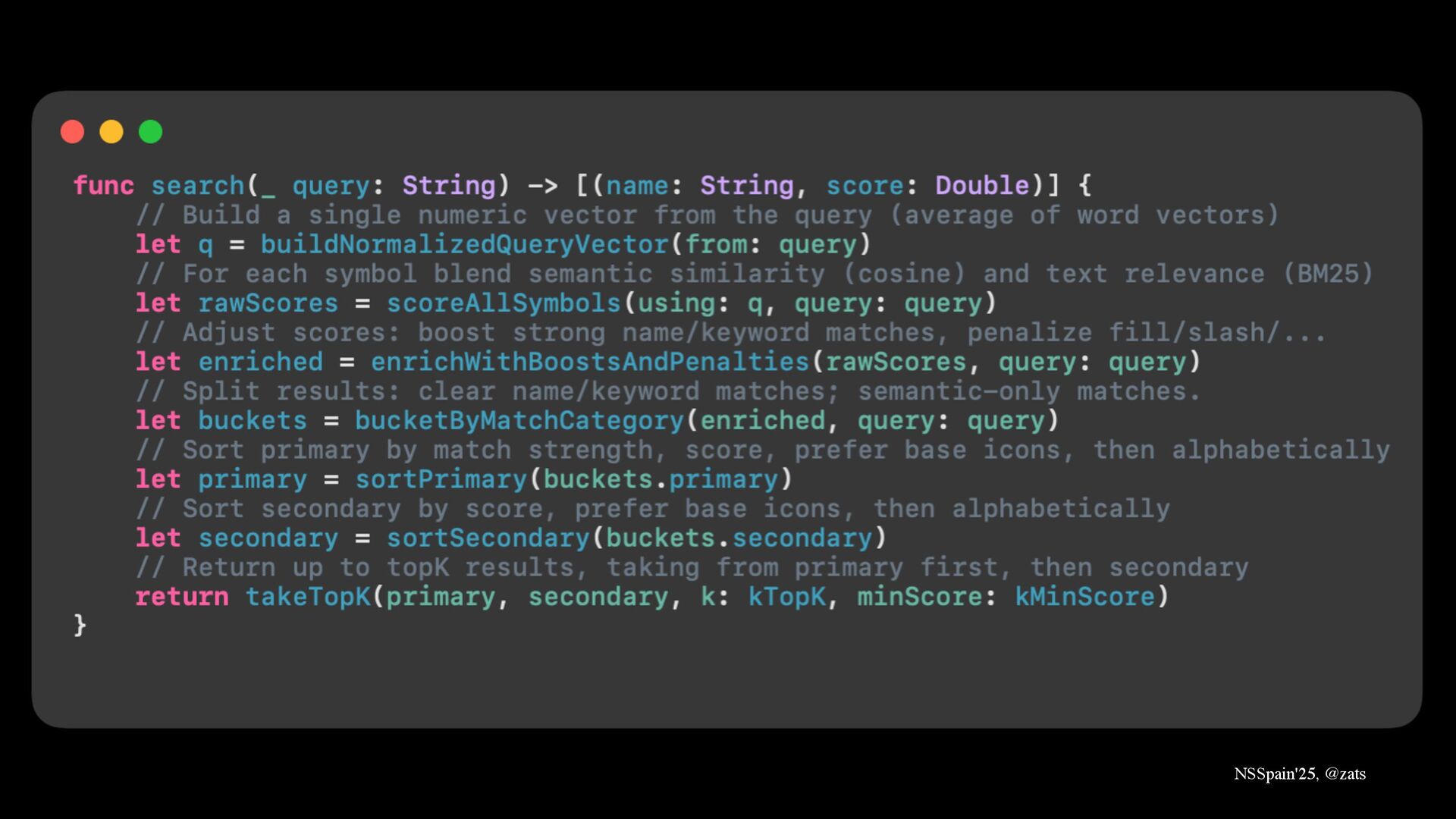
3. RAG → Ground model in your private knowledge.
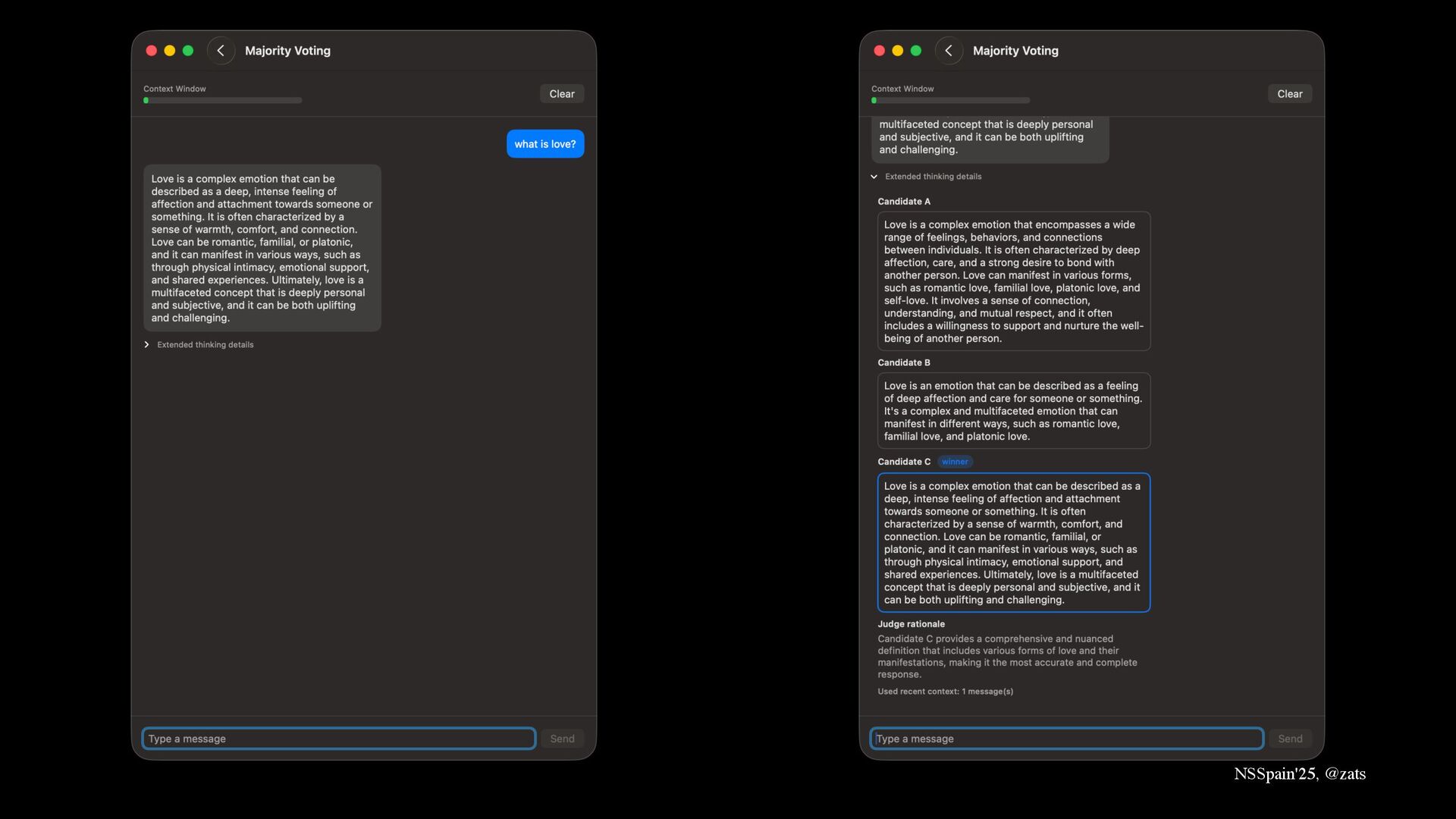
