OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS Server Guest OS
do the same thing: distribute (balance) traffic between targets. Targets could be different tasks in a service, IP addresses, or EC2 instances in a cluster.
traffic between EC2 instances. Application Load Balancer: request level (7). great for microservices. Path-based HTTP/HTTPS routing (/web, /messages), content based routing, IP routing. Only in VPC. Network Load Balancer: connection level (4). Route to targets (EC2, containers, IPs). High throughput, low latency. Great for spiky traffic patterns. Requires no warming. Can assign elastic IP per subnet View the entire breakdown here: https://aws.amazon.com/elasticloadbalancing/details/#details)
ELB is what actually distributes the request. So, deployments and scheduling can be tweaked at that level: for example, changing the connection draining timeout can speed up deployments. • Secondly, your ELB can influence your resource management. For example, dynamic port allocation with ALB.
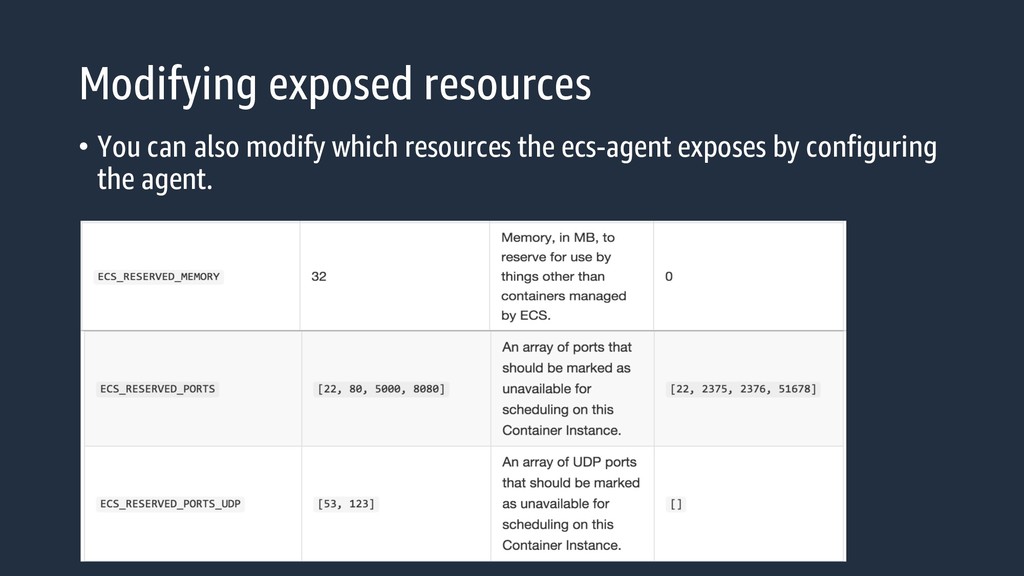
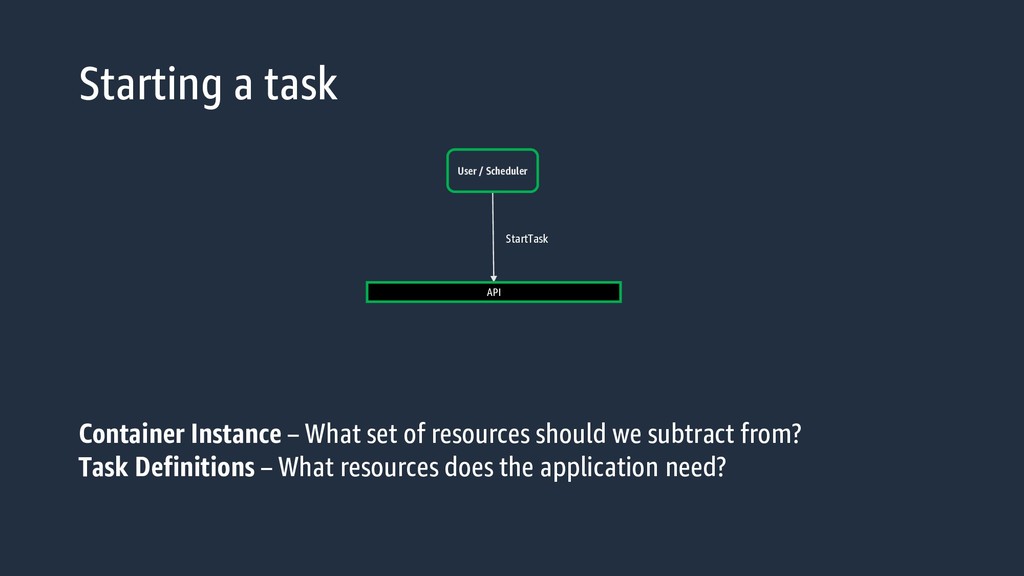
with the ECS cluster, it reports its total amount of resources register-container-instance --total-resources [ { “name” : “cpu”, “type” : “integerValue”, “integerValue” : 2048 }, … ]
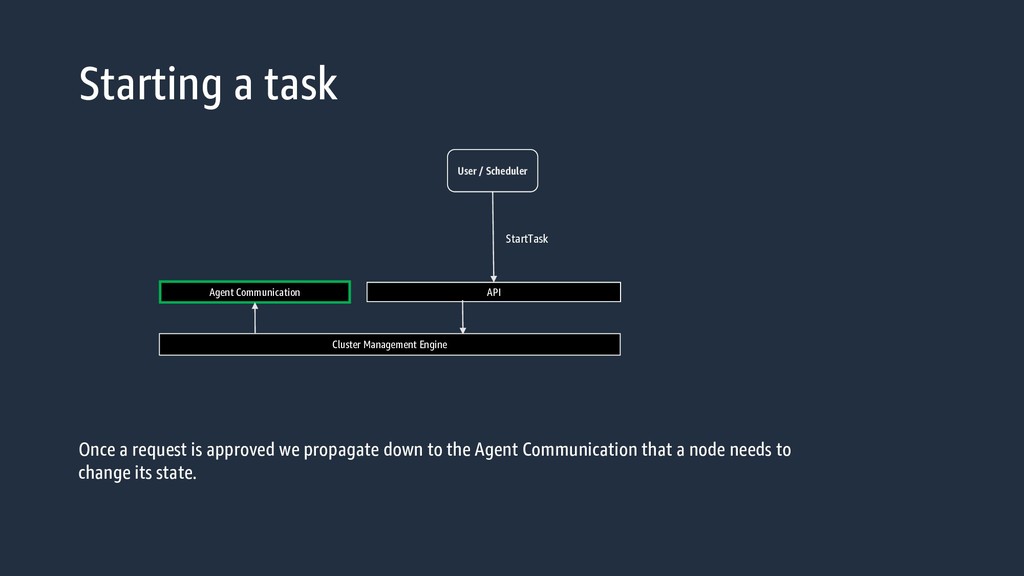
Engine We take that information, check against our Regional Cluster Management Engine, and either Approve or reject the request. The Cluster Management Engine has been designed to provide distributed transactions with Availability Zone isolation. So even if there is an issue in one Availability Zone you will continue to be able to schedule to your cluster.
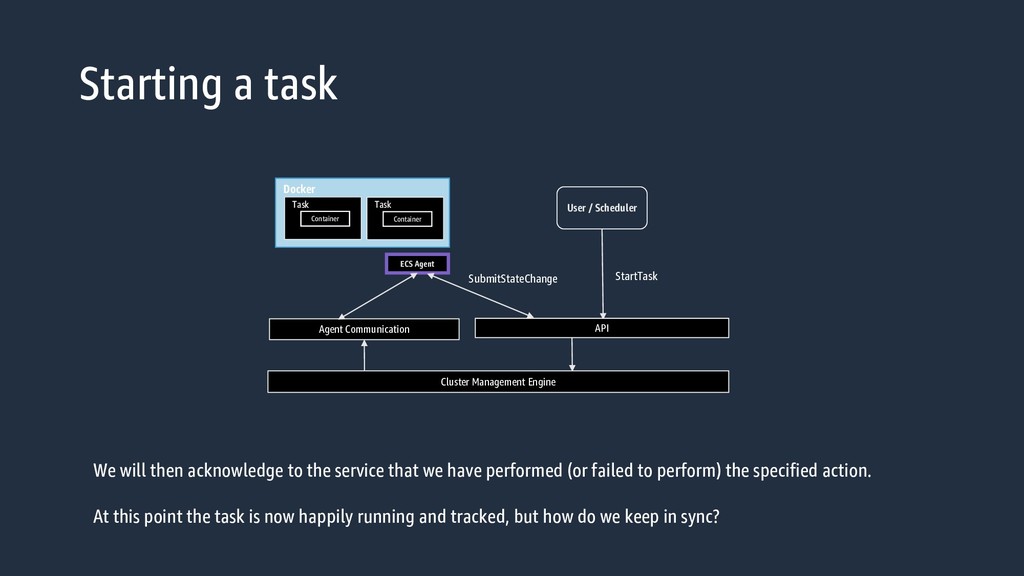
Engine Agent Communication Docker Container Instance ECS Agent Task Container WebSocket The Agent Communication Service will push this information down to the Websocket that the container instance opened.
