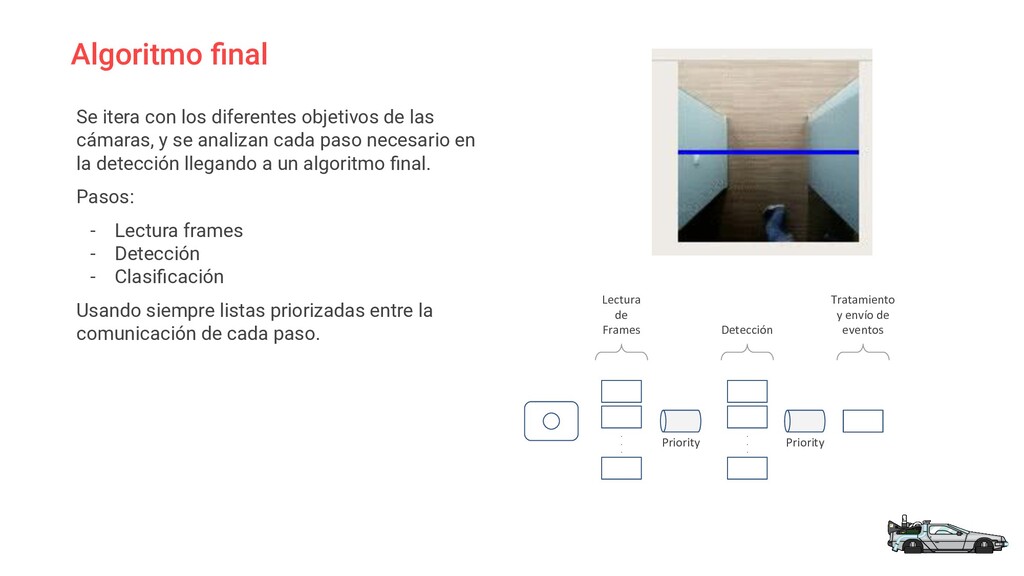
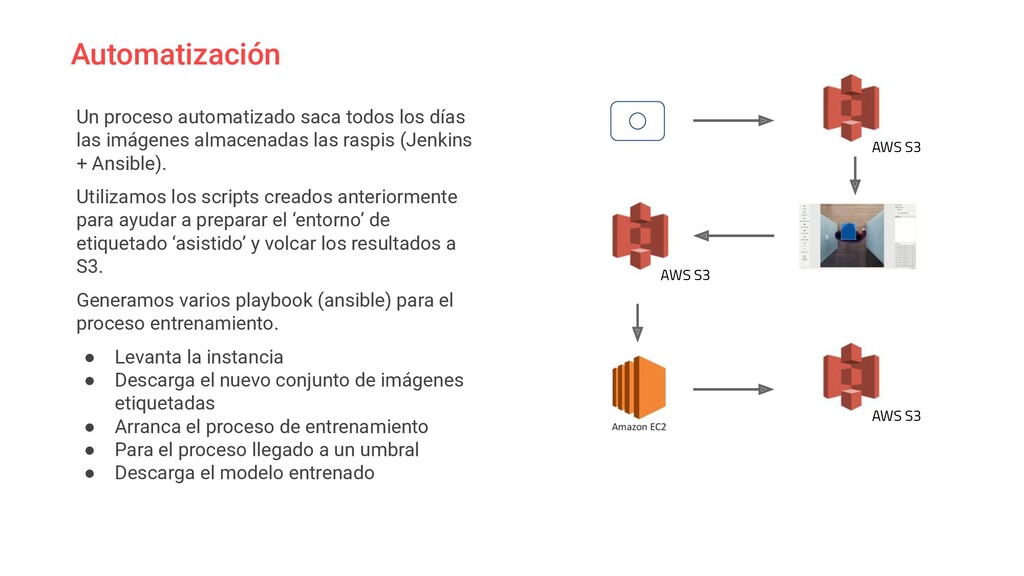
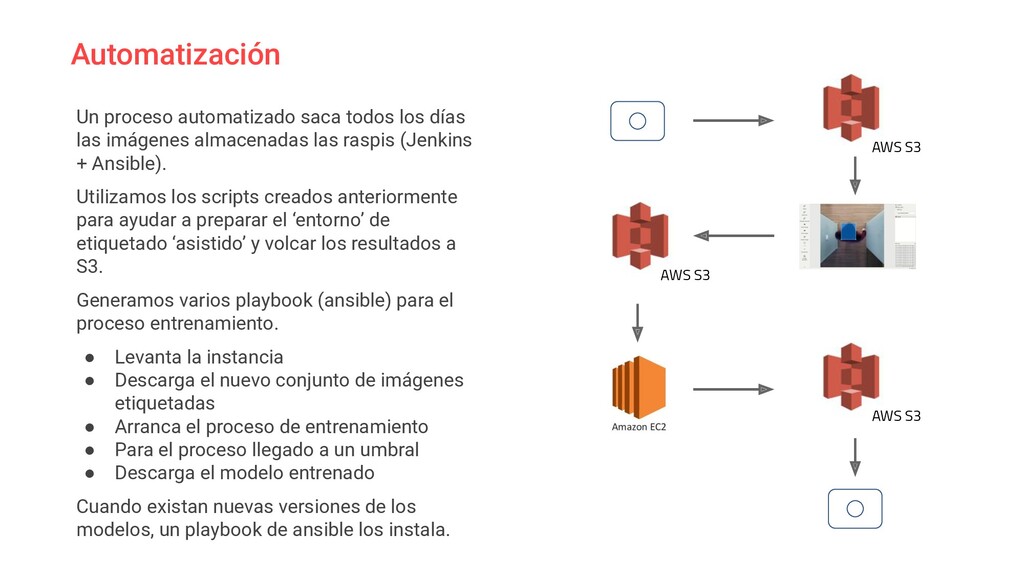
En este charla trataremos un caso práctico en el que se ha implementado un solución de *smart-office* dentro del ecosistema **IoT de AWS**.
