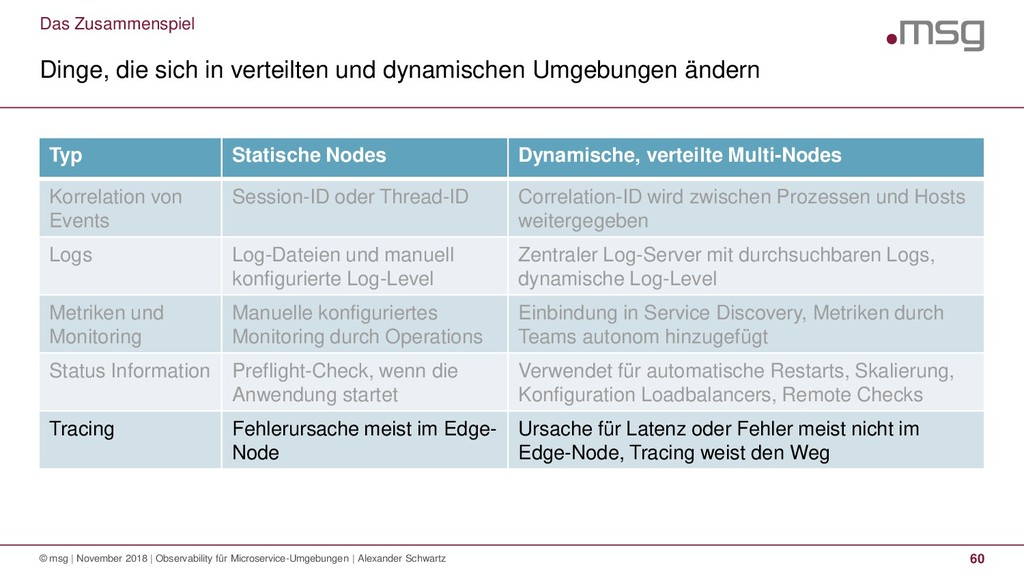
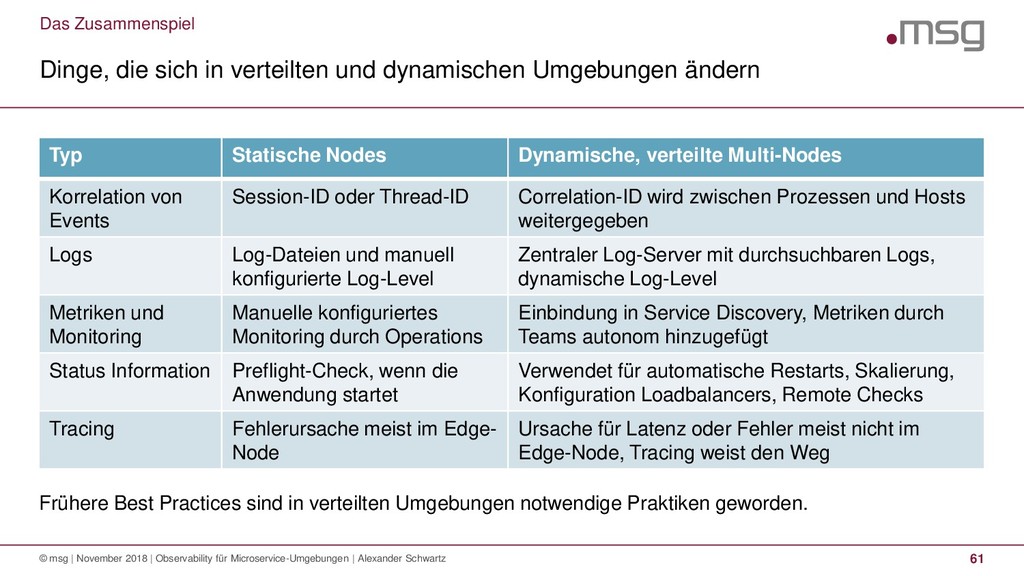
Anwendungen müssen Status- und Laufzeitinformationen bereitstellen, damit Fehler erkannt und analysiert werden können. Verteilte und dynamische Microservices-Umgebungen müssen dies standardisiert umsetzen, damit ein effizienter Betrieb möglich ist.