Task Container ECS Agent Task Container SubmitStateChange API Cluster Management Engine We will then acknowledge to the service that we have performed (or failed to perform) the specified action. At this point the task is now happily running and tracked, but how do we keep in sync?
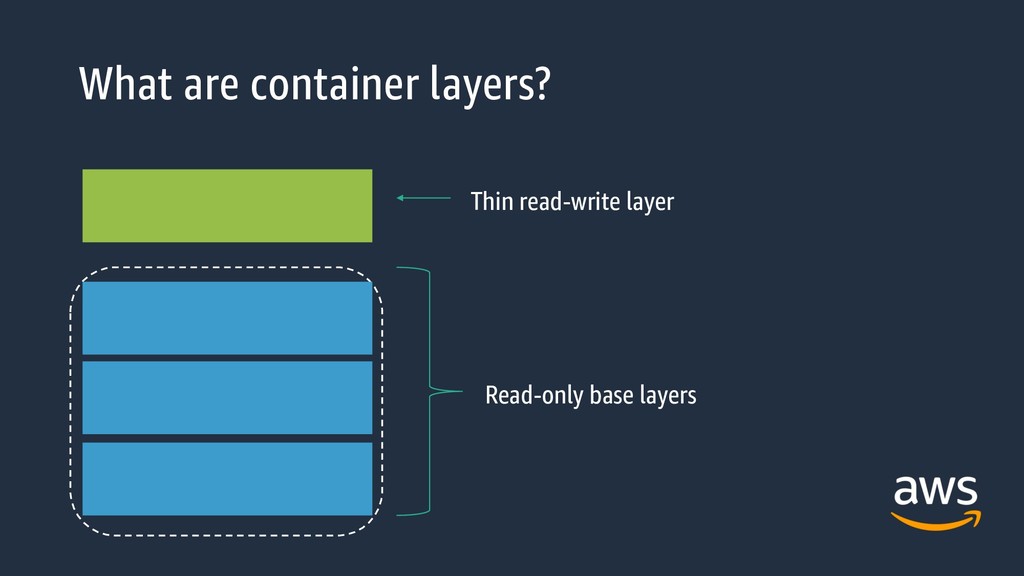
the size of your Docker images. They add up quickly, with big consequences. • The more layers you have (in general), and the larger those layers are, the larger your final image will be. This eats up disk space. • You don’t always need the recommended packages (--no-install- recommends)
is caring. • Use shared base images where possible • Limit the data written to the container layer • Chain RUN statements • Prevent cache misses at build for as long as possible
RUN, ADD or COPY will add layers. Other instructions will not (Docker 1.10 and above) • How the cache works: starting from the current layer, Docker looks backwards at all child images to see if they use the same instruction. If so, the cache is used*** • For ADD and COPY: a checksum is used: other than with ADD and COPY, Docker looks at the string of the command, not the contents of the packages (for example, with apt-get update)
if my command string is always the same, but I need to rerun the command? For example, with git commands. You can ignore the cache, or some people break it by changing in the string each time (like with a timestamp)
you download and install a package (like with curl and tar), remove the compressed original in the same layer: RUN mkdir -p /app/cruft/ \ && curl -SL http://cruft.com/bigthing.tar.xz \ | tar -xvf /app/cruft/ \ && make -C /app/cruft/ all && \ rm /app/cruft/bigthing.tar.xz
and system prune: • Make sure your orchestration platform (like ECS or K8s) is garbage collecting: • ECS • Kubernetes • 3rd party tools like spotify-gc
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}