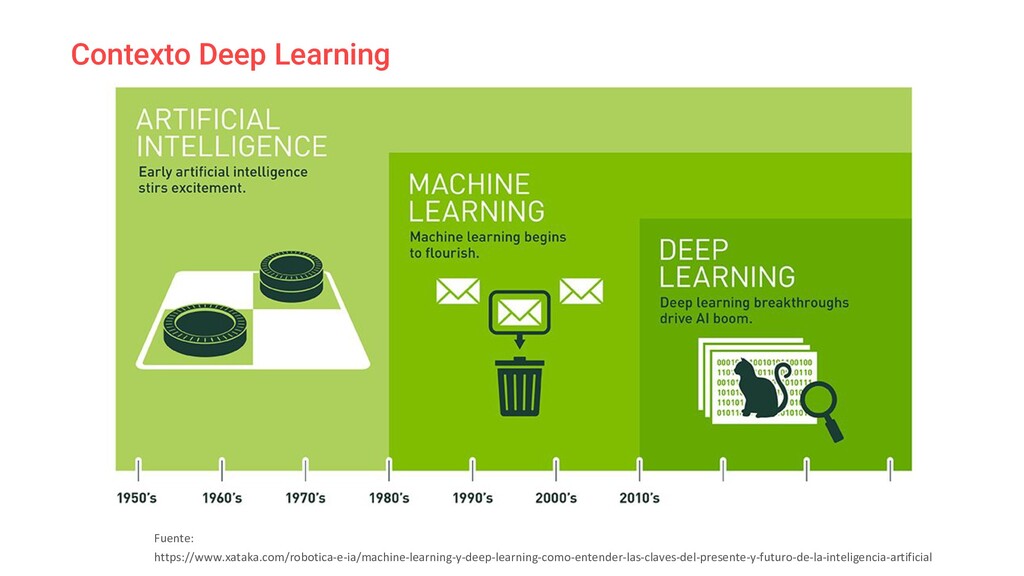
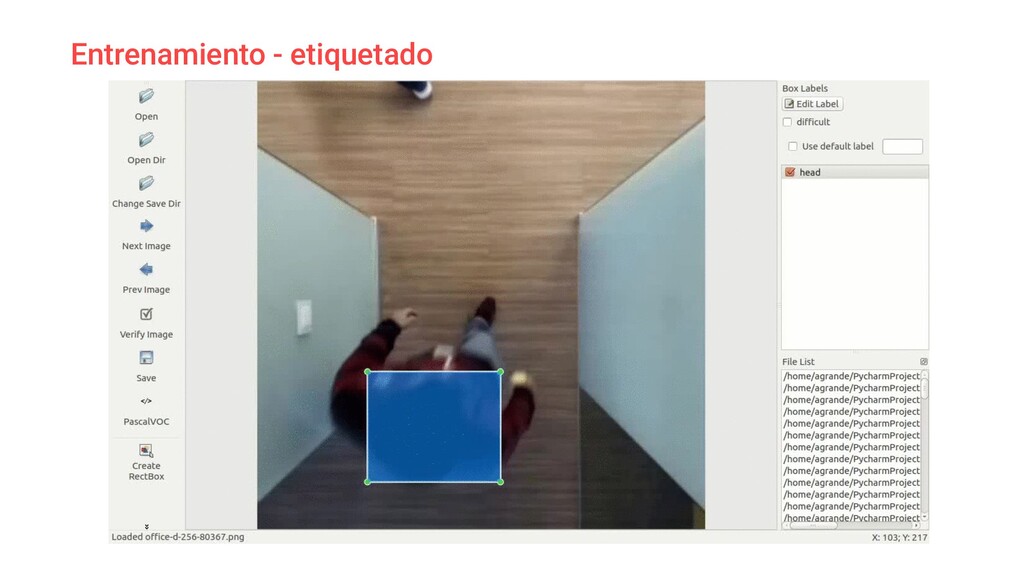
El sistema se apoya en hardware básico (Raspberrypi) y mediante un algoritmo de **aprendizaje supervisado** a través del reconocimiento de