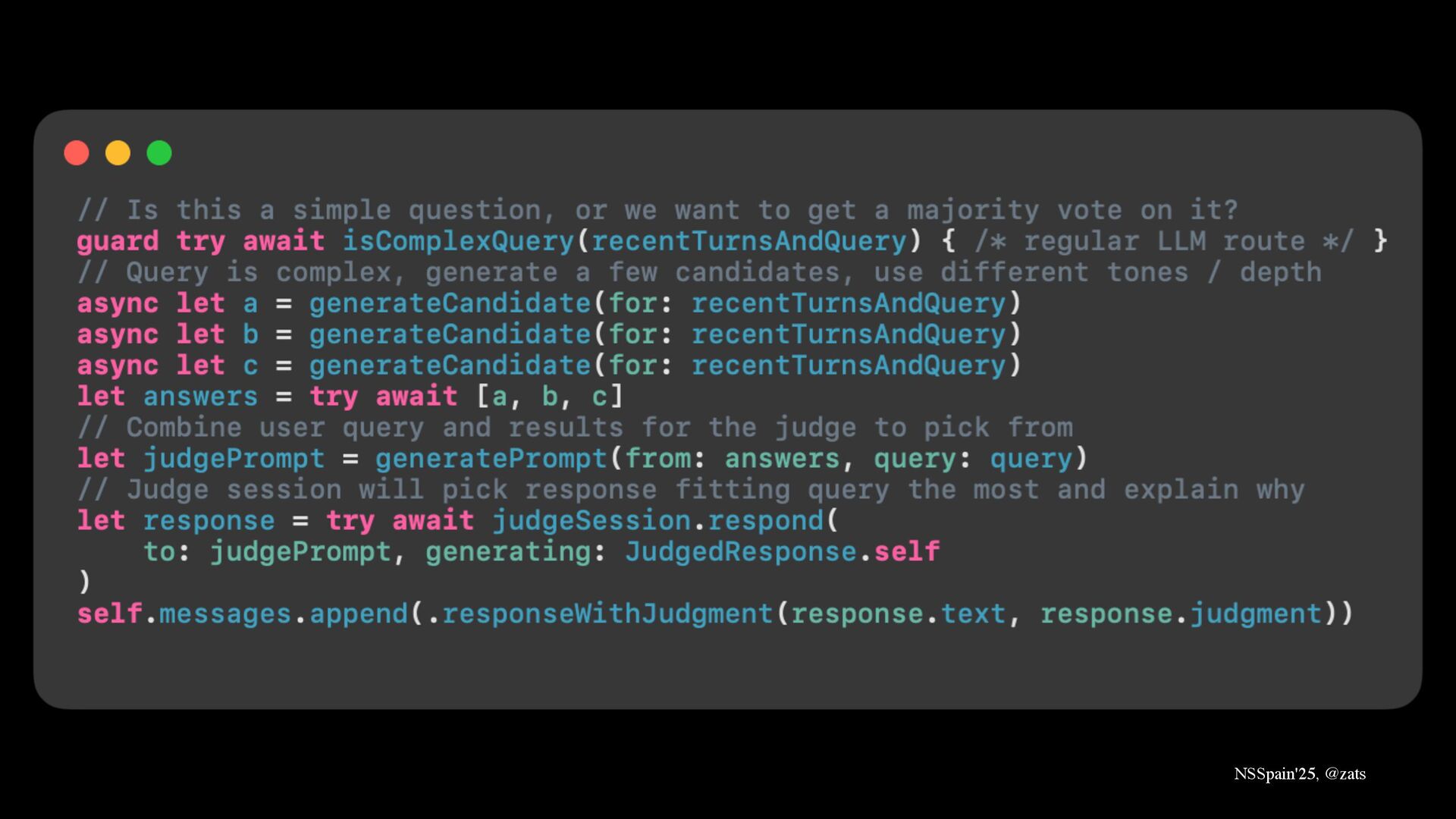
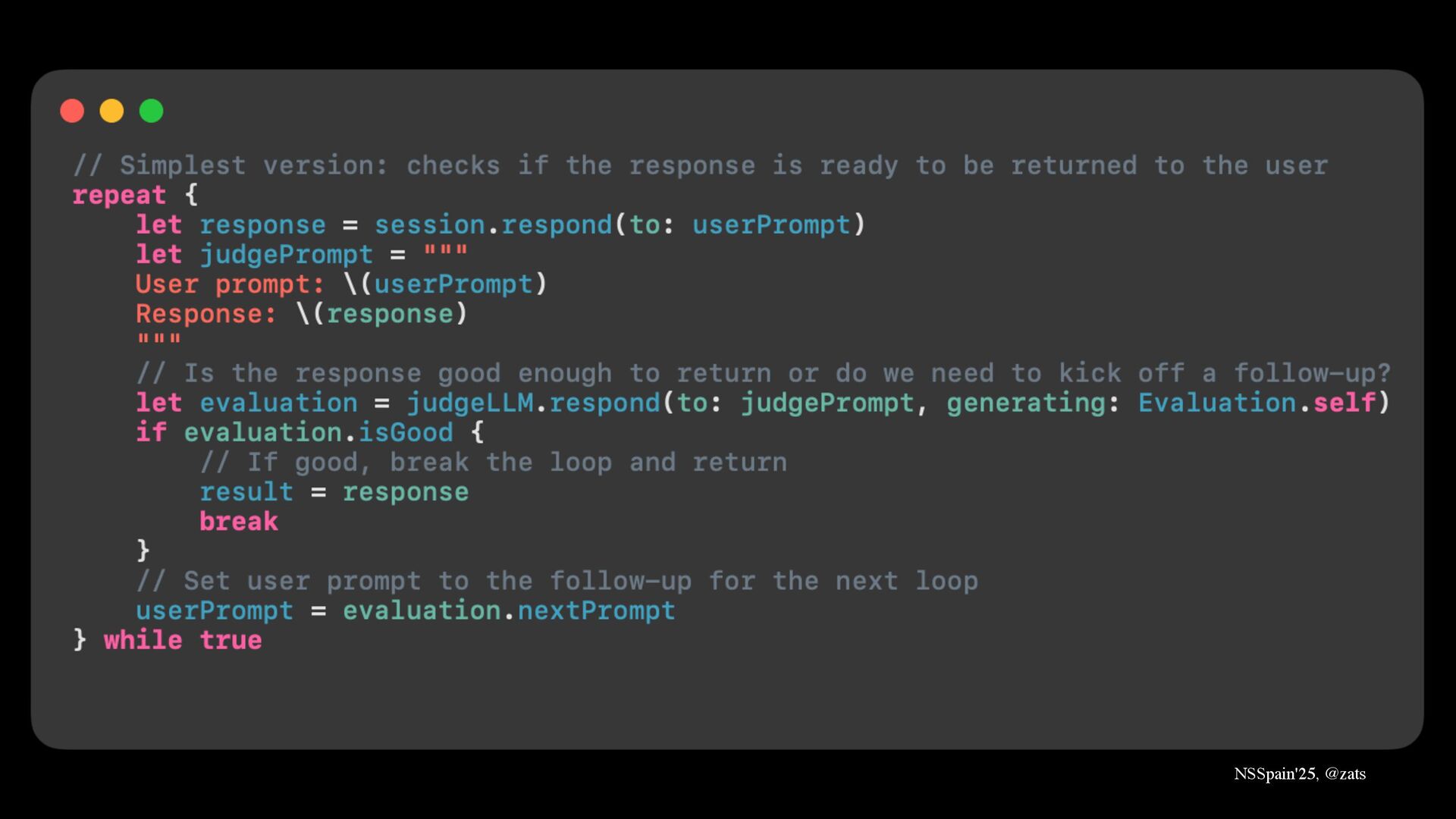
4. Majority voting → Improve quality of answers by choosing the best one with judge LLM.