Dieser Vortrag stellt die vier Bereiche vor, die zur Beobachtbarkeit (Observability) dazugehören: Statusinformationen, Logs, Metriken und Traces. Technologiebeispiele zu Spring Boot Actuator, Log4j, Micrometer und Prometheus zeigen, wie die Konzepte praktisch umgesetzt werden können.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
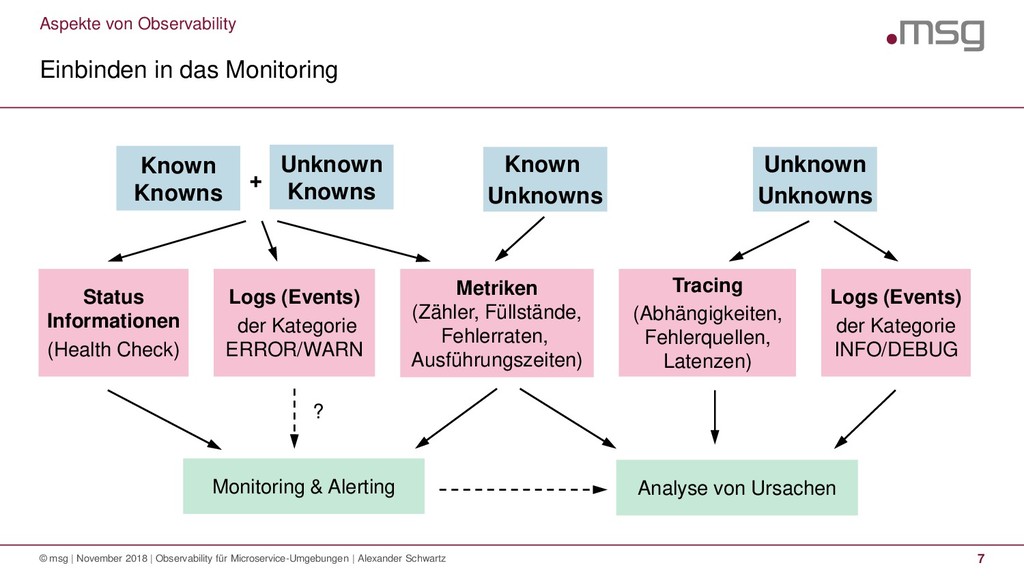{kind=link}
{kind=link}
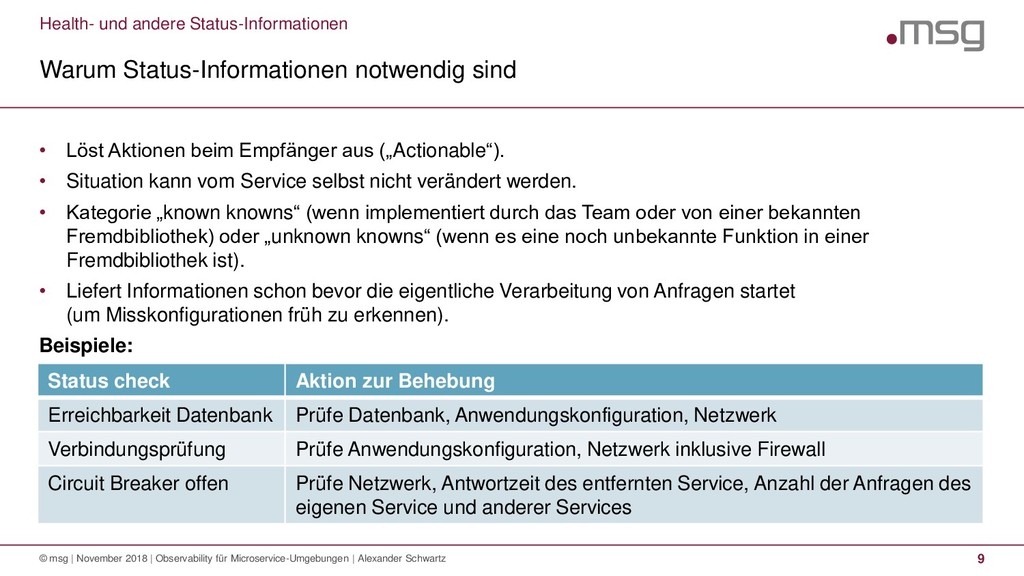{kind=link}
