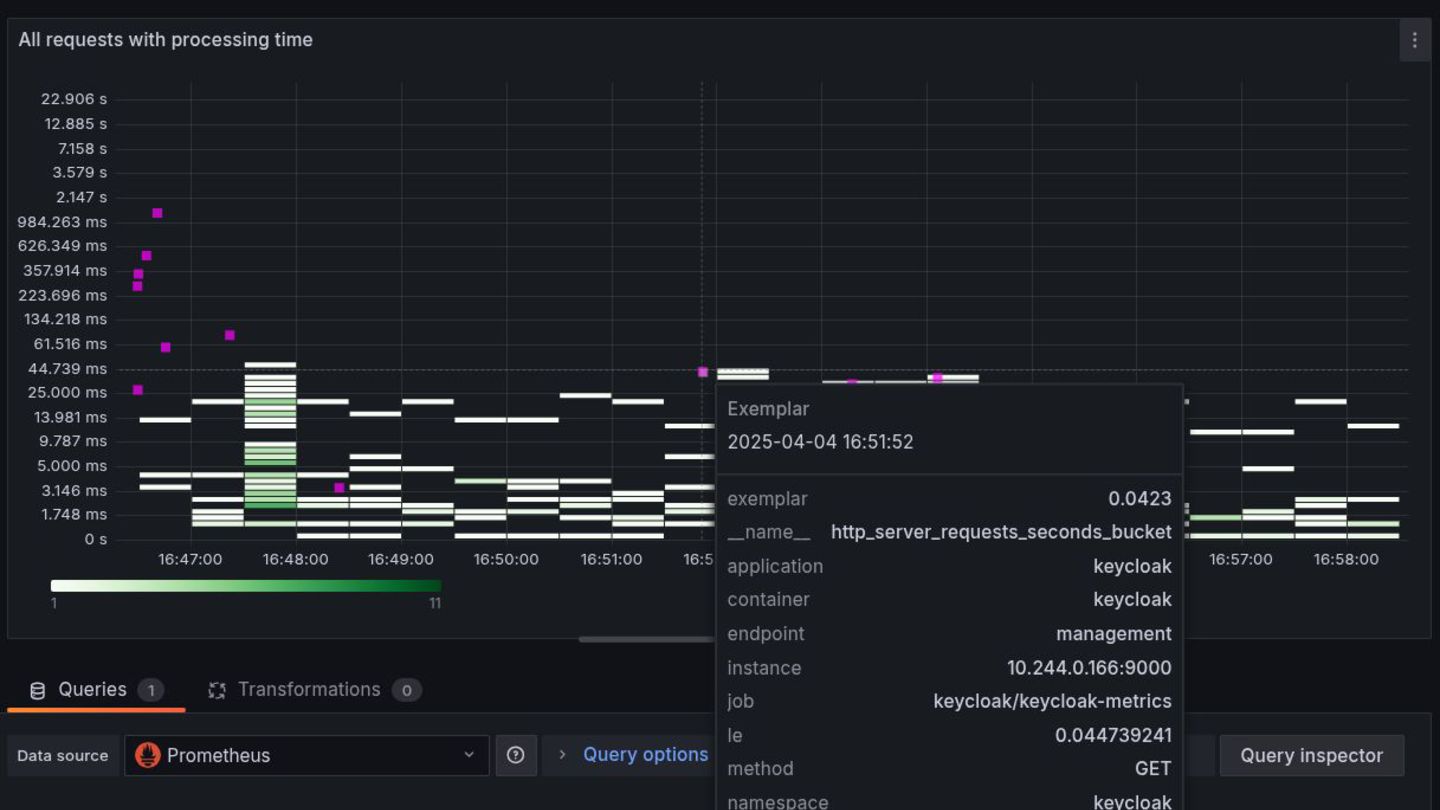
A single sign-on system like Keycloak is a central component of the application landscape. Users depend on it to log in to their applications. Detailed monitoring and analysis options help prevent outages or resolve them quickly.