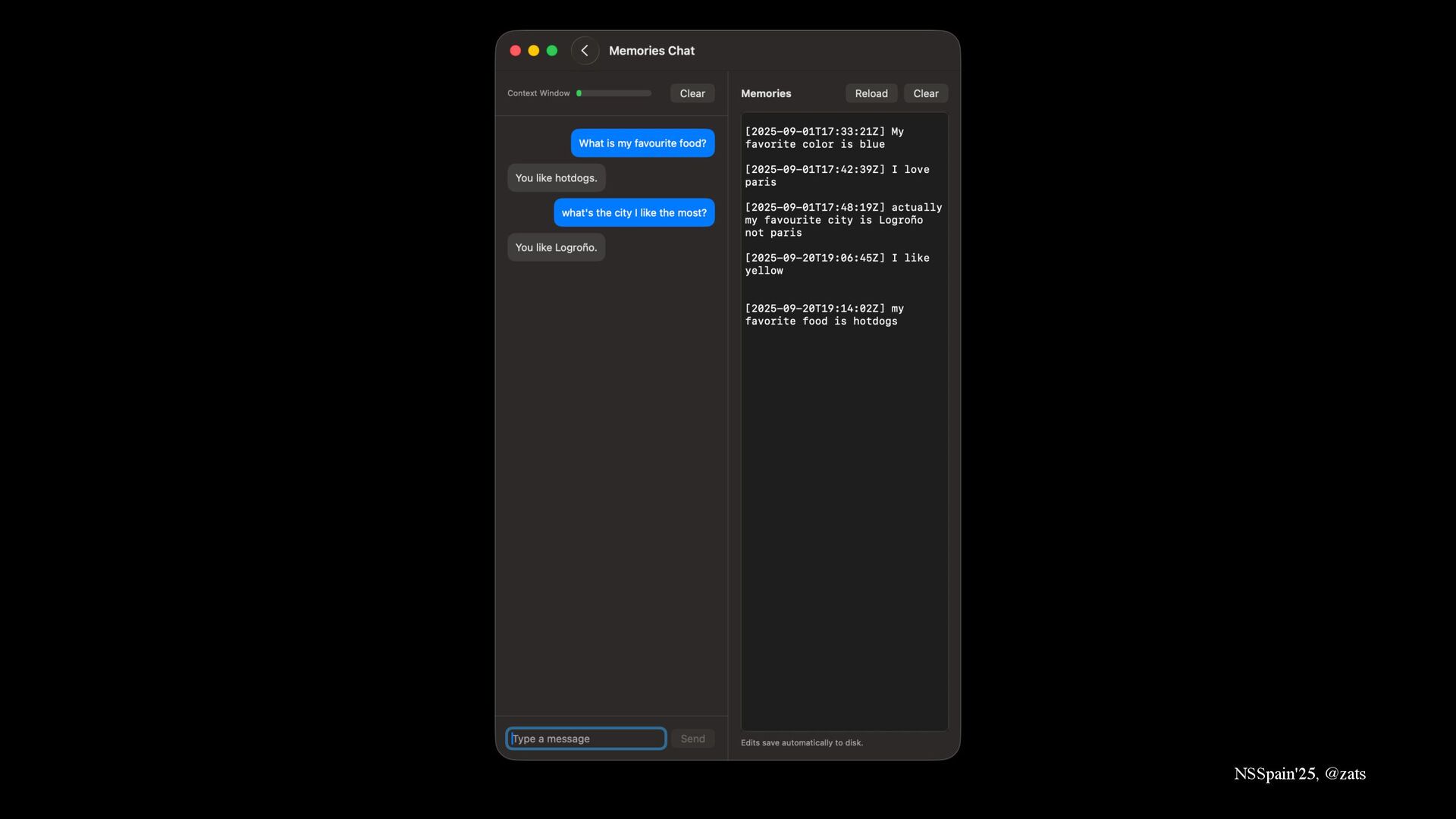
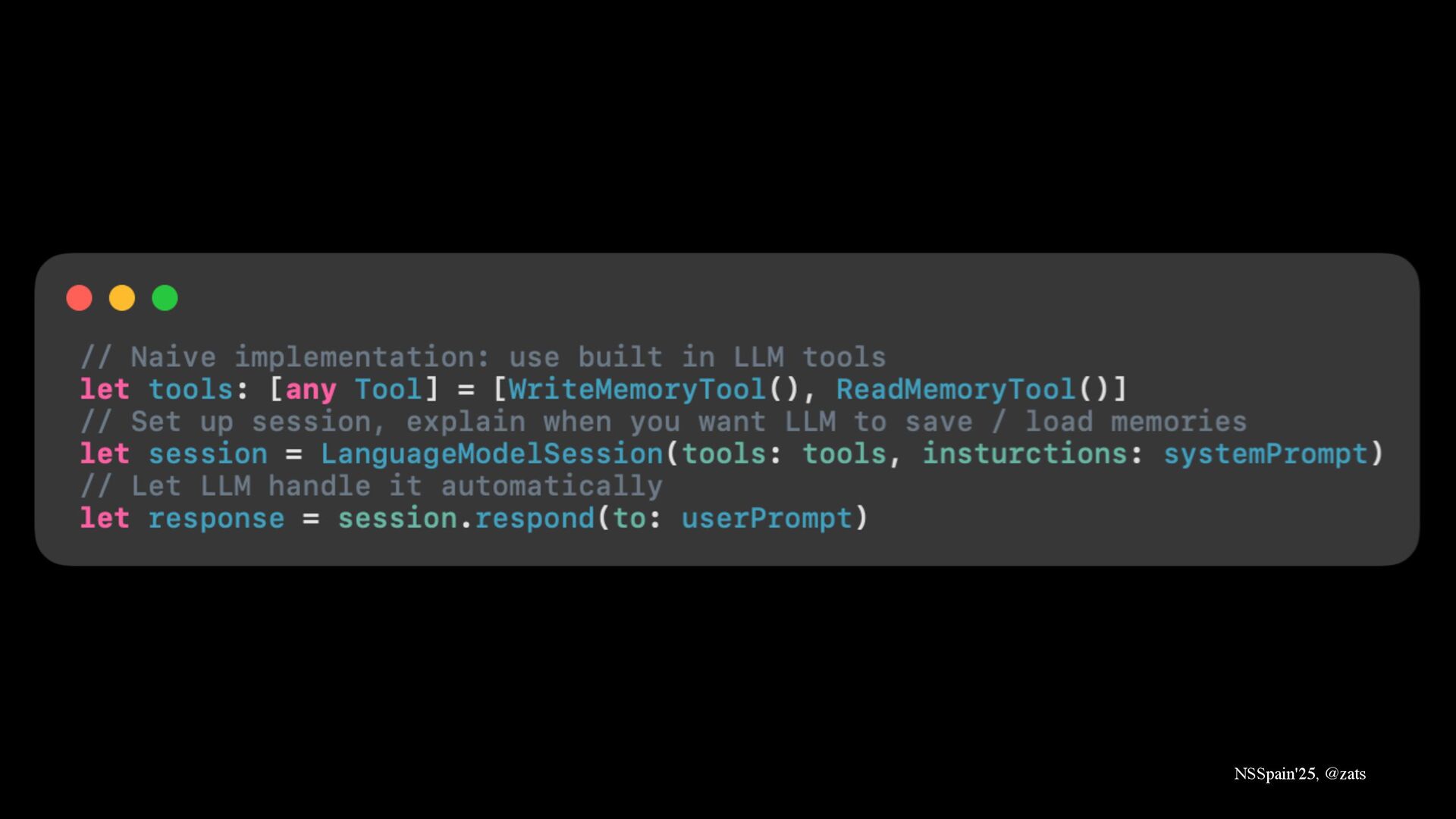
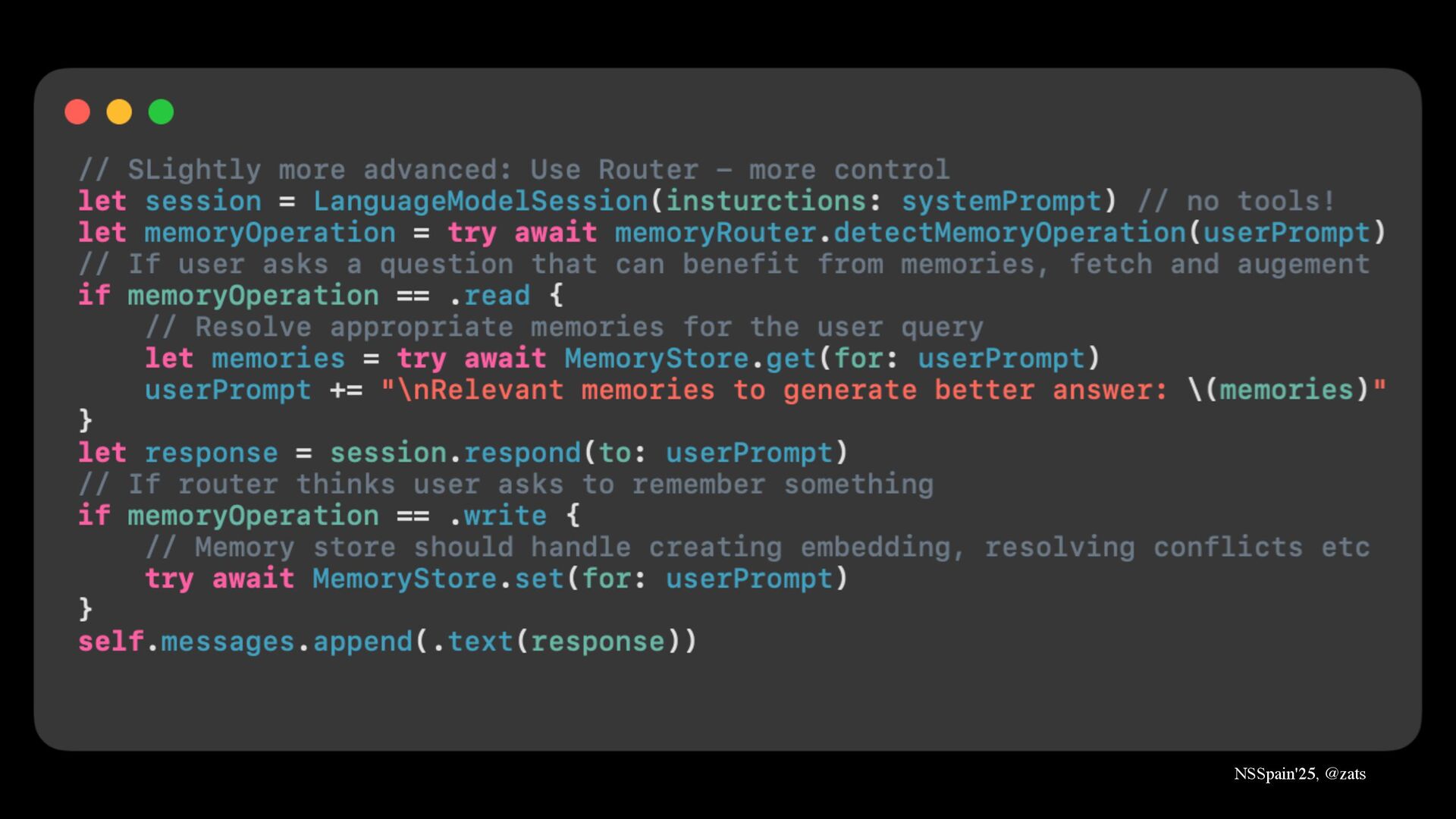