{kind=link}
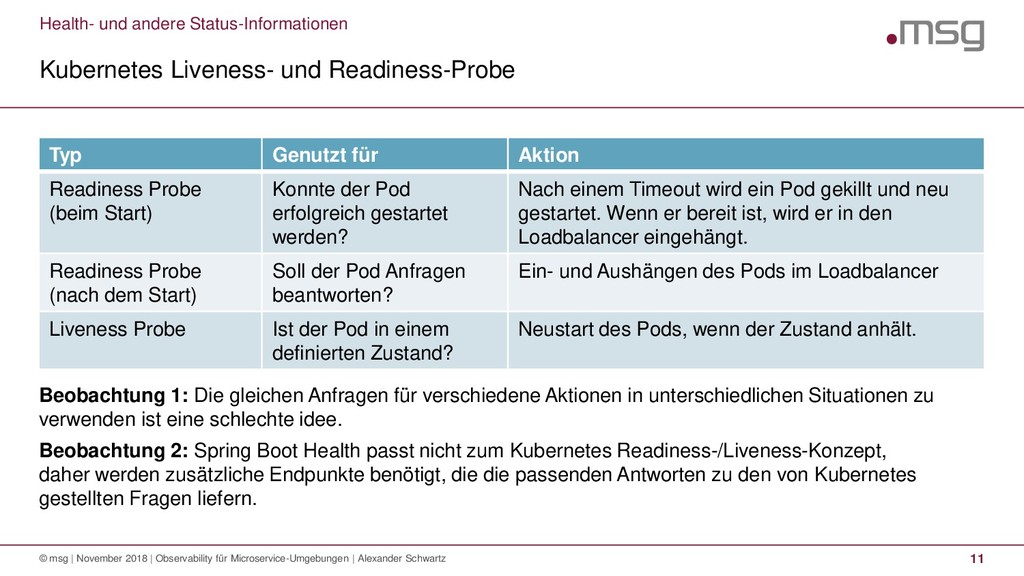{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
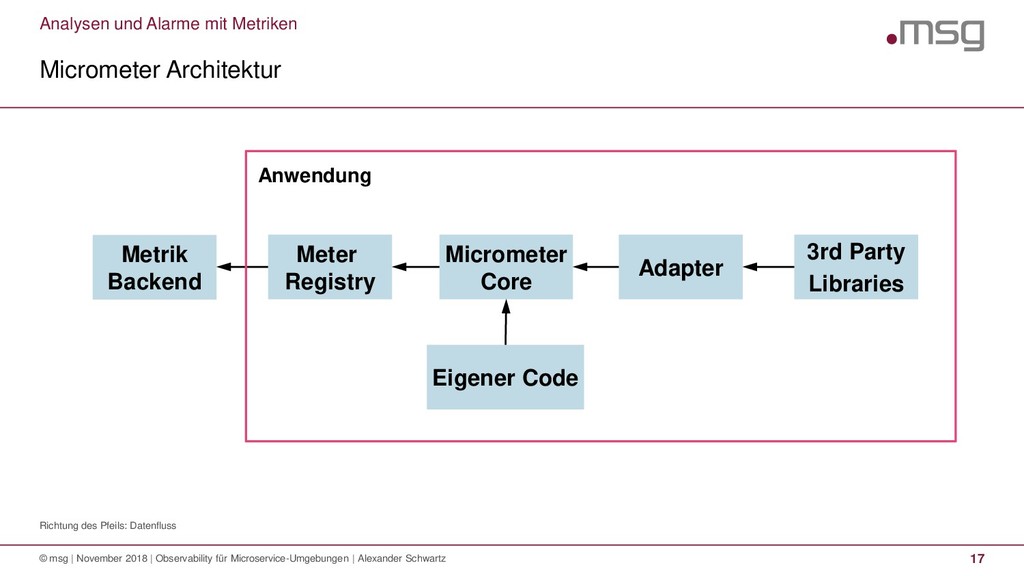{kind=link}
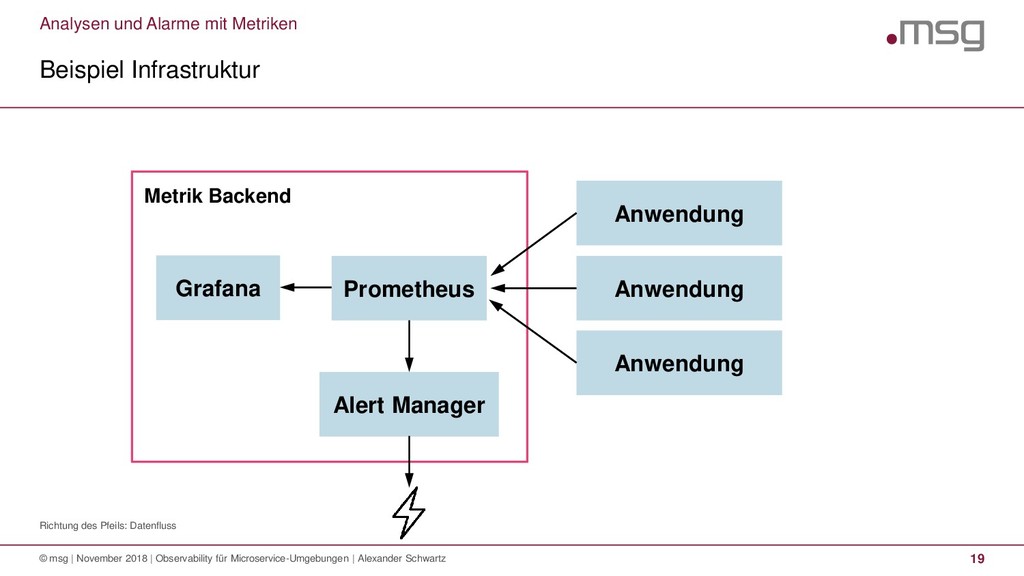{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