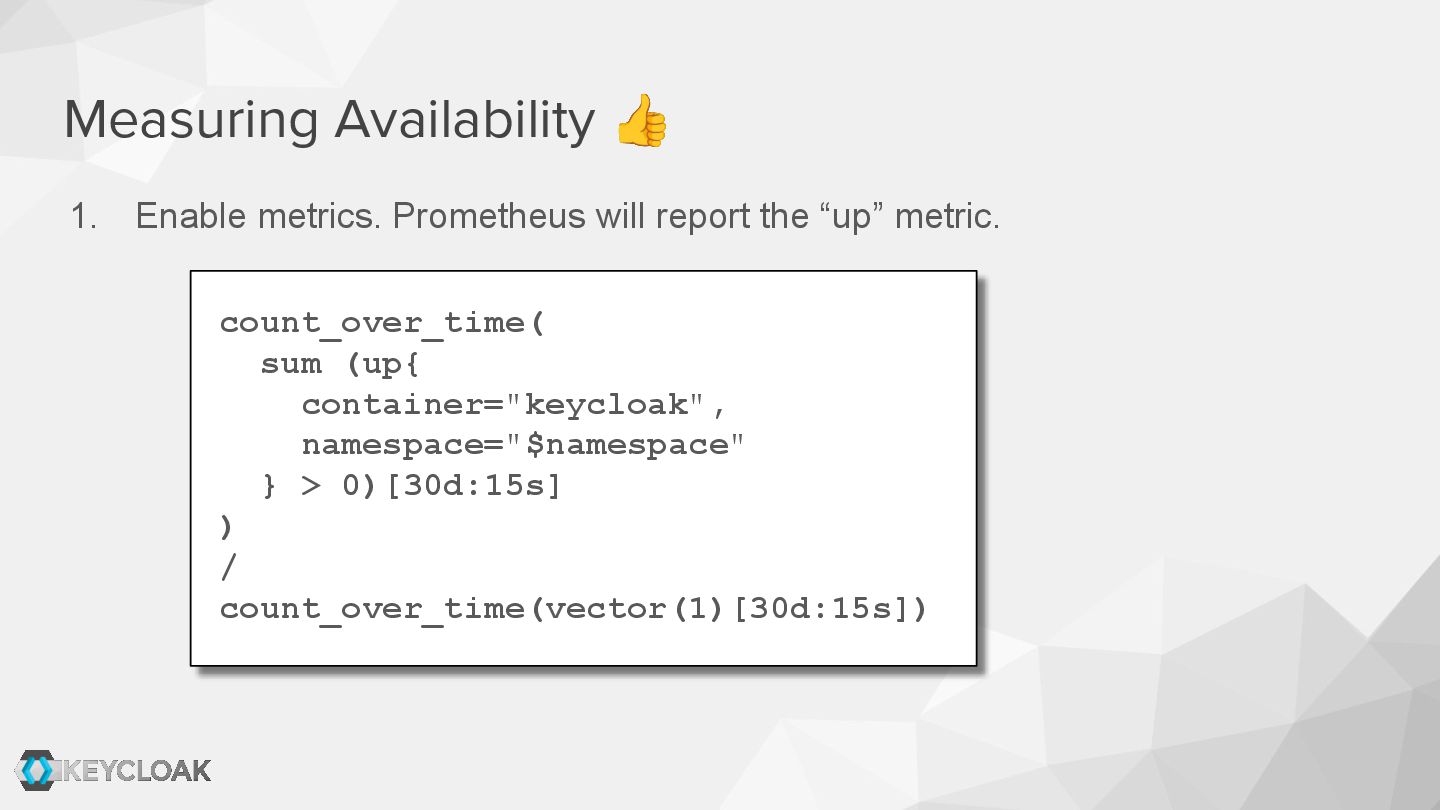
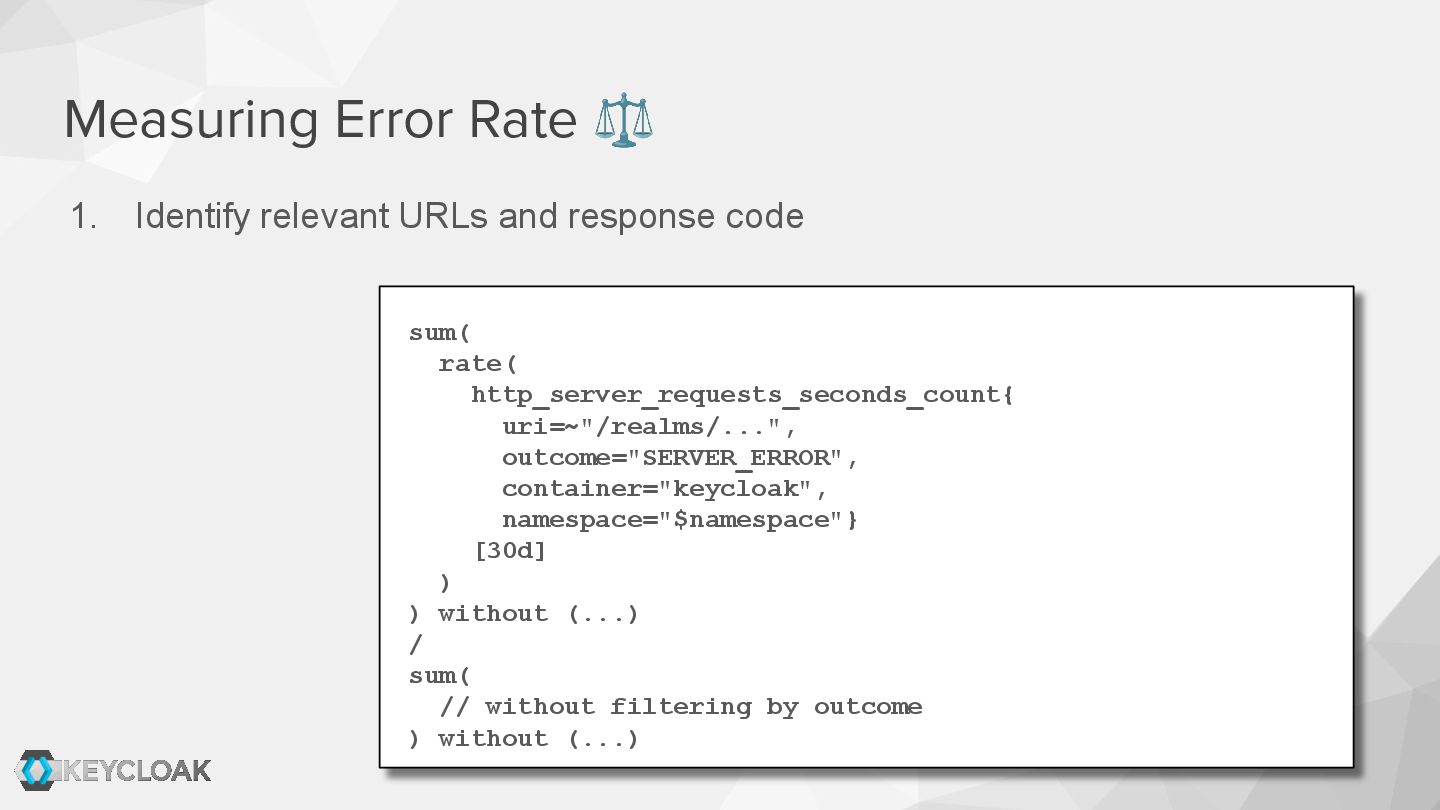
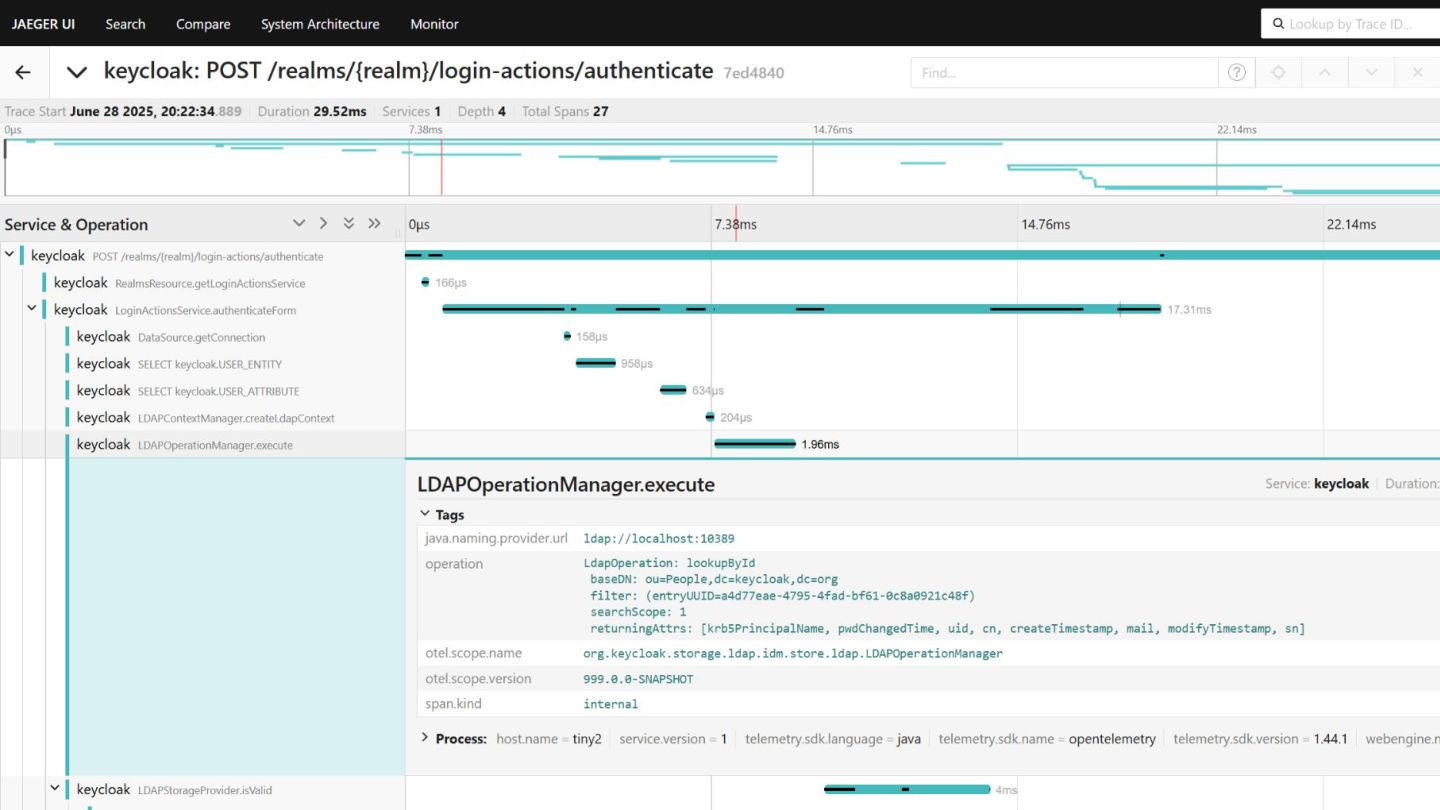
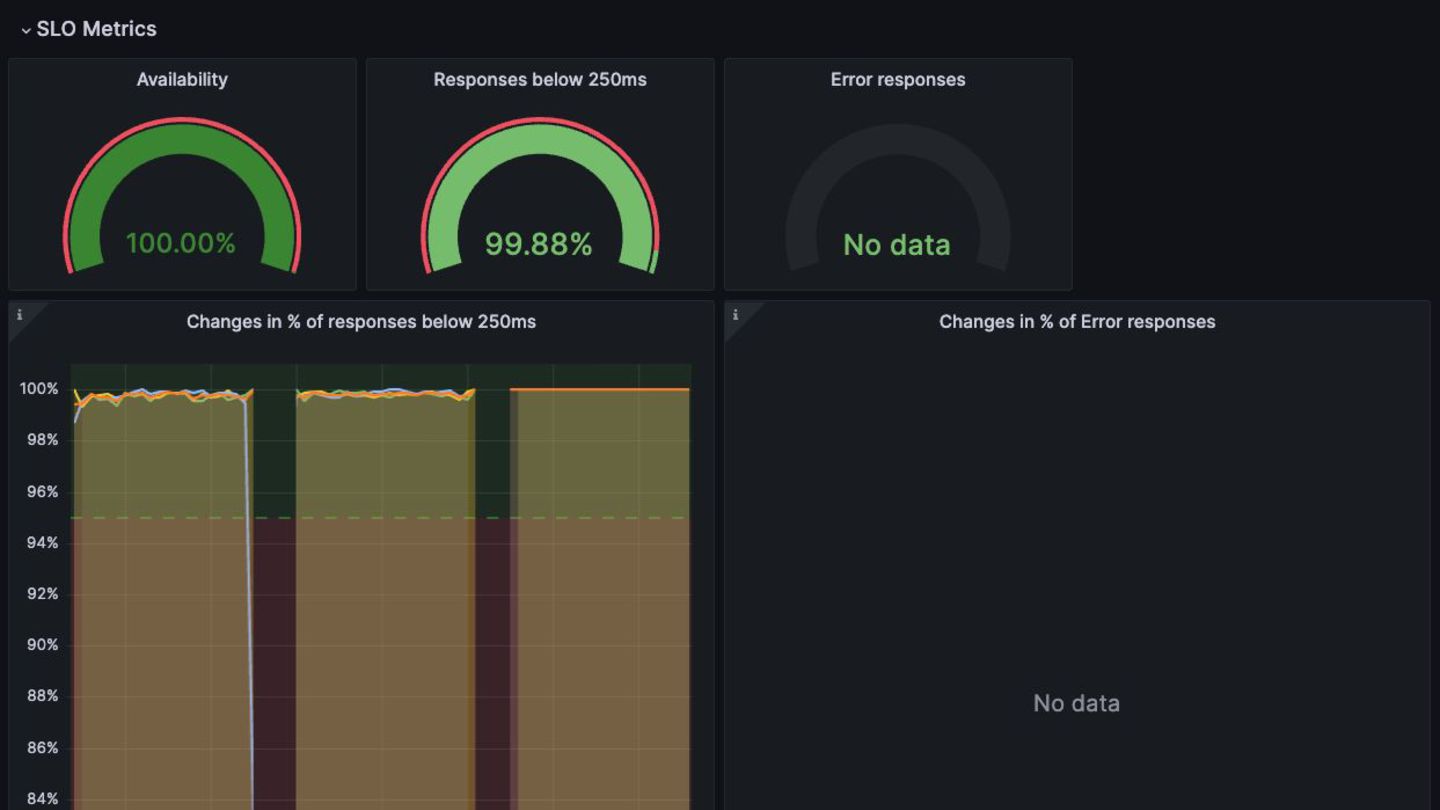
Over the past 12 months, the Keycloak team has implemented numerous technical improvements regarding logs, metrics, and traces. We also provide a guide to service-level indicators and a matching Grafana dashboard for defining and monitoring behavior from the user perspective.
This talk offers practical advice on using Keycloak and is also a case study of how observability can be implemented for custom-built applications.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Contact Alexander Schwartz Principal Software Engineer [email protected] https://www.ahus1.de @ahus1.de @[email protected]](https://files.speakerdeck.com/presentations/7121298501584e9cb307eb665512fd43/slide_26.jpg){kind=link}