5. Memory → Preserve user information across sessions allowing LLM to read and write memories.
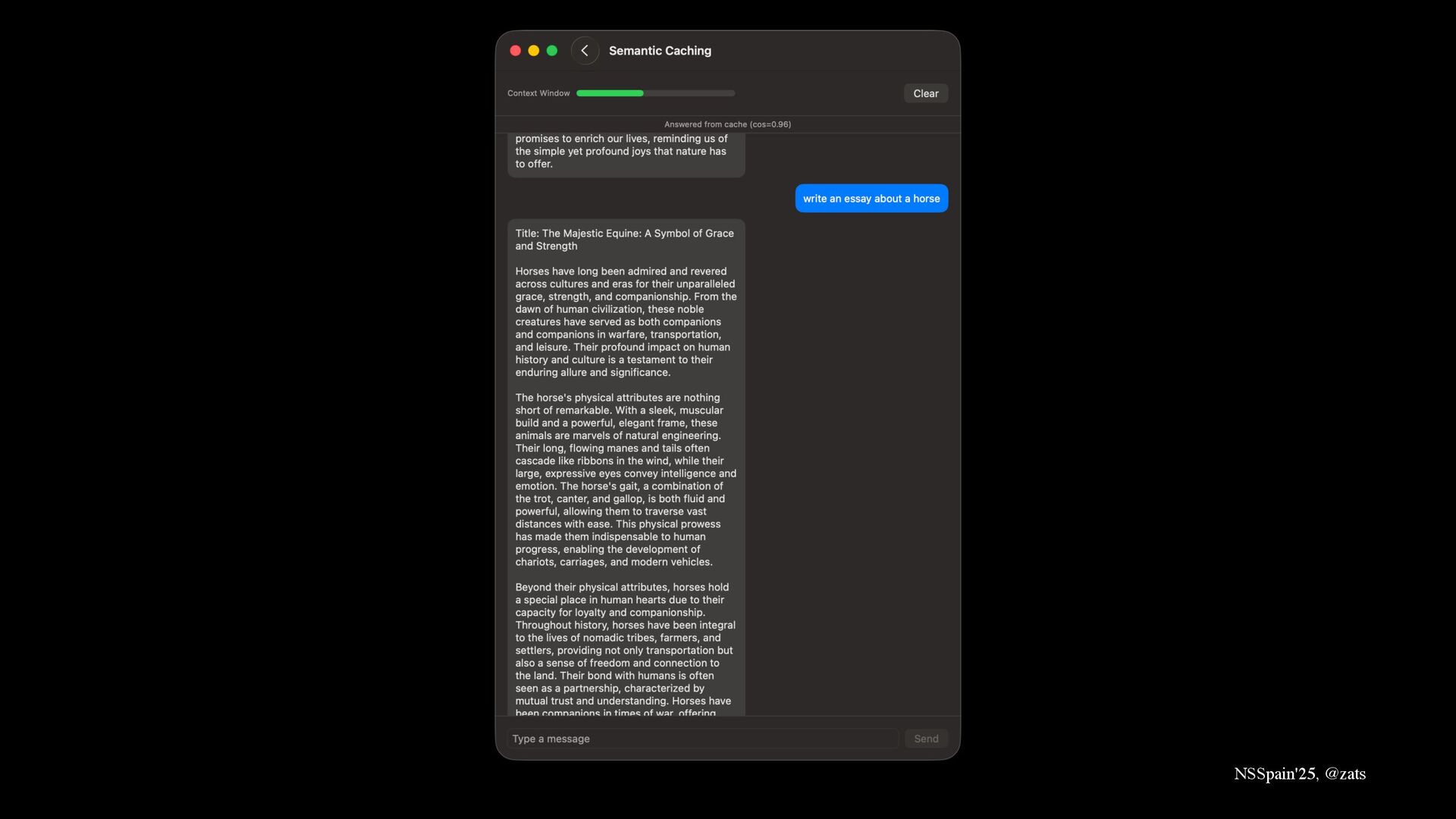