imágenes con *OpenCV* monitorizamos el uso de salas y zonas comunes de la oficina.
Analizaremos problemas y soluciones aplicadas durante su desarrollo, desde el propio entrenamiento del algoritmo hasta la arquitectura del sistema implementada para ser capaces de ponerlo en marcha sobre hardware poco potente.
{kind=link}
{kind=link}
{kind=link}
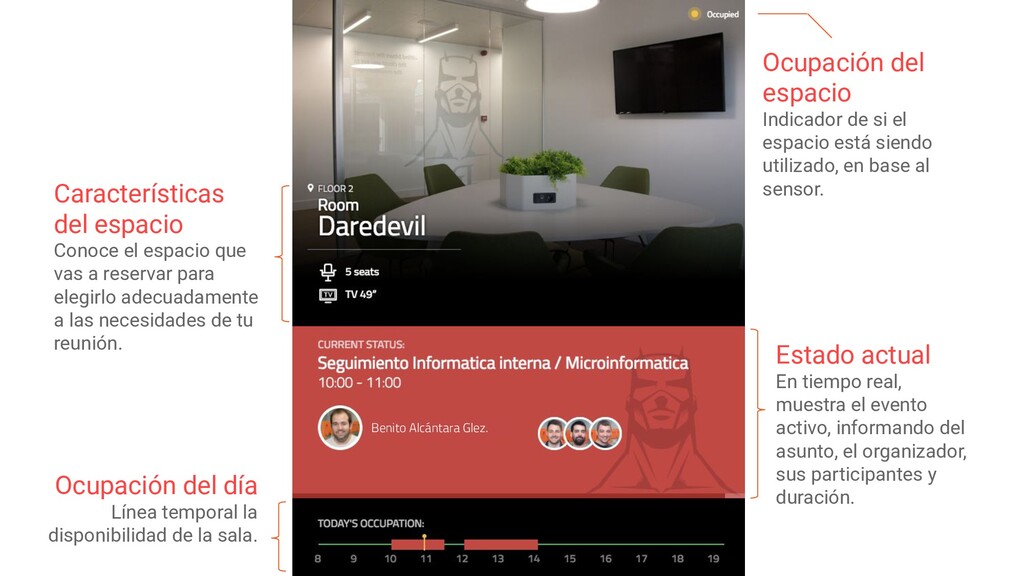{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
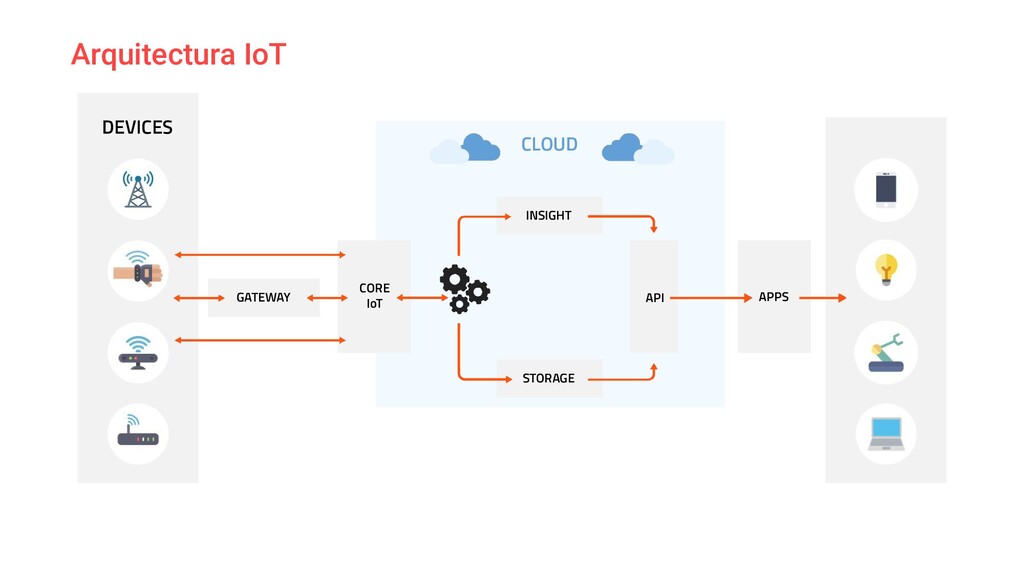{kind=link}