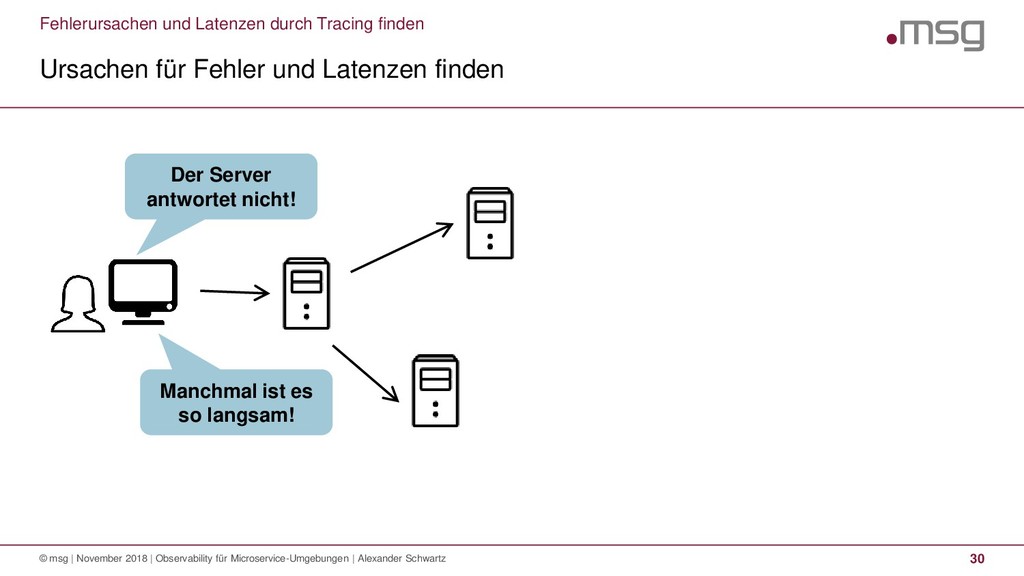{kind=link}
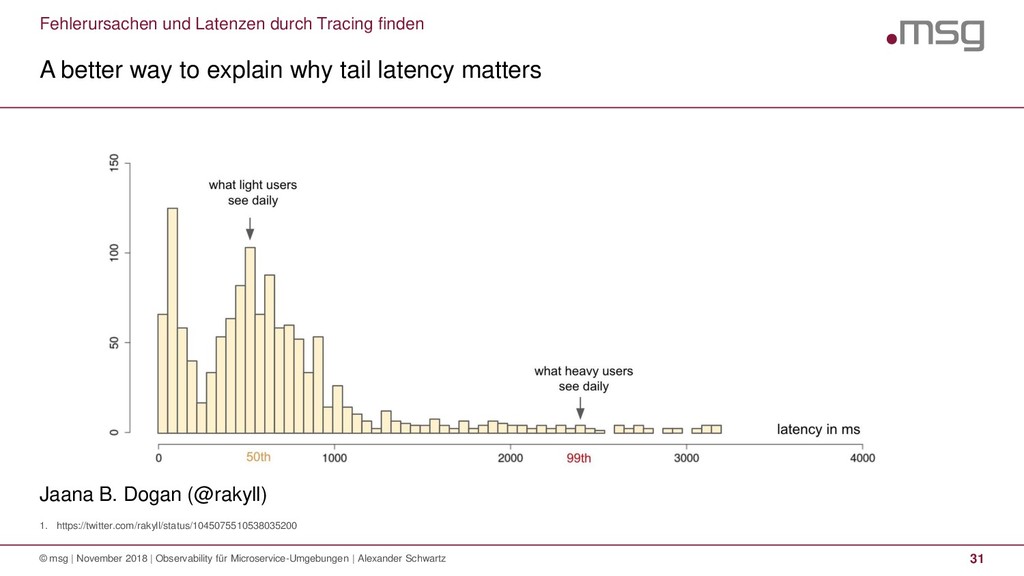{kind=link}
{kind=link}
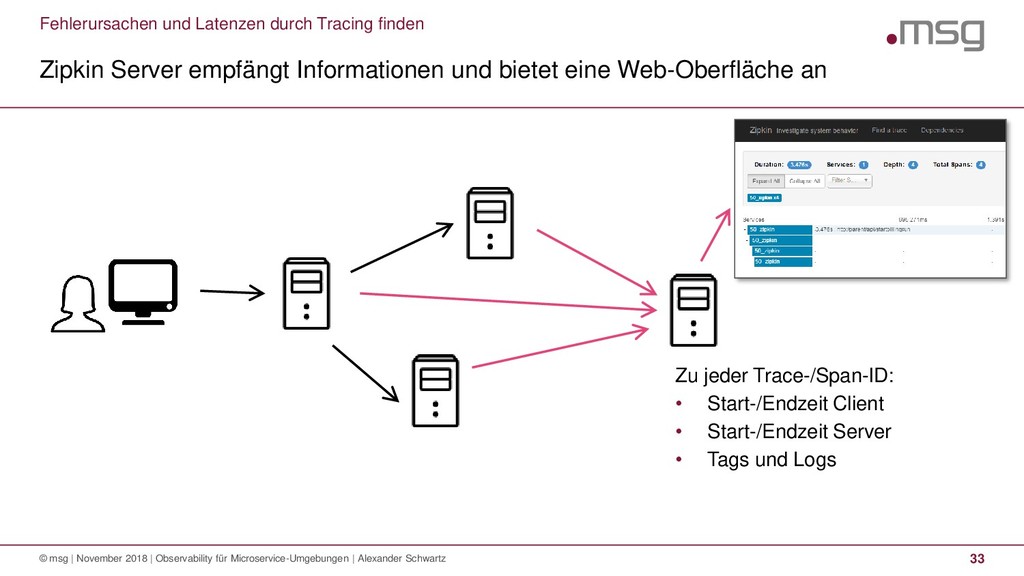{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}