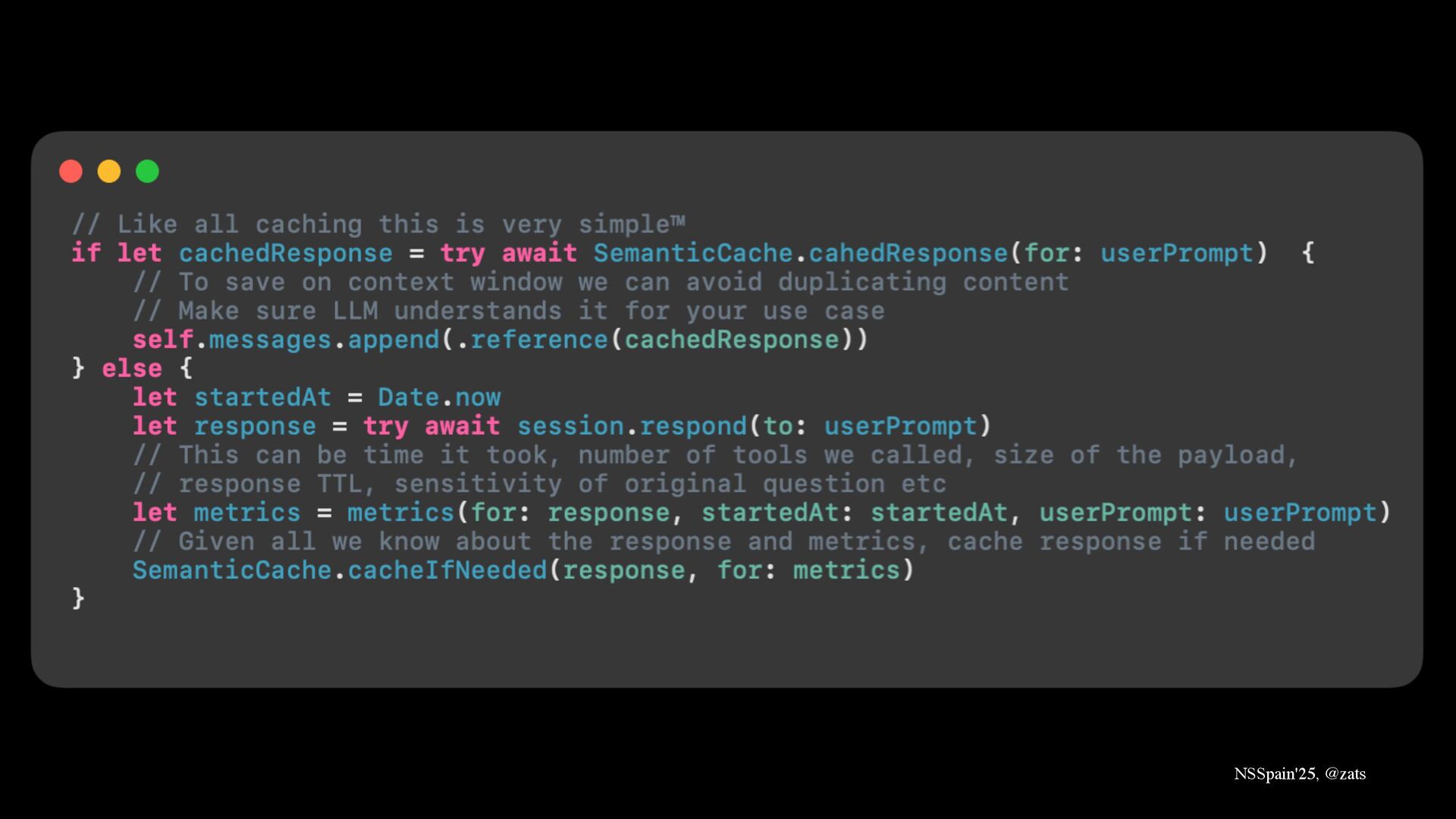
6. Semantic caching → Save cycles on generating expensive content.
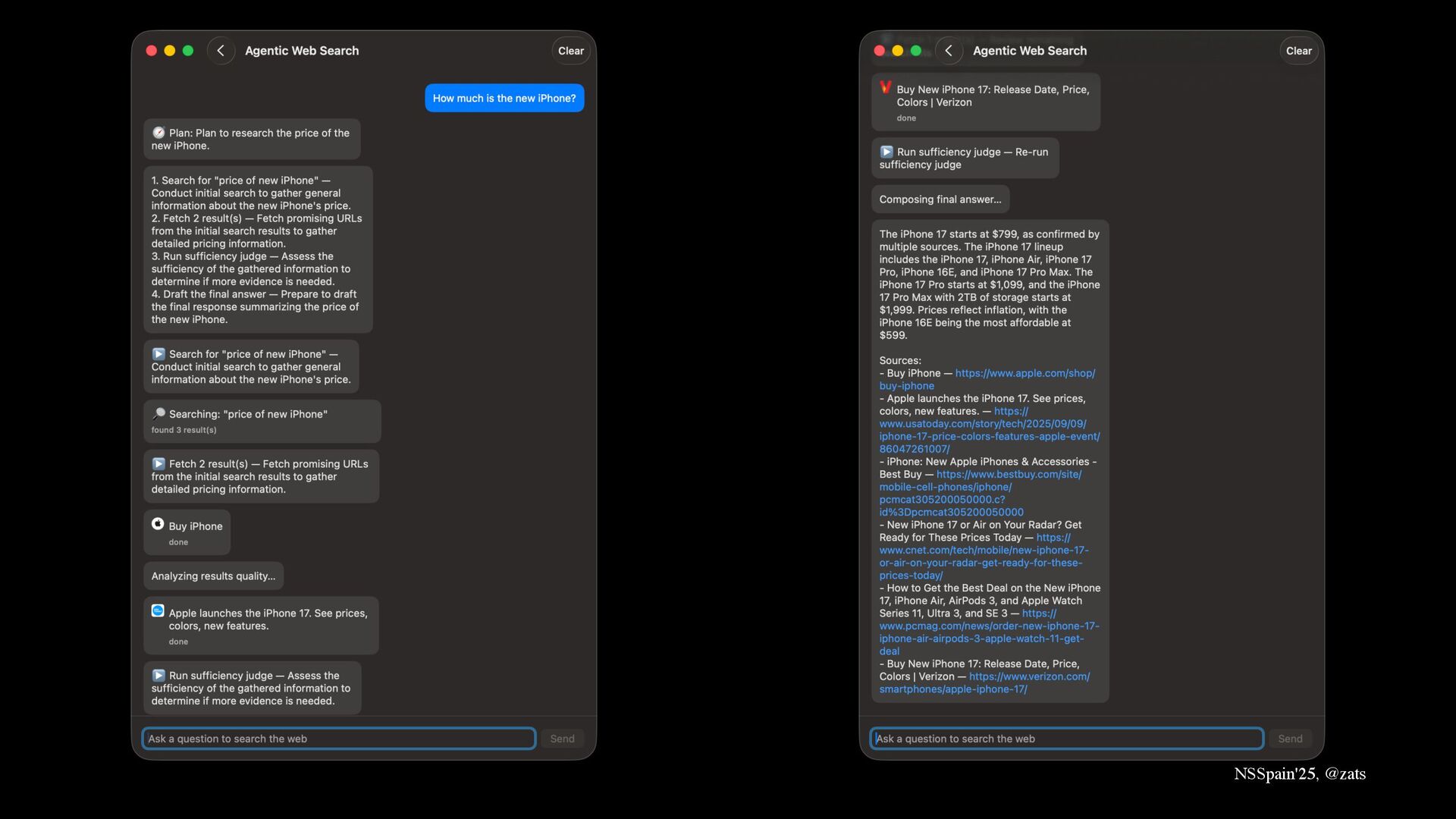