{kind=link}
{kind=link}
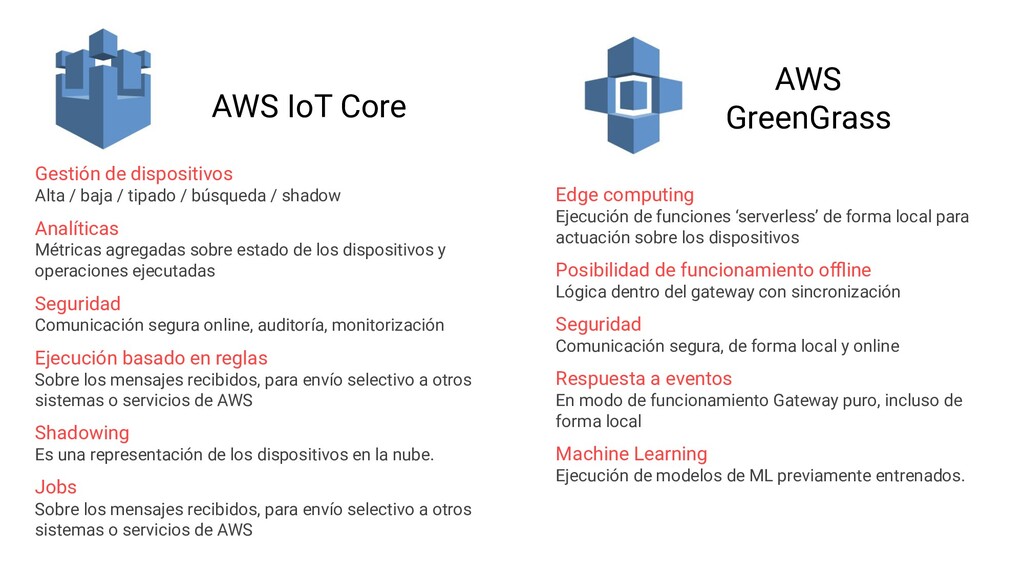{kind=link}
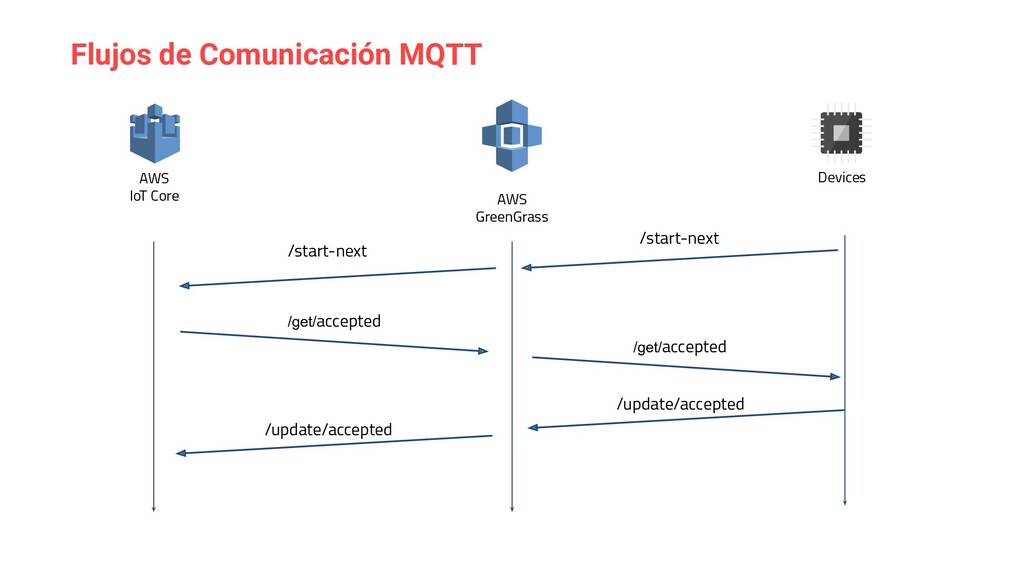{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
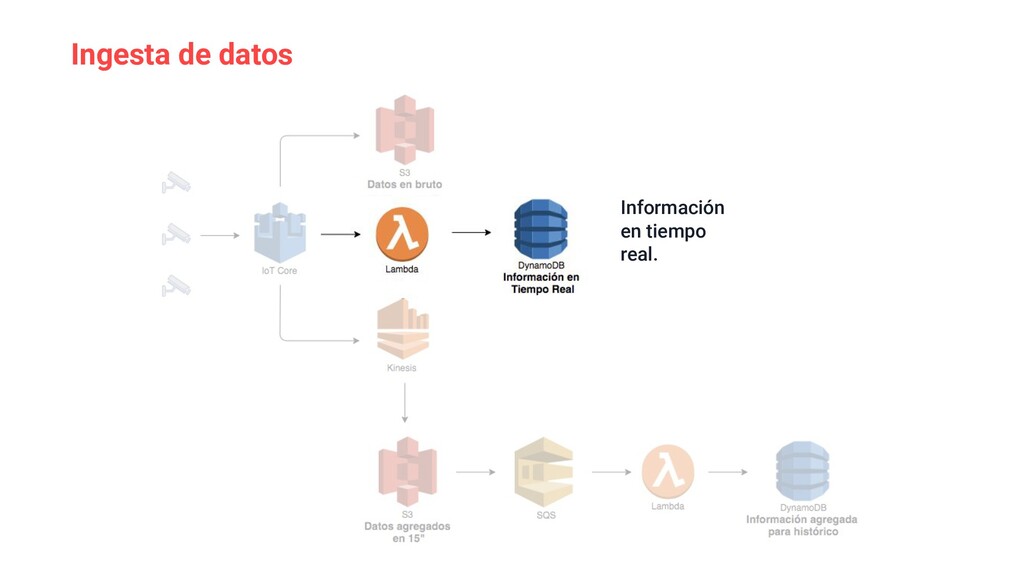{kind=link}