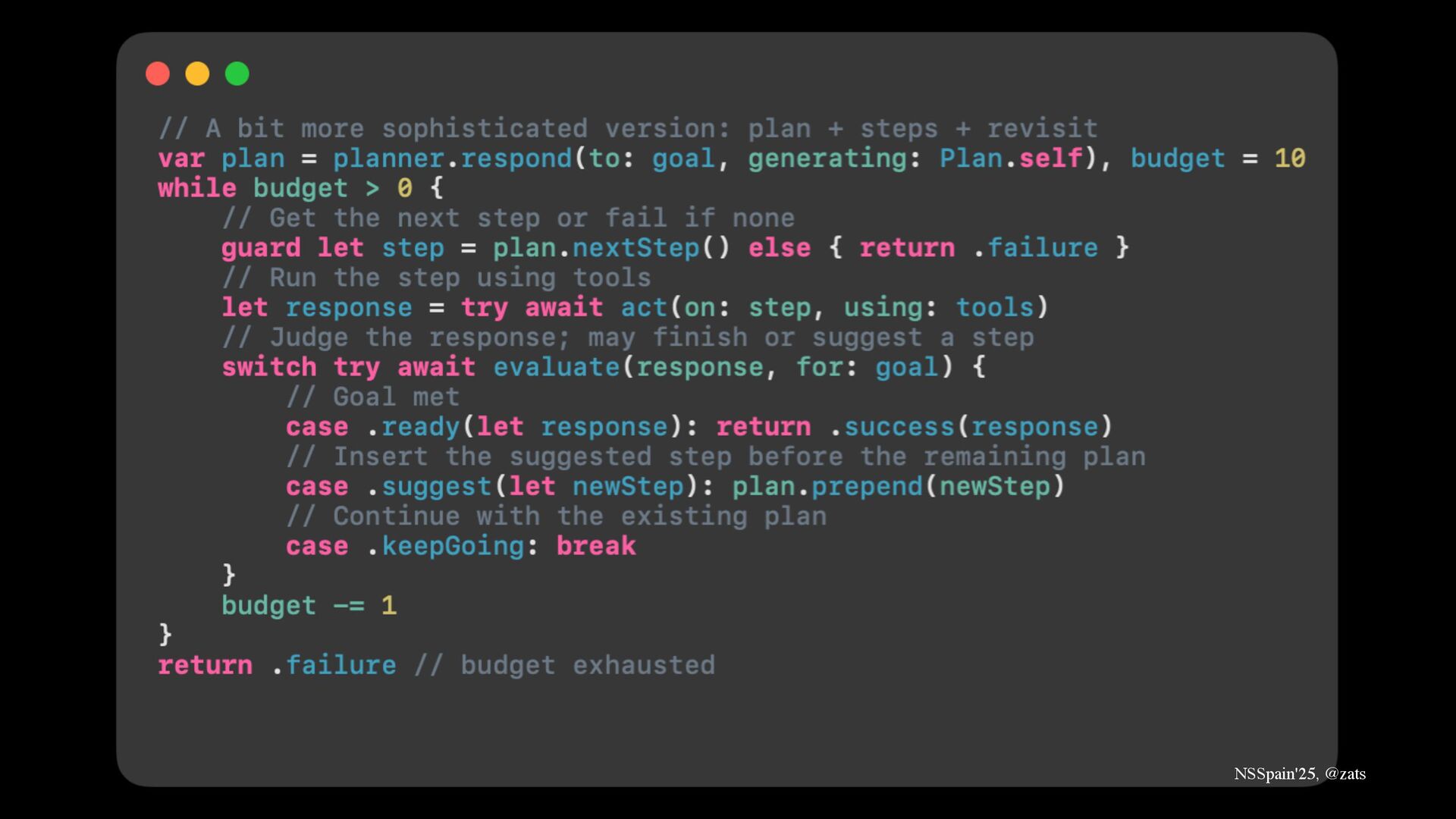
7. Agentic setup → Use Apple Foundation Models to build Perplexity-like agent searching internet for you.
Bonus:
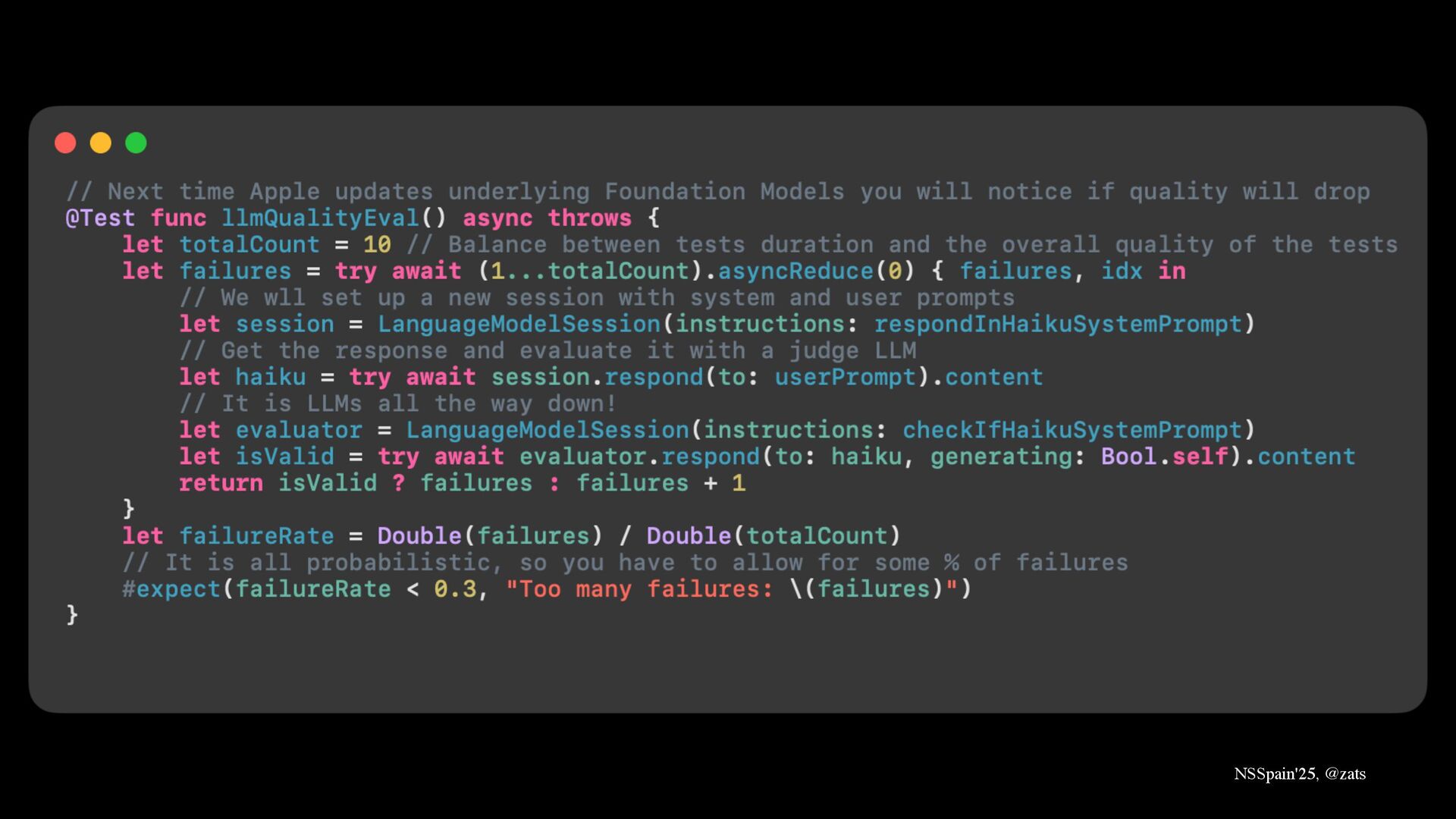
How to set up evals using Swift unit testing framework preventing sudden quality degradation if Apple updates Foundation Models
Source code for the companion app https://github.com/zats/LLMPatterns
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}