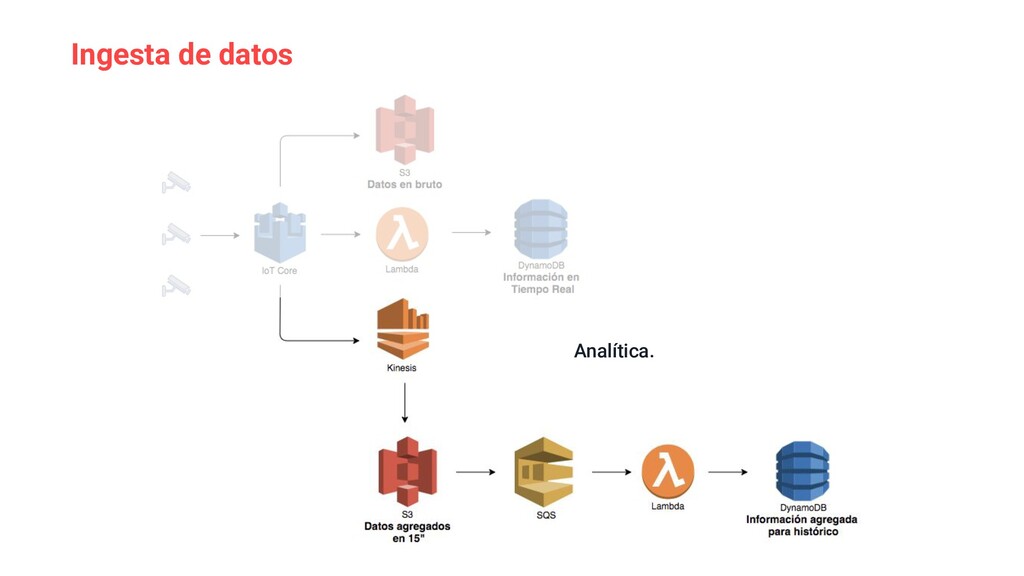{kind=link}
{kind=link}
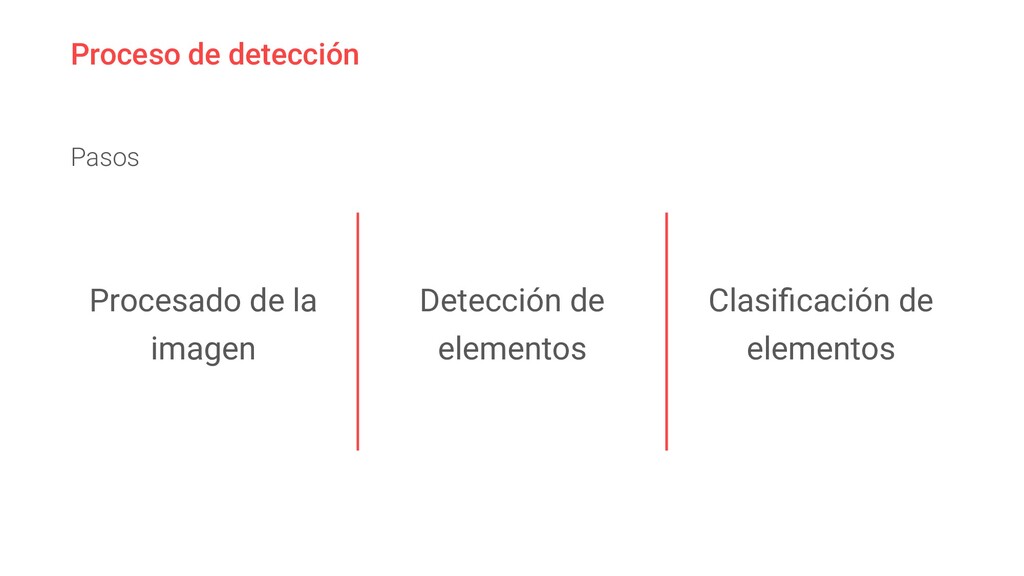{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
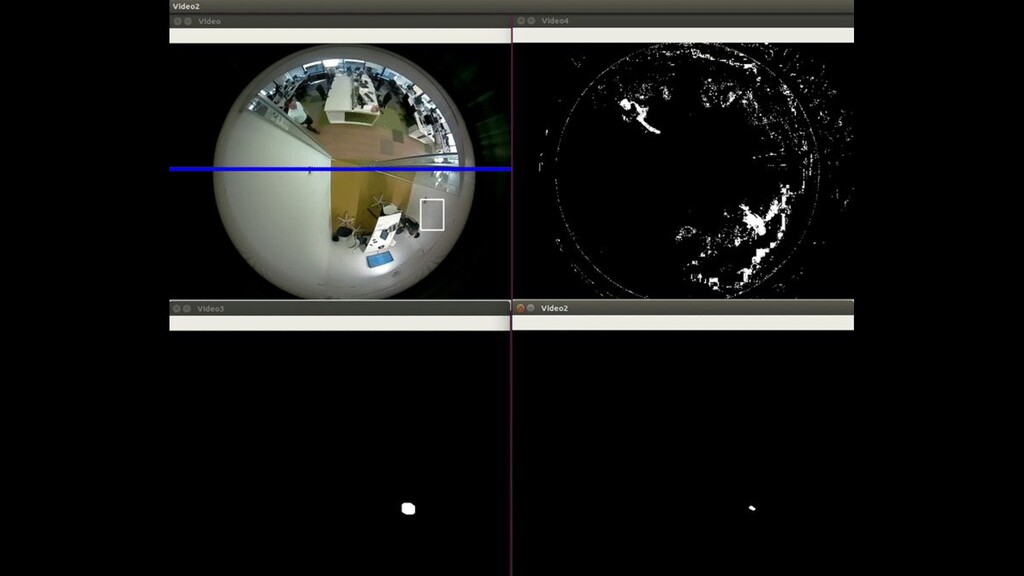{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}